Netweaver
el
深度遍历
云idea
SylixOS
系统
博通蓝牙vendor
标准库与HAL库实现
通识
EMC
远程工作
cannones
ACK
MMoE
中断
xargs
图片分享平台
每日一问
死锁
遗传算法
论文阅读
2024/4/11 13:56:32
多视图聚类的论文阅读
当聚类的方式使用的是某一类预定义好的相似性度量时, 会出现如下情况:
数据聚类方面取得了成功,但它们通常依赖于预定义的相似性度量,而这些度量受原始方法的影响:当输入维数相对较高时,往往是无效的。
1. Deep Mult…

论文阅读:“基于快速特征点提取和描述算法与色调、饱和度和明度的图像特征点匹配算法”
文章目录 摘要引言方法实验结果图像预处理结果对比图像配准结果对比 参考文献 摘要
提出了一种基于快速点特征提取和描述(ORB)算法与色调、饱和度和明度(HSV)的图像特征点匹配算法。首先利用双边滤波和均值滤波结合对图像进行预处…
ICCV 2021《Hypercorrelation Squeeze for Few-Shot Segmentation》FSS论文笔记
link:<论文总结2> Hypercorrelation Squeeze for Few-Shot Segmentation (ICCV 2021) 链接讲的很清楚详细。记录一下。
5+铁死亡+分型+多组机器学习,铁死亡到现在还是大热
今天给同学们分享一篇生信文章“Identification of ferroptosis-related molecular clusters and genes for diabetic osteoporosis based on the machine learning”,这篇文章发表在Front Endocrinol (Lausanne)期刊上,影响因子为5.2。 结果解读&#x…
《一种使用光电容积图和生物特征进行无需校准的非侵入式血压估计方法》阅读笔记
目录
一、论文摘要
二、论文十问
Q1:论文试图解决什么问题?
Q2:这是否是一个新的问题?
Q3:这篇文章要验证一个什么科学假设?
Q4:有哪些相关研究?如何归类?谁是这一…

论文阅读新神器SciSpace(Typeset.io)测评-和AI一起进化
论文阅读神器SciSpace(Typeset.io)测评-和AI一起进化
恳请各位大佬的点赞,您的点赞是我更新的动力! 文章目录论文阅读神器SciSpace(Typeset.io)测评-和AI一起进化前言:SciSpace使用教程和测评:前言:
最近沉迷chat的使用和开发&a…

【论文阅读】SeaD: End-to-end Text-to-SQL Generation with Schema-aware Denoising
【论文阅读】SeaD: End-to-end Text-to-SQL Generation with Schema-aware Denoising 文章目录 【论文阅读】SeaD: End-to-end Text-to-SQL Generation with Schema-aware Denoising1. 来源2. 介绍3. 模型3.0 问题定义3.1 采样公式3.2 带指针的 Transformer3.3 模式感知去噪&am…
SimCSE论文阅读
正负样本对构建原理正样本pair:one sentence two different embeddings as “positive pairs”. (通过dropout 作为噪声)负样本pair:Then we take other sentences in the same mini-batch as “negatives”任务: the model predicts the pos…
Hausdorff是什么距离,怎样计算的
Hausdorff距离是一种用于度量两个集合之间的相似性或差异性的距离度量指标。它基于数学家Felix Hausdorff的工作而得名。
对于给定的两个集合A和B,Hausdorff距离定义为集合A中的每个点到集合B的最近点的最大距离,与集合B中的每个点到集合A的最近点的最大…
![[论文笔记] Scaling Laws for Neural Language Models](https://img-blog.csdnimg.cn/2674d8d5c6c84d59b73491ca58184c91.png)
[论文笔记] Scaling Laws for Neural Language Models
概览: 一、总结 计算量、数据集大小、模型参数量大小的幂律 与 训练损失呈现 线性关系。
三个参数同时放大时,如何得到最佳的性能? 更大的模型 需要 更少的样本 就能达到相同的效果。 </
论文笔记--Deep contextualized word representations
论文笔记--Deep contextualized word representations 1. 文章简介2. 文章概括3 文章重点技术3.1 BiLM(Bidirectional Language Model)3.2 ELMo3.3 将ELMo用于NLP监督任务 4. 文章亮点5. 原文传送门 1. 文章简介
标题:Deep contextualized word representations作者…
【论文阅读】VideoComposer: Compositional Video Synthesis with Motion Controllability
VideoComposer: 具有运动可控性的合成视频。
paper:[2306.02018] VideoComposer: Compositional Video Synthesis with Motion Controllability (arxiv.org)
由阿里巴巴研发的可控视频生成框架,可以灵活地使用文本条件、空间条件和时序条件…

【论文阅读】HOLMES:通过关联可疑信息流进行实时 APT 检测(SP-2019)
HOLMES: Real-time APT Detection through Correlation of Suspicious Information Flows S&P-2019 伊利诺伊大学芝加哥分校、密歇根大学迪尔伯恩分校、石溪大学 Milajerdi S M, Gjomemo R, Eshete B, et al. Holmes: real-time apt detection through correlation of susp…
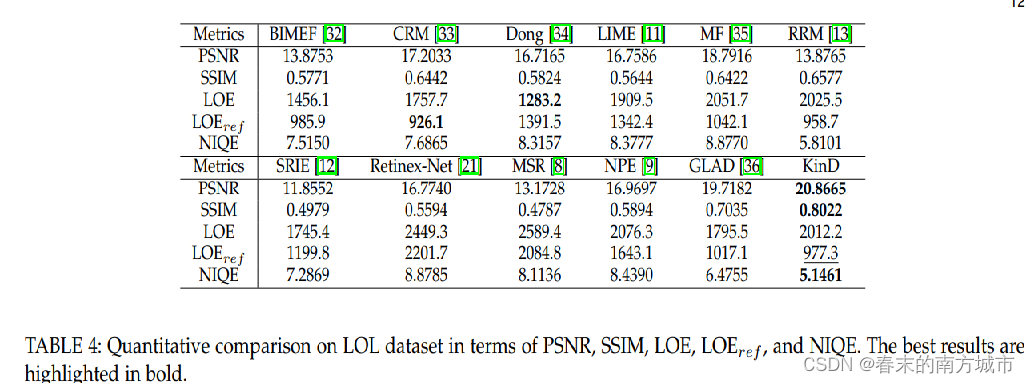
论文阅读之《Kindling the Darkness: A Practical Low-light Image Enhancer》
目录
摘要
介绍
已有方法回顾
普通方法
基于亮度的方法
基于深度学习的方法
基于图像去噪的方法
提出的方法
2.1 Layer Decomposition Net
2.2 Reflectance Restoration Net
2.3 Illumination Adjustment Net
实验结果
总结 Kindling the Darkness: A Practical L…
【论文阅读】Resnet
第一遍
深度残差学习
微软亚洲研究院
残差网络很容易训练,并且可以得到很好的精度
深八倍,更低的复杂度
CVPR要求正文数量不能超过八页
怎么让更深的神经网络更容易训练
通过图:在没有加残差层时,34层的网络的误差比18层的…
一种基于外观-运动语义表示一致性的视频异常检测框架 论文阅读
A VIDEO ANOMALY DETECTION FRAMEWORK BASED ON APPEARANCE-MOTION SEMANTICS REPRESENTATION CONSISTENCY 论文阅读 ABSTRACT1. INTRODUCTION2. PROPOSED METHOD3. EXPERIMENTAL RESULTS4. CONCLUSION阅读总结: 论文标题:A VIDEO ANOMALY DETECTION FRA…
论文阅读<MULTISCALE DOMAIN ADAPTIVE YOLO FOR CROSS-DOMAIN OBJECT DETECTION>
论文链接:https://arxiv.org/pdf/2106.01483v2.pdfhttps://arxiv.org/pdf/2106.01483v2.pdf
代码链接:GitHub - Mazin-Hnewa/MS-DAYOLO: Multiscale Domain Adaptive YOLO for Cross-Domain Object DetectionMultiscale Domain Adaptive YOLO for Cross…

Zotero插件安装、问题、bug大全(随时更新)
Zotero插件安装、问题、bug大全(随时更新) 1. 插件安装2. 茉莉花(Jasminum)插件使用tips及可能遇到的问题2.1 更新2.2 未找到PDFtk Server的可执行文件 问题解决方法 3. Zotero Sci-hub插件相关问题3.1 Zotero Sci-hub插件有时抓取…
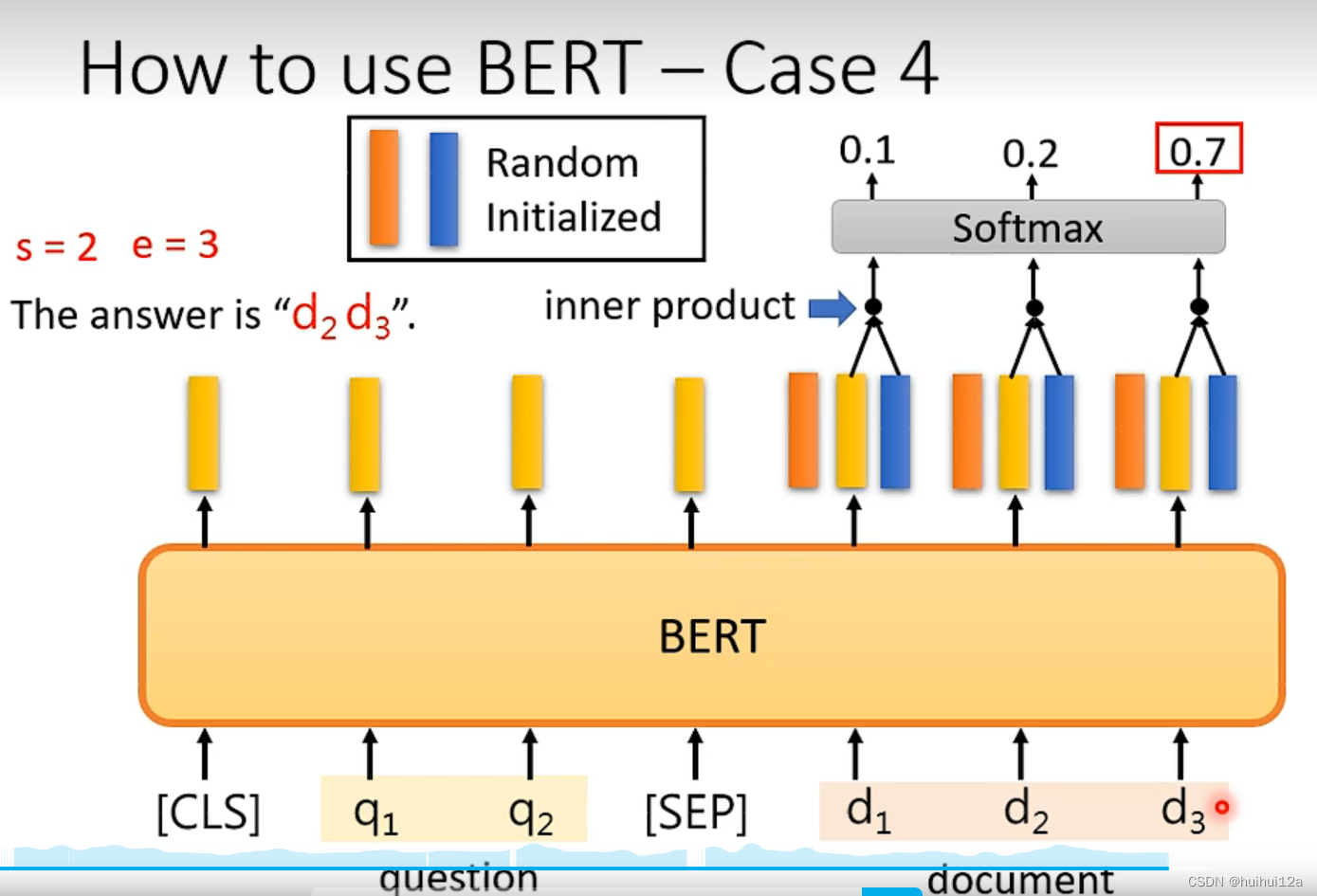
BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding
参考BERT原文[1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (arxiv.org)【(强推)李宏毅2021/2022春机器学习课程】 https://www.bilibili.com/video/BV1Wv411h7kN/?p73&share_sourcecopy_web&vd_source30e93e9c70e…
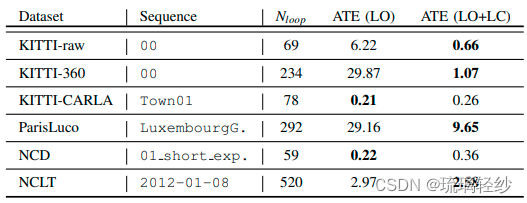
论文阅读及复现——《CT_ICP: Real-time Elastic LiDAR Odometry with Loop Closure》
论文阅读之——《CT_ICP: Real-time Elastic LiDAR Odometry with Loop Closure》带闭环的实时弹性激光雷达里程计 1. 主要贡献2. 相关说明3. 激光里程计3.1 里程计公式构建3.2 局部地图与健壮性 4. 回环检测与后端5. 实验结果5.1 里程计实验结果5.2 回环检测实验结果 6. 总结…
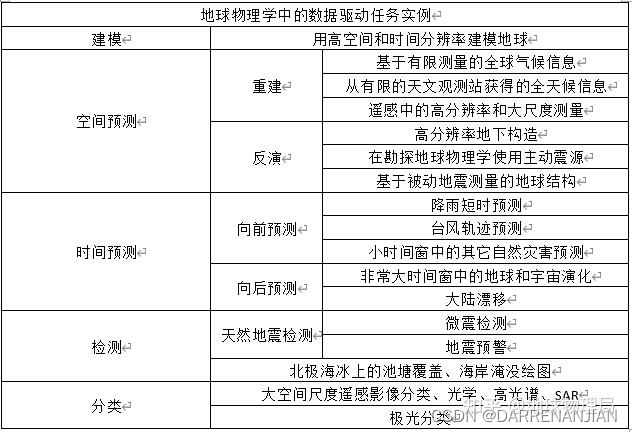
Deep Learning for Geophysics综述阅读(未完)
文章题目《Deep Learning for Geophysics: Current and Future Trends》
文章解读:地球物理学(人工智能轨道)——(1)文献翻译《面向地球物理学的深度学习:当前与未来趋势》 - 知乎 (zhihu.com)
这里主要列…
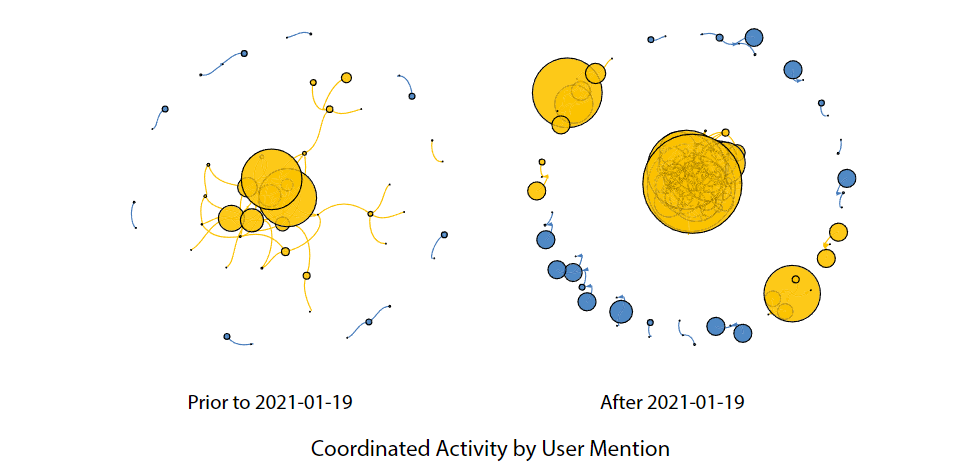
论文阅读 - Hidden messages: mapping nations’ media campaigns
论文链接:
https://link.springer.com/content/pdf/10.1007/s10588-023-09382-7.pdf
目录
1 Introduction
2 The influence model
2.1 The influence‑model library 3 Data
4 Methodology
4.1 Constructing observations
4.2 Learning the state‑transiti…

【半监督】Minimizing Estimated Risks on Unlabeled Data文章
【Segment Anything Model】做分割的专栏链接,欢迎来学习。 【数据集介绍和预处理】处理医疗数据集的专栏链接,欢迎来学习。 【博主微信】cvxiayixiao 【医疗AI】本专栏为医疗AI方向论文学习 文章目录 论文信息摘要Intro研究背景与动机研究重点与贡献主要…
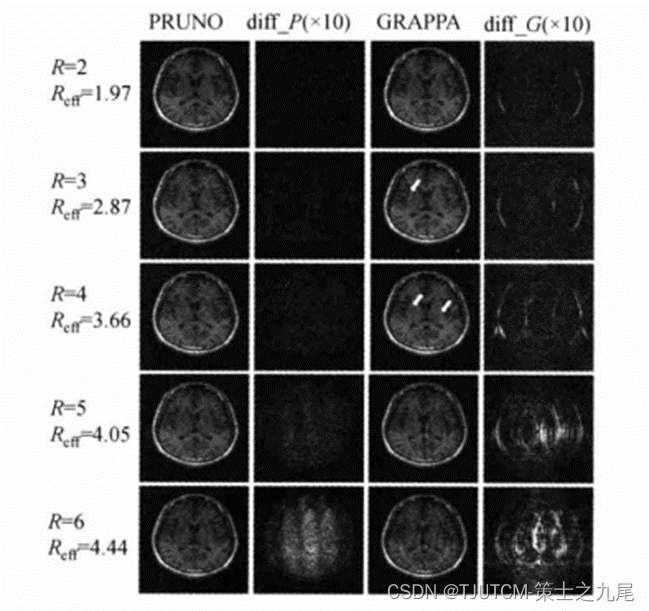
【核磁共振成像】并行采集MRI
目录 一、并行成像二、SENSE重建三、SMASH重建四、灵敏度校准五、AUTO-SMASH和VD-AUTO-SMASH六、GRAPPA重建七、SPACE RIP重建算法八、PILS重建算法九、PRUNO重建算法十、UNFOLD算法 一、并行成像 并行MR成像(pMRI):相位阵列接受线圈不但各有自己专用的接受通道,而且…
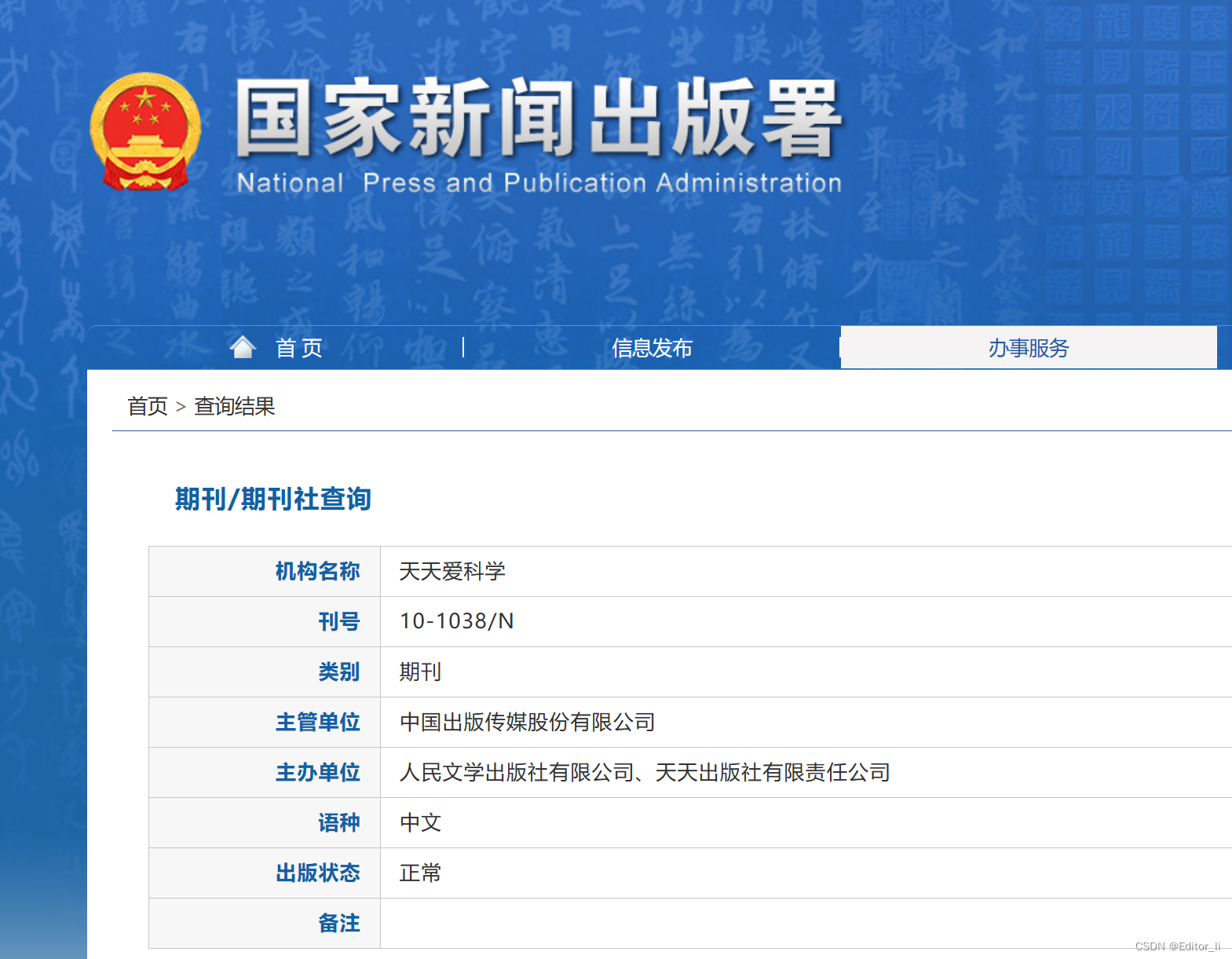
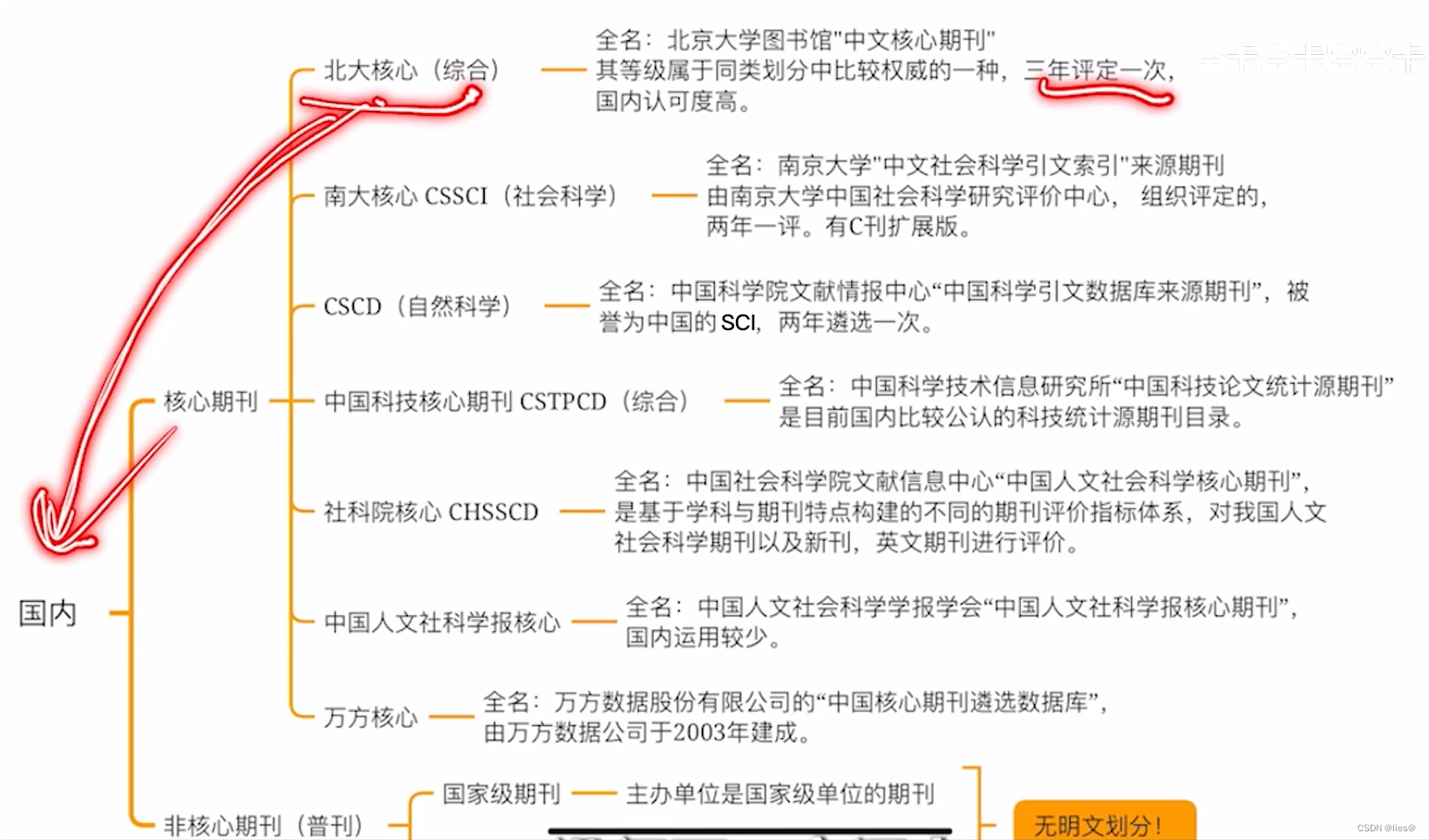
《天天爱科学》期刊国家级知网投稿
《天天爱科学》国家级期刊知网收录,投稿方向:幼儿教育、基础教育文章,不收案例分析、教学设计、图表讲解、例题分析。
刊名:天天爱科学
主管单位:中国出版传媒股份有限公司
主办单位:人民文学出版社有限…
论文复现代码《基于自适应哈夫曼编码的密文可逆信息隐藏算法》调试版
前言
本文展示论文《基于自适应哈夫曼编码的密文可逆信息隐藏算法》的复现代码。代码块的结构如下: 其中,每个代码块都包含了测试该代码块的功能的主函数代码,使用时可放心运行,前提是你按照这个包结构把文件命名改好,…

中医药治疗抑郁症——来自肠道菌群的解释
谷禾健康 抑郁症和抑郁情绪是不一样的,如果说抑郁情绪是一阵悲伤或沮丧,那么抑郁症可以具有巨大的深度和持久力。抑郁症不只是沮丧发作,也不是性格弱点,无法以“快刀斩乱麻”的方式轻松摆脱。 世界卫生组织统计,全球约…
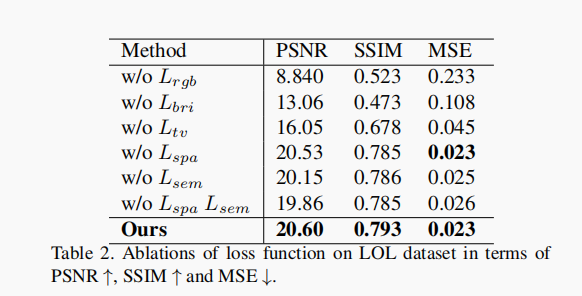
Semantic-Guided Zero-Shot Learning for Low-Light ImageVideo Enhancement
论文阅读之无监督低光照图像增强 Semantic-Guided Zero-Shot Learning for Low-Light Image/Video Enhancement
代码: https://github.com/ShenZheng2000/SemantiGuided-Low-Light-Image-Enhancement
在低光条件下增加亮度的一个可行方法是使用更高的ISO或更长时间…
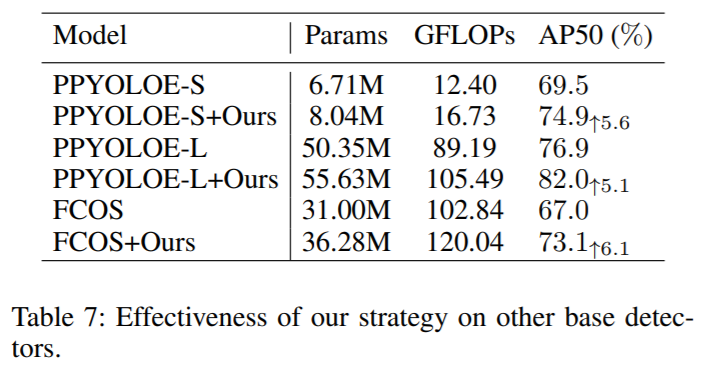
论文阅读:YOLOV: Making Still Image Object Detectors Great at Video Object Detection
发表时间:2023年3月5日 论文地址:https://arxiv.org/abs/2208.09686 项目地址:https://github.com/YuHengsss/YOLOV
视频物体检测(VID)具有挑战性,因为物体外观的高度变化以及一些帧的不同恶化。有利的信息…
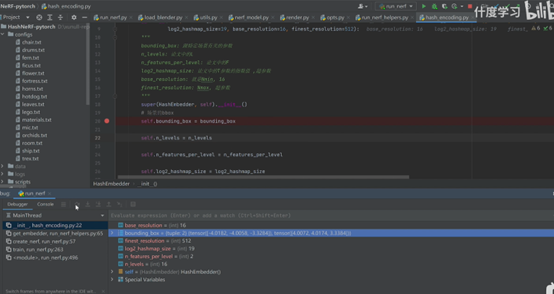
Instant-NGP稿子
Instant-NGP是英伟达2022年发表的一篇论文,全称是使用哈希编码的多分辨率的即时神经图形原语
那这篇文章呢
这篇文章提出了一种对输入做哈希encoding的方式,来让很小的网络也能学到很高的质量。
这个图片是文中的一个图片,表现了可以在训练…

ELFNet: Evidential Local-global Fusion for Stereo Matching
论文地址:https://arxiv.org/pdf/2308.00728.pdf 源码地址:https://github.com/jimmy19991222/ELFNet 概述 针对现有立体匹配模型面临可靠性和跨域泛化的问题,本文提出了Evidential Local-global Fusion(ELF)框架&…

论文阅读 Memory Enhanced Global-Local Aggregation for Video Object Detection
Memory Enhanced Global-Local Aggregation for Video Object Detection
Abstract
人类如何识别视频中的物体?由于单一帧的质量低下,仅仅利用一帧图像内的信息可能很难让人们在这一帧中识别被遮挡的物体。我们认为人们识别视频中的物体有两个重要线索&…
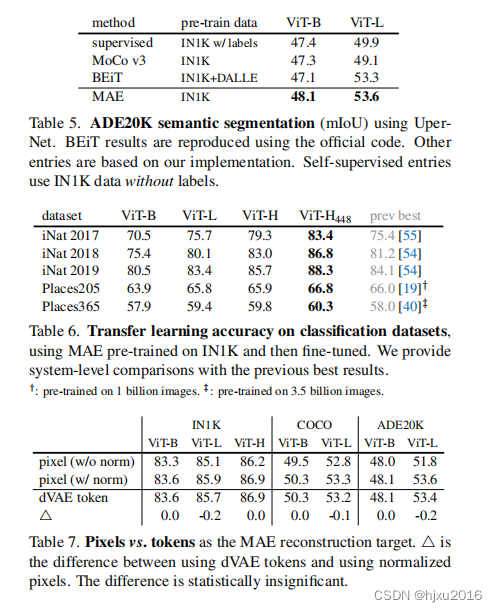
【自监督论文阅读 2】MAE
文章目录 一、摘要二、引言2.1 引言部分2.2 本文架构 三、相关工作3.1 Masked language modeling3.2 Autoencoding3.3 Masked image encoding3.4 Self-supervised learning 四、方法4.1 Masking4.2 MAE encoder4.3 MAE decoder4.4 Reconstruction target 五、主要实验5.1 不同m…
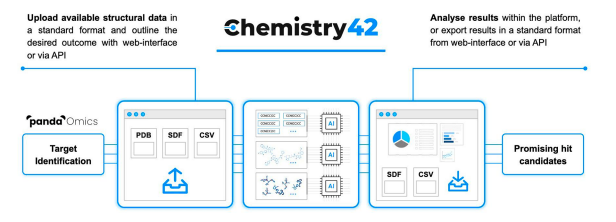
JCIM|Chemistry42:一个人工智能驱动的分子设计和优化平台
题目:Chemistry42: An AI-Driven Platform for Molecular Design and Optimization
文献来源:https://doi.org/10.1021/acs.jcim.2c01191
代码:https://insilico.com/pipeline (平台网址)
1.背景介绍
Chemistry42是Insilico Medicine提出…
科研论文中PPT图片格式选择与转换:EPS、SVG 和 PDF 的比较
当涉及论文中的图片格式时,导师可能要求使用 EPS 格式的图片。EPS(Encapsulated PostScript)是一种矢量图格式,它以 PostScript 语言描述图像,能够无损地缩放并保持图像清晰度。与像素图像格式(如 PNG 和 J…
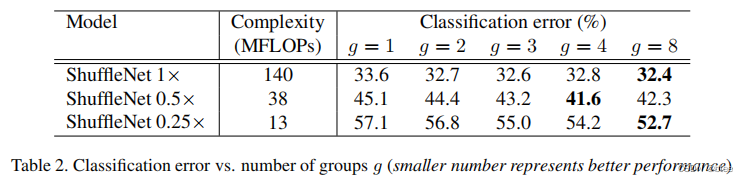
论文阅读 | 轻量级网络 MobileNets/Xception/ShuffleNet
前言:重温经典,整理了一些几年前做轻量级网络的论文,其中的深度可分离卷积和通道shuffle的思想至今也在沿用 (这几天都没看论文然而实验还是没跑出来,不卷会议了,开始摆烂…) 论文地址ÿ…

Attention is all you need 论文阅读
论文链接
Attention is all you need 0. Abstract
主要序列转导模型基于复杂的循环或卷积神经网络,包括编码器和解码器。性能最好的模型还通过注意力机制连接编码器和解码器提出Transformer,它 完全基于注意力机制,完全不需要递归和卷积对两…
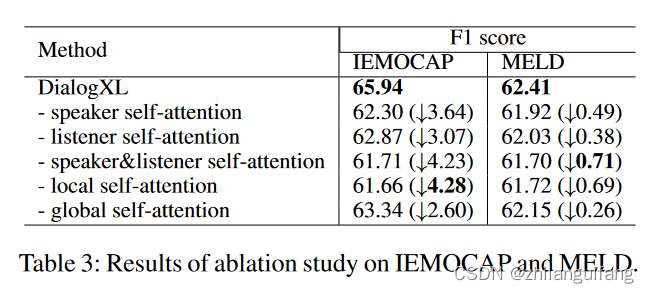
论文阅读笔记(12月15)--DialogXL
论文阅读笔记(12月15)–DialogXL
基本情况介绍:
作者:Weizhou Shen等 单位:中山大学 时间&期刊:AAAI 2021 主题:对话情绪识别(ERC)–文本模态 论文链接:https://ojs.aaai.org/index.php/AAAI/article…
(论文阅读15/100)You Only Look Once: Unified, Real-Time Object Detection
文献阅读笔记 简介 题目 You Only Look Once: Unified, Real-Time Object Detection 作者 Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi 原文链接 https://arxiv.org/pdf/1506.02640.pdf 《You Only Look Once: Unified, Real-Time Object Detection》…
【论文阅读】Untargeted Backdoor Attack Against Object Detection(针对目标检测的无目标后门攻击)
文章目录 一.论文信息二.论文内容0.摘要1.论文概述2.背景介绍3.作者贡献4.重点图表 一.论文信息
论文题目: Untargeted Backdoor Attack Against Object Detection(针对目标检测的无目标后门攻击)
发表年份: 2023-ICASSP&#x…
【Spatial-Temporal Action Localization(三)】论文阅读2018年
文章目录 1. AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions 时空局部原子视觉动作的视频数据集摘要和结论模型框架思考不足之处时间信息对于识别 AVA 类别有多重要?定位与识别相比有何挑战性?哪些类别具有挑战性ÿ…

目标检测论文阅读:GaFPN算法笔记
标题:Construct Effective Geometry Aware Feature Pyramid Network for Multi-Scale Object Detection 会议:AAAI2022 论文地址:https://ojs.aaai.org/index.php/AAAI/article/view/19932 文章目录Abstract1. Introduction2. Related Work2.…

【论文阅读】SHADEWATCHER:使用系统审计记录的推荐引导网络威胁分析(SP-2022)
SHADEWATCHER: Recommendation-guided CyberThreat Analysis using System Audit Records S&P-2022 新加坡国立大学、中国科学技术大学 Zengy J, Wang X, Liu J, et al. Shadewatcher: Recommendation-guided cyber threat analysis using system audit records[C]//2022 I…

Learning Normal Dynamics in Videos with Meta Prototype Network 论文阅读
文章信息:发表在cvpr2021 原文链接: Learning Normal Dynamics in Videos with Meta Prototype Network 摘要1.介绍2.相关工作3.方法3.1. Dynamic Prototype Unit3.2. 视频异常检测的目标函数3.3. 少样本视频异常检测中的元学习 4.实验5.总结代码复现&a…

【自监督论文阅读笔记】Efficient Visual Pretraining with Contrastive Detection
摘要 自监督预训练已被证明可以为迁移学习产生强大的表征。然而,这些性能提升是以巨大的计算成本为代价的,最先进的方法需要比监督预训练多一个数量级的计算量。我们通过引入一个新的自监督目标、对比检测来解决这个计算瓶颈,该目标通过 识别…

DETRs with Collaborative Hybrid Assignments Training论文笔记
Title:[DETRs with Collaborative Hybrid Assignments Training
Code 文章目录 1. Motivation2. one to one VS one to many3. Method(1)Encoder feature learning(2)Decoder attention learning 1. Motivation
当前…

论文阅读_模型结构_LoRA
name_en: LoRA: Low-Rank Adaptation of Large Language Models name_ch: LORA:大语言模型的低阶自适应 paper_addr: http://arxiv.org/abs/2106.09685 date_read: 2023-08-17 date_publish: 2021-10-16 tags: [‘深度学习’,‘大模型’] author: Edward J. Hu cita…
论文阅读--A Tutorial on Stance Detection
论文链接:https://dl.acm.org/doi/pdf/10.1145/3488560.3501391
摘要 立场检测(也称为立场分类、立场预测和立场分析)是与社交媒体分析、自然语言处理和信息检索相关的问题,旨在从一段文本中确定一个人的位置oward a target (a c…
JoyT的科研之旅第一周——科研工具学习及论文阅读收获
CiteSpace概述
CiteSpace 是一个用于可视化和分析科学文献的工具,它专门针对研究者进行文献回顾和趋势分析。CiteSpace 的核心功能是创建文献引用网络,这些网络揭示了研究领域内各个文献之间的相互关系。使用 CiteSpace 可以为论文研究做出贡献的几种方…
论文学习之对比学习【1】-SimCLR:论文阅读与简单demo测试
对比学习SimCLR:论文阅读与简单demo测试 1. 论文摘要解读:1.1 内容翻译1.2 重点提要2. 对比学习的主要思想3. SimCLR的主要结构解析3.1 数据增强3.2 数据编码3.3 深度映射模块3.4 对比损失函数4. 基于Pytorch的简单实现4.1 加载相关包4.2 设置随机参数4.3 Cifar10数据读取4.4…
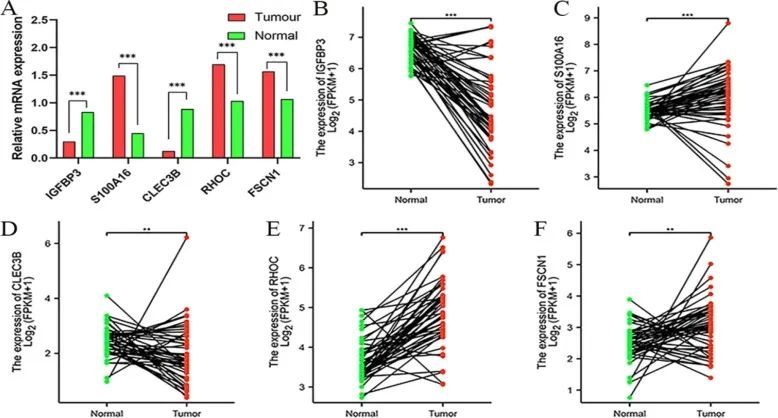
5分+肿瘤预后模型生信分析如何做?单细胞分析+干湿结合
今天给同学们分享一篇单细胞分析干湿结合的生信文章“Tumor-associated endothelial cell prognostic risk model and tumor immune environment modulation in liver cancer based on single-cell and bulk RNA sequencing: Experimental verification”,这篇文章于…
[论文笔记]GPT-2
引言
今天继续GPT系列论文, 这次是Language Models are Unsupervised Multitask Learners,即GPT-2,中文题目的意思是 语言模型是无监督多任务学习器。
自然语言任务,比如问答、机器翻译、阅读理解和摘要,是在任务相关数据集上利用监督学习的典型方法。作者展示了语言模型…

文献查询辅助工具,查看文献影响因子期刊,显示文献排名,翻译文献
插件工具:easyScholar
适配浏览器(Edge、chrome、Firefox),本文以Edge为例: 1.打开Edge浏览器,输入: edge://extensions/ 2.点击获取Microsoft Edge扩展 3.搜索 easyscholar,然后…

【网安大模型专题10.19】论文6:Java漏洞自动修复+数据集 VJBench+大语言模型、APR技术+代码转换方法+LLM和DL-APR模型的挑战与机会
How Effective Are Neural Networks for Fixing Security Vulnerabilities 写在最前面摘要贡献发现 介绍背景:漏洞修复需求和Java漏洞修复方向动机方法贡献 数据集先前的数据集和Java漏洞Benchmark数据集扩展要求数据处理工作最终数据集 VJBenchVJBench 与 Vul4J 的…
【论文阅读】大语言模型中的文化道德规范知识
摘要:
在已有的研究中,我们知道英语语言模型中包含了类人的道德偏见,但从未有研究去检测语言模型对不同国家文化的道德差异。
我们分析了语言模型包含不同国家文化道德规范的程度,主要针对两个方面,其一是看语言模型…

论文笔记(三十):Counter-Hypothetical Particle Filters for Single Object Pose Tracking
Counter-Hypothetical Particle Filters for Single Object Pose Tracking 文章概括摘要1. 简介II. 相关工作A. 机器人的物体姿态估计和跟踪B. 鲁棒性的粒子滤波 III. 背景:粒子滤波A. 粒子滤波B. 粒子剥夺和粒子重振IV. 反假设粒子滤波A. 反假设重取样B. 6D姿势估计…
论文阅读:CenterFormer: Center-based Transformer for 3D Object Detection
目录
概要
Motivation
整体架构流程
技术细节
Multi-scale Center Proposal Network
Multi-scale Center Transformer Decoder
Multi-frame CenterFormer
小结 论文地址:[2209.05588] CenterFormer: Center-based Transformer for 3D Object Detection (arx…
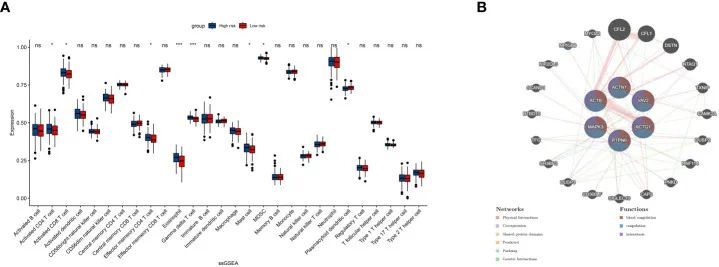
7+非肿瘤+WGCNA+机器学习+诊断模型,构思巧妙且操作简单
今天给同学们分享一篇生信文章“Platelets-related signature based diagnostic model in rheumatoid arthritis using WGCNA and machine learning”,这篇文章发表在Front Immunol期刊上,影响因子为7.3。 结果解读:
DEGs和血小板相关基因的…
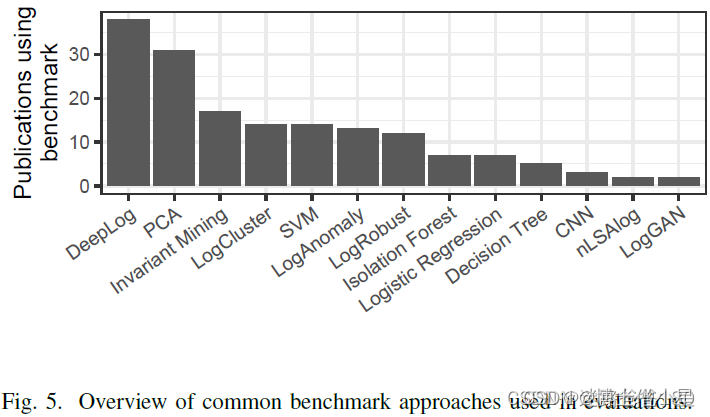
科研学习|论文解读——Deep learning for anomaly detection in log data: a survey
摘要 自动日志文件分析能够及早发现系统故障等相关事件。特别是,自学习异常检测技术能够捕捉日志数据中的模式,然后向系统操作员报告意外的日志发生,而无需提前提供或手动建模异常场景。最近,越来越多的利用深度学习方法来实现此目…

论文阅读: (CVPR2023 SDT )基于书写者风格和字符风格解耦的手写文字生成及源码对应
引言
许久不认真看论文了,这不赶紧捡起来。这也是自己看的第一篇用到Transformer结构的CV论文。之所以选择这篇文章来看,是考虑到之前做过手写字体生成的项目。这个工作可以用来合成一些手写体数据集,用来辅助手写体识别模型的训练。本篇文章…
![[论文笔记] Gunrock: A High-Performance Graph Processing Library on the GPU](https://img-blog.csdnimg.cn/cc068ff5376d44db997dddf945d31cf6.png)
[论文笔记] Gunrock: A High-Performance Graph Processing Library on the GPU
Gunrock: A High-Performance Graph Processing Library on the GPU
Gunrock: GPU 上的高性能图处理库 [Paper] [Code] PPoPP’16
摘要
Gunrock, 针对 GPU 的高层次批量同步图处理系统.
采用了一种新方法抽象 GPU 图分析: 实现了以数据为中心(data-centric)的抽象, 以在结点…

《论文阅读》用于情绪回复生成的情绪正则化条件变分自动编码器 Affective Computing 2021
《论文阅读》用于情绪回复生成的情绪正则化条件变分自动编码器 前言简介模型结构实验结果总结前言
今天为大家带来的是《Emotion-Regularized Conditional Variational Autoencoder for Emotional Response Generation》 出版:IEEE Transactions on Affective Computing
时间…
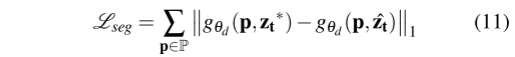
论文阅读:PVO: Panoptic Visual Odometry
全景视觉里程计、同时做全景分割和视觉里程计
连接:PVO: Panoptic Visual Odometry
0.Abstract
我们提出了一种新的全景视觉里程计框架PVO,以实现对场景运动、几何和全景分割信息的更全面的建模。我们将视觉里程计(VO)和视频全景分割(VPS)在一个统一的…
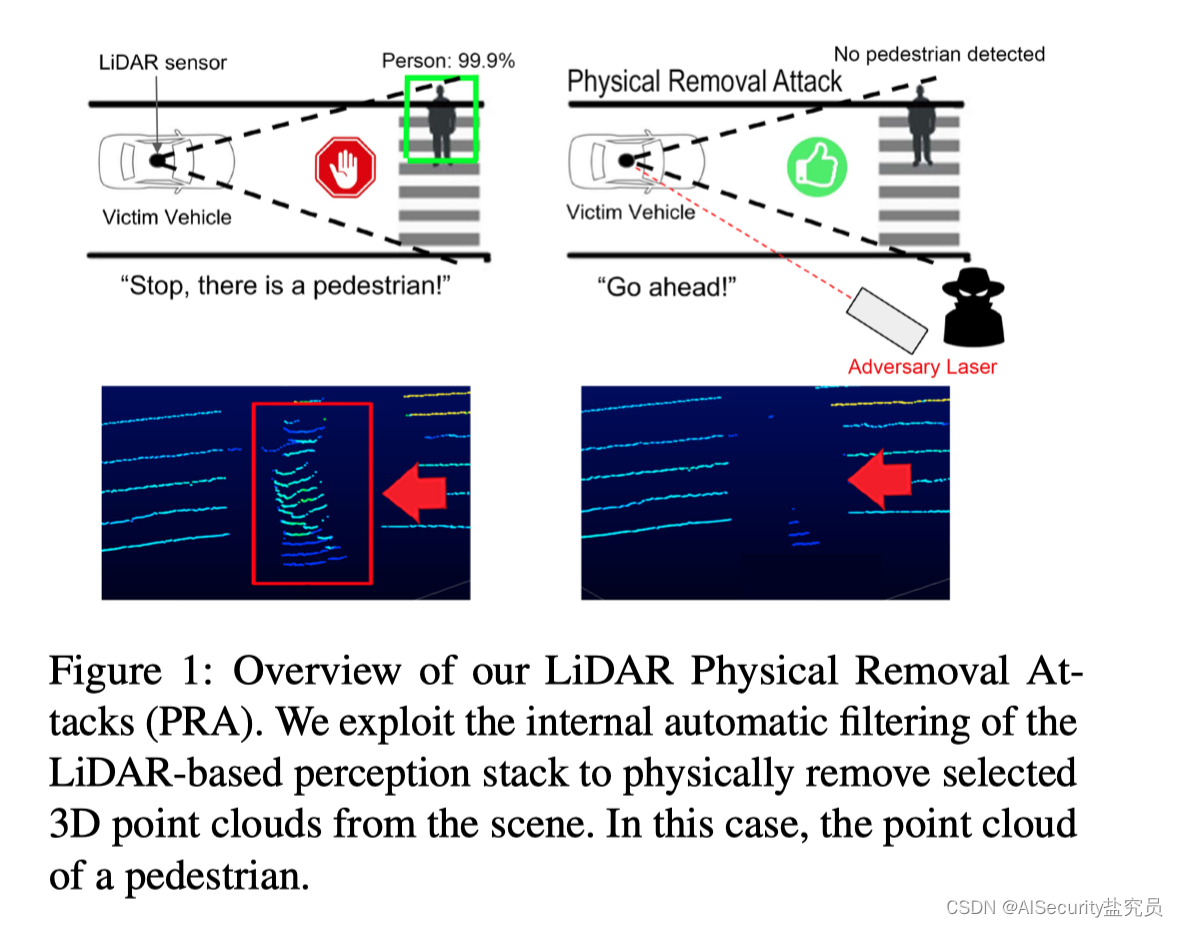
【论文阅读】你看不见我:对基于激光雷达的自动驾驶汽车驾驶框架的物理移除攻击
文章目录 AbstractIntroduction Abstract
自动驾驶汽车(AVs)越来越多地使用基于激光雷达的物体检测系统来感知道路上的其他车辆和行人。目前,针对基于激光雷达的自动驾驶架构的攻击主要集中在降低自动驾驶物体检测模型的置信度,以诱导障碍物误检测&…

目标检测论文阅读:RepPoints v2算法笔记
标题:RepPoints v2: Verification Meets Regression for Object Detection 会议:NeurIPS2020 论文地址:https://dl.acm.org/doi/abs/10.5555/3495724.3496196 官方代码:https://github.com/Scalsol/RepPointsV2 作者单位ÿ…
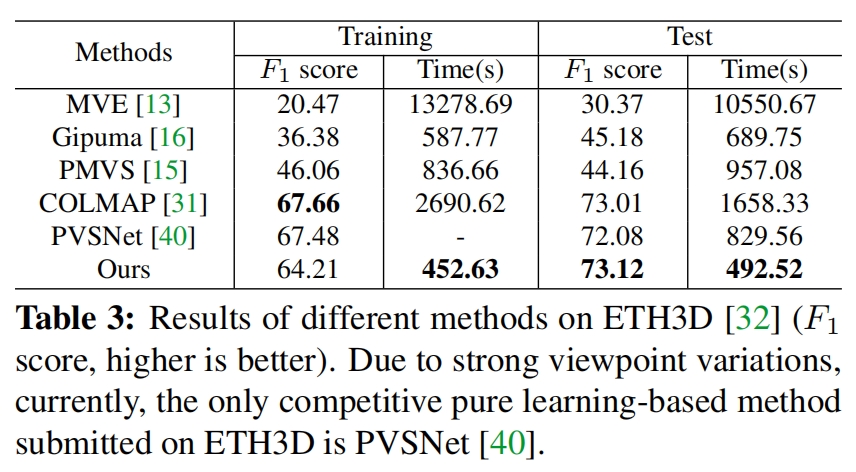
PatchMatchNet笔记
PatchMatchNet笔记 1 概述2 PatchmatchNet网络结构图2.1 多尺度特征提取2.2 基于学习的补丁匹配 3 性能评价 PatchmatchNet: Learned Multi-View Patchmatch Stereo:基于学习的多视角补丁匹配立体算法
1 概述
特点 高速,低内存,可以处理…

论文阅读:Graphics2RAW: Mapping Computer Graphics Images to Sensor RAW Images
论文阅读:Graphics2RAW: Mapping Computer Graphics Images to Sensor RAW Images
这是一篇 ICCV 2023 的文章,主要介绍了一种数据仿真的方式。
Abstract
CG 渲染得到的图像与相机拍摄得到的图像越来越像了,这种摄影级的渲染逼近效果让越来…

【kg推荐->精读】Differentiable Sampling on Knowledge Graph for Recommendation with Relational GNN
DSKReG Differentiable Sampling on Knowledge Graph for Recommendation with Relational GNNAbstract
出现冷启动问题时,将KGs作为side information可以缓解这一问题。
问题:node degrees是倾斜(skewed)的;KGs中大…
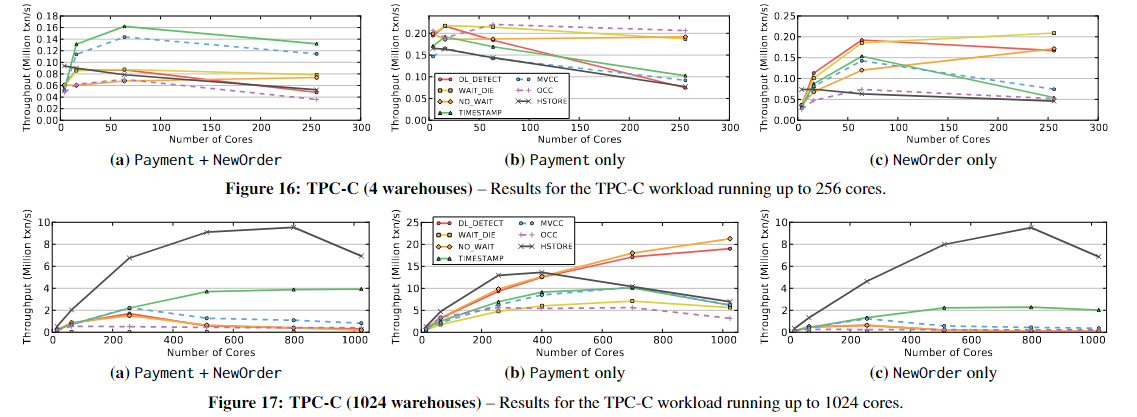
【论文阅读】An Evaluation of Concurrency Control with One Thousand Cores
An Evaluation of Concurrency Control with One Thousand Cores
Staring into the Abyss: An Evaluation of Concurrency Control with One Thousand Cores
ABSTRACT
随着多核处理器的发展,一个芯片可能有几十乃至上百个core。在数百个线程并行运行的情况下&…

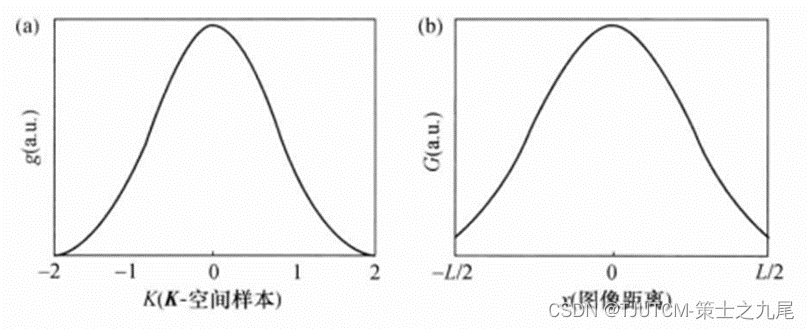
【核磁共振成像】方格化重建
目录 一、缩放比例二、方格化变换的基础三、重建时间四、方格化核 一、缩放比例 对于笛卡尔K空间直线轨迹数据可直接用FFT重建,而如果K空间轨迹的任何部分都是非均匀取样的 可用DFT直接重建,有时称为共轭相位重建,但此法太慢不实用。把数据再…

【论文阅读四】An Efficient Insect Pest Classification Using Multiple Convolutional Neural Network Based Mod
本文记录下今天看的一篇文章《An Efficient Insect Pest Classification Using Multiple Convolutional Neural Network Based Models》,本文是2021年发表在Applied Intelligence的文章,貌似是一篇二区。
文章梗概 本篇文章其实没有引入新的思想或者算法…
【农业害虫论文阅读五】Insect classification and detection in field crops using modern machine learning techniq
本文记录下论文《Insect classification and detection in field crops using modern machine learning techniques》本文发表于2021年。
文章梗概 本文基于两个比较小的农业害虫数据集,使用几种经典的机器学习方法进行害虫分类,主要涉及到方法有&#…

【害虫识别论文阅读六】Image Classification of Pests with Residual Neural Network Based on Transfer Learning
本文记录下刚阅读的农业害虫识别论文《Image Classification of Pests with Residual Neural Network Based on Transfer Learning》,本文章发表于2022年。
文章梗概 文章没有提出新的模块,简单来讲,使用了27组实验组成了整篇文章࿰…

炎症回路和肠道微生物
✦ ✦ ✦ 炎症:就是平时人们所说的“发炎”,是机体对于刺激的一种防御反应。炎症,可以是感染引起的感染性炎症,也可以不是由于感染引起的非感染性炎症。 炎症在在各种症状中起重要作用,如脑雾、焦虑和抑郁、腹胀、各种…
[论文笔记]GPT1
引言
今天带来论文Improving Language Understanding by Generative Pre-Training的笔记,它的中文题目为:通过生成式预训练改进语言理解。其实就是GPT的论文。
自然语言理解可以应用于大量NLP任务上,比如文本蕴含、问答、语义相似和文档分类。虽然无标签文本语料是丰富的,…

CoT进阶:Self Consistency, Least-to-most
CoT进阶 一:Self Consistency1.1 方法简介1.2 实验1.3 结果 二:Least-to-most2.1 方法简介2.2 示例2.3 结果 一:Self Consistency
题目: SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS 机构:Google …
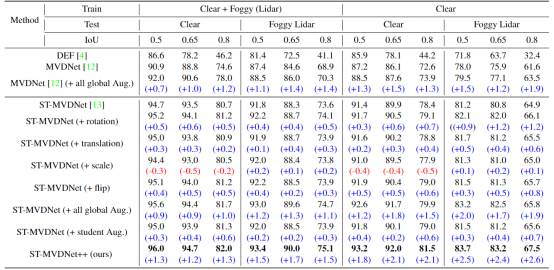
【ICASSP 2023】ST-MVDNET++论文阅读分析与总结
主要是数据增强的提点方式。并不能带来idea启发,但对模型性能有帮助
Challenge:
少有作品应用一些全局数据增强,利用ST-MVDNet自训练的师生框架,集成了更常见的数据增强,如全局旋转、平移、缩放和翻转。
Contributi…
【目标检测论文阅读笔记】Multi-scene small object detection with modified YOLOv4
Abstract. 小目标检测的应用存在于我们日常生活中的许多不同场景中,该课题也是目标检测与识别研究中最难的问题之一。因此,提高小目标检测精度不仅在理论上具有重要意义,在实践中也具有重要意义。然而,当前的检测相关算法在这项任…

【论文阅读】Directional Connectivity-based Segmentation of Medical Images
目录 摘要介绍方法效果结论 论文:Directional Connectivity-based Segmentation of Medical Images 代码:https://github.com/zyun-y/dconnnet
摘要
出发点:生物标志分割中的解剖学一致性对许多医学图像分析任务至关重要。 之前工作的问题&…
![[论文笔记]GTE](https://img-blog.csdnimg.cn/img_convert/edb6a3de10038c00dadaaf3b0ab008f0.png)
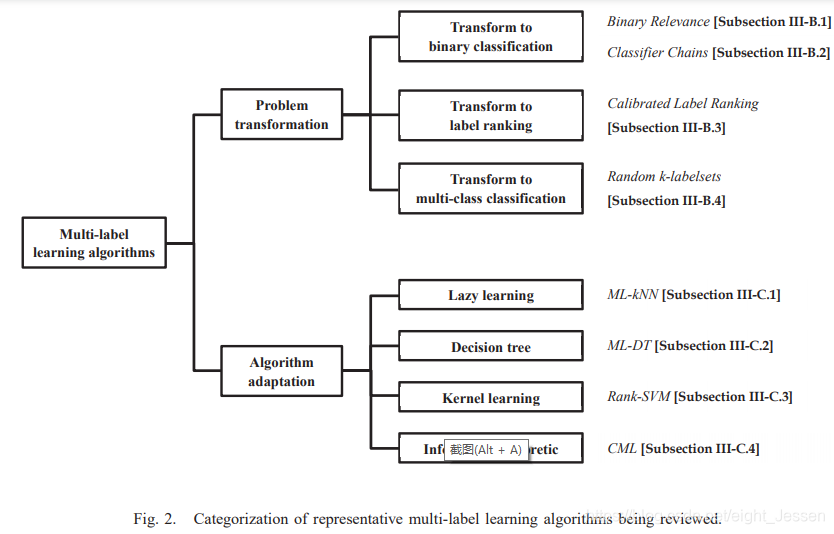
论文笔记:A review on multi-label learning
一、介绍
传统的监督学习是单标签学习,但是现实中一个实例可能对应多个标签。这篇文章介绍了多标签分类的定义和评价指标、多标签学习的算法还有其他相关的任务。
二、问题相关定义
2.1 多标签学习任务
假设 X R d X R^d XRd,表示d维的输入空间&am…
遥感图像之多模态检索AMFMN(支持关键词、句子对图像的检索)论文阅读、环境搭建、模型测试、模型训练
一、论文阅读
1、摘要背景
遥感跨模态文本图像检索以其灵活的输入和高效的查询等优点受到了广泛的关注。然而,传统的方法忽略了遥感图像多尺度和目标冗余的特点,导致检索精度下降。为了解决遥感多模态检索任务中的多尺度稀缺性和目标冗余问题ÿ…
[论文笔记]Batch Normalization
引言
本文是论文神作Batch Normalization的阅读笔记,这篇论文引用量现在快50K了。
由于上一层参数的变化,导致每层输入的分布会在训练期间发生变化,让训练深层神经网络很复杂。这会拖慢训练速度,因为需要更低的学习率并小心地进行参数初始化,使得很难训练这种具有非线性…

《代码整洁之道之程序员的职业素养》-专业主义
专业主义有很深的含义,它不但象征着荣誉和骄傲,而且明确意味着责任和义务担当责任,“为了按时交付软件,没测例行程序,测试例行程序需要几个小时,当时必须交付软件,因为故障修复部分都不涉及例行…
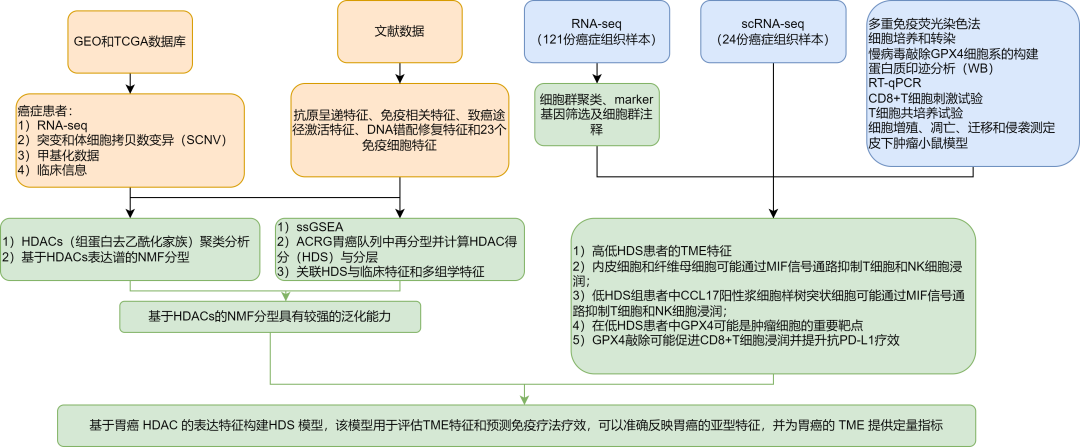
医学专题(6)--多组学在肿瘤分型研究中的应用思路
研究背景
肿瘤免疫分型的由来:每一种肿瘤,甚至每一位患者的肿瘤浸润免疫细胞都存在差异,研究者根据免疫细胞浸润的特点将肿瘤大致分为“冷”肿瘤和“热”肿瘤,此概念的提出是肿瘤免疫分型的雏形。
对肿瘤免疫分型的研究有很多&a…
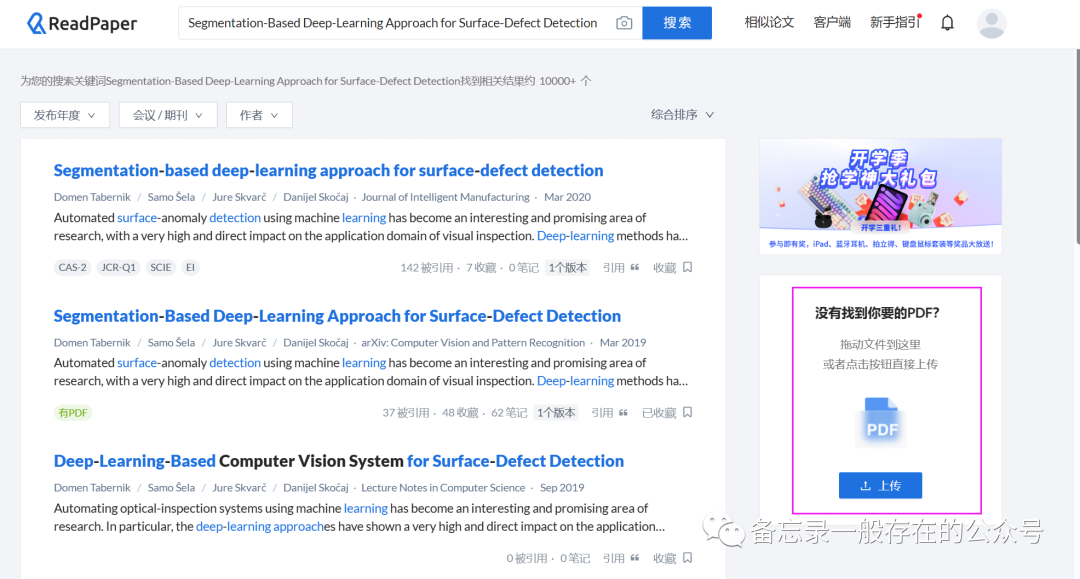
ReadPaper论文阅读工具
之前看文献一直用的EndNote嘛,但是突然发现了它的一个弊端,就是说每次没看完退出去之后,下次再接着看的时候它不能保留我上一次的位置信息,又要重头开始翻阅,这让我感到很烦躁哈哈。(当然也不知道是不是我哪…
揭秘论文开题报告写作技巧,全程无忧,附赠技术路线图模板!
最近不少学校开始让准毕业生撰写论文开题报告,如果是第一次接触学术论文的朋友,多少会卡在概念的理解上,就像题主说到的,开题报告中包含的各个部分,如研究目的、研究目标、研究内容等,容易让人眼花缭乱。
…
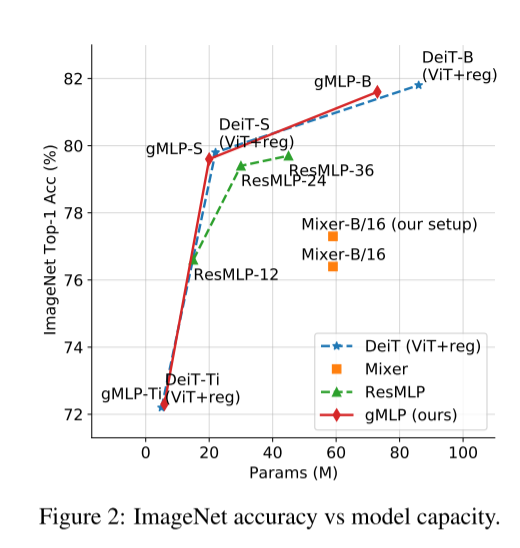
【论文阅读】Pay Attention to MLPs
作者:Google Research, Brain Team
泛读:只关注其中cv的论述
提出了一个简单的网络架构,gMLP,基于门控的MLPs,并表明它可以像Transformers一样在关键语言和视觉应用中发挥作用 提出了一个基于MLP的没有self-attentio…
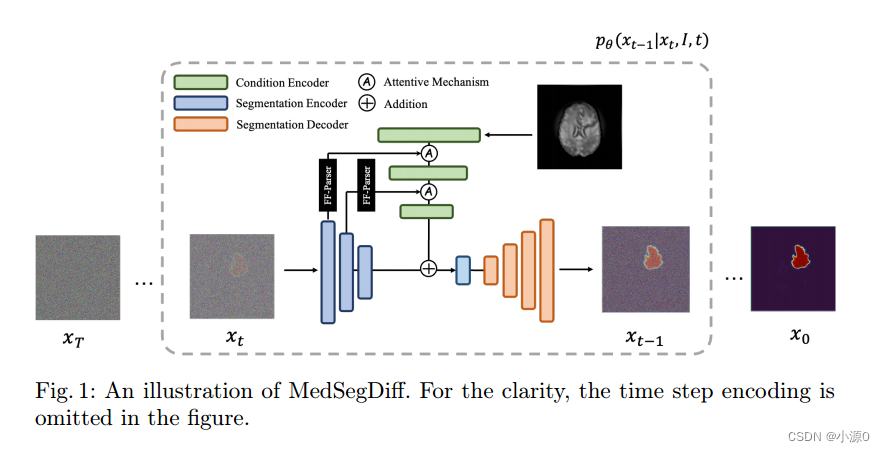
论文阅读:MedSegDiff: Medical Image Segmentation with Diffusion Probabilistic Model
论文标题: MedSegDiff: Medical Image Segmentation with Diffusion Probabilistic Model 翻译: MedSegDiff:基于扩散概率模型的医学图像分割
名词解释: 高频分量(高频信号)对应着图像变化剧烈的部分&…

【科研新手指南2】「NLP+网安」相关顶级会议期刊 投稿注意事项+会议等级+DDL+提交格式
「NLP网安」相关顶级会议&期刊投稿注意事项 写在最前面一、会议ACL (The Annual Meeting of the Association for Computational Linguistics)IH&MMSec (The ACM Workshop on Information Hiding, Multimedia and Security)CCS (The ACM Conference on Computer and Co…
5+非肿瘤+细胞凋亡相关生信思路,请自行查阅
今天给同学们分享一篇生信文章“Genome-wide identification and functional analysis of dysregulated alternative splicing profiles in sepsis”,这篇文章发表在J Inflamm (Lond)期刊上,影响因子为5.1。 结果解读:
脓毒症患者和健康对照…

论文阅读:“iOrthoPredictor: Model-guided Deep Prediction of Teeth Alignment“
文章目录 IntroductionMethodologyProblem FormulationConditional Geometry GenerationTSynNetAligned Teeth Silhouette Maps Generation ResultsReferences Github 项目地址:https://github.com/Lingchen-chen/iOrthopredictor Introduction
这篇文章提出了一种…

多模态论文阅读之BLIP
BLIP泛读 TitleMotivationContributionModel Title
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Motivation
模型角度:clip albef等要么采用encoder-base model 要么采用encoder-decoder model.…
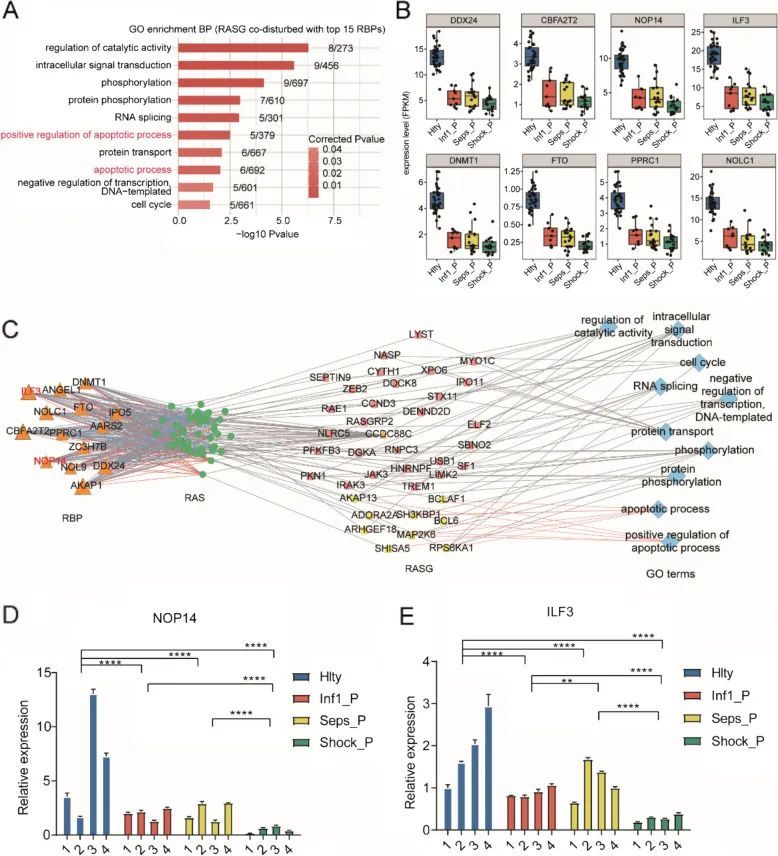
多标签分类论文笔记 | ML-Decoder: Scalable and Versatile Classification Head
个人论文精读笔记,主要是翻译心得,欢迎旁观,如果有兴趣可以在评论区留言,我们一起探讨。 Paper: https://arxiv.org/pdf/2111.12933.pdf Code: https://github.com/Alibaba-MIIL/ML_Decoder 文章目录 0. 摘要1. 介绍2. 方法2.1 Ba…
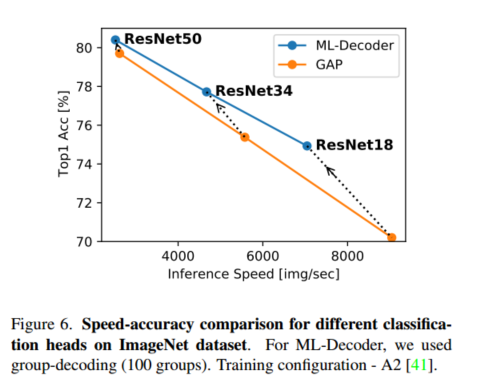
CORE: Cooperative Reconstruction for Multi-Agent Perception 论文阅读
论文连接
CORE: Cooperative Reconstruction for Multi-Agent Perception 0. 摘要
本文提出了 CORE,一种概念简单、有效且通信高效的多智能体协作感知模型。 从合作重建的新颖角度解决了该任务: 合作主体共同提供对环境的更全面的观察整体观察可以作为…

Text-to-3D 任务论文笔记: Latent NeRF
文章目录 概述相关工作3D形状合成使用2D监督的text-to-3D 任务 方法前置知识LDMScore Distillation Latent NeRF文本引导RGB refinementSketch-Shape Guidance对于显式形状的Latent-Paint 实验实验细节文本引导的生成RGB RefinementTextual-Inversion Sketch-Shape GuidanceLat…
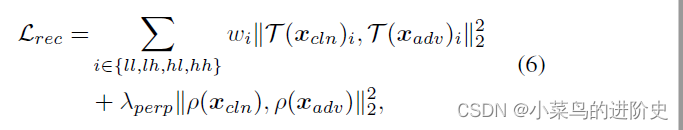
论文阅读——Imperceptible Adversarial Attack via Invertible Neural Networks
Imperceptible Adversarial Attack via Invertible Neural Networks
作者:Zihan Chen, Ziyue Wang, Junjie Huang*, Wentao Zhao, Xiao Liu, Dejian Guan
解决的问题:虽然视觉不可感知性是对抗性示例的理想特性,但传统的对抗性攻击仍然会产…
![[论文笔记]RetroMAE](https://img-blog.csdnimg.cn/img_convert/7e97dd435dd42fbbbb647c5f8d92549e.png)
[论文笔记]RetroMAE
引言
RetroMAE,中文题目为 通过掩码自编码器预训练面向检索的语言模型。
尽管现在已经在许多重要的自然语言处理任务上进行了预训练,但对于密集检索来说,仍然需要探索有效的预训练策略。
本篇工作,作者提出RetroMAE,一个新的基于掩码自编码器(Masked Auto-Encoder,MAE)…
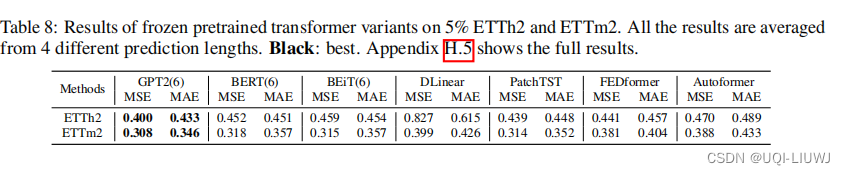
论文笔记: One Fits All:Power General Time Series Analysis by Pretrained LM
1 intro
时间序列领域预训练模型/foundation 模型的研究还不是很多 主要挑战是缺乏大量的数据来训练用于时间序列分析的基础模型——>论文利用预训练的语言模型进行通用的时间序列分析 为各种时间序列任务提供了一个统一的框架 论文还调查了为什么从语言领域预训练的Transf…

【论文阅读】检索增强发展历程及相关文章总结
文章目录 前言Knn-LMInsightMethodResultsDomain AdaptionTuning Nearest Neighbor Search Analysis REALMInsightsMethodKnowledge RetrieverKnowledge-Augmented Encoder ExpResultAblation StudyCase Study DPRInsightMethodExperimentsResults RAGInsightRAG-Sequence Mode…

通过高通量测序评估金针菇(双孢蘑菇)生产过程中的微生物演替
1.1 Title:Microbial succession during button mushroom (Agaricus bisporus) production evaluated via high-throughput sequencing
1.2 作者:Ban Ga-Hee
1.3 机构:Ewha Womans University
1.4 期刊:Food Microbiology
1.5 分区/影响因…

【论文阅读】ActiveNeRF:通过不确定性估计候选新视图
【论文阅读】ActiveNeRF: Learning where to See with Uncertainty Estimation Abstract1 Introduction3 Background4 NeRF with Uncertainty Estimation5 ActiveNeRF5.1 Prior and Posterior Distribution5.2 Acquisition Function5.3 Optimization and Inference 6 Experimen…
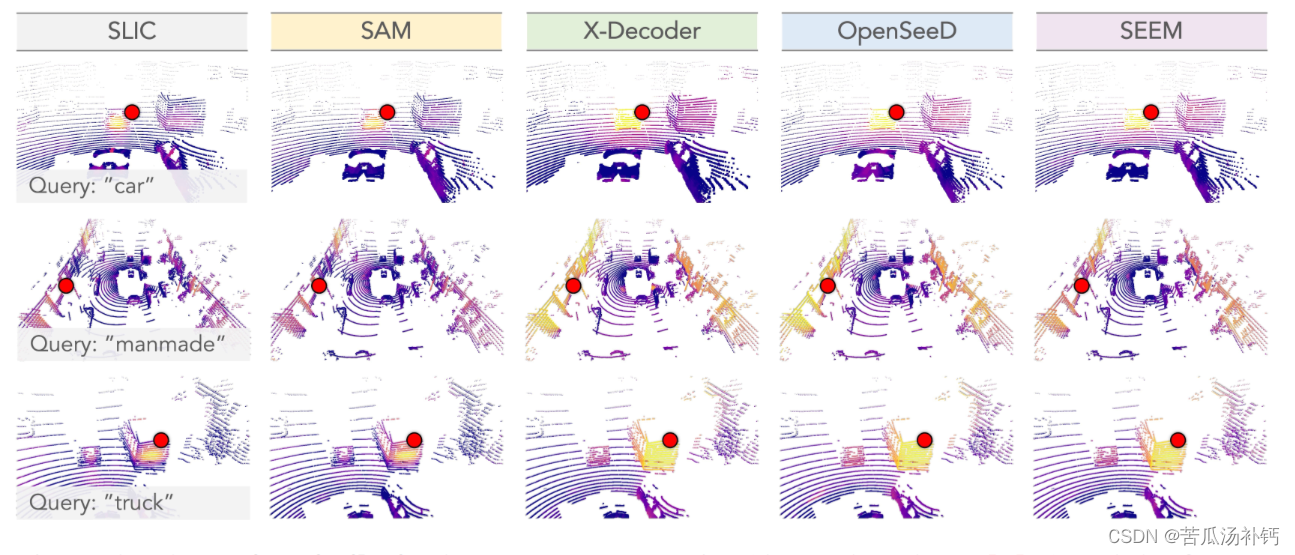
论文阅读:Segment Any Point Cloud Sequences by Distilling Vision Foundation Models
目录
概要
Motivation
整体架构流程
技术细节
小结 论文地址:[2306.09347] Segment Any Point Cloud Sequences by Distilling Vision Foundation Models (arxiv.org)
代码地址:GitHub - youquanl/Segment-Any-Point-Cloud: [NeurIPS23 Spotlight]…
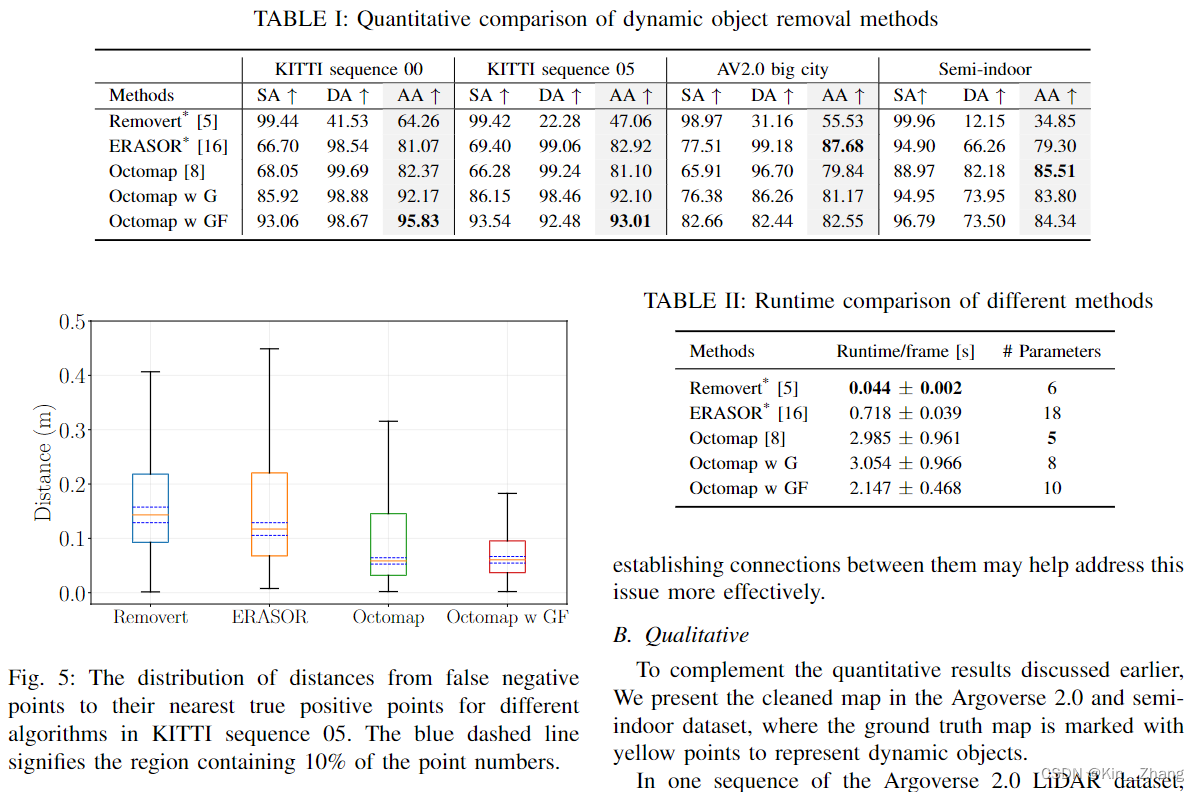
【论文阅读】点云地图动态障碍物去除基准 A Dynamic Points Removal Benchmark in Point Cloud Maps
【论文阅读】点云地图动态障碍物去除基准 A Dynamic Points Removal Benchmark in Point Cloud Maps
终于一次轮到了讲自己的paper了 hahaha,写个中文的解读放在博客方便大家讨论
Title Picture Reference and prenotes paper: https://arxiv.org/abs/2307.07260 …

【每日论文阅读】单目深度估计 近期进展
红外场景单目深度估计的难点
缺乏准确的深度参考标准:红外场景下的深度估计通常需要依赖于大量的输入图像和对应的深度值作为训练的约束。然而,获取准确的深度参考标准是一个挑战,目前常用的方法是使用红外传感器(如Kinect&#…

论文阅读-基于低秩分解的网络异常检测综述
论文地址:基于低秩分解的网络异常检测综述
摘要: 异常检测对于网络管理与安全至关重要.国内外大量研究提出了一系列网络异常检测方法,其 中大多数方法更关注数据包及其独立时序数据流的分析、检测与告警,这类方法仅仅利用了网络数据之 间的…

论文阅读 - End-to-End Wireframe Parsing
文章目录1 概述2 L-CNN2.1 整体架构2.2 backbone2.3 juction proposal module2.4 line sample module2.5 line verificatoin module3 评价指标参考资料1 概述
本文是ICCV2019的一篇论文,核心是提出了一种简单的end-to-end的two-stage的检测图像中线段的方法。同时&…
![[论文阅读]Sparse Fuse Dense](https://img-blog.csdnimg.cn/direct/f4596652f1c84c1db5da3371d2907d9a.png)
[论文阅读]Sparse Fuse Dense
SFD
Sparse Fuse Dense: Towards High Quality 3D Detection with Depth Completion 论文网址:SFD 论文代码:SFD
论文简读
本文主要关注如何利用深度完成技术提高三维目标检测的质量。论文提出了一种名为 SFD(Sparse Fuse Dense࿰…

OpenAI Whisper论文笔记
OpenAI Whisper论文笔记
OpenAI 收集了 68 万小时的有标签的语音数据,通过多任务、多语言的方式训练了一个 seq2seq (语音到文本)的 Transformer 模型,自动语音识别(ASR)能力达到商用水准。本文为李沐老师…
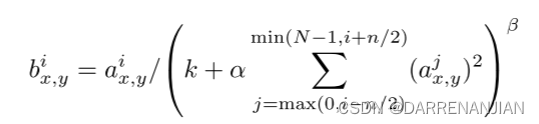
AlexNet论文阅读
开始之前的简介:这篇论文是王林蓉师姐推荐给我看的第一篇入门级别的cv领域的论文,也算是我入手研究生阶段的第一篇论文。我是打算先看看这一领域的论文,然后写自己的一点理解,若有错误欢迎指正。
一. 专有词汇 非饱和神经元 drop…
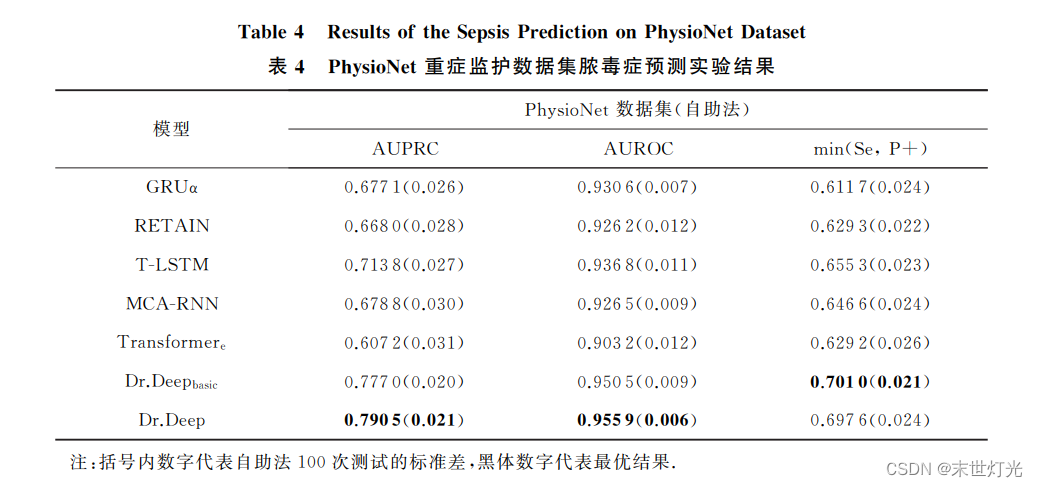
论文阅读-Dr.Deep_基于医疗特征上下文学习的患者健康状态可解释评估
论文地址:Dr.Deep:基于医疗特征上下文学习的患者健康状态可解释评估 (ict.ac.cn) 代码地址:GitHub - Accountable-Machine-Intelligence/Dr.Deep 简介:
深度学习是当前医疗多变量时序数据分析的主流方法。临床辅助决策关乎病人生…

论文阅读:Seeing in Extra Darkness Using a Deep-Red Flash
论文阅读:Seeing in Extra Darkness Using a Deep-Red Flash
今天介绍的这篇文章是 2021 年 ICCV 的一篇 oral 文章,主要是为了解决极暗光下的成像问题,通过一个深红的闪光灯补光。实现了暗光下很好的成像效果,整篇文章基本没有任…

【论文阅读】- 我对“AlexNet”的理解
🤖🤖🤖🤖 欢迎浏览本博客 🤖🤖🤖🤖 😆😆😆😆😆😆😆大家好,我是:我菜就爱学…

KOSMOS-2.5:密集文本的多模态读写模型
Overview 总览摘要1 引言2 KOSMOS-2.52.1 模型结构2.1 图像和文本表征2.3 预训练数据2.4 数据处理2.5 过滤与质量控制 3 实验3.1 评估3.2 实现细节3.3 结果3.4 讨论 4 相关工作4.1 多模态大语言模型4.2 图文理解 5 总结与展望 总览
题目: KOSMOS-2.5: A Multimodal Literate M…
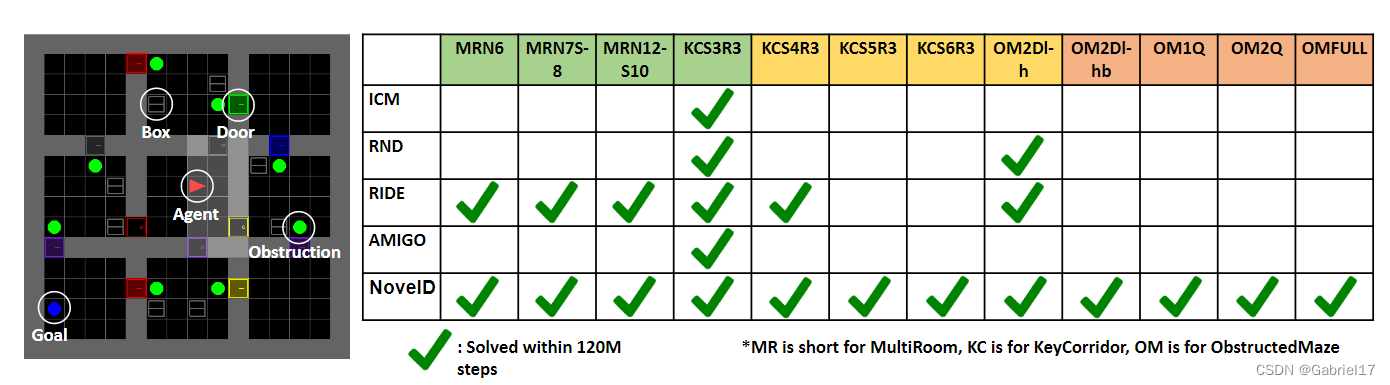
NovelD: A Simple yet Effective Exploration Criterion论文笔记
NovelD:一种简单而有效的探索准则
1、Motivation
针对稀疏奖励环境下的智能体探索问题,许多工作中采用各种内在奖励(Intrinsic Reward)设计来指导困难探索环境中的探索 ,例如:
ICM:基于前向动力学模型的好奇心驱动探索RND&…
(论文阅读11/100)Fast R-CNN
文献阅读笔记 简介 题目 Fast R-CNN 作者 Ross Girshick 原文链接 https://arxiv.org/pdf/1504.08083.pdf 目标检测系列——开山之作RCNN原理详解-CSDN博客 Fast R-CNN讲解_fast rcnn-CSDN博客 Rcnn、FastRcnn、FasterRcnn理论合集_rcnn fastrcnn fasterrcnn_沫念的博客…

论文笔记 Graph Attention Networks
2018 ICLR
1 intro
1.1. GCN的不足
无法完成inductive任务 inductive任务是指: 训练阶段与测试阶段需要处理的graph不同。通常是训练阶段只是在子图上进行,测试阶段需要处理未知的顶点。GGN 的参数依赖于邻接矩阵A/拉普拉斯矩阵L,所以换了…
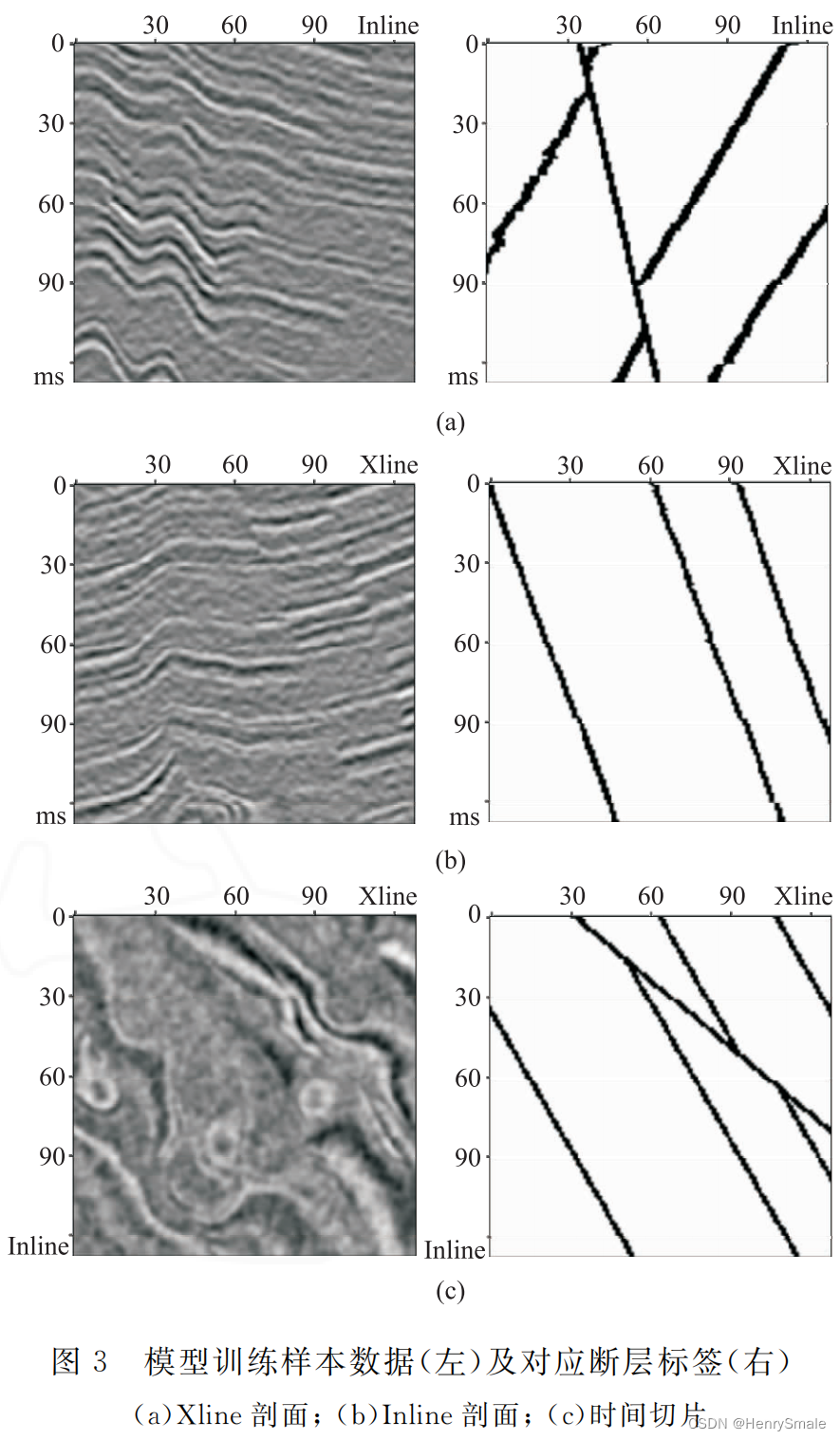
论文笔记:基于U-Net深度学习网络的地震数据断层检测
0 论文简介
论文:基于U-Net深度学习网络的地震数据断层检测 发表:2021年发表在石油地球物理勘探
1 问题分析和主要解决思路
问题:断层智能识别,就是如何利用人工智能技术识别出断层。
解决思路:结合U-N…
论文阅读-多目标强化学习-envelope MOQ-learning
introduction
一种多目标强化学习算法,来自2019 Nips《A Generalized Algorithm for Multi-Objective Reinforcement Learning and Policy Adaptation》
总体思想
待补充
算法
损失函数
虽然论文中用的是Q-learning的架构,但是在提供的代码中&…

多模态之论文笔记BEiT, BEiT V2, BEiT V3
文章目录 OverviewBEiT1.0. Summary1.1. BEiT VS BERT2.1. Two Views: visual tokens2.1. Two Views: image patches3. Results BEiT V21.0. Summary1.1. Motivation2.1. Methods -- VQ-KD2.2. Methods -- patch aggregation3.1. Results -- image classification & semant…
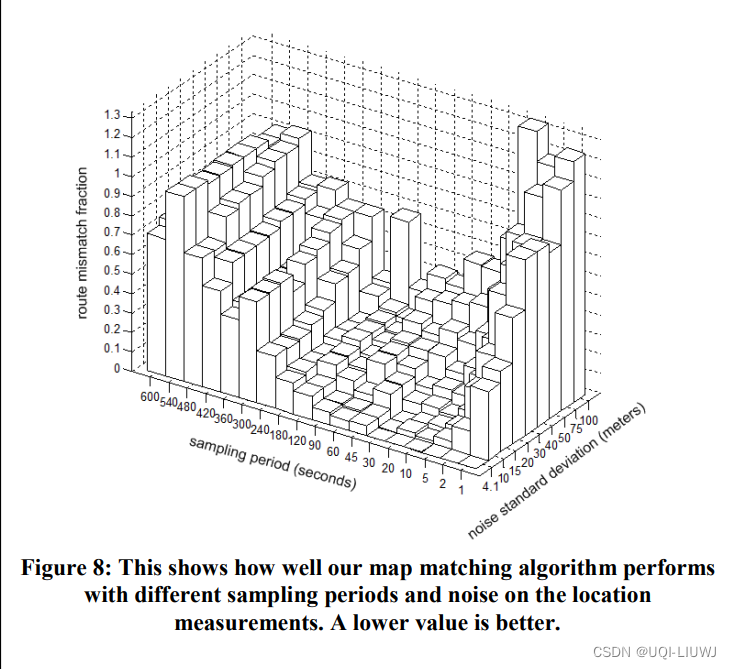
论文笔记:Hidden Markov Map MatchingThrough Noise and Sparseness
sigspatial 2009
1 方法介绍
1.0great circle和route距离 1.1 和ST-matching的比较
1.1.1 转移概率和观测概率
和同一年的ST-matching很类似,也是使用HMM来进行路网匹配论文笔记:Map-Matching for low-sampling-rate GPS trajectories(ST…
【论文阅读】LORA: LOW-RANK ADAPTATION OF LARGE LAN- GUAGE MODELS
3.最近很多工作好像都绕不开lora,无论是sd还是llm.... 1. 背景
问题:大模型重新训练所有模型参数的完全微调变得不太可行。lora在做什么
我们提出了低秩自适应,即LoRA,它冻结预先训练的模型权重,并将可训练的秩分解矩…
[论文笔记]P-tuning
引言
今天带来第四篇大模型微调的论文笔记GPT Understands, Too。
本篇工作提出的方法是P-tuning,使用可训练的连续提示嵌入,使GPT在NLU上表现比传统的全量微调的GPT更好的效果。P-tuning还提高了BERT在少样本和监督设定下的性能,大幅减少了提示工程的需求。
总体介绍
根…

《论文阅读27》SuperGlue: Learning Feature Matching with Graph Neural Networks
一、论文
研究领域: 图像特征点匹配论文:SuperGlue: Learning Feature Matching with Graph Neural NetworksCVPR 2020veido论文code 二、论文简述
[参考] [参考] [参考] 三、论文详述
SuperGlue:使用图神经网络学习特征匹配
本文介绍了…
多模态论文学习之ALBEF(Align BEfore Fusing)
ALBEF泛读 TitleLinksMotivationHow to solve it?(Contribution)ModelExperimentsPre-training DatasetsDownstream tasksAblation ExperimentTitle
《Align before Fuse: Vision and Language Representation Learning with Momentum Distillation》
Links
Paper地址
M…
基于可变形卷积和注意力机制的带钢表面缺陷快速检测网络DCAM-Net(论文阅读笔记)
原论文链接->DCAM-Net: A Rapid Detection Network for Strip Steel Surface Defects Based on Deformable Convolution and Attention Mechanism | IEEE Journals & Magazine | IEEE Xplore DCAM-Net: A Rapid Detection Network for Strip Steel Surface Defects Base…
论文阅读《Generalizing Face Forgery Detection with High-frequency Features》
高频噪声分析会过滤掉图像的颜色内容信息。
本文设计了三个模块来充分利用高频特征,
1.多尺度高频特征提取模块
2.双跨模态注意模块
3.残差引导空间注意模块(也在一定程度上体现了两个模态的交互)
SRM是用于过滤图像的高频噪声
输入的图…
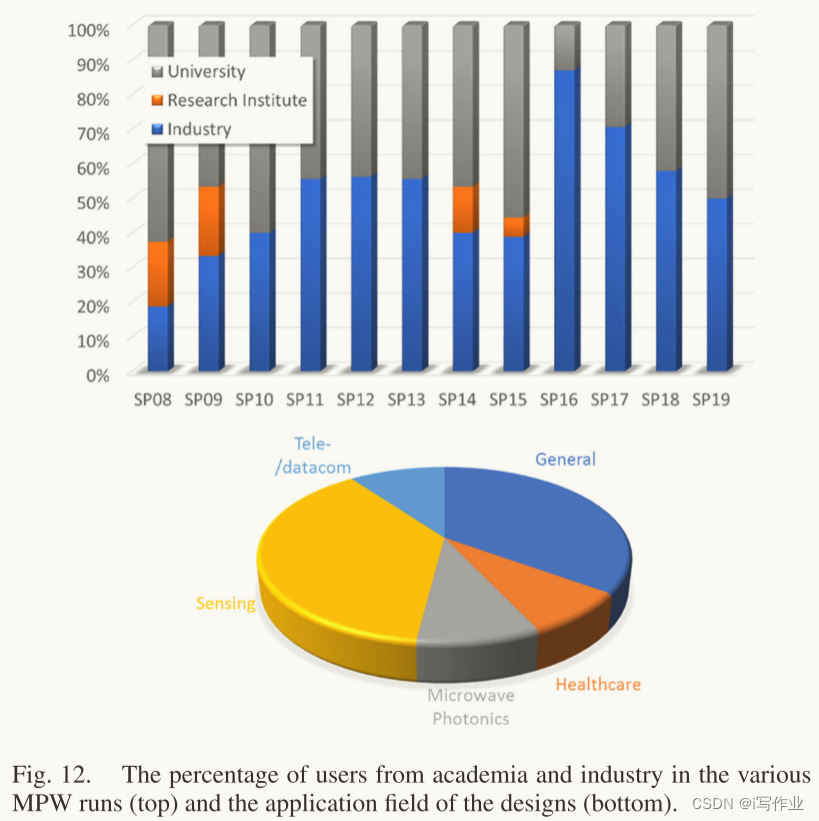
论文阅读_InP-Based_Generic_Foundry_Platform_for_Photonic_Integrated_Circuits
InP-Based_Generic_Foundry_Platform_for_Photonic_Integrated_Circuits
时间:2018年
作者:Luc M. Augustin, Member, IEEE, Rui Santos, Erik den Haan, Steven Kleijn, Peter J. A. Thijs, Sylwester Latkowski, Senior Member, IEEE, Dan Zhao, Wei…

论文阅读:Point-to-Voxel Knowledge Distillation for LiDAR Semantic Segmentation
来源:CVPR 2022
链接:https://arxiv.org/pdf/2206.02099.pdf
0、Abstract 本文解决了将知识从大型教师模型提取到小型学生网络以进行 LiDAR 语义分割的问题。由于点云的固有挑战,即稀疏性、随机性和密度变化,直接采用以前的蒸馏…
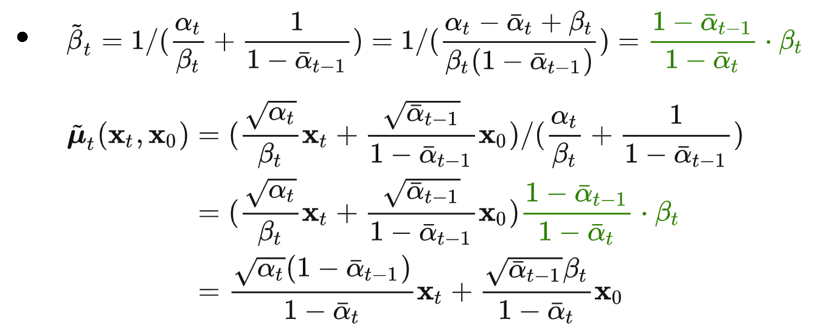
DDPM: Denoising Diffusion Probabilistic Models
DDPM: Denoising Diffusion Probabilistic Models 去噪扩散模型前向过程-加噪声反向过程-去噪声 去噪扩散模型 论文题目:Denoising Diffusion Probabilistic Models (DDPM) 论文来源:NIPS, 2020 论文地址:https://arxiv.org/abs/2006.11239 论…
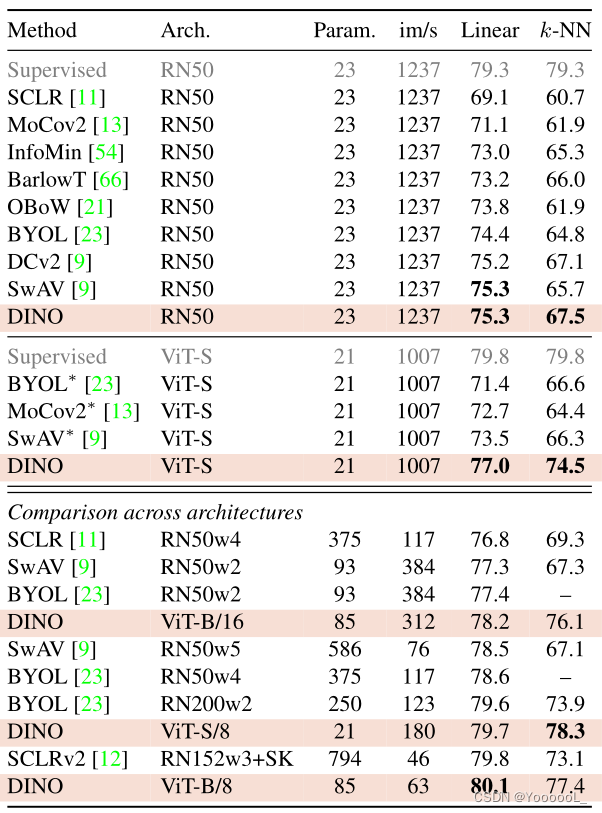
【自监督论文阅读笔记】Emerging Properties in Self-Supervised Vision Transformers
(2021)
Abstract 在本文中,我们质疑 自监督学习是否为 Vision Transformer (ViT) [16] 提供了与卷积网络 (convnets) 相比突出的新属性。除了 使自监督方法适应这种架构的效果 特别好之外,我们还进行了以下观察:首先&…
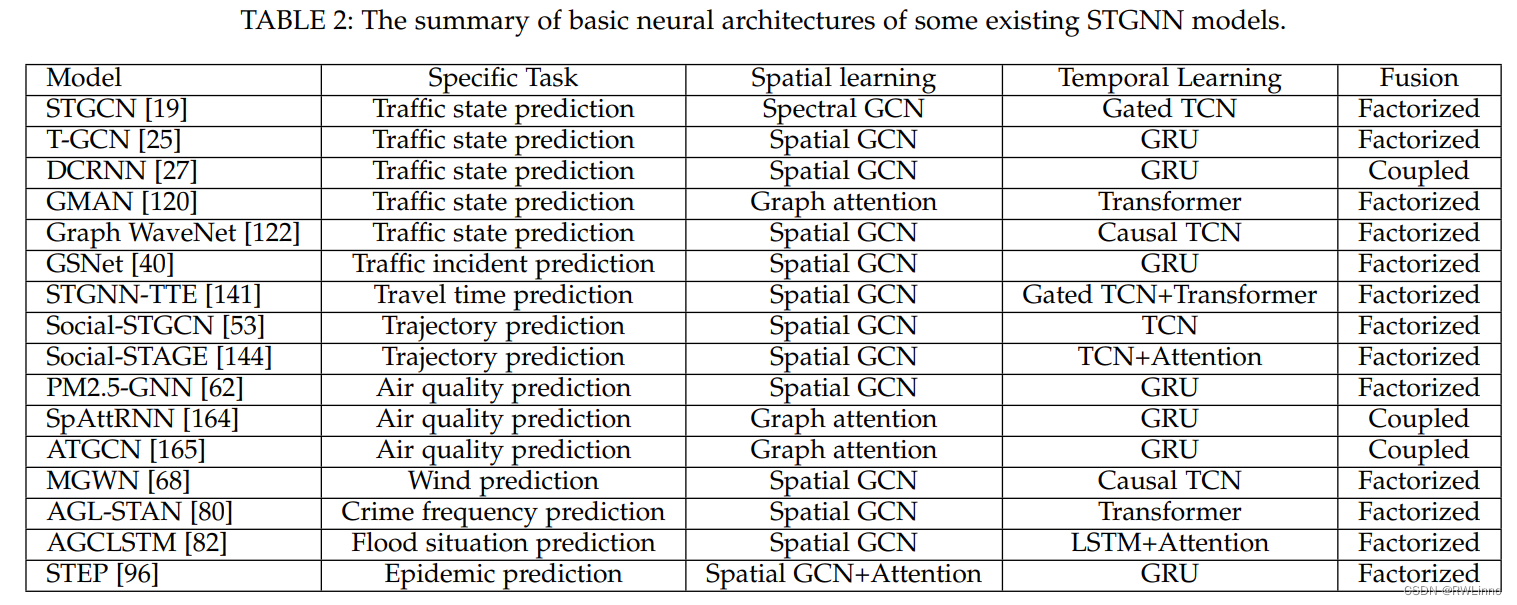
【论文笔记】最近看的时空数据挖掘综述整理8.27
Deep Learning for Spatio-Temporal Data Mining: A Survey
被引用次数:392
[Submitted on 11 Jun 2019 (v1), last revised 24 Jun 2019 (this version, v2)]
主要内容: 该论文是一篇关于深度学习在时空数据挖掘中的应用的综述。论文首先介绍了时空数…
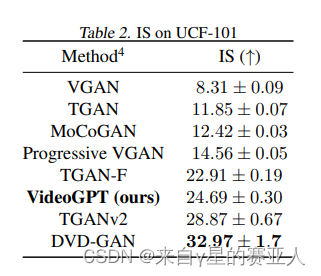
【论文笔记】VideoGPT: Video Generation using VQ-VAE and Transformers
论文标题:VideoGPT: Video Generation using VQ-VAE and Transformers
论文代码:https://wilson1yan. github.io/videogpt/index.html.
论文链接:https://arxiv.org/abs/2104.10157
发表时间: 2021年9月
Abstract
作者提出了…

✅稳定检索,高校嘉宾出席,2024年机械应用与机器视觉研究国际会议(ICMAMVR 2024)
2024年机械应用与机器视觉研究国际会议(ICMAMVR 2024) 数据库:EI,CPCI,CNKI,Google Scholar 等 2024 International Conference on Mechanical Applications and Machine Vision Research(ICMAMVR 2024) 一、【会议简介】 🎉🎉 2024年机械应用…

论文笔记:Multi-Concept Customization of Text-to-Image Diffusion
0 概述
论文:Multi-Concept Customization of Text-to-Image Diffusion 源代码和数据:https://www.cs.cmu.edu/~custom-diffusion/ 当生成模型生成从大规模数据库中学习的概念的高质量图像时,用户通常希望合成他们自己的概念的实例(例如&…

【论文阅读笔记】Smil: Multimodal learning with severely missing modality
Ma M, Ren J, Zhao L, et al. Smil: Multimodal learning with severely missing modality[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(3): 2302-2310.[开源]
本文的核心思想是探讨和解决多模态学习中的一个重要问题:在训练和测…
论文阅读》用语义解耦改进共情对话生成 2022 IJCKG
《论文阅读》用语义解耦改进共情对话生成 前言简介相关知识对抗学习模型架构Semantics DecouplerEmpathetic Generator损失函数前言
论文阅读不迷路!
今天为大家带来的是《Improving Empathetic Dialogue Generation with Semantics Decoupling》 出版:IJCKG(International…
![[论文阅读] Revisiting Feature Propagation and Aggregation in Polyp Segmentation](https://img-blog.csdnimg.cn/direct/6c68dad46b844d08bc38d0d1bd327404.jpeg#pic_center)
[论文阅读] Revisiting Feature Propagation and Aggregation in Polyp Segmentation
[论文地址] [代码] [MICCAI 23] Abstract
息肉的准确分割是筛查过程中有效诊断结直肠癌的关键步骤。 由于能够有效捕获多尺度上下文信息,普遍采用类似UNet 的编码器-解码器框架。 然而,两个主要限制阻碍了网络实现有效的特征传播和聚合。 首先ÿ…

【论文阅读】Speech Driven Video Editing via an Audio-Conditioned Diffusion Model
DiffusionVideoEditing:基于音频条件扩散模型的语音驱动视频编辑
code:GitHub - DanBigioi/DiffusionVideoEditing: Official project repo for paper "Speech Driven Video Editing via an Audio-Conditioned Diffusion Model"
paper&#…
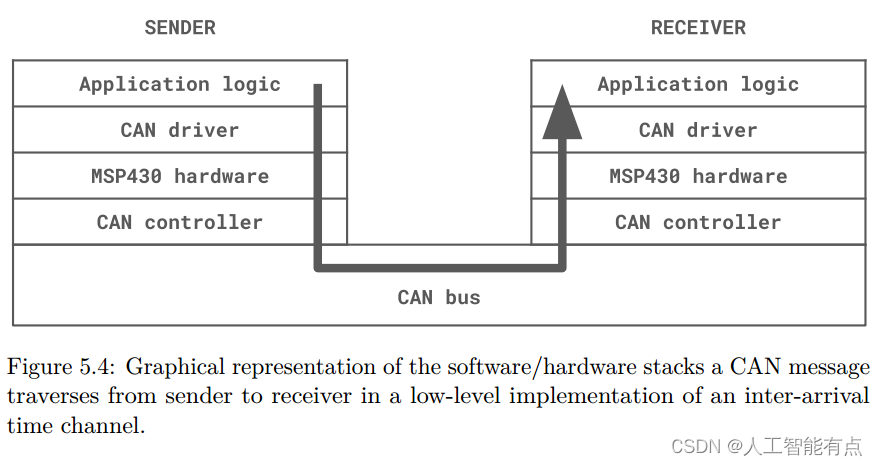
【论文阅读】基于隐蔽带宽的汽车控制网络鲁棒认证(二)
文章目录 第三章 识别CAN中的隐藏带宽信道3.1 隐蔽带宽vs.隐藏带宽3.1.1 隐蔽通道3.1.2 隐藏带宽通道 3.2 通道属性3.3 CAN隐藏带宽信道3.3.1 CAN帧ID字段3.3.2 CAN帧数据字段3.3.3 帧错误检测领域3.3.4 时间通道3.3.5 混合通道 3.4 构建信道带宽公式3.5通道矩阵3.6 结论 第四章…

Adding Conditional Control to Text-to-Image Diffusion Models——【论文笔记】
本文发表于ICCV2023
论文地址:ICCV 2023 Open Access Repository (thecvf.com)
官方实现代码:lllyasviel/ControlNet: Let us control diffusion models! (github.com) Abstract
论文提出了一种神经网络架构ControlNet,可以将空间条件控制添加到大型…
![[论文笔记]P-tuning v2](https://img-blog.csdnimg.cn/img_convert/dd505fa8137f31ec18647f439d986672.png)
[论文笔记]P-tuning v2
引言
今天带来第五篇大模型微调论文笔记P-tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks。
作者首先指出了prompt tuning的一些不足,比如在中等规模的模型上NLU任务表现不好,还不能处理困难的序列标记任务,缺乏统一应用的能力。
然…

论文阅读1---OpenCalib论文阅读之factory calibration模块
前言
该论文的标定间比较高端,一旦四轮定位后,可确定标定板与车辆姿态。以下为本人理解,仅供参考。
工厂标定,可理解为车辆相关的标定,不涉及传感器间标定
该标定工具不依赖opencv;产线长度一般2.5米 Fa…

【论文阅读】Deep Graph Infomax
目录 0、基本信息1、研究动机2、创新点2.1、核心思想:2.2、思想推导: 3、准备3.1、符号3.2、互信息3.3、JS散度3.4、Deep InfoMax方法3.5、判别器:f-GAN估计散度 4、具体实现4.1、局部-全局互信息最大化4.2、理论动机 5、实验设置5.1、直推式…
![[论文阅读]A ConvNet for the 2020s](https://img-blog.csdnimg.cn/14dcdfc29ff8463990419a3235716af8.png)
[论文阅读]A ConvNet for the 2020s
摘要
视觉识别的咆哮的20年代开始于ViTs的引入,它很快取代了卷积神经网络,成为最先进的图像分类模型。另一方面,一个原始的ViT在用于一般的比如目标识别和语义分割的计算机视觉任务的时候面临困难。层次Transformer(例如,Swin-Tr…
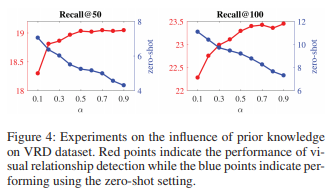
论文记录:Visual Relationship Detection with Deep Structural Ranking (AAAI-18)
(这里只是记录了论文的一些内容以及自己的一点点浅薄的理解,具体实验尚未恢复。由于本人新人一枚,若有错误以及不足之处,还望不吝赐教)
总结 两大挑战: different from individual object learning tasks,…
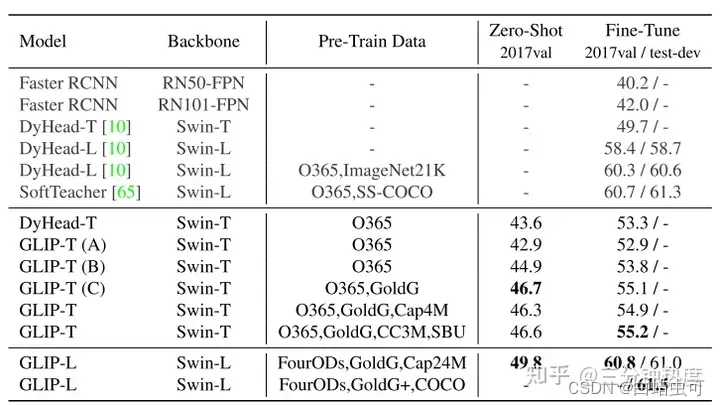
GLIP,FLIP论文阅读
Scaling Language-Image Pre-training via Masking(FLIP,2023)👍 贡献:
1.图像端引入MAE的随机MASK,image encoder只处理未mask的patches(和之前的MAE方法一致),减少了输…

【论文阅读公式推导1】连续体机器人的哈密尔顿动力学推导
推导了一下论文哈密尔顿原理的表达,原论文的计算公式是对的,记录一下。
Gravagne I A, Rahn C D, Walker I D. Good vibrations: a vibration damping setpoint controller for continuum robots[C]//Proceedings 2001 ICRA. IEEE International Confer…
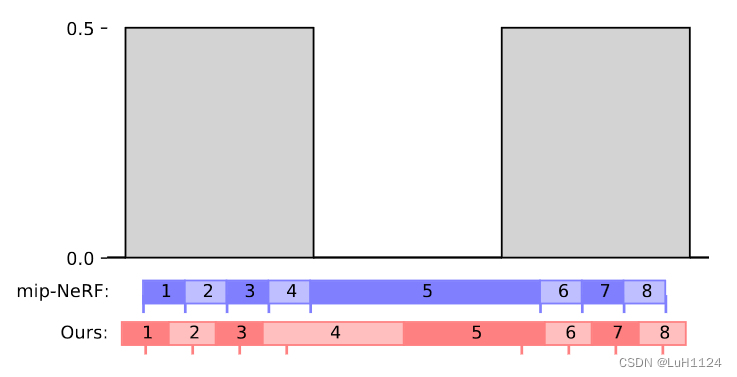
【论文阅读笔记】Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields
目录 概述摘要引言参数化效率歧义性 mip-NeRF场景和光线参数化从粗到细的在线蒸馏基于区间的模型的正则化实现细节实验限制总结:附录退火膨胀采样背景颜色 paper:https://arxiv.org/abs/2111.12077 code:https://github.com/google-research/…
PDF文件中更改 PDF 文本颜色的最有效解决方案
PDF 是最常用的文档类型之一,也是商业中使用的首选文档。在工作中,我们经常需要修改PDF的文本内容,转换格式(如PDF转Word,PDF转Excel等),合并PDF,以达到更好的工作效果。
然而&…

ResNet论文阅读和简单实现
论文:https://arxiv.org/pdf/1512.03385.pdf
Deep Residual Learning for Image Recognition
本模块主要是阅读论文,会做简单的翻译(至少满足我自己能看明白)。
Introduction 由上图可见,在20层和56层的网络上训练的…
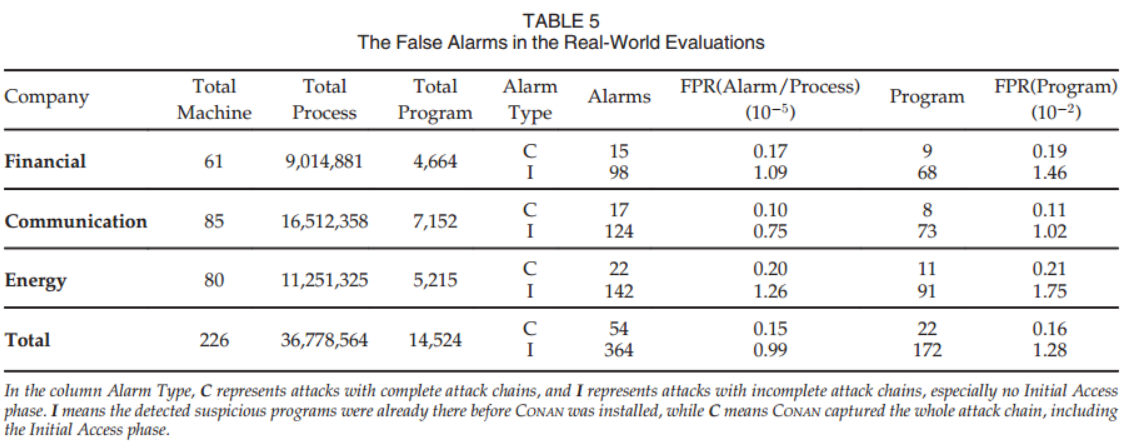
【论文阅读】CONAN:一种实用的、高精度、高效的APT实时检测系统(TDSC-2020)
CONAN:A Practical Real-Time APT Detection System With High Accuracy and Efficiency TDSC-2020 浙江大学 Xiong C, Zhu T, Dong W, et al. CONAN: A practical real-time APT detection system with high accuracy and efficiency[J]. IEEE Transactions on Dep…

【论文阅读笔记】Stable View Synthesis 和 Enhanced Stable View Synthesis
目录 Stable View Synthesis摘要引言 Enhanced Stable View Synthesis 从Mip-NeRF360的对比实验中找到的两篇文献,使用了卷积神经网络进行渲染和新视角合成,特此记录一下
ToDo
Stable View Synthesis
paper:https://readpaper.com/pdf-ann…
![[论文笔记]SimCSE](https://img-blog.csdnimg.cn/img_convert/23ca7438cadf266f0be5fba1e0cb7689.png)
[论文笔记]SimCSE
引言
今天带来一篇当时引起轰动的论文SimCSE笔记,论文题目是 语句嵌入的简单对比学习。
SimCSE是一个简单的对比学习框架,它可以通过无监督和有监督的方式来训练。
对于无监督方式,输入一个句子然后在一个对比目标中预测它自己,仅需要标准的Dropout作为噪声。这种简单的…

【论文阅读】MAG:一种用于航天器遥测数据中有效异常检测的新方法
文章目录 摘要1 引言2 问题描述3 拟议框架4 所提出方法的细节A.数据预处理B.变量相关分析C.MAG模型D.异常分数 5 实验A.数据集和性能指标B.实验设置与平台C.结果和比较 6 结论 摘要
异常检测是保证航天器稳定性的关键。在航天器运行过程中,传感器和控制器产生大量周…
File System Semantics Requirements of HPC Applications——论文泛读
HPDC 2021 Paper 分布式元数据论文汇总
问题
大多数广泛部署的并行文件系统(PFS)实现POSIX语义,这意味着对读写的顺序一致性。但严格遵循POSIX语义会妨碍性能,因此引入了一些具有松弛一致性语义和更好性能的新PFS。这种PFS在应用…

FAST-LIO论文阅读
论文:FAST-LIO: A Fast, Robust LiDAR-inertial Odometry Package by Tightly-Coupled Iterated Kalman Filter
源码链接
各位大佬对论文的解析: FAST-LIO论文解读与详细公式推导
FAST-LIO是港大MaRS实验室在2021年提出的一个紧耦合迭代扩展卡尔曼滤波…
![[论文笔记]SimMIM:a Simple Framework for Masked Image Modeling](https://img-blog.csdnimg.cn/d8775c50461f401e962e16833c5b9d0a.png)
[论文笔记]SimMIM:a Simple Framework for Masked Image Modeling
文章地址:https://arxiv.org/abs/2111.09886 代码地址:https://github.com/microsoft/SimMIM 文章目录 摘要文章思路创新点文章框架Masking strategyPrediction headPrediction targetEvaluation protocols 性能实验实验设置Mask 策略预测头目标分辨率预…

Survey on Cooperative Perception in an Automotive Context 论文阅读
论文链接
Survey on Cooperative Perception in an Automotive Context 0. Abstract
本文就协同基础设施领域提供相关环境的调查回顾了感知中涉及的主要模块:定位,目标检测和跟踪,地图生成提供了协同感知的 SWOT 1. Intro
无人驾驶汽车的背…

ZKP Understanding Nova (2) Relaxed R1CS
Understanding Nova
Kothapalli, Abhiram, Srinath Setty, and Ioanna Tzialla. “Nova: Recursive zero-knowledge arguments from folding schemes.” Annual International Cryptology Conference. Cham: Springer Nature Switzerland, 2022.
Nova: Paper Code
2. Unders…

NLP论文阅读记录 - 2022 | WOS 用于摘要法律文本的有效深度学习方法
文章目录 前言0、论文摘要一、Introduction1.1目标问题 二.相关工作三.本文方法四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结 前言 Effective deep learning approaches for summarization of legal texts(22&#x…

论文阅读《Robust Monocular Depth Estimation under Challenging Conditions》
论文地址:https://arxiv.org/pdf/2308.09711.pdf 源码地址:https://github.com/md4all/md4all 概述 现有SOTA的单目估计方法在理想的环境下能得到满意的结果,而在一些极端光照与天气的情况下往往会失效。针对模型在极端条件下的表现不佳问题&…
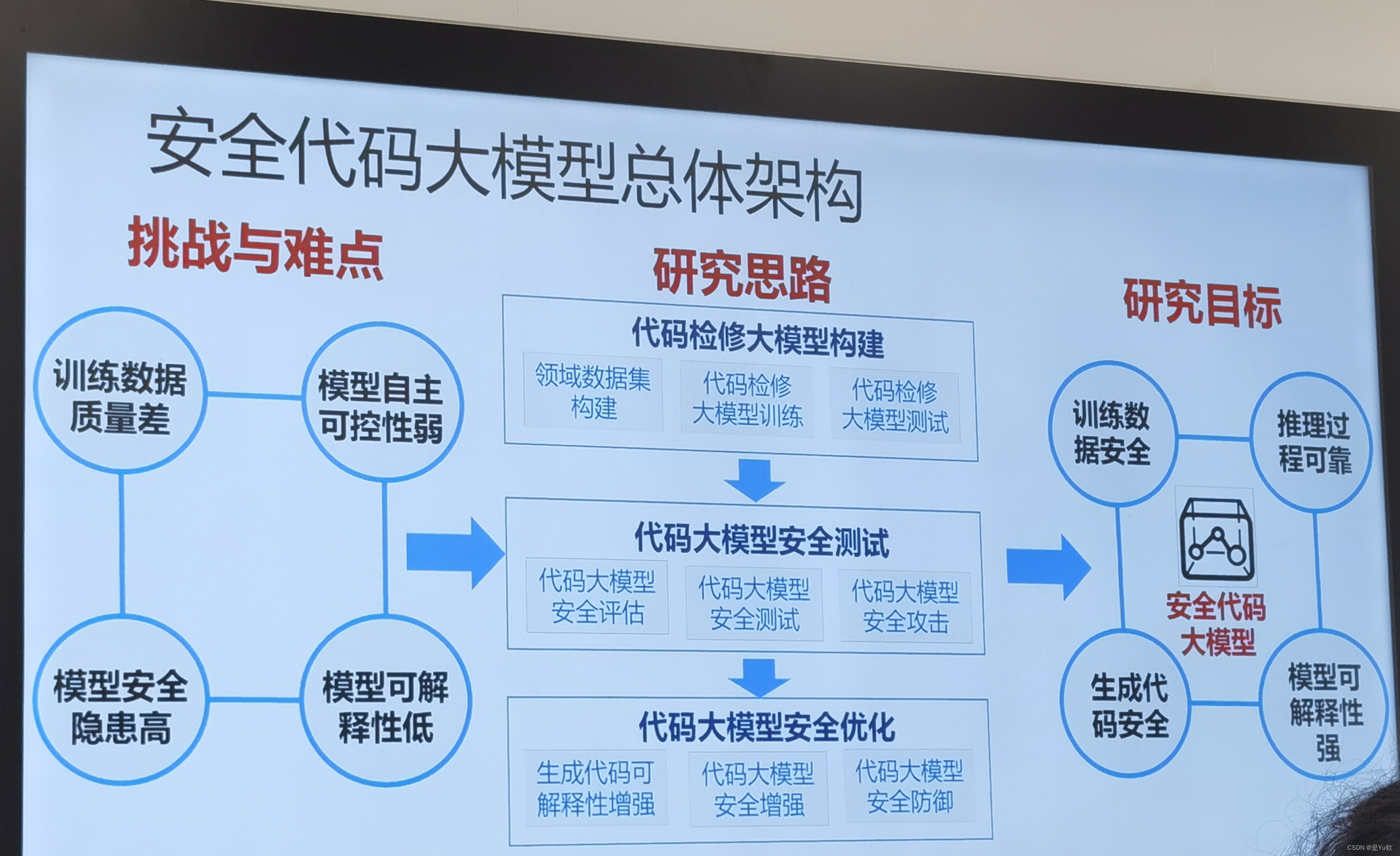
【网安专题10.11】软件安全+安全代码大模型
软件安全安全代码大模型 写在最前面一些启发科研方法科研思路 课程考察要求软件供应链安全漏洞复制1、代码克隆2、组件依赖分析 关键组件安全不足,漏洞指数级放大供应链投毒内部攻击源代码攻击分发、下载网站攻击更新、补丁网站攻击 形成技术壁垒(找方向…

论文阅读:Vary论文阅读笔记
目录 引言整体结构图数据集构造Vary-tiny部分Document Data数据构造Chart Data构造Negative natural image选取 Vary-base部分 引言 论文:Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models Paper | Github | Demo 许久不精读论文了&#x…
论文阅读笔记整理(持续更新)
KV存储
ROLEX: A Scalable RDMA-oriented Learned Key-Value Store for Disaggregated Memory Systems
FAST 2023 Paper 泛读笔记
针对分离式内存系统中,KV存储性能不高的问题,由于内存节点资源有限,现有方法难以直接修改B树或学习索引的模…

科教文汇期刊怎么投稿?
《科教文汇》系国家新闻出版署认定的第一批学术期刊,主要刊登教育领域有创新性、学术性和实用性,有较高学术价值的论文。本刊由顾问、名誉社长、主任编委及编委组成学术审读团体,注重教研教改成果的宣传、案例的分析、经验的介绍及学术的交流…
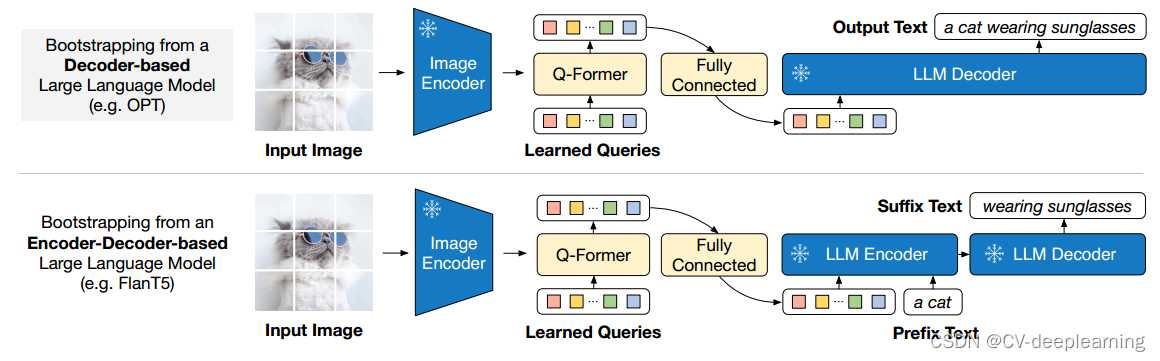
BLIP2原理解读——大模型论文阅读笔记二
一. 论文与代码
论文:https://arxiv.org/abs/2301.12597 代码:https://github.com/salesforce/LAVIS/tree/main/projects/blip2
二. 解决问题
端到端训练视觉语言模型需要大尺度模型及大规模数据,该过程成本大,本文提出方法基于…
论文笔记目录(ver2.0)
1 时间序列
1.1 时间序列预测
论文名称来源主要内容论文笔记:DCRNN (Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting)_UQI-LIUWJ的博客-CSDN博客iclr 2017使用双向扩散卷积GRU,建模空间和…
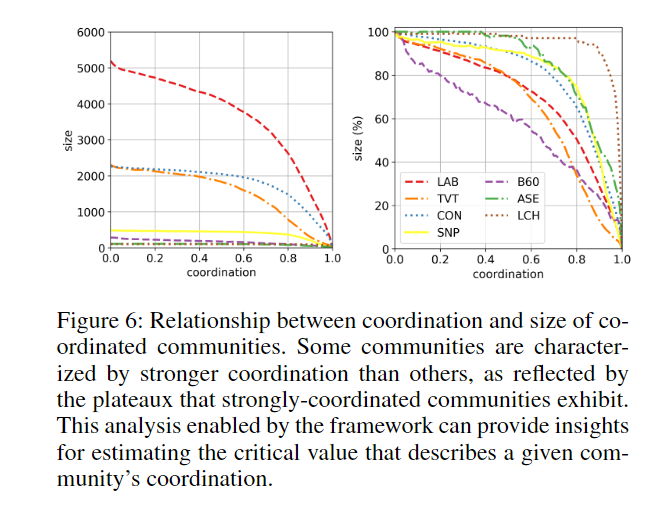
论文阅读 - Coordinated Behavior on Social Media in 2019 UK General Election
论文链接: https://arxiv.org/abs/2008.08370
目录
摘要:
Introduction
Contributions
Related Work
Dataset
Method Overview
Surfacing Coordination in 2019 UK GE
Analysis of Coordinated Behaviors 摘要: 协调的在线行为是信息…

RES 新的数据集 Advancing Referring Expression Segmentation Beyond Single Image 论文笔记
RES 新的数据集 Advancing Referring Expression Segmentation Beyond Single Image 论文笔记 一、Abstract二、引言三、相关工作3.1 Referring Expression Segmentation (RES)3.2 CoSalient Object Detection (CoSOD) 四、提出的方法4.1 概述文本 & 图像编码器TQM & H…

【论文阅读】A Survey on Video Diffusion Models
视频扩散模型(Video Diffusion Model)最新综述GitHub 论文汇总-A Survey on Video Diffusion Models。
paper:[2310.10647] A Survey on Video Diffusion Models (arxiv.org) 0. Abstract
本文介绍了AIGC时代视频扩散模型的全面回顾。简要介…
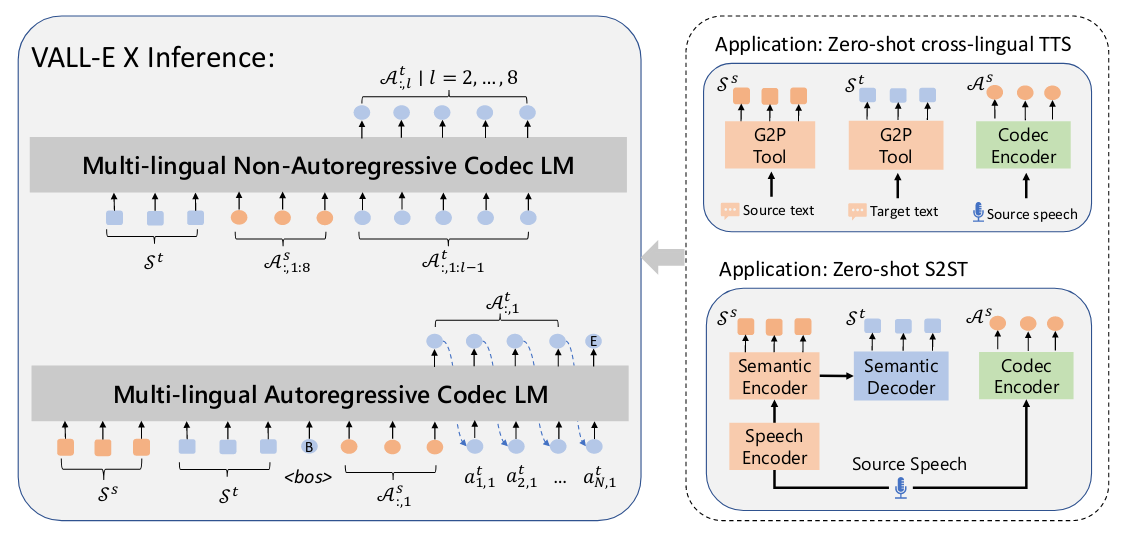
论文阅读_语音合成_VALLE-X
论文信息
name_en: Speak Foreign Languages with Your Own Voice: Cross-Lingual Neural Codec Language Modeling name_ch: 用你自己的声音说外语:跨语言神经编解码器语言建模 paper_addr: http://arxiv.org/abs/2303.03926 date_read: 2023-04-25 date_publish:…

【论文阅读】深度学习方法在数字岩石技术中的应用进展
【论文名称】Advances in the application of deep learning methods to digital rock technology 深度学习方法在数字岩石技术中的应用进展 【论文来源】EI检索 【作者单位】长江大学地球物理与油气资源学院、加拿大阿尔伯塔大学土木与环境工程系、东北石油大学地球科学学院、…

论文笔记——chatgpt评估+
文章目录 1. chatgpt 效果评估:Evaluating ChatGPT’s Information Extraction Capabilities: An Assessment of Performance, Explainability, Calibration, and Faithfulness文章简介文章结论 2. 事件抽取: OneEE: A One-Stage Framework for Fast Overlapping an…

【论文阅读|2024 WACV 多目标跟踪Deep-EloU】
论文阅读|2024 WACV 多目标跟踪Deep-EloU 摘要1 引言(Introduction)2 相关工作(Related Work)2.1 基于卡尔曼滤波器的多目标跟踪算法(Multi-Object Tracking using Kalman Filter)2.2 基于定位的多目标跟踪…
关于区块链的几篇论文的比较
1.Blockchain Adoption for Combating Deceptive Counterfeits
主要专注于欺骗性假货,即客户无法真正区分真货和假货。 假设市场中只有一个制造商(M)销售真货给消费者,还有一个假货商(C)销售假货给消费者。…
【论文阅读】以及部署BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework
BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework BEVFusion:一个简单而强大的LiDAR-相机融合框架
NeurIPS 2022
多模态传感器融合意味着信息互补、稳定,是自动驾驶感知的重要一环,本文注重工业落地,实际应用
融…

【论文阅读】自动驾驶中车道检测系统的物理后门攻击
文章目录 AbstractIntroduction 论文题目: Physical Backdoor Attacks to Lane Detection Systems in Autonomous Driving(自动驾驶中车道检测系统的物理后门攻击) 发表年份: 2022-MM(ACM International Conference on…

论文阅读:A visualized human-computer interactive approach to job shop scheduling
A visualized human-computer interactive approach to job shop scheduling 作者:Dong H. Baek、Sang Y. OH、Wan C. Yoon 期刊:COMPUTER INTEGRATED MANUFACTURING、1999 网络资源:A visualized human-computer interactive approach to jo…

论文笔记:A Simple Framework for Contrastive Learning of Visual Representations
0 简介
论文:A Simple Framework for Contrastive Learning of Visual Representations 代码:https://github.com/google-research/simclr 发表:2020年发表在ICML会议上
1 核心思想
如何构建对比学习的比较对象?本文按如下方式…
大模型综述论文笔记1-5
目录 KeywordsIntroductionSLMNLMPLMLLM Backgroud for LLMsScaling Laws for LLMsKM scaling lawChinchilla scaling law Emergent Abilities of LLMsIn-context learningInstruction followingStep-by-step reasoning Key Techniques for LLMsScalingTrainingAbility eliciti…
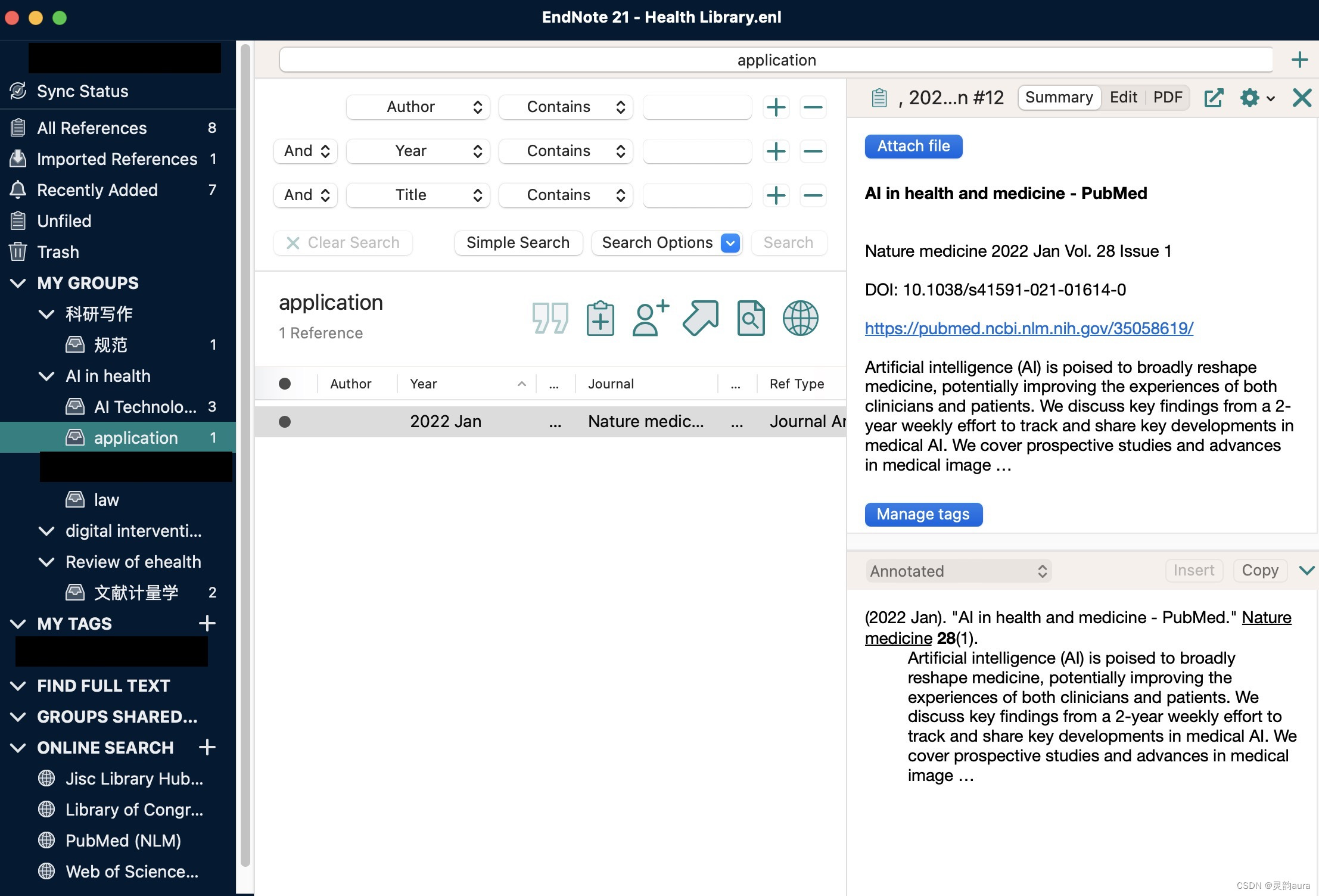
EndNote21 for Mac:科研文献管理神器的保姆级教程
最近写论文要看上百篇英语文献,新手刚开始,真正是一顿操作猛如虎,手动下载、查看abstract、手动分类归档(未来的诺贝尔获奖者正在练成😎)
然而,上述操作重复几天后:疑,这…
《成才之路》期刊投稿方式发表论文要求
《成才之路》杂志是国家新闻出版署批准的正规教育类G4期刊,是国家新闻出版署权威认定专业学术期刊。本刊密切关注人才教育与培养的理论和实践,关注人才学研究的前沿问题,特别是各学科教育教学一线的育才新理念、育才新方法、育才新思路&#…

专攻数学的Prompt:使GPT-3解数学题准确率升至92.5%
专攻数学的Prompt:使GPT-3解数学题准确率升至92.5% 写在最前面示例(试过了,难点的和普通输出差不多;只能说,比简单的题目输出内容更丰富一些)MathPrompter解题示例 机理MathPrompter是怎么工作的࿰…
Learning Sample Relationship for Exposure Correction 论文阅读笔记
这是中科大发表在CVPR2023的一篇论文,提出了一个module和一个损失项,能够提高现有exposure correction网络的性能。这已经是最近第三次看到这种论文了,前两篇分别是CVPR2022的ENC(和这篇文章是同一个一作作者)和CVPR20…

【开源威胁情报挖掘1】引言 + 开源威胁情报挖掘框架 + 开源威胁情报采集与识别提取
基于开源信息平台的威胁情报挖掘综述 写在最前面摘要1 引言近年来的一些新型网络安全威胁类型挖掘网络威胁的情报信息威胁情报分类:内、外部威胁情报国内外开源威胁情报挖掘分析工作主要贡献研究范围和方法 2 开源威胁情报挖掘框架1. 开源威胁情报采集与识别2. 开源…
【论文阅读】(2016)Learning to Branch in Mixed Integer Programming
文章目录 一、摘要二、介绍三、我们的框架概述3.1 数据采集 论文来源:(2016)Learning to Branch in Mixed Integer Programming 作者:Elias B. Khalil 等人 一、摘要
混合整数规划 (MIP) 中的分支策略设计以参数调整和离线实验的…
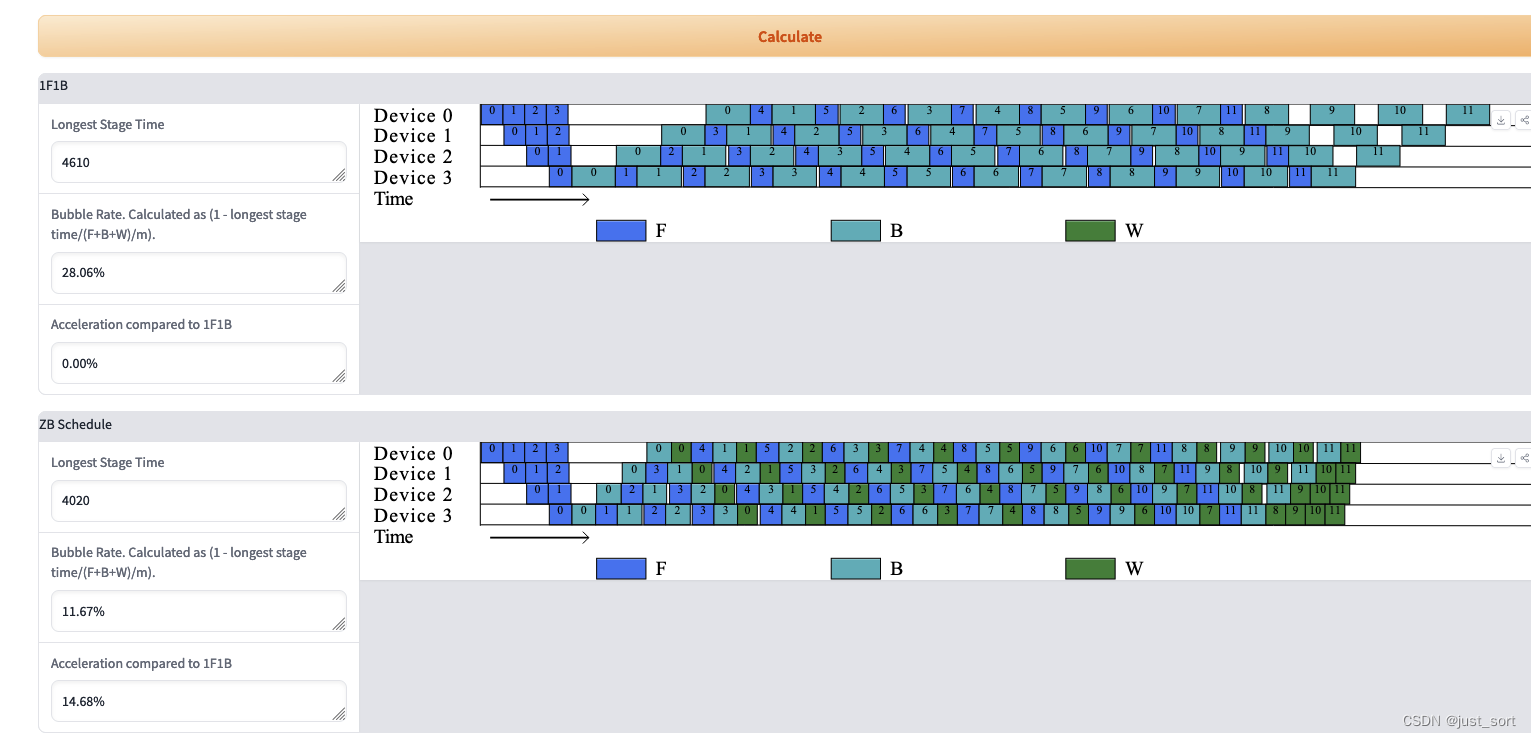
AI Infra论文阅读之将流水线并行气泡几乎降到零(附基于Meagtron-LM的ZB-H1开源代码实现解读)
0x0. 前言
这篇论文对应的链接为:https://openreview.net/pdf?idtuzTN0eIO5 ,最近被ICLR 2024接收,但不少AI Infra的同行已经发现了这个工作的价值,并且已经开源在 https://github.com/sail-sg/zero-bubble-pipeline-parallelis…
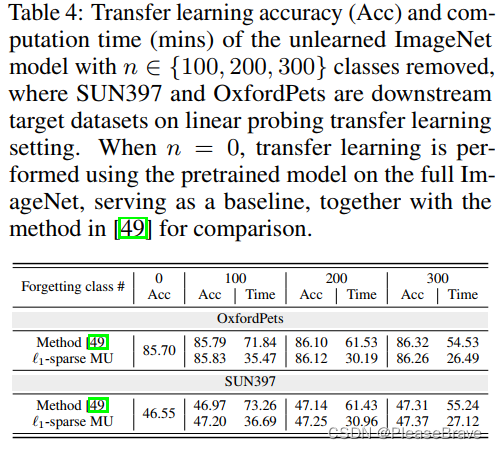
【论文阅读】 Model Sparsity Can Simplify Machine Unlearning
Model Sparsity Can Simplify Machine Unlearning 背景主要内容Contribution Ⅰ:对Machine Unlearning的一个全面的理解Contribution Ⅱ:说明model sparsity对Machine Unlearning的好处Pruning方法的选择sparse-aware的unlearning framework Experiments…

教育观察期刊投稿邮箱、投稿要求
《教育观察》创刊于2012年,是国家新闻出版总署批准的正规教育类学术期刊,本刊致力于在教育实践中以“观察”为方法,以“观察者”为主体,以“新观察”为旨趣,打造从教育实践中洞察教育未来的教育研究与交流的平台。主要…

论文阅读:Syntax-Aware Network for Handwritten Mathematical Expression Recognition
论文阅读:Syntax-Aware Network for Handwritten Mathematical Expression Recognition1
主要观点:
1、提出将语法信息纳入编码器-解码器网络的方法。使用一组语法规则,用于将每个表达式的LaTeX标记序列转换为解析树;用深度神经…
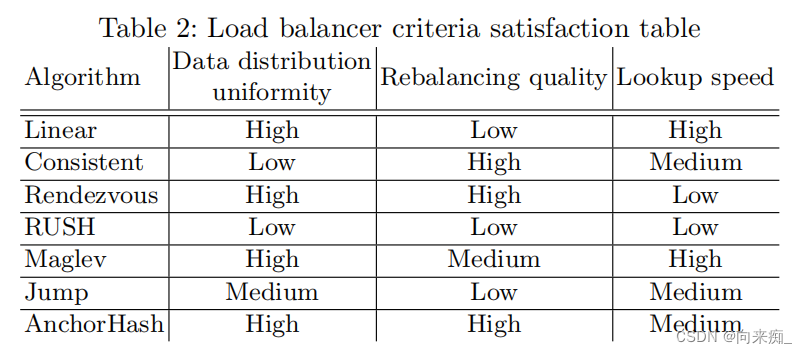
论文阅读-在分布式数据库环境中对哈希算法进行负载均衡基准测试
论文名称:Benchmarking Hashing Algorithms for Load Balancing in a Distributed Database Environment
摘要
现代高负载应用使用多个数据库实例存储数据。这样的架构需要数据一致性,并且确保数据在节点之间均匀分布很重要。负载均衡被用来实现这些目…

NLP论文阅读记录 - 2023 | EXABSUM:一种新的文本摘要方法,用于生成提取和抽象摘要
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.相关工作三.本文方法四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结思考 前言 EXABSUM: a new text summarization approach for generating ex…
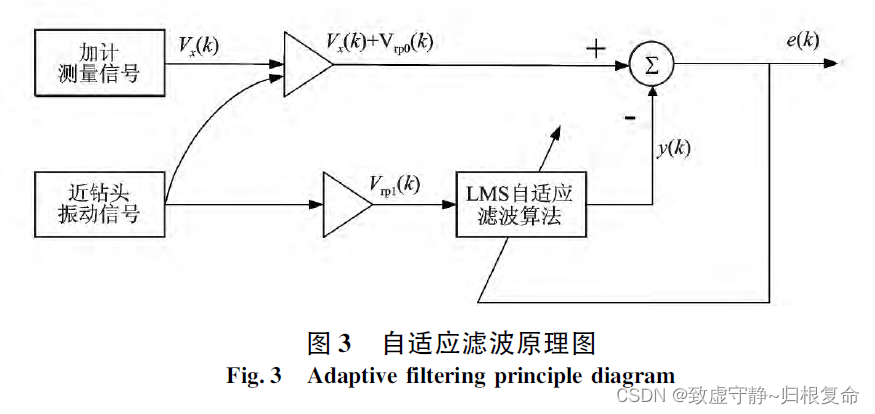
课题学习(九)----阅读《导向钻井工具姿态动态测量的自适应滤波方法》论文笔记
一、 引言 引言直接从原论文复制,大概看一下论文的关键点: 垂直导向钻井工具在近钻头振动和工具旋转的钻井工作状态下,工具姿态参数的动态测量精度不高。为此,通过理论分析和数值仿真,提出了转速补偿的算法以消除工具旋…
(论文阅读27/100)Deep Filter Banks for Texture Recognition and Segmentation
27.文献阅读笔记 简介 题目 Deep Filter Banks for Texture Recognition and Segmentation 作者 Mircea Cimpoi, Subhransu Maji, Andrea Vedaldi, 原文链接 http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Cimpoi_Deep_Filter_Banks_2015_CVPR_pap…
论文阅读【1】--PCWGAN-GP: A New Method for Imbalanced Fault Diagnosis of Machines
文章目录 1. 摘要部分2. 引言3. 一些相关背景知识3.1生成对抗网络概述3.2 Wasserstein GAN 以及梯度惩罚4. 提出方法4.1 模型结构4.2 模型训练5. 实验测试5.1 数据说明5.2 模型构建5.2 实验结果分析6. 结论1. 摘要部分
在实际工业应用场景中,机械设备大多数时间都处在健康状态…

【论文阅读】GPT4Graph: Can Large Language Models Understand Graph Structured Data?
文章目录 0、基本介绍1、研究动机2、准备2.1、图挖掘任务2.2、图描述语言(GDL) 3、使用LLM进行图理解流程3.1、手动提示3.2、自提示 4、图理解基准4.1、结构理解任务4.1、语义理解任务 5、数据搜集5.1、结构理解任务5.2、语义理解任务 6、实验6.1、实验设…
EndNote+有道
EndNote里面有划线翻译的功能,前提是你的电脑里面安装了有道翻译或者百度翻译的客户端。 我更喜欢有道,所以...... 然后点击“快速安装”。完了之后打开如下: 实现翻译的操作如下: ok。

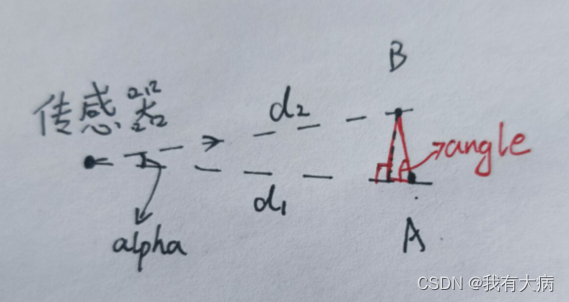
论文笔记:Localizing Cell Towers fromCrowdsourced Measurements
2015
1 Intro
1.1 motivation
opensignal.com 、cellmapper.net 和 opencellid.org 都是提供天线(antenna)位置的网站 他们提供的天线位置相当准确,但至少在大多数情况下不完全正确这个目标难以实现的原因是蜂窝网络供应商没有义务提供有…
【LeGO-LOAM论文阅读(一)--点云分割】
个人笔记,个人理解,不建议参考,如有错误希望多多指教lego-loam简介点云分割理论部分源码解析1、将点云数据转化为pcl点云2、寻找一帧的起始方向角。3、将激光点云转化为深度图4、过滤地面点5、点云分割6、发布各类行点云lego-loam简介
lego-…
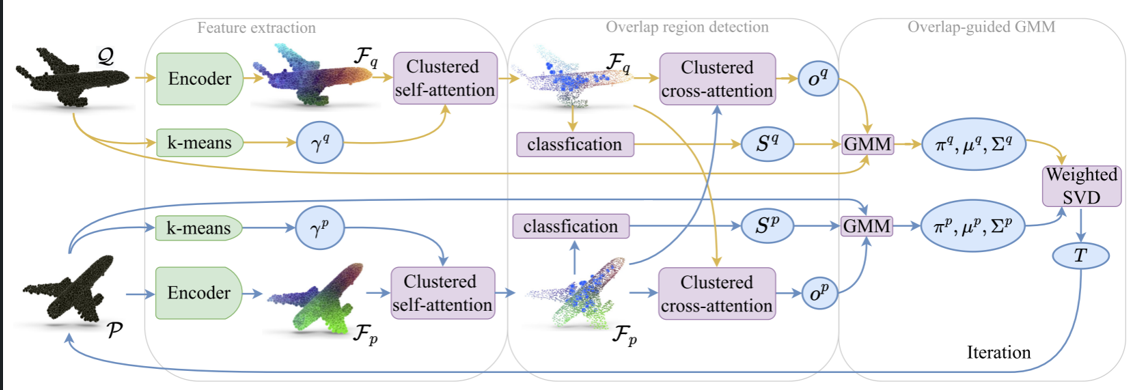
《论文阅读28》OGMM
一、论文
研究领域: 点云配准 | 有监督 部分重叠论文:Overlap-guided Gaussian Mixture Models for Point Cloud Registration WACV 2023 二、概述
概率3D点云配准方法在克服噪声、异常值和密度变化方面表现出有竞争力的性能。本文将点云对的配准问题…
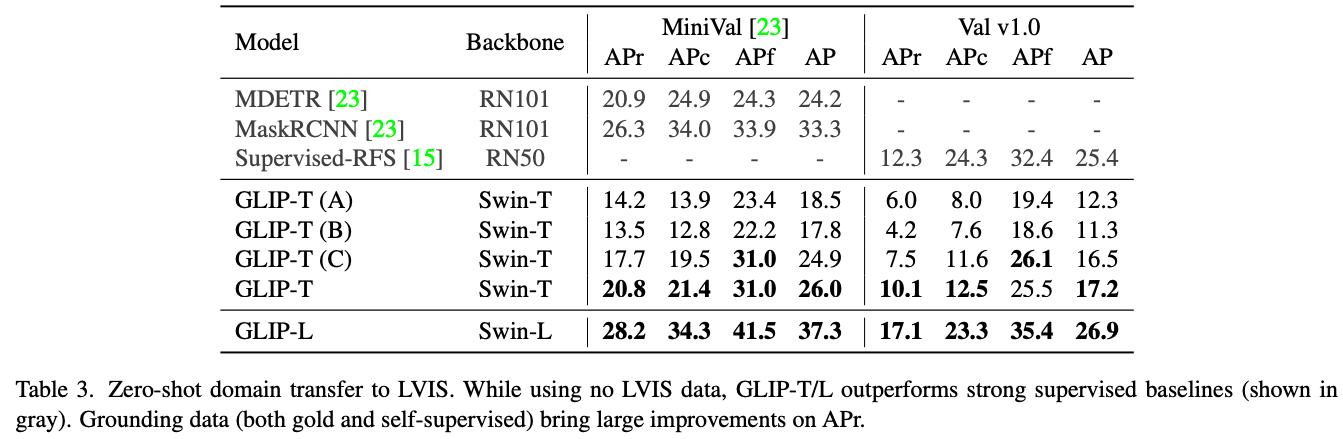
Grounded Language-Image Pre-training论文笔记
Title:Grounded Language-Image Pre-training
Code 文章目录 1. 背景2. 方法(1)Unified Formulation传统目标检测grounding目标检测 (2)Language-Aware Deep Fusion(3)Pre-training with Scala…
【论文阅读笔记】CNN-Transformer for Microseismic Signal Classification
【论文阅读笔记】CNN-Transformer for Microseismic Signal Classification
摘要 这篇论文提出了一种名为CCViT的轻量级网络模型,用于快速准确地识别地下传感器采集的煤矿和岩石裂缝的微震信号中由煤矿爆破产生的大量爆破振动信号。这些微震信号与爆破振动信号的波…
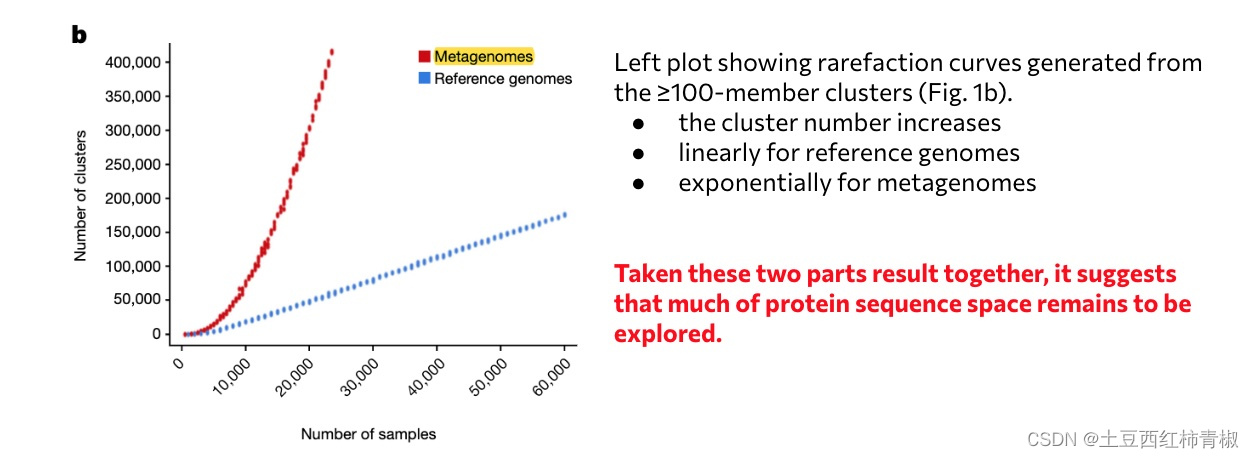
文章系列2:Unraveling the functional dark matter through global metagenomics
这篇文章发布于2023年10月nature。通讯作者是来自于 DOE Joint Genome Institute, Lawrence Berkeley National Laboratory, Berkeley, CA, USA.
背景介绍&目标
作者首先背景介绍了两种主流宏基因组分析方法,包括reads-based reference mapping(eg…

论文阅读:Vary-toy论文阅读笔记
目录 引言整体结构图方法介绍训练vision vocabulary阶段PDF数据目标检测数据 训练Vary-toy阶段Vary-toy结构数据集情况 引言 论文:Small Language Model Meets with Reinforced Vision Vocabulary Paper | Github | Demo 说来也巧,之前在写论文阅读&…
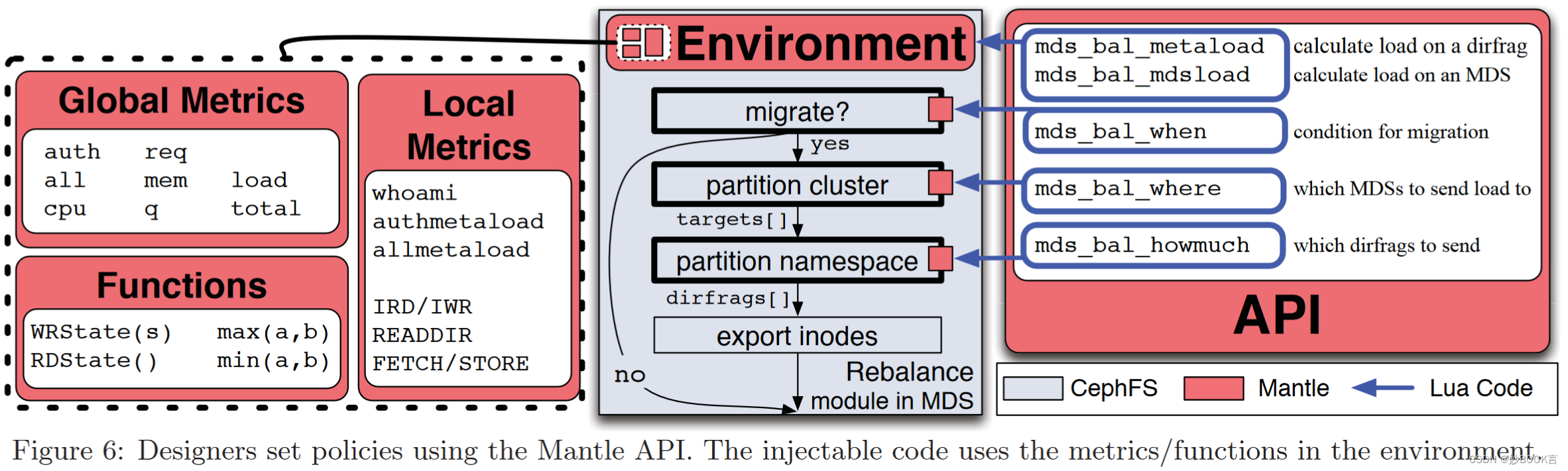
Mantle: A Programmable Metadata Load Balancer for the Ceph File System——论文泛读
SC 2015 Paper 元数据论文阅读汇总
问题
优化Ceph的元数据局部性和负载平衡。
现有方法
提高元数据服务性能的最常见技术是在专用的元数据服务器(MDS)节点之间平衡负载 [16, 25, 26, 21, 28]。常见的方法是鼓励独立增长并减少通信,使用诸…
【持续学习系列(五)】《Progressive Neural Networks》
一、论文信息
1 标题
Progressive Neural Networks
2 作者
Andrei A. Rusu*, Neil C. Rabinowitz*, Guillaume Desjardins*, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Razvan Pascanu, Raia Hadsell
3 研究机构
Google DeepMind, London, UK
二、主要内容 …
【论文阅读】Instruct GPT论文阅读
openAI给出chatGPT的四个功能
fix codechatgpt是有道德的chatgpt是理解上下文的,8000字以内是可以联系上下文的chatgpt是理解自己的局限性
GPT可以支持多轮对话
一般openAI是先发模型和博客,再发论文
InstructGPT
发表在2022.3.4
训练语言模型&…

1024——今天我们不加班
今天,是技术人的节日,在二进制构筑的计算机世界里,1024或许是技术人最熟悉的数字。 你知道为什么选择这一天作为中国程序员的共同节日吗?
1024是2的十次方,二进制计数的基本计量单位之一。程序员(英文Programmer)是从…
论文阅读-Federated Social Recommendation with Graph NeuralNetwork
论文地址:Federated Social Recommendation with Graph Neural Network (arxiv.org)
代码地址:GitHub - YangLiangwei/FeSoG: Code for Federated Social Recommendation with Graph Neural Network
该代码工程没有明确软件版本以及环境配置࿰…

Learning to Super-resolve Dynamic Scenes for Neuromorphic Spike Camera论文笔记
摘要
脉冲相机使用了“integrate and fire”机制来生成连续的脉冲流,以极高的时间分辨率来记录动态光照强度。但是极高的时间分辨率导致了受限的空间分辨率,致使重建出的图像无法很好保留原始场景的细节。为了解决这个问题,这篇文章提出了Sp…
7+非肿瘤+线粒体+PPI+机器学习+实验,多套路搭配干湿结合
今天给同学们分享一篇生信文章“Identification of mitochondrial related signature associated with immune microenvironment in Alzheimers disease”,这篇文章发表在J Transl Med期刊上,影响因子为7.4。 结果解读:
在ND和AD样本中鉴定差…
论文阅读: Semantics-guided Triplet Loss
ICCV 2021
Abstract
一个度量学习方法,通过浏览语义引导的局部集合去优化内在深度表示。一个新颖的特征融合模块能有效利用跨模态特异质特征。
Senantics-guided Triplet Loss
基本假设:
在场景语义分割图像中,目标内部相邻像素拥有同样…

【开源威胁情报挖掘2】开源威胁情报融合评价
基于开源信息平台的威胁情报挖掘综述 写在最前面4 开源威胁情报融合评价开源威胁情报的特征与挑战4.1 开源威胁情报数据融合融合处理方法 4.1 开源威胁情报的质量评价4.1.1 一致性分析本体的定义与组成本体构建的层次 4.1.2 去伪去重4.1.3 数据融合分析 4.2 开源威胁情报质量及…

【知识增强】A Survey of Knowledge-Enhanced Pre-trained LM 论文笔记
A Survey of Knowledge-Enhanced Pre-trained Language Models
Linmei Hu, Zeyi Liu, Ziwang Zhao, Lei Hou, Liqiang Nie, Senior Member, IEEE and Juanzi Li
2023年8月的一篇关于知识增强预训练模型的文献综述
论文思维导图
思维导图网页上看不清的话,可以存…
《论文阅读18》JoKDNet
一、论文
研究领域:用于大尺度室外TLS点云配准的联合关键点检测和特征表达网络论文:JoKDNet: A joint keypoint detection and description network for large-scale outdoor TLS point clouds registration International Journal of Applied Earth Ob…
[论文笔记]MobileBERT
引言
今天带来一篇关于量化的论文MobileBERT,题目翻译过来是:一种适用于资源有限设备的紧凑型任务无关BERT模型。模型的简称是MobileBERT,意思是作者的这个BERT模型可以部署到手机端。
本篇工作,作者提出了MobileBERT用于压缩和加速BERT模型。与原始BERT一样,MobileBERT…
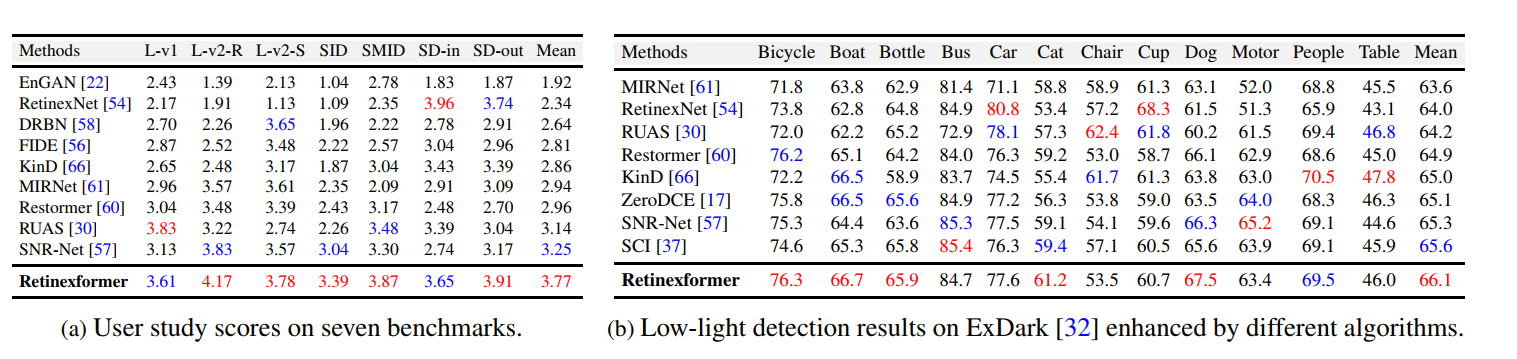
Retinexformer 论文阅读笔记
Retinexformer: One-stage Retinex-based Transformer for Low-light Image Enhancement 清华大学、维尔兹堡大学和苏黎世联邦理工学院在ICCV2023的一篇transformer做暗图增强的工作,开源。文章认为,Retinex的 I R ⊙ L IR\odot L IR⊙L假设干净的R和L&…
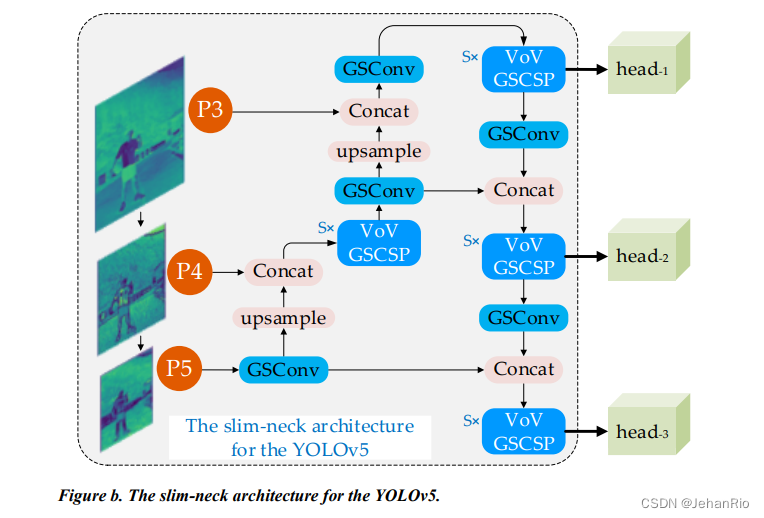
【论文笔记】Slim-neck by GSConv
文章目录 前言1. 简介2. GSConv4. 为什么要在Neck中使用GSConv3. Slim-NeckSlim-Neck中的模块Slim-Neck针对YOLO系列的设计 一些问题总结References 前言 作者提出了一种新方法GSConv来减轻模型复杂度,保持准确性。GSConv可以更好地平衡模型的准确性和速度。并且&am…

论文阅读:Robust High-Resolution Video Matting with Temporal Guidance
发表时间:2021年8月25日 项目地址:https://peterl1n.github.io/RobustVideoMatting/ 论文地址:https://arxiv.org/pdf/2108.11515.pdf
我们介绍了一种鲁棒的,实时的,高分辨率的人体视频匹配方法,以实现了新…

论文阅读-Transformer-based language models for software vulnerability detection
「分享了一批文献给你,请您通过浏览器打开 https://www.ivysci.com/web/share/biblios/D2xqz52xQJ4RKceFXAFaDU/ 您还可以一键导入到 ivySCI 文献管理软件阅读,并在论文中引用 」 本文主旨:本文提出了一个系统的框架来利用基于Transformer的语…
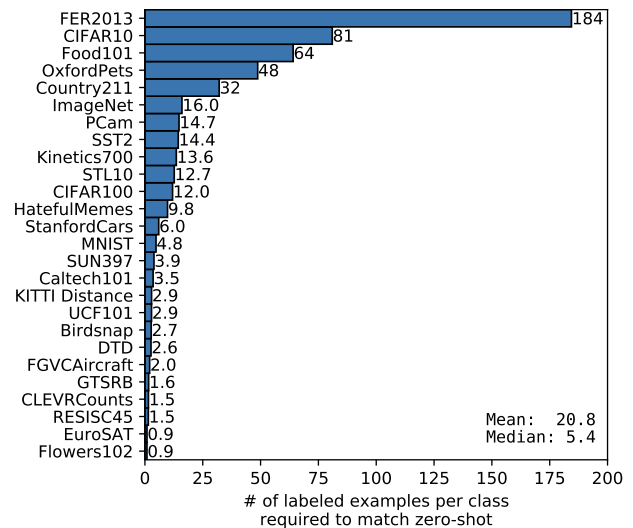
open clip论文阅读摘要
看下open clip论文 Learning Transferable Visual Models From Natural Language Supervision These results suggest that the aggregate supervision accessible to modern pre-training methods within web-scale collections of text surpasses that of high-quality crowd…
如何在电脑和手机设备上编辑只读 PDF
我们大多数人更喜欢以 PDF 格式共享和查看文件,因为它更专业、更便携。但是,通常情况下您被拒绝访问除查看之外的内容编辑、复制或评论。如果您希望更好地控制您的 PDF 或更灵活地编辑它,请弄清楚为什么您的 PDF 是只读的,然后使用…
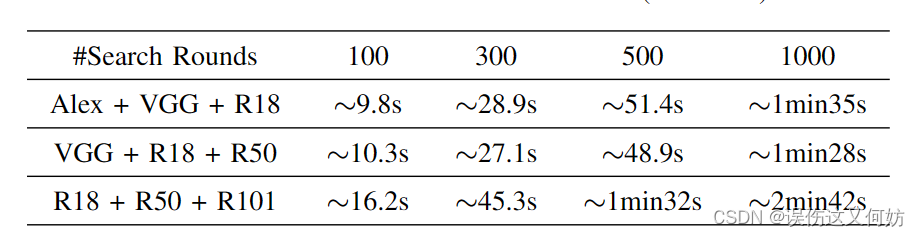
【论文阅读】Automated Runtime-Aware Scheduling for Multi-Tenant DNN Inference on GPU
该论文发布在 ICCAD’21 会议。该会议是EDA领域的顶级会议。
基本信息
AuthorHardwareProblemPerspectiveAlgorithm/StrategyImprovment/AchievementFuxun YuGPUResource under-utilization ContentionSW SchedulingOperator-level schedulingML-based scheduling auto-searc…

【论文阅读】UniDiffuser: Transformer+Diffusion 用于图、文互相推理
而多模态大模型将能够打通各种模态能力,实现任意模态之间转化,被认为是通用式生成模型的未来发展方向。
最近看到不少多模态大模型的工作,有医学、金融混合,还有CV&NLP。
今天介绍: One Transformer Fits All Di…
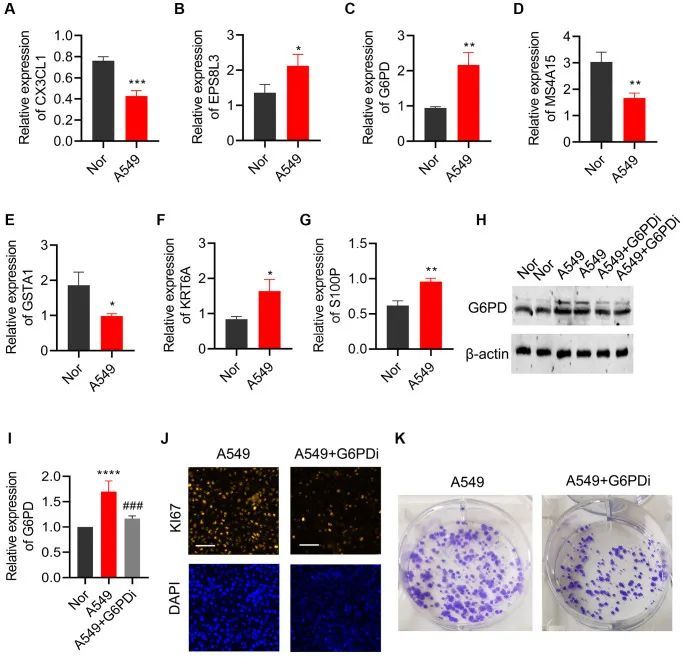
5+双硫死亡+分型+实验,双硫死亡又上大分。干湿结合拿下5+
今天给同学们分享一篇生信文章“The role of molecular subtypes and immune infiltration characteristics based on disulfidptosis-associated genes in lung adenocarcinoma”,这篇文章发表在Aging (Albany NY)期刊上,影响因子为5.2。 结果解读&…
【论文复现】Furthering Datalog in the pursuit of program analysis
本文是对同名论文中GVN相关部分的代码进行复现,该论文的研读可以看笔者主页。
Souffle安装
Souffle是一个Datalog引擎,可以执行Datalog程序,支持将Datalog程序转换为C程序。 在站内有该引擎的安装教程。但是其中的git链接已经失效ÿ…

论文阅读记录SuMa SuMa++
首先是关于SuMa的阅读,SuMa是一个完整的激光SLAM框架,核心在于“基于面元(surfel)”的过程,利用3d点云转换出来的深度图和法向量图来作为输入进行SLAM的过程,此外还改进了后端回环检测的过程,利用提出的面元的概念和使…
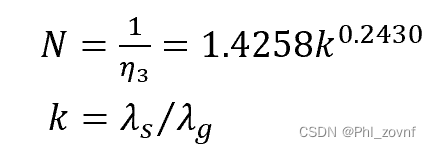
储氢合金/金属氢化物床层有效导热系数的数学模型
最近看到一篇有关“储氢合金/金属氢化物床层有效导热系数的数学模型”的论文,文章DOI:10.1016/j.energy.2023.127085,文章提到的数学物理模型还算好理解一些,特意分享给各位感兴趣的大佬。 一、物理模型简图和假设 文章里…

论文阅读:Self-Supervised Monocular Depth Estimation with Internal Feature Fusion(DIFFNet)
中文标题:基于内部特征融合的自监督单目深度估计
创新点
参照HR-Net在网络上下采样的过程中充分利用语义信息。设计了一个注意力模块处理跳接。提出了一个扩展的评估策略,其中方法可以使用基准数据中的困难的情况进行进一步测试,以一种自我…

强化学习框环境 - robogym - 学习 - 4
强化学习环境 - robogym - 学习 - 4 文章目录 强化学习环境 - robogym - 学习 - 4项目地址为什么选择 robogym如何消去目标位置的阴影?如何让物体颜色变得正确? 项目地址
https://github.com/openai/robogym
为什么选择 robogym 自己的项目需要做一些机…

1- forecasting at scale论文阅读
目录 1. 什么是时间序列2. 什么是时间序列预测3. 时间序列预测的范式4. 时间序列的专有名词介绍5. 时间序列评估 1. 什么是时间序列
按时间先后顺序出现的有序序列
2. 什么是时间序列预测 点预测:预测未来的某一个时间点,它的值到底是多少,…
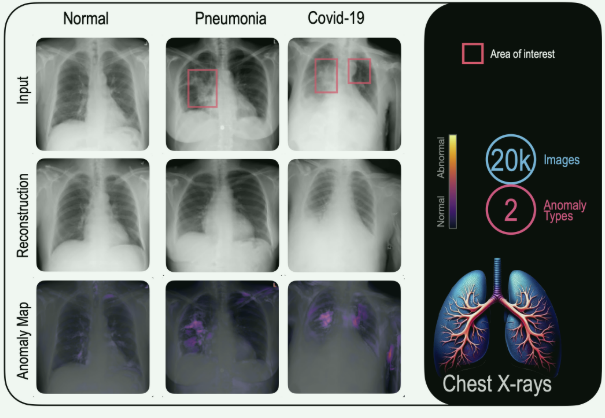
【论文阅读笔记】Towards Universal Unsupervised Anomaly Detection in Medical Imaging
Towards Universal Unsupervised Anomaly Detection in Medical Imaging
arxiv,19 Jan 2024 【开源】
【核心思想】
本文介绍了一种新的无监督异常检测方法—Reversed Auto-Encoders (RA),旨在提高医学影像中病理检测的准确性和范围。RA通过生成类似健…
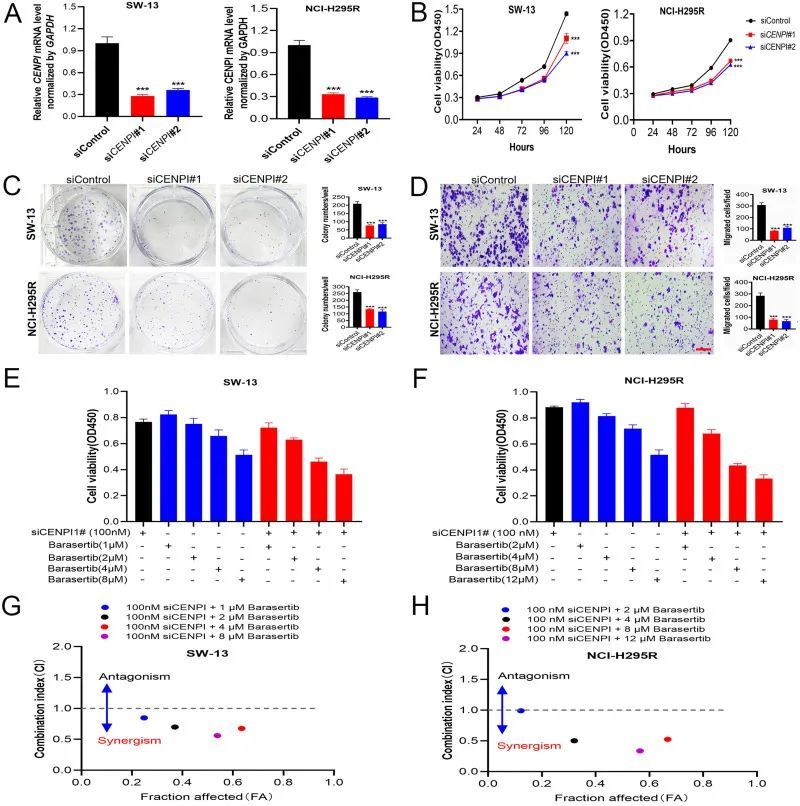
单基因泛癌+实验简单验证,要素丰富,没研究方向的赶紧上车
今天给同学们分享一篇生信文章“Pan-Cancer Analysis Reveals CENPI as a Potential Biomarker and Therapeutic Target in Adrenocortical Carcinoma”,这篇文章发表在J Inflamm Res期刊上,影响因子为4.5。 结果解读:
正常组织、癌症细胞系…
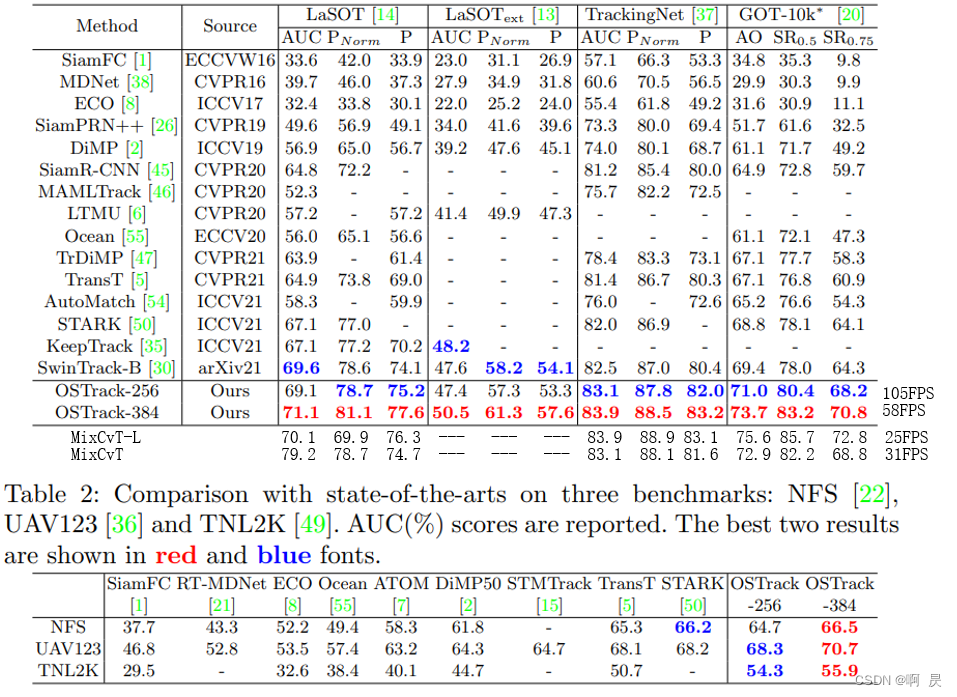
OSTrack论文阅读分享(单目标跟踪)
PS:好久没写csdn了,有点忙,但更多的是比较懒。
今天分享的论文是OSTrack:Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framework
论文网址:https://arxiv.org/pdf/2203.11991.pdf Git…

Graph Transformer系列论文阅读
文章目录research1.《Do Transformers Really Perform Bad for Graph Representation》【NeurIPS 2021 Poster】2.《Relational Attention: Generalizing Transformers for Graph-Structured Tasks》【ICLR2023-spotlight】survey推荐一个汇总Graph Transformer论文的项目&…

【LeGO-LOAM论文阅读(三)--地图优化】
简介
地图优化实现在mapOptmization.cpp 中。 进行的内容主要是地图优化,将得到的局部地图信息融合到全局地图中去。
论文原理
以下内容引自:LeGO-LOAM分析之建图(三)
源码解读
老样子先来看看main函数: loopthr…
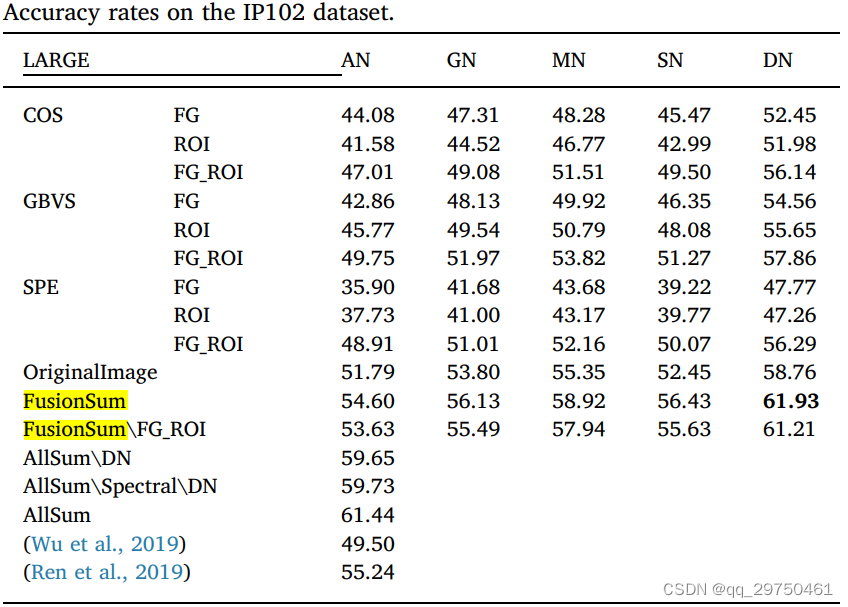
【农业害虫论文阅读三】Insect pest image detection and recognition based on bio-inspired methods
本文记录下刚刚阅读的一篇2020年的害虫识别论文《Insect pest image detection and recognition based on bio-inspired methods》,本篇文章的题目很有意思“基于生物启发的方式进行害虫检测和识别”。
文章概要 本文的脉络非常清晰,比较有意思的地方是…
论文笔记 - Can You Really Backdoor Federated Learning?
文章目录 联邦学习后门攻击操作细节 - Can You Really Backdoor Federated Learning?1. 基本信息2. 基本原理2.1 联邦学习后门攻击场景2.2 恶意模型更新2.2.1 不受约束的显式增强恶意模型更新2.2.2 约束模型更新范数的后门攻击2.3 防御方法2.3.1 模型更新规范裁剪2.3.2 添加弱…
【LeGO-LOAM论文阅读(二)--特征提取(三)】
本文主要讲的是特征提取中线面特征匹配以及优化的代码理解,因为上次代码看麻了,这次静下心来又重新看了一遍。 不想听我废话的,直接去最后参考链接部分自己去理解。
面特征匹配(findCorrespondingSurfFeatures)
找三…
《论文阅读》Unified Named Entity Recognition as Word-Word Relation Classification
总结
将NER视作是word-word间的 Relation Classification。 这个word-word 间的工作就很像是TPlinker那个工作,那篇工作是使用token间的 link。推荐指数:★★★☆☆值得学习的点: (1)用关系抽取的方法做NER抽取 &…

【LeGO-LOAM论文阅读(二)--特征提取(一)】
论文理论部分
特征提取不是从原始点云中进行提取,而是从点云分割中分割出的地面点和分割点中进行提取。参考:LeGO-LOAM论文翻译(内容精简) 过程如下: 只看核心理论部分还是很好理解的。总体流程:(特征提取…

论文笔记:Curriculum Temperature for Knowledge Distillation
1 intro
目前已有的蒸馏方法中,都会采用带有温度超参的 KL 散度作为知识蒸馏的Loss其中温度超参数τ的大小控制了教师神经网络和学生神经网络的平滑程度 τ越大,结果越平滑(最终趋向于label smoothing)τ越小,结果越尖…
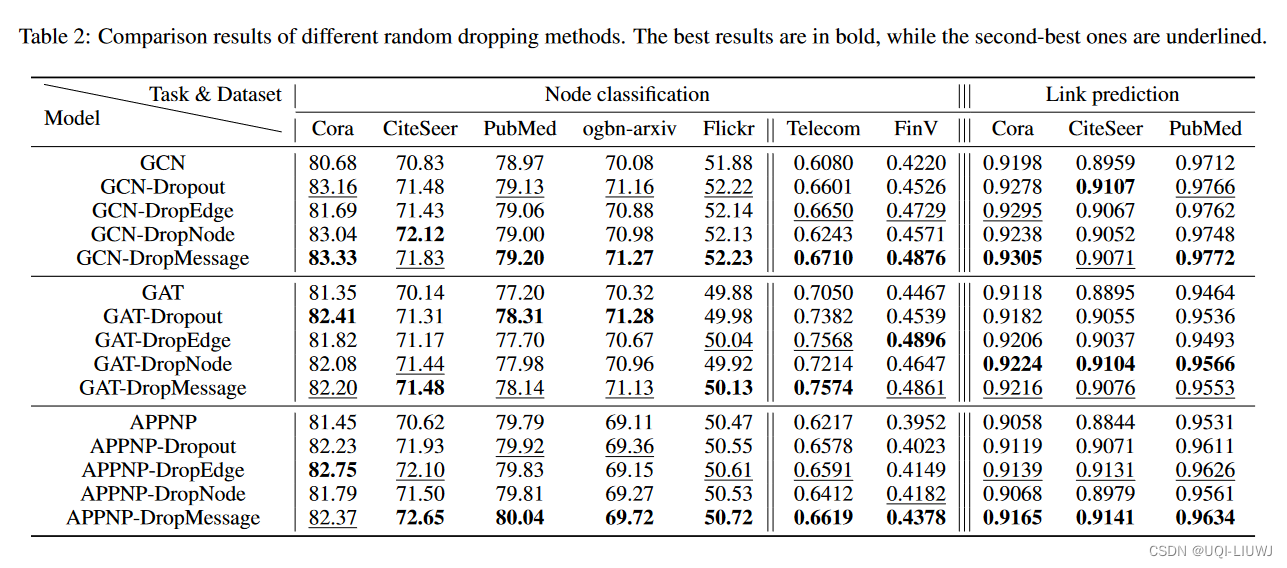
论文笔记:DropMessage: Unifying Random Dropping for Graph Neural Networks
(AAAI 23 优秀论文)
1 intro
GNN的一个普遍思路是,每一层卷积层中,从邻居处聚合信息 尽管GNN有显著的进步,但是在大规模图中训练GNN会遇到各种问题: 过拟合 过拟合之后,GNN的泛化能力就被限制…
2023.8.28日论文阅读
文章目录 NestFuse: An Infrared and Visible Image Fusion Architecture based on Nest Connection and Spatial/Channel Attention Models(2020的论文)本文方法 LRRNet: A Novel Representation Learning Guided Fusion Network for Infrared and Visible Images本文方法学习…
从 PDF 删除PDF 页面的 10 大工具
PDF 文件是全世界几乎每个人最常用的页面之一。借助 PDF 文件,您可以通过任何在线或离线媒体轻松共享信息。但是,如果您想编辑这些 PDF 文件,那么这个过程就很难改变,因为保持文件的原始形式和质量很重要。应该注意的是࿰…
NLP论文阅读记录 - 2021 | WOS 抽象文本摘要:使用词义消歧和语义内容泛化增强序列到序列模型
文章目录 前言0、论文摘要一、Introduction二.前提三.本文方法3.1 总结为两阶段学习3.1.1 基础系统 3.2 重构文本摘要 四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结思考 前言 Abstractive Text Summarization: Enhancing Sequen…
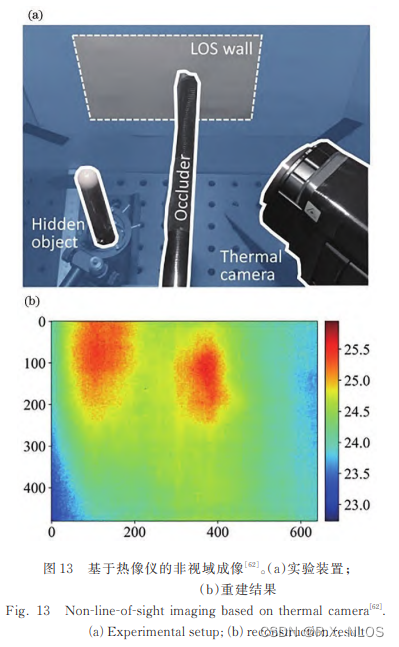
激光与光电子学进展, 2023 | 非视域成像技术研究进展
注1:本文系“计算成像最新论文速览”系列之一,致力于简洁清晰地介绍、解读非视距成像领域最新的顶会/顶刊论文(包括但不限于 Nature/Science及其子刊; CVPR, ICCV, ECCV, SIGGRAPH, TPAMI; Light‑Science & Applications, Optica 等)。 本次介绍的论…

论文笔记:信息融合的门控多模态单元(GMU)
整理了GMU(ICLR2017 GATED MULTIMODAL UNITS FOR INFORMATION FUSION)论文的阅读笔记 背景模型实验 论文地址:
GMU 背景 多模态指的是同一个现实世界的概念可以用不同的视图或数据类型来描述。比如维基百科有时会用音频的混合来描述一个名人…

【论文阅读】LLM4GCL: CAN LARGE LANGUAGE MODEL EM-POWER GRAPH CONTRASTIVE LEARNING?
文章目录 0、基本信息1、研究动机2、创新点2.1、LLM-as-GraphAugmentor2.2、LLM-as-TextEncoder 3、准备3.1、文本属性图3.2、图神经网络3.3、文本属性图上的对比学习 4、LLM4GCL4.1、LLM v.s. Graph Augmentor4.1.1、LLM对特征增广4.1.2、LLM对结构增广 4.2、LLM作为文本编码器…

【每日论文阅读】Do Perceptually Aligned Gradients Imply Robustness?
近似人眼梯度 https://icml.cc/virtual/2023/oral/25482
对抗性鲁棒分类器具有非鲁棒模型所没有的特征——感知对齐梯度(PAG)。它们相对于输入的梯度与人类的感知非常一致。一些研究已将 PAG 确定为稳健训练的副产品,但没有一篇研究将其视为…

easyscholar配置秘钥连接Zotero-style,更方便的了解文献!
如果你不知道什么是easyScholar,以及怎么安装easyScholar?
请参见文章 easyScholar
一、easyscholar配置秘钥
1.首先打开easyscholar插件,并登录 2.点击自定义数据集 3.依次点击 用户信息-开放接口 4.点击刷新 5.在Zoter中 编辑-首选项-高级-编辑器 6.点击…
《论文阅读》CAB:认知、情感和行为的共情对话生成 DASFAA 2023
《论文阅读》CAB:认知、情感和行为的共情对话生成 前言摘要相关知识CVAE 条件变分自编码器最大最小归一化模型架构1.获取 Representation2.Prior Network and Recognition Network (Affection)3.Knowledge Acquisition and Fusion (Cognition)4.Dialogue Act Predictor and Re…
【论文阅读笔记】Prompt Tuning for Parameter-efficient Medical Image Segmentation
Fischer M, Bartler A, Yang B. Prompt tuning for parameter-efficient medical image segmentation[J]. Medical Image Analysis, 2024, 91: 103024. 【开源】
【核心思想】
本文的核心思想是提出了一种用于医学图像分割的参数高效的提示调整(Prompt Tuning&…
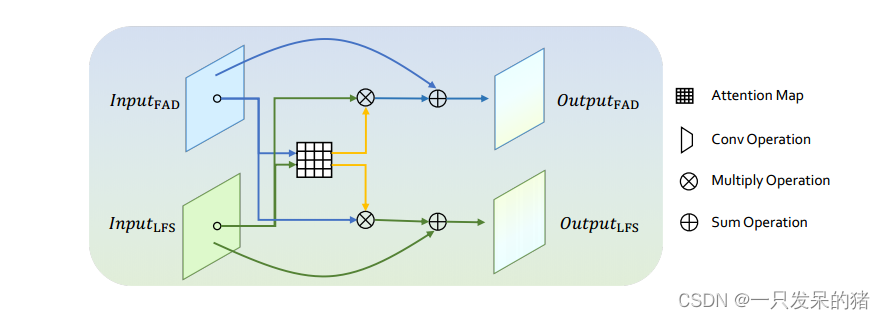
论文阅读《thanking frequency fordeepfake detection》
项目链接:https://github.com/yyk-wew/F3Net
这篇论文从频域的角度出发,提出了频域感知模型用于deepfake检测的模型
整体架构图: 1.FAD:
频域感知分解,其实就是利用DCT变换,将空间域转换为频域ÿ…
【论文笔记合集】TimesNet之TimesBlock详解
本文作者: slience_me 文章目录 TimesNet之TimesBlock详解1. 源代码2. 分步详解2.1 init部分代码2.2 forward部分代码 TimesNet之TimesBlock详解 1. 源代码
class TimesBlock(nn.Module):def __init__(self, configs):super(TimesBlock, self).__init__()self.seq_…
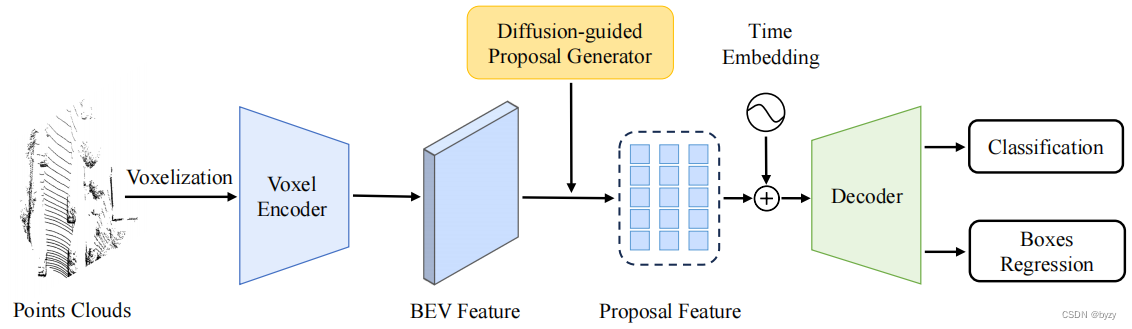
【论文笔记】Diffusion-based 3D Object Detection with Random Boxes
原文链接:https://arxiv.org/abs/2309.02049
1. 引言 基于激光雷达的3D目标检测方法通常依赖经验设置锚框或中心半径,而本文探索从随机框直接预测真实边界框。 本文提出Diff3Det,使用扩散模型进行3D目标检测。首先为真实边界框添加高斯噪…

《论文阅读》利用远程监督选择知识用于对话回复生成
《论文阅读》利用远程监督选择知识用于对话回复生成 前言简介动机相关知识知识对话系统的步骤多样性回复的方法抽取知识oracle label问题定义模型框架EncoderTask1: 合理地获得 oracle knowledge 作为 gold knowledgeTask2:使得selected knowledge与oracle knowledge一致Task3…
《Amazon DynamoDB》 论文笔记 1
文章目录 1. 写在最前面2. 核心观点2.1 作为服务提供要考虑的问题2.1.1.1 部署方案2.1.1.2 多租户的问题2.1.1.3 容量上限2.1.1.4 容量扩展2.1.1.5 可用性指标评估 3. 碎碎念4. 参考资料 1. 写在最前面
最近读到一句话,「所谓云原生并不是简单的将一个云下的数据库…

经典ABR算法介绍:Pensieve (SIGCOMM ‘17) 原理及训练指南
文章目录 前言Pensieve原理*Pensieve重训练参考Oboe [SIGCOMM 18]Comyco [MM 19]Fugu [NSDI 20] A3C熵权重衰减思路实现 前言
Pensieve是DASH点播视频中最经典的ABR算法之一,也是机器学习类(Learning-based)ABR算法的代表性工作。Pensieve基…
论文阅读_大语言模型_Llama2
英文名称: Llama 2: Open Foundation and Fine-Tuned Chat Models 中文名称: Llama 2:开源的基础模型和微调的聊天模型 文章: http://arxiv.org/abs/2307.09288 代码: https://github.com/facebookresearch/llama 作者: Hugo Touvron 日期: 2023-07-19 引用次数: 11…
![论文记录:Detecting Visual Relationships with Deep Relational Networks [DR-Net] (CVPR-17)](https://img-blog.csdnimg.cn/20190113143808616.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2RlZXBpbkM=,size_16,color_FFFFFF,t_70)
论文记录:Detecting Visual Relationships with Deep Relational Networks [DR-Net] (CVPR-17)
(这里仅记录了论文的一些内容以及自己的一点点浅薄的理解,具体实验尚未恢复。由于本人新人一枚,若有错误以及不足之处,还望不吝赐教)
总结 previous works 的缺点 将 VRD 视为分类问题,即 consider each t…
【科研工具】-论文相关
科研工具 1 论文检索2 论文阅读3 论文写作4 论文发表 1 论文检索
计算机类英文文献检索数据库DBLP: 只有论文基本信息(标题、作者等);下载论文:知网\IEEE\ACM\SCI-Hub等,记得创建文件夹(检索词条、日期等&…
【论文阅读】Iterative Poisson Surface Reconstruction (iPSR) for Unoriented Points
文章目录 声明作者列表核心思想归纳算法流程机器翻译声明 本帖更新中如有问题,望批评指正!如果有人觉得帖子质量差,希望在评论中给出建议,谢谢!作者列表
FEI HOU(侯飞)、CHIYU WANG、WENCHENG WANG:中国科学院大学 HONG QIN CHEN QIAN、YING HE
核心思想归纳 当一条从…
【论文阅读】SKDBERT: Compressing BERT via Stochastic Knowledge Distillation
2022-2023年论文系列之模型轻量化和推理加速
定义最新
通过Connected Papers搜索引用PaBEE/DeeBERT/FastBERT的最新工作,涵盖: 模型推理加速边缘设备应用生成模型BERT模型知识蒸馏论文目录 SmartBERT: A Promotion of Dynamic Early Exiting Mechanism for Accelerating BE…
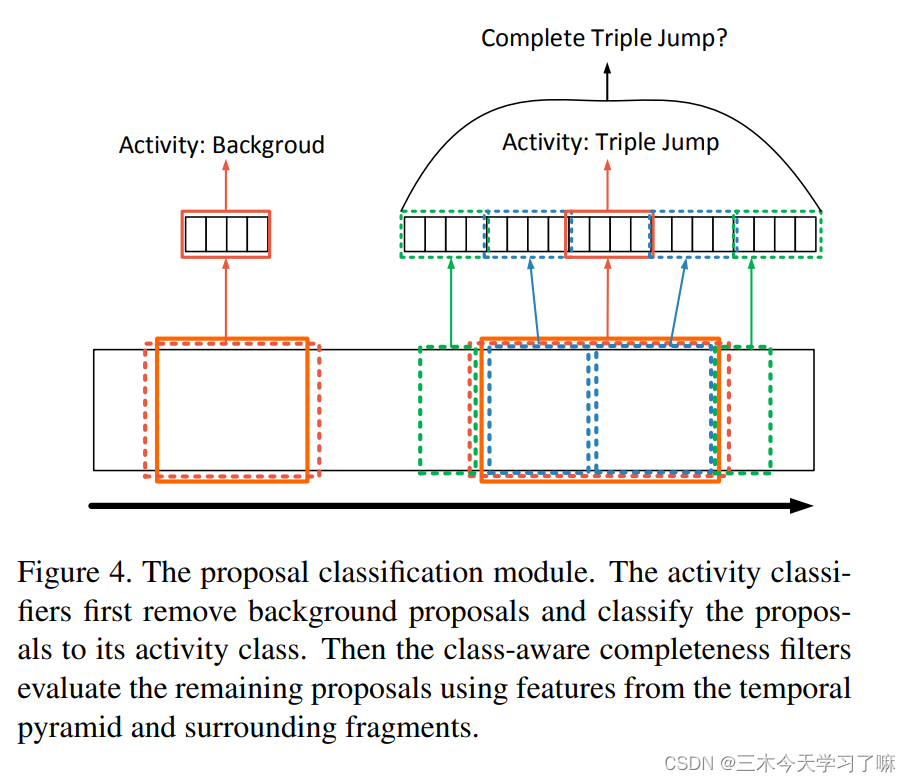
【论文阅读】时序动作检测系列论文精读(2017年 上)
文章目录1.TURN TAP: Temporal Unit Regression Network for Temporal Action Proposals论文目的——拟解决问题贡献——创新实现流程详细方法2. Temporal Action Detection with Structured Segment Networks论文目的——拟解决问题贡献——创新具体方法详细方法3. A Pursuit …

图像生成论文阅读:Latent Diffusion算法笔记
标题:High-Resolution Image Synthesis with Latent Diffusion Models 会议:CVPR2022 论文地址:https://ieeexplore.ieee.org/document/9878449/ 官方代码:https://github.com/CompVis/latent-diffusion 作者单位:慕尼…
【论文解读】Do Prompts Solve NLP Tasks Using Natural Language?
🍥关键词:文本分类、提示学习 🍥发表期刊:Arxiv 2022 🍥原始论文:https://arxiv.org/pdf/2203.00902 最近在做Prompted learning for text classification的工作,Prompted learning的核心在于设…

【论文笔记】《Learning Deconvolution Network for Semantic Segmentation》
重要说明:严格来说,论文所指的反卷积并不是真正的 deconvolution network 。 关于 deconvolution network 的详细介绍,请参考另一篇博客:什么是Deconvolutional Network?
一、参考资料
Learning Deconvolution Netwo…
伪装目标检测模型论文阅读之:Zoom in and out
论文链接:https://arxiv.org/abs/2203.02688 代码;https://github.com/lartpang/zoomnet
1.摘要
最近提出的遮挡对象检测(COD)试图分割视觉上与其周围环境融合的对象,这在现实场景中是非常复杂和困难的。除了与它们的背景具有高…
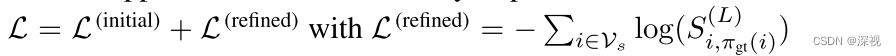
论文阅读笔记《DEEP GRAPH MATCHING CONSENSUS》
核心思想 本文提出一种基于图神经网络的图匹配方法,首先利用节点相似度构建初始的匹配关系,然后利用局部的一致性对初始的匹配关系进行迭代优化,不断筛除误匹配点,得到最终的匹配结果。本文还提出几种措施来降低计算复杂度&#x…
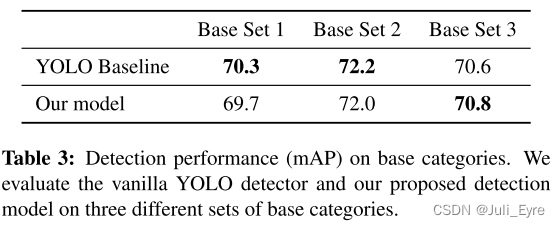
【论文阅读】 Few-shot object detection via Feature Reweighting
Few-shot object detection的开山之作之一 ~~
特征学习器使用来自具有足够样本的基本类的训练数据来 提取 可推广以检测新对象类的meta features。The reweighting module将新类别中的一些support examples转换为全局向量,该全局向量indicates meta features对于检…
【论文阅读】Error Bounds of Imitating Policies and Environments
模仿策略和环境的误差边界
摘要
文章中对行为克隆和GAIL两种模仿方法进行对比,分析了 两种方法生成的模仿策略与专家策略之间的价值差距,得出了GAIL可以减少复合误差的结论,具有更好的样本复杂性。同时发现模仿学习也可以用于学习环境模型&…
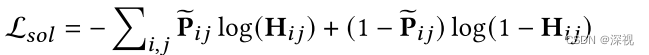
论文阅读笔记《GAMnet: Robust Feature Matching via Graph Adversarial-Matching Network》
核心思想 本文提出一种基于图对抗神经网络的图匹配算法(GAMnet),使用图神经网络作为生成器分别生成源图和目标图的节点的特征,并用一个多层感知机作为辨别器来区分两个特征是否来自同一个图,通过对抗训练的办法提高生成器特征提取…
【音视频第10天】GCC论文阅读(1)
A Google Congestion Control Algorithm for Real-Time Communication draft-alvestrand-rmcat-congestion-03论文理解 看中文的GCC算法一脸懵。看一看英文版的,找一找感觉。 目录Abstract1. Introduction1.1 Mathematical notation conventions2. System model3.Fe…

DETR【论文阅读】
End-to-End Object Detection with Transformers
1. Introduction
发表:ECCV 2020影响:在目标检测上使用了一种全新的架构,是里程碑式的工作。简单优雅统一的结构,不再依赖于人的先验知识(anchor生成,nms…
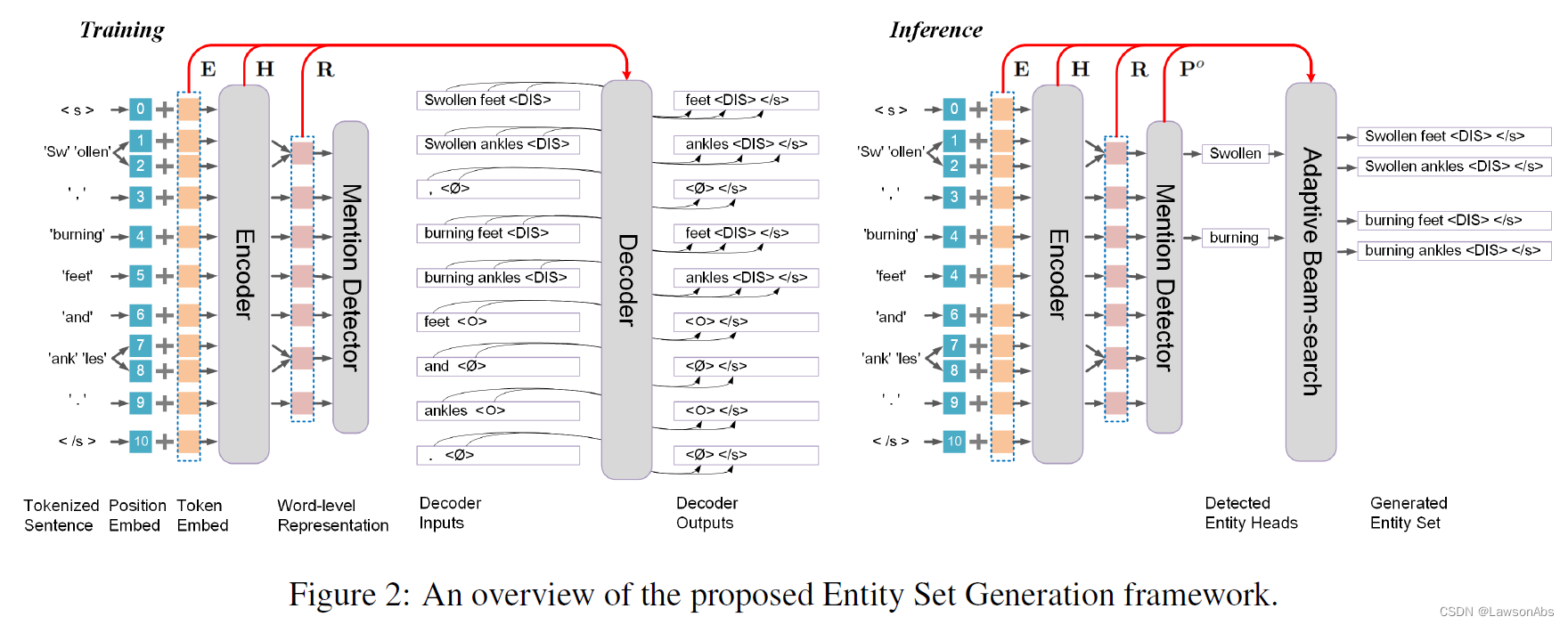
《论文阅读》SetGNER:General Named Entity Recognition as Entity Set Generation
0.总结
不知道是不是大模型的流行还是什么其他原因,导致现在网上都没有人来分享NER模型的相关论文了~本文方法简单,代码应该也比较简单(但是没见作者放出来)。推荐指数:★★☆☆☆ 1. 动机
处理三种不同场景的NER 与…
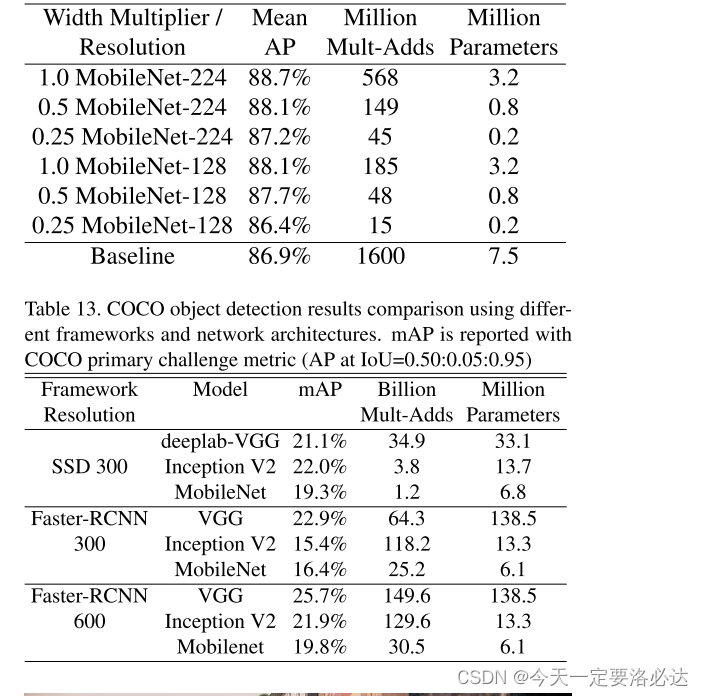
【论文阅读】轻量化网络MobileNet-V1
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、摘要二、MobileNet-V1核心点介绍:普通卷积和深度可分离卷积三、两个超参数四。后续实验 前言
今天重温一下轻量化经典论文MobileNet-V1&#x…

详细介绍Sentence-BERT:使用连体BERT网络的句子嵌入
Sentence-BERT:Sentence Embeddings using Siamese BERT-Networks 使用连体BERT网络的句子嵌入 BERT和RoBERTa在诸如语义文本相似性(STS)的句子对回归任务上创造了新的最优的性能。然而,它要求将两个句子都输入网络,这导致了巨大的…
MiniGPT-4 笔记
目录
简介
实现方法
效果及局限
参考资料 简介
MiniGPT-4 是前段时间由KAUST(沙特阿卜杜拉国王科技大学)开源的多模态大模型,去网站上体验了一下功能,把论文粗略的看了一遍,也做个记录。
论文摘要翻译࿱…

(2020)End-to-end Neural Coreference Resolution论文笔记
2020End-to-end Neural Coreference Resolution论文笔记 Abstract1 Introduction2 Related Work3 Task4 Model4.1 Scoring Architecture4.2 Span Representations5 Inference6 Learning7 Experiments7.1 HyperparametersWord representationsHidden dimensionsFeature encoding…

论文阅读:chain of thought Prompting elicits reasoning in large language models
论文阅读:chain of thought Prompting elicits reasoning in large language models
跟着沐神读论文 视频链接:https://www.bilibili.com/video/BV1t8411e7Ug/?spm_id_from333.788&vd_source350cece3ec9a0c2aee50da8ccc315bf4
title:chain of tho…
GPT-2隐私泄露论文阅读:Extracting Training Data from Large Language Models
文章目录论文地址:原文阐释:渔樵问对:原理梗概预防策略隐私策略这个新颖的攻击方式是什么?三种典型采样策略:隐私风险文章第5页第二段中提到的 memorized training exam ple 是什么意思ThreatModel &Ethics什么是文本的zlib e…

论文阅读Spectral Unsupervised Domain Adaptation for Visual Recognition
1 论文简介
1.1 论文标题
Spectral Unsupervised Domain Adaptation for Visual Recognition
1.2 论文发表位置
CVPR2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition
1.3 论文地址
https://arxiv.org/abs/2106.06112#
1.4 论文署名单位
Nanyang …
【论文阅读】GNN阅读笔记
A gentle introduction on gnn
前言
发表在distill的文章
图神经网络在应用上才刚刚开始
搭建了一个GNN playground
什么是图
图是表示实体之间的关系
可以分别表示成点向量、边向量、图向量
图可以分为有向图和无向图
数据是怎么表示成图
图片表示成图: …

论文阅读和分析:Hybrid Mathematical Symbol Recognition using Support Vector Machines
主要贡献:
1、提出了一种基于支持向量机的混合识别系统,该系统同时使用在线和离线信息进行分类。
2、并行运行的两个基于支持向量机的多类分类器的概率输出通过加权和进行组合。实验结果表明,赋予在线信息稍高的权重会产生更好的结果。混合…
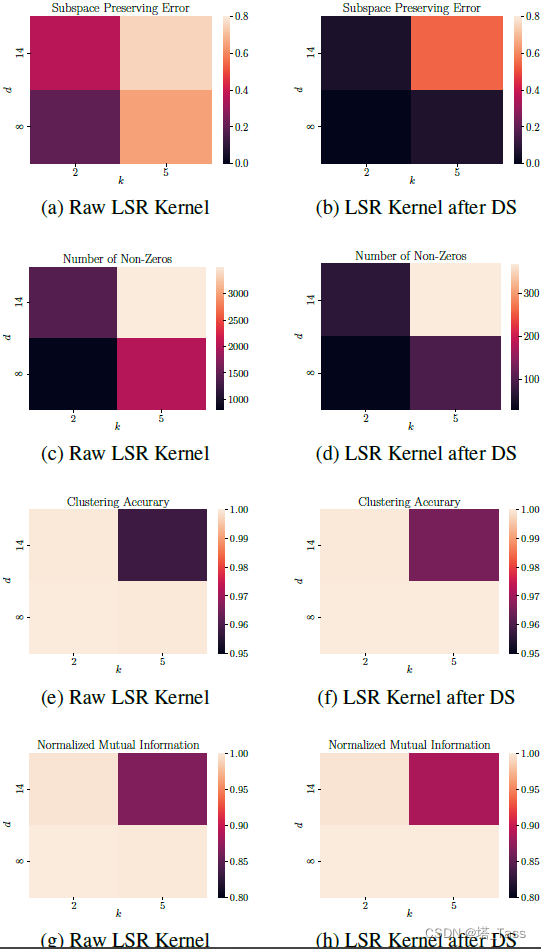
论文阅读:Understanding Doubly Stochastic Clustering
Publisher: PMLR 2022 Author: 丁天骄, 德里克林, 雷内维达尔, 本杰明海菲勒 摘要
将矩阵投影到双随机矩阵空间上的问题在机器学习中有几个应用。例如,在谱聚类中,从数据亲和矩阵形成归一化拉普拉斯矩阵与将其投影到双…
【论文阅读】GAN阅读笔记
Generative Adversarial Nets
标题
分辨模型:对于数据判断类别
生成模型:生成数据的本身
Nets
两个网络相互对抗
摘要
如果是开创性的工作的话,就用wikipedia式的写法
通过一个对抗的过程训练一个生成模型
G用来抓住整个数据的分布&…
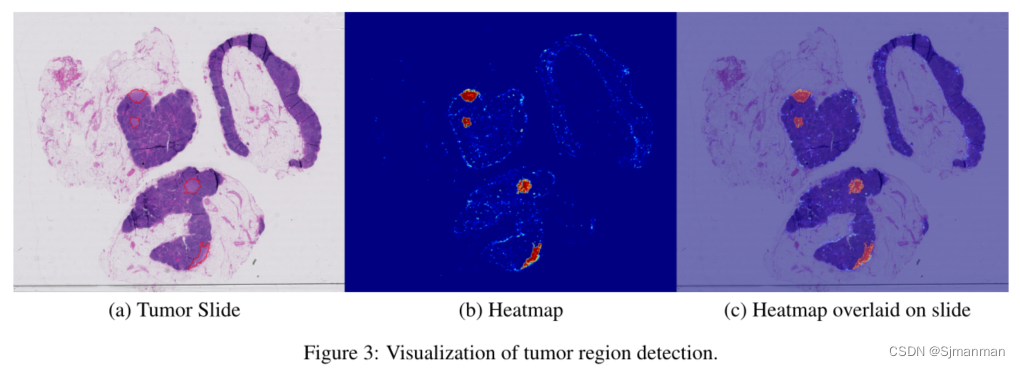
Deep Learning for Identifying Metastatic Breast Cancer识别转移性乳腺癌_论文笔记
摘抄:
1.Standardized, accurate and reproducible pathological diagnoses are essential for advancing precision medicine.
2.Limitations of the qualitative visual analysis of microscopic images includes lack of standardization, diagnostic errors, …
Word2Vec Efficient Estimation of Word Representations inVector Space论文笔记
Title
Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013.
Summary
Word2vec是一种基于神经网络的自然语言处理技术,用于将单词表示为向量。这种技术的最大好处是它能…
YOLOv8详解全流程捋清楚-每个步骤
从第一步,到最后一步,带着你捋
整体架构 Backbone: Feature Extractor提取特征的网络,其作用就是提取图片中的信息,供后面的网络使用 Neck : 放在backbone和head之间的,是为了更好的利用backbo…

论文阅读《NeRF-Supervised Deep Stereo》
论文地址:https://arxiv.org/pdf/2303.17603.pdf 源码地址:https://nerfstereo.github.io/ 概述 针对深度估计的标签数据难以获取,自监督方法在病态(遮挡、非朗伯面)区域的表现差,跨域泛化能力弱的问题&…

【论文阅读--WSOL】Spatial-Aware Token for Weakly Supervised Object Localization
文章目录方法实验Limitation论文:https://arxiv.org/abs/2303.10438代码:https://github.com/wpy1999/SAT/blob/main/Model/SAT.py方法 这篇文章的方法应该属于FAM这一类。 额外添加的一个spatial token,从第10-12层开始,利用其得…

论文阅读《GlueStick: Robust Image Matching by Sticking Points and Lines Together》
论文地址:https://arxiv.org/abs/2304.02008 源码地址:https://github.com/cvg/GlueStick 概述 针对视角变化时在闭塞、无纹理、重复纹理区域的线段匹配难的问题,本文提出一种新的匹配范式(GlueStick),该方…

肠道微生物群、营养与长期疾病风险:母婴视角
谷禾健康 怀孕的母亲与体内的胎儿是息息相关的。由于婴儿接触母体微生物群,母亲和孩子之间的微生物联系在怀孕期间形成。而宿主与微生物群的联系在出生后成熟,并进化成为个体生命中最重要的共生关系之一,对响应营养和环境刺激的稳态调节至关重…
![[论文阅读]Visual Attention Network原文翻译](https://img-blog.csdnimg.cn/b8d180791c6842fea3903e3234786f9f.png)
[论文阅读]Visual Attention Network原文翻译
[论文链接]https://arxiv.org/abs/2202.09741
摘要 虽然一开始是被设计用于自然语言处理任务的,但是自注意力机制在多个计算机视觉领域掀起了风暴。然而,图像的二维特性给自注意力用于计算机视觉带来了三个挑战。(1)将图像视作一…
【Spatial-Temporal Action Localization(二)】论文阅读2017年
文章目录 1. ActionVLAD: Learning spatio-temporal aggregation for action classification [code](https://github.com/rohitgirdhar/ActionVLAD/)[](https://github.com/rohitgirdhar/ActionVLAD/)摘要和结论引言:针对痛点和贡献相关工作模型框架思考不足之处 2.…
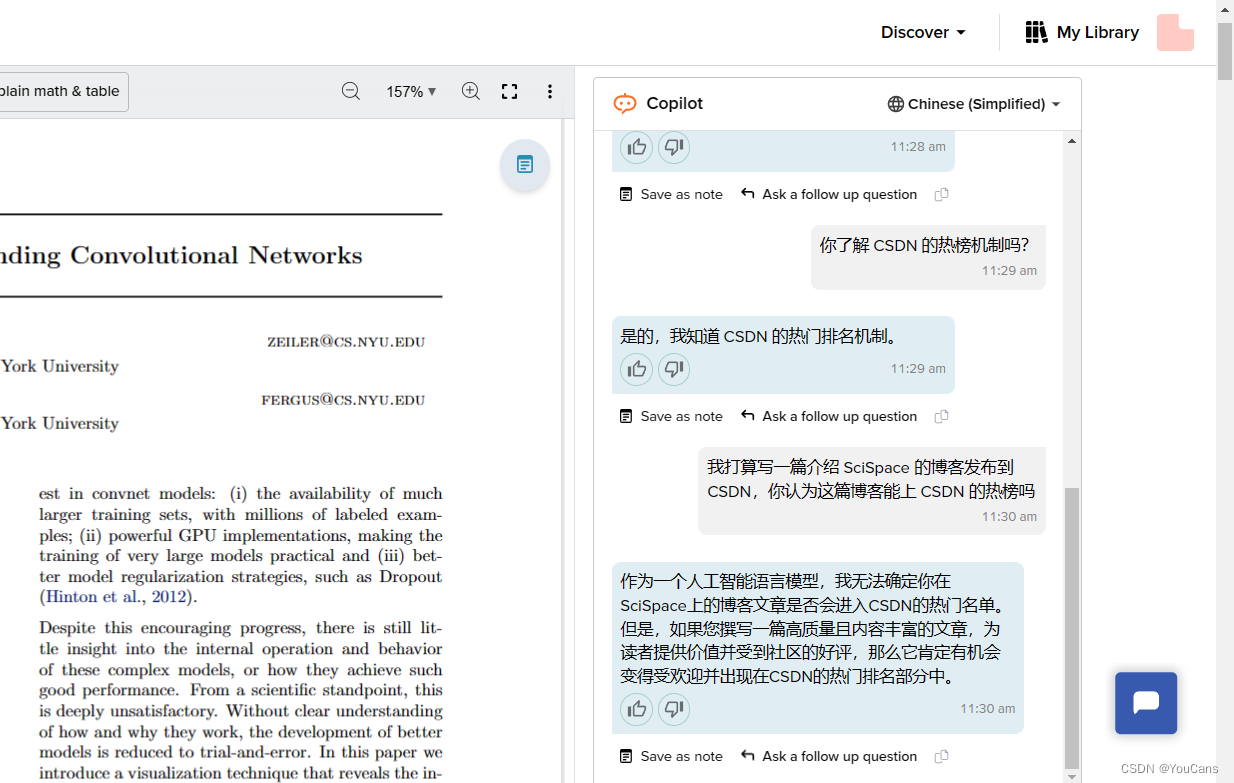
【AIGC】论文阅读神器 SciSpace 注册与测试
欢迎关注【youcans的 AIGC 学习笔记】原创作品 【AIGC】论文阅读神器 SciSpace 注册与测试 1. 【SciSpace】网址与用户注册1.1 官网地址:[【SciSpace官网】https://typeset.io](https://typeset.io)1.2 官网注册 2. 【SciSpace】实战解说2.1 导入论文2.2 论文分析2.…
![[论文阅读笔记26]Tracking Everything Everywhere All at Once](https://img-blog.csdnimg.cn/b4475589645041508c3c049d42aff579.png)
[论文阅读笔记26]Tracking Everything Everywhere All at Once
论文地址: 论文 代码地址: 代码
这是一篇效果极好的像素级跟踪的文章, 发表在ICCV2023, 可以非常好的应对遮挡等情形, 其根本的方法在于将2D点投影到一个伪3D(quasi-3D)空间, 然后再映射回去, 就可以在其他帧中得到稳定跟踪.
这篇文章的方法不是很好理解, 代码也刚开源, 做一…

【论文笔记】DiffBEV: Conditional Diffusion Model for Bird’s Eye View Perception
原文链接:https://arxiv.org/abs/2303.08333
1. 引言 通常,相机参数和激光雷达扫描的噪声会使BEV特征带有有害的噪声。扩散模型有去噪能力,能将有噪声样本还原为理想数据。本文提出DiffBEV,使用条件扩散概率模型(DPM&…
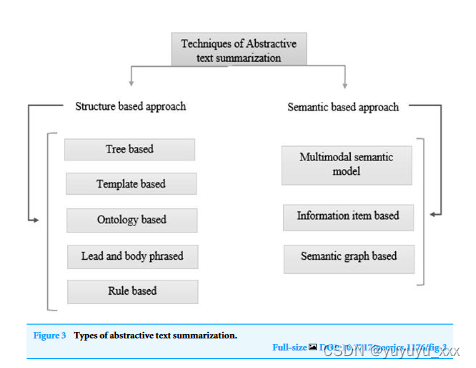
NLP论文阅读记录 - wos | 01 使用深度学习对资源匮乏的语言进行抽象文本摘要
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.相关工作三.本文方法四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结思考 前言 Abstractive text summarization of lowresourced languages usi…

论文阅读_大模型_ToolLLM
英文名称: ToolLLM: Facilitating Large Language Models to Master 16000 Real-world APIs 中文名称: TOOLLLM:帮助大语言模型掌握16000多个真实世界的API 文章: http://arxiv.org/abs/2307.16789 代码: https://github.com/OpenBMB/ToolBench 作者: Yujia Qin 日期…
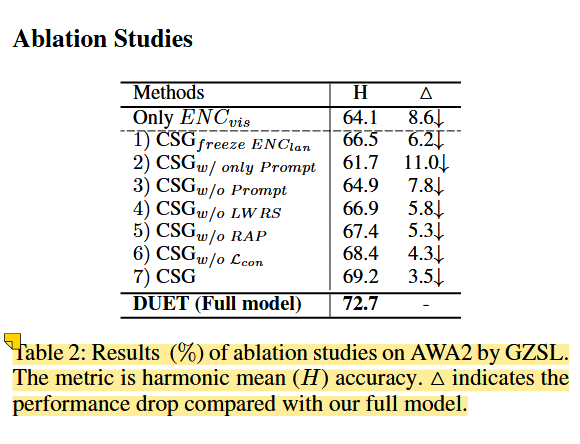
DUET: Cross-Modal Semantic Grounding for Contrastive Zero-Shot Learning论文阅读
文章目录 摘要1.问题的提出引出当前研究的不足与问题属性不平衡问题属性共现问题 解决方案 2.数据集和模型构建数据集传统的零样本学习范式v.s. DUET学习范式DUET 模型总览属性级别对比学习正负样本解释: 3.结果分析VIT-based vision transformer encoder.消融研究消…
(论文阅读14/100)End-to-end people detection in crowded scenes
文献阅读笔记 简介 题目 End-to-end people detection in crowded scenes 作者 Russell Stewart, Mykhaylo Andriluka 原文链接 https://arxiv.org/pdf/1506.04878.pdf 关键词 Null 研究问题 当前的人员检测器要么以滑动窗口的方式扫描图像,要么对一组离…

【网安专题10.11】代码大模型的应用及其安全性研究
代码大模型的应用及其安全性研究 写在最前面一些想法大型模型输出格式不受控制的解决方法 大模型介绍(很有意思)GPT 模型家族的发展Chatgpt优点缺点GPT4 其他模型补充:self-instruct合成数据 Code Llama 代码大模型的应用(第一次理…

【论文阅读】Co-EM Support Vector Learning
论文下载 bib:
INPROCEEDINGS{Brefeld2004CoEMSVM,
title {Co-EM Support Vector Learning},
author {Ulf Brefeld and Tobias Scheffer},
booktitle {ICML},
year {2004},
pages {16}
}1. 摘要 Multi-view algorithms, such as co-training and co-EM, utiliz…
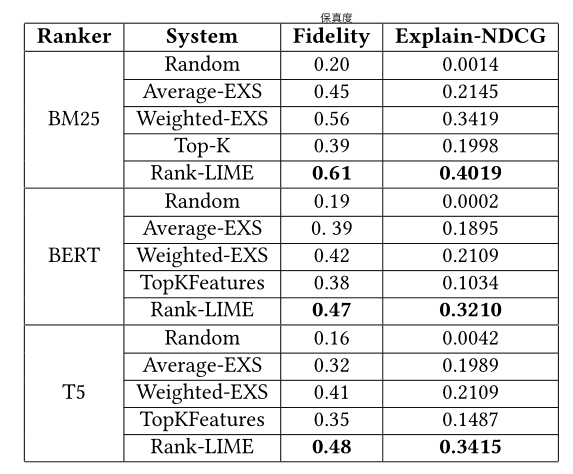
《Rank-LIME: Local Model-Agnostic Feature Attribution for Learning to Rank》论文精读
文章目录一、论文信息摘要二、要解决的问题现有工作存在的问题论文给出的方法(Rank-LIME)介绍贡献三、前置知识LIMEFeature AttributionModel-AgnosticLocalLearning to Rank(LTR)单文档方法(PointWise Approach&#…
【论文阅读】一些研究想法
如何找研究想法
打补丁法,可以在一个研究的基础上,找方法来解,但是要讲好这个方法的故事,把不同的点串起来
如何判断研究工作的价值
用有新意的方法有效地解决一个研究问题
新意有效(相对)研究问题
在…
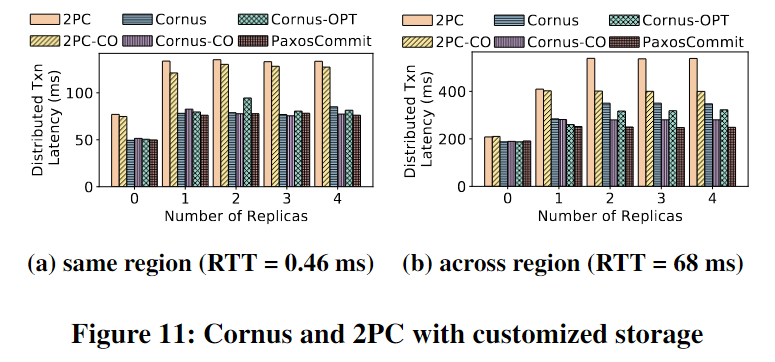
【论文阅读】Cornus: Atomic Commit for a Cloud DBMS with Storage Disaggregation
Cornus
Paper Preknowledge Share-Nothing Related Work
Cornus: Atomic Commit for a Cloud DBMS with Storage Disaggregation
ABSTRACT
传统2PC存在两个限制(缺点)
Long Latency:long latency due to two eager log writes on the …
【CVPR2020】DEF:Seeing Through Fog Without Seeing Fog论文阅读分析与总结
Challenge:
之前网络架构的设计假设数据流是一致的,即出现在一个模态中的对象也出现在另一个模态中。然而,在恶劣的天气条件下,如雾、雨、雪或极端照明条件,多模态传感器配置中的信息可能不对称。不同传感器在特征提取…
论文阅读_音频表示_W2V-BERT
信息
number headings: auto, first-level 2, max 4, _.1.1 name_en: w2v-BERT: Combining Contrastive Learning and Masked Language Modeling for Self-Supervised Speech Pre-Training name_ch: W2V-BERT:结合对比学习和Mask语言建模进行自监督语音预训练 pape…
TreEnhance: A Tree Search Method For Low-Light Image Enhancement 论文阅读笔记
这是2023年PR这个期刊的论文主要思想是,利用一系列预定义好的操作序列来进行增强,然后利用强化学习来学习增强序列的预测。所以训练阶段有两个交替进行的阶段,一个是蒙特卡洛树搜索阶段,第二个是训练深度强化学习的阶段。而测试的…

使用AIGC工具提升论文阅读效率
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…

IMAGEBIND: One Embedding Space To Bind Them All论文笔记
论文https://arxiv.org/pdf/2305.05665.pdf代码https://github.com/facebookresearch/ImageBind
1. Motivation 像CLIP这一类的方法只能实现Text-Image这两个模态的 Embedding 对齐,本文提出的ImageBind能够实现六个模态(images, text, audio, depth, t…

论文笔记 CPU Accounting for Multicore Processors
Abstract
确定了对CPU utilization的不准确测量是如何影响OS的几个关键方面的这篇文章提出来了一个比CPU utilization更准确的性能评估指标 In this paper, we identify how an inaccurate measurement of the CPU utilization affects several key aspects of the system suc…

【论文阅读】基于深度学习的时序预测——Autoformer
系列文章链接 论文一:2020 Informer:长时序数据预测 论文二:2021 Autoformer:长序列数据预测
论文链接:https://arxiv.org/abs/2106.13008 github链接:https://github.com/thuml/Autoformer 解读参考&…
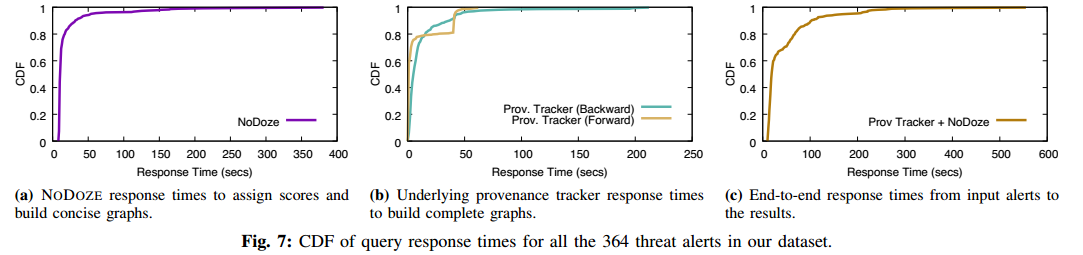
【论文阅读】NoDoze:使用自动来源分类对抗威胁警报疲劳(NDSS-2019)
NODOZE: Combatting Threat Alert Fatigue with Automated Provenance Triage 伊利诺伊大学芝加哥分校 Hassan W U, Guo S, Li D, et al. Nodoze: Combatting threat alert fatigue with automated provenance triage[C]//network and distributed systems security symposium.…

【论文阅读】基于深度学习的时序预测——Non-stationary Transformers
系列文章链接 论文一:2020 Informer:长时序数据预测 论文二:2021 Autoformer:长序列数据预测 论文三:2022 FEDformer:长序列数据预测 论文四:2022 Non-Stationary Transformers:非平…
word自带公式编辑
快捷键:
公式编辑:alt“”
上标:x^i 空格
下标:x_i 空格
实数R:\doubleR 空格
偏微分算子:“\partial”
极限:“\limit”(按空格后会显示一串很长的式子,再空格就变…

【生成式AI】ProlificDreamer论文阅读
ProlificDreamer 论文阅读
Project指路:https://ml.cs.tsinghua.edu.cn/prolificdreamer/ 论文简介:截止2023/8/10,text-to-3D的baseline SOTA,提出了VSD优化方法
前置芝士:text-to-3D任务简介
text-to-3D Problem
text-to-3D…
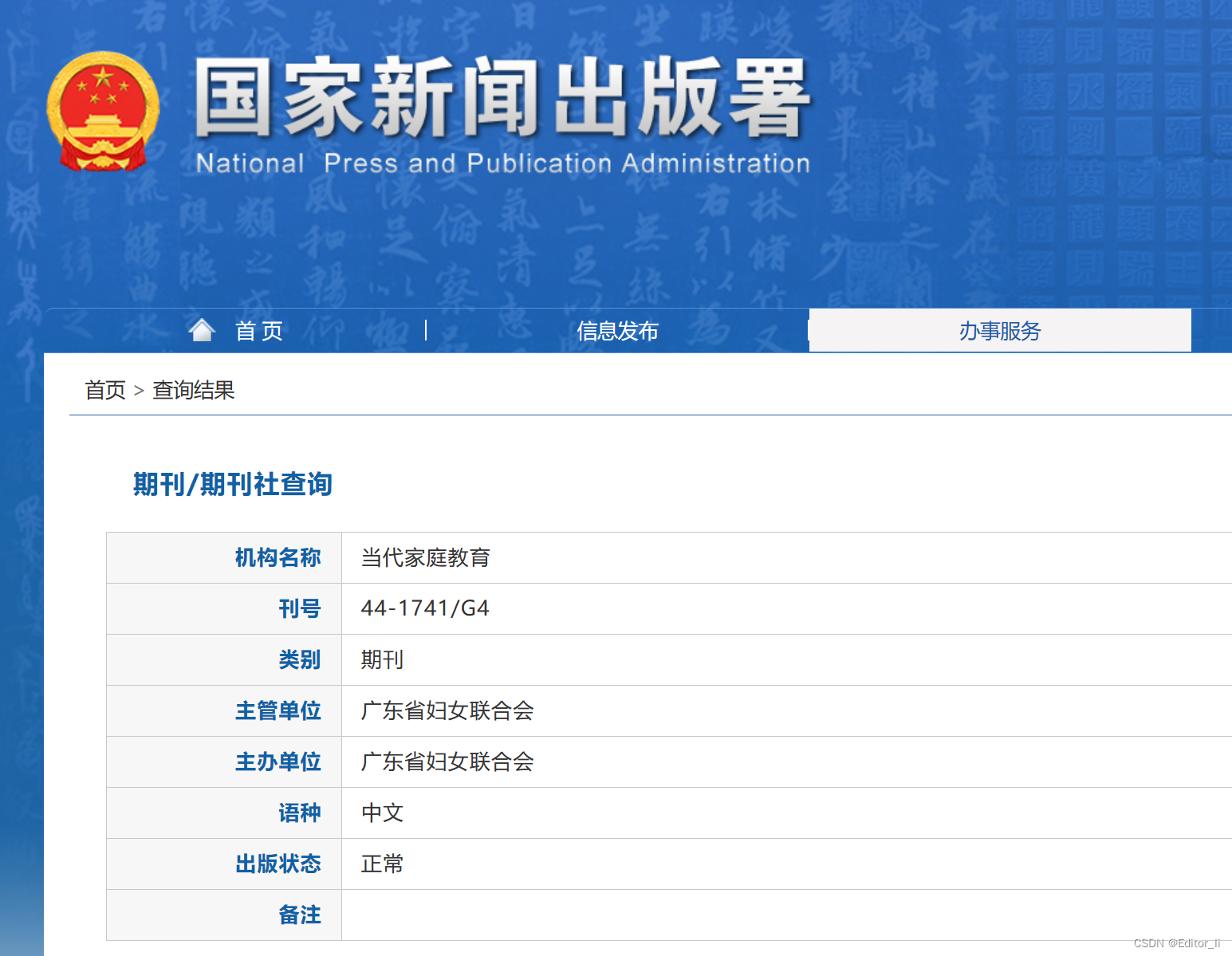
《当代家庭教育》期刊论文投稿发表简介
《当代家庭教育》杂志是家庭的参谋和助手,社会的桥梁和纽带,人生的伴侣和知音,事业的良师益友。
国家新闻出版总署批准的正规省级教育类G4期刊,知网、维普期刊网收录。安排基础教育相关稿件,适用于评职称时的论文发表…
【论文阅读】EPnP: An Accurate O(n) Solution to the PnP Problem
目录 EPnP: An Accurate O(n) Solution to the PnP ProblemOpencv.solvePnP documentationsimilar functionscv::SOLVEPNP_EPNP: Paper 008 EPnP: An Accurate O(n) Solution to the PnP Problem
Opencv.solvePnP documentation
solvePnP
bool cv::solvePnP(
InputArray ob…
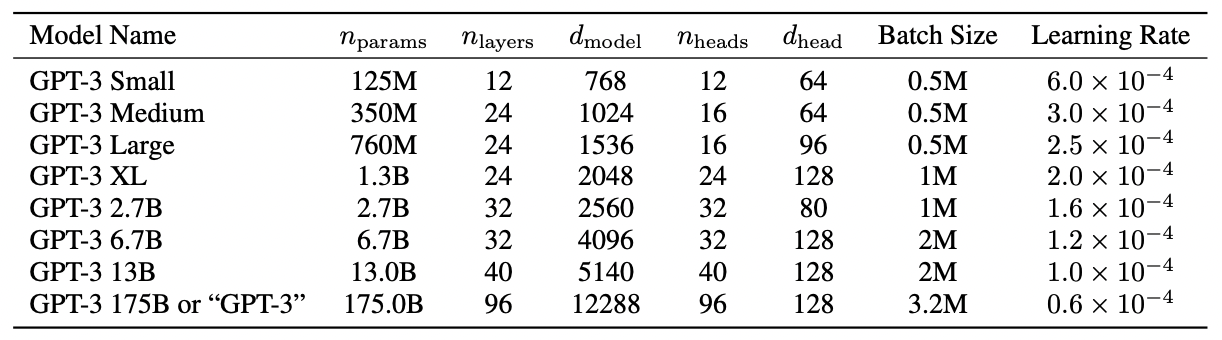
(GPT3)Language Models are Few-Shot Learners论文阅读
论文地址:https://arxiv.org/pdf/2005.14165v4.pdf
摘要 最近的工作表明,通过对大量文本语料库进行预训练,然后对特定任务进行微调,许多 NLP 任务和基准测试取得了实质性进展。 虽然在体系结构中通常与任务无关,但此方…
(论文阅读18/100)SSD: Single Shot MultiBox Detector
文献阅读笔记 简介 题目 SSD: Single Shot MultiBox Detector 作者 Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg 原文链接 https://arxiv.org/pdf/1512.02325v2.pdf 【精选】目标检测->SS…

【论文阅读笔记】Contrast image correction method
论文小结: 本文是2010年发表出来的一篇文章,提出的方法是一种增强对比度的方法,其基本原理是自适应参数的 ganma 校正。ganma 校正的目标在于同时校正曝光过度和曝光不足区域的图像。 同时,为了防止光晕伪影,使用双…
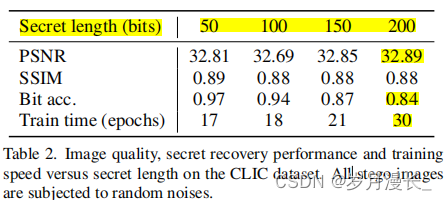
【论文阅读】RoSteALS: Robust Steganography using Autoencoder Latent Space-2023-CVPR
摘要
RoSteALS使用一个轻量级的秘密编码器将秘密信息映射到图像的潜空间中,并通过对潜空间进行微小的偏移来嵌入秘密信息。 该方法使用预训练的自编码器作为基础模型,不需要学习图像分布,因此训练过程简单且效果良好。
方法 架构图…

【论文阅读】Robust Object-based SLAM for High-speed Autonomous Navigation
一、问题概述
这篇文章是在QuadricSLAM的基础上进行的改进,也就是说依然使用了椭球对物体进行描述,论文中提到使用椭球本身是因为椭球其参数化表示可以完全通过相机的检测框来进行约束,二次曲面与对偶二次曲面可以参考链接,文章使…
FAST-LIO2论文阅读
目录 迭代扩展卡尔曼滤波增量式kd-tree(ikd-tree)增量式维护示意图ikd-tree基本结构与构建ikd-tree的增量更新(Incremental Updates)逐点插入与地图下采样使用lazy labels的盒式删除属性更新 ikd-tree重平衡平衡准则重建及并行重建…
论文阅读 Interpretable Unified Language Checking
本文提出了一种新的方法来解决多种自然语言处理任务中的问题,包括公平性检查、事实检查、虚假新闻检测和对抗攻击检测等。该方法基于大型语言模型和少量人类标注的提示信息,通过在模型中引入相应的提示,来提高模型的性能和可解释性。该论文的…
[论文笔记] SurroundOcc: Multi-Camera 3D Occupancy Prediction for Autonomous Driving
Wei, Yi, et al. “Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023. 重点记录
将占用网格应用到多个相机构成的3D空间中; 使用BEVFormer中的方法获取3D特征, …
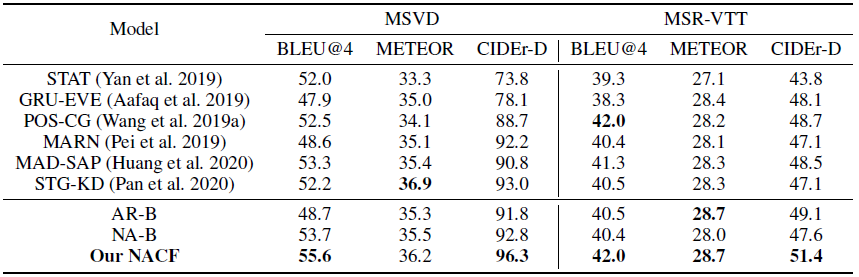
Non-Autoregressive Coarse-to-Fine Video Captioning【论文阅读】
Non-Autoregressive Coarse-to-Fine Video Captioning
发表:AAAI 2021idea:(1)针对推理阶段不能并行,推理效率低的问题使用一种双向解码(在bert中不使用sequence mask)。(2…
LIO-SAM论文与代码阅读笔记(一)论文阅读
文章目录0.前言1.内容介绍2.研究背景2.1.不同的地图维护方式2.2.LIO的紧耦合和松耦合3.方法3.1.因子图3.2.激光里程计因子3.3.GPS因子4.实验4.1.旋转数据集4.2.行走数据集4.3.校园数据集4.4/5.公园数据集和运河数据集5.总结5.1.LIO-SAM的核心思想和优缺点5.2.LiDAR SLAM的展望0…
R-Drop: Regularized Dropout for Neural Networks 论文笔记(介绍,模型结构介绍、代码、拓展KL散度等知识)
目录前言一、摘要二、R-Drop介绍三、R-Drop公式详解四、R-Drop计算流程附录0:代码附录一:熵以及信息熵附录二:KL散度(相对熵)附录三:JS散度附录四:互信息总结前言 R-Drop——神经网络的正则化Dr…

论文阅读:MPViT : Multi-Path Vision Transformer for Dense Prediction
中文标题:基于多路视觉Transformer的密集预测 提出问题
创新点
提出了一种具有多路径结构的多尺度嵌入方法,以同时表示密集预测任务的精细和粗糙特征。全局到局部的特征交互(GLI),以同时利用卷积的局部连通性和转换器…
论文阅读-DISTILLING KNOWLEDGE FROM READER TORETRIEVER FOR QUESTION ANSWERING
论文链接:https://arxiv.org/pdf/2012.04584.pdf
目录
方法
交叉注意机制
交叉注意力得分作为段落检索的相关性度量
用于段落检索的密集双编码器
将交叉注意力分数提取到双编码器
数据集 方法 我们的系统由两个模块组成,即检索器和阅读器…
Faster RCNN 论文阅读
1.网络架构 VGG16网络 anchors:人工放上去的 RPN对anchors进行二分类,正样本,负样本 RoIP:前面的框框已经圈出目标,但还不知道具体属于哪个类,它就是干这个工作的 2.VGG网络 VGG网络可以任意替换其他的任意神经网络&am…
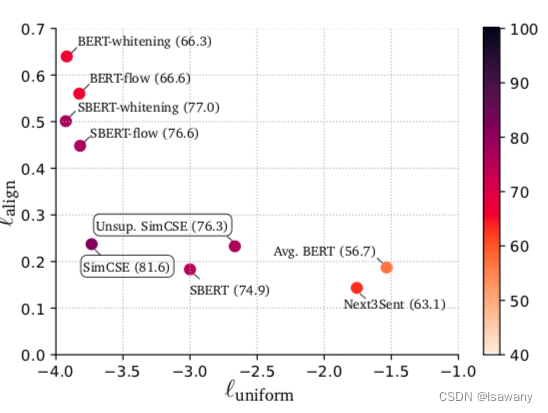
论文笔记--SimCSE: Simple Contrastive Learning of Sentence Embeddings
论文笔记--SimCSE: Simple Contrastive Learning of Sentence Embeddings 1. 文章简介2. 文章概括3 文章重点技术3.1 对比学习 Contrastive Learning3.2 Unsupervised SimCSE3.3 Supervised SimCSE3.4 Anisotropy3.5 Alignment and Uniformity 4. 文章亮点5. 原文传送门6. Refe…
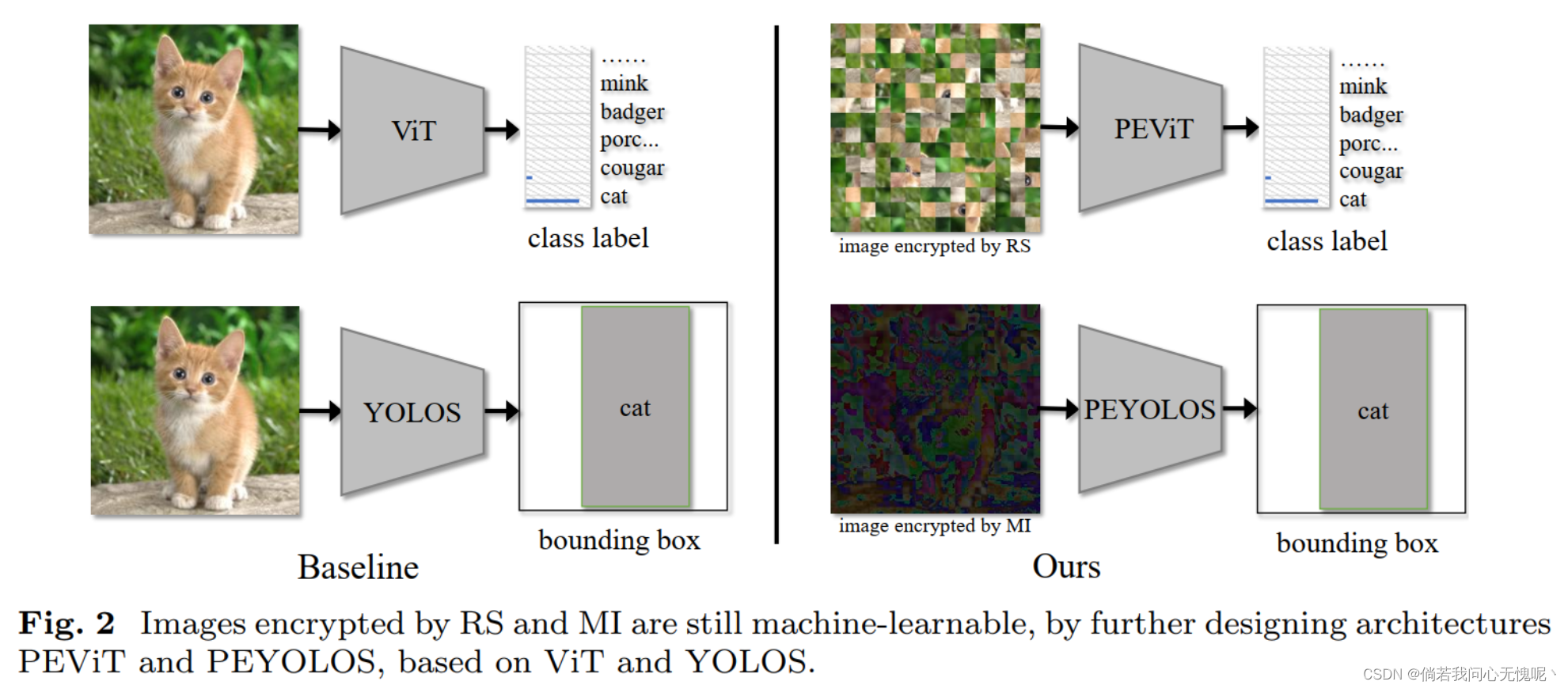
【论文阅读】(2023.06.09-2023.06.18)论文阅读简单记录和汇总
(2023.06.09-2023.06.12)论文阅读简单记录和汇总 2023/06/09:虽然下周是我做汇报,但是到了周末该打游戏还是得打的 2023/06/12:好累好困,现在好容易累。
目录
(TCSVT 2023)Facial Image Compression via …
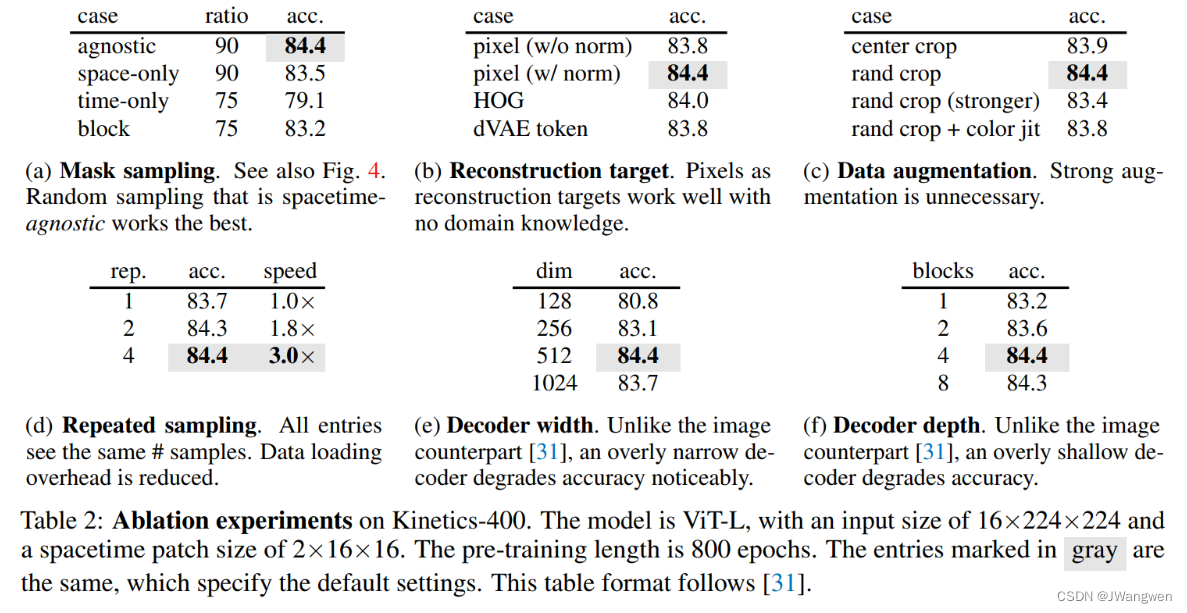
论文阅读 :Masked Autoencoders As Spatiotemporal Learners
NeurIPS2022——Masked Autoencoders As Spatiotemporal Learners
Keywords: Videos;object detection; 文章目录NeurIPS2022——Masked Autoencoders As Spatiotemporal Learners研究动机本文贡献Introduction & Related work整体架构&…

OCR之论文笔记TrOCR
论文题目:TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models 发表:CVPR2022 机构:微软 代码:https://github.com/microsoft/unilm/tree/master/trocr
摘要: Text recognition is a lo…
BARF: Bundle-Adjusting Neural Radiance Fields论文阅读
摘要
神经辐射场 (NeRF)可以合成真实世界场景的全新视角的照片,其性能优异,因此在计算机视觉领域引起较大的兴趣。NeRF的一个限制条件是需要准确相机位姿。本文提出了集束调整神经辐射场 (BARF) ,可以用不完美的(甚至不知道&…
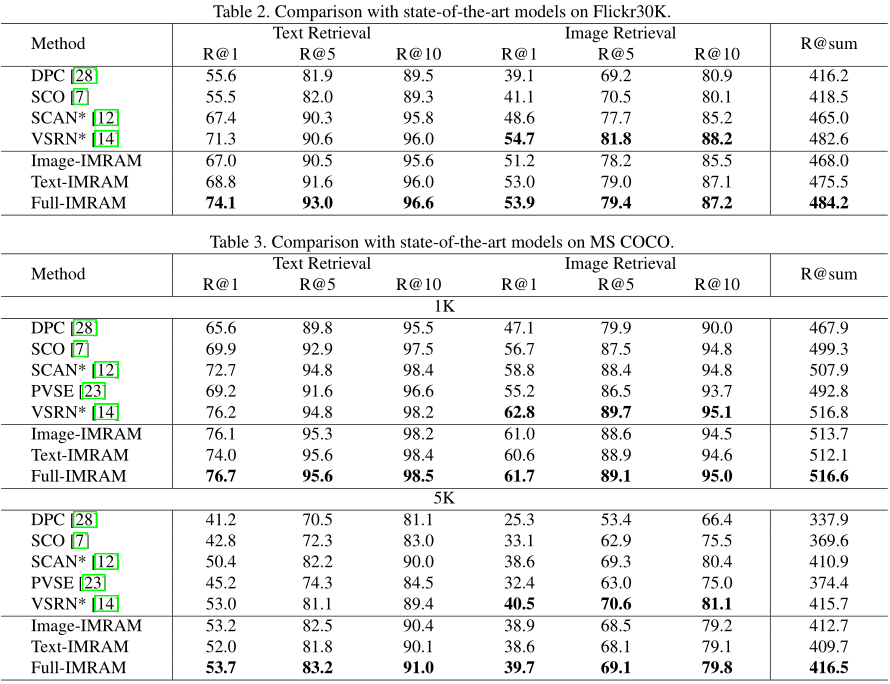
跨模态检索论文阅读:IMRAM
IMRAM: Iterative Matching with Recurrent Attention Memory for Cross-Modal Image-Text Retrieval
IMRAM: 基于循环注意记忆的迭代匹配跨模态图像-文本检索[Submitted on 8 Mar 2020]
概述
现有的方法利用注意力机制以细粒度的方式探索视觉和语言之间对应关系。然而&…

【论文笔记】Throwing Objects into A Moving Basket While Avoiding Obstacles
文章目录【论文笔记】Throwing Objects into A Moving Basket While Avoiding ObstaclesAbstractI. INTRODUCTIONII. RELATED WORKA. Analytical ApproachesB. Learning ApproachesC. Other WorksIII. METHODA. PreliminariesMarkov Decision Process (MDP)Off-policy RLB. Pro…

An Empirical Study on Leveraging Position Embeddings for TOWE 论文阅读笔记
一、作者
Samuel Mensah、Kai Sun Computer Science Department, University of Sheffield, UK BDBC and SKLSDE, Beihang University, China
二、背景
面向目标的意见词提取(TOWE)是面向目标的情感分析的一个新的子任务,旨在为文本中的给…
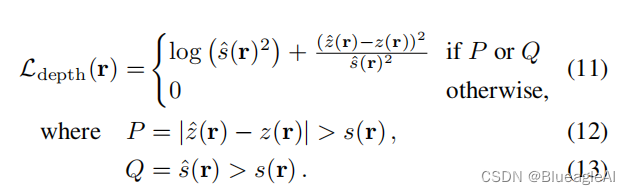
论文阅读:Dense Depth Priors for Neural Radiance Fields from Sparse Input Views
CVPR2022
Preliminary
首先我们由一组室内的RGB图像 { I i } i 0 N − 1 , I i ∈ [ 0 , 1 ] H W 3 \{I_i\}^{N-1}_{i0}, I_i \in [0,1]^{H \times W \times 3} {Ii}i0N−1,Ii∈[0,1]HW3。通过SFM的方法,我们可以获得相机位姿 p i ∈ R 6 p_i \in \mathb…

Latent Diffusion(CVPR2022 oral)-论文阅读
文章目录摘要背景算法3.1. Perceptual Image Compression3.2. Latent Diffusion Models3.3. Conditioning Mechanisms实验4.1. On Perceptual Compression Tradeoffs4.2. Image Generation with Latent Diffusion4.3. Conditional Latent Diffusion4.4. Super-Resolution with …
![论文记录:Visual Relationship Detection with Language Priors [VR-LP] (ECCV-16)](https://img-blog.csdnimg.cn/20190113144618488.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2RlZXBpbkM=,size_16,color_FFFFFF,t_70)
论文记录:Visual Relationship Detection with Language Priors [VR-LP] (ECCV-16)
(这里只是记录了论文的一些内容以及自己的一点点浅薄的理解,具体实验尚未恢复。由于本人新人一枚,若有错误以及不足之处,还望不吝赐教)
总结 contributions: 该论文是第一篇提出将 relationship 的 objects 和 predic…
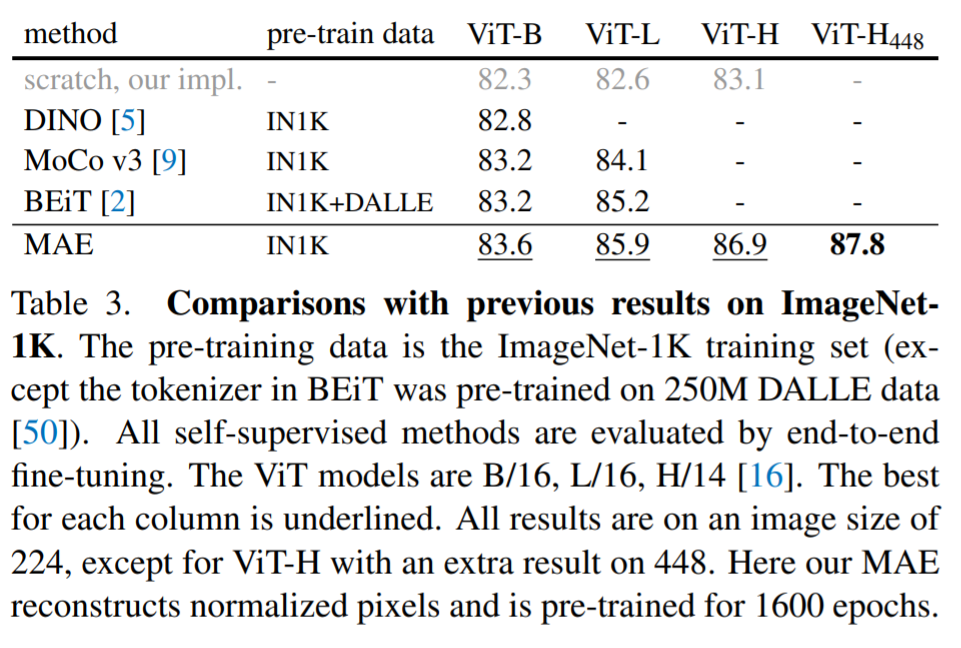
MAE论文阅读《Masked Autoencoders Are Scalable Vision Learners》
文章目录动机方法写作方面参考Paper: https://arxiv.org/pdf/2111.06377.pdf 动机
首先简要介绍下BERT,NLP领域的BERT是基于Transformer架构,并采取无监督预训练的方式去训练模型。它提出的预训练方法在本质上是一种masked autoencoding,也就…
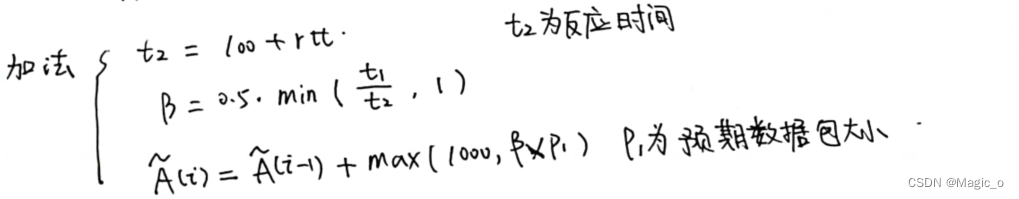
【音视频第11天】GCC论文阅读(2)
A Google Congestion Control Algorithm for Real-Time Communication draft-alvestrand-rmcat-congestion-03论文理解 看中文的GCC算法一脸懵。看一看英文版的,找一找感觉。 目录Abstract1. Introduction1.1 Mathematical notation conventions2. System model3.Fe…
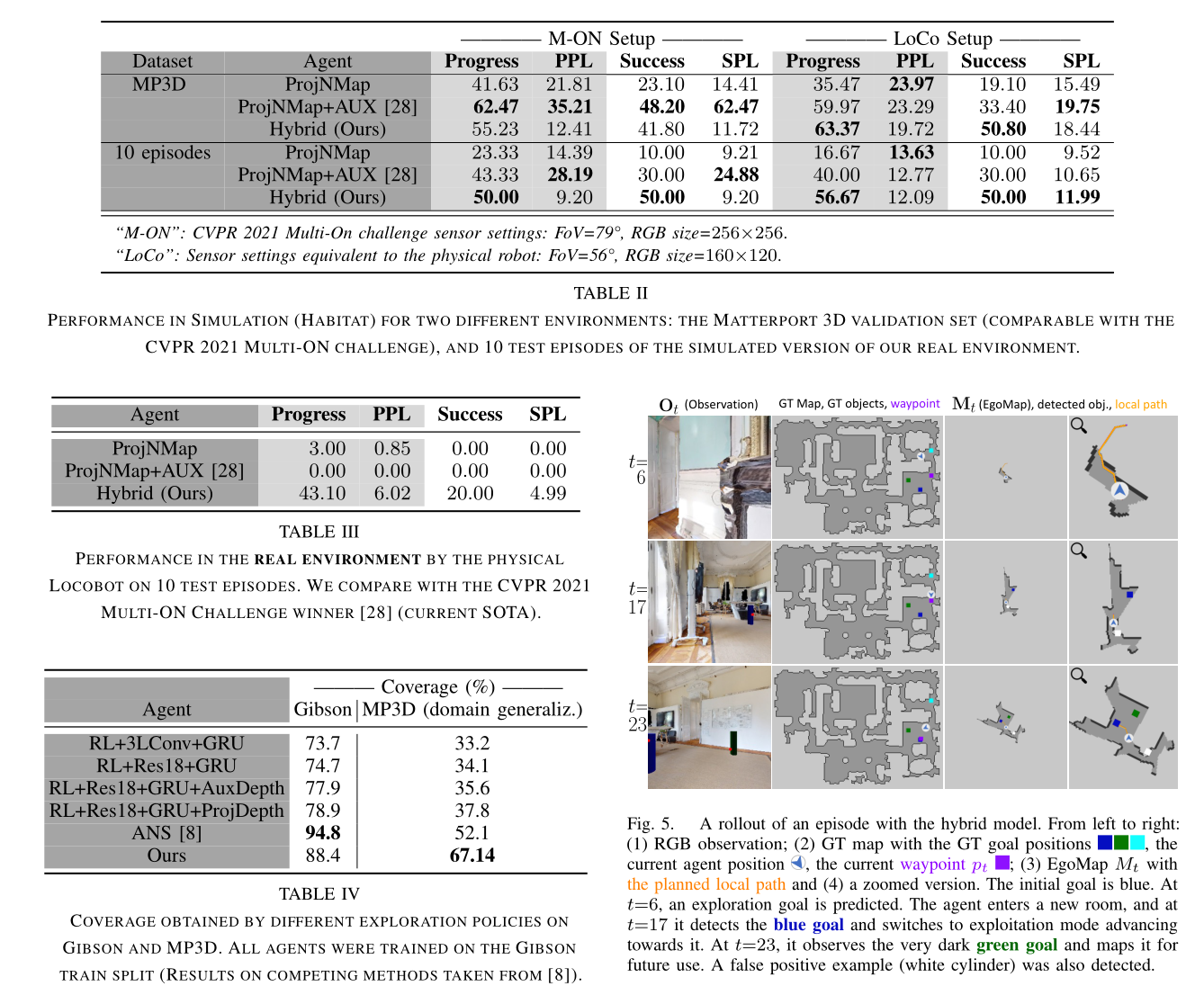
Multi-object navigation in real environments using hybrid policies 论文阅读
论文信息
题目:Multi-object navigation in real environments using hybrid policies 作者:Assem Sadek, Guillaume Bono 来源:CVPR 时间:2023
Abstract
机器人技术中的导航问题通常是通过 SLAM 和规划的结合来解决的。
最近…
[论文笔记]Self-Attention with Relative Position Representations
引言
这是论文Self-Attention with Relative Position Representations的阅读笔记。这是一篇18年的论文。
仅依赖于注意力机制的Transformer没有显示地建模相对或绝对信息,而是需要把绝对位置表示加到输入中。在这篇文章中,作者提出了一种相对方法扩展了自注意机制,以有效…
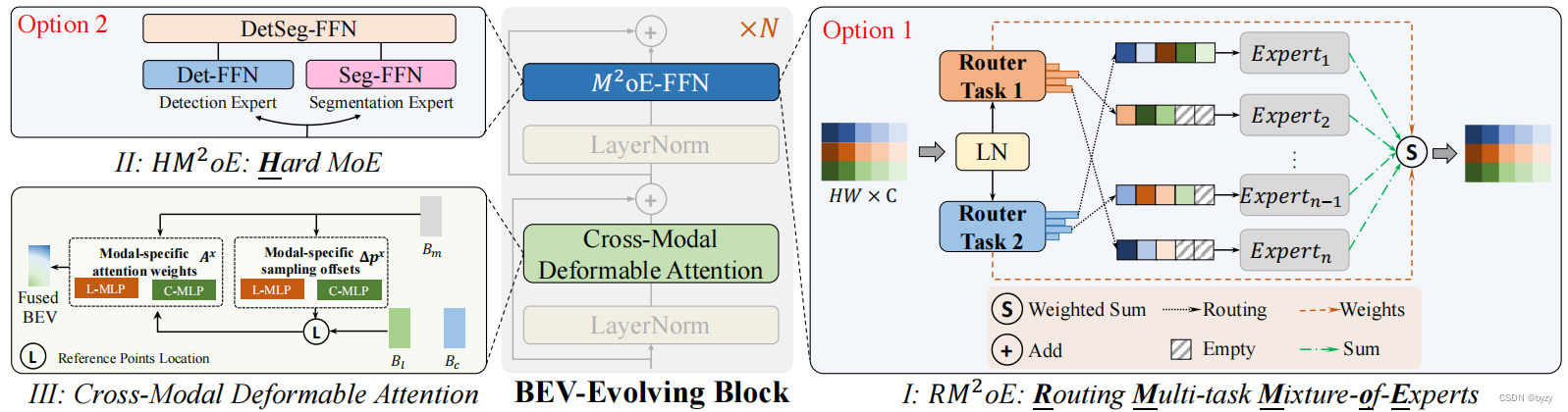
【论文笔记】MetaBEV: Solving Sensor Failures for BEV Detection and Map Segmentation
原文链接:https://arxiv.org/abs/2304.09801
1. 引言 目前,多模态融合感知中的一大问题在于忽视了传感器失效带来的影响。之前工作的主要问题包括:
特征不对齐:通常使用CNN处理拼接后的特征图,存在几何噪声时可能导致…
论文阅读_医疗知识图谱_GraphCare
英文名称: GraphCare: Enhancing Healthcare Predictions with Open-World Personalized Knowledge Graphs 中文名称: GraphCare:通过开放世界的个性化知识图增强医疗保健预测 文章: http://arxiv.org/abs/2305.12788 代码: https://github.com/pat-jj/GraphCare 作…
【核磁共振成像】傅里叶重建
目录 一、傅里叶重建二、填零三、移相四、数据窗函数五、矩形视野六、多线圈数据重建七、图像变形校正八、缩放比例九、基线校准 长TR,长TE,是T2加权像; 短TR,短TE,是T1加权像; 长TR,短TE&#…
论文笔记:基于概念漂移的在线类非平衡学习系统研究
0 摘要
论文:A Systematic Study of Online Class Imbalance Learning With Concept Drift 发表:2018年发表在TNNLS上 源代码:?
作为一个新兴的研究课题,在线类非平衡学习往往结合了类非平衡和概念漂移的挑战。它处理…
OVRL-V2: A simple state-of-art baseline for IMAGENAV and OBJECTNAV 论文阅读
论文信息
题目:OVRL-V2: A simple state-of-art baseline for IMAGENAV and OBJECTNAV 作者:Karmesh Yadav, Arjun Majumdar, Ram Ramrakhya 来源:arxiv 时间:2023 代码地址: https://github.com/ykarmesh…
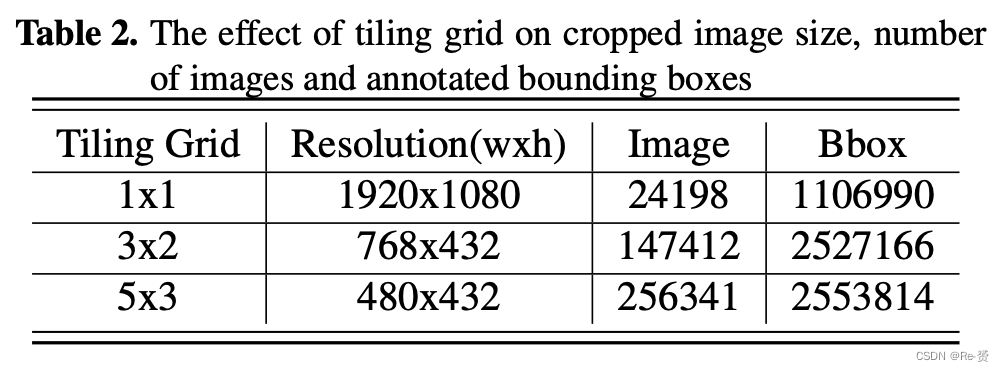
论文阅读 The Power of Tiling for Small Object Detection
The Power of Tiling for Small Object Detection
Abstract
基于深度神经网络的技术在目标检测和分类方面表现出色。但这些网络在适应移动平台时可能会降低准确性,因为图像分辨率的增加使问题变得更加困难。在低功耗移动设备上实现实时小物体检测一直是监控应用的…

论文阅读_扩散模型_LDM
英文名称: High-Resolution Image Synthesis with Latent Diffusion Models 中文名称: 使用潜空间扩散模型合成高分辨率图像 地址: https://ieeexplore.ieee.org/document/9878449/ 代码: https://github.com/CompVis/latent-diffusion 作者:Robin Rombach 日期: 20…
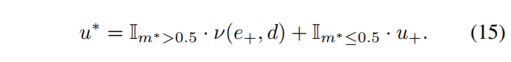
Competitive Collaboration 论文阅读
论文信息
题目:Competitive Collaboration: Joint Unsupervised Learning of Depth, Camera Motion, Optical Flow and Motion Segmentation 作者:Anurag Ranjan, Varun Jampani, Lukas Balles 来源:CVPR 时间&#x…
![[异构图-论文阅读]Heterogeneous Graph Transformer](https://img-blog.csdnimg.cn/e8c4750d1ade4944b74a82cb7a93be59.png)
[异构图-论文阅读]Heterogeneous Graph Transformer
这篇论文介绍了一种用于建模Web规模异构图的异构图变换器(HGT)架构。以下是主要的要点:
摘要和引言 (第1页) 异构图被用来抽象和建模复杂系统,其中不同类型的对象以各种方式相互作用。许多现有的图神经网络(GNNs)主要针对同构图设计,无法有效表示异构结构。HGT通过设计…
【论文阅读笔记】Endoscopic navigation in the absence of CT imaging
论文小结 上一篇的导航导论,是需要先验,也就是需要事先拍摄堆叠的图片(比如CT图等),在体外构建相应的3D模型,再与内窥镜图像进行实时匹配。对于很多情况来说,是无法拥有如此充足的先验的。所以&…

论文笔记 | 谷歌 Soft Prompt Learning ,Prefix-Tuning的 -> soft promt -> p tuning v2
论文笔记 | 谷歌 Soft Prompt Learning
ptuning -> Prefix-Tuning -> soft promt -> p tuning v2
"The Power of Scale for Parameter-Efficient Prompt Tuning" EMNLP 2021 Google Brain
人能理解的不一定是模型需要的,所以不如让模型自己训…

论文阅读 FCOS: Fully Convolutional One-Stage Object Detection
文章目录 FCOS: Fully Convolutional One-Stage Object DetectionAbstract1. Introduction2. Related Work3. Our Approach3.1. Fully Convolutional One-Stage Object Detector3.2. Multi-level Prediction with FPN for FCOS3.3. Center-ness for FCOS 4. Experiments4.1. Ab…

gen1-视频生成论文阅读
文章目录 摘要贡献算法3.1 LDM3.2 时空隐空间扩散3.3表征内容及结构内容表征结构表征条件机制采样 3.4优化过程 实验结果结论 论文:
《Structure and Content-Guided Video Synthesis with Diffusion Models》 官网:
https://research.runwayml.com/ge…

论文阅读《Graph Contextualized Self-Attention Network for Session-based Recommendation》
论文地址:https://www.ijcai.org/Proceedings/2019/0547.pdf Graph Contextualized Self-Attention Network for Session-based Recommendation
1.引言
在电子商务、音乐、社交媒体等许多应用领域,推荐系统在帮助用户缓解信息过载和选择感兴趣内容方面…
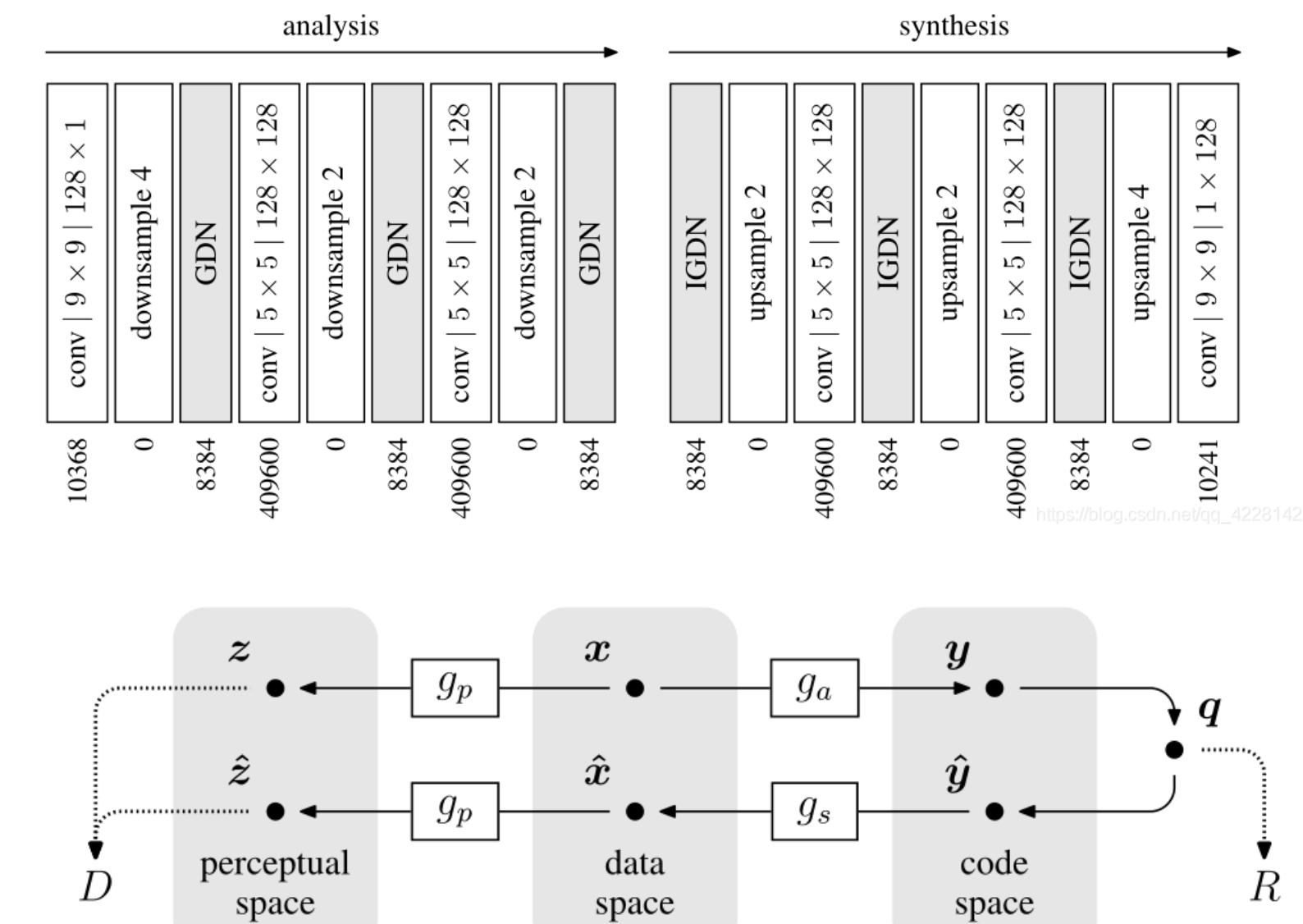
END-TO-END OPTIMIZED IMAGE COMPRESSION论文阅读
END-TO-END OPTIMIZED IMAGE COMPRESSION 文章目录 END-TO-END OPTIMIZED IMAGE COMPRESSION单词重要不重要 摘要: 单词
重要
image compression 图像压缩
quantizer 量化器
rate–distortion performance率失真性能
不重要
a variant of 什么什么的一个变体 …
论文笔记 - BadEncoder: Backdoor Attacks to Pre-trained Encoders in Self-Supervised Learning
文章目录 自监督学习下的后门攻击基本信息核心贡献基本方法限制条件问题定义符号说明转换思想算法思路基本步骤目标优化函数BadEncoder训练过程实验设计(后续整理实验继续补充)自监督学习下的后门攻击
基本信息 论文标题BadEncoder: Backdoor Attacks to Pre-trained Encode…
论文笔记(精读文章) - Invisible Backdoor Attack with Sample-Specific Triggers
文章目录 订制样本触发器方法的隐蔽式后门攻击基本信息论文贡献算法思路前提假设问题定义基本步骤实验验证实验设置数据集与模型实验比较基准攻击实验防御实验度量方式实验结果分析(重在模仿其实验分析的表述方式)攻击性能分析攻击隐蔽性分析抵御各种后门攻击防御的比较扩展实…
《论文阅读》用提示和释义模拟对话情绪识别的思维过程 IJCAI 2023
《论文阅读》用提示和复述模拟对话情绪识别的思维过程 IJCAI 2023 前言简介相关知识prompt engineeringparaphrasing模型架构第一阶段第二阶段History-oriented promptExperience-oriented Prompt ConstructionLabel Paraphrasing损失函数前言
你是否也对于理解论文存在困惑?…

论文阅读_扩散模型_DDPM
英文名称: Denoising Diffusion Probabilistic Models 中文名称: 去噪扩散概率模型 论文地址: http://arxiv.org/abs/2006.11239 代码地址1: https://github.com/hojonathanho/diffusion (论文对应代码 tensorflow) 代码地址2: https://github.com/AUTOM…

论文笔记:ViTGAN: Training GANs with Vision Transformers
2021
1 intro
论文研究的问题是:ViT是否可以在不使用卷积或池化的情况下完成图像生成任务 即不用CNN,而使用ViT来完成图像生成任务将ViT架构集成到GAN中,发现现有的GAN正则化方法与self-attention机制的交互很差,导致训练过程中…

论文阅读:Distortion-Free Wide-Angle Portraits on Camera Phones
论文阅读:Distortion-Free Wide-Angle Portraits on Camera Phones
今天介绍一篇谷歌 2019 年的论文,是关于广角畸变校正的。
Abstract
广角摄影,可以带来不一样的摄影体验,因为广角的 FOV 更大,所以能将更多的内容…
![[论文笔记]ESIM](https://img-blog.csdnimg.cn/img_convert/a810b56a6d91559841fce712c1923cef.png)
[论文笔记]ESIM
引言
这是经典论文Enhanced LSTM for Natural Language Inference的笔记。 本篇论文文是建立在自然语言推理(Natural Language Inference,NLI)任务上的。提出了简单的通过基于LSTM的序列推理模型效果到达了当时的SOTA水平。同时基于该模型,在局部推理建模层和推理组合层使用了…
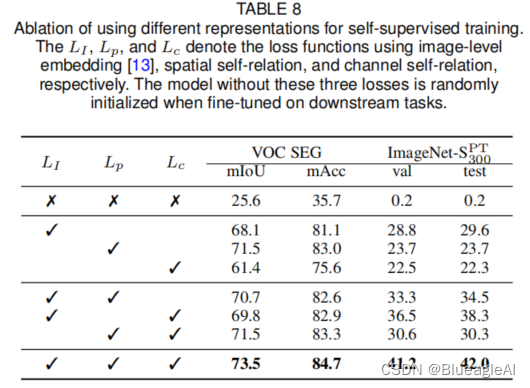
论文阅读:SERE: Exploring Feature Self-relation for Self-supervised Transformer
Related Work
Self-supervised 学习目的是在无人工标注的情况下通过自定制的任务(hand-crafted pretext tasks)学习丰富的表示。
Abstract
使用自监督学习为卷积网络(CNN)学习表示已经被验证对视觉任务有效。作为CNN的一种替代…
《论文阅读》CARE:通过条件图生成的共情回复因果关系推理 EMNLP 2022
《论文阅读》CARE:通过条件图生成的移情反应因果关系推理 前言简介基础知识TransformerVariational Graph Auto-Encoder 变分图自编码器`邻接矩阵(adjacency matrix)``图神经网络(GNN)``图卷积神经网络(GCN)``自编码器(Auto Encoder)``图自编码器(GAE)``变分图自编码…
[论文笔记]Prompt Tuning
引言
今天带来第三篇大模型微调论文笔记The Power of Scale for Parameter-Efficient Prompt Tuning。
作者提出了prompt tuning(提示微调),一种简单高效地微调方法。可以看成是prefix tuning的简化版。
总体介绍
最近的研究表明,提示设计(prompt design)在通过文本提示调…
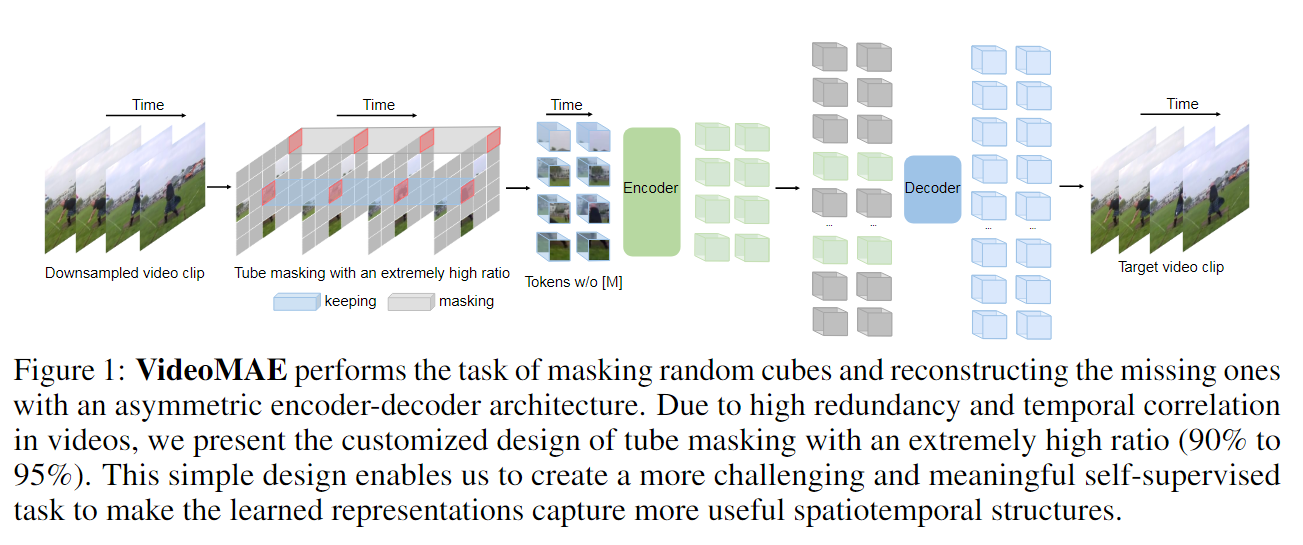
【Spatial-Temporal Action Localization(七)】论文阅读2022年
文章目录 1. TubeR: Tubelet Transformer for Video Action Detection摘要和结论引言:针对痛点和贡献模型框架TubeR Encoder:TubeR Decoder:Task-Specific Heads: 2. Holistic Interaction Transformer Network for Action Detect…

论文阅读笔记(三)——有监督解耦+信息瓶颈
论文信息
《Disentangled Information Bottleneck》 论文地址:https://ojs.aaai.org/index.php/AAAI/article/view/17120 代码地址:GitHub - PanZiqiAI/disentangled-information-bottleneck inproceedings{pan2021disentangled, title{Disentangled in…
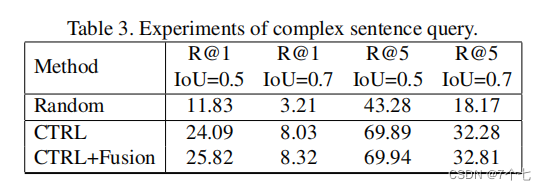

论文笔记 - EncoderMI: Membership Inference against Pre-trained Encoders in Contrastive Learning
文章目录自监督学习模型的成员推理攻击论文信息摘要总结基本方法训练“影子模型”提取推理数据特征向量构造推理输入特征及分类器未完待更新!自监督学习模型的成员推理攻击
论文信息
论文标题EncoderMI: Membership Inference against Pre-trained Encoders in Co…
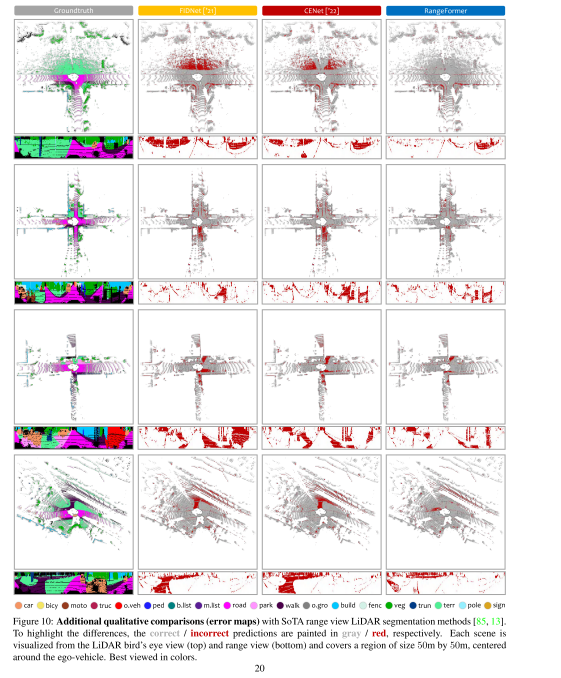
论文阅读:Rethinking Range View Representation for LiDAR Segmentation
来源ICCV2023
0、摘要
LiDAR分割对于自动驾驶感知至关重要。最近的趋势有利于基于点或体素的方法,因为它们通常产生比传统的距离视图表示更好的性能。在这项工作中,我们揭示了建立强大的距离视图模型的几个关键因素。我们观察到,“多对一”…

论文笔记|ECCV2022:Self-Promoted Supervision for Few-Shot Transformer
论文地址:https://arxiv.org/abs/2203.07057 代码链接:https://github.com/DongSky/few-shot-vit 这篇论文在2022年发表在ECCV上,论文的题目是用于小样本Transformer的self-promoted supervision(自我推荐监督)
1 Mot…
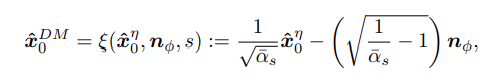
denoising diffusion post-processing for low-light image enhancement 论文阅读笔记
这是arxiv上一篇做denoising diffusion的文章,用来做low-light image enhancement的post-processing,感觉可能是已经投稿还未发表
diffusion model 背景
diffusion model是比较多公式的一个模型,但是其实不难,话不多说ÿ…

论文阅读——《Contextual Sequence Modeling for Recommendation with Recurrent Neural Networks》
《Contextual Sequence Modeling for Recommendation with Recurrent Neural Networks》
摘要
推荐可以从推荐时间用户状态的良好表示中获益。最近利用递归神经网络(RNN)进行基于会话的推荐的方法表明,深度学习模型可以为推荐提供有用的用户…
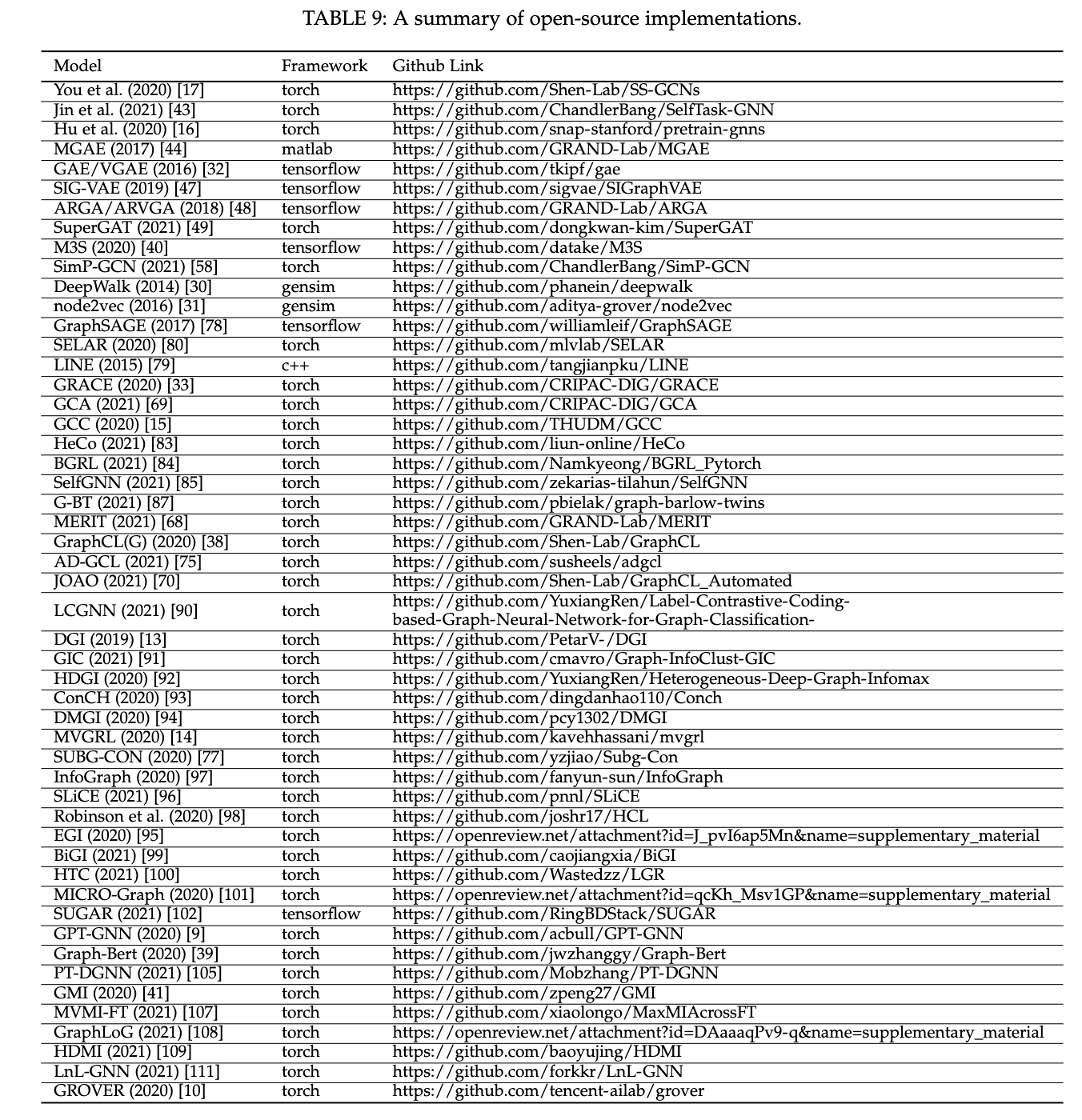
论文阅读 —— Graph Self-Supervised Learning: A Survey (自监督图学习综述)
论文链接:https://arxiv.org/pdf/2103.00111.pdf 目录
摘要
1 引言
2 定义和符号(notation)
2.1 术语定义
2.2 符号
3 框架和分类
3.1 图自监督学习的统一框架和数学公式 3.2 图自监督学习的分类
3.3自我监督训练计划的分类
3.4 下游…

【论文阅读】基于深度学习的时序预测——Informer
系列文章链接 论文一:2020 Informer:长序列数据预测 论文二:2021 Autoformer:长序列数据预测
文章地址:https://arxiv.org/abs/2012.07436 github地址:https://github.com/zhouhaoyi/Informer2020 参考解读…

论文阅读 关联规则挖掘综述
这是一篇关联规则挖掘的综述,也记录下自己的心得笔记
A comprehensive review of visualization methods for association rule mining: Taxonomy, Challenges, Open problems and Future ideas 文章目录 摘要1、介绍2、关联规则挖掘是个小东西2.1、数值关联规则挖…

【论文阅读】GNN在推荐系统中的应用
【论文阅读】GNN在推荐系统中的应用
参考Graph Neural Networks for Recommender Systems: Challenges, Methods, and Directions 文章目录 【论文阅读】GNN在推荐系统中的应用1、本文结构2、推荐系统的目的,发展和基于GNN模型的挑战3、推荐系统相应背景࿰…

Segment Anything——论文笔记
home page:segment-anything.com code:segment-anything
1. 概述 介绍:SAM是最近提出的一种通用分割大模型,其表现出了强大的零样本泛化能力,视觉感知模型的通用化又前进了一步。为了达到文章标题字面意义“segment a…
论文笔记--PANGU-α
论文笔记--PANGU-α: LARGE-SCALE AUTOREGRESSIVE PRETRAINED CHINESE LANGUAGE MODELS WITH AUTO-PARALLEL COMPUTATION 1. 文章简介2. 文章概括3 文章重点技术3.1 Transformer架构3.2 数据集3.2.1 数据清洗和过滤3.2.2 数据去重3.2.3 数据质量评估 4. 文章亮点5. 原文传送门6…

【论文阅读】Neuralangelo:高保真神经表面重建
【论文阅读】Neuralangelo:高保真神经表面重建 Abstract1. Introduction2. Related work3. Approach3.1.预备工作3.2.数值梯度计算3.3.渐进细节层次3.4.优化 4. Experiments4.1. DTU Benchmark4.2. Tanks and Temples4.3.细节水平4.4.消融 5. Conclusion paper proj…

在模拟冷藏牛肉加工条件下,冷和酸对荧光假单胞菌和单核细胞增生李斯特菌双菌种生物膜的综合影响
1.1 Title:Combined effects of cold and acid on dual-species biofilms of Pseudomonas fluorescens and Listeria monocytogenes under simulated chilled beef processing conditions
1.2 分区/影响因子:Q1/5.3
1.3 作者:Zhou Guanghui…
论文阅读-可泛化深度伪造检测的关键
一、论文信息 论文名称:Learning Features of Intra-Consistency and Inter-Diversity: Keys Toward Generalizable Deepfake Detection 作者团队:Chen H, Lin Y, Li B, et al. (广东省智能信息处理重点实验室、深圳市媒体安全重点实验室和深…
G1D18-WarshallFloyd课程报告matlab下载
今天先从算法开始吧嘿嘿~
一、DP
(一)Warshall求闭包
1、DP大概看明白啦~ 2、一会再看一下基于邻接表的暴搜
(二)Floyd完全最短路径的Floyd算法
欸嘿~~基本上好啦还差一点图的遍历晚上问问同学吧! 啊哈大概看了一…
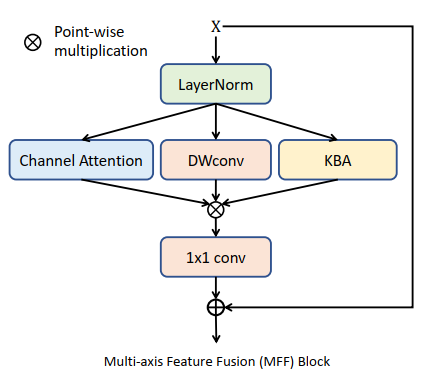
图像降噪网络:KBNet 论文笔记
0 前言 Zhang Y, Li D, Shi X, et al. KBNet: Kernel Basis Network for Image Restoration[J]. arXiv preprint arXiv:2303.02881, 2023. https://arxiv.org/abs/2303.02881 论文主要提出了 Kernel Basis Attention Module 注意力模块,称为 KBA 模块。该模块可以轻…
学术速运|利用机器学习进行有机反应机理分类
题目:Organic reaction mechanism classification using machine learning
文献来源: Nature | Vol 613 | 26 January 2023 | 691
代码:https://doi.org/10.48420/16965271
简介:对催化有机反应的机理的理解,有助于设计新的催化剂、反应…

华为又开始放大招了?CV新架构:VanillaNet: the Power of Minimalism in Deep Learning 论文阅读笔记
华为又开始放大招了?CV新架构:VanillaNet: the Power of Minimalism in Deep Learning 论文阅读笔记 一、Abstract二、引言三、单个 Vanilla 的神经结构四、训练 VanillaNet4.1 深度训练策略4.2 Series Informed Activation Function 五、实验5.1 消融实…
G1D13-Apt论文阅读fraudgitKGbookrce33-36php环境搭建
一、APT论文
今天终于把6个模型论文和一篇综述读完了!!! 今天主要读了一篇论文写了个总表。发现之前读的论文都忘了,所以
明天要复习一下模型,记录在文档中,并完善模型对比的总表,并且把代码下…

【论文阅读】基于深度学习的时序预测——FEDformer
系列文章链接 论文一:2020 Informer:长时序数据预测 论文二:2021 Autoformer:长序列数据预测 论文三:2022 FEDformer:长序列数据预测 论文四:2022 Non-Stationary Transformers:非平…
![[论文笔记]C^3F,MCNN:图片人群计数模型](https://img-blog.csdnimg.cn/e9025f1d6d7f4b349e9bae36b1cfe15f.png)
[论文笔记]C^3F,MCNN:图片人群计数模型
(万能代码)CommissarMa/Crowd_counting_from_scratch
代码:https://github.com/CommissarMa/Crowd_counting_from_scratch
(万能代码)C^3 Framework开源人群计数框架
科普中文博文:https://zhuanlan.zhihu.com/p/65650998
框架网址:https…

DIP: NAS(Neural Architecture Search)论文阅读与总结(双份快乐)
文章地址:
NAS-DIP: Learning Deep Image Prior with Neural Architecture SearchNeural Architecture Search for Deep Image Prior
参考博客:https://zhuanlan.zhihu.com/p/599390720 文章目录 NAS-DIP: Learning Deep Image Prior with Neural Architecture Search1. 方法…
[论文笔记]Sentence-BERT[v2]
引言
本文是SBERT(Sentence-BERT)论文1的笔记。SBERT主要用于解决BERT系列模型无法有效地得到句向量的问题。很久之前写过该篇论文的笔记,但不够详细,今天来重新回顾一下。
BERT系列模型基于交互式计算输入两个句子之间的相似度是非常低效的(但效果是很好的)。当然可以通过…
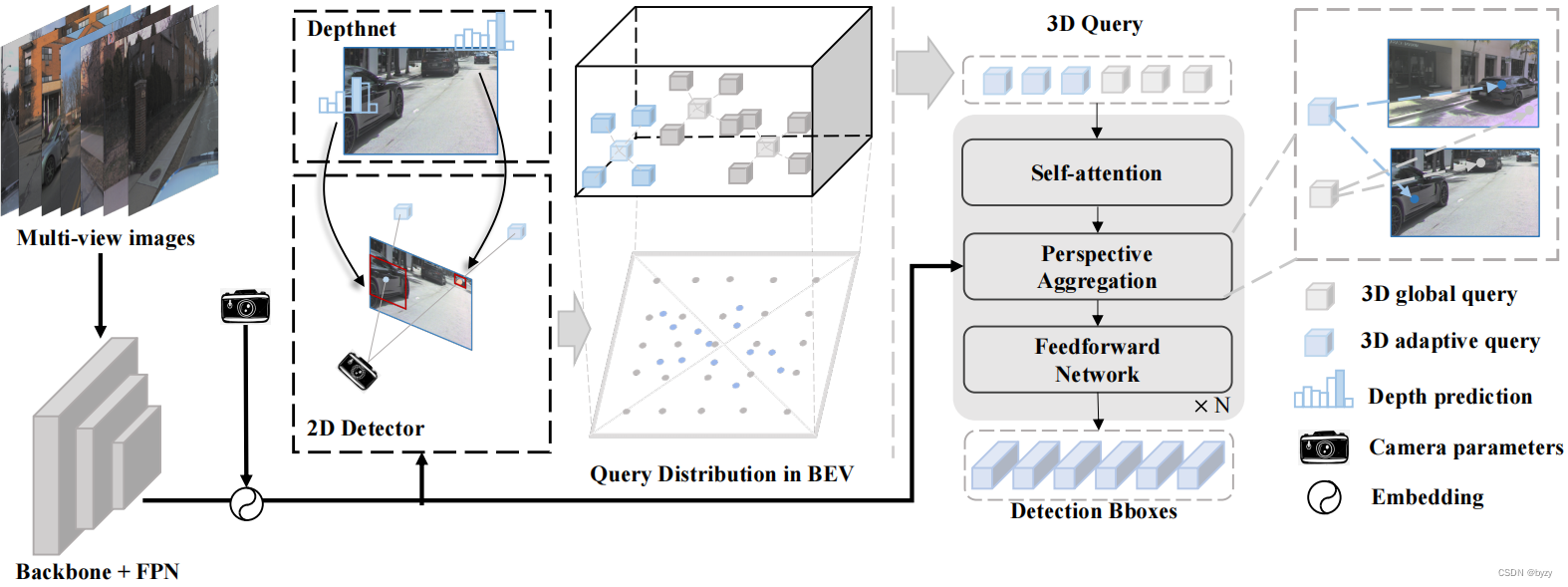
【论文笔记】Far3D: Expanding the Horizon for Surround-view 3D Object Detection
原文链接:https://arxiv.org/pdf/2308.09616.pdf
1. 引言
目前的环视图图像3D目标检测方法分为基于密集BEV的方法和基于稀疏查询的方法。前者需要较高的计算量,难以扩展到长距离检测。后者全局固定的查询不能适应动态场景,通常会丢失远距离…
![论文阅读[51]通过深度学习快速识别荧光组分](https://img-blog.csdnimg.cn/bc6b8c50c3504a2aa6e132623e5f4687.png)
论文阅读[51]通过深度学习快速识别荧光组分
【论文基本信息】 标题:Fast identification of fluorescent components in three-dimensional excitation-emission matrix fluorescence spectra via deep learning 标题译名:通过深度学习快速识别 三维激发-发射矩阵荧光光谱中的荧光组分 期刊与年份&…
[论文笔记]NEZHA
引言
今天带来华为诺亚方舟实验室提出的论文NEZHA,题目是 针对中文中文语言理解神经网络上下文表示(NEural contextualiZed representation for CHinese lAnguage understanding),为了拼出哪吒。
预训练语言模型由于具有通过对大型语料库进行预训练来捕获文本中深层上下文信…
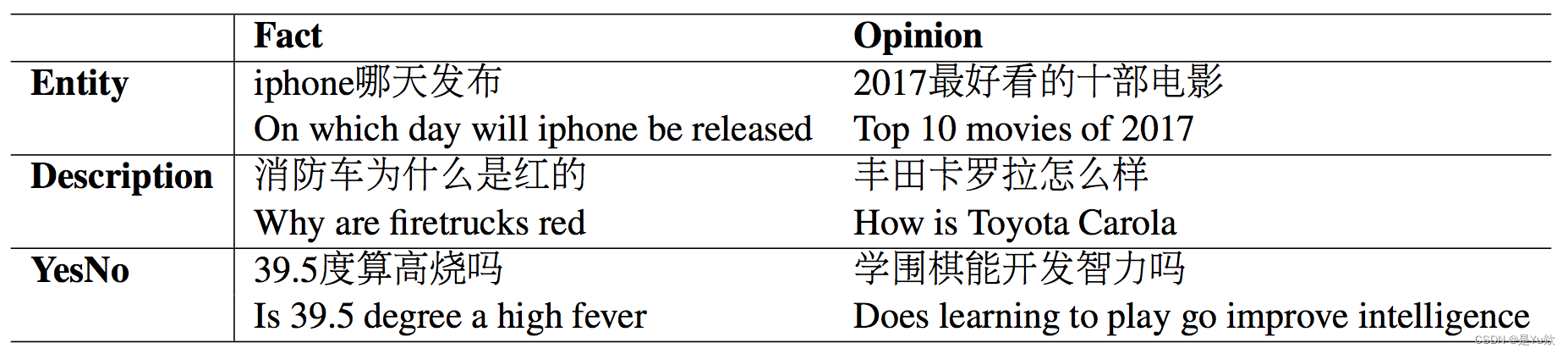

论文笔记《3D Gaussian Splatting for Real-Time Radiance Field Rendering》
项目地址
原论文
Abstract
最近辐射场方法彻底改变了多图/视频场景捕获的新视角合成。然而取得高视觉质量仍需神经网络花费大量时间训练和渲染,同时最近较快的方法都无可避免地以质量为代价。对于无边界的完整场景(而不是孤立的对象)和 10…
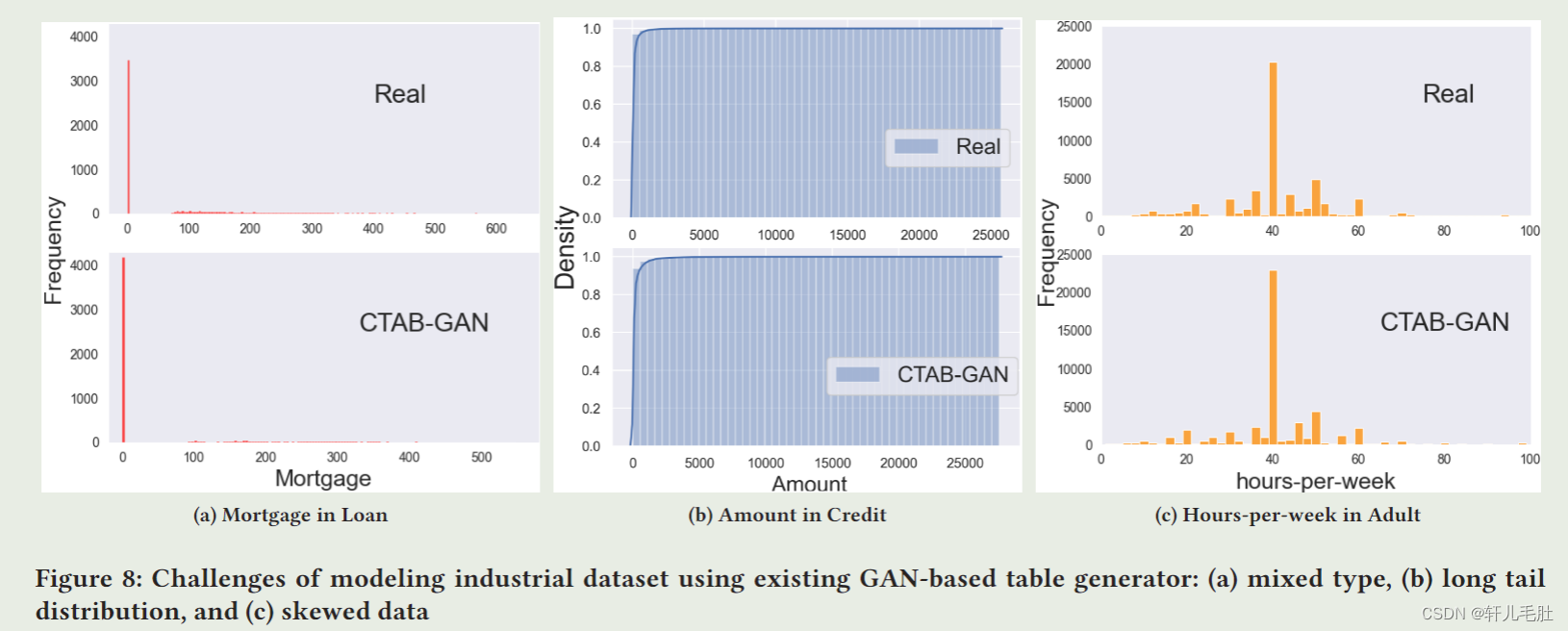
【论文阅读】CTAB-GAN: Effective Table Data Synthesizing
论文地址:[2102.08369] CTAB-GAN: Effective Table Data Synthesizing (arxiv.org) 介绍
虽然数据共享对于知识发展至关重要,但遗憾的是,隐私问题和严格的监管(例如欧洲通用数据保护条例 GDPR)限制了其充分发挥作用。…

【论文笔记】图神经网络采样相关工作整理9.19
【论文笔记】图神经网络采样相关工作整理9.19
GraphSAGE NIPS2017
论文:Inductive Representation Learning on Large Graphs
目前引用数:11628
本文提出了一种称为GraphSAGE的新的图嵌入方法,该方法可以在大型图上进行高效的无监督和有监…

【脑机接口论文与代码】 基于自适应FBCCA的脑机接口控制机械臂
Brain-Controlled Robotic Arm Based on Adaptive FBCCA 基于自适应FBCCA的脑机接口控制机械臂论文下载:算法程序下载:摘要1 项目介绍2 方法2.1CCA算法2.2FBCCA 算法2.3自适应FBCCA算法 3数据获取4结果4.1脑地形图4.2频谱图4.3准确率 5结论 基于自适应FB…
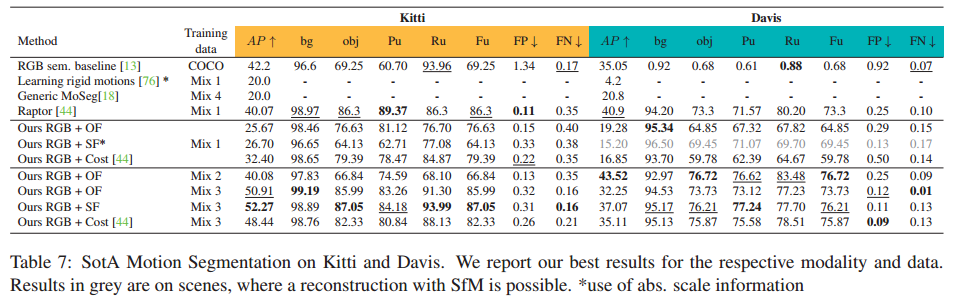
On Moving Object Segmentation from Monocular Video with Transformers 论文阅读
论文信息
标题:On Moving Object Segmentation from Monocular Video with Transformers 作者: 来源:ICCV 时间:2023 代码地址:暂无
Abstract
通过单个移动摄像机进行移动对象检测和分割是一项具有挑战性的任务&am…
论文阅读:基于隐马尔可夫模型的蛋白质多序列比对方法研究
本文来自chatpaper
Basic Information: • Title: Research on Protein Multiple Sequence Alignment Method Based on Hidden Markov Model (基于隐马尔可夫模型的蛋白质多序列比对方法研究) • Authors: Zhan Qing • Affiliation: Harbin Institute of Technology (哈尔滨工…
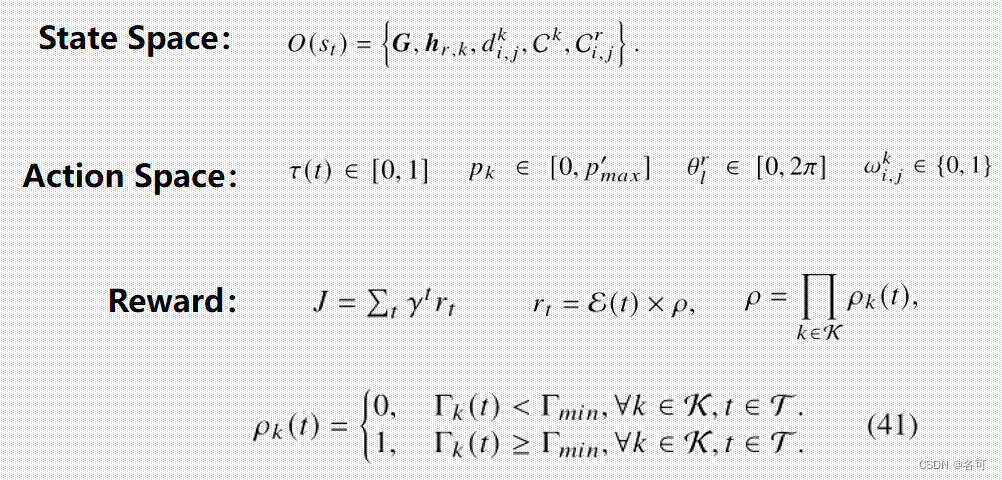
【论文阅读】基于鲁棒强化学习的无人机能量采集可重构智能表面
只做学习记录,侵删原文链接 article{peng2023energy, title{Energy Harvesting Reconfigurable Intelligent Surface for UAV Based on Robust Deep Reinforcement Learning}, author{Peng, Haoran and Wang, Li-Chun}, journal{IEEE Transactions on Wireless Comm…

【论文阅读】Prototypical Networks for Few-shot Learning
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、论文摘要方法 二、视频总结 前言
本文结合论文和youtube上的视频[Few-shot learning][2.2] Prototypical Networks: intuition, algorithm, pytorch code来…
[论文笔记]BitFit
引言
今天带来一篇参数高效微调的论文笔记,论文题目为 基于Transformer掩码语言模型简单高效的参数微调。
BitFit,一种稀疏的微调方法,仅修改模型的偏置项(或它们的子集)。对于小到中等规模数据,应用BitFit去微调预训练的BERT模型能达到(有时超过)微调整个模型。对于大规…
![[论文笔记] Atos: A Task-Parallel GPU Scheduler for Graph Analytics](https://img-blog.csdnimg.cn/68206d5564ea415f8f1b2cbd07d2f33d.png)
[论文笔记] Atos: A Task-Parallel GPU Scheduler for Graph Analytics
Atos: A Task-Parallel GPU Scheduler for Graph Analytics
Atos: 用于图分析的任务并行 GPU 调度程序 [Paper] [Slides] ICPP’22
摘要
提出了 Atos, 一个特别针对动态不规则应用的任务并行 GPU 动态调度框架.
支持消除依赖关系的应用的任务并行公式来暴露额外的并发性除了…
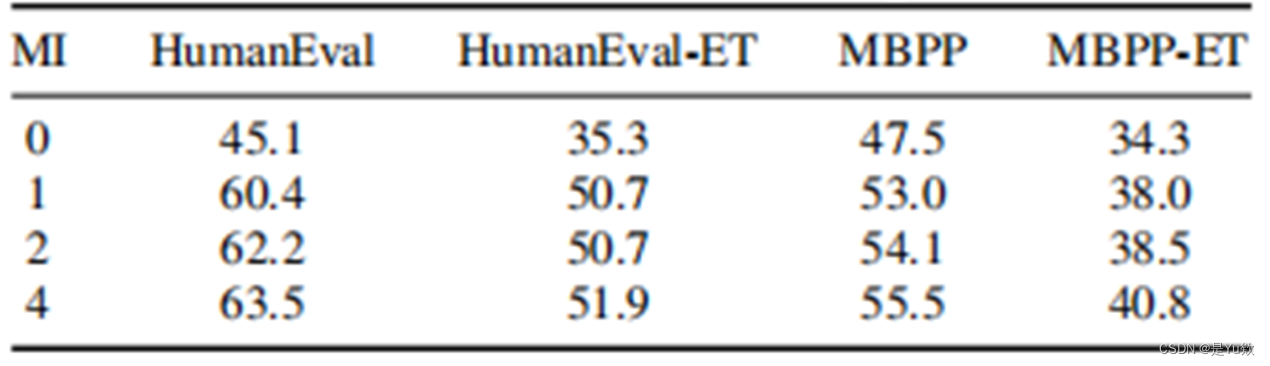
【网安大模型专题10.19】论文3:ChatGPT+自协作代码生成+角色扮演+消融实验
Self-collaboration Code Generation via ChatGPT 写在最前面朋友分享的收获与启发课堂讨论代码生成如何协作,是一种方法吗思路相同交互实用性 代码生成与自协作框架 摘要相关工作PPT学习大语言模型在代码生成方向提高生成的代码的准确性和质量:前期、后…
Zotero拓展功能之Zotero Style
Zotero Style拓展功能
一、列:
1.简介
首先你必须知道Zotero的基本功能:右键任意一个列的名字,会弹出一个右键菜单,你可以勾选/取消勾选一个列,并且在最后有两个按钮,一个是“列设置”,一个是…

Practical Memory Leak Detection using Guarded Value-Flow Analysis 论文阅读
本文于 2007 年投稿于 ACM-SIGPLAN 会议1。
概述
指针在代码编写过程中可能出现以下两种问题: 存在一条执行路径,指针未成功释放(内存泄漏),如下面代码中注释部分所表明的: int foo()
{int *p malloc(4 …
![[论文阅读]Point Density-Aware Voxels for LiDAR 3D Object Detection(PDV)](https://img-blog.csdnimg.cn/2d10cf012dfd44f3afc52db18d40ae65.png)
[论文阅读]Point Density-Aware Voxels for LiDAR 3D Object Detection(PDV)
PDV
Point Density-Aware Voxels for LiDAR 3D Object Detection 论文网址:PDV 论文代码:PDV
简读论文
摘要
LiDAR 已成为自动驾驶中主要的 3D 目标检测传感器之一。然而,激光雷达的发散点模式随着距离的增加而导致采样点云不均匀&#x…
![[论文阅读]MVF——基于 LiDAR 点云的 3D 目标检测的端到端多视图融合](https://img-blog.csdnimg.cn/7efb7e02d08042d99ff4171bcccfec9d.png)
[论文阅读]MVF——基于 LiDAR 点云的 3D 目标检测的端到端多视图融合
MVF
End-to-End Multi-View Fusion for 3D Object Detection in LiDAR Point Clouds 论文网址:MVF 论文代码:
简读论文
这篇论文提出了一个端到端的多视角融合(Multi-View Fusion, MVF)算法,用于在激光雷达点云中进行3D目标检测。论文的主要贡献有两个…
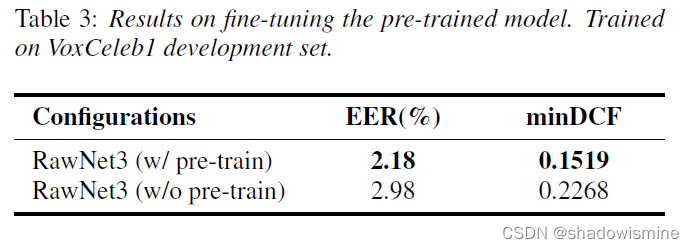
RawNet 1-3 介绍
1. Overview
RawNet: Advanced end-to-end deep neural network using raw waveforms for text-independent speaker verification (RawNet 1) 出自会议:INTERSPEECH 2019.
(论文链接:https://arxiv.org/pdf/1904.0…

降低毕业论文写作压力的终极指南
亲爱的同学们,时光荏苒,转眼间你们即将踏入毕业生的行列。毕业论文作为本科和研究生阶段的重要任务,不仅是对所学知识的综合运用,更是一次对自己学术能力和专业素养的全面考验。然而,论文写作常常伴随着压力和焦虑&…
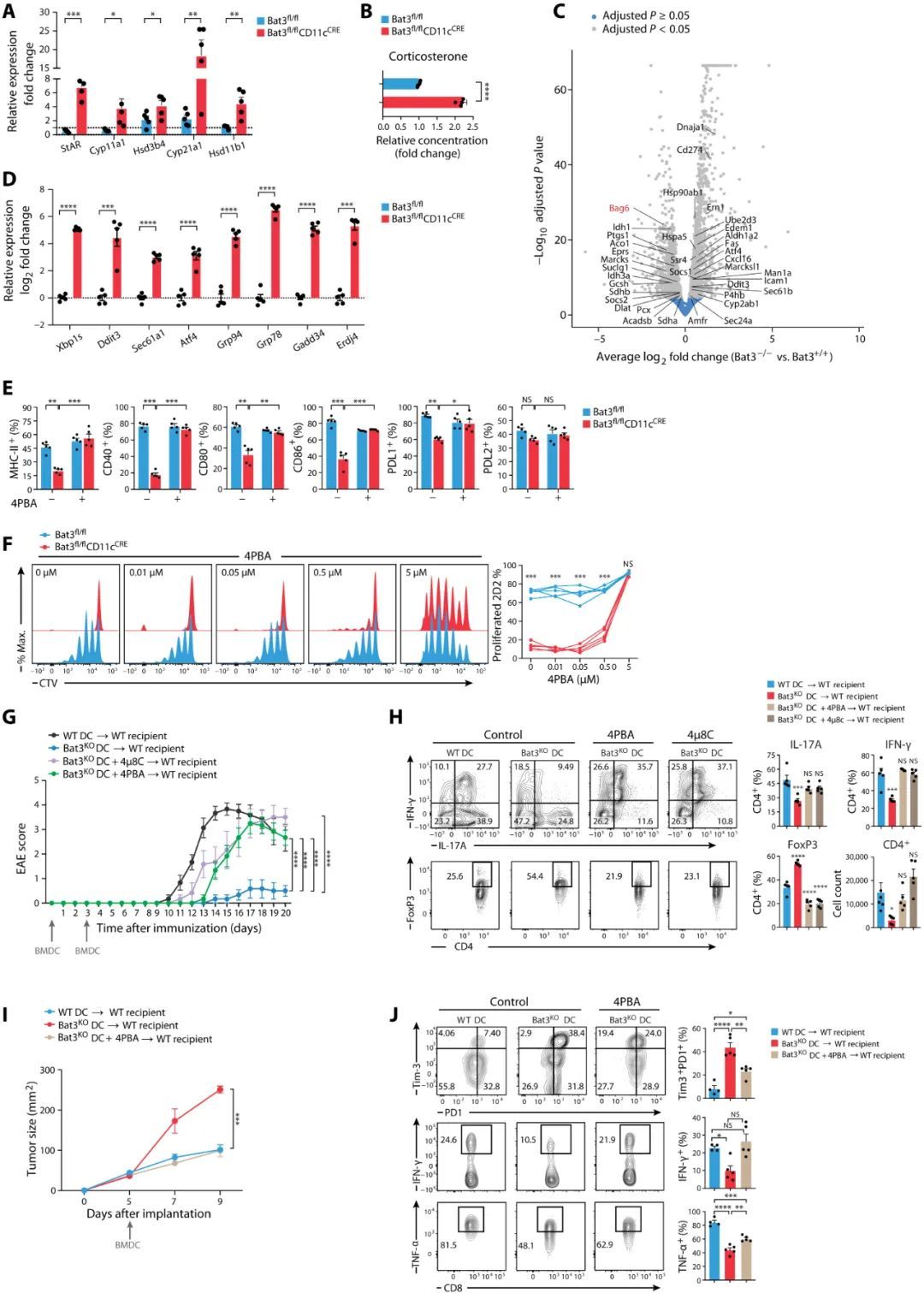
Sci Immunol丨Tim-3 适配器蛋白 Bat3 是耐受性树突状细胞
今天和大家分享一篇发表于2022年3月的文章,题目为“Tim-3 adapter protein Bat3 acts as an endogenous regulator of tolerogenic dendritic cell function”,发表在《Sci Immunol》杂志上。文章主要研究了Tim-3和其适配蛋白Bat3在调节免疫应答中的作用…
7+单细胞分析+预后模型构建+验证实验思路,干湿结合也能拿高分
今天给同学们分享一篇单细胞分析肿瘤预后模型构建验证实验思路的生信文章“Identification of a novel immune-related gene signature for prognosis and the tumor microenvironment in patients with uveal melanoma combining single-cell and bulk sequencing data”&…

一分钟生成PPT,利用人工智能快速提高办公效率(无需第三方插件)
人工智能技术的发展正以惊人的速度改变着我们的世界,今天给大家介绍下利用ChatGPT快速生成PPT的方法,它能够帮助你一键生成PPT内容和漂亮的PPT文档,无需繁琐的设计和排版,只需要与ChatGPT交流,你就能轻松拥有一份令人赞…

海外媒体发稿:10大海外媒体推广秘诀助力你的全球业务飞跃-华媒舍
随着全球化的深入,越来越多的企业开始将目光投向海外市场。而对于海外市场的开拓,海外媒体推广成为一个不可或缺的重要手段。本文将为大家介绍10大海外媒体推广秘诀,助力你的全球业务飞跃。
1. 确定目标受众
要明确你的目标受众是谁。不同的…
论文阅读:Offboard 3D Object Detection from Point Cloud Sequences
目录
概要
Motivation
整体架构流程
技术细节
3D Auto Labeling Pipeline
The static object auto labeling model
The dynamic object auto labeling model
小结 论文地址:[2103.05073] Offboard 3D Object Detection from Point Cloud Sequences (arxiv.o…
Empowering Low-Light Image Enhancer through Customized Learnable Priors 论文阅读笔记
中科大、西安交大、南开大学发表在ICCV2023的论文,作者里有李重仪老师和中科大的Jie Huang(ECCV2022的FEC CVPR2022的ENC和CVPR2023的ERL的一作)喔,看来可能是和Jie Huang同一个课题组的,而且同样代码是开源的…
![论文笔记[156]PARAFAC. tutorial and applications](https://img-blog.csdnimg.cn/62c9ad9a573741e78993eb571431a58f.png)
论文笔记[156]PARAFAC. tutorial and applications
原文下载:https://www.sciencedirect.com/science/article/abs/pii/S0169743997000324
摘要
本文介绍了PARAFAC的多维分解方法及其在化学计量学中的应用。PARAFAC是PCA对高阶数组的推广,但该方法的一些特性与普通的二维情况截然不同。例如,…
双热点机制结合。5+铜死亡+铁死亡相关基因生信思路
今天给同学们分享一篇结合铜死亡和铁死亡相关基因预测肿瘤预后、免疫和药敏的生信文章“A novel signature of combing cuproptosis- with ferroptosis-related genes for prediction of prognosis, immunologic therapy responses and drug sensitivity in hepatocellular car…
论文阅读-FCD-Net: 学习检测多类型同源深度伪造人脸图像
一、论文信息
论文题目:FCD-Net: Learning to Detect Multiple Types of Homologous Deepfake Face Images
作者团队:Ruidong Han , Xiaofeng Wang , Ningning Bai, Qin Wang, Zinian Liu, and Jianru Xue (西安理工大学,西安交…
![论文笔记与复现[156]PARAFAC. tutorial and applications](https://img-blog.csdnimg.cn/e9db131fc8af4ce4bfa1f9652003da6e.png)
论文笔记与复现[156]PARAFAC. tutorial and applications
原文下载:https://www.sciencedirect.com/science/article/abs/pii/S0169743997000324
摘要
本文介绍了PARAFAC的多维分解方法及其在化学计量学中的应用。PARAFAC是PCA向高阶数组的推广,但该方法的一些特性与普通的二维情况截然不同。例如,…
(论文阅读13/100)R-CNN minus R
文献阅读笔记 简介 题目 R-CNN minus R 作者 Karel Lenc Andrea Vedaldi 原文链接 https://arxiv.org/pdf/1506.06981.pdf 关键词 Null 研究问题 proposal generation在基于CNN的探测器中的作用,以确定它是否是一个必要的建模组件。 R-CNN留下的几个有趣…
PointNet++ 论文阅读
论文链接
PointNet 0. Abstract
**背景:**PointNet的设计并未捕捉到度量空间中存在的局部结构,限制了其识别细粒度模式和适用于复杂场景的能力
解决思路:
引入了一种分层神经网络,该网络在输入点集的嵌套分割上递归地应用Poin…

(论文阅读29/100 人体姿态估计)
29.文献阅读笔记 简介 题目 DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation 作者 Leonid Pishchulin, Eldar Insafutdinov, Siyu Tang, Bjoern Andres, Mykhaylo Andriluka, Peter Gehler, and Bernt Schiele, CVPR, 2016. 原文链接 h…
DALL-E 3: 管窥蠡测OpenAI open的一个文生图小口
DALL-E 3 DALL-E 3总览摘要1 引言 DALL-E 3
总览
题目: Improving Image Generation with Better Captions 机构:OpenAI,微软 论文: https://cdn.openai.com/papers/dall-e-3.pdf 任务: 文本生成图像 特点: 前置相关工作:DALL-E,…
探讨m6调控因子与人类癌症之间的因果关系,纯生信也能轻松上5+
今天给同学们分享一篇生信文章“m6A Regulators Is Differently Expressed and Correlated With Immune Response of Esophageal Cancer”,这篇文章发表在Front Cell Dev Biol期刊上,影响因子为5.5。 结果解读: m6A调控因子在基因组中的异常与…
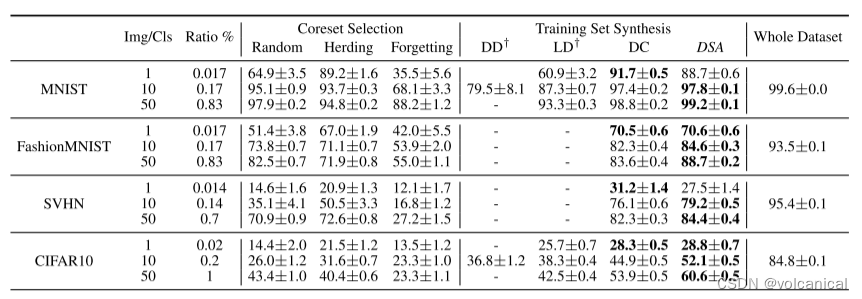
《Dataset Condensation with Differentiable Siamese Augmentation》
《Dataset Condensation with Differentiable Siamese Augmentation》 在本文中,我们专注于将大型训练集压缩成显著较小的合成集,这些合成集可以用于从头开始训练深度神经网络,性能下降最小。受最近的训练集合成方法的启发,我们提…
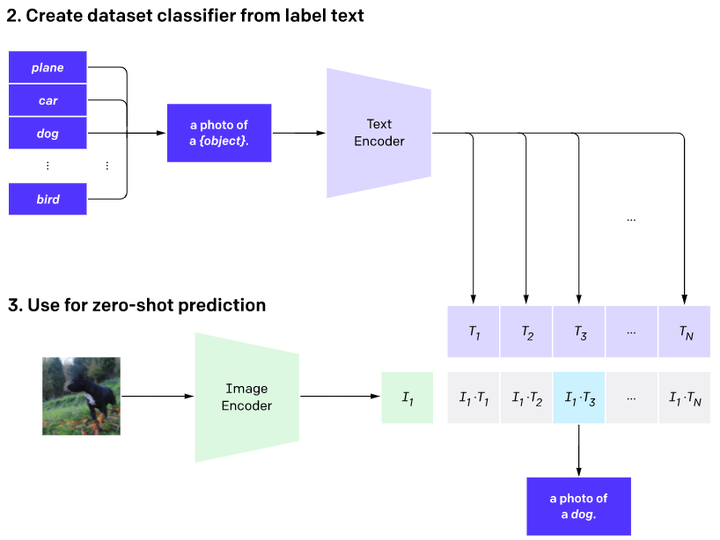
【论文阅读】DALL·E: Zero-Shot Text-to-Image Generation
OpenAI第一代文本生成图片模型
paper:https://arxiv.org/abs/2102.12092 DALLE有120亿参数,基于自回归transformer,在2.5亿 图片-文本对上训练的。实现了高质量可控的text to image,同时也有zero-shot的能力。
DALL-E没有使用扩…
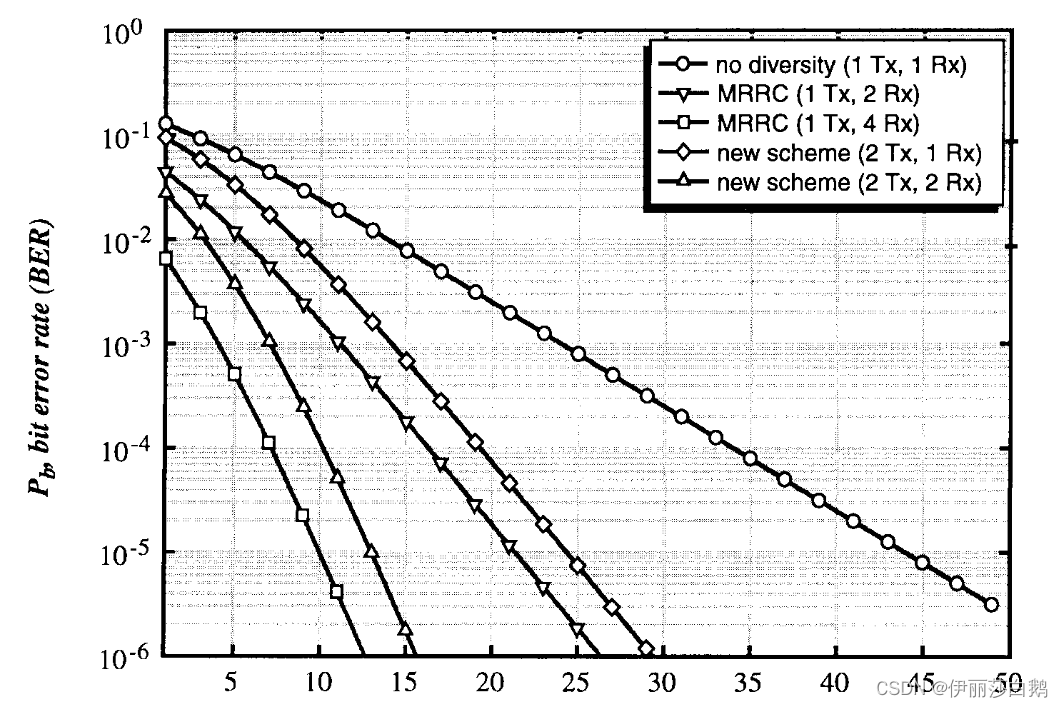
论文阅读-- A simple transmit diversity technique for wireless communications
一种简单的无线通信发射分集技术
论文信息: Alamouti S M. A simple transmit diversity technique for wireless communications[J]. IEEE Journal on selected areas in communications, 1998, 16(8): 1451-1458.
创新性:
提出了一种新的发射分集方…
论文阅读(一)城市干道分段绿波协调控制模型研究
[1]酆磊,赵欣,李林等.城市干道分段绿波协调控制模型研究[J].武汉理工大学学报(交通科学与工程版),2021,45(06):1034-1038.
主要内容:该文介绍了基于绿波带宽和关联度的城市干道分段绿波协调控制模型。通过将主干道划分为不同子区域,并根据路段特点进行精准化控制,实现了分段…
《论文阅读》同情对话生成的知识桥梁 AAAI 2021
《论文阅读》同情对话生成的知识桥梁 AAAI 2021 前言简介基础知识Emotional DG 和Empathetic DG 的不同外部知识最小最大正则化模型架构Emotional Context GraphEmotional Context EncoderEmotional context graph encodingEmotional signal perceptionEmotion-dependency deco…
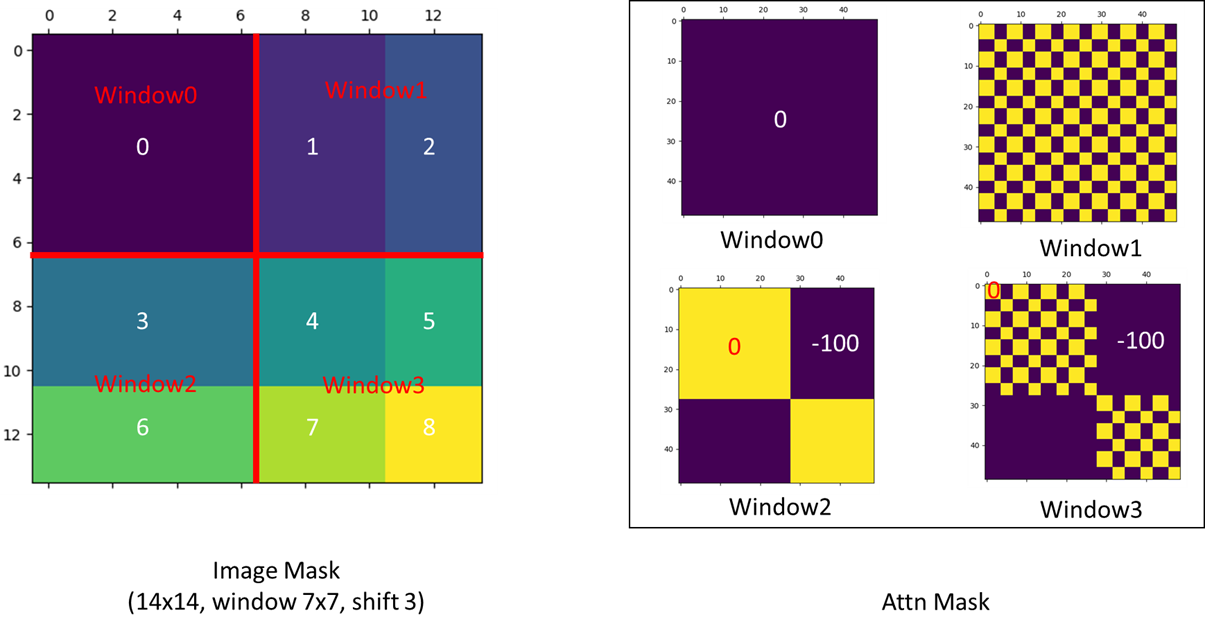
《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》阅读笔记
论文标题
《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》
Swin 这个词貌似来自后面的 Shifted WindowsShifted Windows:移动窗口Hierarchical:分层
作者
微软亚洲研究院出品
初读
摘要 提出 Swin Transformer 可以…
【论文阅读】Generating Radiology Reports via Memory-driven Transformer (EMNLP 2020)
资料链接
论文原文:https://arxiv.org/pdf/2010.16056v2.pdf 代码链接(含数据集):https://github.com/cuhksz-nlp/R2Gen/
背景与动机 这篇文章的标题是“Generating Radiology Reports via Memory-driven Transformer”…
「NLP+网安」相关顶级会议期刊 投稿注意事项+会议等级+DDL+提交格式
「NLP网安」相关顶级会议&期刊投稿注意事项 写在最前面一、会议ACL (The Annual Meeting of the Association for Computational Linguistics)IH&MMSec (The ACM Workshop on Information Hiding, Multimedia and Security)CCS (The ACM Conference on Computer and Co…

【科研新手指南3】chatgpt辅助论文优化表达
chatgpt辅助论文优化表达 写在最前面最终版什么是好的论文整体上:逻辑/连贯性细节上一些具体的修改例子 一些建议,包括具体的提问范例1. 明确你的需求2. 提供上下文信息3. 明确问题类型4. 测试不同建议5. 请求详细解释综合提问范例: 常规技巧…
【论文阅读】GAIN: Missing Data Imputation using Generative Adversarial Nets
论文地址:[1806.02920] GAIN: Missing Data Imputation using Generative Adversarial Nets (arxiv.org)

【论文阅读】(VAE)Auto-Encoding Variational Bayes
论文地址:[1312.6114] Auto-Encoding Variational Bayes (arxiv.org) 【前言】:VAE模型是Kingma(也是Adam的作者)大神在2014年发表的文章,是一篇非常非常经典,且实现非常优雅的生成模型,同时它还为bayes概率图模型难以…

论文笔记:Deep Trajectory Recovery with Fine-Grained Calibration using Kalman Filter
TKDE 2021
1 intro
1.1 背景
用户轨迹数据对于改进以用户为中心的应用程序很有用 POI推荐城市规划路线规划由于设备和环境的限制,许多轨迹以低采样率记录 采样的轨迹无法详细说明物体的实际路线增加了轨迹中两个连续采样点之间的不确定性——>开发有效的算法以…
(论文阅读32/100)Flowing convnets for human pose estimation in videos
32.文献阅读笔记 简介 题目 Flowing convnets for human pose estimation in videos 作者 Tomas Pfister, James Charles, and Andrew Zisserman, ICCV, 2015. 原文链接 https://arxiv.org/pdf/1506.02897.pdf 关键词 Human Pose Estimation in Videos 研究问题 视频…
FSOD论文阅读 - 基于卷积和注意力机制的小样本目标检测
来源:知网
标题:基于卷积和注意力机制的小样本目标检测 作者:郭永红,牛海涛,史超,郭铖 郭永红,牛海涛,史超,郭铖.基于卷积和注意力机制的小样本目标检测 [J/OL].兵工学报. https://…
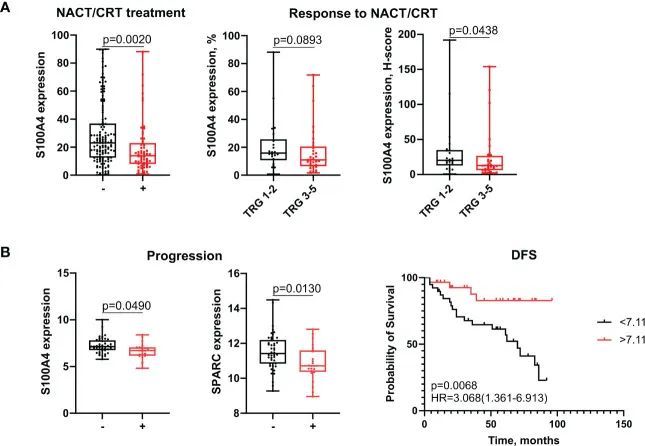
参考意义大。4+巨噬细胞相关生信思路,简单易复现。
今天给同学们分享一篇生信文章“Angiogenesis regulators S100A4, SPARC and SPP1 correlate with macrophage infiltration and are prognostic biomarkers in colon and rectal cancers”,这篇文章发表在Front Oncol期刊上,影响因子为4.7。 结果解读&a…
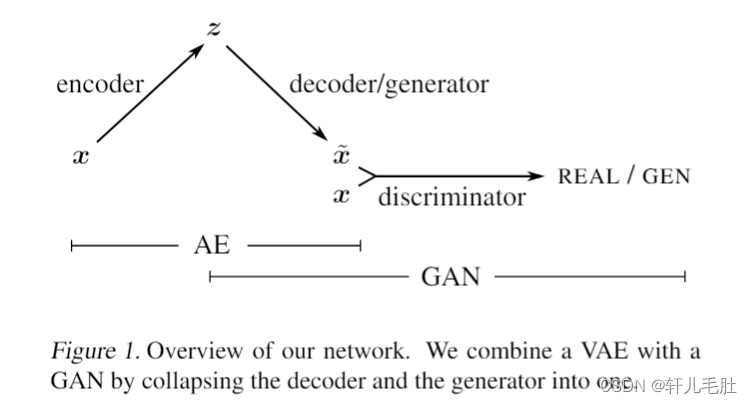
【论文阅读】(VAE-GAN)Autoencoding beyond pixels using a learned similarity metric
论文地址;[1512.09300] Autoencoding beyond pixels using a learned similarity metric (arxiv.org) /
一、Introduction
主要讲了深度学习中生成模型存在的问题,即常用的相似度度量方式(使用元素误差度量)对于学习良好的生成模型存在一定…
(论文阅读19/100)Speed/accuracy trade-offs for modern convolutional object detectors
文献阅读笔记 简介 题目 Speed/accuracy trade-offs for modern convolutional object detectors 作者 Jonathan Huang, Vivek Rathod, Chen Sun, Menglong Zhu, Anoop Korattikara, Alireza Fathi, Ian Fischer, Zbigniew Wojna, Yang Song, Sergio Guadarrama, Kevin Mu…
《论文阅读》监督对抗性对比学习在对话中的情绪识别 ACL2023
《论文阅读》监督对抗性对比学习在对话中的情绪识别 前言摘要相关知识最坏样本干扰监督对比学习生成式对抗网络纳什均衡琴森香农散度范式球模型架构监督对抗性对比学习模型结构图实验结果问题前言
你是否也对于理解论文存在困惑?
你是否也像我之前搜索论文解读,得到只是中文…
论文阅读--深度学习基础文献
AlphaGo Zero
论文信息:Silver D, Schrittwieser J, Simonyan K, et al. Mastering the game of go without human knowledge[J]. nature, 2017, 550(7676): 354-359. 参考文章: 深入浅析AlphaGo Zero与深度强化学习 AlphaGo Zero论文解析
Attention i…
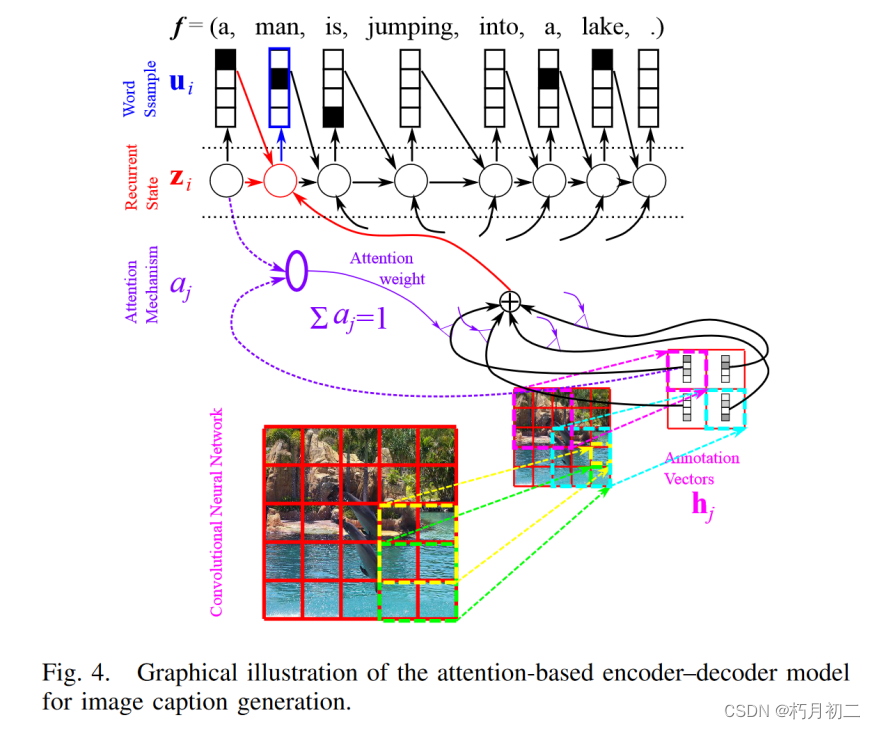
(论文阅读51-57)图像描述3 53
51.文献阅读笔记(KNN) 简介 题目 Exploring Nearest Neighbor Approaches for Image Captioning 作者 Jacob Devlin, Saurabh Gupta, Ross Girshick, Margaret Mitchell, C. Lawrence Zitnick, arXiv:1505.04467 原文链接 http://arxiv.org/pdf/1…
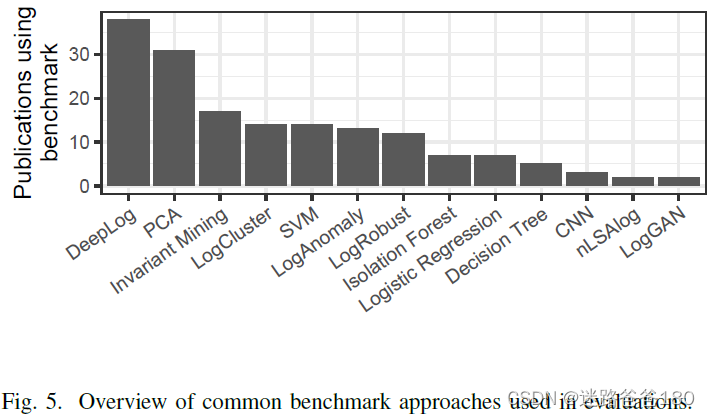
01-论文阅读-Deep learning for anomaly detection in log data: a survey
01-论文阅读-Deep learning for anomaly detection in log data: a survey 文章目录 01-论文阅读-Deep learning for anomaly detection in log data: a survey摘要I 介绍II 背景A 初步定义B 挑战 III 调查方法A 搜索策略B 审查的功能 IV 调查结果A 文献计量学B 深度学习技术C …
[论文阅读]Ghost-free High Dynamic Range Imaging with Context-aware Transformer
多帧高动态范围成像(High Dynamic Range Imaging, HDRI/HDR)旨在通过合并多幅不同曝光程度下的低动态范围图像,生成具有更宽动态范围和更逼真细节的图像。如果这些低动态范围图像完全对齐,则可以很好地融合为HDR图像,但…
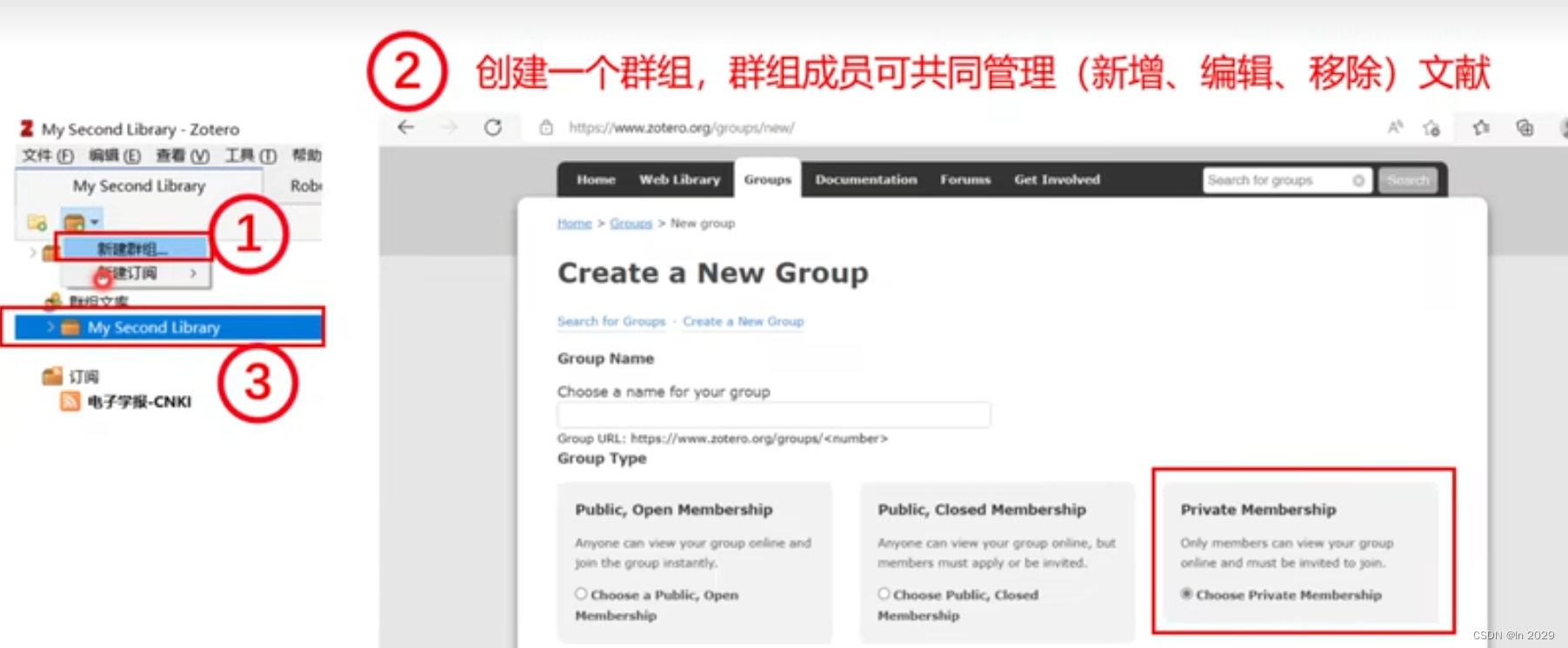
Zotero详细功能补充!熟练使用!【进阶版,持续更新】
Zotero安装请参见文章Zotero安装
1.改变条目文件夹
如果直接选择条目直接进行移动,能移动成功,但是原来文件夹和目标文件夹都会存在,实际是复制! 如果只想保留在一个文件夹里面,可以选中条目,右击-从分…
论文复现代码《基于自适应哈夫曼编码的密文可逆信息隐藏算法》导演剪辑版
前言
本篇是论文《基于自适应哈夫曼编码的密文可逆信息隐藏算法》复现代码的精简版本。 内含调试过程的代码在这里:
论文复现代码《基于自适应哈夫曼编码的密文可逆信息隐藏算法》调试版-CSDN博客
论文的解析文章在这里:
论文简述基于自适应哈夫曼编…

【网安AIGC专题】46篇前沿代码大模型论文、24篇论文阅读笔记汇总
网安AIGC专题 写在最前面一些碎碎念课程简介 0、课程导论1、应用 - 代码生成2、应用 - 漏洞检测3、应用 - 程序修复4、应用 - 生成测试5、应用 - 其他6、模型介绍7、模型增强8、数据集9、模型安全 写在最前面 本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,…

【论文阅读笔记】InstructDiffusion: A Generalist Modeling Interface for Vision Tasks
【论文阅读笔记】StyleAvatar3D: Leveraging Image-Text Diffusion Models for High-Fidelity 3D Avatar Generation 论文阅读笔记论文信息引言动机挑战 方法结果 关键发现相关工作1. 视觉语言基础模型2. 视觉通用模型 方法/模型视觉任务的统一说明训练数据构建网络结构 实验设…
![[论文阅读]CBAM——代码实现和讲解](https://img-blog.csdnimg.cn/7f281c9531f3497bba6ffa958599746e.png)
[论文阅读]CBAM——代码实现和讲解
CBAM
论文网址:CBAM 论文代码:CBAM 本文提出了一种卷积块注意力模块(CBAM),它是卷积神经网络(CNN)的一种轻量级、高效的注意力模块。该模块沿着通道和空间两个独立维度依次推导注意力图&#x…
【论文阅读】An Experimental Survey of Missing Data Imputation Algorithms
论文地址:An Experimental Survey of Missing Data Imputation Algorithms | IEEE Journals & Magazine | IEEE Xplore 处理缺失数据最简单的方法就是是丢弃缺失值的样本,但这会使得数据更加不完整并且导致偏差或影响结果的代表性。因此,…
(论文阅读23/100)Hierarchical Convolutional Features for Visual Tracking
文献阅读笔记(分层卷积特征) 简介 题目 Hierarchical Convolutional Features for Visual Tracking 作者 Chao Ma, Jia-Bin Huang, Xiaokang Yang and Ming-Hsuan Yang 原文链接 arxiv.org/pdf/1707.03816.pdf 关键词 Hierarchical convolution…
Safe and Practical GPU Computation in TrustZone论文阅读笔记
Safe and Practical GPU Computation in TrustZone 背景知识: youtube GR视频讲解链接:ASPLOS’22 - Session 2A - GPUReplay: A 50-KB GPU Stack for Client ML - YouTube GPU软件栈: 概念:"GPU软件栈"指的是与GPU硬件…

【论文阅读】CAN网络中基于时序信道的隐蔽认证算法
文章目录 摘要一、引言和动机A 相关工作 二、背景及实验设置A 以前工作中的时钟偏差和局限性B.最坏到达时间C.安装组件 三、优化流量分配A.问题陈述B.优化帧调度 四、协议和结果A.主协议B.对手模型C. 优化流量和单一发送者的结果D.多发送方情况和噪声信道E.信道数据速率&#x…
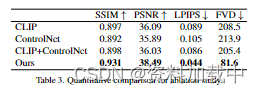
【论文解读】角色动画的一致可控的图像到视频合成
论文:https://arxiv.org/pdf/2311.17117.pdf 代码:https://github.com/HumanAIGC/AnimateAnyone 图片解释:给定参考图像(每组中最左边的图像)的一致且可控的角色动画结果。我们的方法能够对任意角色进行动画处理&#…
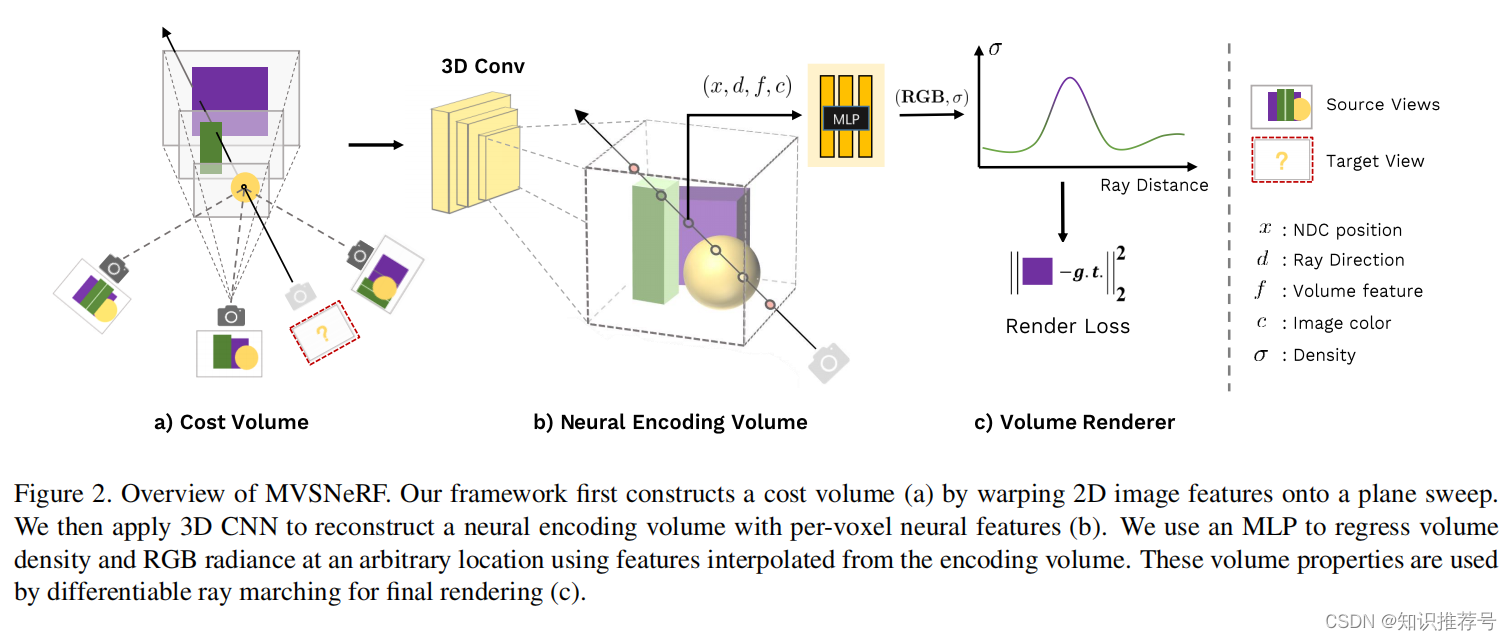
MVSNeRF:多视图立体视觉的快速推广辐射场重建(2021年)
MVSNeRF:多视图立体视觉的快速推广辐射场重建(2021年) 摘要1 引言2 相关工作3 MVSNeRF实现方法3.1 构建代价体3.2 辐射场的重建 Anpei Chen and Zexiang Xu and Fuqiang Zhao et al. MVSNeRF: Fast Generalizable Radiance Field Reconstruct…
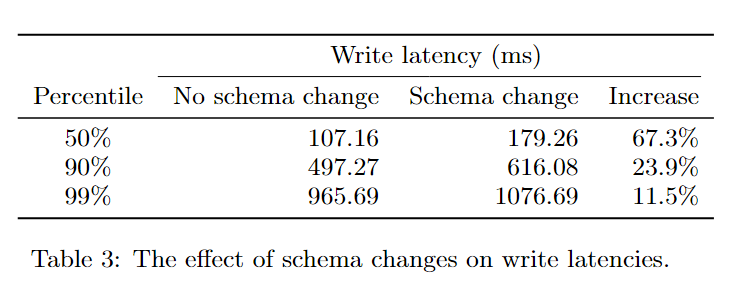
【论文阅读VLDB13】Online, Asynchronous Schema Change in F1
Online, Asynchronous Schema Change in F1
ABSTRACT
在一个globally 分布式数据库,with shared data, stateless servers, and no global membership.进行一个schema演变。证明许多常见的模式更改可能会导致异常和数据库损坏,通过将破坏引起的模式更改…

【文章学习系列之模型】TimeGPT-1
本章内容 文章概况模型结构数据集实验结果调包使用一般性报错API报错 总结 文章概况
《TimeGPT-1》是2023年公开于arXiv的一篇文章,该文章以chatgpt为灵感,提出一种基础时序大模型TimeGPT。该方案的提出致力于解决数据集规模不够大、模型泛化能力不强以…

你的轻量化设计能有效提高模型的推理速度吗?
写在前面:本博客仅作记录学习之用,部分图片来自网络,如需引用请注明出处,同时如有侵犯您的权益,请联系删除! 文章目录 前言预备知识模型指标MACs计算卷积MACs全连接MACs激活函数MACsBN MACs 存储访问存储构…
![[论文阅读]BEVFusion](https://img-blog.csdnimg.cn/direct/7da3ac93c5bc416f98f79c93e0158589.png)
[论文阅读]BEVFusion
BEVFusion
BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework BEVFusion:简单而强大的激光雷达相机融合框架 论文网址:BEVFusion 论文代码:BEVFusion
简读论文 论文背景:激光雷达和摄像头是自动驾驶系统中常用的两…
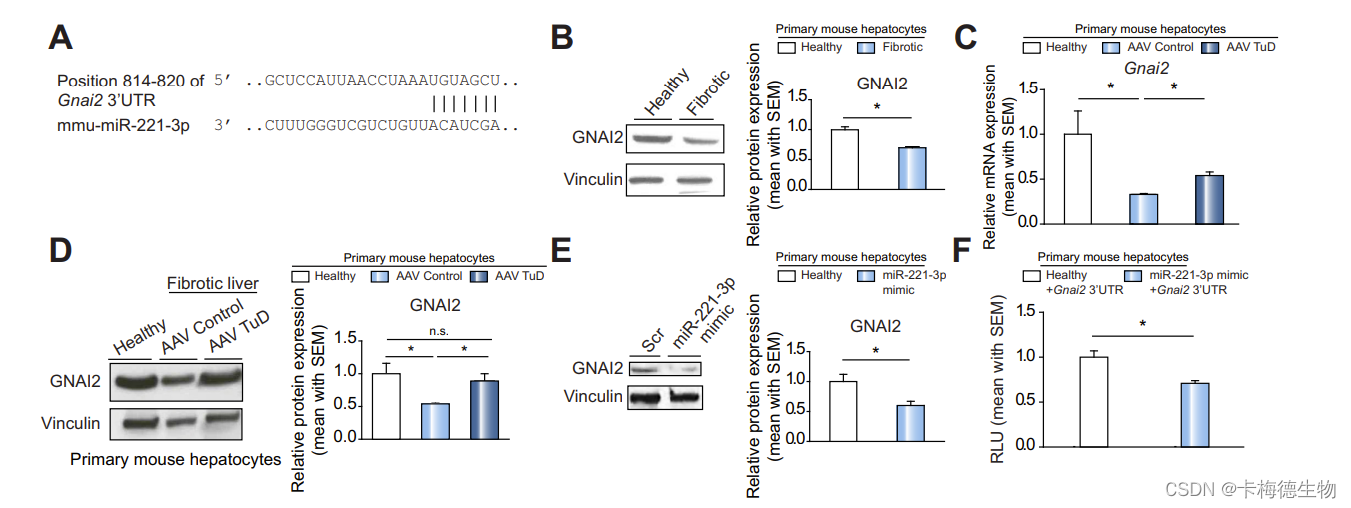
双荧光素酶报告基因检测(二)
双荧光素酶实验通常被用来评估miRNA是否与其潜在的靶基因发生相互作用。实验中,预测的miRNA靶标基因的3’-UTR序列被克隆到含有萤火虫荧光素酶的报告基因载体的3’-UTR位置。如果miRNA与插入到质粒中的目标序列发生结合,miRNA将通过抑制该序列的翻译来降…

PairLIE论文阅读笔记
PairLIE论文阅读笔记 论文为2023CVPR的Learning a Simple Low-light Image Enhancer from Paired Low-light Instances.论文链接如下: openaccess.thecvf.com/content/CVPR2023/papers/Fu_Learning_a_Simple_Low-Light_Image_Enhancer_From_Paired_Low-Light_Instan…
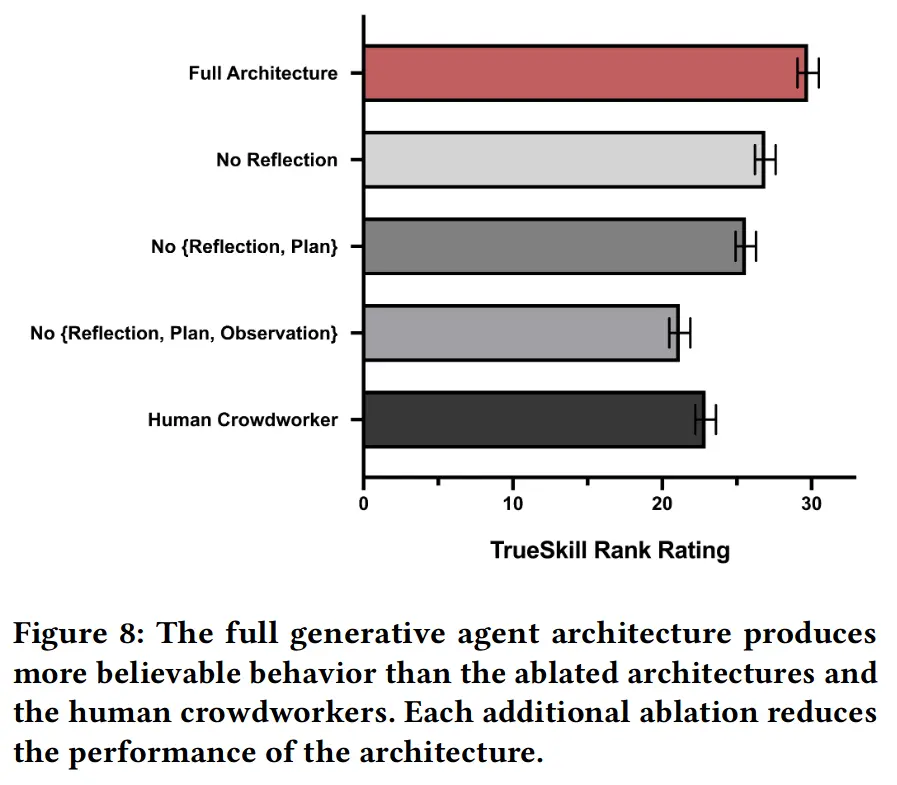
论文阅读_生成式Agent
英文名称: Generative Agents: Interactive Simulacra of Human Behavior
中文名称: 生成代理:**人类行为的交互式模拟**
文章: http://arxiv.org/abs/2304.03442
代码: https://github.com/joonspk-research/generative_agents
作者: Joon Sung Park
机构: 斯坦福大…
物联网中基于信任的安全性调查研究:挑战与问题
A survey study on trust-based security in Internet of Things: Challenges and issues 文章目录 a b s t r a c t1. Introduction2. Related work3. IoT security from the one-stop dimension3.1. Output data related security3.1.1. Confidentiality3.1.2. Authenticity …

Unsupervised MVS论文笔记(2019年)
Unsupervised MVS论文笔记(2019年) 摘要1 引言2 相关工作3 实现方法3.1 网络架构3.2 通过光度一致性学习3.3 MVS的鲁棒光度一致性3.4 学习设置和实施的细节3.5.预测每幅图像的深度图 4 实验4.1 在DTU上的结果4.2 消融实验4.3 在ETH3D数据集上的微调4.4 在…

Unsupervised Skill Discovery via Recurrent Skill Training论文笔记
Zheyuan Jiang, Jingyue Gao, Jianyu Chen (2022). Unsupervised Skill Discovery via Recurrent Skill Training. In Conference on Neural Information Processing Systems (NeurIPS), 2022.
通过循环技能训练发现无监督技能
1、Motivation
以往的无监督技能发现方法主要使…

科研工具推荐之ReadPaper
科研工具推荐之ReadPaper
之前也用很多朋友在问英文文献如何阅读,一直推荐的是Adobe PDF有道翻译。
但是呢,最近了解到了另外一个神器 ReadPaper 自己稍微体验了一下 感觉非常nice,特此推荐给大家。
想体验的朋友可以通过下面的方式注册呢…
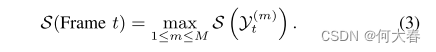
Making Reconstruction-based Method Great Again for Video Anomaly Detection
Making Reconstruction-based Method Great Again for Video Anomaly Detection
文章信息: 发表于ICDM 2022(CCF B会议) 原文地址:https://arxiv.org/abs/2301.12048 代码地址:https://github.com/wyzjack/MRMGA4VAD…
![[论文阅读]VoxSet——Voxel Set Transformer](https://img-blog.csdnimg.cn/direct/3ac5184eebf3409ab1b15a933c212f63.png)
[论文阅读]VoxSet——Voxel Set Transformer
VoxSet
Voxel Set Transformer: A Set-to-Set Approach to 3D Object Detection from Point Clouds 论文网址:VoxSet 论文代码:VoxSet
简读论文
这篇论文提出了一个称为Voxel Set Transformer(VoxSeT)的3D目标检测模型,主要有以下几个亮点: 提出了基于…
[论文笔记] tiktoken中的gpt4 tokenizer
亲测可用!!!!! 注意是bytelevel的BPE!! 只有vocab.json是不ok的,只能encode单字节的字符,对于中文这种会encode之后tokens,ids都是[]。
gpt-tokenizer - npm
GitHub - openai/tiktoken: tiktoken is a fast BPE tokeniser for use with OpenAIs models.
GitHub - …

论文阅读《High-frequency Stereo Matching Network》
论文地址:https://openaccess.thecvf.com/content/CVPR2023/papers/Zhao_High-Frequency_Stereo_Matching_Network_CVPR_2023_paper.pdf 源码地址: https://github.com/David-Zhao-1997/High-frequency-Stereo-Matching-Network 概述 在立体匹配研究领域…

【论文阅读】Video-to-Video Synthesis
基于条件GAN的视频到视频生成。
introduce 总结:基于条件GAN的视频到视频生成。将视频到视频的合成问题视为一个分布匹配问题。 动机:GAN生成的视频很难保证前后帧的一致性,容易出现抖动。本文加入前后帧的光流信息作为约束。Vid2Vid作为pix…

Paper Reading: (ACRST) 基于自适应类再平衡自训练的半监督目标检测
目录 简介工作重点方法CropBankFBRAFFRTwo-stage Pseudo-label Filtering 实验与SOTA比较消融实验 简介
题目:《Semi-Supervised Object Detection with Adaptive Class-Rebalancing Self-Training》,AAAI’22, 基于自适应类再平衡自训练的半…

论文阅读《Masked representation learning for domain generalized stereo matching》
论文地址:https://openaccess.thecvf.com/content/CVPR2023/html/Rao_Masked_Representation_Learning_for_Domain_Generalized_Stereo_Matching_CVPR_2023_paper.html 概述 近年来,立体匹配的领域泛化能力受到了越来越多的关注,但是现有的方…
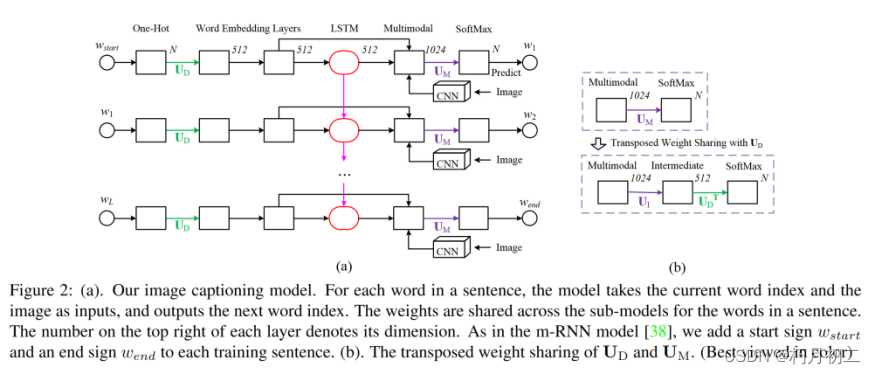
(论文阅读46-50)图像描述2
46.文献阅读笔记 简介 题目 Learning a Recurrent Visual Representation for Image Caption Generation 作者 Xinlei Chen, C. Lawrence Zitnick, arXiv:1411.5654. 原文链接 http://www.cs.cmu.edu/~xinleic/papers/cvpr15_rnn.pdf 关键词 2014年rnn图像特征和文本特…
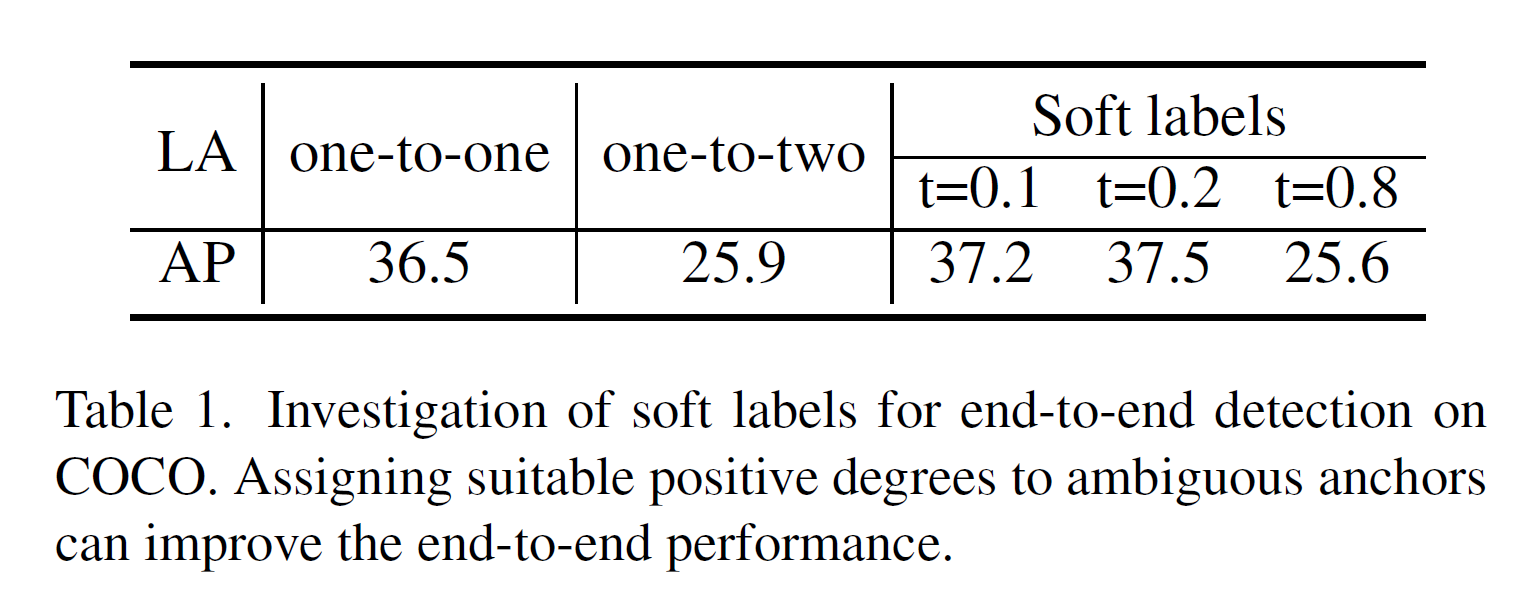
One-to-Few Label Assignment for End-to-End Dense Detection阅读笔记
One-to-Few Label Assignment for End-to-End Dense Detection阅读笔记
Abstract
一对一(o2o)标签分配对基于变换器的端到端检测起着关键作用,最近已经被引入到全卷积检测器中,用于端到端密集检测。然而,o2o可能因为…
Video Summarise 入门
Video Summarise 入门 DefinitionAchieve methodWhat can chatgpt do for Video Summarise?Literatures Definition
“Video summarization” refers to the process of creating a concise and condensed representation of a video, capturing its essential content, key …
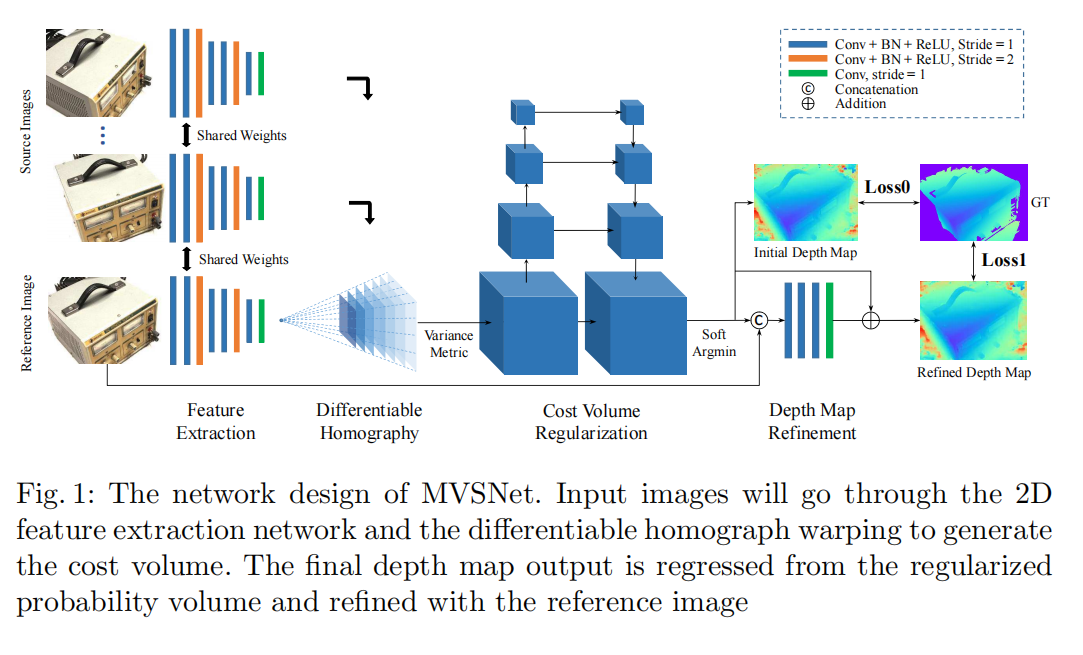
MVSNet论文笔记
MVSNet论文笔记 摘要1 引言2 相关基础2.1 多视图立体视觉重建(MVS Reconstruction)2.2 基于学习的立体视觉(Learned Stereo)2.3 基于学习的多视图的立体视觉(Learned MVS) Yao, Y., Luo, Z., Li, S., Fang,…
![[论文笔记] chatgpt系列 SparseMOE—GPT4的MOE结构](https://img-blog.csdnimg.cn/direct/d340aaa05f8647e89b5604ab3a333816.png)
[论文笔记] chatgpt系列 SparseMOE—GPT4的MOE结构
SparseMOE: 稀疏激活的MOE Swtich MOE,所有token要在K个专家网络中,选择一个专家网络。 显存增加。 Experts Choice:路由MOE: 由专家选择token。这样不同的专家都选择到某个token,也可以不选择该token。 由于FFN层的时间复杂度和attention层不同,FFN层的时…
NLP论文阅读记录 - AAAI 23 | 02 SUMREN:总结有关新闻事件的报道演讲
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.相关工作2.1新闻摘要2.2 以查询为中心的摘要2.3 新闻归因 三.本文方法3.1 SumREN 基准3.1.1基准建设3.1.2 统计3.1.3 银牌训练数据生成 3.2 Models3.2.1以查询为中心的摘要基线3.2.2 基于管道…

BEVFormerV2 论文阅读
论文链接
BEVFormer v2: Adapting Modern Image Backbones to Bird’s-Eye-View Recognition via Perspective Supervision
0. Abstract
提出了一种新颖的 BEV 检测器,具有透视监督,收敛速度更快,更适合现代图像基础架构优先考虑通过引入透…
论文阅读<CF-YOLO: Cross Fusion YOLO for Object Detection in Adverse Weather.....>
论文链接:https://arxiv.org/pdf/2309.08152.pdfhttps://arxiv.org/pdf/2206.01381.pdfhttps://arxiv.org/pdf/2309.08152.pdf
代码链接:https://github.com/DiffPrompter/diff-prompter
目前没有完整代码放出。 恶劣天气下的目标检测主要有以下三种解…

【论文阅读】Reachability and distance queries via 2-hop labels
Cohen E, Halperin E, Kaplan H, et al. Reachability and distance queries via 2-hop labels[J]. SIAM Journal on Computing, 2003, 32(5): 1338-1355. Abstract
图中的可达性和距离查询是许多应用的基础,从地理导航系统到互联网路由。其中一些应用程序涉及到巨…
论文笔记--Learning Political Polarization on Social Media Using Neural Networks
论文笔记--Learning Political Polarization on Social Media Using Neural Networks 1. 文章简介2. 文章概括3. 相关工作4. 文章重点技术4.1 Collection of posts4.1.1 数据下载4.1.2 数据预处理4.1.3 统计显著性分析 4.2 Classification of Posts4.3 Polarization of users 5…

多模态统计图表综述:图表分类,图表理解,图表生成,图表大一统模型
Overview 多模态统计图表综述一、图表分类1.1 Survey1.2 常见分类数据集:1.3 常见图表类型 二、图表理解2.1 VQA2..1.1 DVQA CVPR20182.1.2 PlotQA 20192.1.3 ChartQA 2022 2.2 Summary2.2.1 Chart-to-text ACL 2022 三、图表生成四、图表大一统模型4.1 UniChart 20…
【论文阅读】Answering Label-Constraint Reachability in Large Graphs
Xu K, Zou L, Yu J X, et al. Answering label-constraint reachability in large graphs[C]//Proceedings of the 20th ACM international conference on Information and knowledge management. 2011: 1595-1600. Abstract
在本文中,我们研究了可达性查询的一种变…
论文阅读:PointCLIP: Point Cloud Understanding by CLIP
CVPR2022
链接:https://arxiv.org/pdf/2112.02413.pdf
0、Abstract 最近,通过对比视觉语言预训练(CLIP)的零镜头学习和少镜头学习在2D视觉识别方面表现出了鼓舞人心的表现,即学习在开放词汇设置下将图像与相应的文本匹配。然而,…
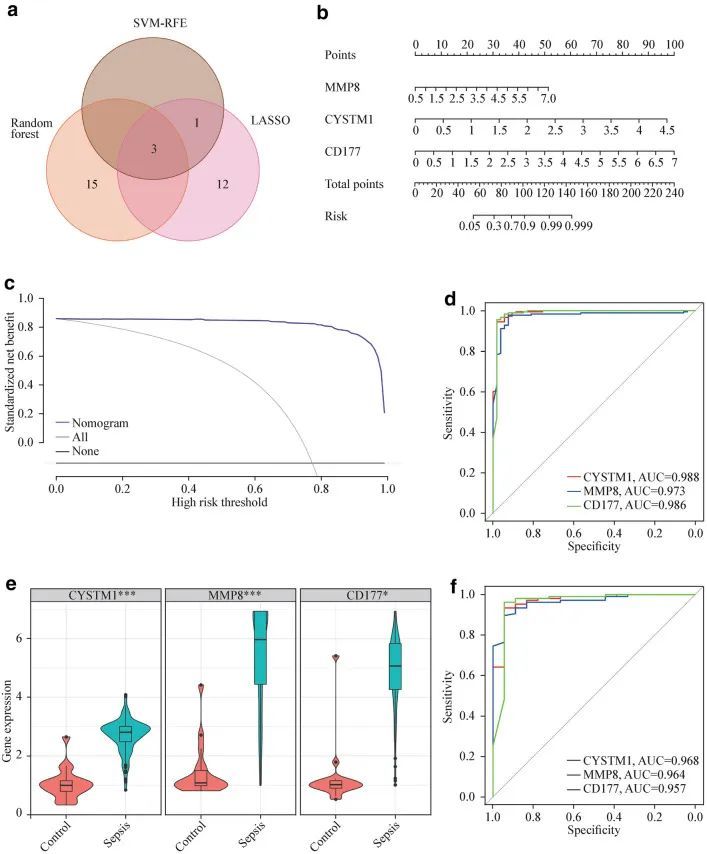
非肿瘤纯生信也能拿8+机器学习是关键
今天给同学们分享一篇生信文章“Analysis and validation of diagnostic biomarkers and immune cell infiltration characteristics in pediatric sepsis by integrating bioinformatics and machine learning”,这篇文章发表在World J Pediatr期刊上,影…
【论文阅读】O’Reach: Even Faster Reachability in Large Graphs
Hanauer K, Schulz C, Trummer J. O’reach: Even faster reachability in large graphs[J]. ACM Journal of Experimental Algorithmics, 2022, 27: 1-27. Abstract
计算机科学中最基本的问题之一是可达性问题:给定一个有向图和两个顶点s和t,s可以通过…
[论文笔记] 大模型主流Benchmark测试集介绍
自然语言处理(NLP)的进步往往通过在各种benchmark测试集上的表现来衡量。随着多语言和跨语言NLP研究的兴起,越来越多的多语言测试集被提出以评估模型在不同语言和文化背景下的泛化能力。在这篇文章中,我们将介绍几个主流的多语言NLP benchmark测试集,包括ARC Challenge、H…

论文笔记:详解图注意力网络(GAT)
整理了GAT( ICLR2018 Graph Attention Network)论文的阅读笔记 背景图注意力网络的构建模块与其他模型对比实验 背景 图神经网络的任务可以分为直推式(Transductive)学习与归纳(Inductive)学习: Inductive learning,翻译成中文可以…
![论文阅读[2022sigcomm]GSO-Simulcast Global Stream Orchestration in Simulcast Video](https://img-blog.csdnimg.cn/direct/459ed2ee0a894900bfc252fa9067c1c1.png)
论文阅读[2022sigcomm]GSO-Simulcast Global Stream Orchestration in Simulcast Video
GSO-Simulcast Global Stream Orchestration in Simulcast Video
作者:
1 背景
1视频会议成为全球数十亿人远程协作、学习和个人互动的核心,这些不断增长的虚拟连接需求推动视频会议服务的蓬勃发展 2当前用户越来越希望在低延迟下看到更高质量的视频…
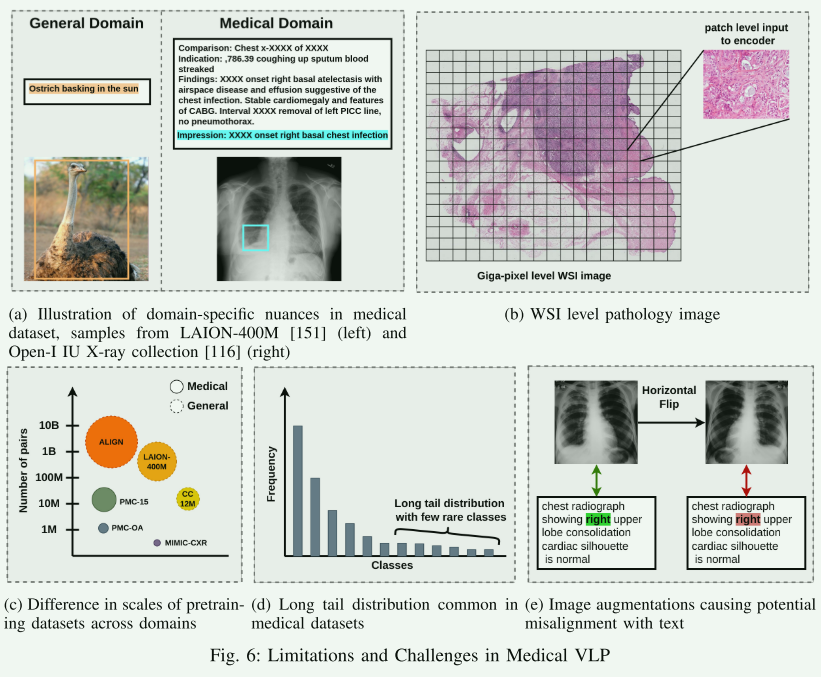
【论文阅读笔记】Medical Vision Language Pretraining: A survey
arXiv:2312.06224Submitted 11 December, 2023; originally announced December 2023.
这篇综述文章很长,本文对各部分简要概述。
【文章整体概述】
医学视觉语言预训练(VLP)最近已经成为解决医学领域标记数据稀缺问题的一种有希望的解决方…
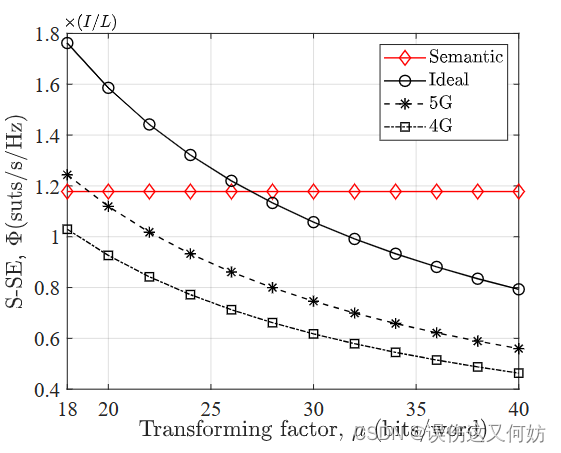
【论文阅读】Resource Allocation for Text Semantic Communications
这是一篇关于语义通信中资源分配的论文。全文共5页,篇幅较短。 目录在这里 摘要关键字引言语义通信资源分配贡献公式符号 系统模型DeepSC TransmitterTransmission ModelDeepSC Receiver 语义感知资源分配策略Semantic Spectral Efficiency (S-SE&#…
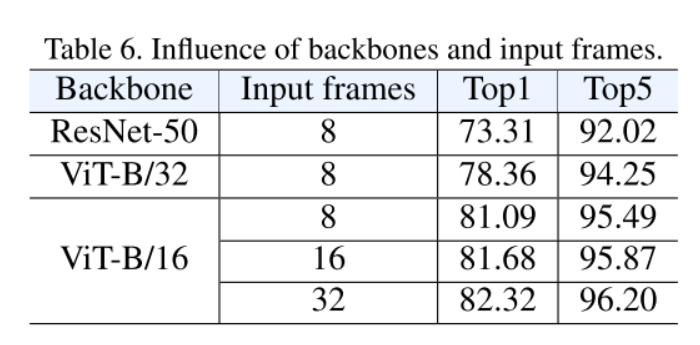
ActionCLIP:A New Paradigm for Video Action Recognition
文章目录 ActionCLIP: A New Paradigm for Video Action Recognition动机创新点相关工作方法多模态框架新范式预训练提示微调 实验实验细节消融实验关键代码 总结相关参考 ActionCLIP: A New Paradigm for Video Action Recognition
论文:https://arxiv.org/abs/21…
![[论文阅读笔记28] 对比学习在多目标跟踪中的应用](https://img-blog.csdnimg.cn/direct/3a1ab023cdd74b8e904cea1382db8e64.png)
[论文阅读笔记28] 对比学习在多目标跟踪中的应用
这次做一篇2D多目标跟踪中使用对比学习的一些方法.
对比学习通过以最大化正负样本特征距离, 最小化正样本特征距离的方式来实现半监督或无监督训练. 这可以给训练MOT的外观特征网络提供一些启示. 使用对比学习做MOT的鼻祖应该是QDTrack, 本篇博客对QDTrack及其后续工作做一个总…
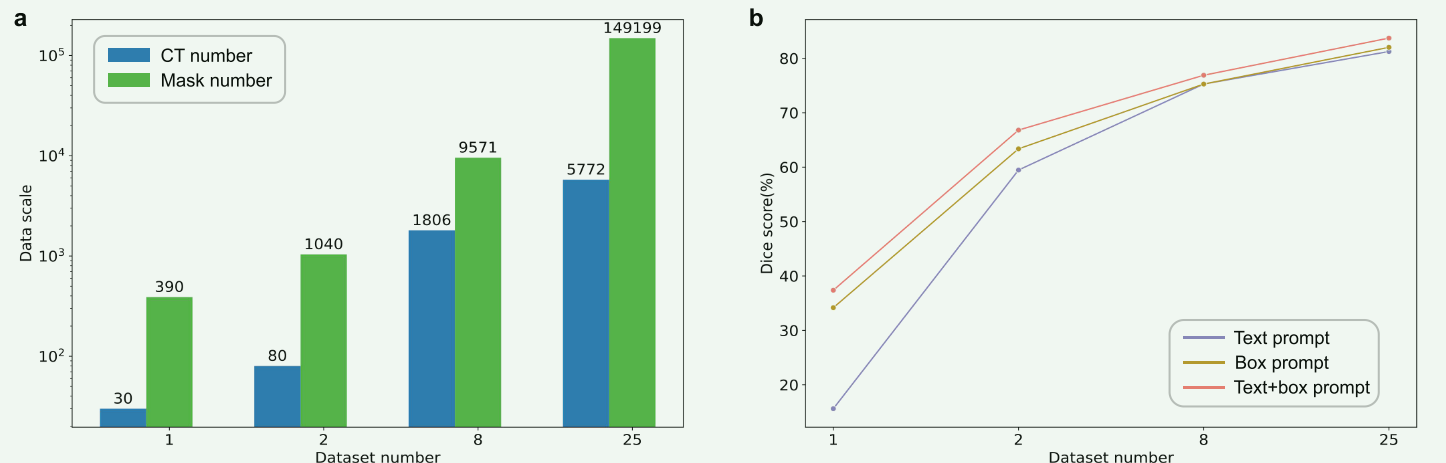
【论文阅读笔记】SegVol: Universal and Interactive Volumetric Medical Image Segmentation
Du Y, Bai F, Huang T, et al. SegVol: Universal and Interactive Volumetric Medical Image Segmentation[J]. arXiv preprint arXiv:2311.13385, 2023.[代码开源] 【论文概述】
本文思路借鉴于自然图像分割领域的SAM,介绍了一种名为SegVol的先进医学图像分割模型…
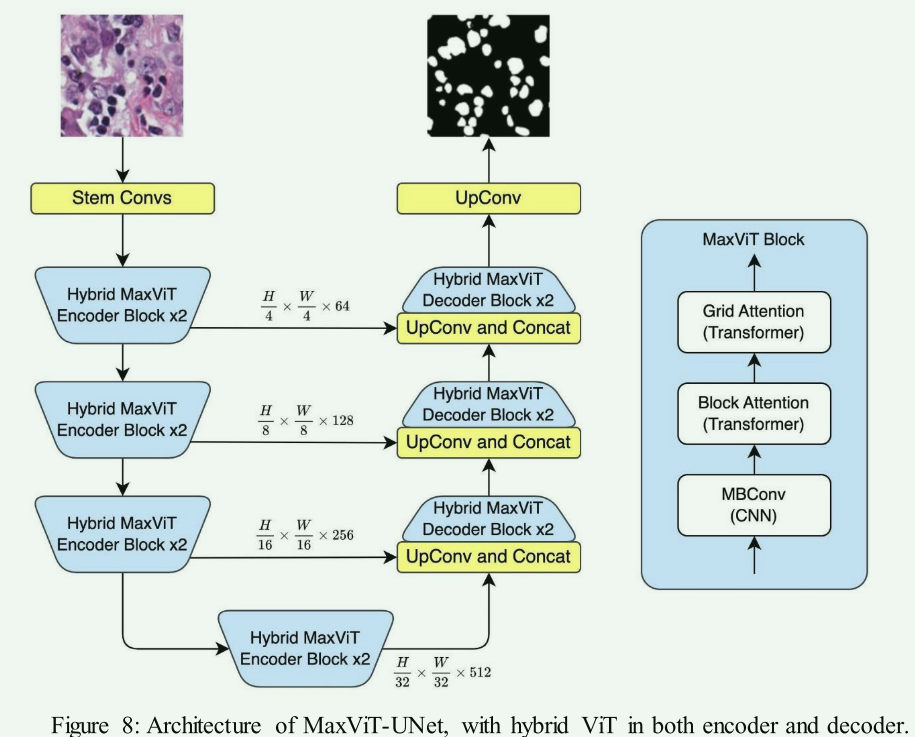
【论文阅读笔记】A Recent Survey of Vision Transformers for Medical Image Segmentation
Khan A, Rauf Z, Khan A R, et al. A Recent Survey of Vision Transformers for Medical Image Segmentation[J]. arXiv preprint arXiv:2312.00634, 2023.
【论文概述】
本文是关于医学图像分割中视觉变换器(Vision Transformers,ViTs)的…
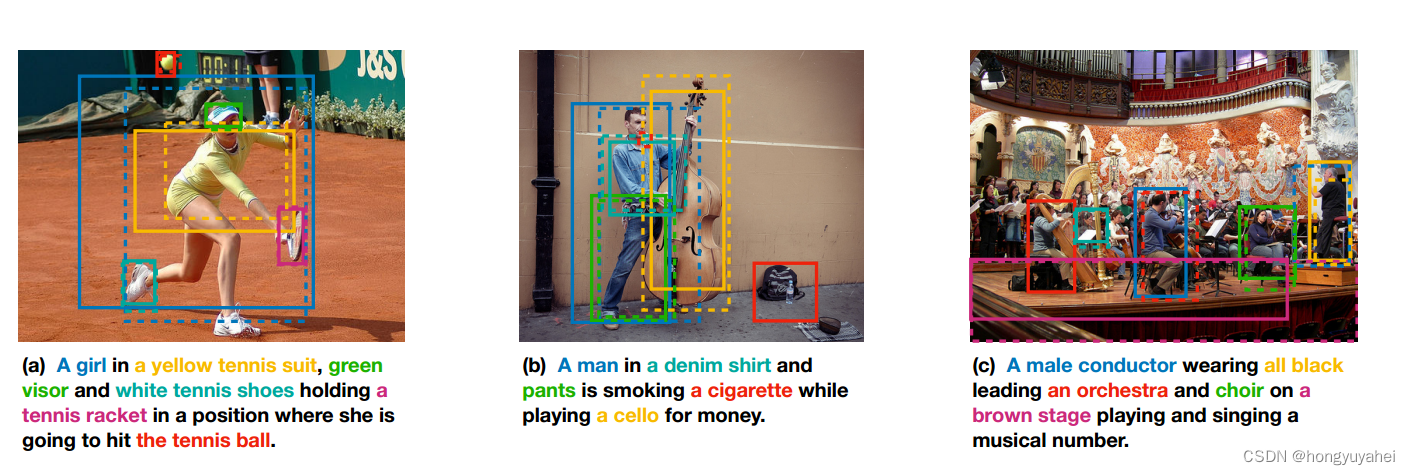
论文笔记:Bilinear Attention Networks
更精简的论文学习笔记
1、摘要
多模态学习中的注意力网络提供了一种选择性地利用给定视觉信息的有效方法。然而,学习每一对多模态输入通道的注意力分布的计算成本是非常昂贵的。为了解决这个问题,共同注意力为每个模态建立了两个独立的注意分布&#x…
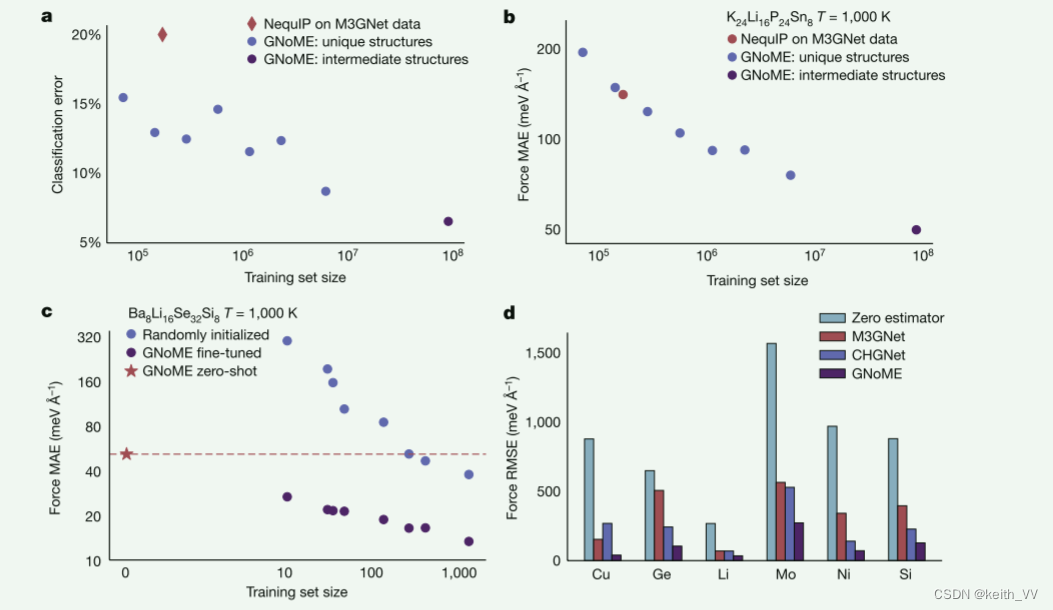
材料论文阅读/中文记录:Scaling deep learning for materials discovery
Merchant A, Batzner S, Schoenholz S S, et al. Scaling deep learning for materials discovery[J]. Nature, 2023: 1-6. 文章目录 摘要引言生成和过滤概述GNoME主动学习缩放法则和泛化 发现稳定晶体通过实验匹配和 r 2 S C A N r^2SCAN r2SCAN 进行验证有趣的组合家族 扩大…
《大观》期刊杂志发表投稿方式
《大观》杂志刊登文化、文学、艺术、民俗、影视等领域的理论研究文章,杂志内容丰富,雅俗共赏,集权威性、实用性、前瞻性与专业性于一体,具有很高的学术价值和社会影响力。是广大专家、学者、教师 、学子发表论文、交流信息的重要平…
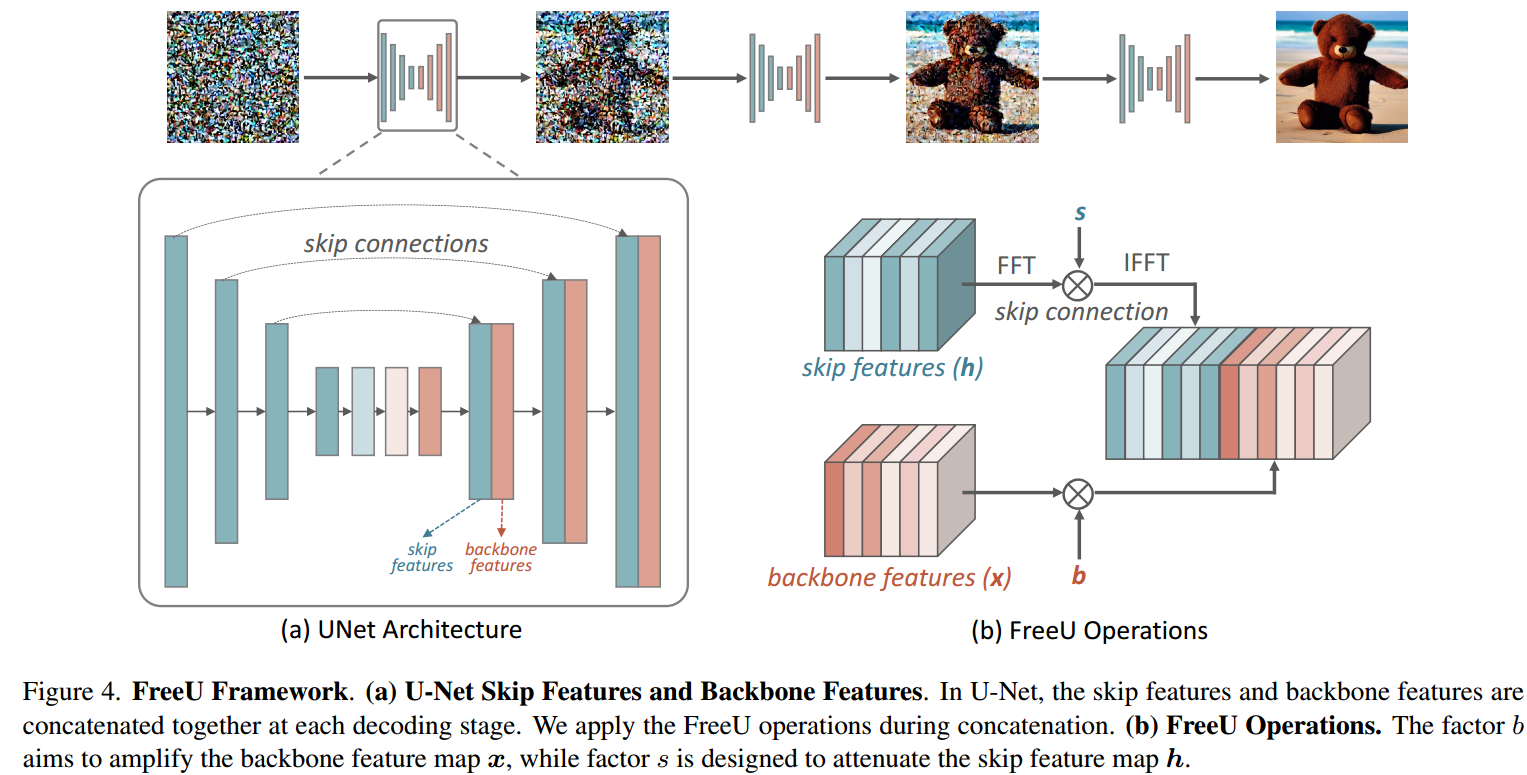
【论文阅读】FreeU: Free Lunch in Diffusion U-Net
paper:https://arxiv.org/abs/2309.11497
code:GitHub - ChenyangSi/FreeU: FreeU: Free Lunch in Diffusion U-Net 1.intro
贡献:
•研究并揭示了U-Net架构在扩散模型中去噪的潜力,并确定其主要骨干主要有助于去噪,…
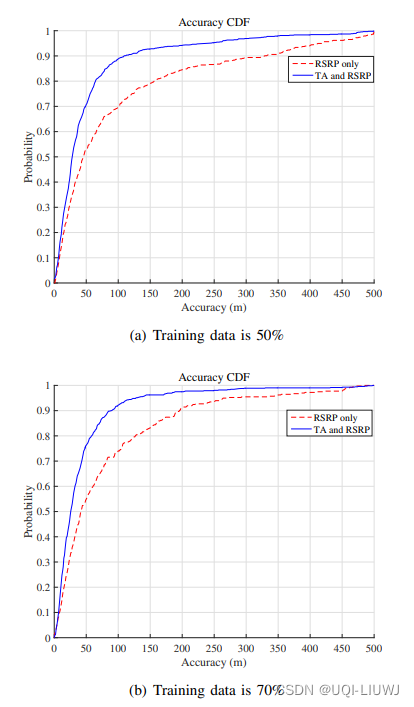
论文笔记:Accurate Localization using LTE Signaling Data
1 intro
论文提出LTELoc,仅使用信令数据实现精准定位 信令数据已经包含在已在LTE系统中,因此这种方法几乎不需要数据获取成本仅使用TA(时序提前)和RSRP【这里单位是瓦】(参考信号接收功率) TA值对应于信号…

【起草】【第十章】免费代写论文!让ChatGPT协助你写毕业论文
你还在花费几万元找抢手代写毕业论文吗?要不你自己开一个chatGPT代写论文提纲工作室?
让ChatGPT协助你写毕业论文,搞不好比和你导师沟通更频繁? 1.鉴于ChatGPT只会说一些陈词滥调的内容,让它生成论文大纲似乎比写具体…
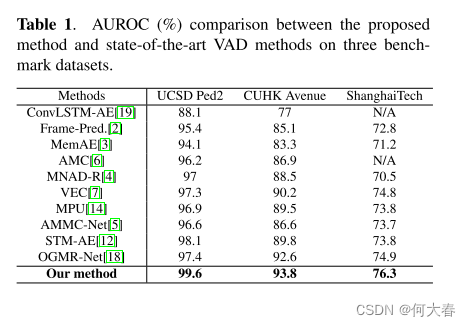
多层记忆增强外观-运动对齐框架用于视频异常检测 论文阅读
MULTI-LEVEL MEMORY-AUGMENTED APPEARANCE-MOTION CORRESPONDENCE FRAMEWORK FOR VIDEO ANOMALY DETECTION 论文阅读 摘要1.介绍2.方法2.1外观和运动对其建模2.2.记忆引导抑制模块2.3. Training Loss2.4. Anomaly Detection 3.实验与结果4.结论 论文标题:MULTI-LEVE…
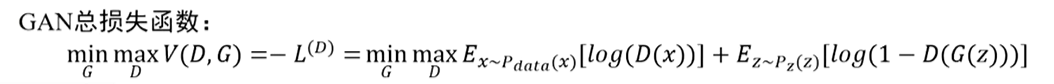
《论文阅读28》Unsupervised 3D Shape Completion through GAN Inversion
GAN,全称GenerativeAdversarialNetworks,中文叫生成式对抗网络。顾名思义GAN分为两个模块,生成网络以及判别网络,其中
生成网络负责根据随机向量产生图片、语音等内容,产生的内容是数据集中没有见过的,也可…
【论文阅读笔记】PraNet: Parallel Reverse Attention Network for Polyp Segmentation
1. 论文介绍
PraNet: Parallel Reverse Attention Network for Polyp Segmentation PraNet:用于息肉分割的并行反向注意力网络 2020年发表在MICCAI Paper Code
2. 摘要
结肠镜检查是检测结直肠息肉的有效技术,结直肠息肉与结直肠癌高度相关。在临床实…
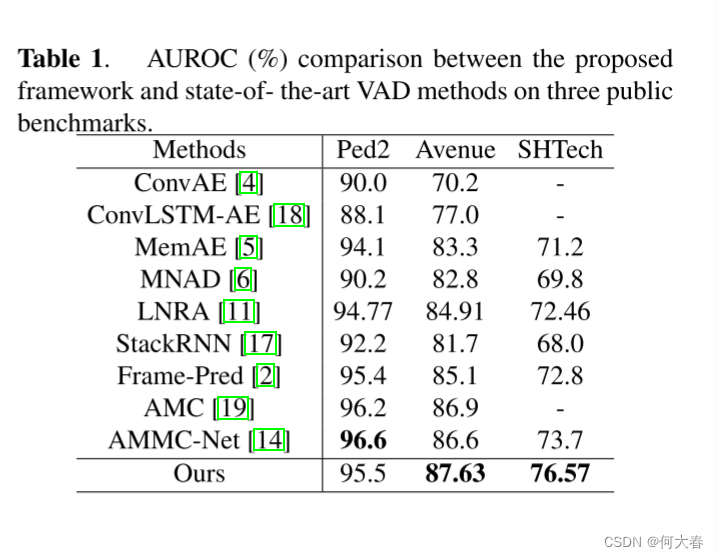
用于无监督视频异常检测的合成伪异常:一种简单有效的基于掩码自动编码器的框架 论文阅读
SYNTHETIC PSEUDO ANOMALIES FOR UNSUPERVISED VIDEO ANOMALY DETECTION: A SIMPLE YET EFFICIENT FRAMEWORK BASED ON MASKED AUTOENCODER ABSTRACT1. INTRODUCTION2. METHODS3. EXPERIMENTS AND RESULTS4. CONCLUSION阅读总结: 论文标题:SYNTHETIC PSE…
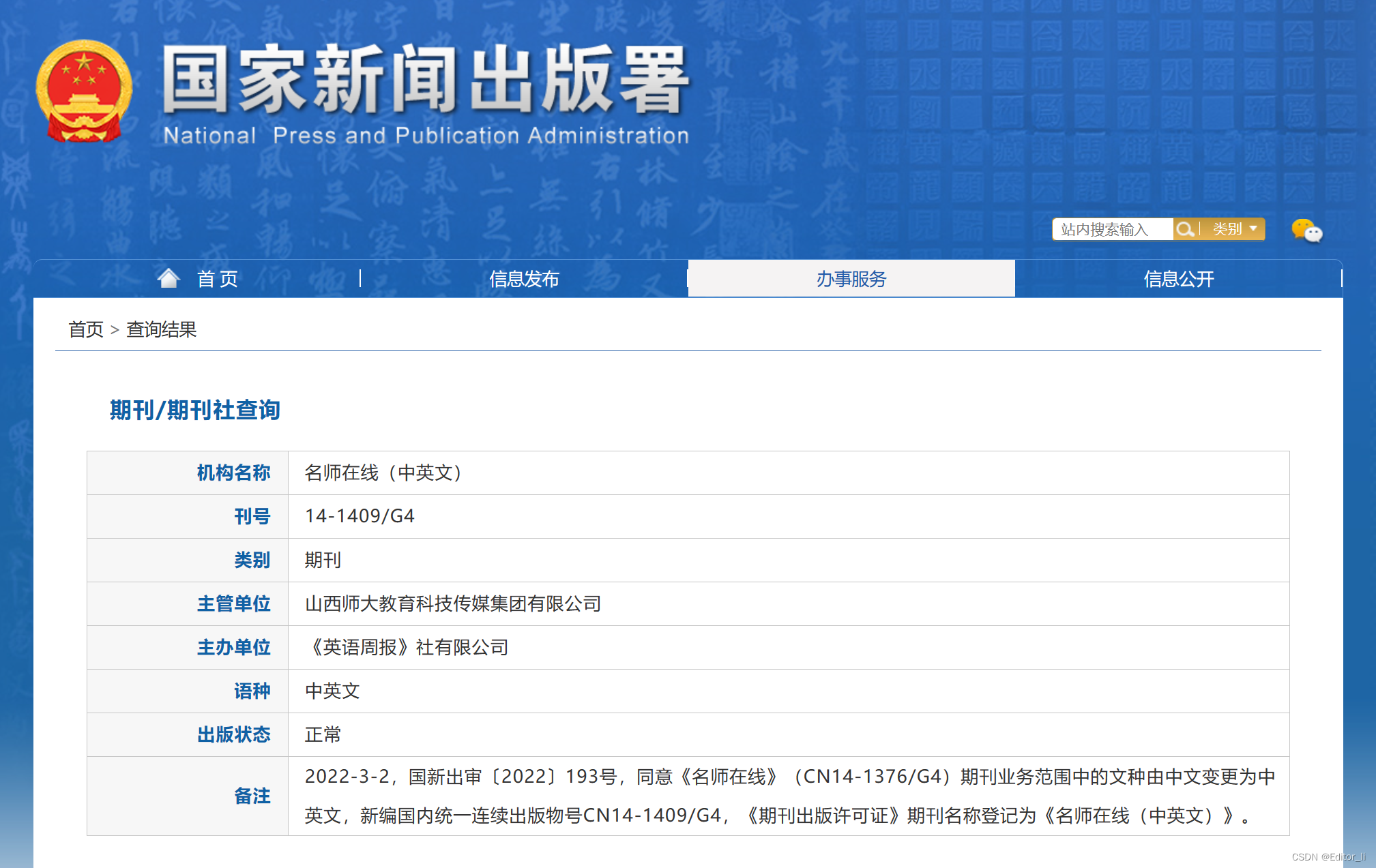
《名师在线》期刊发表杂志投稿
《名师在线《中英文)》期刊是由山西师大教育科技传媒集团有限公司主管,《英语周报》社有限公司主办的教育类学术期刊,本刊办刊宗旨为汇聚全国一线优秀教师资源、以“线上教学、线下研讨“的方式,促进课程建设和教师专业化发展&…
各大高校科研工具链培训PPT汇总
各大高校科研工具链培训PPT汇总
RSS
北邮图书馆:通过RSS订阅高效获取信息、追踪研究前沿山东大学图书馆:如何追踪学科研究前沿苏大图书馆:个人知识管理软件的使用中科院图书馆:利用RSS与最新资讯同步
文献管理工具
中南大学图…

论文阅读《Restormer: Efficient Transformer for High-Resolution Image Restoration》
论文地址:https://openaccess.thecvf.com/content/CVPR2022/html/Zamir_Restormer_Efficient_Transformer_for_High-Resolution_Image_Restoration_CVPR_2022_paper.html 源码地址:https://github.com/swz30/Restormer 概述 图像恢复任务旨在从受到各种扰动(噪声、模糊、雨滴…
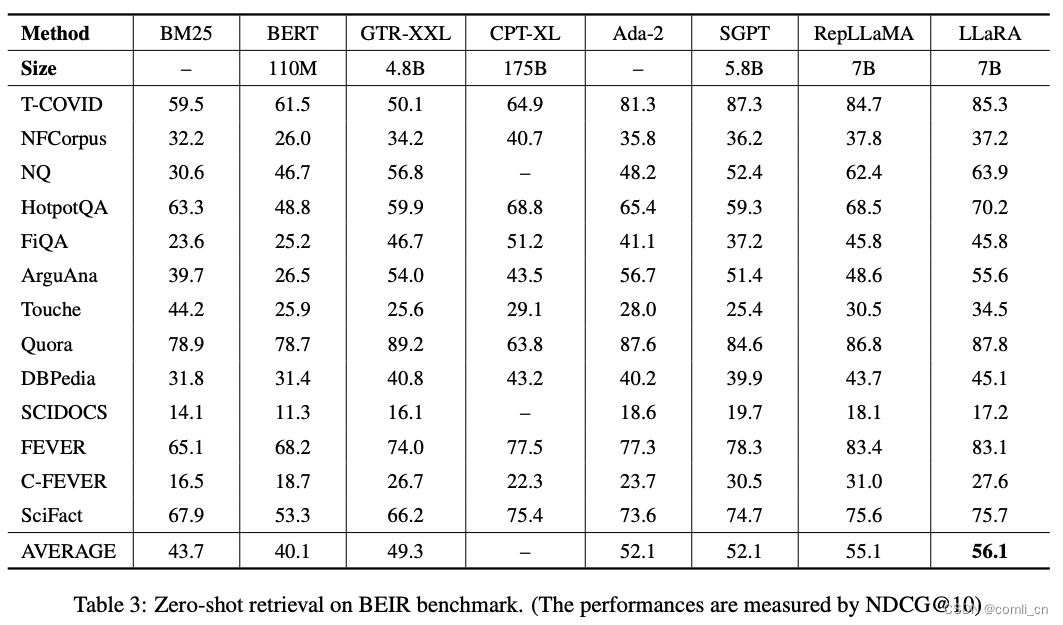
论文阅读:Making Large Language Models A Better Foundation For Dense Retrieval
论文链接
Abstract
密集检索需要学习区分性文本嵌入来表示查询和文档之间的语义关系。考虑到大型语言模型在语义理解方面的强大能力,它可能受益于大型语言模型的使用。然而,LLM是由文本生成任务预先训练的,其工作模式与将文本表示为嵌入完全…
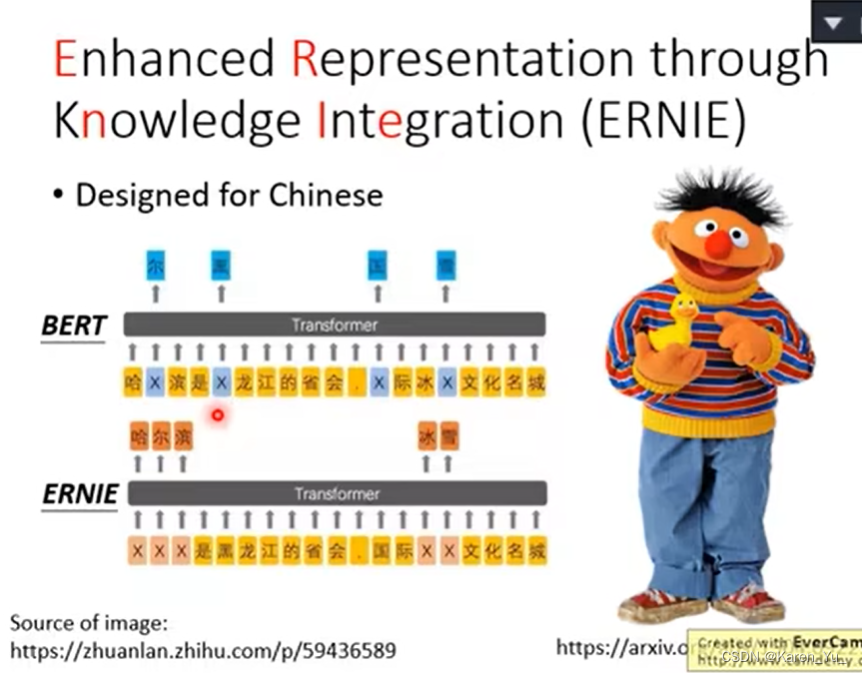
BERT Intro
继续NLP的学习,看完理论之后再看看实践,然后就可以上手去kaggle做那个入门的project了orz。
参考:
1810.04805.pdf (arxiv.org)
BERT 论文逐段精读【论文精读】_哔哩哔哩_bilibili
(强推!)2023李宏毅讲解大模型鼻祖BERT,一小时…
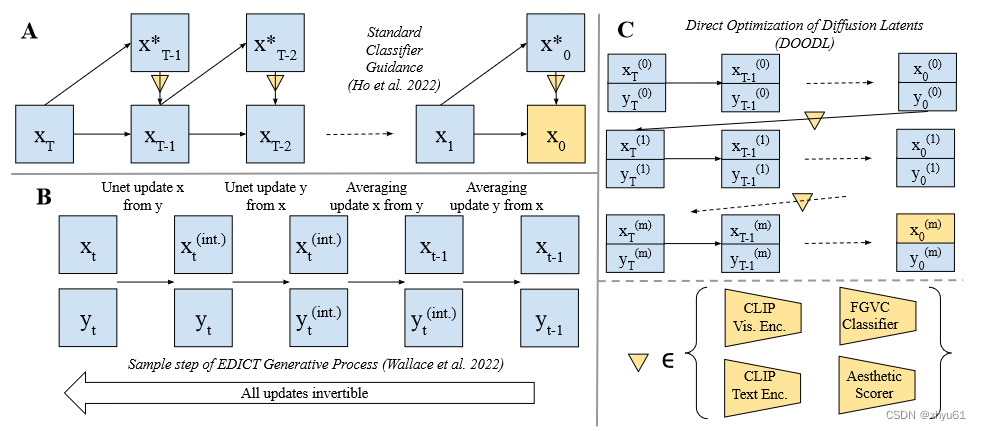
【论文笔记】End-to-End Diffusion Latent Optimization Improves Classifier Guidance
Abstract
Classifier guidance为图像生成带来了控制,但是需要训练新的噪声感知模型(noise-aware models)来获得准确的梯度,或使用最终生成的一步去噪近似,这会导致梯度错位(misaligned gradients)和次优控制(sub-optimal control)。 梯度错位…

【论文阅读】Realtime multi-person 2d pose estimation using part affinity fields
OpenPose:使用PAF的实时多人2D姿势估计。
code:GitHub - ZheC/Realtime_Multi-Person_Pose_Estimation: Code repo for realtime multi-person pose estimation in CVPR17 (Oral)
paper:[1611.08050] Realtime Multi-Person 2D Pose Estima…

【论文阅读】Self-supervised Learning: Generative or Contrastive
Abstract
研究了在计算机视觉、自然语言处理和图形学习中用于表示的新的自监督学习方法。全面回顾了现有的实证方法,并根据其目的将其归纳为三大类:生成性、对比性和生成性对比(对抗性)。进一步收集了关于自我监督学习的相关理论…
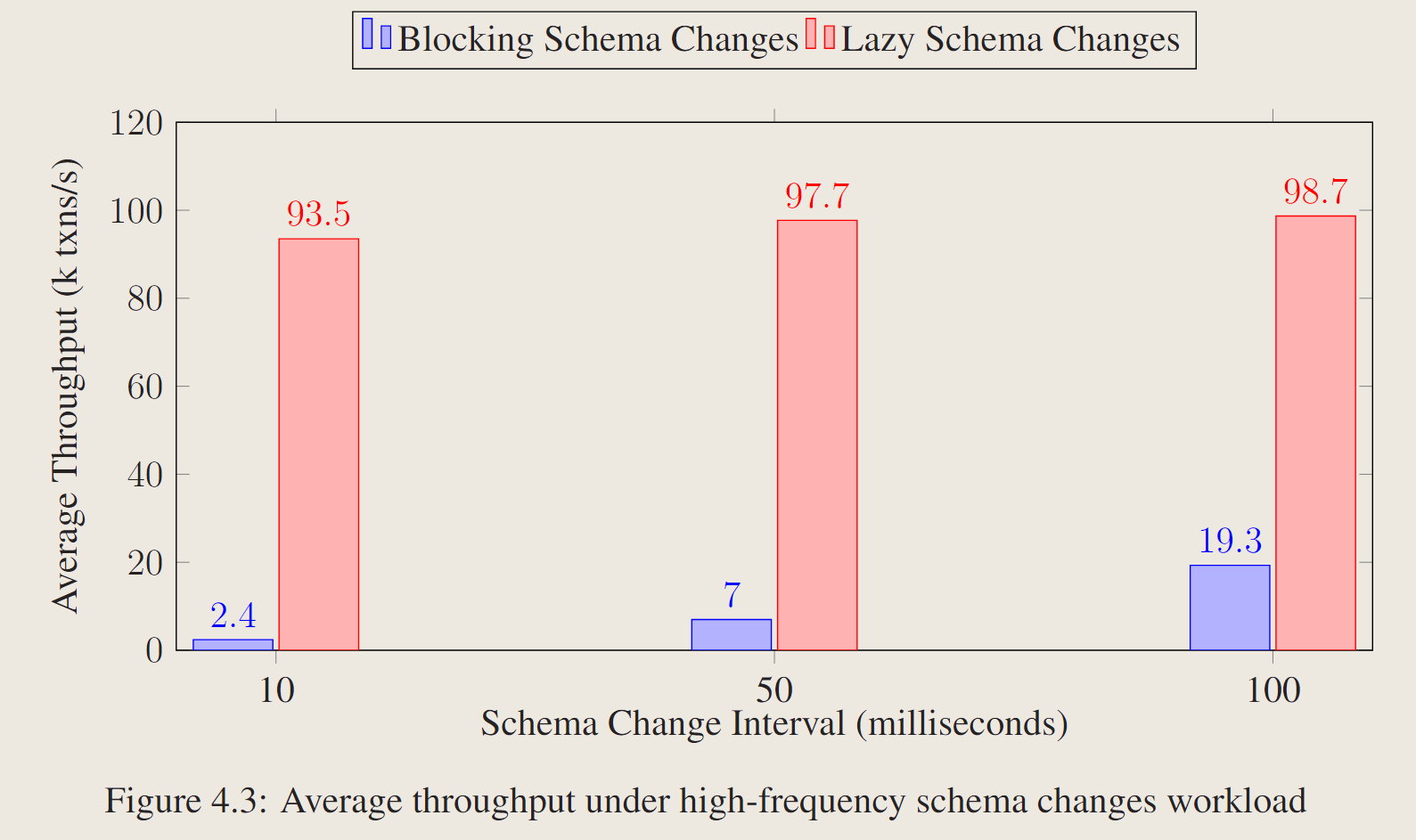
【论文阅读】Non-blocking Lazy Schema Changes in Multi-Version
Non-blocking Lazy Schema Changes in Multi-Version Database Management Systems
1. Intro
1.1 Motivation
一个是online能够提供不停机的更新的能力,在很多业务系统里面是必要的。第二个是满足高可用,SaaS、PaaS要提供高可用的系统给用户ÿ…

室内定位相关中文期刊/学报笔记
这里写目录标题 文章最重要的部分通信学报1. 2023 基于扩散模型的室内定位射频指纹数据增强方法2. 2023 基于 CHAN 的改进卡尔曼滤波室内定位算法3. 2022 基于自适应蝙蝠算法的室内 RFID 定位算法4. 2017 基于核函数特征提取的室内定位算法研究5. 2021 基于CSI张量分解的室内Wi…
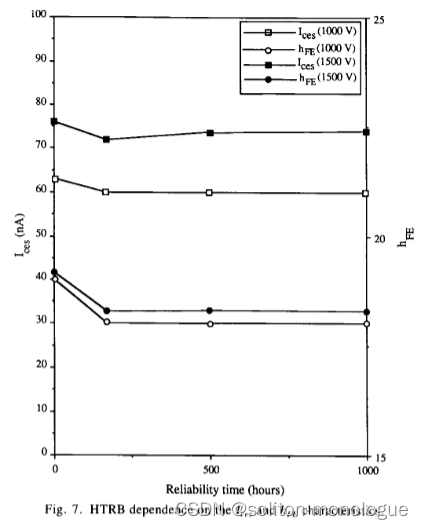
硅像素传感器文献调研(三)
写在前面:
引言:也是先总结前人的研究结果,重点论述其不足之处。
和该方向联系不大,但还是有值得学习的地方。逻辑很清晰,易读性很好。
1991年—场板半阻层
使用场板和半电阻层的高压平面器件
0.摘要
提出了一种…
《儿童绘本》期刊杂志发表论文投稿
《儿童绘本》杂志是由国家新闻出版管理部门批准,由吉林省舆林报刊发展有限责任公司主管主办,国内外公开发行的全国优秀期刊。办刊宗旨:以“普及绘本知识、推动儿童阅读”为理念,带动家庭亲子阅读,推动阅读教育及图画书…
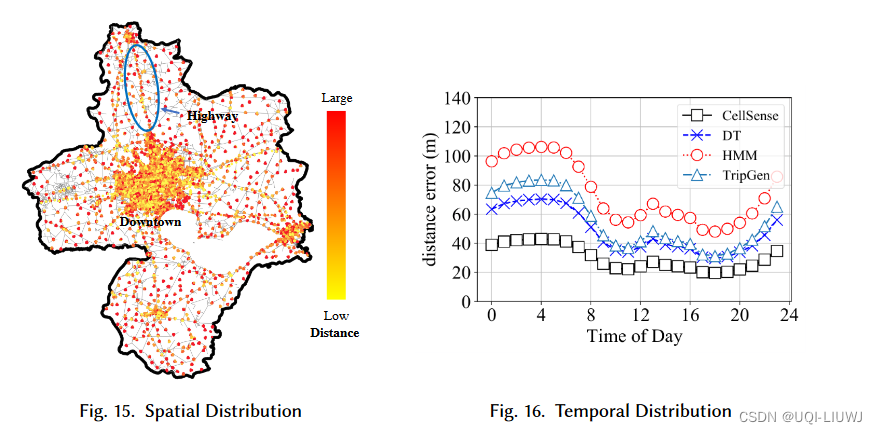
论文笔记:CellSense: Human Mobility Recovery via Cellular Network Data Enhancement
1 intro
1.1 背景
1.1.1 蜂窝计费记录(CBR)
人类移动性在蜂窝网络上的研究近些年得到了显著关注,这主要是因为手机的高渗透率和收集手机数据的边际成本低蜂窝服务提供商收集蜂窝计费记录(CBR)用于计费目的…
硅像素传感器文献调研(四)
写在前面: 好喜欢这种短论文哈哈哈哈哈
感觉这篇文献已经提到了保护环的概念啊,只不过叫的是:场限制环。
1986——高压功率器件场终端横向掺杂的变化 0.摘要
对于高压平面结提出了一个简单的新概念。通过在氧化物掩模中的小开口和随后的驱…

NLP论文阅读记录 - 2022 | WOS 一种新颖的优化的与语言无关的文本摘要技术
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.前提三.本文方法四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结思考 前言 A Novel Optimized Language-Independent Text Summarization Techni…

论文阅读:Blind Super-Resolution Kernel Estimation using an Internal-GAN
这是发表在 2019 年 NIPS 上的一篇文章,那个时候还叫 NIPS,现在已经改名为 NeurIPS 了。文章中的其中一个作者 Michal Irani 是以色 Weizmann Institute of Science (魏茨曼科学研究学院) 的一名教授,对图像纹理的内在统计规律有着很深入的研…

RO-NeRF论文笔记
RO-NeRF论文笔记 文章目录 RO-NeRF论文笔记论文概述Abstract1 Introduction2 Related Work3 Method3.1 RGB and depth inpainting network3.2 Background on NeRFs3.3 Confidence-based view selection3.4 Implementation details 4 Experiments4.1 DatasetsReal ObjectsSynthe…

《新传奇》期刊投稿论文发表
《新传奇》杂志是经国家新闻出版总署批准、面向国内外公开发行的综合性社科期刊,由湖北省文联主管,湖北今古传奇传媒集团有限公司主办,湖北优秀期刊。本刊旨在坚守初心、引领创新,展示高水平研究成果,支持优秀学术人才…
LOAM: Lidar Odometry and Mapping in Real-time 论文阅读
论文链接
LOAM: Lidar Odometry and Mapping in Real-time 0. Abstract
提出了一种使用二维激光雷达在6自由度运动中的距离测量进行即时测距和建图的方法 距离测量是在不同的时间接收到的,并且运动估计中的误差可能导致生成的点云的错误配准 本文的方法在不需要高…

《Ensemble deep learning: A review》阅读笔记
论文标题
《Ensemble deep learning: A review》
集成深度学习: 综述
作者
M.A. Ganaie 和 Minghui Hu
来自印度理工学院印多尔分校数学系和南洋理工大学电气与电子工程学院
本文写的大而全。
初读
摘要 集成学习思想: 结合几个单独的模型以获得…

【论文阅读笔记】Detecting Camouflaged Object in Frequency Domain
1.论文介绍
Detecting Camouflaged Object in Frequency Domain 基于频域的视频目标检测 2022年发表于CVPR [Paper] [Code]
2.摘要
隐藏目标检测(COD)旨在识别完美嵌入其环境中的目标,在医学,艺术和农业等领域有各种下游应用。…
Modeling Long- and Short-Term Temporal Patterns with DeepNeural Networks
This paper was pulished at SIGIR’18, July 2018, Ann Arbor, MI, USA
一、简介
LSTNet是一种用于时间序列预测的深度学习模型,其全称为Long- and Short-term Time-series Networks。LSTNet结合了长短期记忆网络(LSTM)和一维卷积神经网络…
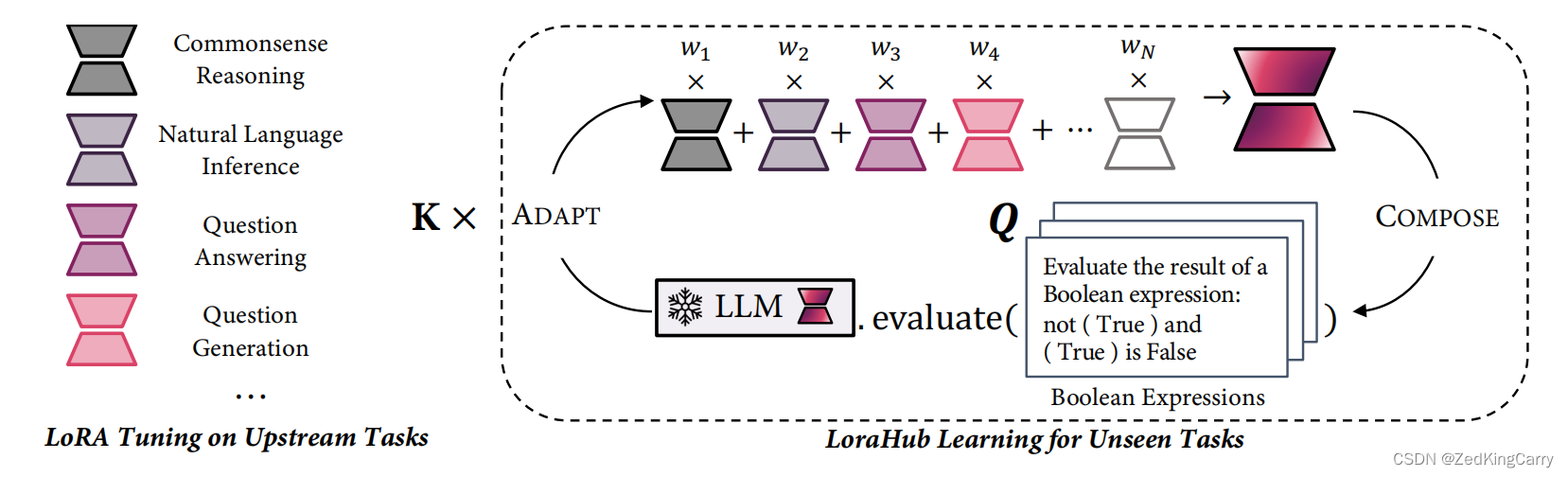
【阅读笔记】LoRAHub:Efficient Cross-Task Generalization via Dynamic LoRA Composition
一、论文信息
1 论文标题
LoRAHub:Efficient Cross-Task Generalization via Dynamic LoRA Composition
2 发表刊物
NIPS2023_WorkShop
3 作者团队
Sea AI Lab, Singapore
4 关键词
LLMs、LoRA
二、文章结构 #mermaid-svg-Gn81hPysu7z59nlv {font-family:&…
NLP论文阅读记录 - 以大语言模型为参考学习总结
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.相关工作2.1文本生成模型的训练方法2.2 基于LLM的自动评估2.3 LLM 蒸馏和基于 LLM 的数据增强 三.本文方法3.1 Summarize as Large Language Models3.1.1 前提3.1.2 大型语言模型作为参考具有…
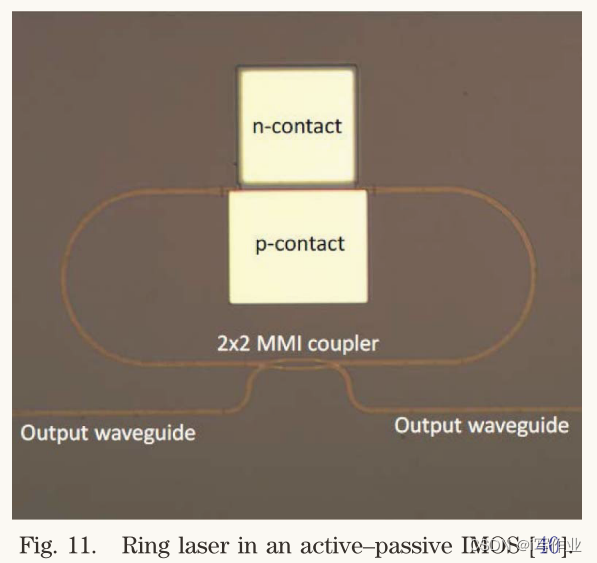
论文笔记_InP_photonic_circuits_using_generic_integration
InP_photonic_circuits_using_generic_integration
时间:2015年5月 文章目录 InP_photonic_circuits_using_generic_integrationⅠ IntroductionⅡ 通用集成平台A. 对特定信号进行处理B. Multiwavelength TransmitterC. 超快激光(皮秒激光、飞秒激光&am…
【论文笔记】BiFormer: Vision Transformer with Bi-Level Routing Attention
论文地址:BiFormer: Vision Transformer with Bi-Level Routing Attention
代码地址:https://github.com/rayleizhu/BiFormer
vision transformer中Attention是极其重要的模块,但是它有着非常大的缺点:计算量太大。
BiFormer提…

2023.8.12号论文阅读
文章目录 TriFormer: A Multi-modal Transformer Framework For Mild Cognitive Impairment Conversion Prediction摘要本文方法实验结果 SwIPE: Efficient and Robust Medical Image Segmentation with Implicit Patch Embeddings摘要本文方法实验结果 TriFormer: A Multi-mod…
![[论文笔记]DSSM](https://img-blog.csdnimg.cn/img_convert/d3d54f15abf8c9fdcf623a7ef607be7a.png)
[论文笔记]DSSM
引言
这是DSSM论文的阅读笔记,后续会有一篇文章来复现它并在中文数据集上验证效果。
本文的标题翻译过来就是利用点击数据学习网页搜索中深层结构化语义模型,这篇论文被归类为信息检索,但也可以用来做文本匹配。
这是一篇经典的工作,在DSSM之前,通常使用传统机器学习的…
![[论文笔记]SiameseNet](https://img-blog.csdnimg.cn/img_convert/853619ed045766a8cbd22e7215564f5f.png)
[论文笔记]SiameseNet
引言
这是Learning Text Similarity with Siamese Recurrent Networks的论文笔记。
论文标题意思是利用孪生循环神经网络学习文本相似性。
什么是孪生神经网络呢?满足以下两个条件即可: 输入是成对的网络结构和参数共享(即同一个网络)如下图所示: 看到这种图要知道可能代…
Scientific discovery in the age of artificial intelligence
人工智能时代的科学发现
摘要 人工智能(AI)正越来越多地融入科学发现,以增强和加速研究,帮助科学家产生假设,设计实验,收集和解释大型数据集,并获得仅使用传统科学方法可能无法获得的见解。在这里,我们研究…
![[论文笔记]Glancing Transformer for Non-Autoregressive Neural Machine Translation](https://img-blog.csdnimg.cn/995ccaae14124f42815d92b9eb6676c7.png)
[论文笔记]Glancing Transformer for Non-Autoregressive Neural Machine Translation
引言
这是论文Glancing Transformer for Non-Autoregressive Neural Machine Translation的笔记。
传统的非自回归文本生成速度较慢,因为需要给定之前的token来预测下一个token。但自回归模型虽然效率高,但性能没那么好。 这篇论文提出了Glancing Transformer,可以只需要一…

![[论文阅读笔记25]A Comprehensive Survey on Graph Neural Networks](https://img-blog.csdnimg.cn/a60d7a56c9a444439815142a440d23f5.png)
[论文阅读笔记25]A Comprehensive Survey on Graph Neural Networks
这是一篇GNN的综述, 发表于2021年的TNNLS. 这篇博客旨在对GNN的基本概念做一些记录.
论文地址: 论文 1. 引言, 背景与定义
对于图像数据来说, CNN具有平移不变性和局部连接性, 因此可以在欧氏空间上良好地学习. 然而, 对于具有图结构的数据(例如社交网络 化学分子等)就需要用…
超图嵌入论文阅读1:对偶机制非均匀超网络嵌入
超图嵌入论文阅读1:对偶机制非均匀超网络嵌入 原文:Nonuniform Hyper-Network Embedding with Dual Mechanism ——TOIS(一区 CCF-A) 背景
超边:每条边可以连接不确定数量的顶点
我们关注超网络的两个属性࿱…
GL-Cache: Group-level learning for efficient and high-performance caching
会议全称: Conference on File and Storage Technologies 出版社: USENIX 21st USENIX Conference on File and Storage Technologies 摘要:
web应用强依赖于软件缓存去实现低延迟和高吞吐量服务。 Web应用程序严重依赖软件缓存来实现低延…
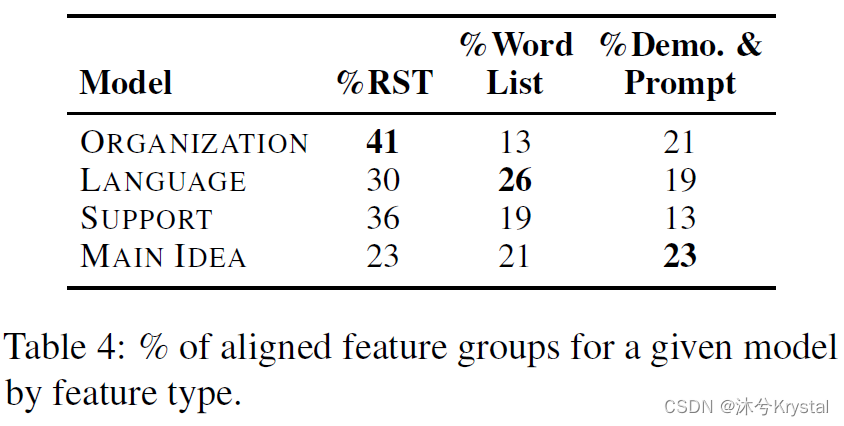
【论文阅读】面向抽取和理解基于Transformer的自动作文评分模型的隐式评价标准(实验结果部分)
方法 结果
在这一部分,我们展示对于每个模型比较的聚合的统计分析当涉及到计算特征和独立的特征组(表格1),抽取功能组和对齐重要功能组(表格2),并且最后,我们提供从模型比较&#x…
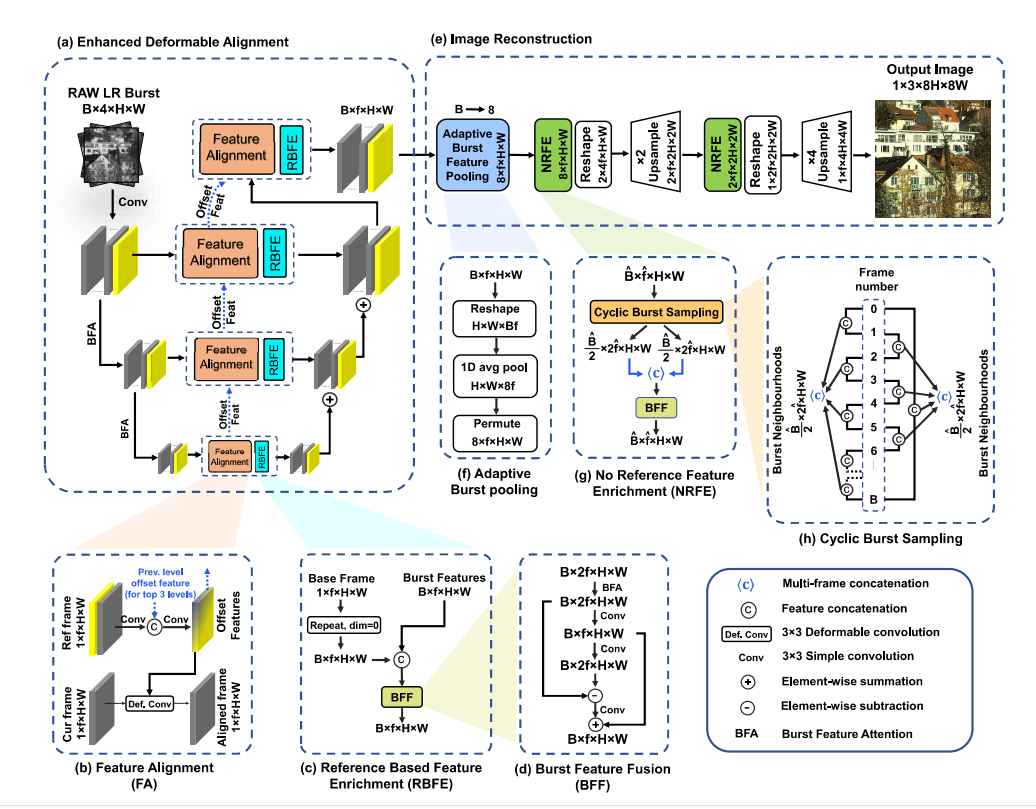
Burstormer论文阅读笔记
这是CVPR2023的一篇连拍图像修复和增强的论文,一作是阿联酋的默罕默德 本 扎耶得人工智能大学,二作是旷视科技。这些作者和CVPR2022的一篇BIPNet,同样是做连拍图像修复和增强的,是同一批。也就是说同一个方向,22年中了…

【论文阅读】StyleganV1 算法理解
文章目录 为什么提出?具体是怎么做的?1.解耦的思想(对应文章第四章4.Disentanglement studies)1.1 感知路径长度(对应4.1Perceptual path length)1.2 线性可分离性(对应4.2Linear separability&…
Wav2vec2 论文阅读看到的一些问题
Wav2vec2 论文阅读看到的一些问题 这里只是简单的思考一下论文的一些问题,不是论文解读。 Q1. 为什么wav2vec依旧需要Transformer来做推理,而不直接使用VQ生成的内容? A1. Transformer在更长的序列上有更好的编码效果,例如论文也写…
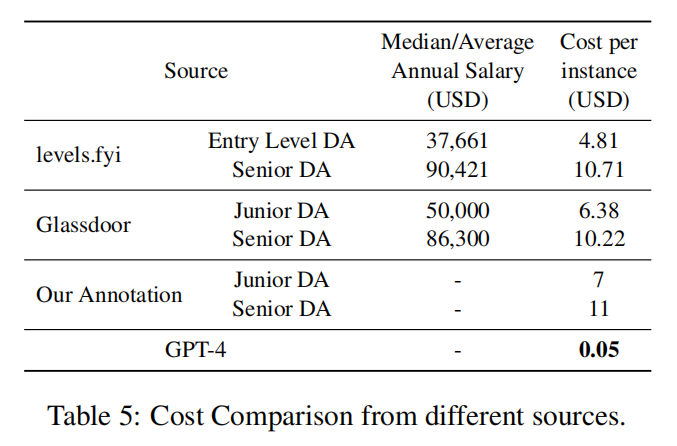
论文阅读之【Is GPT-4 a Good Data Analyst?(GPT-4是否是一位好的数据分析师)】
文章目录 论文阅读之【Is GPT-4 a Good Data Analyst?(GPT-4是否是一位好的数据分析师)】背景:数据分析师工作范围基于GPT-4的端到端数据分析框架将GPT-4作为数据分析师的框架的流程图 实验分析评估指标表1:GPT-4性能表现表2&…

【论文阅读】基于深度学习的时序预测——LSFT-Linear
系列文章链接 论文一:2020 Informer:长时序数据预测 论文二:2021 Autoformer:长序列数据预测 论文三:2022 FEDformer:长序列数据预测 论文四:2022 Non-Stationary Transformers:非平…
![[论文阅读]Voxel R-CNN——迈向高性能基于体素的3D目标检测](https://img-blog.csdnimg.cn/de54f52aca1c49af9d4c214f39cd5ee8.png)
[论文阅读]Voxel R-CNN——迈向高性能基于体素的3D目标检测
Voxel R-CNN
Voxel R-CNN: Towards High Performance Voxel-based 3D Object Detection 迈向高性能基于体素的3D目标检测 论文网址:Voxel R-CNN 论文代码:Voxel R-CNN
简读论文
该论文提出了 Voxel R-CNN,这是一种基于体素的高性能 3D 对象…
#经典论文 异质山坡的物理模型 2 有效导水率
Binley, A., Beven, K., & Elgy, J. (1989). A physically based model of heterogeneous hillslopes: 2. Effective hydraulic conductivities. Water Resources Research, 25(6), 1227–1233. https://doi.org/10.1029/WR025i006p01227
这篇论文指出, 每个输…
(WWW2023)论文阅读-Detecting Social Media Manipulation in Low-ResourceLanguages
论文链接:https://arxiv.org/pdf/2011.05367.pdf 摘要 社交媒体被故意用于恶意目的,包括政治操纵和虚假信息。大多数研究都集中在高资源语言上。然而,恶意行为者会跨国家/地区和语言共享内容,包括资源匮乏的语言。 在这里…

Exploiting Proximity-Aware Tasks for Embodied Social Navigation 论文阅读
论文信息
题目:Exploiting Proximity-Aware Tasks for Embodied Social Navigation 作者:Enrico Cancelli, Tommaso Campari 来源:arXiv 时间:2023
Abstract
学习如何在封闭且空间受限的室内环境中在人类之间导航&a…
![[12 种安卓数据恢复方案] 最佳免费 Android 照片恢复工具榜单](https://img-blog.csdnimg.cn/img_convert/fd15a460a99b31013b28d5b2eb354bea.jpeg)
[12 种安卓数据恢复方案] 最佳免费 Android 照片恢复工具榜单
我们用 Android 手机的相机捕捉我们难忘的时刻,并将它们存储在画廊中。但是由于各种原因,照片可能会从 Android 手机中删除。一次丢失所有令人难忘的重要照片对任何人来说都是非常令人沮丧的。但是,可以使用适用于 Android 手机的免费照片恢复…

《Deep Residual Learning for Image Recognition》阅读笔记
论文标题
《Deep Residual Learning for Image Recognition》
撑起CV界半边天的论文Residual :主要思想,残差。
作者
何恺明,超级大佬。微软亚研院属实是人才辈出的地方。
初读
摘要 提问题: 更深层次的神经网络更难训练。 …
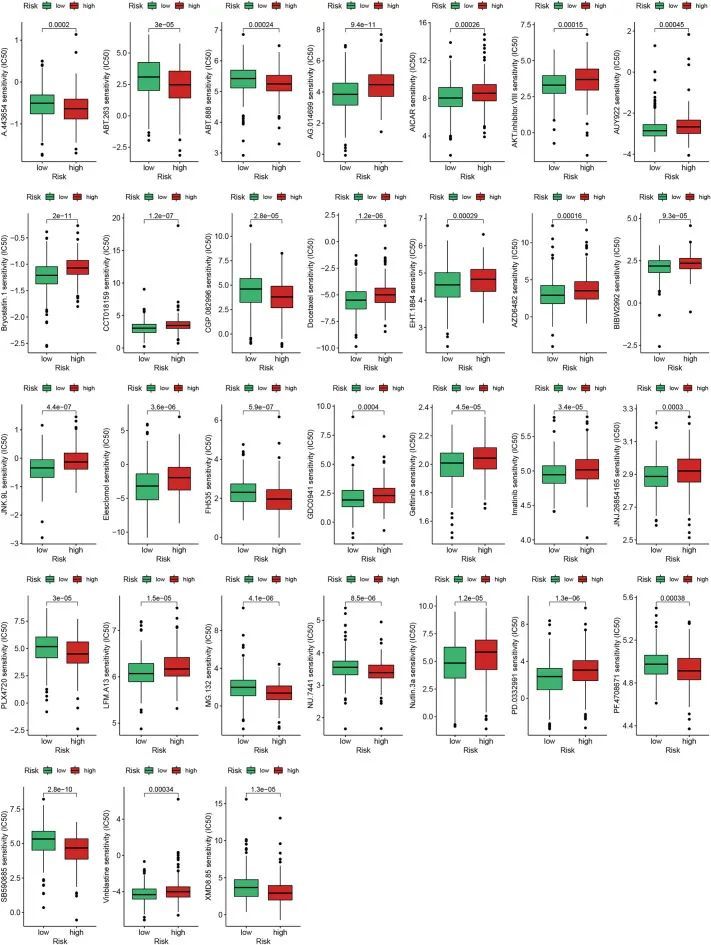
发布不到一月的4+经典单细胞+预后模型生信思路,可复现可升级
今天给同学们分享一篇单细胞预后模型的生信文章“Integrating single-cell and bulk RNA sequencing to predict prognosis and immunotherapy response in prostate cancer”,这篇文章于2023年9月20日发表在Scientific Reports期刊上,影响因子为4.6。 前…
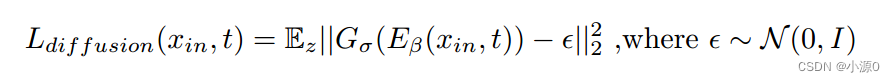
FSDiffReg:心脏图像的特征和分数扩散引导无监督形变图像配准
论文标题: FSDiffReg: Feature-wise and Score-wise Diffusion-guided Unsupervised Deformable Image Registration for Cardiac Images 翻译: FSDiffReg:心脏图像的特征和分数扩散引导无监督形变图像配准
摘要 无监督可变形图像配准是医学…

多模态大模型升级:LLaVA→LLaVA-1.5,MiniGPT4→MiniGPT5
Overview LLaVA-1.5总览摘要1.引言2.背景3.LLaVA的改进4.讨论附录 LLaVA-1.5
总览
题目: Improved Baselines with Visual Instruction Tuning 机构:威斯康星大学麦迪逊分校,微软 论文: https://arxiv.org/pdf/2310.03744.pdf 代码: https://llava-vl.…
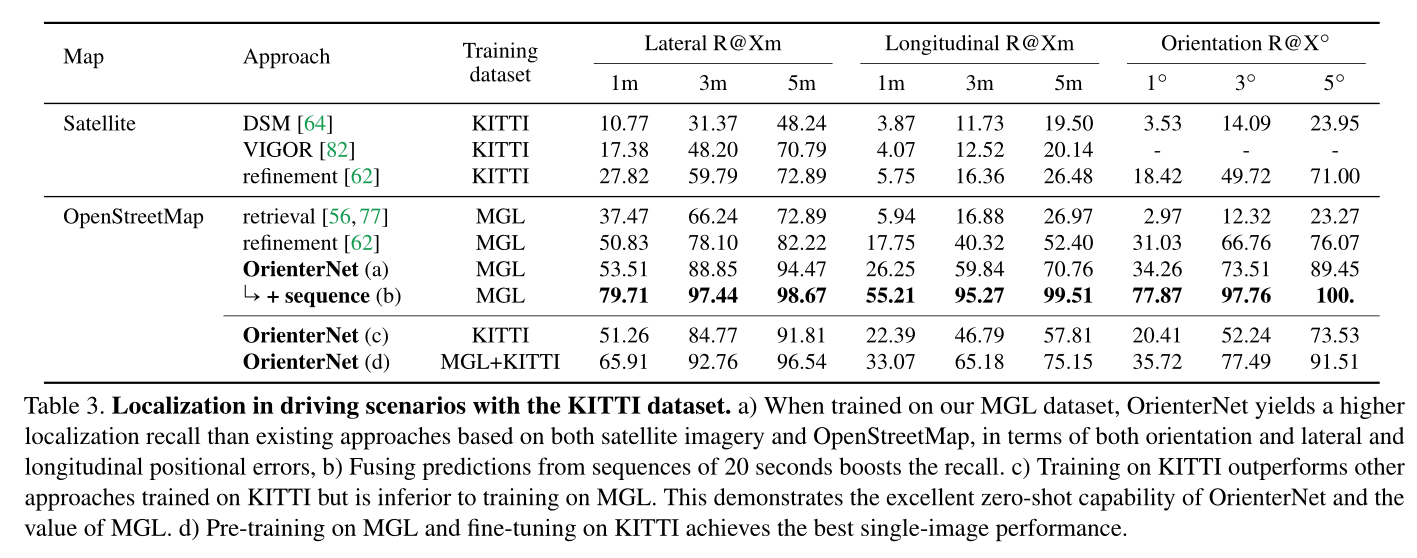
OrienterNet: visual localization in 2D public maps with neural matching 论文阅读
论文信息
题目:OrienterNet: visual localization in 2D public maps with neural matching 作者:Paul-Edouard Sarlin, Daniel DeTone 项目地址:github.com/facebookresearch/OrienterNet 来源:CVPR 时间:…
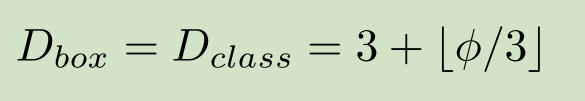
EfficientDet论文讲解
目录 EfficientDet
0、摘要
1、整体架构
1.1 BackBone:EfficientNet-B0
1.2 Neck:BiFPN特征加强提取网络
1.3 Head检测头
1.4 compound scaling
2、anchors先验框
3、loss组成
4、论文理解
5、参考资料 EfficientDet 影响网络的性能(或者说规…

《论文阅读》LORA:大型语言模型的低秩自适应 2021
《论文阅读》LORA: LOW-RANK ADAPTATION OF LARGE LAN-GUAGE MODELS 前言简介现有方法模型架构优点前言
今天为大家带来的是《LORA: LOW-RANK ADAPTATION OF LARGE LAN-GUAGE MODELS》 出版:
时间:2021年10月16日
类型:大语言模型的微调方法
关键词:
作者:Edward Hu,…
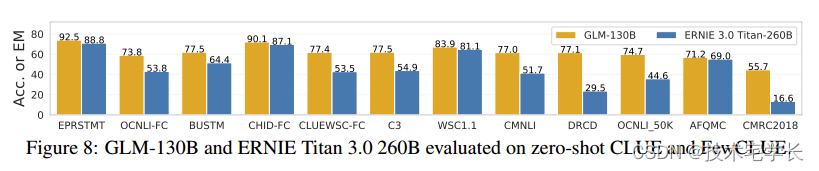
【论文阅读笔记】GLM-130B: AN OPEN BILINGUAL PRE-TRAINEDMODEL
Glm-130b:开放式双语预训练模型 摘要 我们介绍了GLM-130B,一个具有1300亿个参数的双语(英语和汉语)预训练语言模型。这是一个至少与GPT-3(达芬奇)一样好的100b规模模型的开源尝试,并揭示了如何成功地对这种规模的模型进行预训练。在这一过程中࿰…
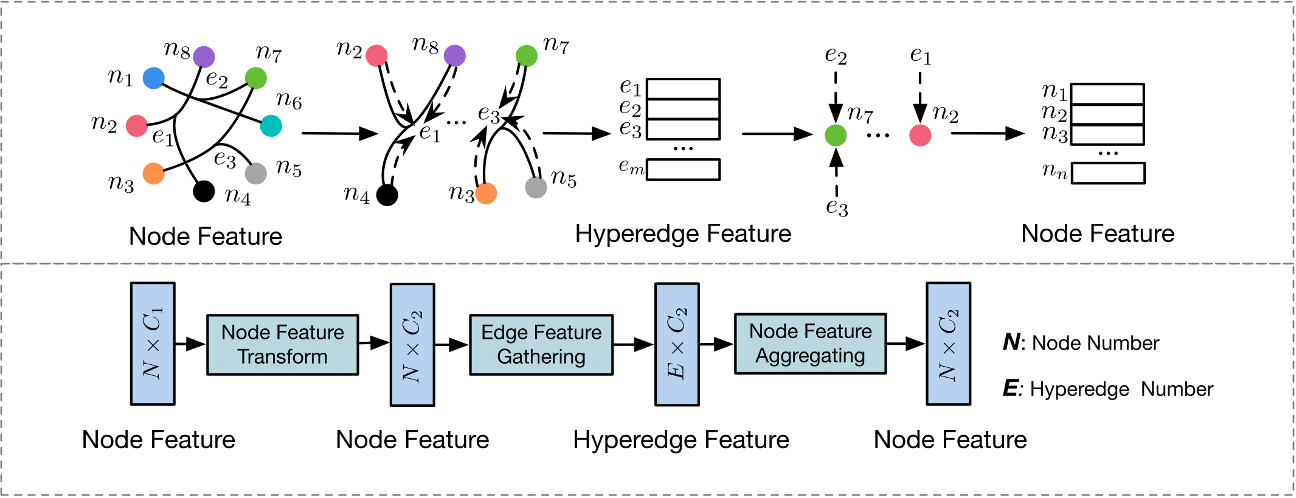
超图嵌入论文阅读2:超图神经网络
超图嵌入论文阅读2:超图神经网络 原文:Hypergraph Neural Networks ——AAAI2019(CCF-A) 源码:https://github.com/iMoonLab/HGNN 500star 概述
贡献:用于数据表示学习的超图神经网络 (HGNN) 框架…
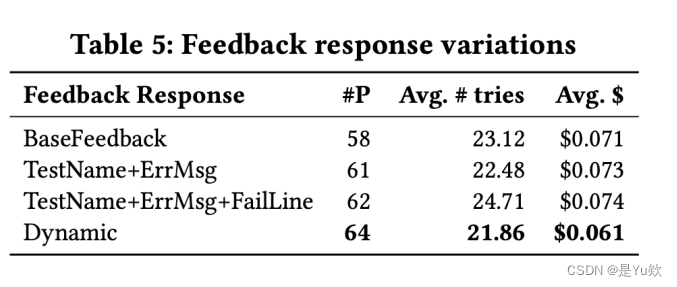
【网安大模型专题10.19】※论文5:ChatGPT+漏洞定位+补丁生成+补丁验证+APR方法+ChatRepair+不同修复场景+修复效果(韦恩图展示)
Keep the Conversation Going: Fixing 162 out of 337 bugs for $0.42 each using ChatGPT 写在最前面背景介绍自动程序修复流程Process of APR (automated program repair)1、漏洞程序2、漏洞定位模块3、补丁生成4、补丁验证 (可以学习的PPT设计)经典的…
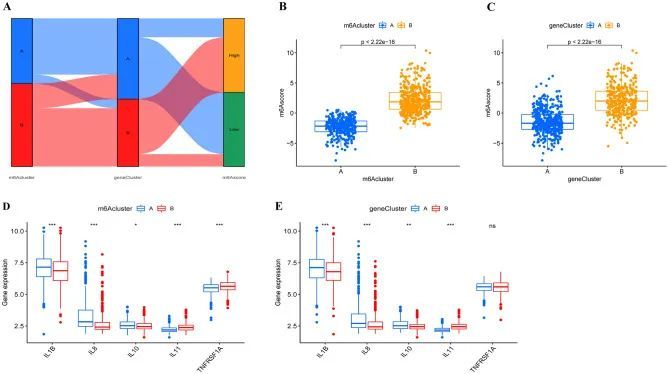
4+m6A+机器学习+分型,要素过多,没有思路的同学可借鉴
今天给同学们分享一篇生信文章“Diagnostic, clustering, and immune cell infiltration analysis of m6A regulators in patients with sepsis”,这篇文章发表在Sci Rep.期刊上,影响因子为4.6。 结果解读:
脓毒症中m6A调节因子的转录改变
…

文献关系的可视化工具
文章目录 简介网站链接Demo说明数据库 简介
One minute to find a hundred related papers
网站链接
https://www.connectedpapers.com/
Demo 说明
You can use Connected Papers to:
Get a visual overview of a new academic field
Enter a typical paper and we’ll …

【论文笔记】Point Cloud Forecasting as a Proxy for 4D Occupancy Forecasting
原文链接:https://arxiv.org/abs/2302.13130
1. 引言
运动规划需要预测其余物体的运动,但相应的感知模块如建图、目标检测、跟踪和轨迹预测通常都需要大量人力标注HD地图、语义标签、边界框或物体的轨迹,难以扩展到大型无标签数据集上。3D点…

【论文阅读】WATSON:通过聚合上下文语义从审计日志中抽象出行为(NDSS-2021)
Zeng J, Chua Z L, Chen Y, et al. WATSON: Abstracting Behaviors from Audit Logs via Aggregation of Contextual Semantics[C]//NDSS. 2021. TC_e3 trace、攻击调查、TransE、 以信息流为边界提取子图,为子图提取行为表示,进一步聚类,分析…
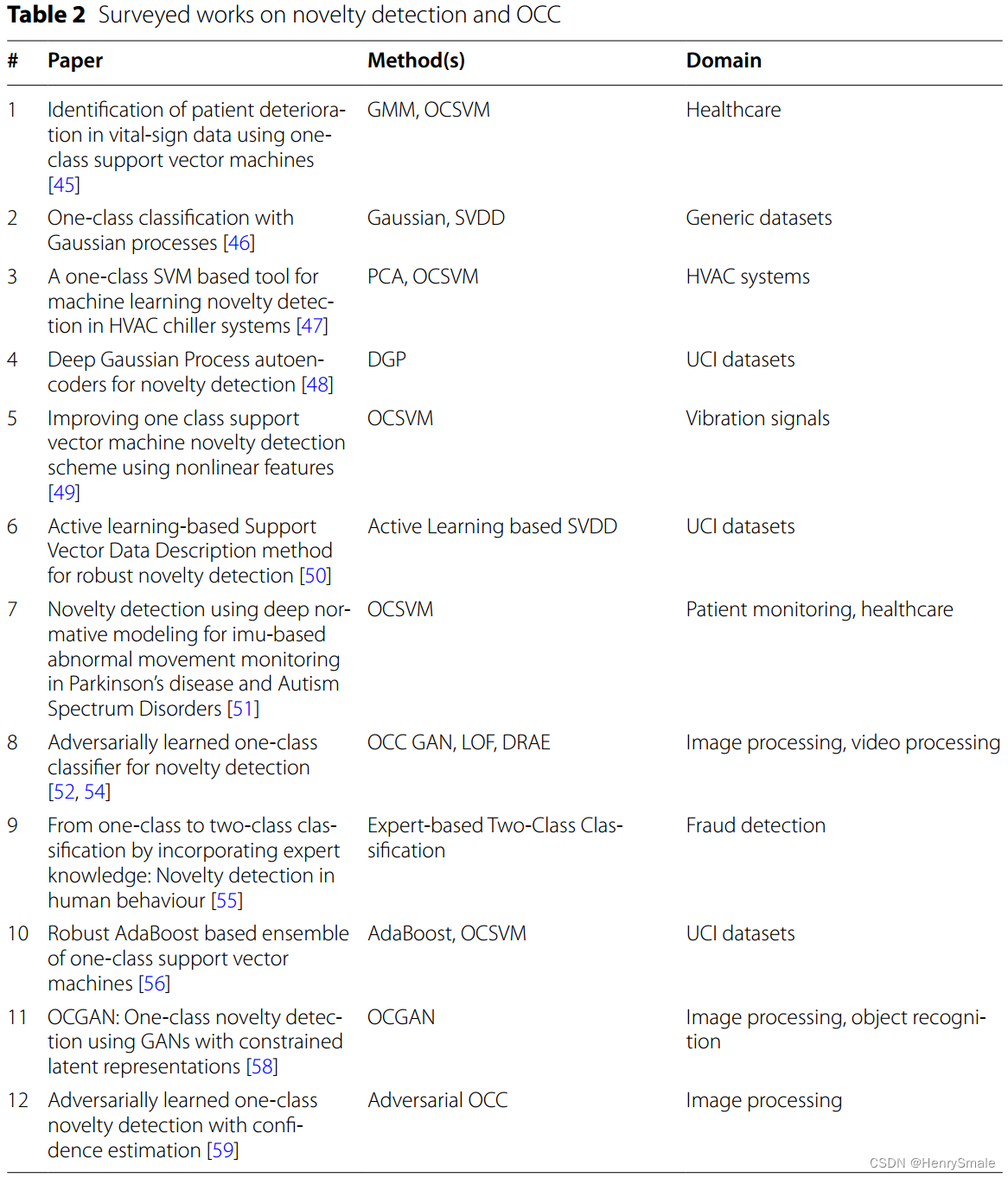
论文笔记:一分类及其在大数据中的潜在应用综述
0 概述
论文:A literature review on one‑class classification and its potential applications in big data 发表:Journal of Big Data
在严重不平衡的数据集中,使用传统的二分类或多分类通常会导致对具有大量实例的类的偏见。在这种情况…
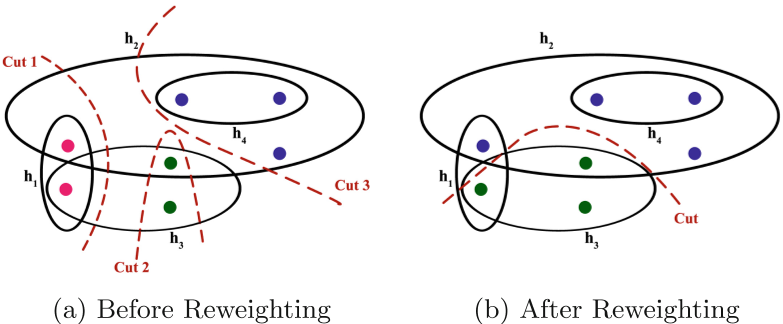
超图聚类论文阅读1:Kumar算法
超图聚类论文阅读1:Kumar算法 《超图中模块化的新度量:有效聚类的理论见解和启示》 《A New Measure of Modularity in Hypergraphs: Theoretical Insights and Implications for Effective Clustering》 COMPLEX NETWORKS 2020, SCI 3区 具体实现源码见…
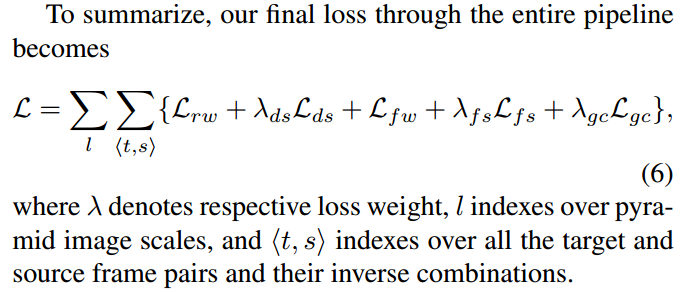
GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose 论文阅读
论文信息
题目:GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose 作者:Zhichao Yin and Jianping Shi 来源:CVPR 时间:2018
Abstract
我们提出了 GeoNet,这是一种联合无监督学习框架&a…

【论文笔记】Baidu Apollo EM Motion Planner
文章目录 AbstractI. INTRODUCTIONA. Multilane StrategyB. Path-Speed Iterative AlgorithmC. Decisions and Traffic Regulations II. EM PLANNER FRAMEWORK WITH MULTILANE STRATEGYIII. EM PLANNER AT LANE LEVELA. SL and ST Mapping (E-step)B. M-Step DP PathC. M-Step …
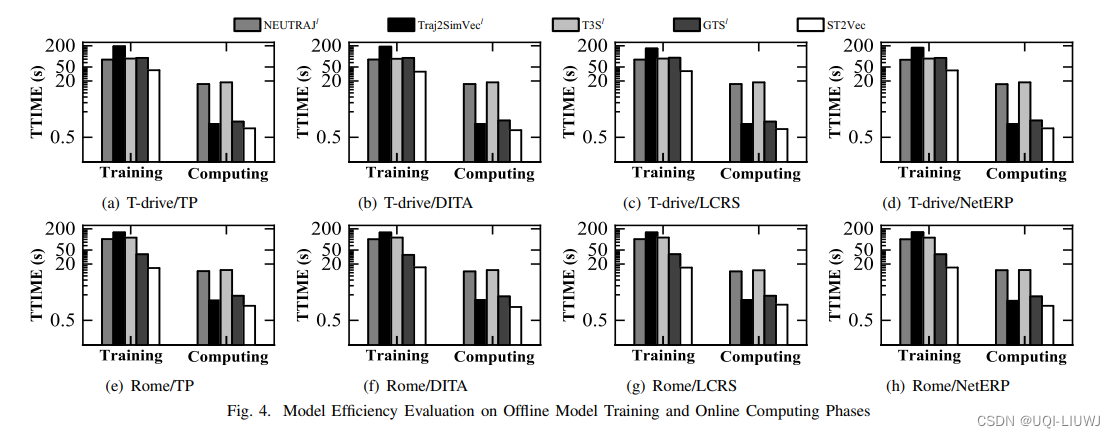
论文笔记:ST2Vec: Spatio-Temporal Trajectory SimilarityLearning in Road Networks
2022 KDD
1 intro 现有的轨迹相似性学习方案强调空间相似性而忽视了时空轨迹的时间维度,这使得它们在有时间感知的场景中效率低下 如上图,在拼车过程中,T1表示司机计划的行程,T2和T3是两个想要搭车的人。T1和T2在空间上更接近&am…
TM 学习记录--论文阅读1
这里可以查看所有论文。由于作者book只更新到第二章剩下的只有从论文中学习,但书中的目录和论文可以由于对应起来。第一二章可以对应到第一篇论文,这里。
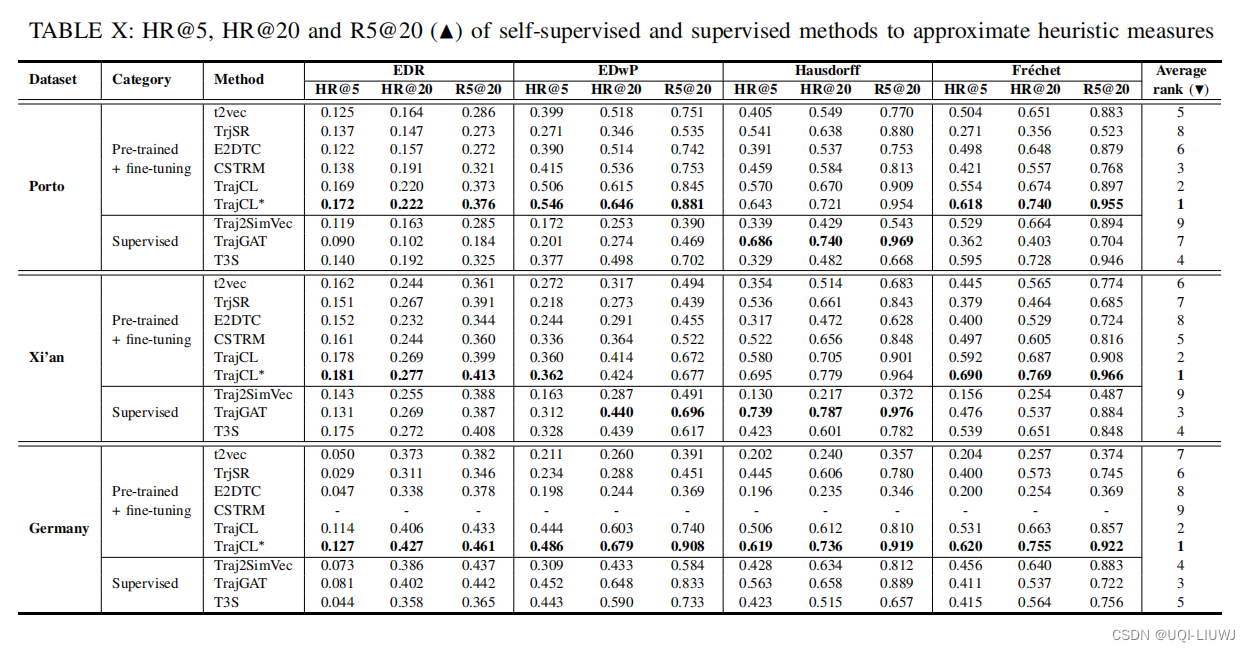
论文笔记:Contrastive Trajectory Similarity Learning withDual-Feature Attention
ICDE 2023
1 intro
1.1 背景
轨迹相似性,可以分为两类 启发式度量 根据手工制定的规则,找到两条轨迹之间基于点的匹配学习式度量 通过计算轨迹嵌入之间的距离来预测相似性值上述两种度量的挑战: 无效性: 具有不同采样率或含有噪…
![【数据科学】Scikit-learn[Scikit-learn、加载数据、训练集与测试集数据、创建模型、模型拟合、拟合数据与模型、评估模型性能、模型调整]](https://img-blog.csdnimg.cn/71420b26359a4e3a984a3277316156f7.png)
【数据科学】Scikit-learn[Scikit-learn、加载数据、训练集与测试集数据、创建模型、模型拟合、拟合数据与模型、评估模型性能、模型调整]
这里写目录标题 一、Scikit-learn二、加载数据三、训练集与测试集数据四、创建模型4.1 有监督学习评估器4.1.1 线性回归4.1.2 支持向量机(SVM)4.1.3 朴素贝叶斯4.1.4 KNN 4.2 无监督学习评估器4.2.1 主成分分析(PCA)4.2.2 K Means 五、模型拟合5.1 有监督学习5.2 无监督学习 六…
[论文笔记]Poly-encoder
引言
本文是Poly-encoder1的阅读笔记,论文题目为基于预训练模型的快速准确多句评分模型。
也是本系列第一篇基于Transformer架构的模型,对于进行句子对之间比较的任务,有两种常用的途经:Cross-encoder在句子对上进行交互完全自注意力;Bi-encoder单独地编码不同的句子。前…
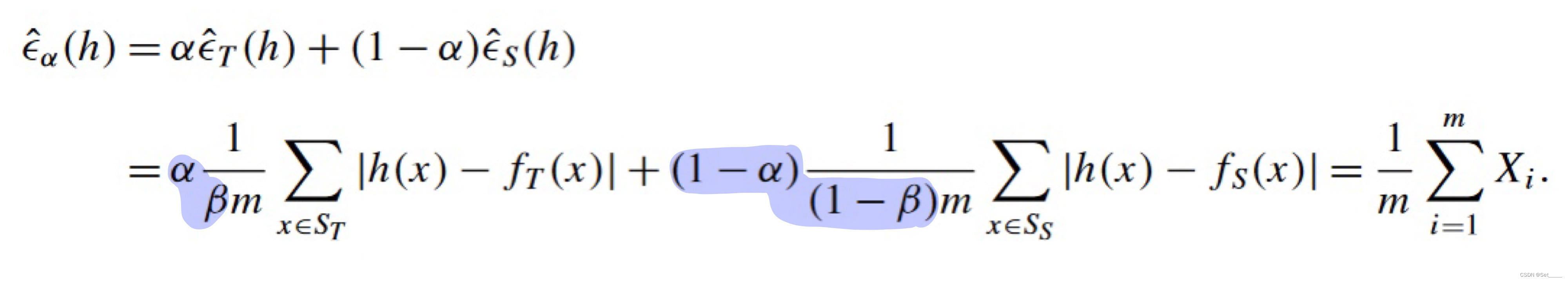
论文笔记 A theory of learning from different domains
domain adaptation 领域理论方向的重要论文. 这篇笔记主要是推导文章中的定理, 还有分析定理的直观解释. 笔记中的章节号与论文中的保持一致.
1. Introduction
domain adaptation 的设定介绍: 有两个域, source domain 与 target domain. source domain: 一组从 source dist.…

论文阅读--On optimization methods for deep learning
深度学习的优化方法研究
论文信息:Le Q V, Ngiam J, Coates A, et al. On optimization methods for deep learning[C]//Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, Washington, USA, June 28 - July 2, 2011. …
论文笔记--Enriching Word Vectors with Subword Information
论文笔记--Enriching Word Vectors with Subword Information 1. 文章简介2. 文章概括3 文章重点技术3.1 FastText模型3.2 Subword unit 4. 文章亮点5. 原文传送门6. References 1. 文章简介
标题:Enriching Word Vectors with Subword Information作者:…
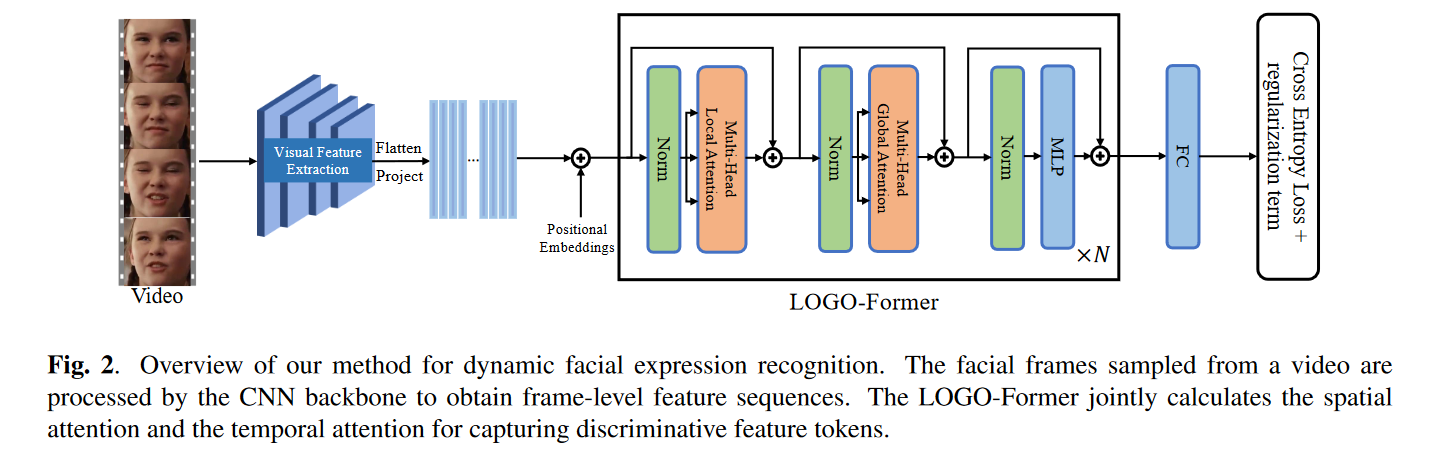
论文阅读:LOGO-Former: Local-Global Spatio-Temporal Transformer for DFER(ICASSP2023)
文章目录 摘要动机与贡献具体方法整体架构输入嵌入生成LOGO-Former多头局部注意力多头全局注意力 紧凑损失正则化 实验思考总结 本篇论文
LOGO-Former: Local-Global Spatio-Temporal Transformer for Dynamic Facial Expression Recognition发表在ICASSP(声学顶会…

Markov Chain Fingerprinting to Classify Encrypted Traffic 论文笔记
0.Abstract 在本文中,提出了用于SSL/TLS会话中传输的应用程序流量的随机指纹。这个指纹基于一阶齐次马尔可夫链,模型识别应用程序的准确率,并提供了检测异常对话的可能性。 1.Introduction 通过SSL/TLS会话时的头部信息创建统计指纹ÿ…
![[论文阅读]PV-RCNN++](https://img-blog.csdnimg.cn/c21f542c8a3f4031949e66cf43fa9c17.png)
[论文阅读]PV-RCNN++
PV-RCNN
PV-RCNN: Point-Voxel Feature Set Abstraction With Local Vector Representation for 3D Object Detection 论文网址:PV-RCNN 论文代码:PV-RCNN
简读论文
这篇论文提出了两个用于3D物体检测的新框架PV-RCNN和PV-RCNN,主要的贡献如下: 提出P…
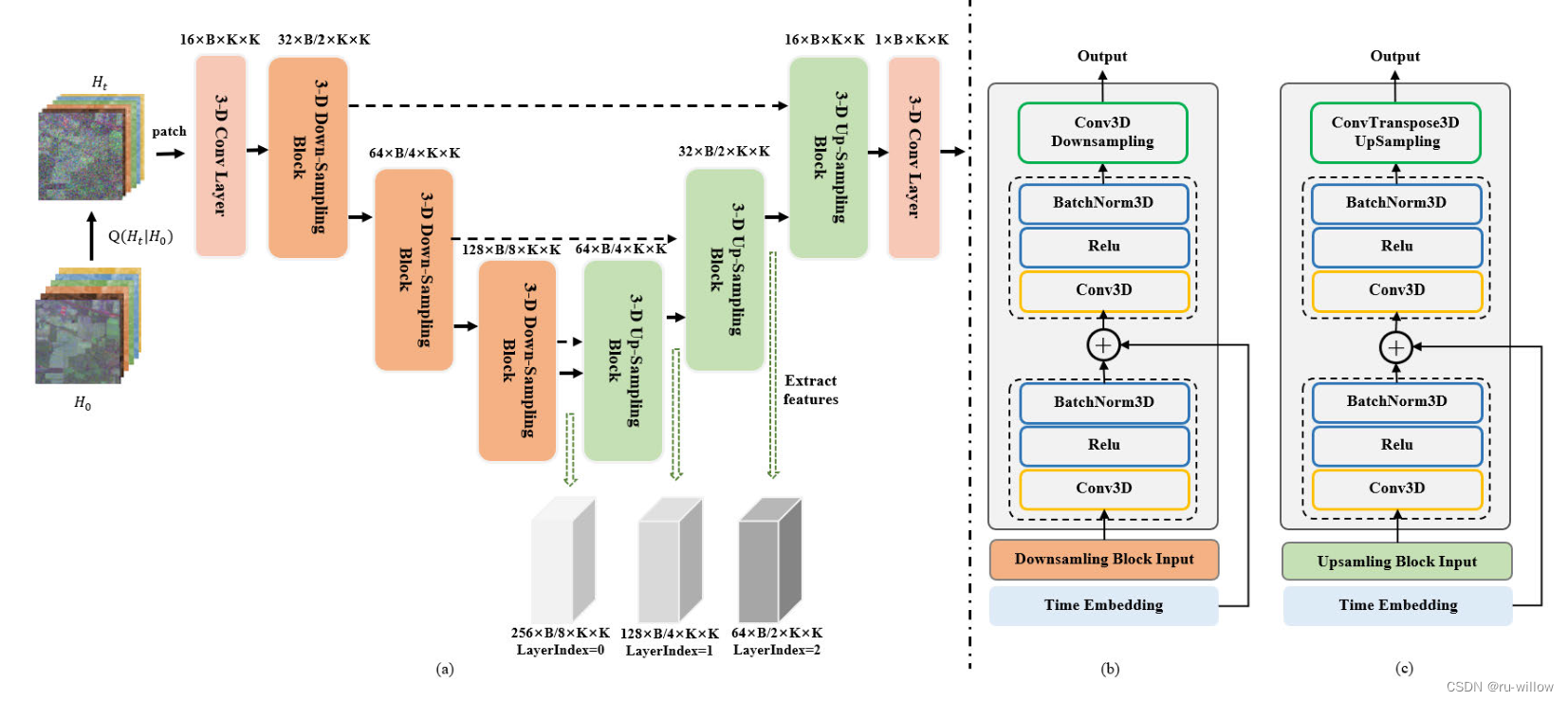
SpectralDiff论文阅读笔记
高光谱图像分类是遥感领域的一个重要问题,在地球科学中有着广泛的应用。近年来,人们提出了大量基于深度学习的HSI分类方法。然而,现有方法处理高维、高冗余和复杂数据的能力有限,这使得捕获数据的光谱空间分布和样本之间的关系具有…

Masked Image Training for Generalizable Deep Image Denoising 论文阅读笔记
CVPR2023 港科大(广州)发的一篇denoising的论文,作者里面有上海AILab的董超老师(看introduction的时候看到有一段很像董超老师 Networks are slaching off 的论文的思想,说网络overfitting的时候学习了训练集的噪声模式…

Count-based exploration with neural density models论文笔记
Count-based exploration with neural density models[J]. International Conference on Machine Learning,International Conference on Machine Learning, 2017.
基于计数的神经密度模型探索
0、问题
这篇文章的关键在于弄懂pseudo-count的概念,以及是如何运用…
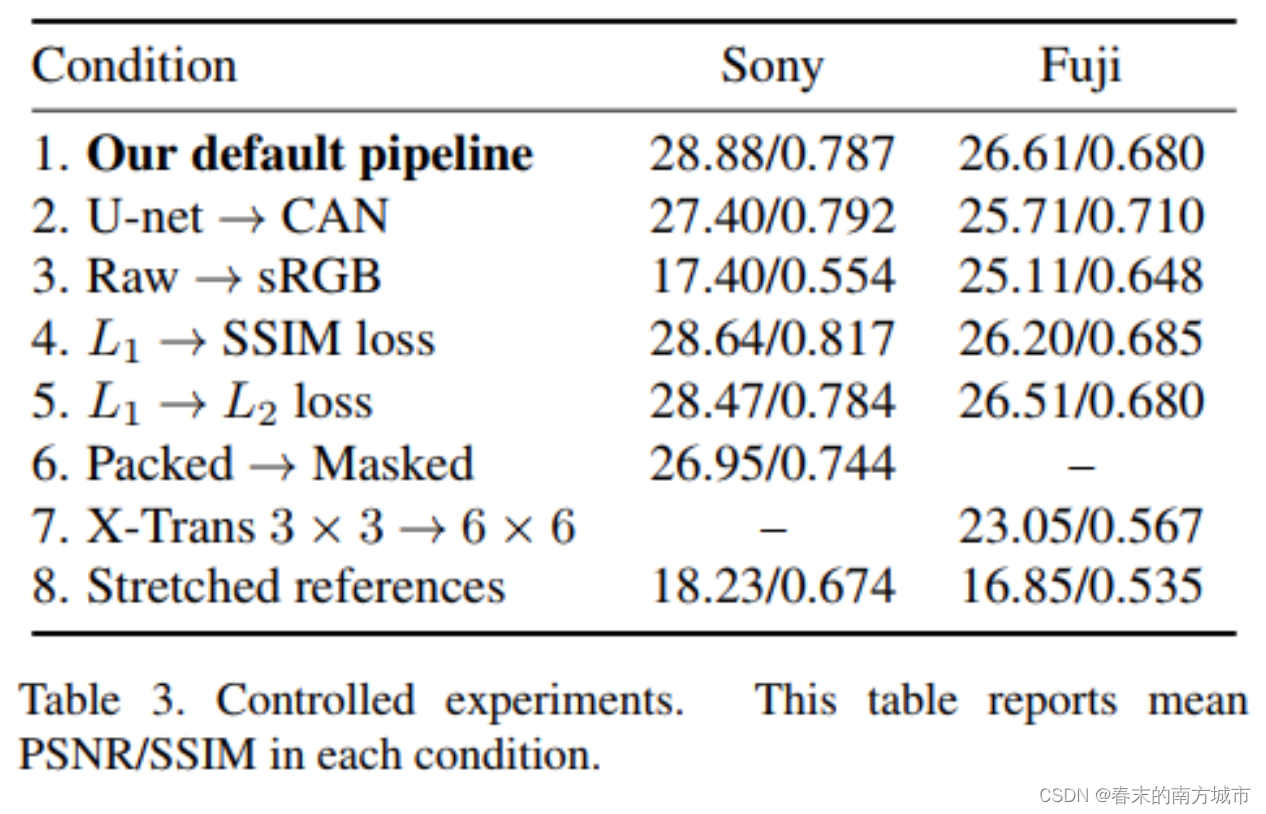
论文阅读之《Learn to see in the dark》
Learning to See in the Dark-CVPR2018
Chen ChenUIUC(伊利诺伊大学厄巴纳-香槟分校)
Qifeng Chen, Jia Xu, Vladlen Koltun Intel Labs(英特尔研究院)
文章链接:https://arxiv.org/pdf/1805.01934.pdfhttps://arxiv.org/pdf/1805.01934.p…
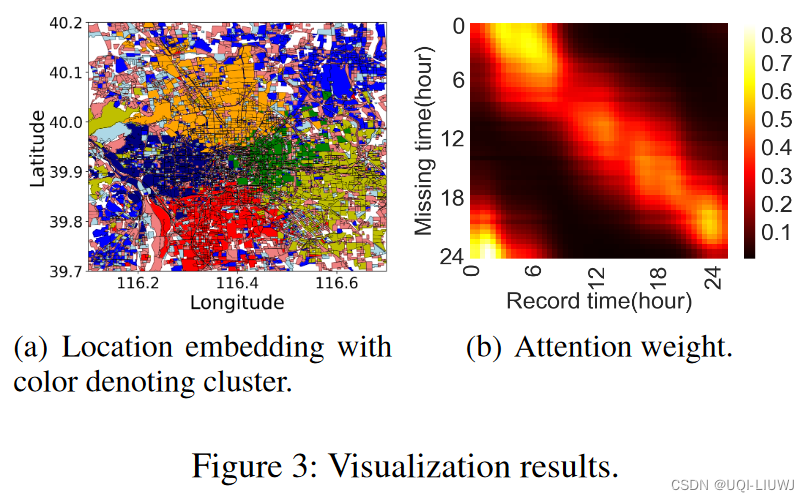
论文笔记:AttnMove: History Enhanced Trajectory Recovery via AttentionalNetwork
AAAI 2021
1 intro
1.1 背景
将用户稀疏的轨迹数据恢复至细粒度的轨迹数据是十分重要的恢复稀疏轨迹数据至细粒度轨迹数据是非常困难的 已观察到的用户位置数据十分稀疏,使得未观察到的用户位置存在较多的不确定性真实数据中存在大量噪声,如何有效的挖…

Exploration by random network distillation论文笔记
Exploration by Random Network Distillation (2018)
随机网络蒸馏探索
0、问题
这篇文章提出的随机网络蒸馏方法与Curiosity-driven Exploration by Self-supervised Prediction中提出的好奇心机制的区别?
猜想:本文是基于随机网络蒸馏提出的intrin…
医学专题--多组学在病原微生物感染中的研究思路
研究背景
病原微生物是指可以侵犯人和动物,引起感染甚至传染病的微生物,包括病毒、细菌、真菌、立克次体、寄生虫等。在我国,感染性疾病占所有疾病的50%以上,每年约1300万儿童死于感染性疾病;而临床上感染性疾病患者中…

基于GPTs个性化定制SCI论文专业翻译器
1. 什么是GPTs
GPTs是OpenAI在2023年11月6日开发者大会上发布的重要功能更新,允许用户根据特定需求定制自己的ChatGPT模型。
Introducing GPTs 官方介绍页面https://openai.com/blog/introducing-gpts
在原有自定义ChatGPT的流程中,首先需要自己编制p…

BEVFormer 论文阅读
论文链接
BEVFormer BEVFormer,这是一个将Transformer和时间结构应用于自动驾驶的范式,用于从多相机输入中生成鸟瞰(BEV)特征利用查询来查找空间/时间,并相应地聚合时空信息,从而为感知任务提供更强的表示…
chatgpt辅助论文优化表达
chatgpt辅助论文优化表达 写在最前面最终版什么是好的论文整体上:逻辑/连贯性细节上一些具体的修改例子 一些建议,包括具体的提问范例1. **明确你的需求**2. **提供上下文信息**3. **明确问题类型**4. **测试不同建议**5. **请求详细解释**综合提问范例&…

Instant-NGP论文笔记
文章目录 论文笔记 论文笔记 instant-ngp的nerf模型与vanilla nerf的模型架构相同。
instant-ngp的nerf模型包含两个MLP,第一个MLP就两个全连接,输入维度是32(16层分辨率x2),输出是16(用于预测密度&#x…
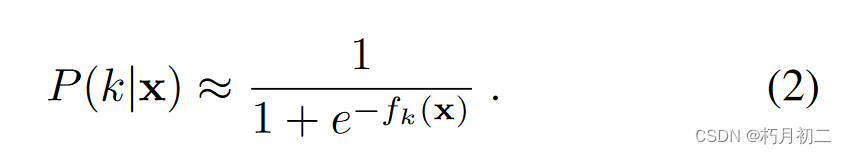
(论文阅读26/100)Weakly-supervised learning with convolutional neural networks
26.文献阅读笔记 简介 题目 Weakly-supervised learning with convolutional neural networks 作者 Maxime Oquab,Leon Bottou,Ivan Laptev,Josef Sivic,CVPR,2015 原文链接 http://www.cv-foundation.org/open…
(论文阅读31/100)Stacked hourglass networks for human pose estimation
31.文献阅读笔记 简介 题目 Stacked hourglass networks for human pose estimation 作者 Alejandro Newell, Kaiyu Yang, and Jia Deng, ECCV, 2016. 原文链接 https://arxiv.org/pdf/1603.06937.pdf 关键词 Human Pose Estimation 研究问题 CNN运用于Human Pose E…

【文章学习系列之模型】DAGMM
本章内容 文章概况模型结构损失函数实验结果实验分析总结 文章概况
《Deep Autoencoding Gaussian Mixture Model for Unsupervised Anomaly Detection》是2018年发表于ICLR的一篇论文,该论文提出一种端到端的无监督异常检测方法DAGMM,取得了不错的效果…
Talk2BEV: Language-enhanced Bird’s-eye View Maps for Autonomous Driving
论文标题为“Talk2BEV: Language-enhanced Bird’s-eye View Maps for Autonomous Driving”,主要介绍了一种新型的视觉-语言模型(LVLM)界面,用于自动驾驶情境中的鸟瞰图(BEV)映射。以下是论文的主要内容概…
LLM-Embedder
1. 目标
训出一个统一的embedding模型LLM-Embedder,旨在全面支持LLM在各种场景中的检索增强
2. 模型的四个关键检索能力
knowledge:解决knowledge-intensive任务memory:解决long-context modelingexample:解决in-context learn…
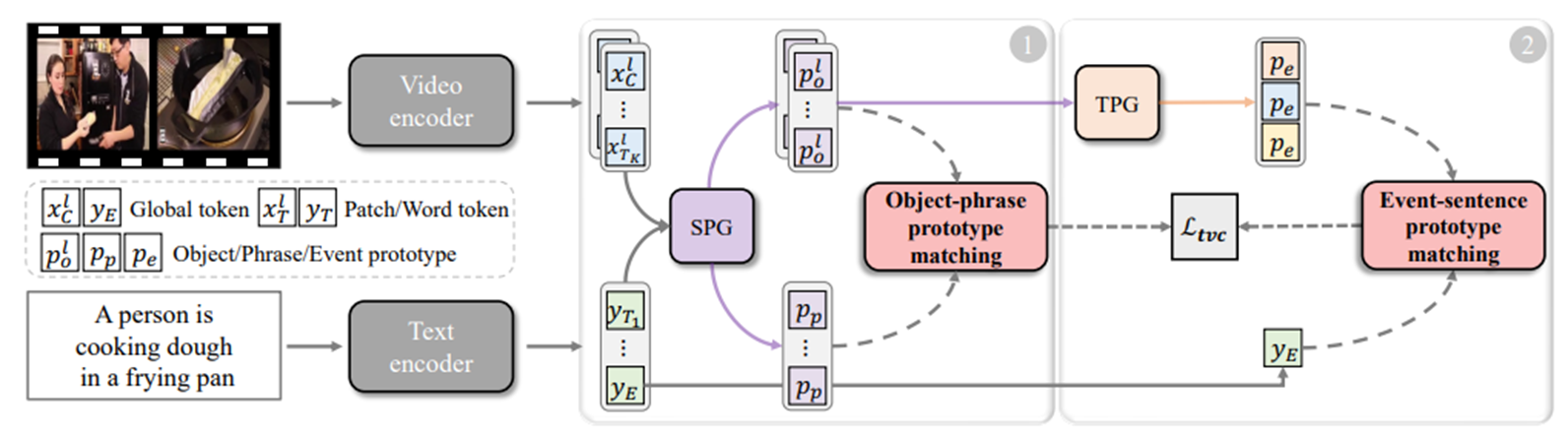
【论文阅读】Progressive Spatio-Temporal Prototype Matching for Text-Video Retrieval
资料链接
论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Li_Progressive_Spatio-Temporal_Prototype_Matching_for_Text-Video_Retrieval_ICCV_2023_paper.pdf 代码链接:https://github.com/imccretrieval/prost
背景与动机 文章发…
【论文阅读】基于隐蔽带宽的汽车控制网络鲁棒认证(一)
文章目录 Abstract第一章 引言1.1 问题陈述1.2 研究假设1.3 贡献1.4 大纲 第二章 背景和相关工作2.1 CAN安全威胁2.1.1 CAN协议设计2.1.2 CAN网络攻击2.1.3 CAN应用攻击 2.2 可信执行2.2.1 软件认证2.2.2 消息身份认证2.2.3 可信执行环境2.2.4 Sancus2.2.5 VulCAN 2.3 侧信道攻…
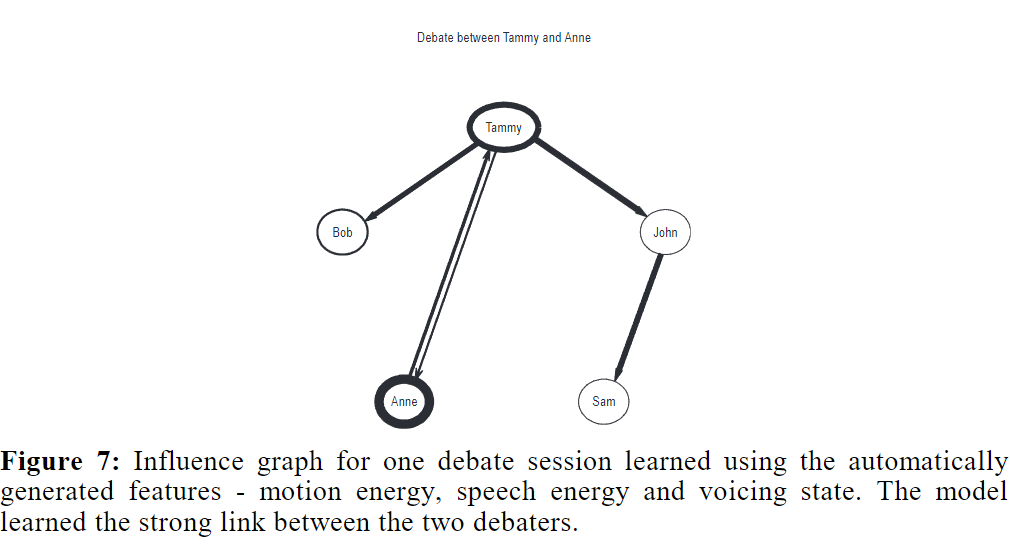
论文阅读 - Learning Human Interactions with the Influence Model
NIPS01 早期模型
要求知识背景: 似然函数,极大似然估计、HMM、期望最大化
目录
1 Introduction
2 The Facilitator Room
3 T h e I n f l u e n c e M o d e l
3 . 1 ( R e ) i n t r o d u c i n g t h e I n f l u e n c e M o d e l
3 . 2 L e…

三篇论文:速览GPT在网络安全最新论文中的应用案例
GPT在网络安全领域的应用案例 写在最前面论文1:Chatgpt/CodeX引入会话式 APR 范例利用验证反馈LLM 的长期上下文窗口:更智能的反馈机制、更有效的信息合并策略、更复杂的模型结构、鼓励生成多样性和GPT类似的步骤:Conversational APR 对话式A…
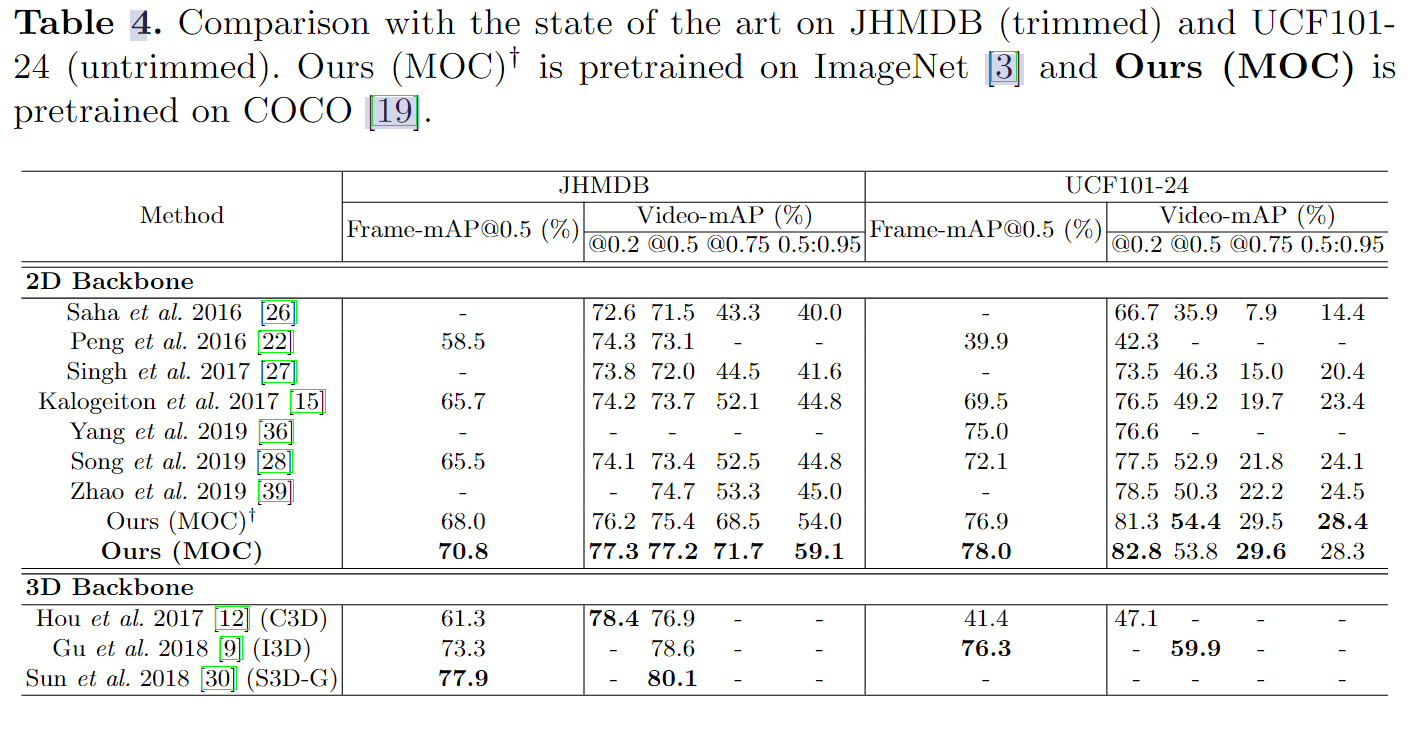
【Spatial-Temporal Action Localization(五)】论文阅读2020年
文章目录 1. Actions as Moving Points摘要和结论引言:针对痛点和贡献模型框架实验 1. Actions as Moving Points
Actions as Moving Points (ECCV 2020)
摘要和结论
MovingCenter Detector (MOCdetector) 通过将动作实例视为移动点的轨迹。通过三个分支生成 tub…
论文阅读:Distributed Initialization for VVIRO with Position-Unknown UWB Network
前言
Distributed Initialization for Visual-Inertial-Ranging Odometry with Position-Unknown UWB Network这篇论文是发表在ICRA 2023上的一篇文章,本文提出了一种基于位置未知UWB网络的一致性视觉惯性紧耦合优化测距算法( DC-VIRO )的分布式初始化方法。
对于…
![[论文阅读]CT3D——逐通道transformer改进3D目标检测](https://img-blog.csdnimg.cn/direct/6448668c9e2d4c8a8b021533d303ea9b.png)
[论文阅读]CT3D——逐通道transformer改进3D目标检测
CT3D
论文网址:CT3D 论文代码:CT3D
简读论文
本篇论文提出了一个新的两阶段3D目标检测框架CT3D,主要的创新点和方法总结如下:
创新点:
(1) 提出了一种通道注意力解码模块,可以进行全局和局部通道聚合,生成更有效的解码权重。
(2) 提出了建议到点嵌…

【稳定检索|投稿优惠】2024年经济管理与安全科学国际学术会议(EMSSIC 2024)
2024年经济管理与安全科学国际学术会议(EMSSIC 2024) 2024 International Conference on Economic Management and Security Sciences(EMSSIC 2024) 一、【会议简介】 2024年经济管理与安全科学国际学术会议(EMSSIC 2024),将于繁华的上海城召开。这次会议的主题是“…
《论文阅读》DualGATs:用于对话中情绪识别的双图注意力网络
《论文阅读》DualGATs:用于会话中情感识别的双图注意力网络 前言摘要模型架构DisGAT图构建图关系类型图节点更新SpkGAT图构建图关系类型图节点更新交互模块情绪预测损失函数问题前言
今天为大家带来的是《DualGATs: Dual Graph Attention Networks
分析Pun老师的论文
Combating copycatting from emerging market suppliers in global supply chains 疯狂看潘老师的论文,感觉找论文的方向好难啊,好做的别人都做了,不好做的,你又没想法能做。
这篇文章就是讲保护全球制造商免受新兴市场普遍存在的…
![[论文阅读] CLRerNet: Improving Confidence of Lane Detection with LaneIoU](https://img-blog.csdnimg.cn/914be7db17eb404491ad773e49a61a6f.png)
[论文阅读] CLRerNet: Improving Confidence of Lane Detection with LaneIoU
Abstract
车道标记检测是自动驾驶和驾驶辅助系统的重要组成部分。采用基于行的车道表示的现代深度车道检测方法在车道检测基准测试中表现出色。通过初步的Oracle实验,我们首先拆分了车道表示组件,以确定我们方法的方向。我们的研究表明,现有…

【论文阅读笔记】Detecting AI Trojans Using Meta Neural Analysis
个人阅读笔记,如有错误欢迎指出!
会议:2021 S&P Detecting AI Trojans Using Meta Neural Analysis | IEEE Conference Publication | IEEE Xplore
问题: 当前防御方法存在一些难以实现的假设,或者要求直…

论文阅读_AI生成检测_Ghostbuster
英文名称: Ghostbuster: Detecting Text Ghostwritten by Large Language Models 中文名称: 捉鬼人:检测大语言模型生成的文本 文章: http://arxiv.org/abs/2305.15047 代码: https://github.com/vivek3141/ghostbuster 作者: Vivek Verma,Eve Fleisig&a…
【论文阅读】FreeMatch: Self-adaptive Thresholding for Semi-supervised Learning
论文下载 GitHub bib:
INPROCEEDINGS{wang2023freematch,title {FreeMatch: Self-adaptive Thresholding for Semi-supervised Learning},author {Wang, Yidong and Chen, Hao and Heng, Qiang and Hou, Wenxin and Fan, Yue and and Wu, Zhen and Wang, Jindong and Savv…
《功能磁共振多变量模式分析中空间分辨率对解码精度的影响》论文阅读
《The effect of spatial resolution on decoding accuracy in fMRI multivariate pattern analysis》 文章目录 一、简介论文的基本信息摘要 二、论文主要内容语音刺激的解码任务多变量模式分析(MVPA)K空间 空间分辨率和平滑对MVPA的影响平滑的具体过程…
![[论文阅读]Generalized Attention——空间注意力机制](https://img-blog.csdnimg.cn/direct/07f66202a6d842c5b395748444d84719.png)
[论文阅读]Generalized Attention——空间注意力机制
Generalized Attention
An Empirical Study of Spatial Attention Mechanisms in Deep Networks 论文网址:Generalized Attention 论文代码:文章最后有GeneralizedAttention的实现代码
简读论文
本文主要研究了深度学习网络中的注意力机制。作者们从不…

【论文笔记】Universal Guidance for Diffusion Models
Abstract
典型的扩散模型经过训练以接受特定形式的条件作用(最常见的是文本),并且如果不经过重新训练就不能接受其他形式的条件的作用。 这项工作中提出了一种通用制导算法(universal guidance algorithm),使扩散模型能够通过任意…
Learning Memory-guided Normality for Anomaly Detection 论文阅读
Learning Memory-guided Normality for Anomaly Detection 摘要1.介绍2.相关工作3.方法3.1网络架构3.1.1 Encoder and decoder3.1.2 Memory 3.2. Training loss3.3. Abnormality score 4.实验5.总结总结&代码复现: 文章信息: 发表于:cvpr…
《论文阅读》使用条件变分自动编码器学习神经对话模型的语篇水平多样性 2017 ACL
《论文阅读》使用条件变分自动编码器学习神经对话模型的语篇水平多样性 2017 ACL 前言简介相关知识Stochastic Gradient Variational BayesMultivariate Gaussian DistributionIsotropic Gaussian DistributionReparameterization Trickprior network & posterior network …
7+WGCNA+机器学习+实验+泛癌分析,多要素干湿结合
今天给同学们分享一篇生信文章“Analysis and Experimental Validation of Rheumatoid Arthritis Innate Immunity Gene CYFIP2 and Pan-Cancer”,这篇文章发表在Front Immunol期刊上,影响因子为7.3。 结果解读:
DEG筛选和数据预处理
数据在…

论文阅读-Null-text Inversion for Editing Real Images using Guided Diffusion Models
一、论文信息
作者团队: 论文链接:https://arxiv.org/pdf/2211.09794.pdf
代码链接:https://github.com/google/prompt-to-prompt
二、Conditional Diffusion(classifier-free guidance) Classifier-free guidance方法训练&…
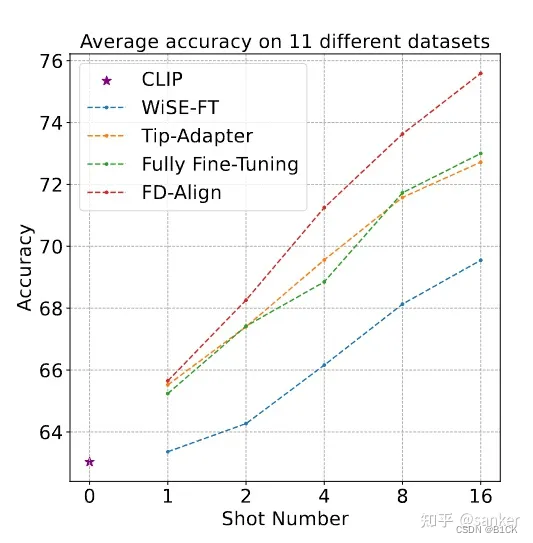
FD-Align论文阅读
FD-Align: Feature Discrimination Alignment for Fine-tuning Pre-Trained Models in Few-Shot Learning(NeurIPS 2023)
主要工作是针对微调的和之前的prompt tuining,adapter系列对比
Motivation:
通过模型对虚假关联性的鲁棒…
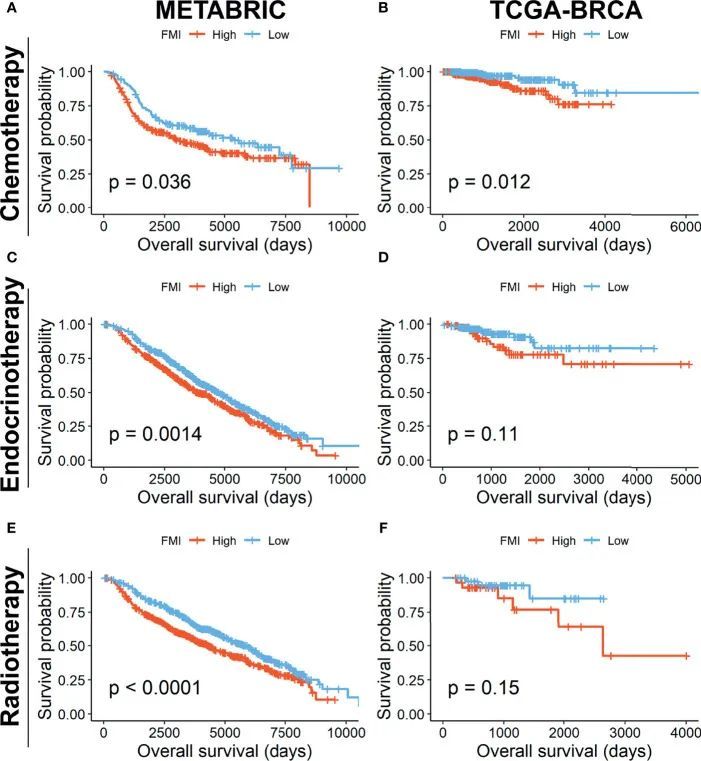
7+脂肪酸代谢+免疫,简单又高效,思路简单到让你怀疑人生
今天给同学们分享一篇生信文章“Prognosis and Dissection of Immunosuppressive Microenvironment in Breast Cancer Based on Fatty Acid Metabolism-Related Signature”,这篇文章发表在Front Immunol期刊上,影响因子为7.3。 结果解读:
癌…
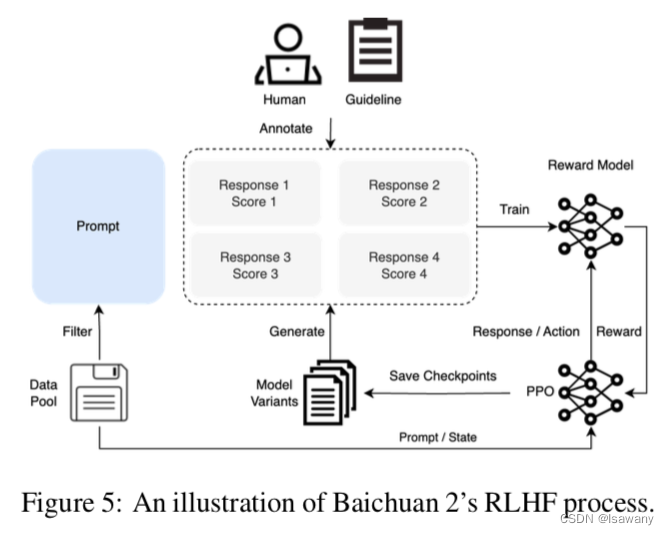
论文笔记--Baichuan 2: Open Large-scale Language Models
论文笔记--Baichuan 2: Open Large-scale Language Models 1. 文章简介2. 文章概括3 文章重点技术3.1 预训练3.1.1 预训练数据3.1.2 模型架构 3.2 对齐3.2.1 SFT3.2.2 Reward Model(RM)3.2.3 PPO 3.3 安全性 4. 文章亮点5. 原文传送门 1. 文章简介
标题:Baichuan 2…
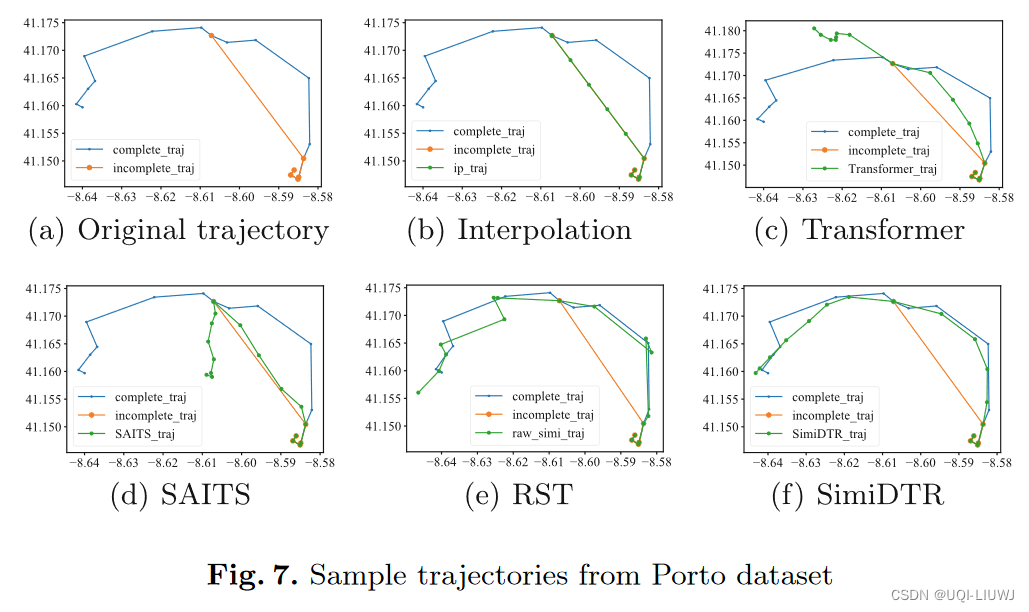
论文笔记:SimiDTR: Deep Trajectory Recovery with Enhanced Trajectory Similarity
DASFFA 2023
1 intro
1.1 背景
由于设备和环境的限制(设备故障,信号缺失),许多轨迹以低采样率记录,或者存在缺失的位置,称为不完整轨迹 恢复不完整轨迹的缺失空间-时间点并降低它们的不确定性是非常重要…
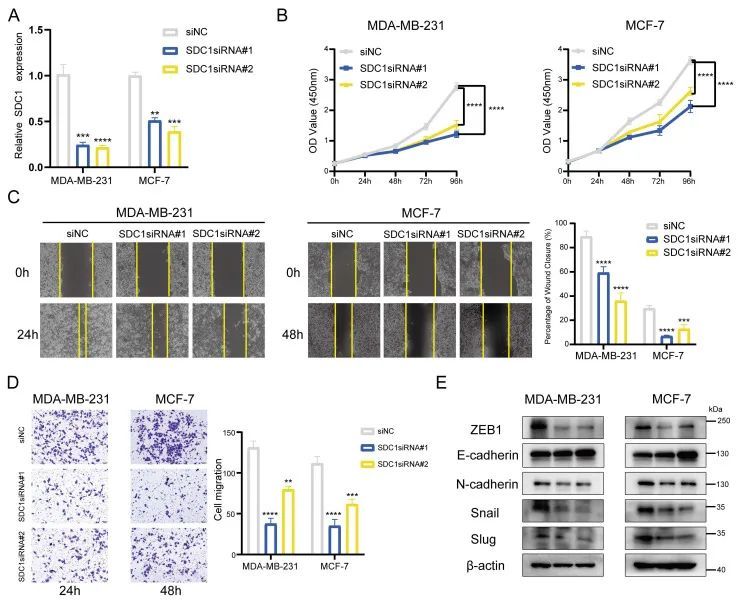
预后模型+实验生信思路,新颖可重复发文空间大
今天给同学们分享一篇生信文章“Novel Implication of the Basement Membrane for Breast Cancer Outcome and Immune Infiltration”,这篇文章发表在Int J Biol Sci期刊上,影响因子为3.5。 结果解读:
建立骨髓评分的预后骨髓基因选择策略
…
论文阅读:Distributed Initialization for VIRO with Position-Unknown UWB Network
前言
Distributed Initialization for Visual-Inertial-Ranging Odometry with Position-Unknown UWB Network这篇论文是发表在ICRA 2023上的一篇文章,本文提出了一种基于位置未知UWB网络的一致性视觉惯性紧耦合优化测距算法( DC-VIRO )的分布式初始化方法。
对于…
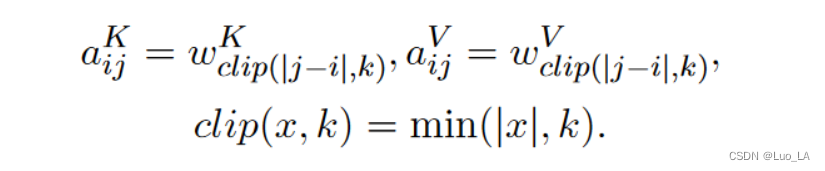
【论文笔记】A Transformer-based Approach for Source Code Summarization
A Transformer-based Approach for Source Code Summarization 1. Introduction2. Approach2.1 ArchitectureSelf-AttentionCopy Attention 2.2 Position Representations编码绝对位置编码成对关系 1. Introduction
生成描述程序功能的可读摘要称为源代码摘要。在此任务中&…
代币化对网约车区块链平台的影响
The effects of tokenization on ride-hailing blockchain platforms
再一次分析一下一篇关于区块链的文章,这篇文章比较新,2023年发表在POMS上。
由于这篇文章跟之前那几篇关注假货的文章的重点不一样,所以需要仔细读一下他的INTRODUCTION…
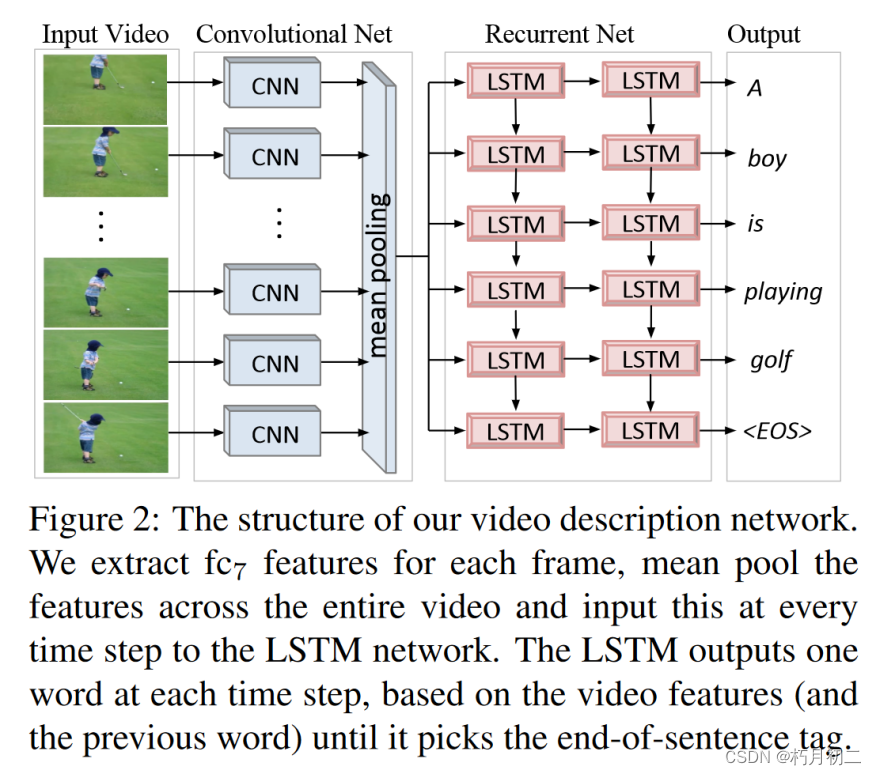
(论文阅读40-45)图像描述1
40.文献阅读笔记(m-RNN) 简介 题目 Explain Images with Multimodal Recurrent Neural Networks 作者 Junhua Mao, Wei Xu, Yi Yang, Jiang Wang, Alan L. Yuille, arXiv:1410.1090 原文链接 http://arxiv.org/pdf/1410.1090.pdf 关键词 m-RNN、…

《Deep learning for fine-grained image analysis: A survey》阅读笔记
论文标题
《Deep learning for fine-grained image analysis: A survey》
作者
魏秀参,旷世研究院
初读
摘要 细粒度图像分析(FGIA)的任务是分析从属类别的视觉对象。 细粒度性质引起的类间小变化和类内大变化使其成为一个具有挑战性的…

论文阅读:JINA EMBEDDINGS: A Novel Set of High-Performance Sentence Embedding Models
Abstract
JINA EMBEDINGS构成了一组高性能的句子嵌入模型,擅长将文本输入转换为数字表示,捕捉文本的语义。这些模型在密集检索和语义文本相似性等应用中表现出色。文章详细介绍了JINA EMBEDINGS的开发,从创建高质量的成对(pairwi…

深度学习中的图像融合:图像融合论文阅读与实战
个人博客:Sekyoro的博客小屋 个人网站:Proanimer的个人网站
abs
介绍图像融合概念,回顾sota模型,其中包括数字摄像图像融合,多模态图像融合,
接着评估一些代表方法
介绍一些常见应用,比如RGBT目标跟踪,…

论文阅读:“基于特征检测与深度特征描述的点云粗对齐算法”
文章目录 摘要简介相关工作粗对齐传统的粗对齐算法基于深度学习的粗对齐算法 特征检测及描述符构建 本文算法ISS 特征检测RANSAC 算法3DMatch 算法 实验结果参考文献 摘要
点云对齐是点云数据处理的重要步骤之一,粗对齐则是其中的难点。近年来,基于深度…

大一统模型 Universal Instance Perception as Object Discovery and Retrieval 论文阅读笔记
Universal Instance Perception as Object Discovery and Retrieval 论文阅读笔记 一、Abstract二、引言三、相关工作实例感知通过类别名进行检索通过语言表达式的检索通过指代标注的检索 统一的视觉模型Unified Learning ParadigmsUnified Model Architectures 四、方法4.1 Pr…

论文阅读:“Model-based teeth reconstruction”
文章目录 AbstractIntroductionTeeth Prior ModelData PreparationParametric Teeth Model Teeth FittingTeeth Boundary Extraction Reference Abstract
近年来,基于图像的人脸重建方法日趋成熟。这些方法可以捕捉整个面部或面部特定区域(如头发、眼睛…

RC-MVSNet:无监督的多视角立体视觉与神经渲染--论文笔记(2022年)
RC-MVSNet:无监督的多视角立体视觉与神经渲染--论文笔记(2022年) 摘要1 引言2 相关工作2.1 基于监督的MVS2.2 无监督和自监督MVS2.3 多视图神经渲染 3 实现方法3.1 无监督的MVS网络 Chang, D. et al. (2022). RC-MVSNet: Unsupervised Multi-…

论文阅读:“Appearance Capture and Modeling of Human Teeth”
文章目录 AbstractIntroductionMethod OverviewTeeth Appearance ModelEnamelDentinGingiva and oral cavity Data AcquisitionImage captureGeometry capture ResultsReferences Abstract
如果要为电影,游戏或其他类型的项目创建在虚拟环境中显示的人类角色&#…
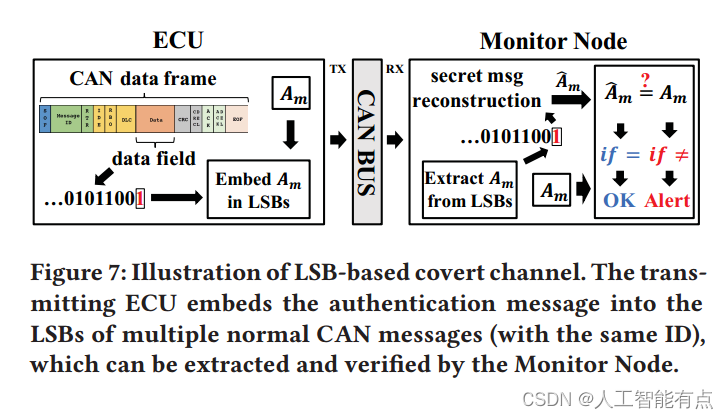
【论文阅读】TACAN:控制器局域网中通过隐蔽通道的发送器认证
文章目录 摘要一、引言二、相关工作三、系统和对手模型3.1 系统模型对手模型 四、TACAN4.1 TACAN 架构4.2 发送方认证协议4.3 基于IAT的隐蔽通道4.4 基于偏移的隐蔽通道(本节公式格式暂未整理)4.5 基于LSB的隐蔽通道 摘要
如今,汽车系统与现…
【论文阅读】【基于隐蔽带宽的汽车控制网络鲁棒认证】中的一些顶会论文摘要
读摘要,了解面貌 文章目录 [12][51][58][35][xx] 原文:https://webofscience.clarivate.cn/wos/alldb/full-record/WOS:000387820900034 Large numbers of smart connected devices, also named as the Internet of Things (IoT), are permeating our en…
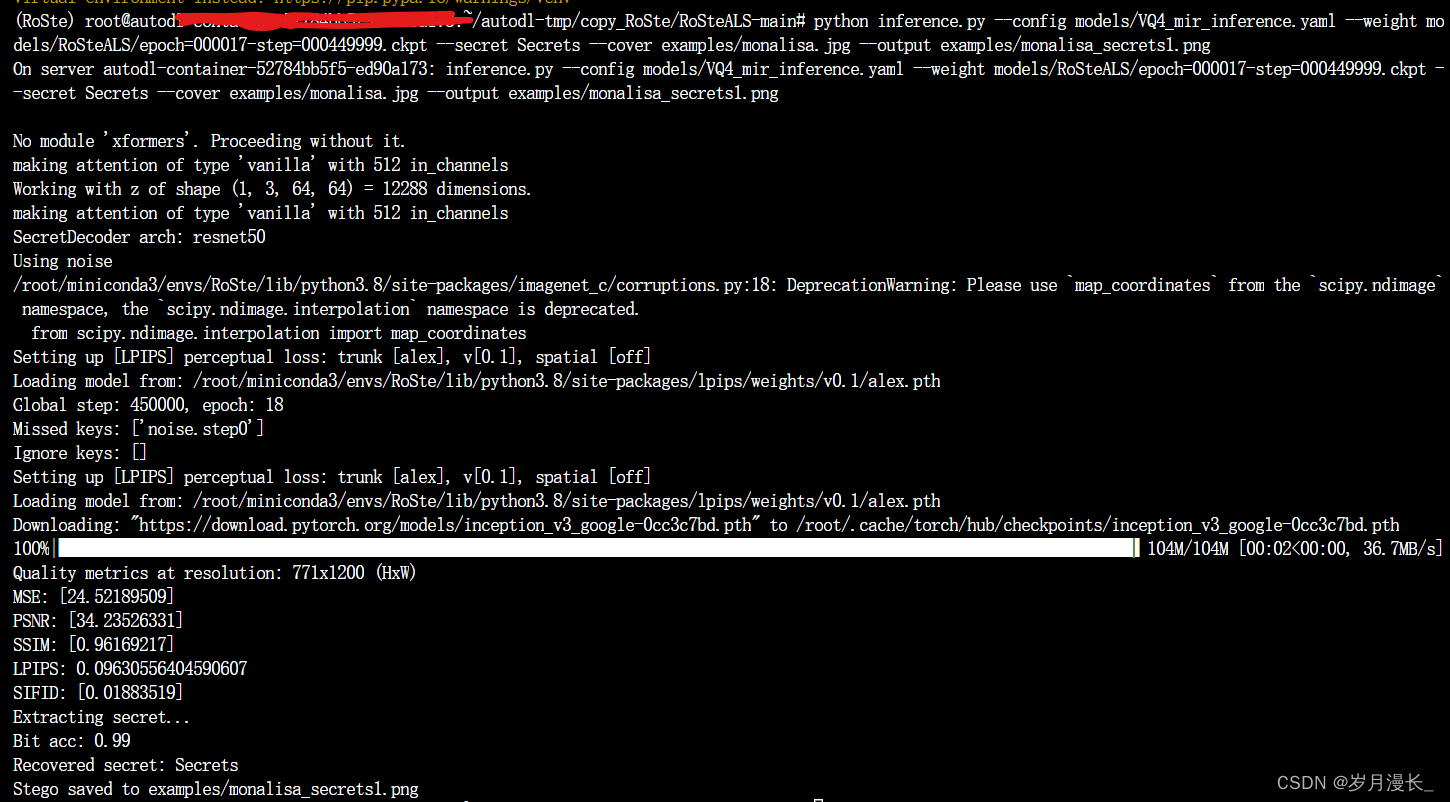
【论文复现】RoSteALS: Robust Steganography using Autoencoder Latent Space-2023-CVPR
代码链接:https://github.com/TuBui/RoSteALS
一定要按照dockerfile,requirements.txt和requirements2.txt配置环境
需要补充的库: pip安装:omegaconf slack slackclient bchlib (0.14.0版本) einops imagenet-c conda安装&…
【论文阅读】基于隐蔽带宽的汽车控制网络鲁棒认证(三)
文章目录 第六章 通过认证帧定时实现VulCAN的非once同步6.1 问题陈述6.2 方法概述6.3 动机和缺点6.3.1 认证帧定时隐蔽通信6.3.2 VulCAN的梵蒂冈后端Nonce同步的应用 6.4 设计与实现6.4.1发送方6.4.2 接收方6.4.3 设计参数配置6.4.4 实现 6.5 安全注意事项6.5.1 系统模型6.5.2攻…
5+单细胞+WGCNA+预后模型+实验,经典肿瘤生信思路
今天给同学们分享一篇生信文章“Single cell sequencing analysis constructed the N7-methylguanosine (m7G)-related prognostic signature in uveal melanoma”,这篇文章发表在Aging (Albany NY)期刊上,影响因子为5.2。 结果解读: 图1展示…

《虹》国家级月刊维普收录期刊投稿
《虹》杂志由中华人民共和国国家新闻出版署正式批准,国内外公开发行的优秀期刊。虹杂志由团中央主管、中国青年出版总社主办,发行周期为月刊。为各行各业广大朋友提供一个学术交流的平台。
刊名:虹
主管单位:共青团中央
主办单…
文献解读:荧光原位杂交(FISH)
荧光原位杂交(fluorescence in situ hybridization,FISH)技术基于与任何DNA杂交方法相同的原理,该方法利用单链DNA与互补DNA退火的能力。在FISH的情况下,靶DNA可以是中期染色体、间期细胞核或组织切片,附着…
论文阅读三——端到端的帧到凝视估计
论文阅读三——端到端的帧到凝视估计 主要内容研究问题文章的解题思路文章的主要结构 论文实验关于端到端凝视估计的数据集3种基线模型与EFE模型的对比在三个数据集中与SOTA进行比较 问题分析重要架构U-Net 基础知识 主要内容
文章从端到端的方法出发,提出了根据he…

论文阅读_反思模型_Reflexion
英文名称: Reflexion: Language Agents with Verbal Reinforcement Learning 中文名称: 反思:具有言语强化学习的语言智能体 文章: http://arxiv.org/abs/2303.11366 代码: https://github.com/noahshinn/reflexion 作者: Noah Shinn (Northeastern University) 日期…
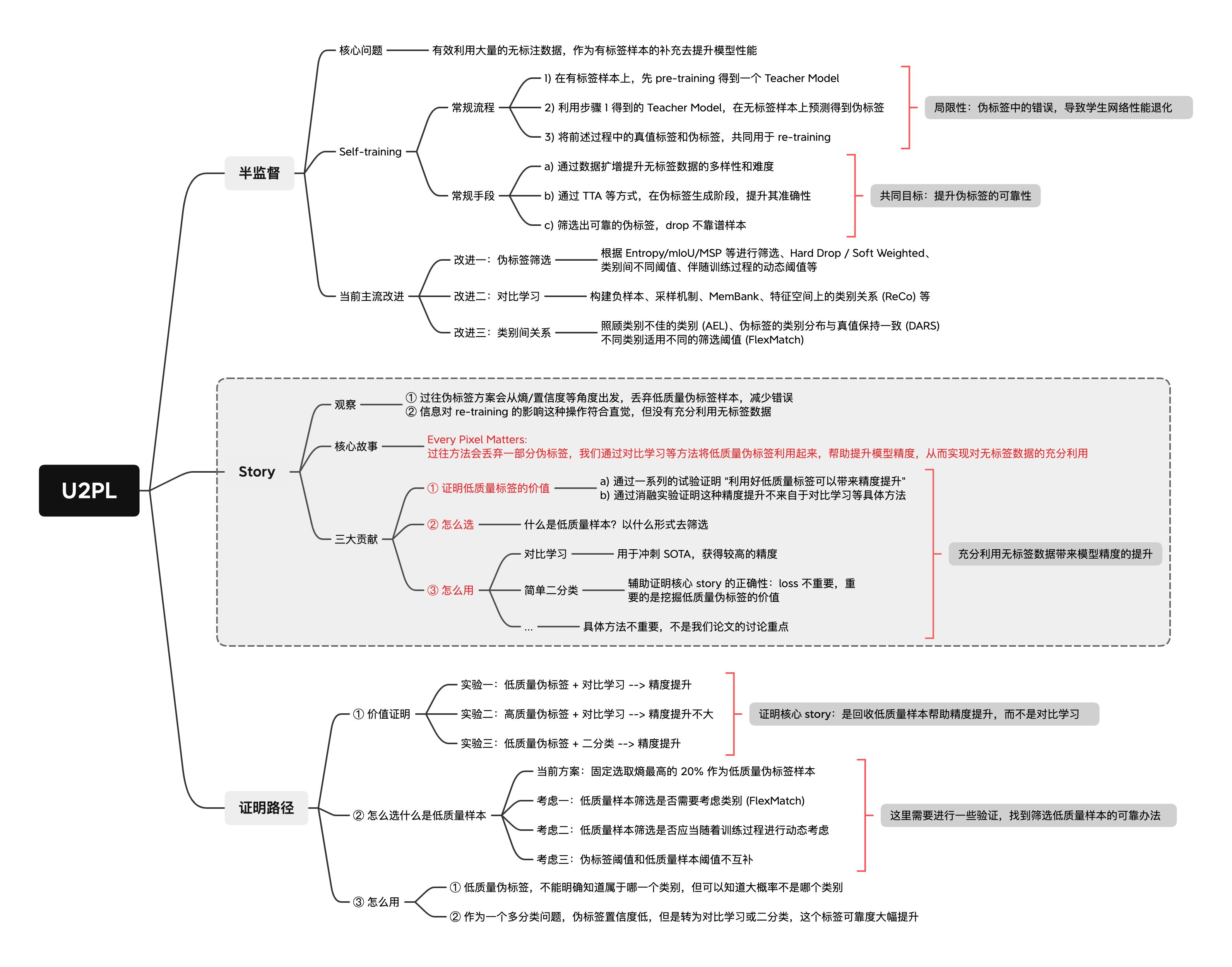
Paper Reading: (U2PL) 基于不可靠伪标签的半监督语义分割
目录 简介目标/动机方法Pseudo-LabelingUsing Unreliable Pseudo-Labels 补充知识InfoNCE LossOHEM 实验Comparison with Existing AlternativesAblationEffectiveness of Using Unreliable Pseudo-LabelsAlternative of Contrastive Learning 总结附录U2PL 与 negative learni…

论文阅读:2023_Semantic Hearing: Programming Acoustic Scenes with Binaural Hearables
论文地址:语义听觉:用双耳可听器编程声学场景 论文代码:https://semantichearing.cs.washington.edu/ 引用格式:Veluri B, Itani M, Chan J, et al. Semantic Hearing: Programming Acoustic Scenes with Binaural Hearables[C]//Proceedings…
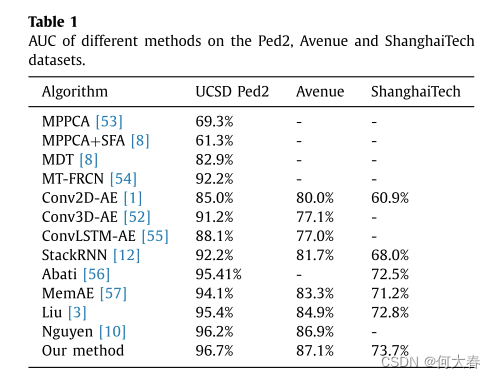
Video anomaly detection with spatio-temporal dissociation 论文阅读
Video anomaly detection with spatio-temporal dissociation 摘要1.介绍2.相关工作3. Methods3.1. Overview3.2. Spatial autoencoder3.3. Motion autoencoder3.4. Variance attention module3.5. Clustering3.6. The training objective function 4. Experiments5. Conclusio…

【论文阅读】AADiff: Audio-Aligned Video Synthesis with Text-to-Image Diffusion
AADiff:基于文本到图像扩散的音频对齐视频合成。
code:没开源
paper:[2305.04001] AADiff: Audio-Aligned Video Synthesis with Text-to-Image Diffusion (arxiv.org) 一种新的T2V框架,额外使用音频信号来控制时间动态,使现成的…

ViTDet论文笔记
arxiv:https://arxiv.org/abs/2203.16527 GitHub:https://github.com/ViTAE-Transformer/ViTDet
摘要
本文提出使用plain,non-hierarchical视觉transformer作为目标检测的主干网络。通过这种设计可以使得ViT结构模型不需要再重新设计一个分…

论文阅读《Parameterized Cost Volume for Stereo Matching》
论文地址:https://openaccess.thecvf.com/content/ICCV2023/papers/Zeng_Parameterized_Cost_Volume_for_Stereo_Matching_ICCV_2023_paper.pdf 源码地址:https://github.com/jiaxiZeng/Parameterized-Cost-Volume-for-Stereo-Matching 概述 现有的立体匹…
孟德尔随机化+WGCNA+预后模型,7+轻松get
今天给同学们分享一篇生信文章“Exploring the causality and pathogenesis of systemic lupus erythematosus in breast cancer based on Mendelian randomization and transcriptome data analyses”,这篇文章发表在Front Immunol期刊上,影响因子为7.3…

论文阅读二——基于全脸外观的凝视估计
论文阅读二——基于全脸外观的凝视估计 基础知识主要内容文章中需要学习的架构AlexNet 代码复现 该论文是2017年在CVPR中发表的一篇关于 “gaze estimation” 的文章,其论文地址与代码地址如下:
论文地址
代码地址
论文特点:文章提出了一种…
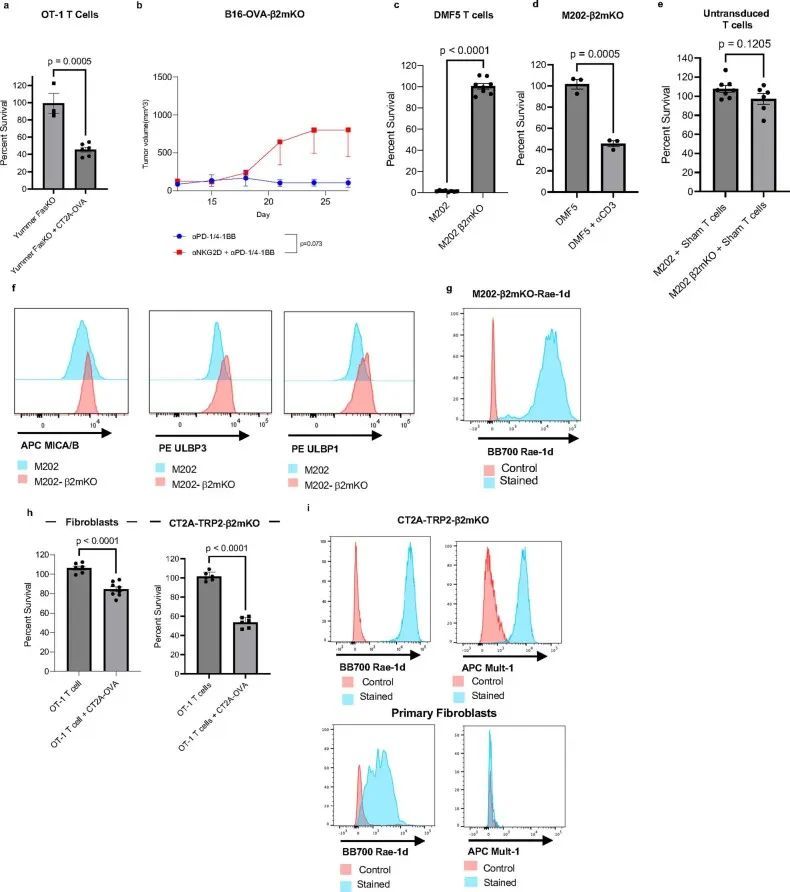
CD8+T细胞通过NKG2D-NKG2DL轴维持对MHC-I阴性肿瘤细胞的杀伤
今天给同学们分享一篇实验文章“CD8 T cells maintain killing of MHC-I-negative tumor cells through the NKG2D-NKG2DL axis”,这篇文章发表在Nat Cancer期刊上,影响因子为22.7。 结果解读:
MHC-I阴性肿瘤的免疫疗法需要CD8 T细胞
作者先…
![[论文笔记] GAMMA: A Graph Pattern Mining Framework for Large Graphs on GPU](https://img-blog.csdnimg.cn/direct/f60b98607e08477b9735657df6d4bf89.png)
[论文笔记] GAMMA: A Graph Pattern Mining Framework for Large Graphs on GPU
GAMMA: A Graph Pattern Mining Framework for Large Graphs on GPU
GAMMA: 基于 GPU 的针对大型图的图模式挖掘框架 [Paper] [Code] ICDE’23
摘要
提出了一个基于 GPU 的核外(out-of-core) 图模式挖掘框架(Graph Pattern Mining, GPM) GAMMA, 充分利用主机内存来处理大型图…
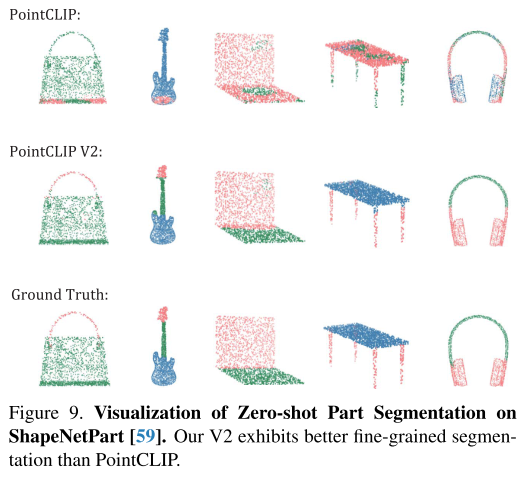
论文阅读:PointCLIP V2: Prompting CLIP and GPT for Powerful3D Open-world Learning
https://arxiv.org/abs/2211.11682
0 Abstract
大规模的预训练模型在视觉和语言任务的开放世界中都表现出了良好的表现。然而,它们在三维点云上的传输能力仍然有限,仅局限于分类任务。在本文中,我们首先协作CLIP和GPT成为一个统一的3D开放世…

论文阅读:Learning sRGB-to-Raw-RGB De-rendering with Content-Aware Metadata
论文阅读:Learning sRGB-to-Raw-RGB De-rendering with Content-Aware Metadata
Abstract
大多数的 Camera ISP 会将 RAW 图经过一系列的处理,变成 sRGB 图像,ISP 的处理中很多模块是非线性的操作,这些操作会破坏环境光照的线性…
细胞培养之一二三:哺乳动物细胞培养污染问题和解决方案
一、哺乳动物细胞污染是什么[1]? 污染通常是指在细胞培养基中存在不需要的微生物、不需要的哺乳动物细胞和各种生化或化学物质,从而影响所需哺乳动物细胞的生理和生长。由于微生物在包括人体特定部位在内的环境中无处不在,而且它们的繁殖速度…

5+分型+预后模型+实验,双热点搭配分子对接
今天给同学们分享一篇生信文章“Characterization and application of a lactate and branched chain amino acid metabolism related gene signature in a prognosis risk model for multiple myeloma”,这篇文章发表在Cancer Cell Int期刊上,影响因子为…
【论文阅读笔记】Pre-trained Universal Medical Image Transformer
Luo L, Chen X, Tang B, et al. Pre-trained Universal Medical Image Transformer[J]. arXiv preprint arXiv:2312.07630, 2023.【代码开源】
【论文概述】
本文介绍了一种名为“预训练通用医学图像变换器(Pre-trained Universal Medical Image Transformer&…
【论文笔记】动态蛇卷积(Dynamic Snake Convolution)
精确分割拓扑管状结构例如血管和道路,对医疗各个领域至关重要,可确保下游任务的准确性和效率。然而许多因素使分割任务变得复杂,包括细小脆弱的局部结构和复杂多变的全局形态。针对这个问题,作者提出了动态蛇卷积,该结…
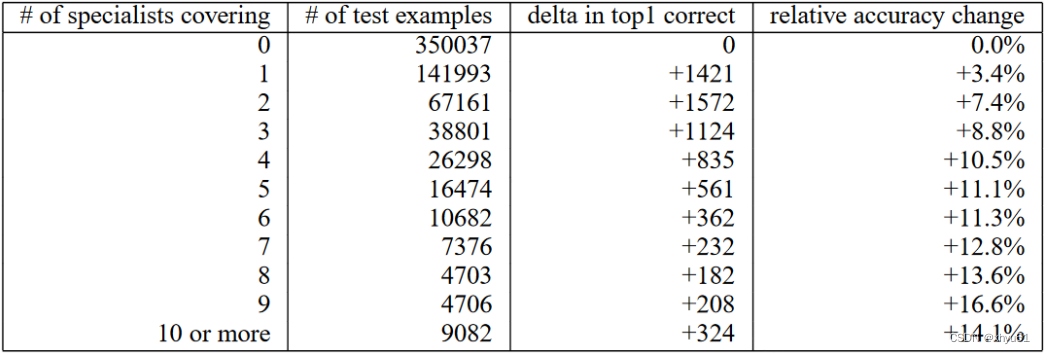
【论文笔记】Distilling the Knowledge in a Neural Network
Abstract
几乎任何机器学习算法性能提升的一个非常简单的方法是在相同数据上训练多个不同的模型,然后对它们的预测结果进行平均。 不幸的是,使用整个模型集合进行预测繁琐,可能会因为计算成本过高而难以部署给大量用户,尤其是如果…
【Online Schema Evolution】文档整理
文档整理
综述
Schema Evolution In RDBMS (yuque.com)
致命的分布式MDL死锁 (yuque.com)
F1
对F1的解读,原文形式化证明太多有点绕。
分布式 Schema 变更在 Google F1 的实践 - 知乎 (zhihu.com)
谷歌 F1 Online DDL的关键点:状态间兼容性 - 知乎…
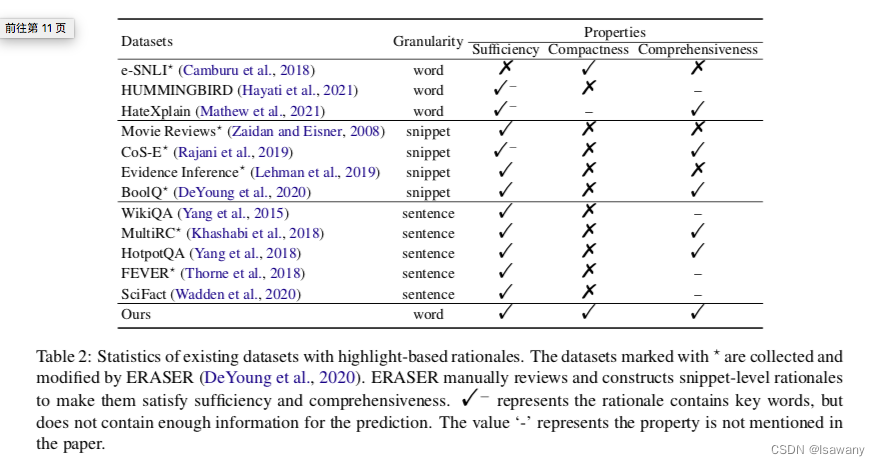
论文笔记--A Fine-grained Interpretability Evaluation Benchmark for Neural NLP
论文笔记--A Fine-grained Interpretability Evaluation Benchmark for Neural NLP 1. 文章简介2. 文章概括3 文章重点技术3.1 数据收集3.2 数据扰动3.3 迭代标注和检查根因3.4 度量3.4.1 Token F1-score3.4.2 MAP(Mean Average Precision) 4. 文章亮点5. 原文传送门 1. 文章简…

多路径传输(MPTCP MPQUIC)数据包调度研究总结
近些年来,以5G和Wifi6为代表的无线通信技术发展迅速,并已经在全世界实现了大规模部署。此外,智能手机等移动设备不断迭代更新,其网络通信能力也持续演进,使得应用同时利用多个不同网卡在多条不同物理链路上(…
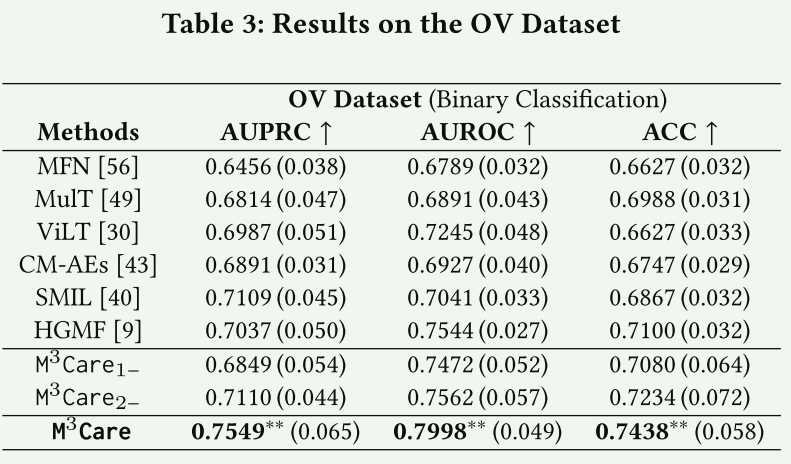
【论文阅读笔记】M3Care: Learning with Missing Modalities in Multimodal Healthcare Data
本文介绍了一种名为“MCare”的模型,旨在处理多模态医疗保健数据中的缺失模态问题。这个模型是端到端的,能够补偿病人缺失模态的信息,以执行临床分析。MCare不是生成原始缺失数据,而是在潜在空间中估计缺失模态的任务相关信息&…
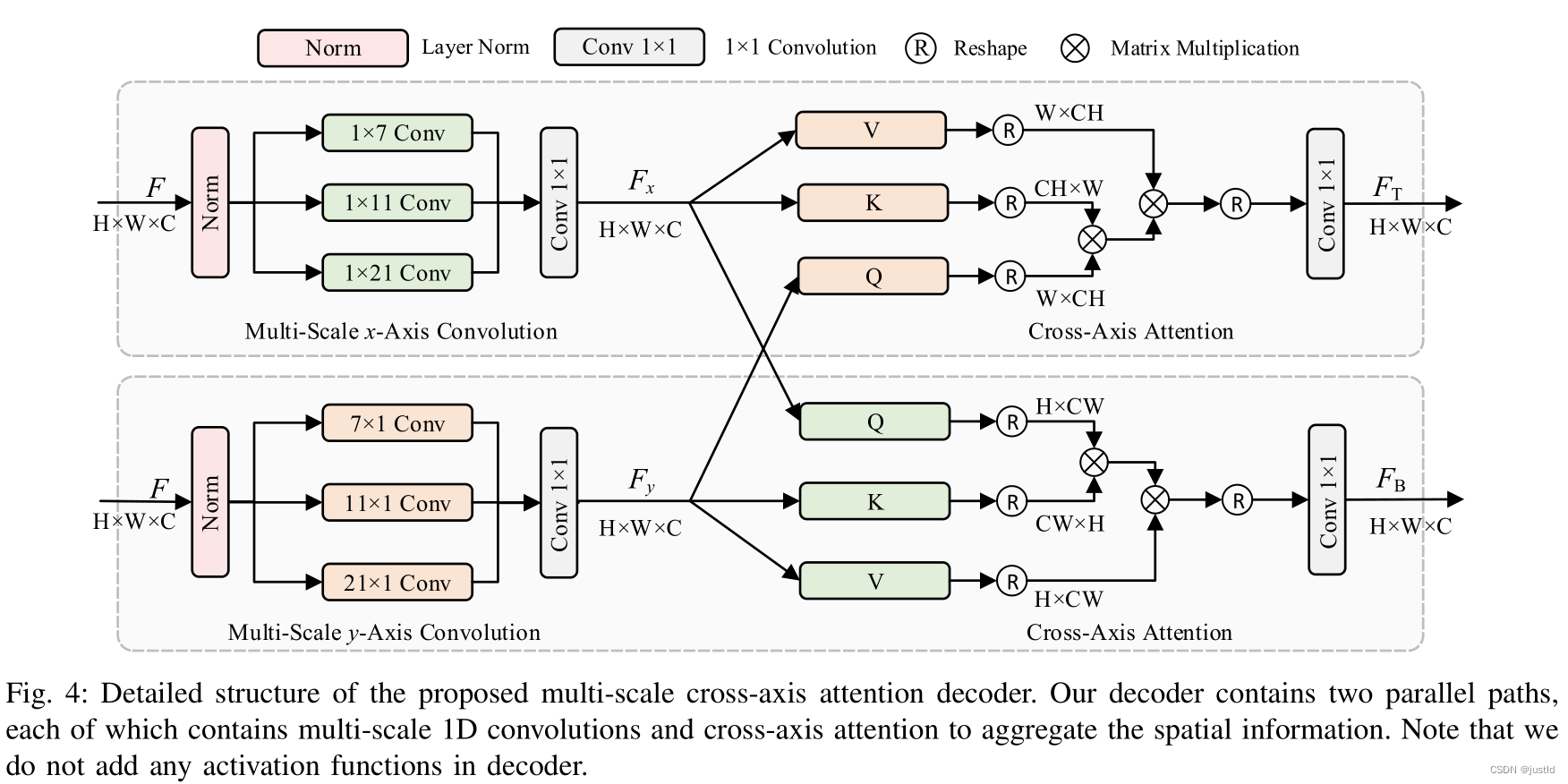
【论文笔记】MCANet: Medical Image Segmentation withMulti-Scale Cross-Axis Attention
医疗图像分割任务中,捕获多尺度信息、构建长期依赖对分割结果有非常大的影响。该论文提出了 Multi-scale Cross-axis Attention(MCA)模块,融合了多尺度特征,并使用Attention提取全局上下文信息。
论文地址:…

论文阅读《Learning Adaptive Dense Event Stereo from the Image Domain》
论文地址:https://openaccess.thecvf.com/content/CVPR2023/html/Cho_Learning_Adaptive_Dense_Event_Stereo_From_the_Image_Domain_CVPR_2023_paper.html 概述 事件相机在低光照条件下可以稳定工作,然而,基于事件相机的立体方法在域迁移时性…
论文阅读:Long-Term Visual Simultaneous Localization and Mapping
论文摘要指出,为了在长期变化的环境中准确进行定位,提出了一种新型的长期视觉SLAM(同步定位与地图构建)系统,该系统具备地图预测和动态物体移除功能。系统首先设计了一个高效的视觉点云匹配算法,将2D像素信…
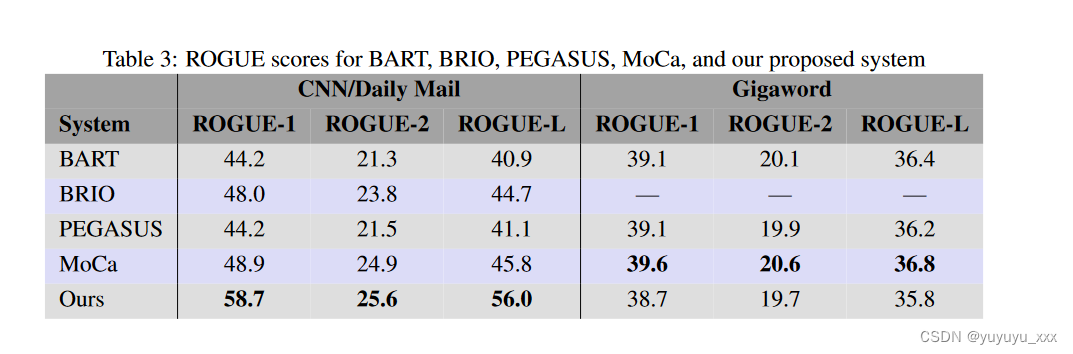
NLP论文阅读记录 - | 使用GPT对大型文档集合进行抽象总结
文章目录 前言0、论文摘要一、Introduction二.相关工作2.1Summarization2.2 神经网络抽象概括2.2.1训练和测试数据集。2.2.2 评估。 2.3 最先进的抽象摘要器 三.本文方法3.1 查询支持3.2 文档聚类3.3主题句提取3.4 语义分块3.5 GPT 零样本总结 四 实验效果4.1数据集4.2 对比模型…
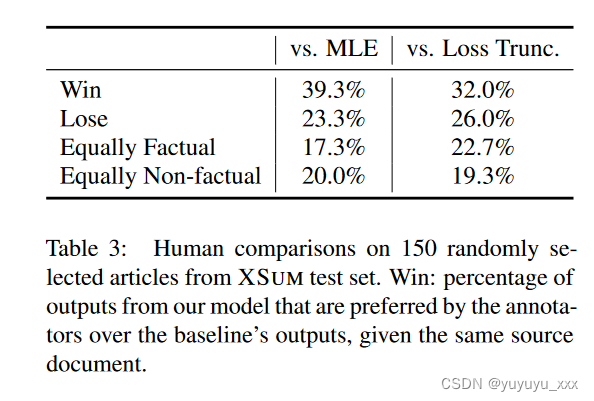
NLP论文阅读记录 - ACL 2022 | 抽象文本摘要的拒绝学习
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.相关工作三.本文方法3.1拒绝中学习3.1.1 问题表述3.1.2 拒绝损失 3.2拒绝解码 四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.5.1真实性评估自动评估结果人工评价 五…
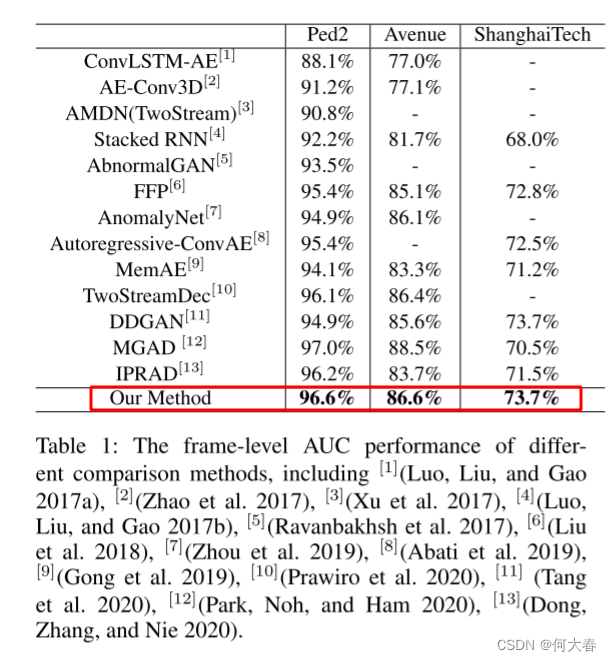
Appearance-Motion Memory Consistency Network for Video Anomaly Detection 论文阅读
Appearance-Motion Memory Consistency Network for Video Anomaly Detection 论文阅读 AbstractIntroductionRelated WorkMethodExperimentsConclusions阅读总结 论文标题:Appearance-Motion Memory Consistency Network for Video Anomaly Detection
文章信息&am…
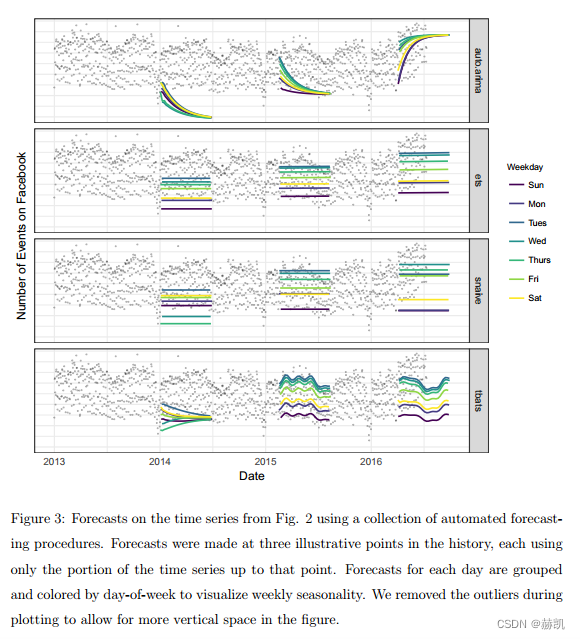
论文阅读 Forecasting at Scale (一)
最近在看时间序列的文章,回顾下经典 论文地址 项目地址 Forecasting at Scale 摘要1、介绍2、时间业务序列的特点3、Prophet预测模型3.1、趋势模型3.1.1、非线性饱和增长3.1.2、具有变化点的线性趋势3.1.3、自动转换点选择3.1.4、趋势预测的不确定性 摘要
预测是一…
[论文笔记]MatchPyramid
引言
又一篇文本匹配论文Text Matching as Image Recognition,论文题目是 文本匹配当成图像识别。
挺有意思的一篇工作,我们来看它是如何实现的。
作者受到卷积神经网络在图像识别中成功应用的启发,其中神经元可以捕获很多复杂的模式,作者提出将文本匹配看作是图像识别任…
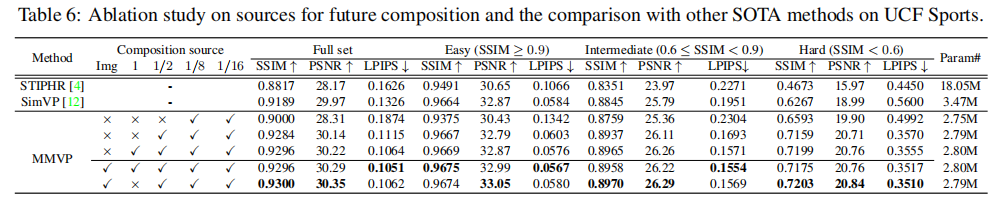
【ICCV2023】MMVP:基于运动矩阵的视频预测
目录
导读
本文方法
步骤1:空间特征提取
步骤2:运动矩阵的构造和预测
步骤3:未来帧的合成和解码
实验
实验结果
消融实验
结论 论文链接:https://openaccess.thecvf.com/content/ICCV2023/html/Zhong_MMVP_Motion-Matrix…

岁月随笔-穿拖鞋的汉子
时间如白驹过隙般,转眼间2023年也只剩下最后的40天。汉子我拿出年初自己定的目标,立下的Flag,恍恍惚若昨天发生,不禁让人感慨万千。
其实最近自己遇到了很大的困惑,也导致了断更了一个月。自己逐渐摸不清自己的定位啦…
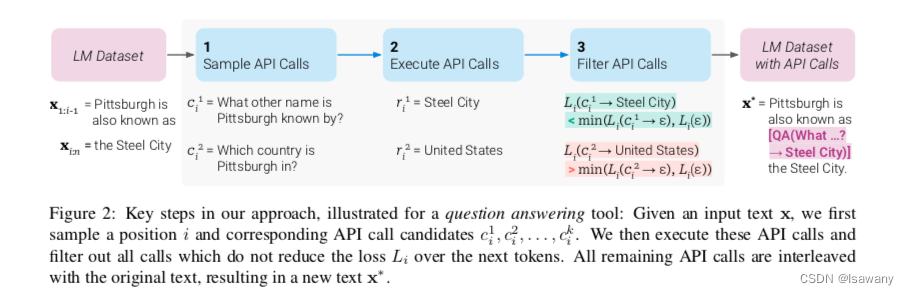
论文笔记--Toolformer: Language Models Can Teach Themselves to Use Tools
论文笔记--Toolformer: Language Models Can Teach Themselves to Use Tools 1. 文章简介2. 文章概括3 文章重点技术3.1 Toolformer3.2 APIs 4. 文章亮点5. 原文传送门 1. 文章简介
标题:Toolformer: Language Models Can Teach Themselves to Use Tools作者&#…
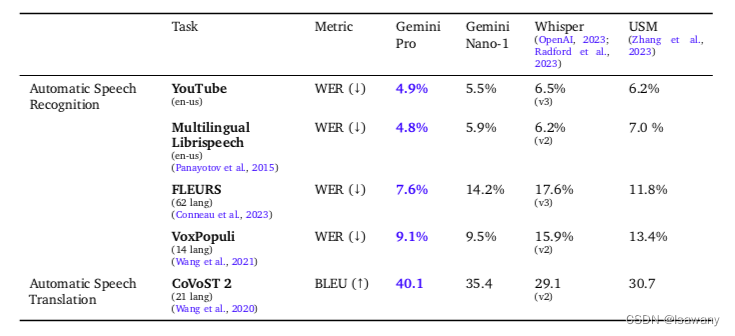
论文笔记--Gemini: A Family of Highly Capable Multimodal Models
论文笔记-- 1. 文章简介2. 文章概括3 文章重点技术3.1 模型架构3.2 训练数据3.3 模型评估3.3.1 文本3.3.1.1 Science3.3.1.2 Model sizes3.3.1.3 Multilingual3.3.1.4 Long Context3.3.1.5 Human preference 3.3.2 多模态3.3.2.1 图像理解3.3.2.2 视频理解3.3.2.3 图像生成3.3.…
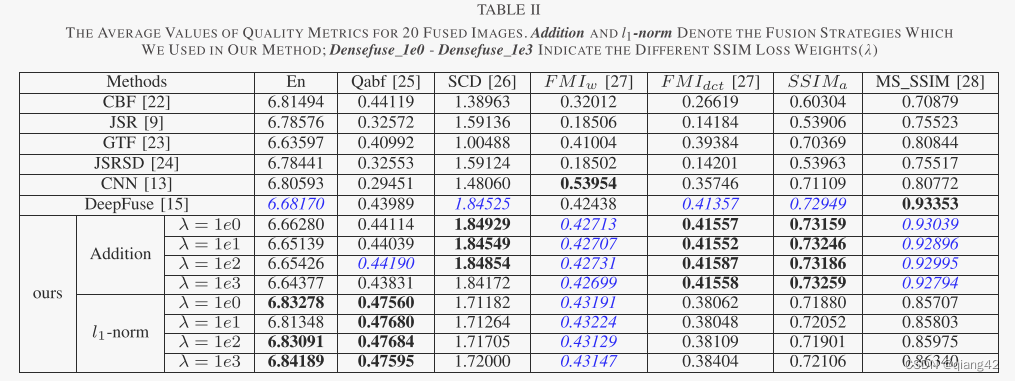
图像融合论文阅读:DenseFuse: A fusion approach to infrared and visible images
article{li2018densefuse, title{DenseFuse: A fusion approach to infrared and visible images}, author{Li, Hui and Wu, Xiao-Jun}, journal{IEEE Transactions on Image Processing}, volume{28}, number{5}, pages{2614–2623}, year{2018}, publisher{IEEE} } 论文级别&…
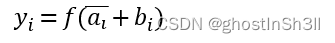
ImageBind-LLM: Multi-modality Instruction Tuning 论文阅读笔记
ImageBind-LLM: Multi-modality Instruction Tuning 论文阅读笔记 Method 方法Bind NetworkRMSNorm的原理及与Layer Norm的对比 Related Word / Prior WorkLLaMA-Adapter 联系我们 本文主要基于LLaMA和ImageBind工作,结合多模态信息和文本指令来实现一系列任务。训练…
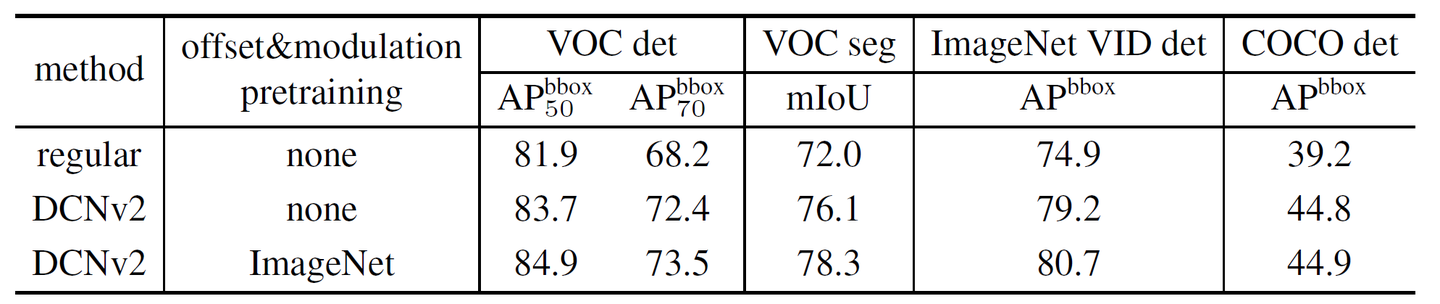
论文阅读——Deformable ConvNets v2
论文:https://arxiv.org/pdf/1811.11168.pdf
代码:https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch
1. 介绍 可变形卷积能够很好地学习到发生形变的物体,但是论文观察到当尽管比普通卷积网络能够更适应物体形变ÿ…
多模态大模型:关于RLHF那些事儿
Overview 多模态大模型关于RLHF的代表性文章一、LLaVA-RLHF二、RLHF-V三、SILKIE多模态大模型关于RLHF的代表性文章
一、LLaVA-RLHF
题目: ALIGNING LARGE MULTIMODAL MODELS WITH FACTUALLY AUGMENTED RLHF 机构:UC伯克利 论文: https://arxiv.org/pdf/2309.14525.pdf 代码…
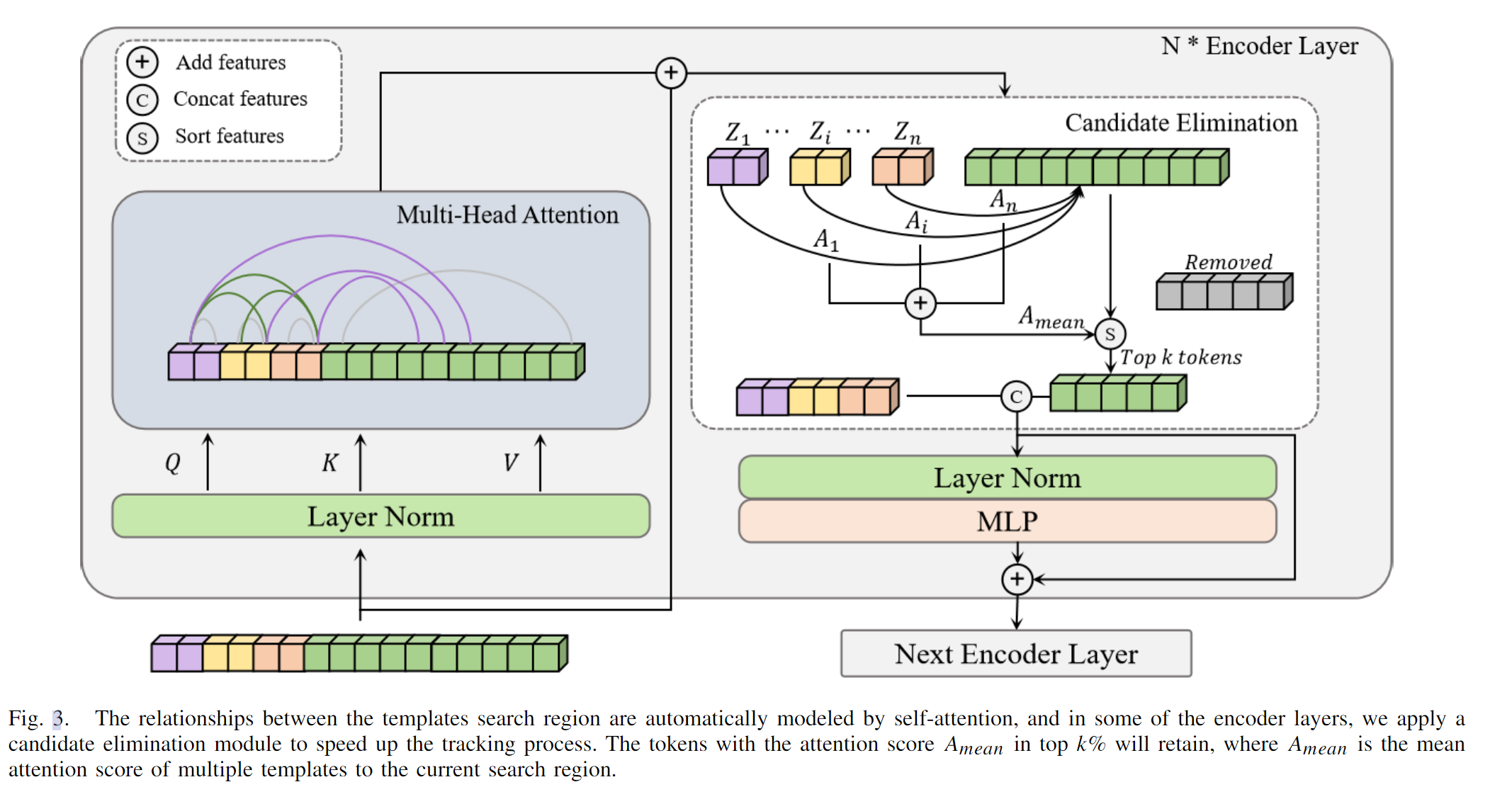
Cross-Drone Transformer Network for Robust Single Object Tracking论文阅读笔记
Cross-Drone Transformer Network for Robust Single Object Tracking论文阅读笔记
Abstract
无人机在各种应用中得到了广泛使用,例如航拍和军事安全,这得益于它们与固定摄像机相比的高机动性和广阔视野。多无人机追踪系统可以通过从不同视角收集互补的…

Exploring the Limits of Masked Visual Representation Learning at Scale论文笔记
论文名称:EVA: Exploring the Limits of Masked Visual Representation Learning at Scale 发表时间:CVPR2023 作者及组织:北京人工智能研究院;华中科技大学;浙江大学;北京理工大学 GitHub:http…
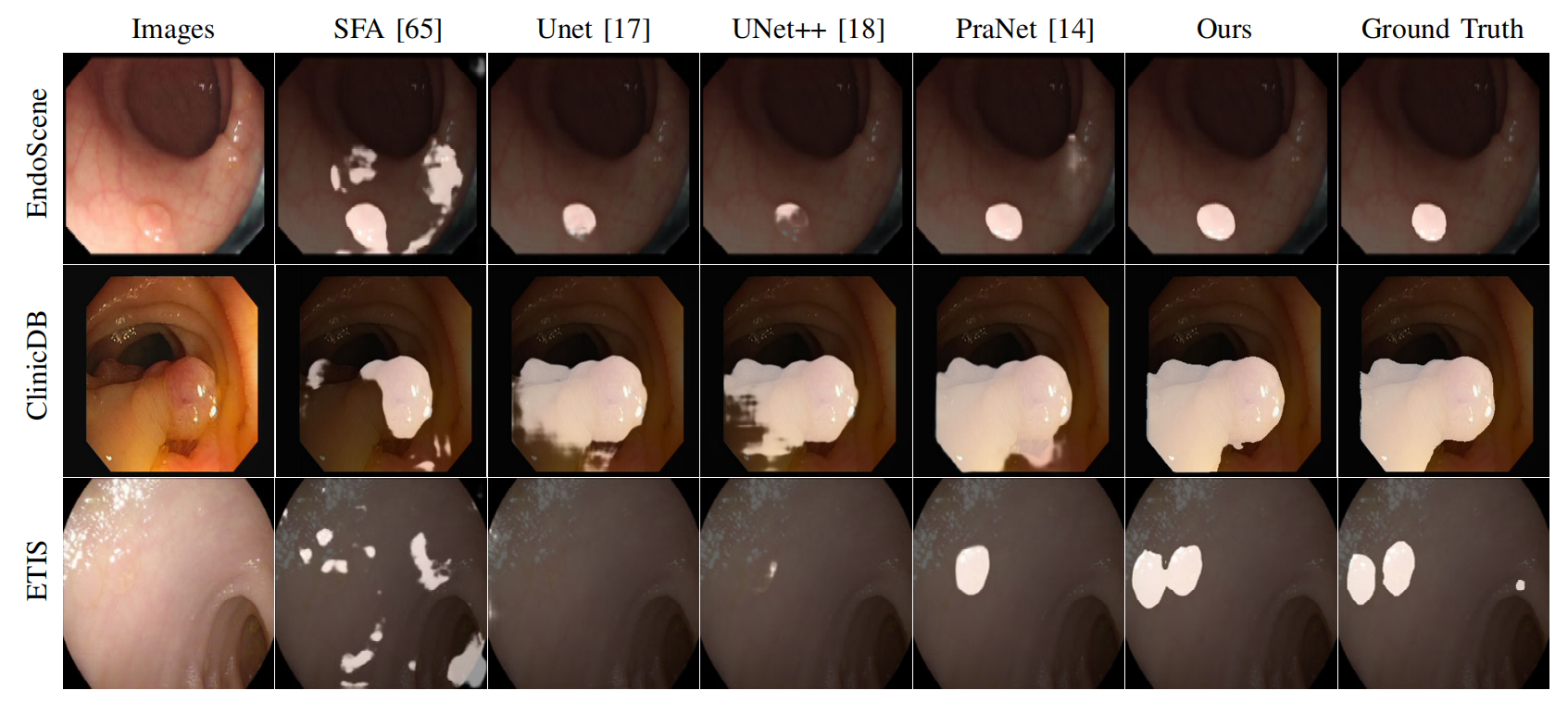
【论文阅读】MCANet: Medical Image Segmentation with Multi-Scale Cross-Axis Attention
文章目录 摘要创新点总结实现效果总结 摘要
链接:https://arxiv.org/abs/2312.08866 医学图像分割是医学图像处理和计算机视觉领域的关键挑战之一。由于病变区域或器官的大小和形状各异,有效地捕捉多尺度信息和建立像素间的长距离依赖性至关重要。本文提…
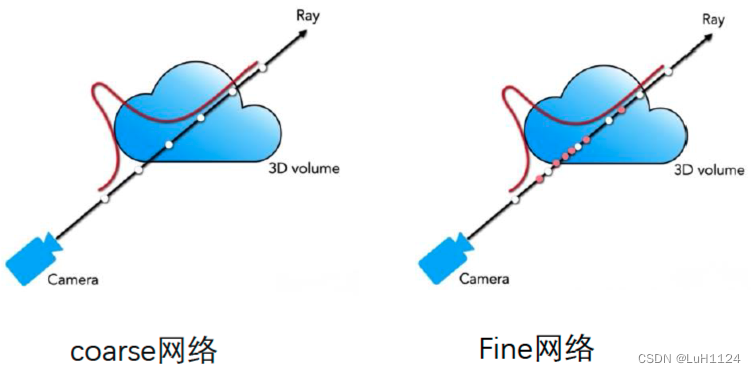
【论文阅读笔记】NeRF+Mip-NeRF+Instant-NGP
目录 前言NeRF神经辐射场体渲染连续体渲染体渲染离散化 方法位置编码分层采样体渲染推导公式(1)到公式(2)部分代码解读相机变换(重要!) Mip-NerfTo do Instant-NGPTo do 前言
NeRF是NeRF系列的…
《信息技术时代》期刊杂志论文发表投稿
《信息技术时代》期刊收稿方向:通信工程、大数据、计算机、办公自动化、信息或计算机教育、电子技术、系统设计、移动信息、图情信息研究、人工智能、智能技术、信息技术与网络安全等。
刊名:信息技术时代
主管主办单位:深圳湾科技发展有限…
5+共病+WGCNA+实验。共病+实验搭配是经典的得分套路
今天给同学们分享一篇生信文章“Adipocyte dysfunction promotes lung inflammation and aberrant repair: a potential target of COPD”,这篇文章发表在Front Endocrinol (Lausanne)期刊上,影响因子为5.2。 结果解读:
肥胖对慢性阻塞性肺疾…

SCENIC+:增强子和基因调控网络的单细胞多组学推理
摘要
对单个细胞中染色质可及性和基因表达的联合分析为破译增强子驱动的基因调控网络(GRN)提供了机会。在这里,我们提出了一种用于推理增强器驱动的 GRN 的方法,称为 SCENIC。 SCENIC 预测基因组增强子以及候选上游转录因子 (TF)…
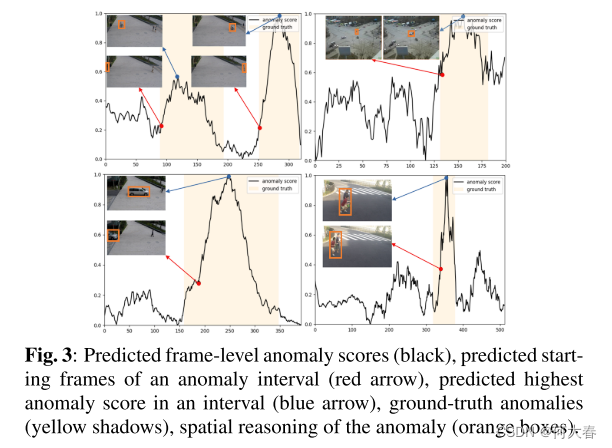
EXPLORING DIFFUSION MODELS FOR UNSUPERVISED VIDEO ANOMALY DETECTION 论文阅读
EXPLORING DIFFUSION MODELS FOR UNSUPERVISED VIDEO ANOMALY DETECTION 论文阅读 ABSTRACT1. INTRODUCTION2. RELATEDWORK3. METHOD4. EXPERIMENTAL ANALYSIS AND RESULTS4.1. Comparisons with State-Of-The-Art (SOTA)4.2. Diffusion Model Analysis4.3. Qualitative Result…
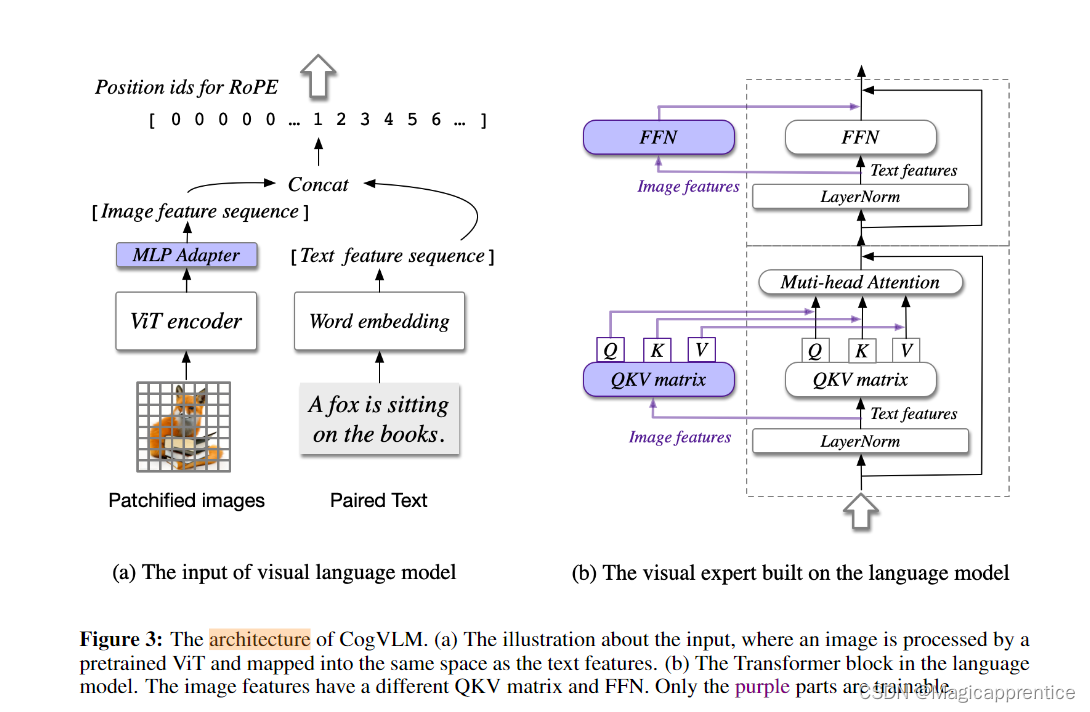
多模态大模型-CogVLm 论文阅读笔记
多模态大模型-CogVLm 论文阅读笔记
COGVLM: VISUAL EXPERT FOR LARGE LANGUAGEMODELS 论文地址 :https://arxiv.org/pdf/2311.03079.pdfcode地址 : https://github.com/THUDM/CogVLM时间 : 2023-11机构 : zhipuai,tsinghua关键词: visual language model效果:(2023…
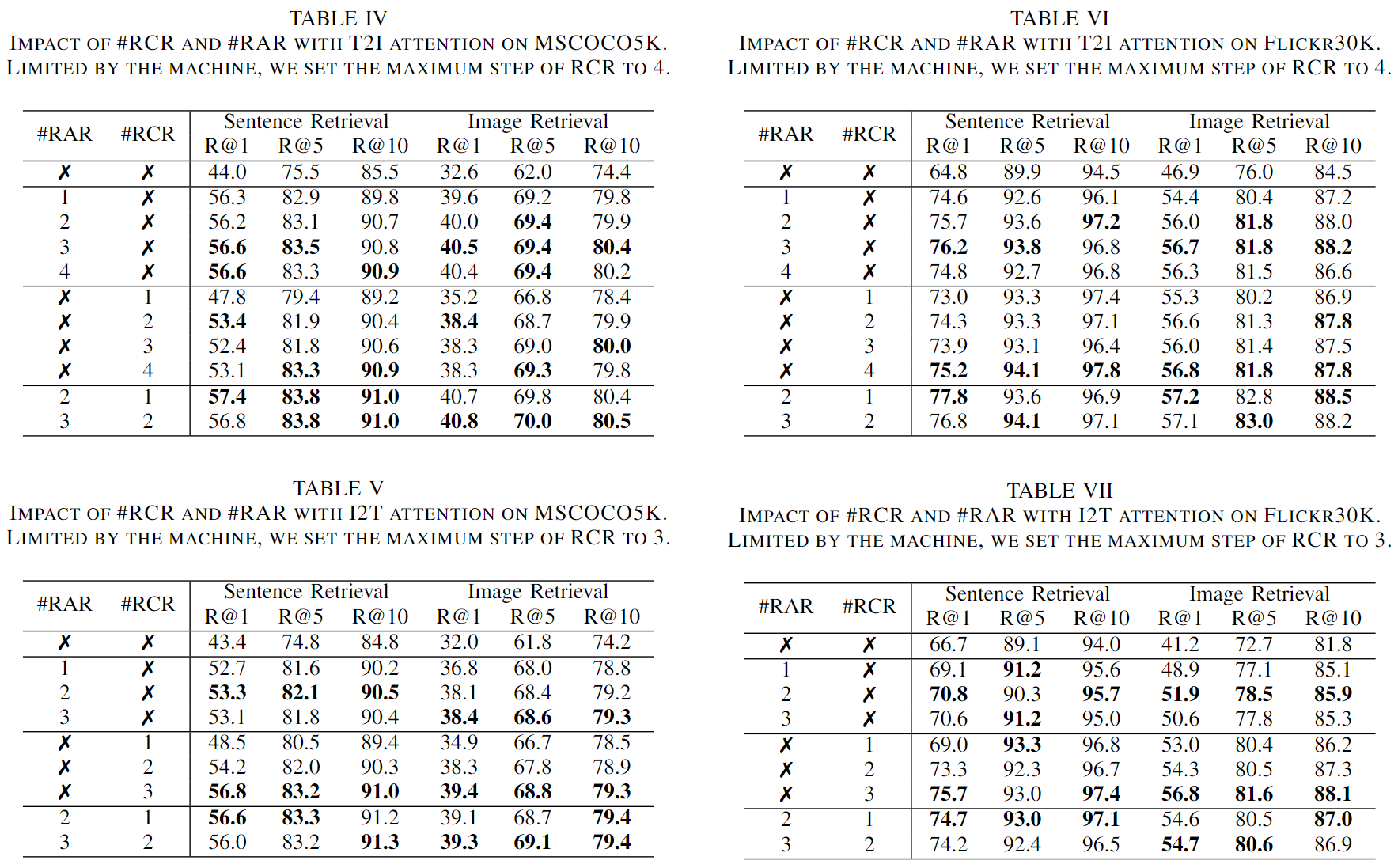
跨模态检索论文阅读:Plug-and-Play Regulators for Image-Text Matching用于图像文本匹配的即插即用调节器
Plug-and-Play Regulators for Image-Text Matching用于图像文本匹配的即插即用调节器 利用细粒度的对应关系和视觉语义比对在图像-文本匹配中显示出巨大的潜力。通常,最近的方法首先使用跨模态注意力单元来捕捉潜在的区域-单词交互,然后整合所有比对以获…
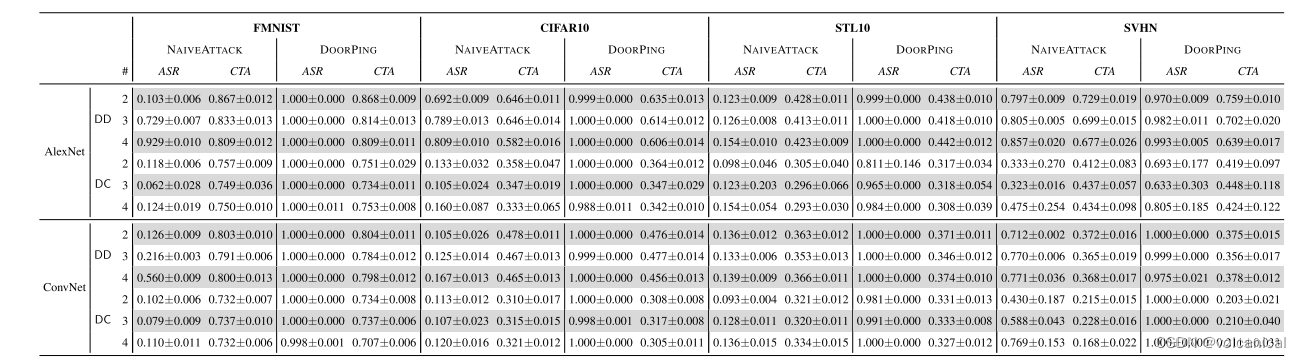
《论文阅读:Backdoor Attacks Against Dataset Distillation》
数据浓缩下的后门攻击 1. 摘要
数据集蒸馏已成为训练机器学习模型时提高数据效率的一项重要技术。它将大型数据集的知识封装到较小的综合数据集中。在这个较小的蒸馏数据集上训练的模型可以获得与在原始训练数据集上训练的模型相当的性能。然而,现有的数据集蒸馏技…

OR-NeRF论文笔记
OR-NeRF论文笔记 文章目录 OR-NeRF论文笔记论文概述Abstract1 Introduction2 Related Work3 Background4 Method4.1 Multiview Segmentation4.2 Scene Object Removal 5 ExperimentsDatasetsMetricsMultiview SegmentationScene Object Removal 6 Conclusion 论文概述
目的&am…

论文阅读<Contrastive Learning-based Robust Object Detection under Smoky Conditions>
论文链接:https://openaccess.thecvf.com/content/CVPR2022W/UG2/papers/Wu_Contrastive_Learning-Based_Robust_Object_Detection_Under_Smoky_Conditions_CVPRW_2022_paper.pdf Abstract 目标检测是指有效地找出图像中感兴趣的目标,然后准确地确定它们…
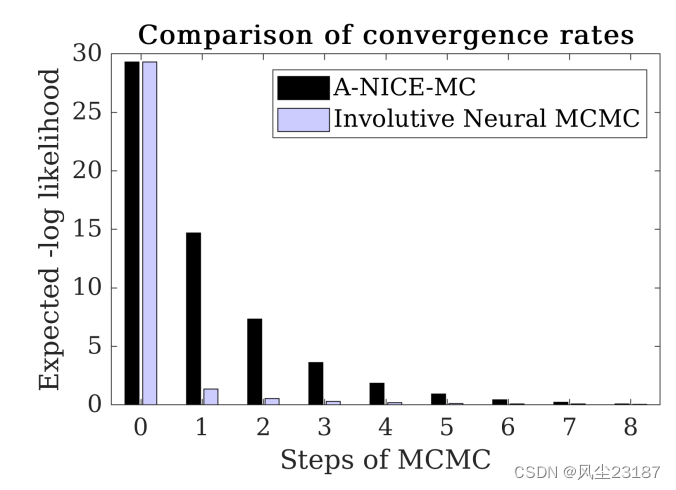
论文阅读:神经 MCMC 的深度内卷生成模型 Deep Involutive Generative Models for Neural MCMC
文章总结:本文提出了使用一种生成式的模型作为MCMC算法中的建议方式,并通过GAN进行优化。 原文:Deep Involutive Generative Models for Neural MCMC
我们引入了深度内卷生成模型(一种深度生成建模的新架构)ÿ…

论文阅读--EFFICIENT OFFLINE POLICY OPTIMIZATION WITH A LEARNED MODEL
作者:Zichen Liu, Siyi Li, Wee Sun Lee, Shuicheng YAN, Zhongwen Xu
论文链接:Efficient Offline Policy Optimization with a Learned Model | OpenReview
发表时间: ICLR 2023年1月21日
代码链接:https://github.com/s…
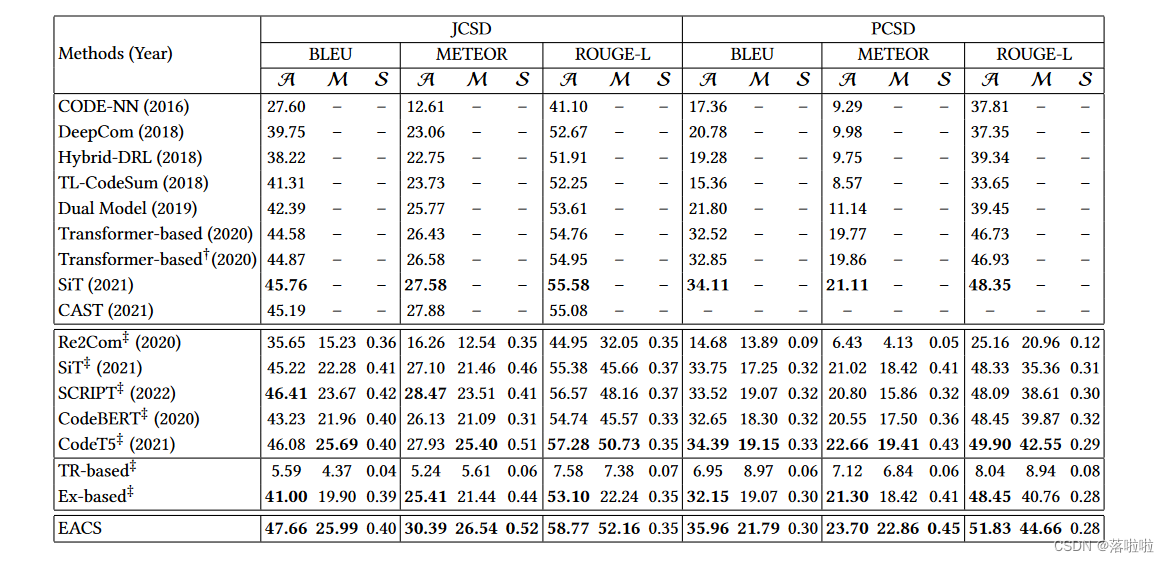
【论文笔记】An Extractive-and-Abstractive Framework for Source Code Summarization
An Extractive-and-Abstractive Framework for Source Code Summarization 1. Introduction2. Model2.1 Overview2.2 Training of EACS2.2.1 Part i : Training of Extractor2.2.2 Part ii : Training of Abstracter 3. Evaluation 1. Introduction
代码摘要可以细分为抽取式代…
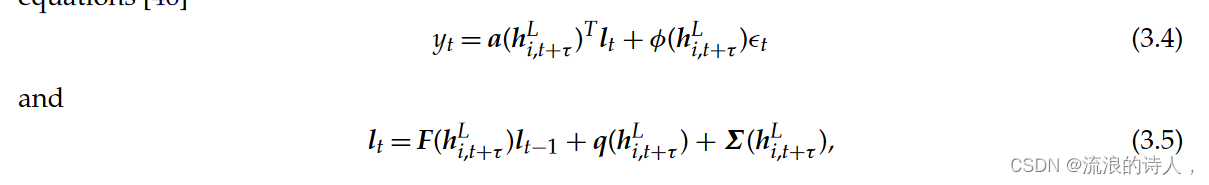
Time-series forecasting with deep learning: a survey
人们开发了许多深度学习架构来适应不同领域的时间序列数据集的多样性。在本文中,我们调查了一步前进和多水平时间序列预测中使用的常见编码器和解码器设计,描述了如何将时间信息纳入每个模型的预测中。接下来,我们重点介绍混合深度学习模型的…
【论文阅读】深度学习中的后门攻击综述
深度学习中的后门攻击综述 1.深度学习模型三种攻击范式1.1.对抗样本攻击1.2.数据投毒攻击1.3.后门攻击 2.后门攻击特点3.常用术语和标记4.常用评估指标5.攻击设置5.1.触发器5.1.1.触发器属性5.1.2.触发器类型5.1.3.攻击类型 5.2.目标类别5.3.训练方式 1.深度学习模型三种攻击范…

【LLM 论文阅读】NEFTU N E: LLM微调的免费午餐
指令微调的局限性
指令微调对于训练llm的能力至关重要,而模型的有用性在很大程度上取决于我们从小指令数据集中获得最大信息的能力。在本文中,我们提出在微调正向传递的过程中,在训练数据的嵌入向量中添加随机噪声,论文实验显示这…
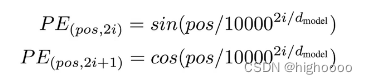
论文阅读 Attention is all u need - transformer
文章目录 1 摘要1.1 核心 2 模型架构2.1 概览2.2 理解encoder-decoder架构2.2.1 对比seq2seq,RNN2.2.2 我的理解 3. Sublayer3.1 多头注意力 multi-head self-attention3.1.1 缩放点乘注意力 Scaled Dot-Product Attention3.1.2 QKV3.1.3 multi-head3.1.4 masked 3.…

准博士生教你如何阅读论文
AI方向如何阅读论文 绪论会议整理一篇论文的主要结构AbstractIntroductionRelated WorkApproach(framework名称亦可)ExperimentsImplementation detailsResultsAblation StudyDiscussion Conclusion 如何阅读多篇论文怎样读/写related work怎样读approach结语 绪论
作为一位工…
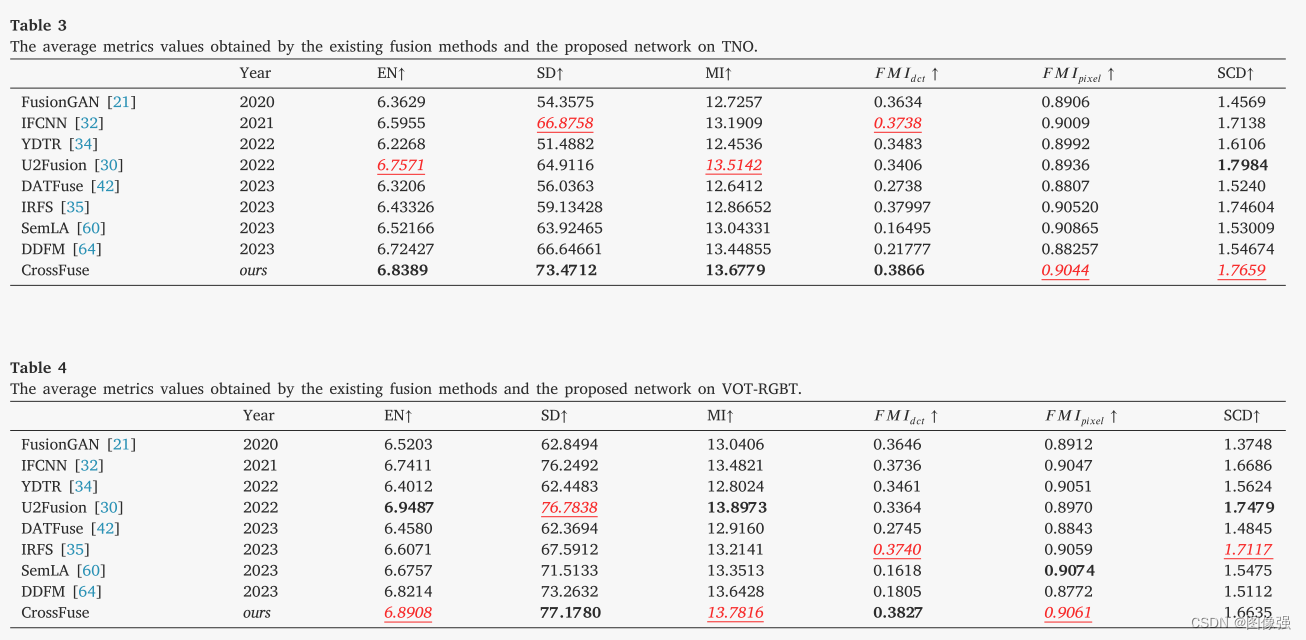
图像融合论文阅读:CrossFuse: 一种基于交叉注意机制的红外与可见光图像融合方法
article{li2024crossfuse, title{CrossFuse: A novel cross attention mechanism based infrared and visible image fusion approach}, author{Li, Hui and Wu, Xiao-Jun}, journal{Information Fusion}, volume{103}, pages{102147}, year{2024}, publisher{Elsevier} } 论文…
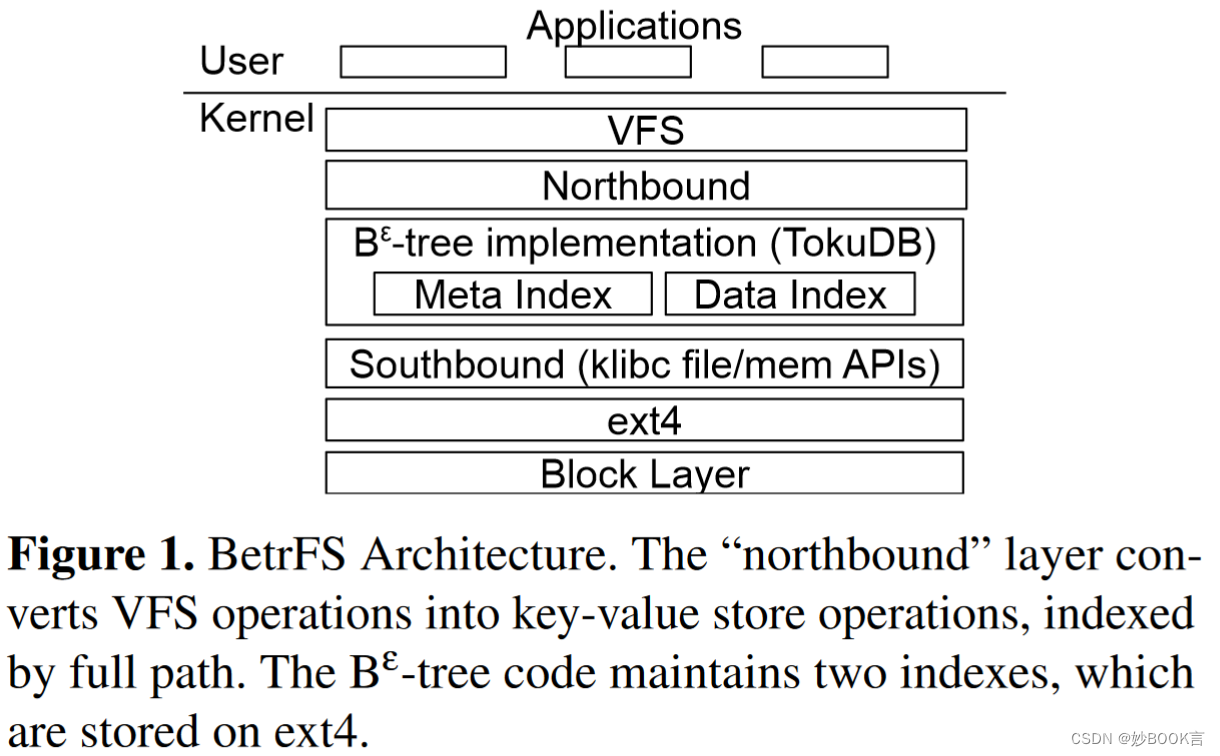
BetrFS: A Compleat File System for Commodity SSDs——论文阅读
EuroSys 2022 Paper 分布式元数据论文汇总
问题
在不同的工作负载下,没有单一的Linux文件系统在普通SSD上始终表现良好。我们将一个完备的文件系统定义为在各种微基准测试和应用程序中,没有一个工作负载的性能低于最佳文件系统性能的30%,并…

APINNs A gating network-based soft domain decomposition methodology
论文阅读:Augmented Physics-Informed Neural Networks APINNs A gating network-based soft domain decomposition methodology Augmented Physics-Informed Neural Networks (APINNs) A gating network-based soft domain decomposition methodology方法APINN门网…
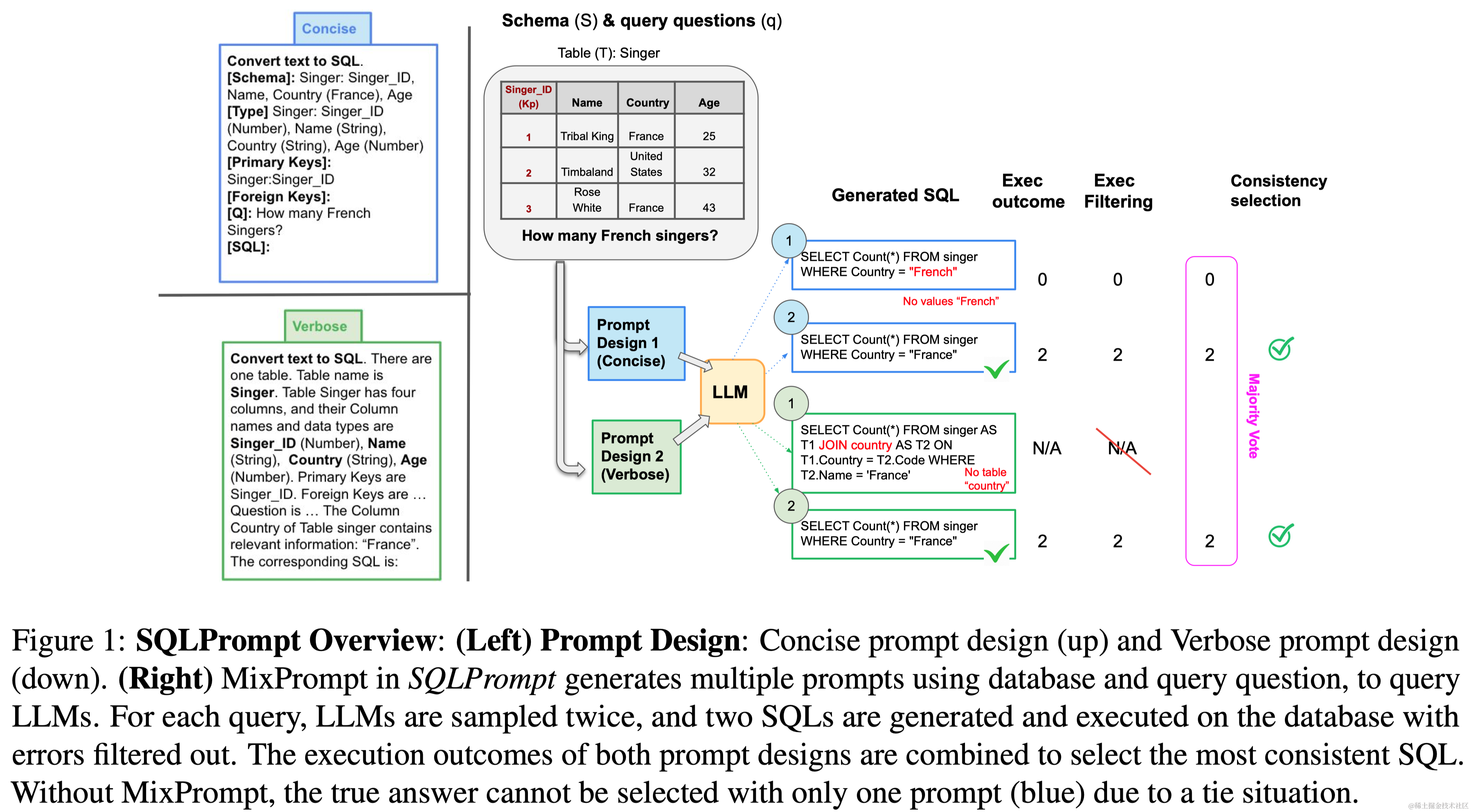
EMNLP 2023精选:Text-to-SQL任务的前沿进展(下篇)——Findings论文解读
导语
本文记录了今年的自然语言处理国际顶级会议EMNLP 2023中接收的所有与Text-to-SQL相关(通过搜索标题关键词查找得到,可能不全)的论文,共计12篇,包含5篇正会论文和7篇Findings论文,以下是对这些论文的略…
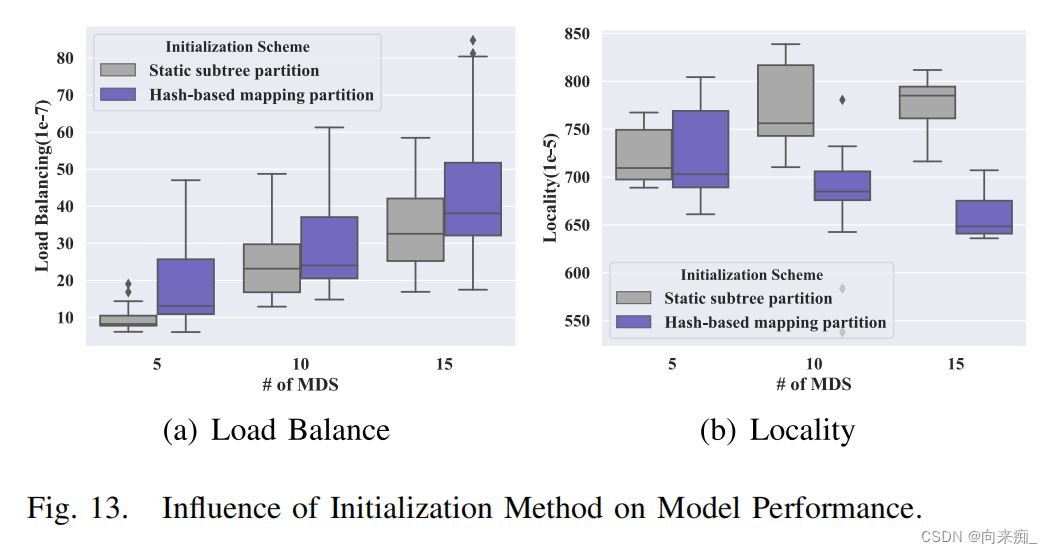
论文阅读-一种用于大规模分布式文件系统中基于深度强化学习的自适应元数据管理方案
名称: An Adaptive Metadata Management Scheme Based on Deep Reinforcement Learning for Large-Scale Distributed File Systems
I. 引言
如今,大型集群文件系统的规模已达到PB甚至EB级别,由此产生的数据呈指数级增长。系统架构师不断设…

NLP论文阅读记录 - 2022 W0S | 基于Longformer和Transformer的提取摘要层次表示模型
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.相关工作三.本文方法四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结思考 前言 A Hierarchical Representation Model Based on Longformer and …
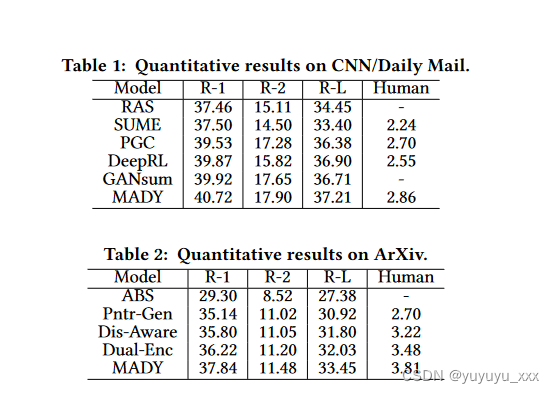
NLP论文阅读记录 - 2021 | WOS 使用分层多尺度抽象建模和动态内存进行抽象文本摘要
文章目录 前言0、论文摘要一、Introduction1.3本文贡献 二.前提三.本文方法四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结思考 前言 Abstractive Text Summarization with Hierarchical Multi-scale Abstraction Modeling and Dy…
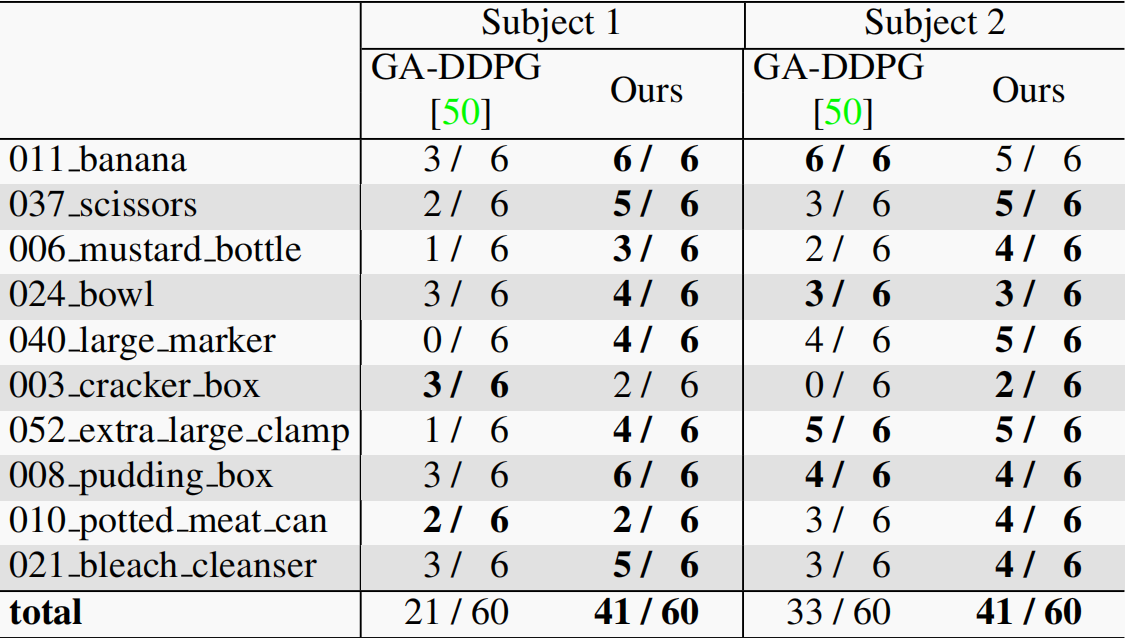
论文笔记(三十九)Learning Human-to-Robot Handovers from Point Clouds
Learning Human-to-Robot Handovers from Point Clouds 文章概括摘要1. 介绍2. 相关工作3. 背景3.1. 强化学习3.2. 移交模拟基准 4. 方法4.1. Handover Environment4.2. 感知4.3. 基于视觉的控制4.4. 师生两阶段培训 (Two-Stage Teacher-Student Training) 5. 实验5.1. 模拟评估…

【论文阅读】Latent Consistency Models (LDMs)、LCM-LoRa
文章目录 IntroductionPreliminariesDiffusion ModelsConsistency Models Latent Consistency ModelsConsistency Distillation in the Latent SpaceOne-Stage Guided Distillation by Solving Augmented PF-ODEAccelerating Distillation with Skipping Time StepsLatent Cons…
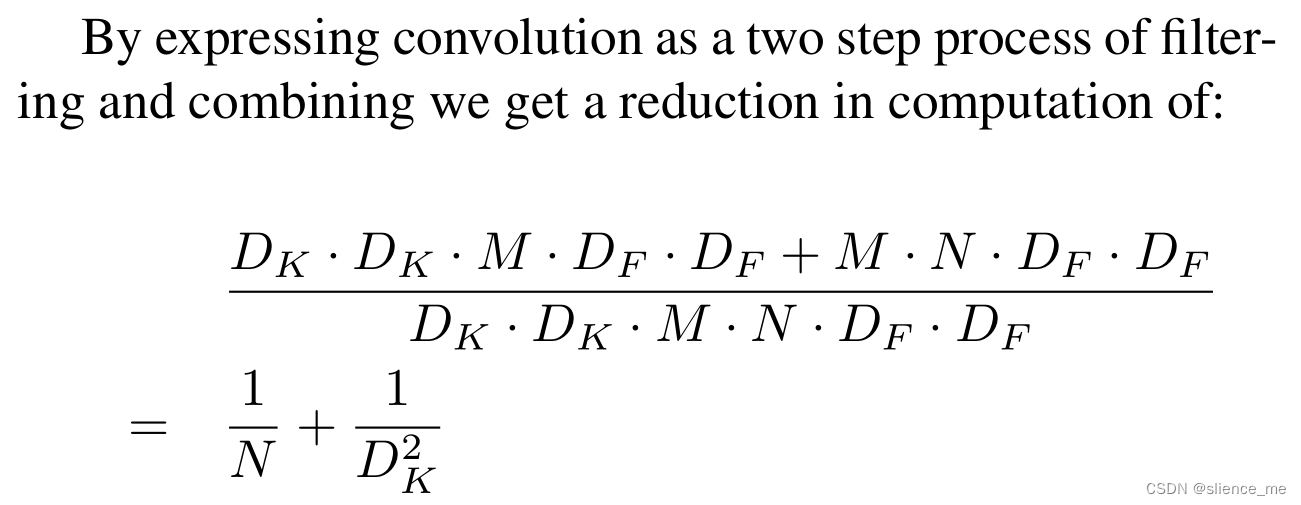
【论文笔记合集】卷积神经网络之深度可分离卷积(Depthwise Separable Convolution)
本文作者: slience_me 我看的论文地址:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
内容
1. 标准卷积
假设输入为DFDFM,输出为输入为DFDFN,卷积核为DKDKM,共有N个卷积核进…
论文笔记(四十)Goal-Auxiliary Actor-Critic for 6D Robotic Grasping with Point Clouds
Goal-Auxiliary Actor-Critic for 6D Robotic Grasping with Point Clouds 文章概括摘要1. 介绍2. 相关工作3. 学习 6D 抓握政策3.1 背景3.2 从点云抓取 6D 策略3.3 联合运动和抓握规划器的演示3.4 行为克隆和 DAGGER3.5 目标--辅助 DDPG3.6 对未知物体进行微调的后视目标 4. 实…
![6个免费好用的 PDF 文件加密软件 [Windows Mac]](https://img-blog.csdnimg.cn/img_convert/2f65ecf171104119c928db308b157585.jpeg)
6个免费好用的 PDF 文件加密软件 [Windows Mac]
加密 PDF 文件使您能够保护它们免受未经授权的访问。当重要信息处于危险之中时,黑客可以访问电子文档。
考虑到它们很容易被黑客入侵,您需要迅速采取行动。避免这种情况的方法之一是使用更适合您需要的 PDF 加密软件。
有很多选项可供选择,…
【每日论文阅读】生成模型篇
联邦多视图合成用于元宇宙
标题: Federated Multi-View Synthesizing for Metaverse
作者: Yiyu Guo; Zhijin Qin; Xiaoming Tao; Geoffrey Ye Li
摘要: 元宇宙有望提供沉浸式娱乐、教育和商务应用。然而,虚拟现实(VR)在无线网络上的传输是…
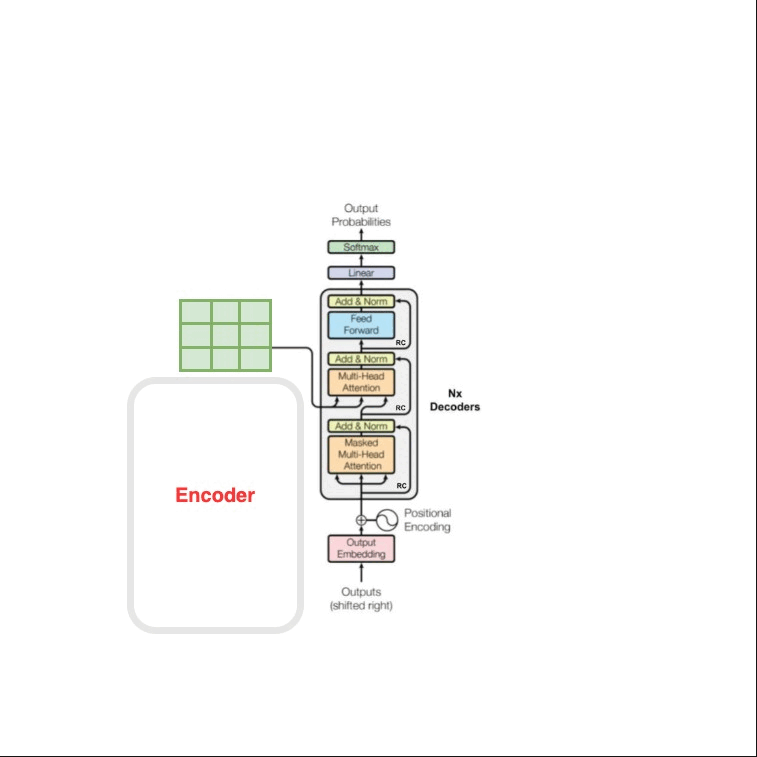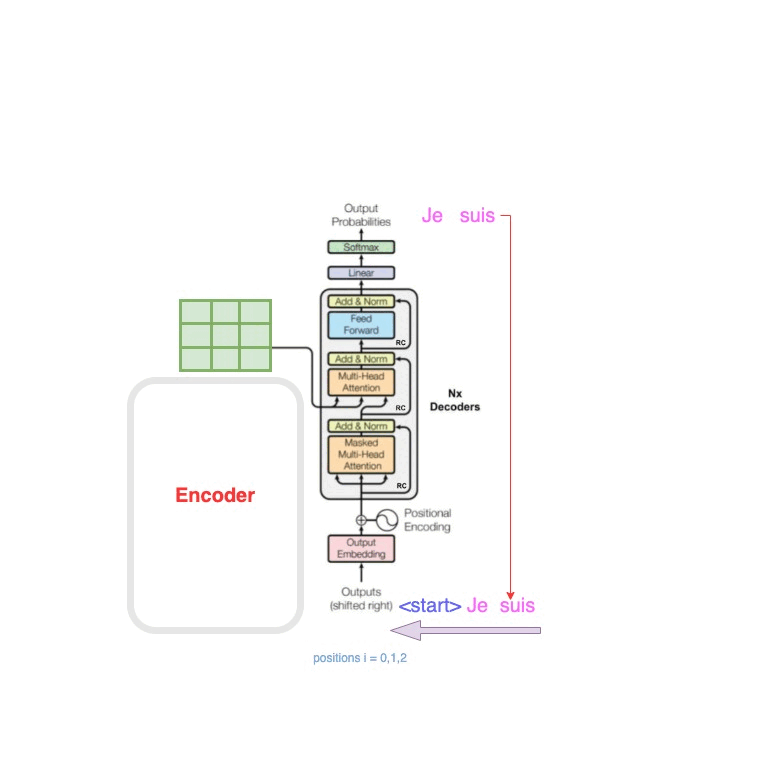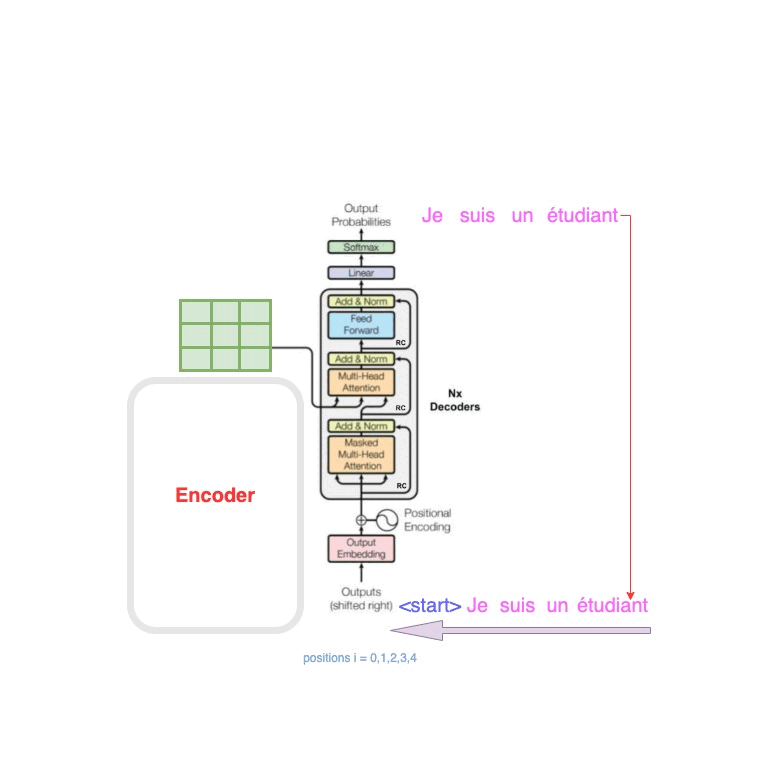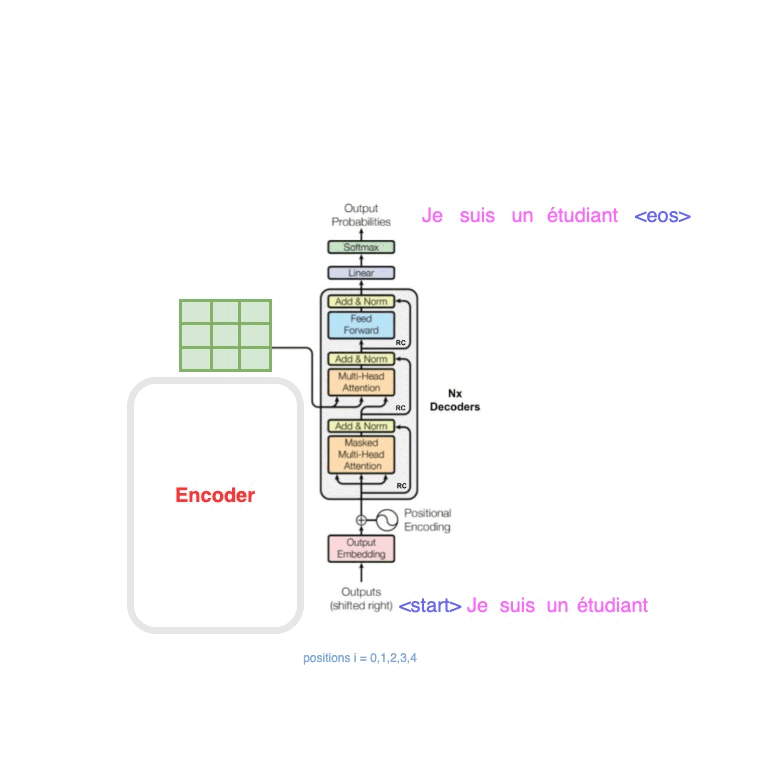
论文阅读笔记AI篇 —— Transformer模型理论+实战 (三)
论文阅读笔记AI篇 —— Transformer模型理论实战 (三) 第三遍阅读(精读)3.1 Attention和Self-Attention的区别?3.2 Transformer是如何进行堆叠的?3.3 如何理解Positional Encoding?3.x 文章涉及…
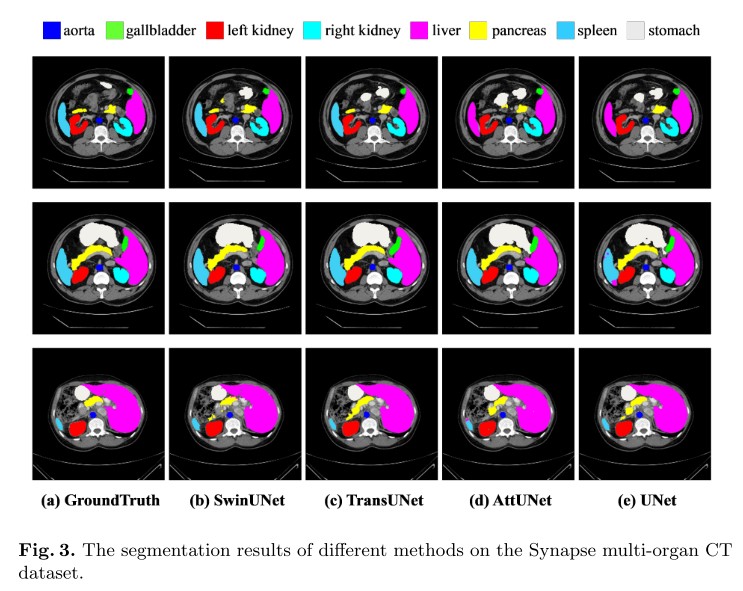
【论文阅读笔记】Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
1.介绍
Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation Swin-Unet:用于医学图像分割的类Unet纯Transformer
2022年发表在 Computer Vision – ECCV 2022 Workshops Paper Code
2.摘要
在过去的几年里,卷积神经网络ÿ…
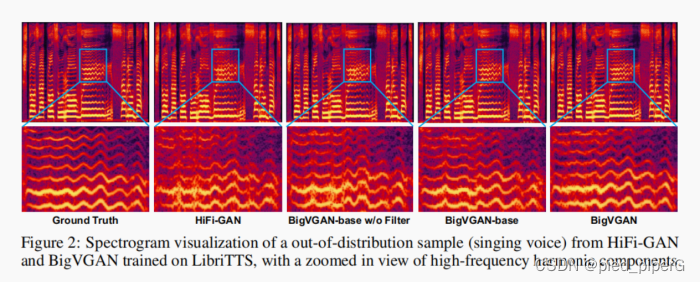
BIGVGAN: A UNIVERSAL NEURAL VOCODER WITHLARGE-SCALE TRAINING——TTS论文阅读
笔记地址:https://flowus.cn/share/a16a61b3-fcd0-4e0e-be5a-22ba641c6792 【FlowUs 息流】Bigvgan
论文地址:
BigVGAN: A Universal Neural Vocoder with Large-Scale Training
Abstract
背景:
最近基于生成对抗网络(GAN&am…
论文阅读:求解约束多目标区间优化的交互多属性决策NSGA-II算法
求解约束多目标区间优化的交互多属性决策NSGA-II算法 作者:陈志旺,陈林,白锌,杨七,赵方亮 期刊:控制与决策、2015.05 DOI:10.13195/j.kzyjc.2014.0455 内容简介
针对约束多目标区间优化问题,提出一种交互多属性决策NSGA-II算法.该算法将非线…

论文阅读:通过时空生成卷积网络合成动态模式(重点论文)
原文链接 github code 介绍视频 视频序列包含丰富的动态模式,例如在时域中表现出平稳性的动态纹理模式,以及在空间或时域中表现出非平稳的动作模式。 我们证明了时空生成卷积网络可用于建模和合成动态模式。 该模型定义了视频序列上的概率分布࿰…

Tortoise-tts Better speech synthesis through scaling——TTS论文阅读
笔记地址:https://flowus.cn/share/a79f6286-b48f-42be-8425-2b5d0880c648 【FlowUs 息流】tortoise
论文地址:
Better speech synthesis through scaling
Abstract:
自回归变换器和DDPM:自回归变换器(autoregressive transfo…
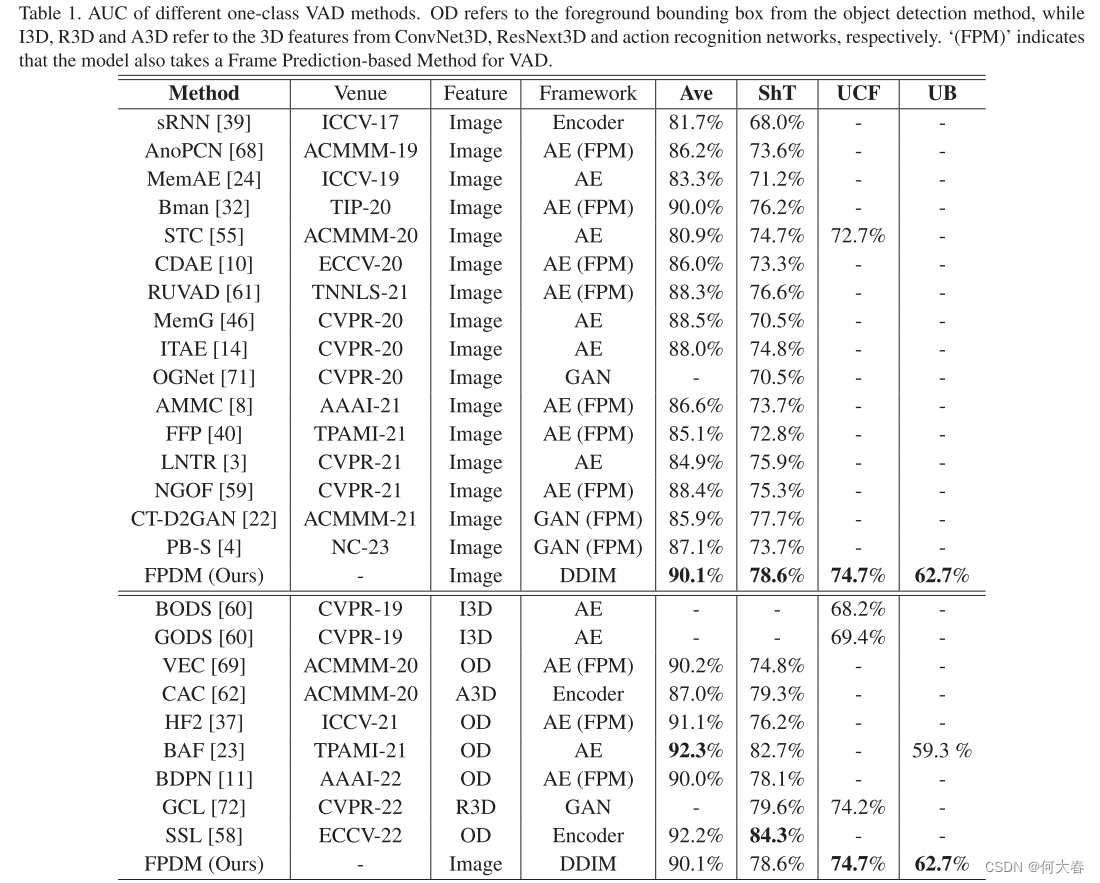
Feature Prediction Diffusion Model for Video Anomaly Detection 论文阅读
Feature Prediction Diffusion Model for Video Anomaly Detection论文阅读 Abstract1. Introduction2. Related work3. Method3.1. Problem Formulation3.2. Feature prediction diffusion module 3.3. Feature refinement diffusion module4. Experiments and discussions4.1…
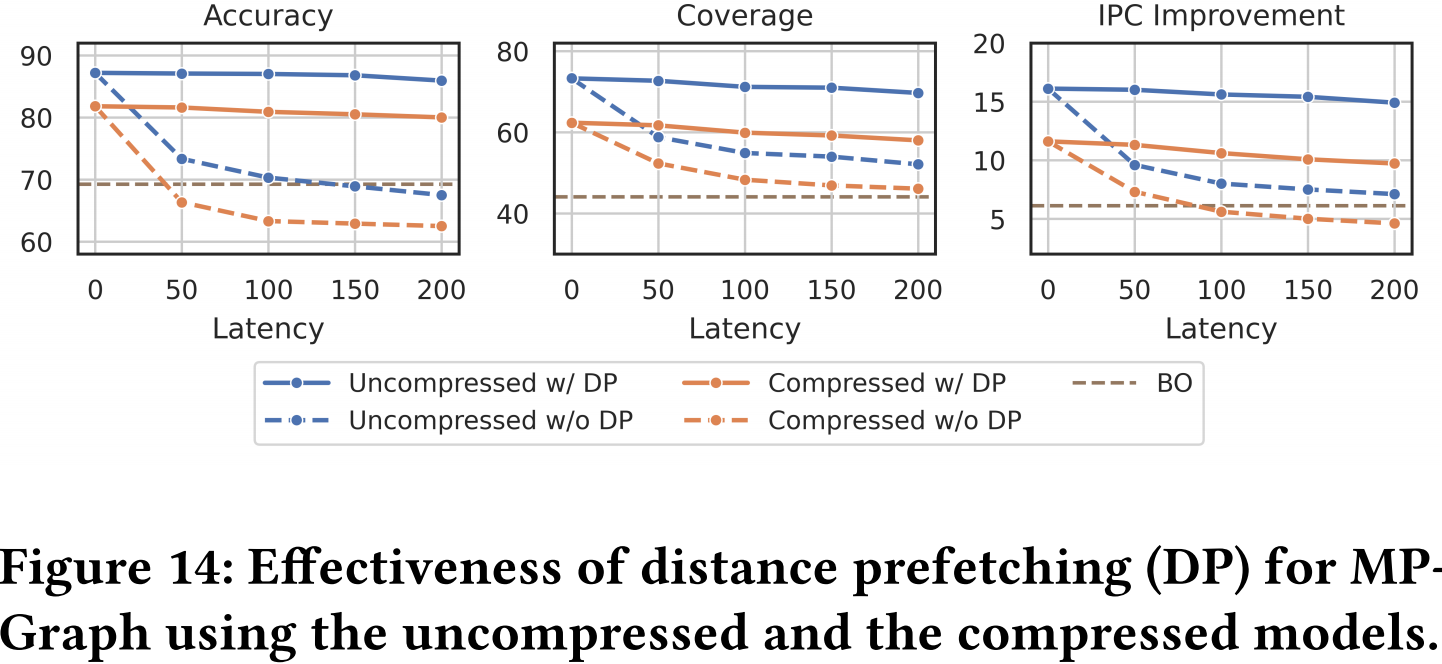
论文阅读,Domain Specific ML Prefetcher for Accelerating Graph Analytics(一)
目录
一、Article:文献出处(方便再次搜索)
(1)作者
(2)文献题目
(3)文献时间
(4)引用
二、Data:文献数据(总结归纳,方便理解&am…

AI Infra论文阅读之通过打表得到训练大模型的最佳并行配置
目录 0x0. 前言0x1. 摘要0x2. 介绍0x3. 背景0x4. 实验设置0x5. 高效的LLM训练分析0x5.1 Fused Kernels 和 Flash Attention0x5.1.1 Attention0x5.1.2 RMSNorm Kernel 0x5.2 Activation Checkpointing0x5.3 Micro-Batch 大小0x5.4 Tensor Parallelism和Pipline Parallelism0x5.5…
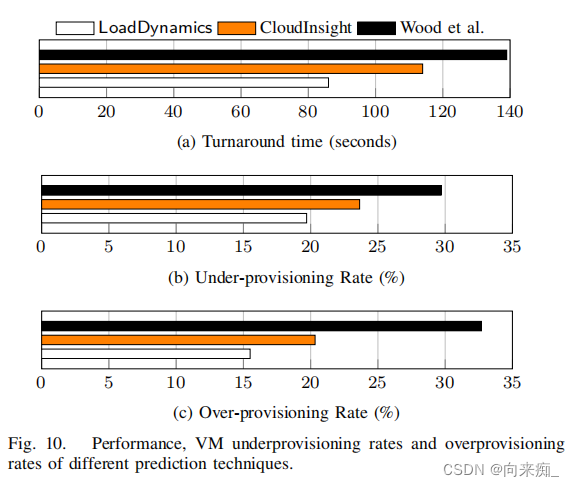
论文阅读-一个用于云计算中自我优化的通用工作负载预测框架
论文标题:A Self-Optimized Generic Workload Prediction Framework for Cloud Computing
概述
准确地预测未来的工作负载,如作业到达率和用户请求率,对于云计算中的资源管理和弹性非常关键。然而,设计一个通用的工作负载预测器…

EMNLP 2023精选:Text-to-SQL任务的前沿进展(上篇)——正会论文解读
导语
本文记录了今年的自然语言处理国际顶级会议EMNLP 2023中接收的所有与Text-to-SQL相关(通过搜索标题关键词查找得到,可能不全)的论文,共计12篇,包含5篇正会论文和7篇Findings论文,以下是对这些论文的略…
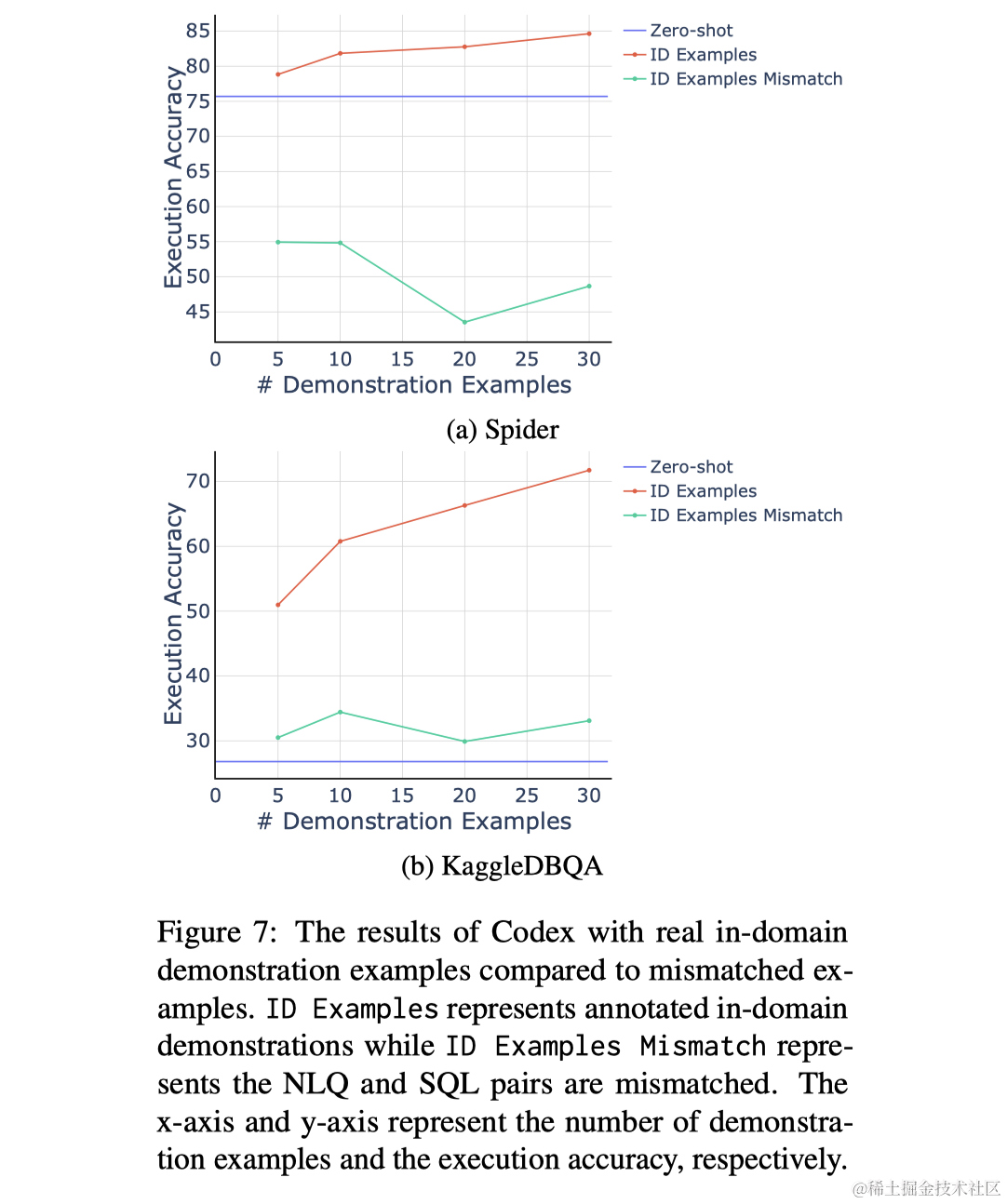
从领域外到领域内:LLM在Text-to-SQL任务中的演进之路
导语
本文介绍了ODIS框架,这是一种新颖的Text-to-SQL方法,它结合了领域外示例和合成生成的领域内示例,以提升大型语言模型在In-context Learning中的性能。
标题:Selective Demonstrations for Cross-domain Text-to-SQL会议&am…

图像处理之《生成隐写术中秘密到图像的可逆变换》论文阅读
一、文章摘要
近年来,将秘密信息转化为生成图像的生成隐写术已成为一种很有前途的抗隐写检测技术。然而,由于秘密图像变换的低效率和不可逆性,很难在信息隐藏能力和提取精度之间找到一个好的平衡点。为了解决这个问题,我们提出了…

NLP论文阅读记录 - 2021 | WOS 使用 GA-HC 和 PSO-HC 改进新闻文章的文本摘要
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试 二.相关工作三.本文方法3.1 总结为两阶段学习3.1.1 基础系统 3.2 重构文本摘要 四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结思考 前言 Improved Text Summa…

论文阅读 Self-Supervised Burst Super-Resolution
这是一篇 ICCV 2023 的文章,主要介绍的是用自监督的方式进行多帧超分的学习
Abstract
这篇文章介绍了一种基于自监督的学习方式来进行多帧超分的任务,这种方法只需要原始的带噪的低分辨率的图。它不需要利用模拟退化的方法来构造数据,而且模…
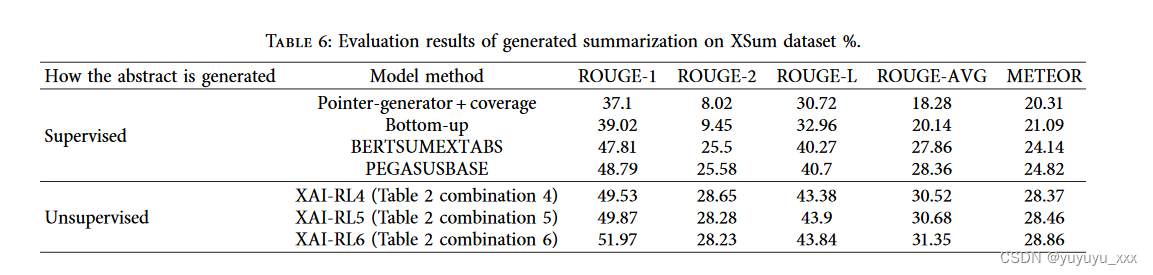
NLP论文阅读记录 - 2022 | WOS 04.基于 XAI 的强化学习方法,用于社交物联网内容的文本摘要
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.相关工作三.本文方法3.1 总结为两阶段学习3.1.1 基础系统 3.2 重构文本摘要 四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结思考 前言 XAI-Base…
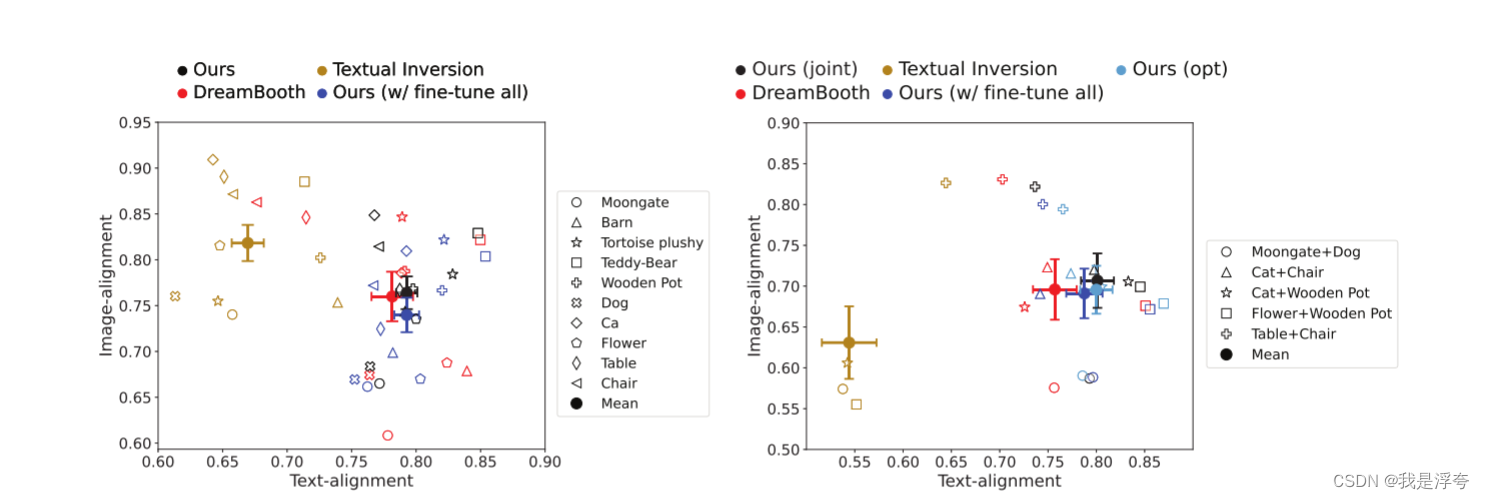
Multi-Concept Customization of Text-to-Image Diffusion——【论文笔记】
本文发表于CVPR 2023
论文地址:CVPR 2023 Open Access Repository (thecvf.com)
Github官方代码地址: github.com 一、Intorduction
最近的文本到图像模型能够根据文本提示生成高质量的图像,可以覆盖广泛的物体、风格和场景。尽管这些模型…

【论文笔记】UniVision: A Unified Framework for Vision-Centric 3D Perception
原文链接:https://arxiv.org/pdf/2401.06994.pdf
1. 引言
目前,同时处理基于图像的3D检测任务和占用预测任务还未得到充分探索。3D占用预测需要细粒度信息,多使用体素表达;而3D检测多使用BEV表达,因其更加高效。
本…

【论文阅读】Vlogger: Make Your Dream A Vlog
Vlogger:把你的梦想变成Vlog
paper:https://arxiv.org/abs/2401.09414
code:https://github.com/zhuangshaobin/vlogger
看起来挺有意思的,有空读一下 本文提出Vlogger,一种用于生成用户描述的分钟级视频博客(即vlo…

【论文阅读】EDPLVO: Efficient Direct Point-Line Visual Odometry
一、公式及符号约定
这篇论文是将直接法的残差计算从点扩展到了线段,所以一些符号在第三章的部分提前做了约定。用Π表示投影的函数,也就是用像素坐标和内参矩阵以及深度信息,投影出点的空间坐标,反之Π-1表示的是将空间坐标投影…
搜索服从幂律分布的网络 论文阅读
一、定义
1、幂律分布网络定义: 大部分通信网络和社会网络都具有幂律分布的特点,也即度数高的节点的数量少,度数低节点的数量多。
2、数学推导: 对于指数为τ、最小度数为k 1、在mkmaxm k_{max}mkmax处有突变截止点的幂律分…
论文阅读:On the User Behavior Leakage from Recommender System Exposure
论文地址
Motivation: 现阶段对于用户行为的保护仅仅从用户端来考虑,比如用户的行为数据等。然而推荐系统是一个闭环的过程,即用户交互了物品,推荐系统根据用户的交互信息去推荐物品,用户也会根据推荐系统推荐的物品做…

【论文阅读】Long-Tailed Recognition via Weight Balancing(CVPR2022)附MaxNorm的代码
目录 论文使用方法weight decayMaxNorm 如果使用原来的代码报错的可以看下面这个 论文
问题:真实世界中普遍存在长尾识别问题,朴素训练产生的模型在更高准确率方面偏向于普通类,导致稀有的类别准确率偏低。 key:解决LTR的关键是平衡各方面&a…

《论文阅读》Towards Emotional Support Dialog Systems
《论文阅读》Towards Emotional Support Dialog Systems 前言简介思路出发点相关知识区别EC、ER和ESCEmotional Support Conversation任务定义ESC框架数据集总结前言
你是否也对于理解论文存在困惑?
你是否也像我之前搜索论文解读,得到只是中文翻译的解读后感到失望?
小白…

论文阅读笔记《Common Visual Pattern Discovery via Spatially Coherent Correspondences》
核心思想 两组点集中共有的匹配区域通常具备两个特点:1.局部的特征相似;2.特征点在空间上的分布也相似。作者将候选匹配点对作为图的节点,将两种相似性统一到边的权重来表示。通过寻找图中稠密连接的子图来寻找两个点集中的匹配区域ÿ…
论文笔记 - 基于振动信号的减速器故障诊断方法
1.论文摘要
基于振动信号的减速器故障诊断方法, 沈晴,《起重运输机械》,2018 原作者联系方式: shenqing@zmpc.com
这篇文章包含了一个从工程到数据处理和故障定位的完整过程。是一篇综述文档。它介绍了机械设备常见的三类故障(轴,齿轮、轴承)的故障特征,并在一个故障追…
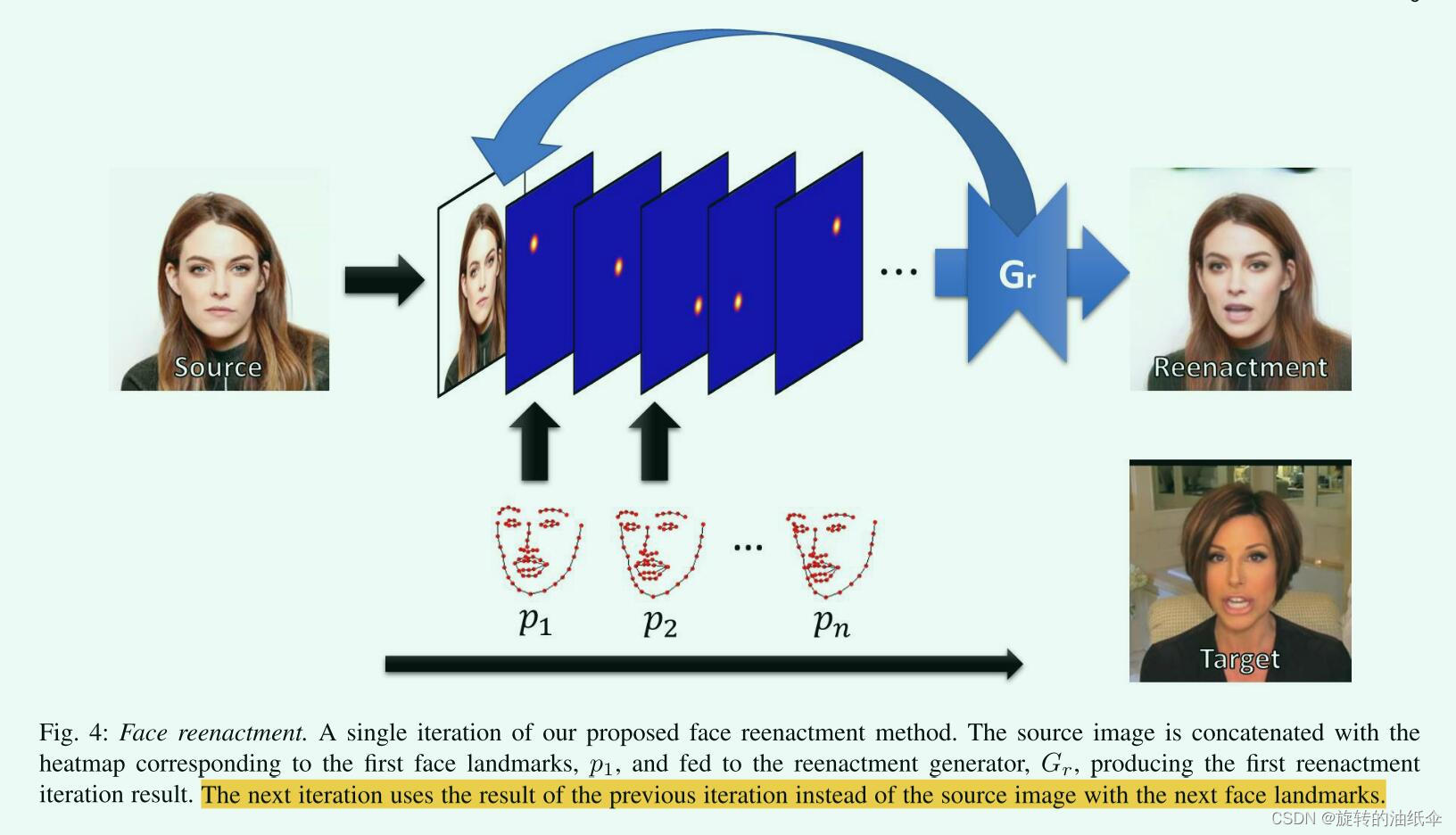
论文阅读【PAMI_2022】FSGANv2: Improved Subject Agnostic Face Swapping and Reenactment
论文阅读【PAMI_2022】FSGANv2: Improved Subject Agnostic Face Swapping and Reenactment论文的缩写全拼一、摘要(问题,贡献,效果)二、引言(idea)三、方法(FSGAN)1.Detection and tracking2.Generator ar…

【论文阅读】Frustratingly Simple Few-Shot Object Detection
从几个例子中检测稀有物体是一个新出现的问题。 先前的工作表明Meta-Learning是一种有希望的方法。 但是,微调技术很少引起注意。 我们发现,在稀有类上只对现有探测器的最后一层进行微调对于 Few-Shot Object Detection至关重要。 这样一种简单的方法在当…
[论文笔记] ICLR 2022 | 减少跨语言表示差异,字节跳动AI Lab通过流形混合增强跨语言迁移
论文地址:https://openreview.net/pdf?id=OjPmfr9GkVv代码地址:https://github.com/yhy1117/X-Mixup 字节跳动人工智能实验室和加利福尼亚大学圣塔芭芭拉分校的研究者提出了 跨语言流形混合(X-Mixup)方法为目标语言提供 “折衷” 的表示,让模型自适应地校准表示差…
【论文阅读】SimGNN:A Neural Network Approach to Fast Graph Similarity Computation
文章目录一、摘要二、要完成的任务分析三、图模型提取全局与局部特征四、NTN模块的作用与效果五、点之间的对应关系计算论文来源:SimGNN:A Neural Network Approach to Fast Graph Similarity Computation 一、摘要
图形相似性搜索是最重要的基于图形的应用程序之一…

图像处理之《黑盒扰动的可逆噪声流鲁棒水印》论文阅读
一、文章摘要
近年来,基于深度学习的数字水印框架得到了广泛的研究。现有的方法大多采用基于“编码器-噪声层-解码器”的架构,其中嵌入和提取过程分别由编码器和解码器完成。然而,这种框架的一个潜在缺点是编码器和解码器可能不能很好地耦合…

AI论文速读 | 2024【综述】图神经网络在智能交通系统中的应用
论文标题:A Survey on Graph Neural Networks in Intelligent Transportation Systems
链接:https://arxiv.org/abs/2401.00713
作者:Hourun Li, Yusheng Zhao, Zhengyang Mao, Yifang Qin, Zhiping Xiao, Jiaqi Feng, Yiyang Gu, Wei Ju, …

论文阅读:四足机器人对抗运动先验学习稳健和敏捷的行走
论文:Learning Robust and Agile Legged Locomotion Using Adversarial Motion Priors
进一步学习:AMP,baseline方法,TO
摘要:
介绍了一种新颖的系统,通过使用对抗性运动先验 (AMP) 使四足机器人在复杂地…

图像处理之《隐写网络的隐写术》论文阅读
一、文章摘要
隐写术是一种在双方之间进行秘密通信的技术。随着深度神经网络(DNN)的快速发展,近年来越来越多的隐写网络被提出,并显示出良好的性能。与传统的手工隐写工具不同,隐写网络的规模相对较大。如何在公共信道上秘密传输隐写网络引起…

论文阅读-EMS: History-Driven Mutation for Coverage-based Fuzzing(2022)模糊测试
一、背景 本文研究了基于覆盖率的模糊测试中的历史驱动变异技术。之前的研究主要采用自适应变异策略或集成约束求解技术来探索触发独特路径和崩溃的测试用例,但它们缺乏对模糊测试历史的细粒度重用,即它们在不同的模糊测试试验之间很大程度上未能正确利用…

【论文阅读笔记】Contrastive Learning with Stronger Augmentations
Contrastive Learning with Stronger Augmentations
摘要
基于提供的摘要,该论文的核心焦点是在对比学习领域提出的一个新框架——利用强数据增强的对比学习(Contrastive Learning with Stronger Augmentations,简称CLSA)。以下…

『论文阅读|利用深度学习在热图像中实现无人机目标检测』
利用深度学习在热图像中实现无人机目标检测 摘要1 引言1.1 小物体检测1.2 物体检测中的模型组合1.3 热图像处理 2 提出的模型2.1 预测头数量2.2 骨干网络优化2.3 Transformer encoder 模块2.4 使用滑动窗口和注意力进行卷积2.5 训练和运行过程 3 结果3.1 数据集3.2 评估指标和平…

论文阅读【ACM_2020】SimSwap: An Efficient Framework For High Fidelity Face Swapping
论文阅读【ACM_2020】SimSwap: An Efficient Framework For High Fidelity Face Swapping论文的缩写全拼一、摘要(问题,贡献,效果)二、引言(idea)1.idea,指出问题所在。三、方法1.Generalization to Arbitrary Identity(介绍IIM模块)2.Genera…
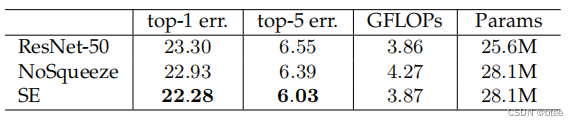
论文阅读 | Squeeze-and-Excitation Networks (SENet)
前言:经典重温,不怎么加参数提升性能的模块SENet 代码:【here】
Squeeze-and-Excitation Networks
引言
神经网络中每一层的卷积实际就是一组卷积核作用在带着通道的空间局部区域上,一起融合有着感受野的空间信息和通道信息 At…
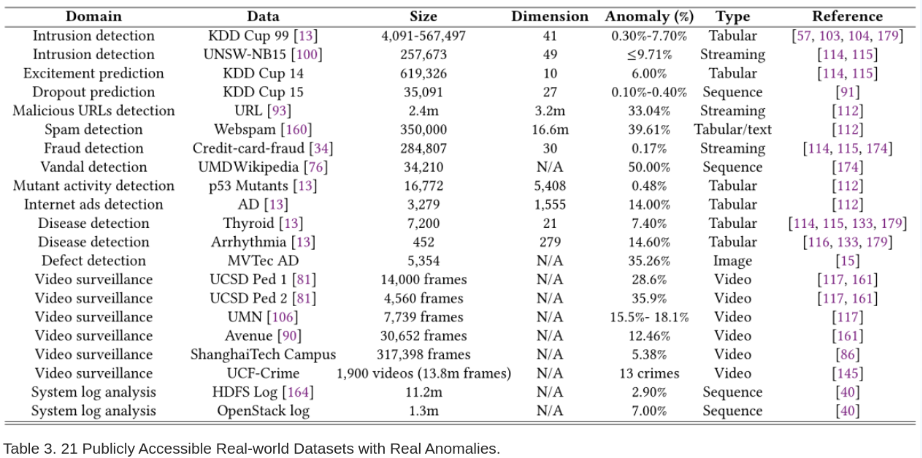
论文阅读_基于深度学习的异常检测综述
英文题目:Deep Learning for Anomaly Detection: A Review 中文题目:基于深度学习的异常检测综述 论文地址:https://arxiv.org/pdf/2007.02500.pdf 领域:异常检测,深度学习 发表时间:2020.01 作者ÿ…
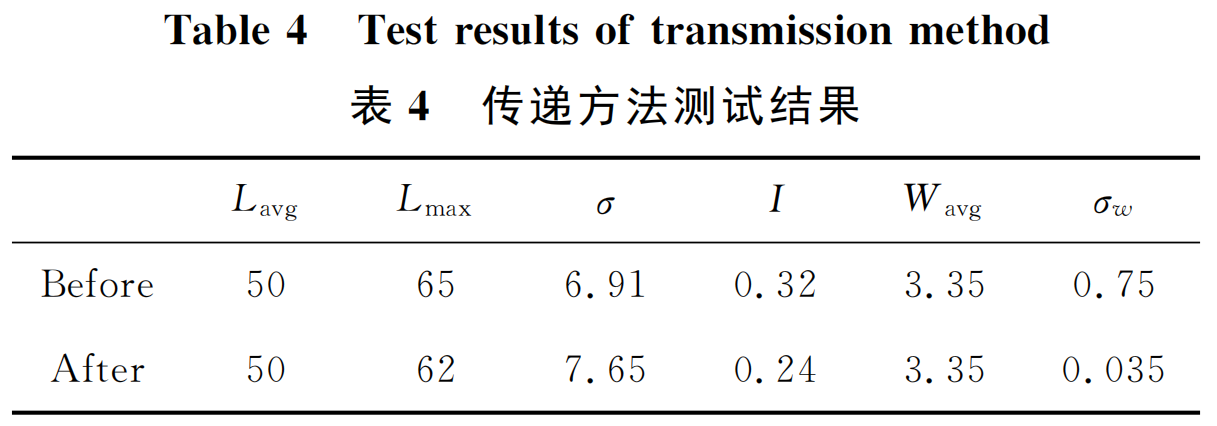
论文阅读-基于动态权重的一致性哈希微服务负载均衡优化
论文名称:基于动态权重的一致性哈希微服务负载均衡优化
摘要
随着互联网技术的发展,互联网服务器集群的负载能力正面临前所未有的挑战。在这样的背景下,实现合理的负载均衡策略变得尤为重要。为了达到最佳的效率,可以利用一致性…

【论文阅读 WWW‘23】Zero-shot Clarifying Question Generation for Conversational Search
文章目录前言MotivationContributionsMethodFacet-constrained Question GenerationMultiform Question Prompting and RankingExperimentsDatasetResultAuto-metric evaluationHuman evaluationKnowledge前言
最近对一些之前的文章进行了重读,因此整理了之前的笔记…
【论文阅读笔记】AutoAugment:Learning Augmentation Strategies from Data
AutoAugment:Learning Augmentation Strategies from Data
摘要
🔬 研究方法: 本文描述了一种名为AutoAugment的简单程序,通过这个程序可以自动寻找改进的数据增强策略。研究设计了一个策略空间,其中策略包含多个子策略,在每个小…

『论文阅读|研究用于视障人士户外障碍物检测的 YOLO 模型』
研究用于视障人士户外障碍物检测的 YOLO 模型 摘要1 引言2 相关工作2.1 障碍物检测的相关工作2.2 物体检测和其他基于CNN的模型 3 问题的提出4 方法4.1 YOLO4.2 YOLOv54.3 YOLOv64.4 YOLOv74.5 YOLOv84.6 YOLO-NAS 5 实验和结果5.1 数据集和预处理5.2 训练和实现细节5.3 性能指…
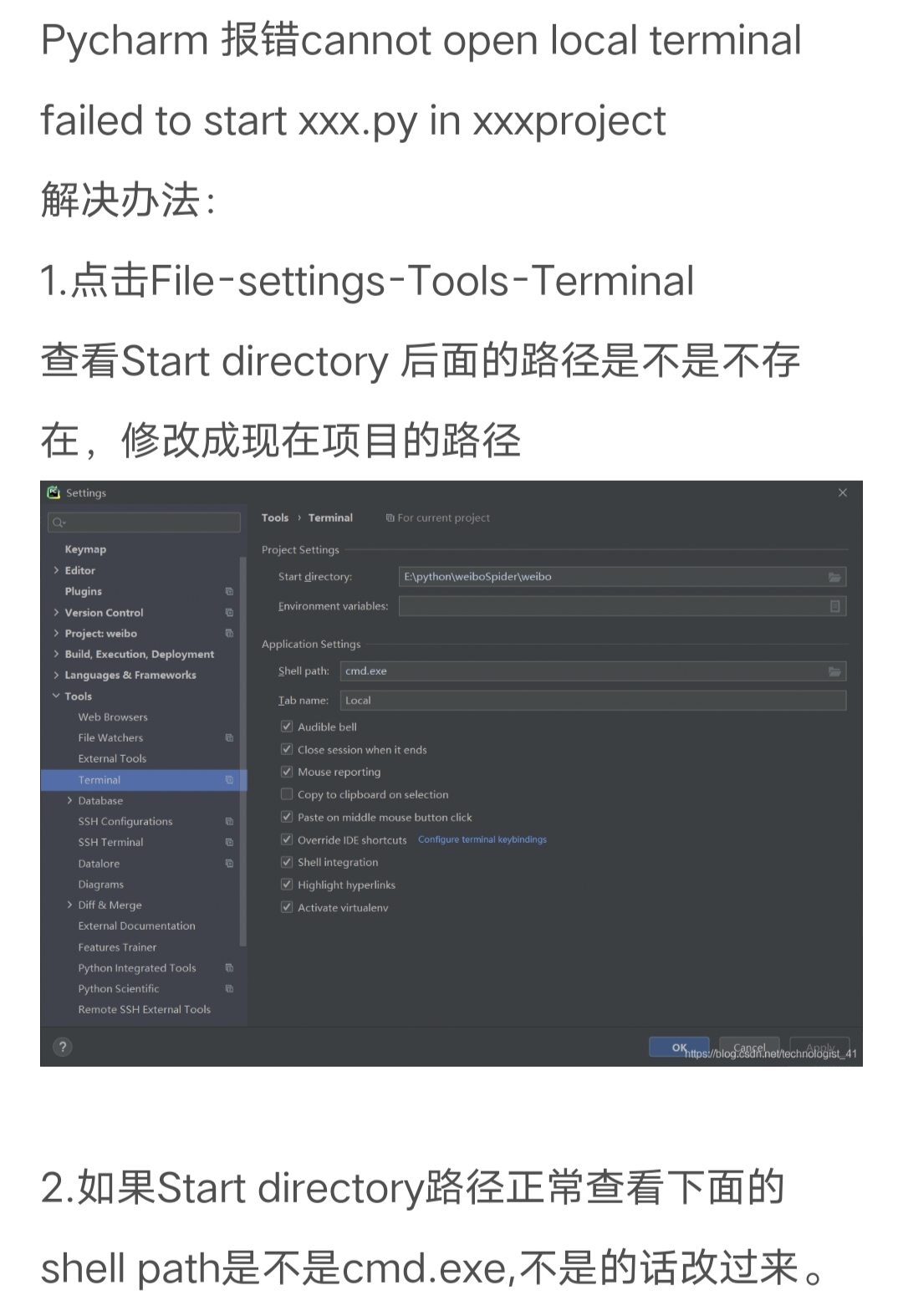
TensoRF-张量辐射场论文笔记
TensoRF-张量辐射场论文笔记_什度学习的博客-CSDN博客
注释代码: https://github.com/xunull/read-TensoRF 官方源码:https://github.com/apchenstu/TensoRF
Install environment
conda create -n TensoRF python3.8
conda activate TensoRF
pip install torch t…

论文阅读笔记 | 三维目标检测——AVOD算法
如有错误,恳请指出。 文章目录1. 背景2. 网络结构3. 实验结果paper:《Joint 3D Proposal Generation and Object Detection from View Aggregation》
1. 背景
AVOD同样是一个two-stage(使用了RPN提取候选框)、anchor-based网络结构。获得较高的召回率对…

编程思维是一种什么思维?
hello wordl! keep coding!🏃 学编程不是将来要当程序猿,而是在学习编程思维。比尔盖茨、扎克伯格、乔布斯用经验告诉我们,拥有编程思维的人,就相当于成功了一半——不但逻辑清晰心思缜密,…
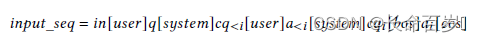
关于Conversational QA 的一些调研
文章目录Paper1: Understanding User Satisfaction with Task-oriented Dialogue SystemsMotivation:Classification:Contributions:DatasetKnowledge:Paper2: Evaluating Mixed-initiative Conversational Search Systems via User SimulationMotivationClassification:Contri…

论文精读--GPT3
不像GPT2一样追求zero-shot,而换成了few-shot
Abstract Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically task-agnos…

论文阅读《Point NeRF:Point-based Neural Radiance Fileds》
论文地址:https://arxiv.org/abs/2201.08845 源码地址:https://xharlie.github.io/projects/project_sites/pointnerf 概述 体素神经渲染的方法生成高质量的结果非常耗时,且对不同场景需要重新训练(模型不具备泛化能力)…
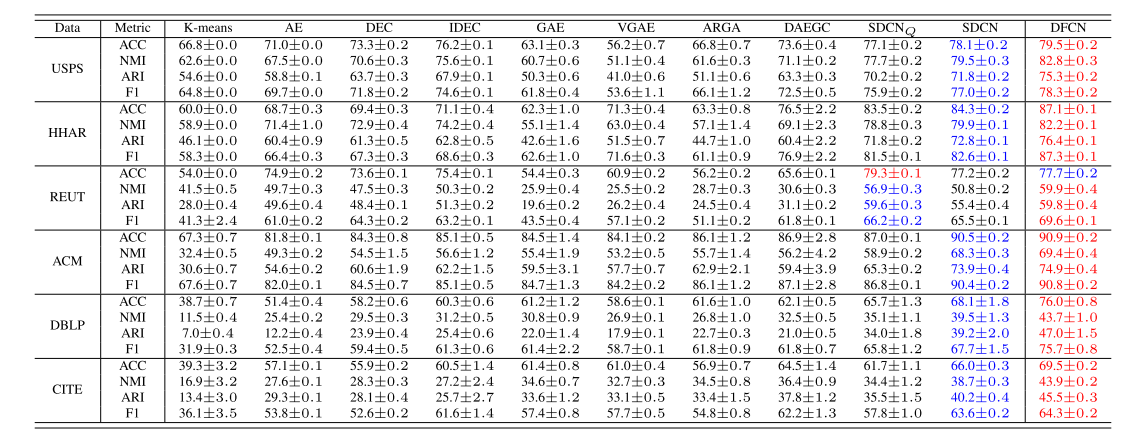
论文阅读09——《Deep Fusion Clustering Network》
论文阅读09——《Deep Fusion Clustering Network》
原文链接:论文阅读09——《Deep Fusion Clustering Network》 作者:Wenxuan Tu, Sihang Zhou, Xinwang Liu, Xifeng Guo, Zhiping Cai, En zhu, Jieren Cheng 发表时间:2021年5月18日 论文…

论文阅读《Block-NeRF: Scalable Large Scene Neural View Synthesis》
论文地址:https://arxiv.org/pdf/2202.05263.pdf 复现源码:https://github.com/dvlab-research/BlockNeRFPytorch 概述 Block-NeRF是一种能够表示大规模环境的神经辐射场(Neural Radiance Fields)的变体,将 NeRF 扩展到…

通过大语言模型理解运维故障:评估和总结
张圣林 南开大学软件学院副教授、博士生导师 第六届CCF国际AIOps挑战赛程序委员会主席
在ATC、WWW、VLDB、KDD、SIGMETRICS等国际会议和JSAC、TC、TSC等国际期刊发表高水平论文50余篇。主持国家自然科学基金项目2项,横向项目13项(与华为、字节跳动、腾讯…
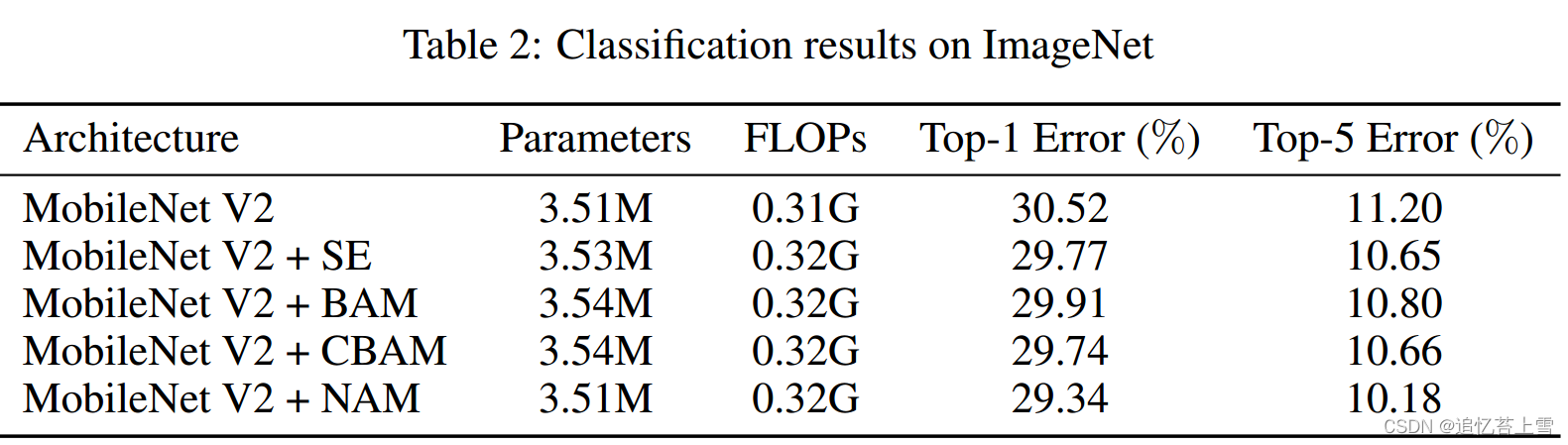
论文阅读NAM:Normalization-based Attention Module
Abstarct
识别不太显著的特征是模型压缩的关键。然而,在革命性的注意力机制中却没有对其进行研究。在这项工作中,我们提出了一种新的基于归一化的注意力模块(NAM),它抑制了不太显著的权重。它对注意力模块应用了权重稀…

【论文阅读笔记】Explicit Visual Prompting for Low-Level Structure Segmentations
1.介绍
Explicit Visual Prompting for Low-Level Structure Segmentations 低级结构分割的显式视觉提示 2023年发表在IEEE CVPR Paper Code
2.摘要
检测图像中低级结构(低层特征)一般包括分割操纵部分、识别失焦像素、分离阴影区域和检测隐藏对象。虽…

论文阅读|Embedding-based Retrieval in Facebook Search
该论文是facebook发表在KDD2020上的一篇关于搜索召回的paper。这篇文章提到的大多trick对于做过召回的同学比较熟悉了,可贵之处在于全面,包括了特征、样本、模型、全链路等各种细节知识。
1. 整体思路与框架
本文的出发点是搜索只做到query关键词匹配的…
The Loss Surfaces of Multilayer Networks论文阅读
1. 摘要
本文研究全连接前馈神经网络的简单模型的高度非凸损失函数与球自旋玻璃模型的联系,基本假设是:i)变量独立;ii)网络参数冗余;iii)一致性。这些假设让我们可以利用随机矩阵理论的棱镜来解…
论文阅读:《Evidence for a fundamental property of steering》
文章目录1 背景2 方法2.1 方向盘修正行为标识2.2 数据2.3 数据拟合3 结果3.1 速率曲线3.2 恒定的转向时间3.3 基本运动元素的叠加3.4 其他实验4 讨论5 总结(个人)1 背景 这篇短文的主要目的是去阐述“转方向盘”这一行为的基本性质:方向盘修正…

论文阅读:Towards Stable Test-time Adaptation in Dynamic Wild World
今天阅读ICLR 2023 ——Towards Stable Test-time Adaptation in Dynamic Wild World Keywords:Test-time adaptation (TTA); 文章目录Towards Stable Test-time Adaptation in Dynamic Wild WorldProblem:motivation:Contributio…

论文阅读和分析:Mathematical formula recognition using graph grammar
Mathematical formula recognition using graph grammar
主要工作:
1、第一次实现Ofr(Optical Formula Recognition)系统,提取和识别数学表达式;
2、三个部分:OCR、构建图、解析图到语法树;
3、使用压缩子图成为一…
论文阅读--Diffusion Models for Reinforcement Learning: A Survey
一、论文概述
本文主要内容是关于在强化学习中应用扩散模型的综述。文章首先介绍了强化学习面临的挑战,以及扩散模型如何解决这些挑战。接着介绍了扩散模型的基础知识和在强化学习中的应用方法。然后讨论了扩散模型在强化学习中的不同角色,并对其在多个…
论文笔记 - 基于振动信号的减速器故障诊断(进行中...)
基于振动信号的减速器故障诊断, 沈晴,2018
问题1 倒谱
倒谱 就是近似db坐标,对吧? 倒谱(Cepstrum)是一种信号处理技术,其名称来源于"频谱"(spectrum)一词,通过将信号的对…
论文阅读 - ANEMONE: Graph Anomaly Detection with Multi-Scale Contrastive Learning
目录
摘要
1 简介
2 问题陈述
3 PROPOSED ANEMONE FRAMEWORK
3.1 多尺度对比学习模型
3.1.1 增强的自我网络生成
3.1.2 补丁级对比网络 3.1.3 上下文级对比网络
3.1.4 联合训练 3.2 统计异常估计器
4 EXPERIMENTS
4.1 Experimental Setup 4.1.1 Datasets 4.1.2 …
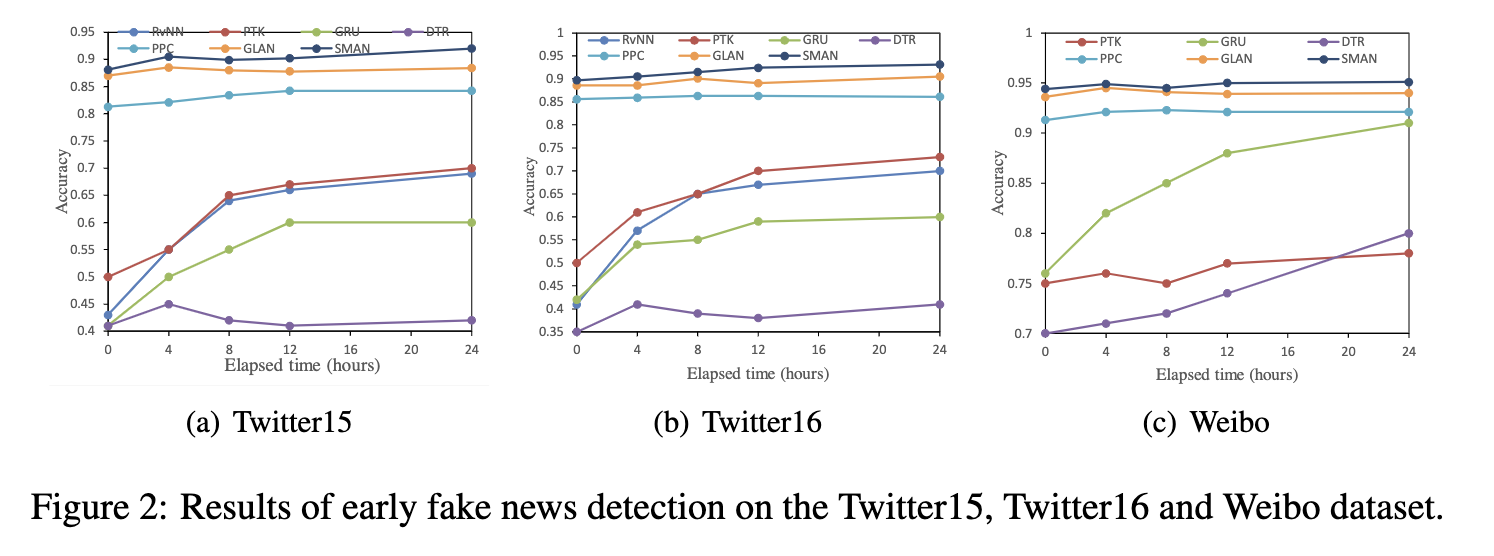
论文阅读 - Early Detection of Fake News by Utilizing the Credibility of News
论文链接:https://arxiv.org/pdf/2012.04233.pdf
目录
摘要
1 简介
2 相关工作
2.1 基于特征的方法
2.2 深度学习方法
3 问题表述
4 拟议的框架
4.2 用户可信度预测
4.3 虚假新闻分类
4.3.1 新闻内容表示
4.3.2 融合注意力单元
5 实验
5.1 数…
【论文阅读】ViT阅读笔记
标题
一张图片可以等价于16*16的单词
transformer可以做大规模的图像识别
摘要
虽然现在transformer在nlp上得到广泛运用,但在cv上还没有运用
一般都是cnnattention
现在用transformer用cv的效果特别好
引言
nlp的主流方式:先做预训练࿰…
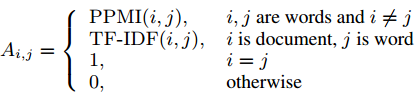
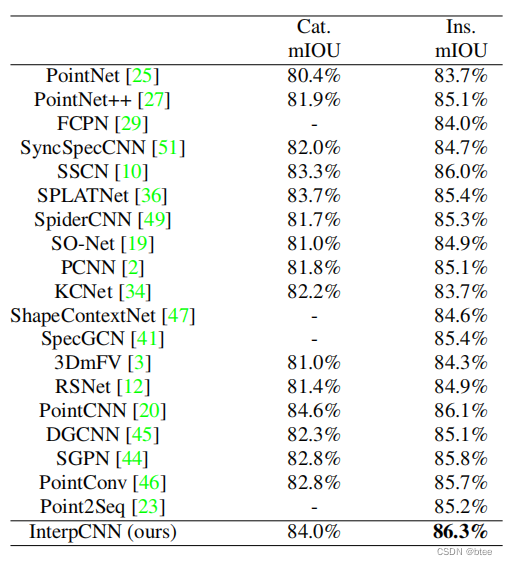
论文阅读 | Interpolated Convolutional Networks for 3D Point Cloud Understanding
前言:ICCV2019点云特征提取点卷积InterpoConv
Interpolated Convolutional Networks for 3D Point Cloud Understanding
引言
点云是不规则、无序、且稀疏的 处理这样的点云数据有两大类方法 第一:voxel化 directly rasterize irregular point clouds…
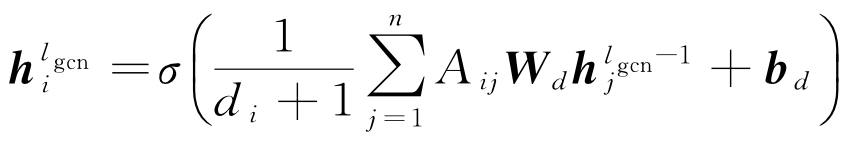
Aspect-Based Sentiment Analysis Model with Bi-Guide Attention Network 论文阅读笔记
一、作者
Xie Jun, Wang Yuzhu, Chen Bo, Zhang Zehua, and Liu Qin
College of Information and Computer, Taiyuan University of Technology, Jinzhong, Shanxi
二、背景
在应用于方面情感分析的深度神经网络中,序列型神经网络能捕获句子的上下文语义信息&am…

目标检测论文阅读:RepPoints算法笔记
标题:RepPoints: Point Set Representation for Object Detection 会议:ICCV2019 论文地址:https://ieeexplore.ieee.org/document/9009032/ 官方代码:https://github.com/microsoft/RepPoints 作者单位:北京大学、清华…
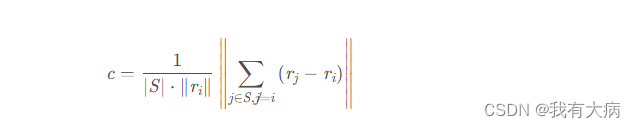
【LeGO-LOAM论文阅读(二)--特征提取(二)】
简介
上篇博客介绍了特征提取的原理以及坐标转化和插值的源码理解,这篇将介绍特征提取的后续算法模块。
源码
1、新数据进来进行坐标转换和插补等工作
见【LeGO-LOAM论文阅读(二)–特征提取(一)】
2、进行光滑度计…
【论文阅读】A Comparative Study on Camera-Radar Calibration Methods
目录 A Comparative Study on Camera-Radar Calibration MethodsAbstractI. INTRODUCTIONII. CALIBRATION METHODSIII. EXPERIMENTSIV. CONCLUSIONWords A Comparative Study on Camera-Radar Calibration Methods
综述文
Abstract
compare three types of the calibration …
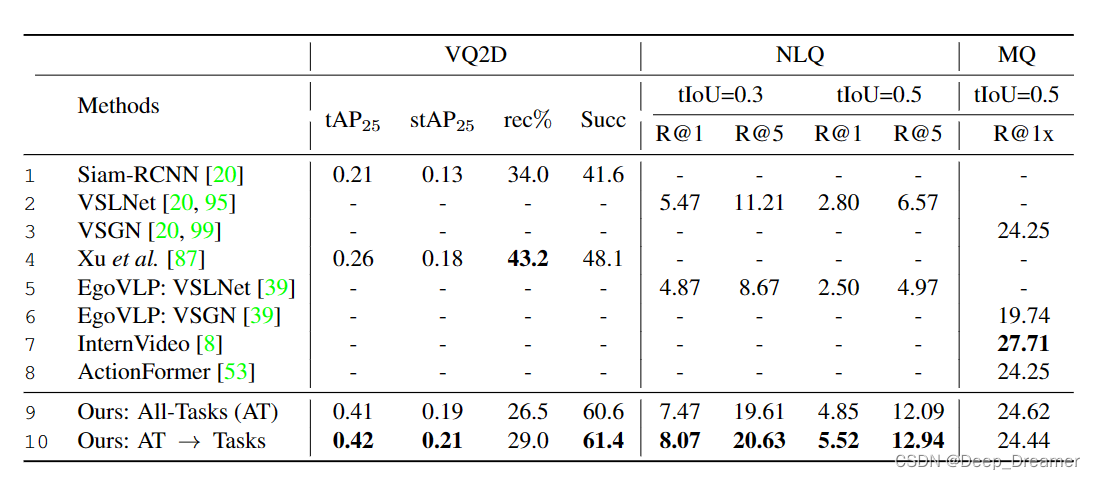
【论文阅读】MINOTAUR: Multi-task Video Grounding From Multimodal Queries
背景动机
细粒度的视频理解已经成为增强现实(AR)和机器人应用开发的关键能力。为了达到这种级别的视频理解,智能体(例如虚拟助手)必须具备识别和推理视频中捕获的事件和对象的能力,处理一系列视觉任务,如活动检测、对象检索和(空间)时间基础…

【论文阅读总结】用于目标检测的特征金字塔网络(FPN)
Feature Pyramid Networks for Object Detection1.摘要2.引言2.1 低级特征对于检测小物体很重要2.2 算法目标3. 文献综述3.1 Hand-engineered features and early neural networks3.2 Deep ConvNet object detectors3.3 Methods using multiple layers4.Feature Pyramid Networ…
《论文阅读》利用提示学习的情感对话识别
《论文阅读》利用提示学习的情感对话识别 前言相关知识范式的转变提示学习任务定义填槽形式答案映射提示生成基于提示的训练策略简介挑战模型框架特征提取语义特征常识特征连续提示生成语句情感预测损失函数设计实验结果宏观比较前言
你是否也对于理解论文存在困惑?
你是否
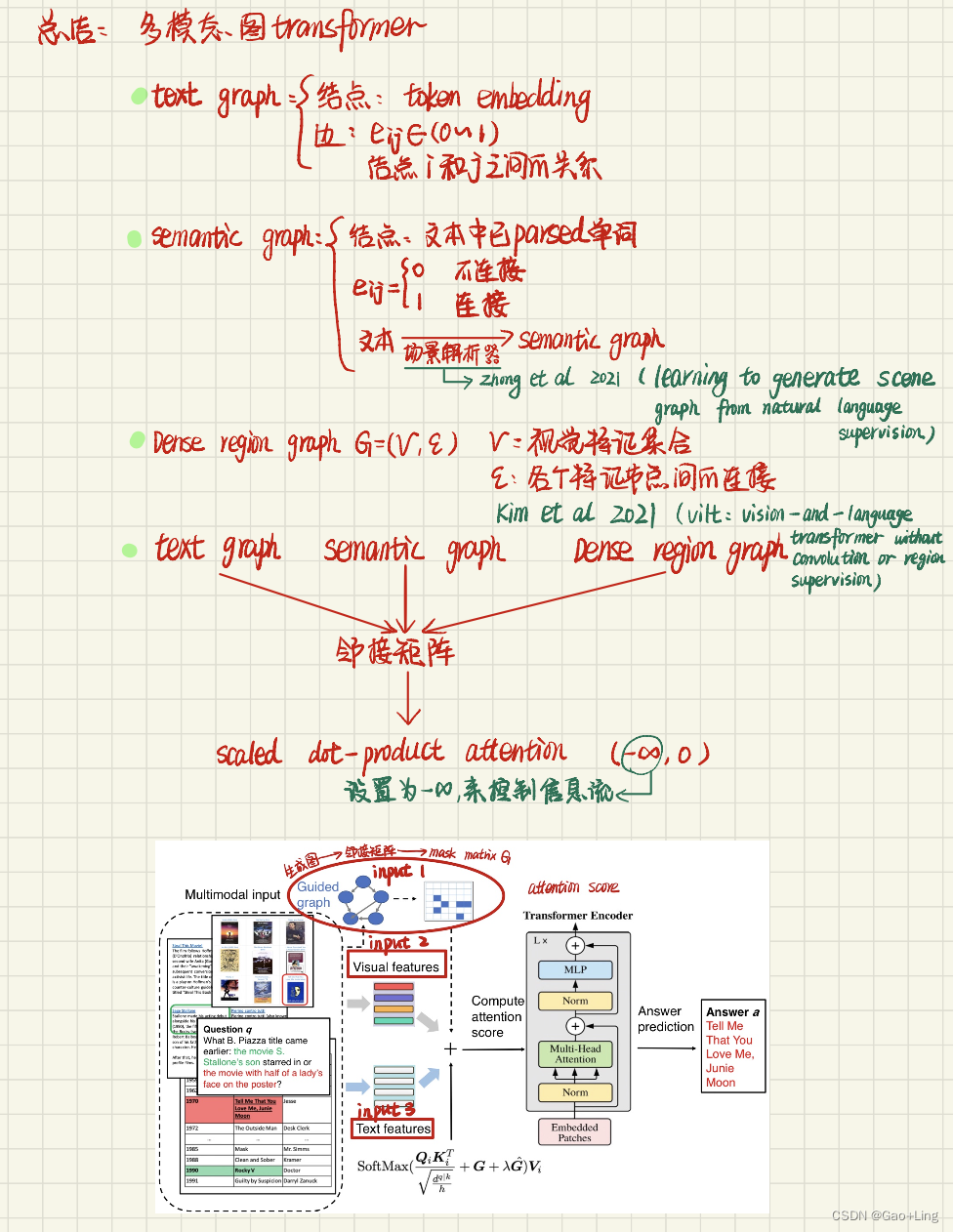
论文阅读:Multimodal Graph Transformer for Multimodal Question Answering
文章目录 论文链接摘要1 contribution3 Multimodal Graph Transformer3.1 Background on Transformers3.2 Framework overview 框架概述3.3 Multimodal graph construction多模态图的构建Text graphSemantic graphDense region graph Graph-involved quasi-attention 总结 论文…
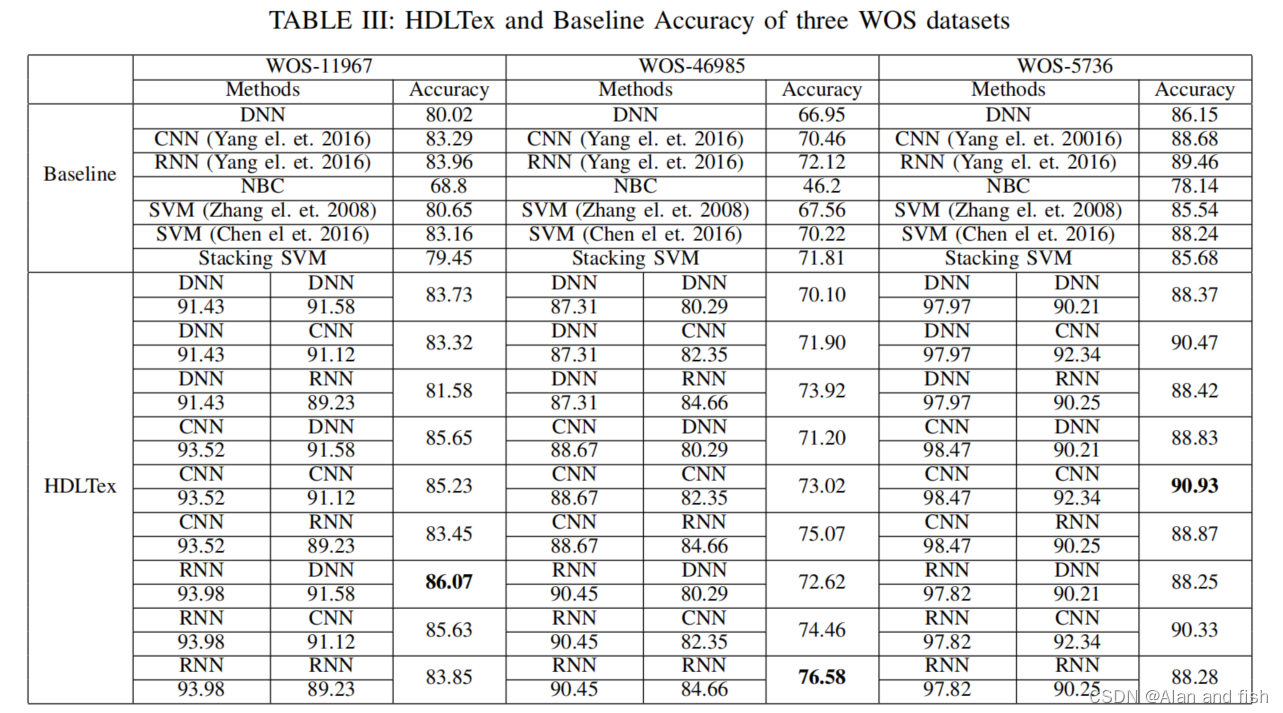
论文阅读【14】HDLTex: Hierarchical Deep Learning for Text Classification
论文十问十答: Q1论文试图解决什么问题? 多标签文本分类问题 Q2这是否是一个新的问题? 不是 Q3这篇文章要验证一个什么科学假设? 因为文本标签越多,分类就越难,所以就将文本类型进行分层分类,这…
盐穴储能项目-机械密封相关方向论文阅读【1】
盐穴储能-机械密封论文阅读【1】 1. 论文1:A study of reciprocating seals with a new mixed-lubrication model based on inverse lubrication theory1.1 题目:基于逆润滑理论并针对往复式密封的一种新型混合润滑模型1.2 摘要翻译1.3 试验台如下:2. A Mixed Lubrication M…
《论文阅读》基于提示的知识生成解决对话情感推理难题
《论文阅读》基于提示的知识生成解决对话情感推理难题 前言摘要作者新观点问题定义模型框架Global ModelLocal ModelPrompt Based Knowledge Generation分类器实验结果问题前言
你是否也对于理解论文存在困惑?
你是否也像我之前搜索论文解读,得到只是中文翻译的解读后感到失…

论文阅读《Gradient-based Camera Exposure Control for Outdoor Mobile Platforms》
摘要
本文介绍了一种用于移动机器人平台上图像处理和计算机视觉应用的自动调节相机曝光的新方法。由于大多数图像处理算法严重依赖于主要基于局部梯度信息的低级图像特征,因此我们认为梯度量可以确定适当的曝光水平,从而使相机能够以对照明条件具有鲁棒…

【论文阅读】23_SIGIR_Disentangled Contrastive Collaborative Filtering(分离对比协同过滤)
【论文阅读】23_SIGIR_Disentangled Contrastive Collaborative Filtering(分离对比协同过滤) 文章目录 【论文阅读】23_SIGIR_Disentangled Contrastive Collaborative Filtering(分离对比协同过滤)1. 来源2. 介绍3. 模型方法3.1…
论文阅读 —— 滤波激光SLAM
文章目录 1 FAST-LIO22 FAST-LIO3 EKF4 摘要第一句 1 FAST-LIO2
摘要: 本文介绍了FAST-LIO2:一种快速、稳健、通用的激光雷达惯性里程计框架。 FAST-LIO2建立在高效紧耦合迭代卡尔曼滤波器的基础上,有两个关键的新颖之处,可以实现…
《论文阅读》连续前缀提示Prompt:table-to-text和摘要生成 ACL2021
《论文阅读》连续前缀提示Prompt:table-to-text和摘要生成 ACL2021 前言相关知识Table-to-Text Generation自编码语言模型自回归语言模型简介任务定义部分参数更新代码实验结果前言
你是否也对于理解论文存在困惑?
你是否也像我之前搜索论文解读,得到只是中文翻译的解读后…

论文阅读和分析:Binary CorNET Accelerator for HR Estimation From Wrist-PPG
主要贡献:
一种完全二值化网络(bCorNET)拓扑结构及其相应的算法-架构映射和高效实现。对CorNET进行量化后,减少计算量,又能实现减轻运动伪影的效果。 该框架在22个IEEE SPC受试者上的MAE为6.675.49 bpm。该设计采用ST65 nm技术框架ÿ…
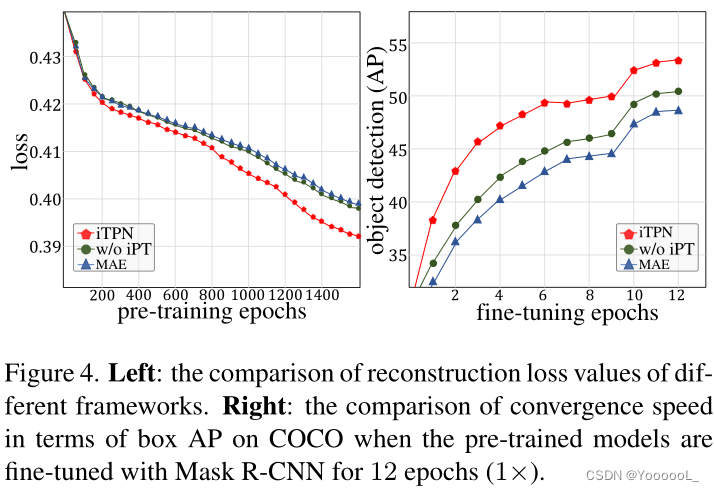
【自监督论文阅读笔记】Integrally Pre-Trained Transformer Pyramid Networks (2022)
Abstract 在本文中,我们提出了一个基于掩码图像建模 (MIM) 的整体预训练框架。我们提倡 联合预训练 backbone 和 neck,使 MIM 和下游识别任务之间的迁移差距最小。我们做出了两项技术贡献。首先,我们通过 在预训练阶段 插入特征金字塔 来统一…
【论文阅读】TDANet:一种具有自上而下注意力的用于语音分离的高效自编码器架构(ICLR 2023)
TDANet: 一种具有自上而下注意力的用于语音分离的高效自编码器架构 文章目录TDANet: 一种具有自上而下注意力的用于语音分离的高效自编码器架构速览摘要方法PipelineTDANet实验总结速览
下载收录源码机构演示arxivICLR 2023PyTorch清华大学Demo
inproceedings{tdanet2023iclr,…
《论文阅读》验证离散提示模板的鲁棒性 EACL2023
《论文阅读》验证离散提示模板的鲁棒性 EACL2023 前言动机手工 prompt 和 离散 prompt质疑实验设置模型数据集评估指标实验验证实验1: 训练数据集大小实验2: 离散 prompt 的泛化能力实验3: 干扰之字符重新排序实验4: 干扰之删除字符实验5: 干扰之对抗性干扰前言
你是否也对于理…
【无标题】Instant NGP(使用哈希编码的多分辨率的即时神经图形原语)
论文基本信息 作者:THOMAS MLLER,NVIDIA,瑞士ALEX EV ANS,NVIDIA,英国CHRISTOPH SCHIED,美国NVIDIA ALEXANDER KELLER,德国 关键词: Image Synthesis, Neural Networks, En- codings…
论文阅读笔记3:Patch-NetVLAD
题目:Patch-NetVLAD: Multi-Scale Fusion of Locally-Global Descriptorsfor Place Recognition
团队:澳大利亚昆士兰理工大学,电气工程与机器人学院和QUT机器人中心
解决的问题:克服视点和外观变化的双重问题
创新点ÿ…
latex_5_一篇IEEE模板以及遇到的问题和解决方案
latex_5_一篇IEEE模板以及遇到的问题和解决方案
模板链接:https://gitee.com/climb-the-wind/others/blob/master/IEEE-open-journal-template/IEEE-open-journal-template.zip,也可自行前往IEEE computer society 官网下载相应的模板
改动后的模板&am…

【大模型系列】图文对齐(CLIP/TinyCLIP/GLIP)
文章目录 1 CLIP(ICML2021,OpenAI)1.1 预训练阶段1.2 推理阶段1.3 CLIP的下游应用1.3.1 ViLD:zero-shot目标检测(2022, Google)1.3.2 图像检索Image Retrival1.3.3 HairCLIP:图像编辑Image Editing(2022,中科大) 2 TinyCLIP(2023,…

论文精读 —— Invisible Backdoor Attack with Sample-Specific Triggers
文章目录 带有样本特定触发器的隐形后门攻击论文信息论文贡献理解性翻译摘要1. 引言2. 相关工作2.1. 后门攻击2.2. 后门防御 3. 深入了解现有防御4. 样本特定的后门攻击(SSBA)4.1. 威胁模型4.2. 提出的攻击如何生成样本特定的触发器样本特定的后门攻击流…

DragGAN论文阅读
文章目录 摘要问题3. 算法:3.1 基于点的交互式操作3.2 运动监督3.3 点跟踪 4. 实验4.1 质量评估4.2 量化评估4.3 讨论 结论 论文:
《Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold》 github:
htt…

DETR 系列有了新发现?DETRs with Hybrid Matching 论文阅读笔记
DETR 系列有了新发现?DETRs with Hybrid Matching 论文阅读笔记 一、Abstract二、引言三、相关工作目标检测中的 DETR其它视觉任务中的 DETR标签赋值 四、方法4.1 基础知识通用的 DETR 框架通用的可变形 Deformable-DETR 框架 4.2 混合匹配4.2.1 混合分支计划一对一…
Adapter Tuning Overview:在CV,NLP,多模态领域的代表性工作
文章目录 Delta TuningAdapter Tuning in CVAdapter Tuning in NLP Delta Tuning Adapter Tuning in CV
题目: Learning multiple visual domains with residual adapters 机构:牛津VGG组 论文: https://arxiv.org/pdf/1705.08045.pdf
Adapter Tuning in NLP
…
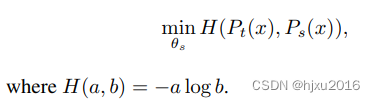
【自监督论文阅读 3】DINOv1
文章目录 一、摘要二、引言三、相关工作3.1 自监督学习3.2 自训练与知识蒸馏 四、方法4.1 SSL with Knowledge Distillation4.2 教师网络4.3 网络架构4.4 避免坍塌 五、实验与评估六、消融实验6.1 不同组合的重要性6.2 教师网络选择的影响6.3 避免坍塌6.4 在小batch上训练 七、…
跨模态检索2023年最新顶会论文汇总
本文主要汇总了几篇跨模态检索2023年最新顶会论文。
Efficient Token-Guided Image-Text Retrieval with Consistent Multimodal Contrastive Training https://arxiv.org/abs/2306.08789 利用一致的多模态对比训练进行高效的标记引导的图像-文本检索 Code is publicly availa…

RIS 系列:TransVG: End-to-End Visual Grounding with Transformers 论文阅读笔记
RIS 系列:TransVG: End-to-End Visual Grounding with Transformers 论文阅读笔记 一、Abstract二、引言三、相关工作3.1 视觉定位两阶段方法单阶段方法 3.2 Transformer视觉任务中的 Transformer视觉-语言任务中的 Transformer 四、视觉定位中的 Transformer4.1 基…
细粒度分类:WS-DAN论文笔记
细粒度分类:WS-DAN论文笔记——See Better Before Looking Closer: Weakly Supervised Data Augmentation Network for Fine-Grained Visual Classification 综述主要思想重要模块双线性注意力池化注意力正则化基于注意力引导的数据增广注意力裁剪注意力下降物体定位以及细化训…

【音视频第12天】GCC论文阅读(3)
A Google Congestion Control Algorithm for Real-Time Communication draft-alvestrand-rmcat-congestion-03论文理解 看中文的GCC算法一脸懵。看一看英文版的,找一找感觉。 目录Abstract1. Introduction1.1 Mathematical notation conventions2. System model2.1 …
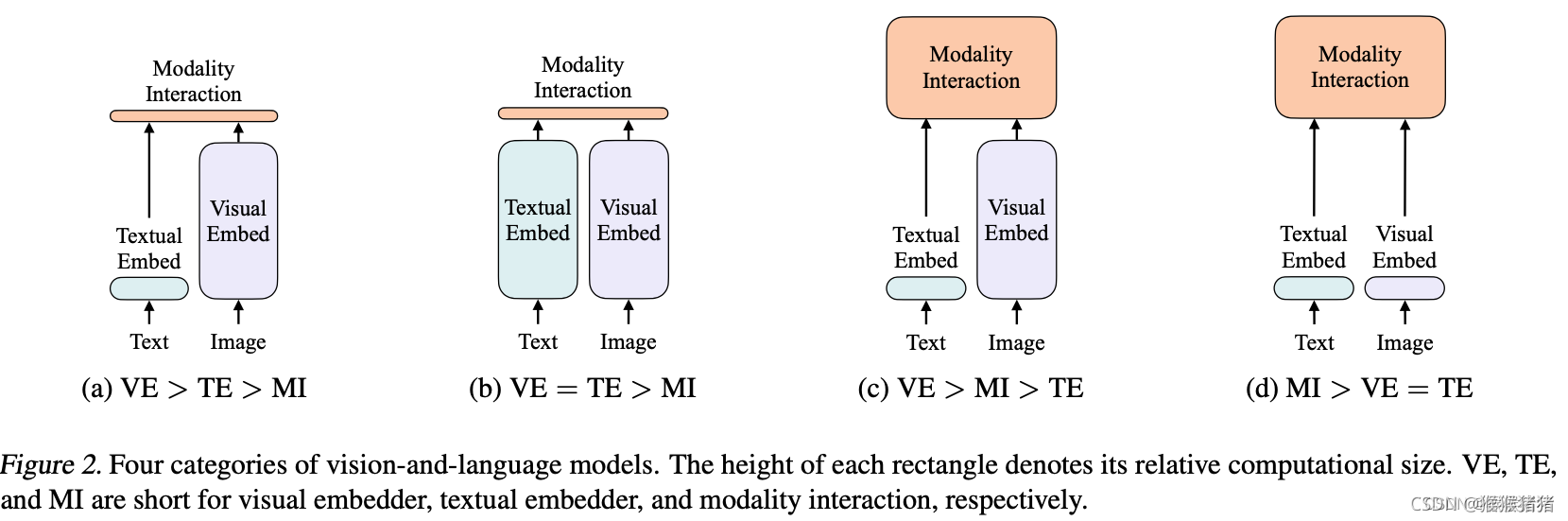
多模态之论文笔记ViLT
文章目录ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision一. 简介1.1 摘要1.2 文本编码器,图像编码器,特征交互复杂度分析1.2 特征交互方式分析1.3 图像特征提取分析二. 方法 Vision-and-Language Transformer2.1. 方…
【论文阅读笔记|ACL2022】Legal Judgment Prediction via Event Extraction with Constraints
论文题目:Legal Judgment Prediction via Event Extraction with Constraints
论文来源:ACL2022
论文链接:https://aclanthology.org/2022.acl-long.48.pdf
代码链接:GitHub - WAPAY/EPM
0 摘要
近年来,虽然法律判…

【论文阅读】You Are What You Do:通过数据来源分析寻找隐蔽的恶意软件
You Are What You Do: Hunting Stealthy Malware via Data Provenance Analysis NDSS-2020 伊利诺伊大学香槟分校、德克萨斯大学达拉斯分校 Wang Q, Hassan W U, Li D, et al. You Are What You Do: Hunting Stealthy Malware via Data Provenance Analysis[C]//NDSS. 2020. 目…
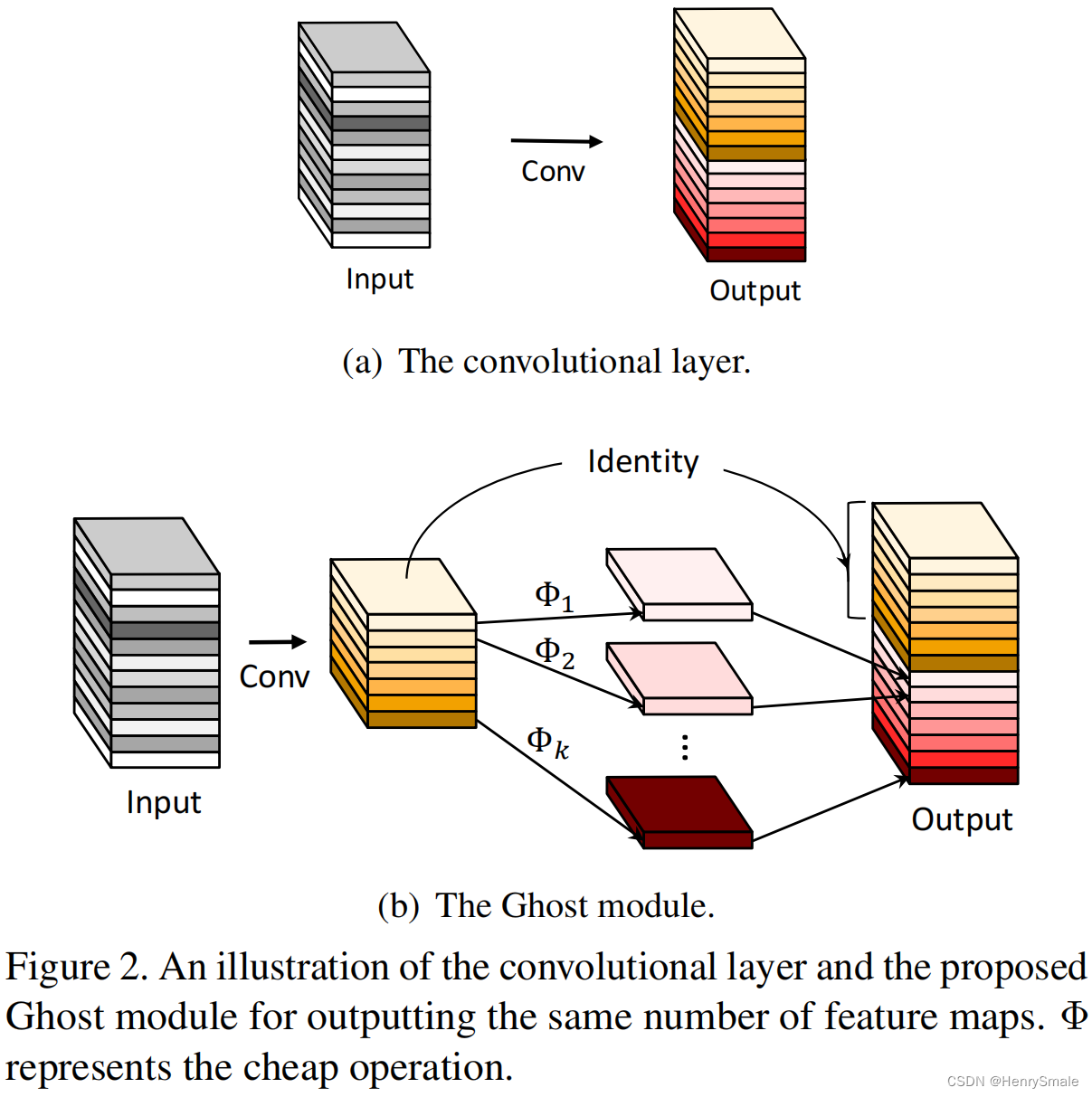
论文笔记:GhostNet: More Features from Cheap Operations
1 论文简介
论文:GhostNet: More Features from Cheap Operations(华为诺亚团队) 源代码:https://github.com/huawei-noah/ghostnet
2 动机
由于内存和计算资源的限制,在嵌入式设备上部署卷积神经网络非常困难。 本…
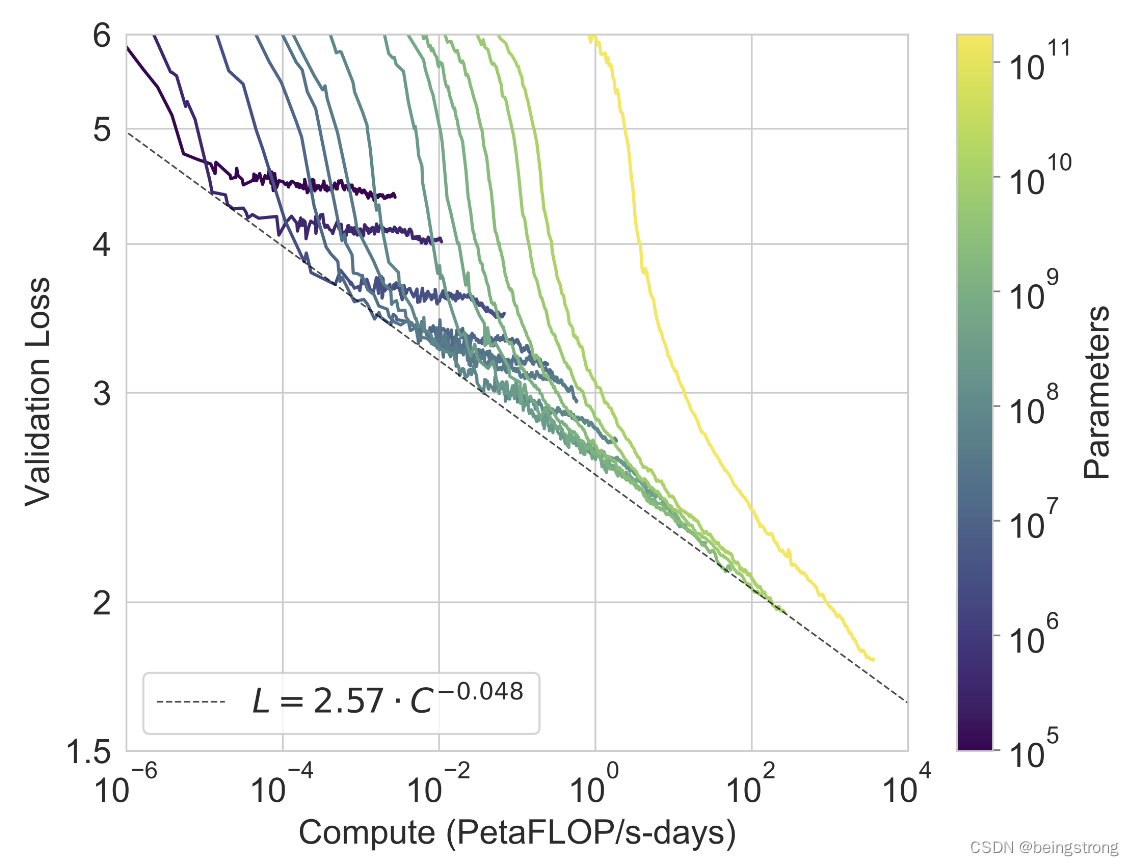
GPT-3 论文阅读笔记
GPT-3模型出自论文《Language Models are Few-Shot Learners》是OpenAI在2020年5月发布的。
论文摘要翻译:最近的工作表明,通过对大量文本进行预训练,然后对特定任务进行微调(fine-tuning),在许多NLP任务和基准测试上…
如何实现电子合同管理系统与其他企业应用的无缝对接?
电子合同管理系统是一种利用信息技术来管理和执行合同的系统。随着企业数字化转型的推进,电子合同管理系统已经成为许多企业必备的工具之一。然而,要实现电子合同管理系统与其他企业应用的无缝对接,并不是一件容易的事情。
实现电子合同管理…

图像生成论文阅读:GLIDE算法笔记
标题:GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models 会议:ICML2022 论文地址:https://proceedings.mlr.press/v162/nichol22a.html 官方代码:https://github.com/openai/glide-…
【论文阅读】RadarNet: Exploiting Radar for Robust Perception of Dynamic Objects
目录 RadarNet: Exploiting Radar for Robust Perception of Dynamic ObjectsAbstract1 Introduction2 Related Work3 Review of LiDAR and Radar Sensors4 Exploiting LiDAR and Radar for Robust Perception4.1 Exploiting Geometric Information via Early Fusion4.2 Detect…
【论文阅读】swin transformer阅读笔记
在vit以后证明了transformer在视觉任务中的一系列表现
video swin transformer在视频上很好的效果
swin MLP
自监督
掩码自监督
效果很炸裂
swin transformer成了视觉领域一个绕不开的baseline
题目
层级式移动窗口
层级式的特征提取,特征有多尺度的概念
…
【论文笔记】Cross Modal Transformer: Towards Fast and Robust 3D Object Detection
原文链接:https://arxiv.org/abs/2301.01283
1. 引言 受到DETR启发,本文提出鲁棒的端到端多模态3D目标检测方法CMT(跨模态Transformer)。首先使用坐标编码模块(CEM),通过将3D点集隐式地编码为多…
TartanVO: A Generalizable Learning-based VO 论文阅读
论文信息
题目:TartanVO: A Generalizable Learning-based VO 作者:Wenshan Wang, Yaoyu Hu 来源:ICRL 时间:2021 代码地址:https://github.com/castacks/tartanvo
Abstract
我们提出了第一个基于学习的视觉里程计&…
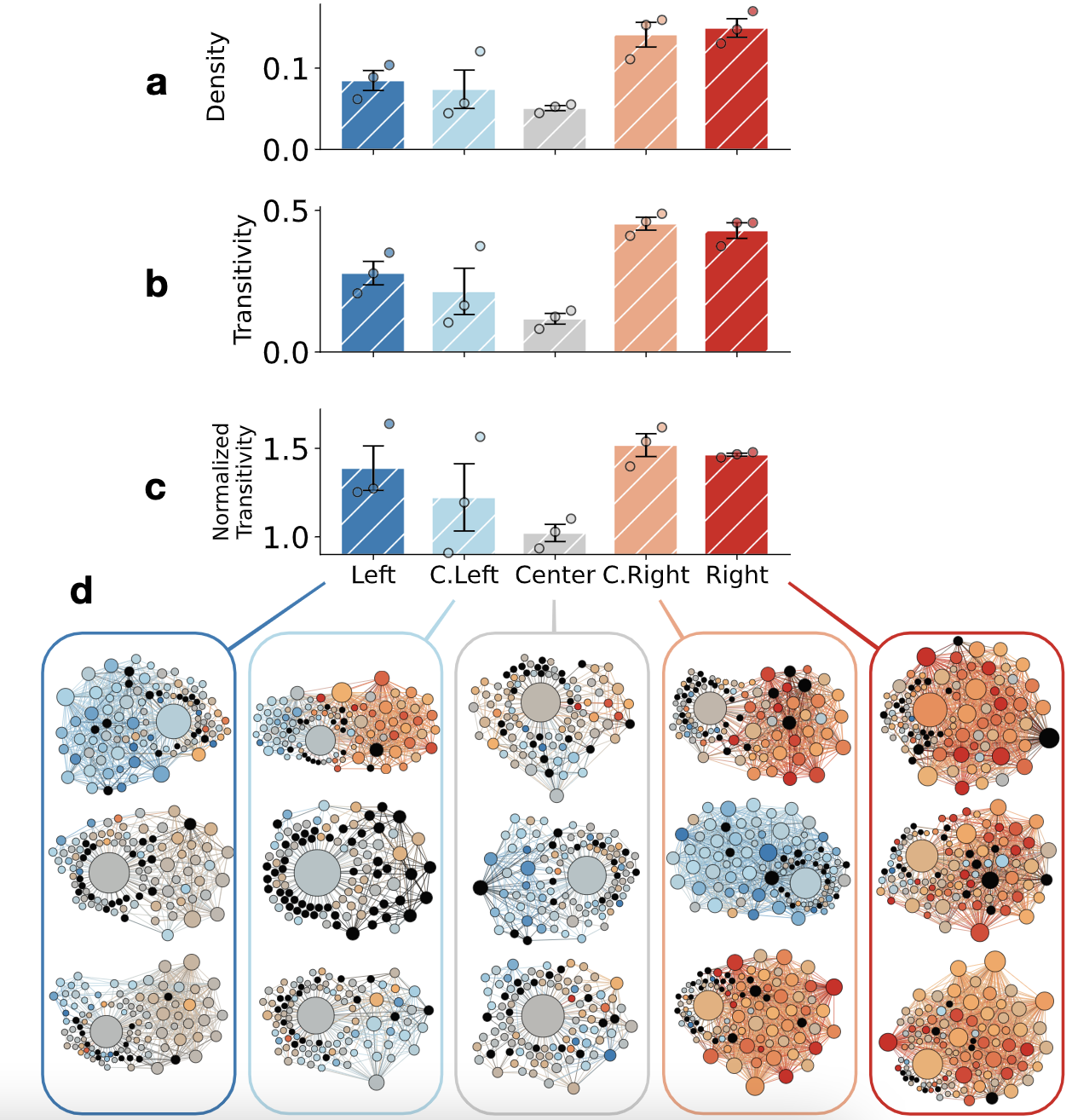
论文阅读 - Neutral bots probe political bias on social media
论文链接:Neutral bots probe political bias on social media | EndNote Click 试图遏制滥用行为和错误信息的社交媒体平台被指责存在政治偏见。我们部署中立的社交机器人,它们开始关注 Twitter 上的不同新闻源,并跟踪它们以探究平台机制与用…
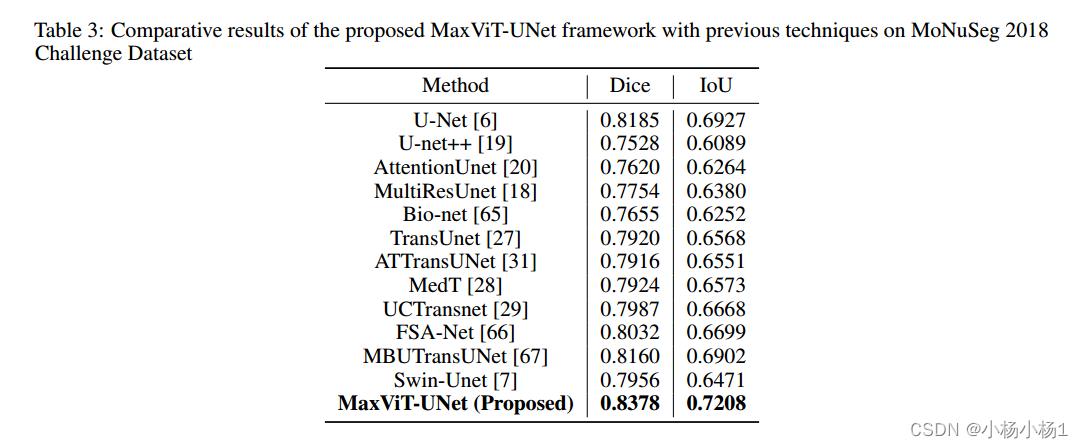

【论文阅读】DEPCOMM:用于攻击调查的系统审核日志的图摘要(SP-2022)
Xu Z, Fang P, Liu C, et al. Depcomm: Graph summarization on system audit logs for attack investigation[C]//2022 IEEE Symposium on Security and Privacy (SP). IEEE, 2022: 540-557. 1 摘要
提出了 DEPCOMM,这是一种图摘要方法,通过将大图划…

【论文阅读】基于深度学习的时序预测——Crossformer
系列文章链接 论文一:2020 Informer:长时序数据预测 论文二:2021 Autoformer:长序列数据预测 论文三:2022 FEDformer:长序列数据预测 论文四:2022 Non-Stationary Transformers:非平…

【论文阅读】基于深度学习的时序预测——Pyraformer
系列文章链接 论文一:2020 Informer:长时序数据预测 论文二:2021 Autoformer:长序列数据预测 论文三:2022 FEDformer:长序列数据预测 论文四:2022 Non-Stationary Transformers:非平…
私域流量宝工具源码搭建-含详细使用说明
👋私域流量宝致力于为个人、团队提供基于微信私域流量的推广、引流的效率工具。可减轻人力,有效降低资源损失、流量流失的几率。引流宝完全开源,免费,可商用、可任意二次开发。引流宝可以辅助你更好地开展营销活动推广!…

论文阅读-DGM4-Detecting and Grounding Multi-Modal Media Manipulation
一、论文信息
论文名称:Detecting and Grounding Multi-Modal Media Manipulation
作者团队:南洋理工哈工大 Github:https://github.com/rshaojimmy/MultiModal-DeepFake 项目主页:https://rshaojimmy.github.io/Projects/MultiModal-DeepF…
《论文阅读》常识推理的生成知识提示
《论文阅读》常识推理的生成知识提示 前言简介相关知识模型构架Generated Knowledge PromptingKnowledge GenerationKnowledge Integration via Prompting推理阶段前言
你是否也对于理解论文存在困惑?
你是否也像我之前搜索论文解读,得到只是中文翻译的解读后感到失望?
小…
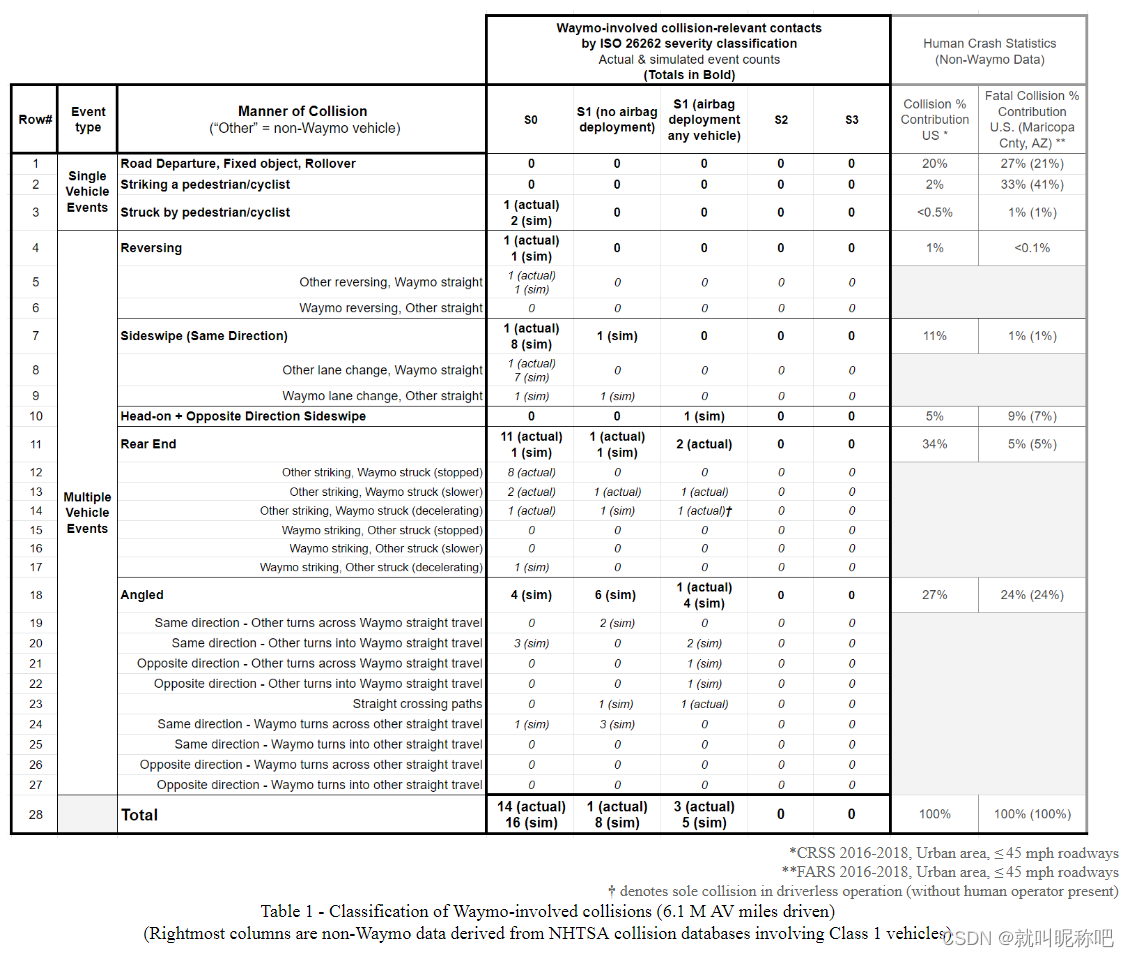
论文阅读:《Waymo Public Road Safety Performance Data》
文章目录 1 背景2 方法2.1 数据来源2.2 碰撞数据 3 碰撞事件分析4 讨论 1 背景 这篇文章是讲waymo道路安全性能数据分析的,主要想表达的是waymo自动驾驶系统在安全上面的出色表现,以向政府、大众提高自己产品的公信力。 这篇文章分析的数据是自从2019年到…

《论文阅读12》RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds
一、论文
研究领域:全监督3D语义分割(室内,室外RGB,kitti)论文:RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds CVPR 2020 牛津大学、中山大学、国防科技大学 论文链接论文gi…

论文阅读:DIN-SQL: Decomposed In-Context Learning of Text-to-SQL withSelf-Correction
NL2SQL是将自然语言转化为SQL的任务,该任务隶属于NLP的子任务,NL2SQL在AIGC时代之前,以seq2seq、BERT等系列的模型在NL2SQL的主流数据集上取得了不错的效果,2022年底,ChatGPT爆火,凭借LLM强大的逻辑推理、上…
【论文阅读】基于深度学习的时序预测——LTSF-Linear
系列文章链接 论文一:2020 Informer:长时序数据预测 论文二:2021 Autoformer:长序列数据预测 论文三:2022 FEDformer:长序列数据预测 论文四:2022 Non-Stationary Transformers:非平…
论文笔记--LIMA: Less Is More for Alignment
论文笔记--LIMA: Less Is More for Alignment 1. 文章简介2. 文章概括3 文章重点技术3.1 表面对齐假设(Superfacial Alignment Hypothesis)3.2 对齐数据3.3 训练 4 数值实验5. 文章亮点5. 原文传送门6. References 1. 文章简介
标题:LIMA: Less Is More for Alignm…
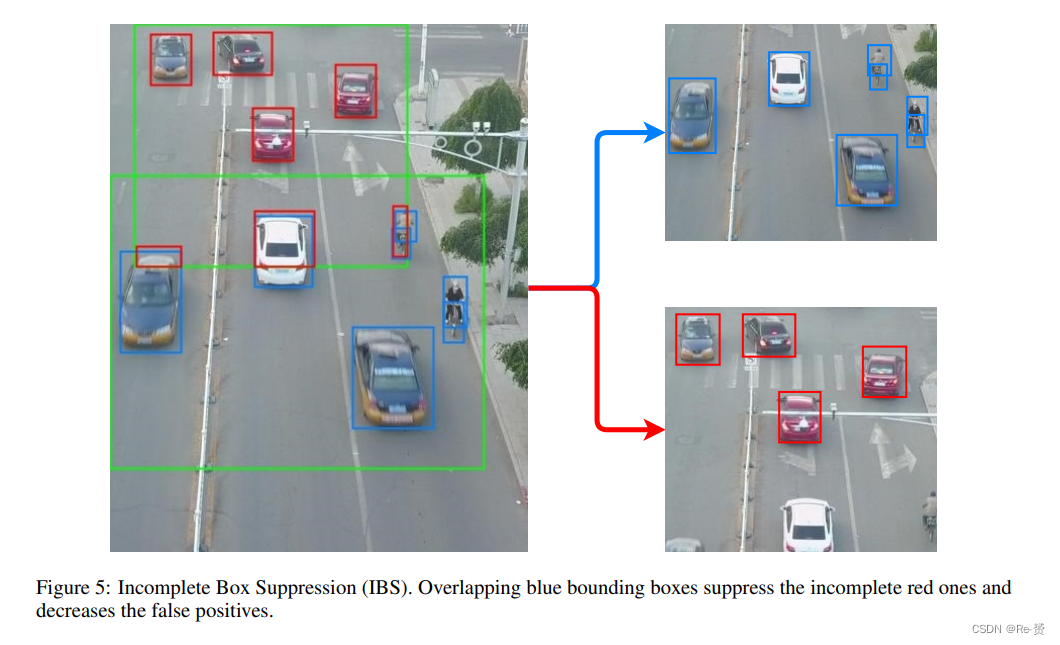
论文阅读 FOCUS-AND-DETECT: A SMALL OBJECT DETECTION FRAMEWORK FOR AERIAL IMAGES
文章目录 FOCUS-AND-DETECT: A SMALL OBJECT DETECTION FRAMEWORK FOR AERIAL IMAGESABSTRACT1 Introduction2 Related Work3 Focus-and-Detect3.1 Overview3.2 Focus Stage3.2.1 Generating Ground-Truth Boxes of Focal Regions Using Gaussian Mixture Model 3.3 Detection …

论文阅读_条件控制_ControlNet
name_en: Adding Conditional Control to Text-to-Image Diffusion Models name_ch: 向文本到图像的扩散模型添加条件控制 paper_addr: http://arxiv.org/abs/2302.05543 date_read: 2023-08-17 date_publish: 2023-02-10 tags: [‘图形图像’,‘大模型’,‘多模态’] author: …
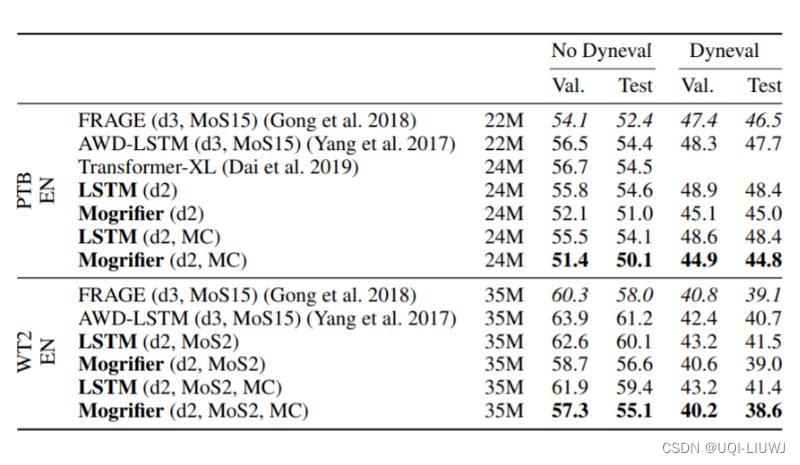
论文笔记: MOGRIFIER LSTM
2020 ICLR
修改传统LSTM 当前输入和隐藏状态充分交互,从而获得更佳的上下文相关表达
1 Mogrifier LSTM
LSTM的输入X和隐藏状态H是完全独立的 机器学习笔记:GRU_gruc_UQI-LIUWJ的博客-CSDN博客这篇论文想探索,如果在输入LSTM之前…
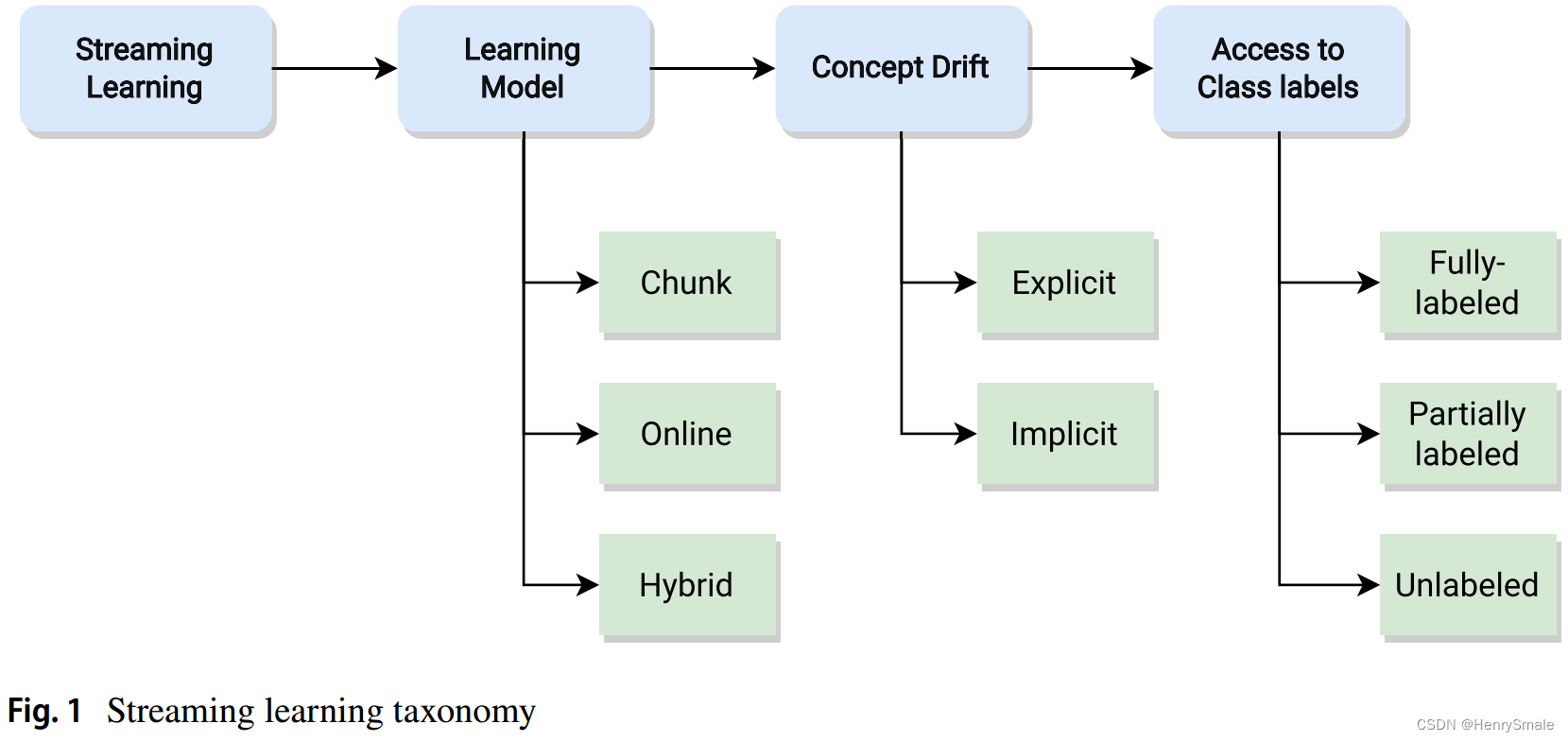
论文笔记:从不平衡数据流中学习的综述: 分类、挑战、实证研究和可重复的实验框架
0 摘要
论文:A survey on learning from imbalanced data streams: taxonomy, challenges, empirical study, and reproducible experimental framework 发表:2023年发表在Machine Learning上。 源代码:https://github.com/canoalberto/imba…

【论文阅读】POIROT:关联攻击行为与内核审计记录以寻找网络威胁(CCS-2019)
POIROT: Aligning Attack Behavior with Kernel Audit Records for Cyber Threat Hunting CCS-2019 伊利诺伊大学芝加哥分校、密歇根大学迪尔伯恩分校 Milajerdi S M, Eshete B, Gjomemo R, et al. Poirot: Aligning attack behavior with kernel audit records for cyber thre…
细粒度分类:Cross-X论文笔记——Cross-X Learning for Fine-Grained Visual Categorization
细粒度分类:Cross-X论文笔记——Cross-X Learning for Fine-Grained Visual Categorization 综述主要思想网络结构OSME模块C3S正则化器CL正则化器损失优化实验可视化分析精度对比总结综述 论文题目:《Cross-X Learning for Fine-Grained Visual Categorization》 会议时间:I…
【论文笔记】Fast Segment Anything
我说个数:一个月5篇基于Fast Segment Anything的改进的论文就会出现哈哈哈哈。
1.介绍
1.1 挑战
SAM架构的主要部分Transformer(ViT)模型相关的大量计算资源需求,这给其实际部署带来了障碍
1.2 任务解耦
将分段任意任务解耦为…
【论文阅读】Dynamic Split Computing for Efficient Deep Edge Intelligence
论文信息
作者:Arian Bakhtiarnia, Nemanja Milošević, Qi Zhang, Dragana Bajović, Alexandros Iosifidis
发表会议: ICML 2022 DyNN WorkshopICASSP 2023发表单位:
∗DIGIT, Department of Electrical and Computer Engineering, Aarhus University, Denmark.
†Fa…
如何将国标规范用EndNote插入到英文期刊中,自定义文献插入指南
EndNote自定义文献 1.插入国标JTG 2034-2020这种新建一个StandardReference填入信息参考 插入英文期刊规范ASTM 1.插入国标JTG 2034-2020这种
首先找到大家要投稿的英文期刊,然后去找那些中…
【论文阅读】Self-supervised Image-specific Prototype Exploration for WSSS
一篇CVPR2022上的论文,用于弱监督分割
论文标题:
Self-supervised Image-specific Prototype Exploration for Weakly Supervised Semantic Segmentation
作者信息: 代码地址:
https://github.com/chenqi1126/SIPE
论文链接&…

关于credal set和credal decision tree的一点思考(其实就是论文笔记)
阅读Abelln老师的Credal-C4.5时,发现好难。。。然后又额外补充了一些论文,终于稍微懂一点点了,所以记录如下。
credal set在DS theory的定义如下 [1]: 这句话的意思是(证据理论中的)credal set是一个概率…
【CCF计算领域学术会议介绍:2024日程安排、CCF会议deadline汇总、2022年录用率】
CCF计算领域学术会议介绍:2024日程安排、CCF会议deadline汇总、2022年录用率
0、目录
1、2024日程安排及deadline汇总2、会议介绍及2022年录用率
1、2024日程安排及deadline汇总 1、Conference List
这个网站汇总了CCF学术会议2023及即将开启的2024学术会议&…
【论文阅读笔记】Analyzing Federated Learning through an Adversarial Lens
个人阅读笔记,如有错误欢迎指出
ICML 2019 [1811.12470] Analyzing Federated Learning through an Adversarial Lens (arxiv.org)
问题: 传统模型攻击容易被服务器通过精度检测以及权重分析检测出来,本文意在找到一种投毒方法绕过服…

Super Resolve Dynamic Scene from Continuous Spike Streams论文笔记
摘要
近期,脉冲相机在记录高动态场景中展示了其优越的潜力。不像传统相机将一个曝光时间内的视觉信息进行压缩成像,脉冲相机连续地输出二的脉冲流来记录动态场景,因此拥有极高的时间分辨率。而现有的脉冲相机重建方法主要集中在重建和脉冲相…

论文阅读_扩散模型_DM
英文名称: Deep Unsupervised Learning using Nonequilibrium Thermodynamics 中文名称: 使用非平衡热力学原理的深度无监督学习 论文地址: http://arxiv.org/abs/1503.03585 代码地址: https://github.com/Sohl-Dickstein/Diffusion-Probabilistic-Models 时间: 2015-11-18 作…

论文阅读《Nougat:Neural Optical Understanding for Academic Documents》
摘要
科学知识主要存储在书籍和科学期刊中,通常以PDF的形式。然而PDF格式会导致语义信息的损失,特别是对于数学表达式。我们提出了Nougat,这是一种视觉transformer模型,它执行OCR任务,用于将科学文档处理成标记语言&a…
MRI多任务技术及应用
目录 一、定量心血管磁共振成像(CMR)的改进方法二、磁共振多任务三、磁共振多任务的成像框架四、磁共振多任务的图像模型和采样和重建策略五、利用MR多任务进行快速三维稳态CEST(ss-CEST)成像5.1 利用MR多任务进行快速三维稳态CEST(ss-CEST)成像介绍5.2 …

《Communicative Agents for Software Development》全文翻译
《Communicative Agents for Software Development》- 沟通性智能主体促进软件开发 论文信息Abstract1. Introduction2. CHATDEV2.1 聊天链2.2 设计2.3 编码2.4 测试2.5 记录 3. 实验4. 讨论5. 相关工作6. 结论 论文信息
题目:《Communicative Agents for Software…
论文阅读——Co-Salient Object Detection with Co-Representation Purification
目录 基本信息标题摘要引言方法PCSRPP 实验 基本信息
期刊IEEE TPAMI年份2023论文地址https://arxiv.org/pdf/2303.07670.pdf代码地址https://github.com/ZZY816/CoRP
标题
具有共同表示净化的共同显著目标检测
摘要
共同显著目标检测(Co-SOD)旨在发…
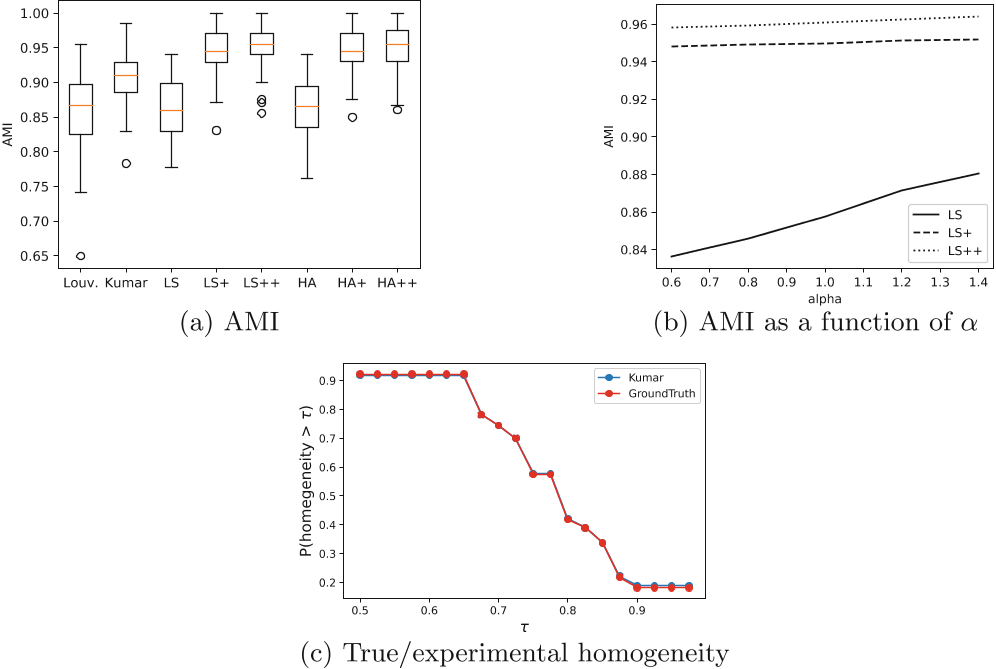
超图聚类论文阅读2:Last-step算法
超图聚类论文阅读2:Last-step算法 《使用超图模块化的社区检测算法》 《Community Detection Algorithm Using Hypergraph Modularity》 COMPLEX NETWORKS 2021, SCI 3区 具体实现源码见HyperNetX库 工作:提出了一种用于超图的社区检测算法。该算法的主要…

Llama 2 论文《Llama 2: Open Foundation and Fine-Tuned Chat Models》阅读笔记
文章目录 Llama 2: Open Foundation and Fine-Tuned Chat Models1.简介2.预训练2.1 预训练数据2.2 训练详情2.3 LLAMA 2 预训练模型评估 3. 微调3.1 supervised Fine-Tuning(SFT)3.2 Reinforcement Learning with Human Feedback (RLHF)3.2.1 人类偏好数据收集3.2.2 奖励模型训…
[论文笔记]BiMPM
引言
这又是一篇文本匹配的论文Bilateral Multi-Perspective Matching for Natural Language Sentences阅读笔记。
论文题目为自然语言文本中双向多视角匹配。
提出了BiMPM(bilateral multi-perspective matching)模型: 基于匹配-聚合(比较-聚合)框架; 采用双向匹配提取交…
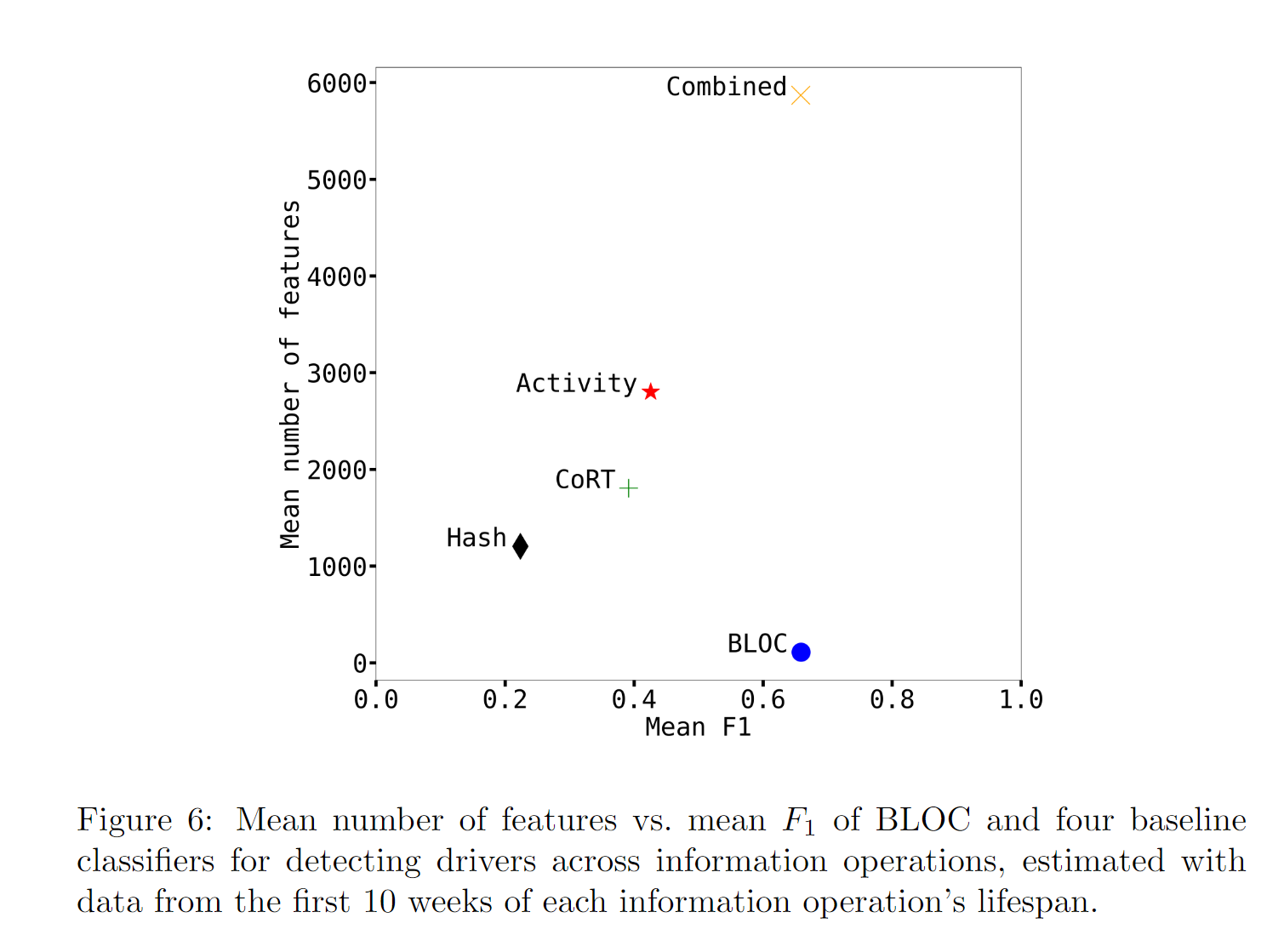
论文阅读-A General Language for Modeling Social Media Account Behavior
论文链接:https://arxiv.org/pdf/2211.00639v1.pdf
目录
摘要
1 Introduction
2 Related work
2.1 Automation
2.2 Coordination
3 Behavioral Language for Online Classification 3.1 BLOC alphabets
3.1.1 Action alphabet
3.1.2 Content alphabets
3.…

论文阅读——Adversarial Eigen Attack on Black-Box Models
Adversarial Eigen Attack on Black-Box Models
作者:Linjun Zhou, Linjun Zhou
攻击类别:黑盒(基于梯度信息),白盒模型的预训练模型可获得,但训练数据和微调预训练模型的数据不可得ÿ…
[论文笔记]Layer Normalization
引言
这是论文神作Layer Normalization的阅读笔记。训练深层神经网络是昂贵的,减少训练时间的一种方法是归一化神经元的激活。
批归一化(Batch normalization,BN)利用小批量的训练样本中神经元累加输入的分布来计算均值和方差,然后用这些统计量来对每个训练样本中神经元的累…
论文笔记: 循环神经网络进行速度模型反演 (未完)
摘要: 分享对论文的理解, 原文见 Gabriel Fabien-Ouellet and Rahul Sarkar, Seismic velocity estimation: A deep recurrent neural-network approach. Geophysics (2020) U21–U29. 作者应该是领域专家, 对地球科学的理解胜于深度学习. 为方便讨论, 等式编号保持与原文一致.…

论文阅读_扩散模型_SDXL
英文名称: SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis 中文名称: SDXL:改进潜在扩散模型的高分辨率图像合成 论文地址: http://arxiv.org/abs/2307.01952 代码: https://github.com/Stability-AI/generative-models 时间: 2023-…
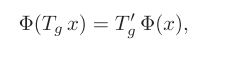
《论文阅读21》Group Equivariant Convolutional Networks
一、论文
研究领域:机器学习论文:Group Equivariant Convolutional Networks PMLR Proceedings of Machine Learning Research 2016 论文链接 二、论文简述 三、论文详述
群等变卷积网络
Abstract
我们引入群等变卷积神经网络(G-CNN&…

大模型综述论文笔记6-15
这里写自定义目录标题 KeywordsBackgroud for LLMsTechnical Evolution of GPT-series ModelsResearch of OpenAI on LLMs can be roughly divided into the following stagesEarly ExplorationsCapacity LeapCapacity EnhancementThe Milestones of Language Models Resources…

Toolformer:可以教会自己使用工具的语言模型
Toolformer:可以教会自己使用工具的语言模型 摘要Introduction现有大模型的局限处理办法本文的idea Approach样例化API调用执行API调用筛选API调用模型微调 实验局限 论文地址点这里
摘要
语言模型(LMs)呈现了令人深刻的仅使用少量的范例或…

Deformable DETR(2020 ICLR)
Deformable DETR(2020 ICLR)
detr训练epochs缩小十倍,小目标性能更好
Deformable attention 结合变形卷积的稀疏空间采样和Transformer的关系建模能力 使用多层级特征层特征,不需要使用FPN的设计(直接使用backbone多层级输出&a…
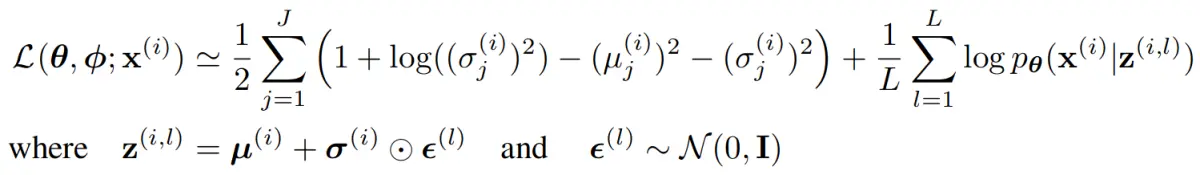
论文阅读_变分自编码器_VAE
英文名称: Auto-Encoding Variational Bayes 中文名称: 自编码变分贝叶斯 论文地址: http://arxiv.org/abs/1312.6114 时间: 2013 作者: Diederik P. Kingma, 阿姆斯特丹大学 引用量: 24840
1 读后感
VAE 变分自编码(Variational Autoencoder)是一种生…
DPVO服务器端复现
配置环境
代码地址:https://github.com/princeton-vl/DPVO
1.下载代码
git clone https://github.com/princeton-vl/DPVO.git --recursive
cd DPVO2.创建环境
conda env create -f environment.yml
conda activate dpvo3.安装DPVO包
wget https://gitlab.com/l…
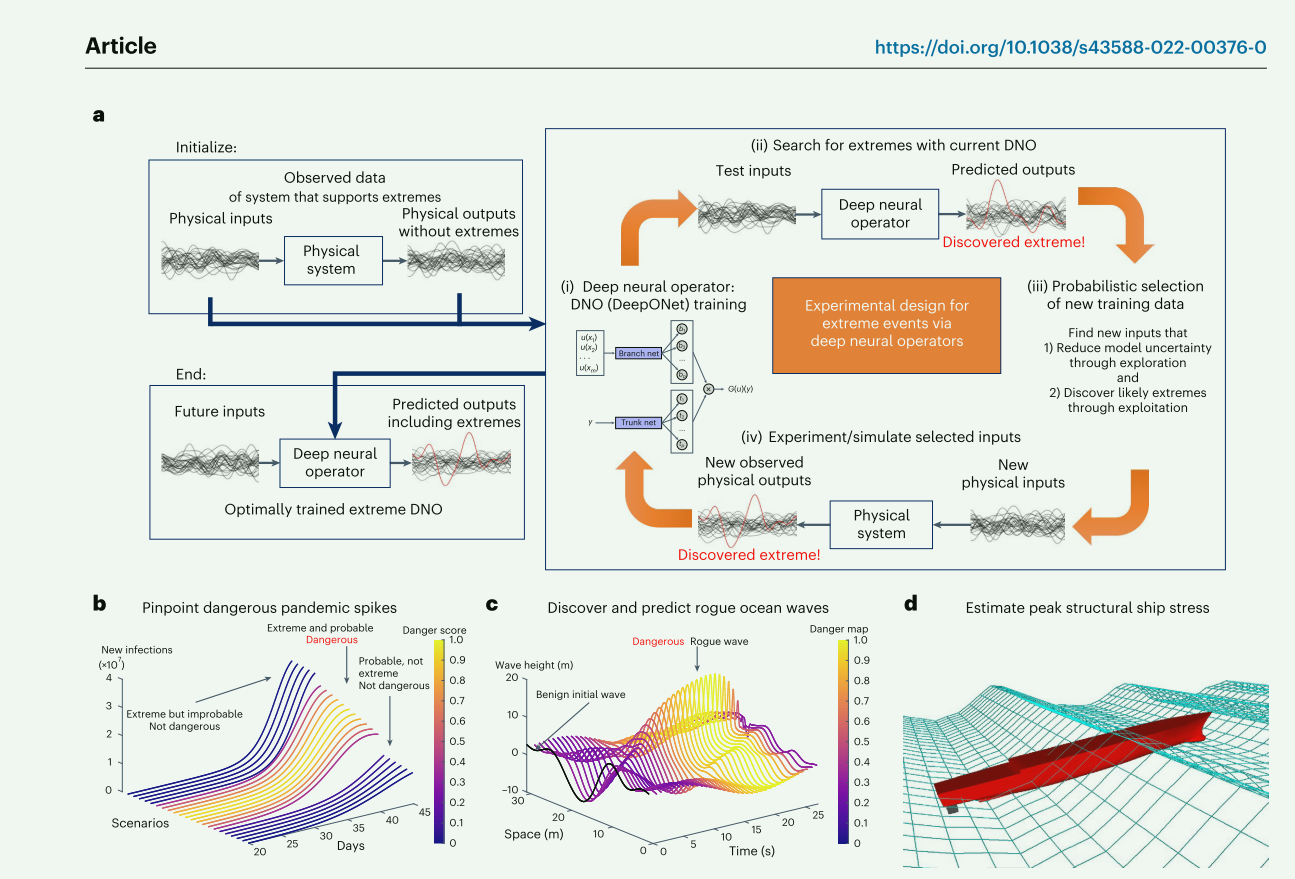
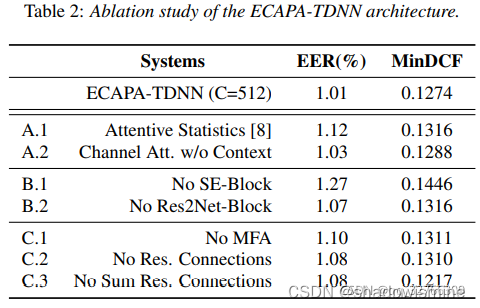
论文阅读:ECAPA-TDNN
1. 提出ECAPA-TDNN架构
TDNN本质上是1维卷积,而且常常是1维膨胀卷积,这样的一种结构非常注重context,也就是上下文信息,具体而言,是在frame-level的变换中,更多地利用相邻frame的信息,甚至跳过…
《论文阅读》用提示和复述模拟对话情绪识别的思维过程 IJCAI 2023
《论文阅读》用提示和复述模拟对话情绪识别的思维过程 IJCAI 2023 前言简介相关知识prompt engineeringparaphrasing模型架构第一阶段第二阶段History-oriented promptExperience-oriented Prompt ConstructionLabel Paraphrasing损失函数前言
你是否也对于理解论文存在困惑?…

X2-VLM: All-In-One Pre-trained Model For Vision-Language Tasks论文笔记
Title:X2-VLM: All-In-One Pre-trained Model For Vision-Language Tasks
Code
1. Motivation CLIP这一类方法只能进行图片级别的视觉和文本对齐;也有一些方法利用预训练的目标检测器进行目标级别的视觉和文本对齐,但是只能编码目标内部的特…
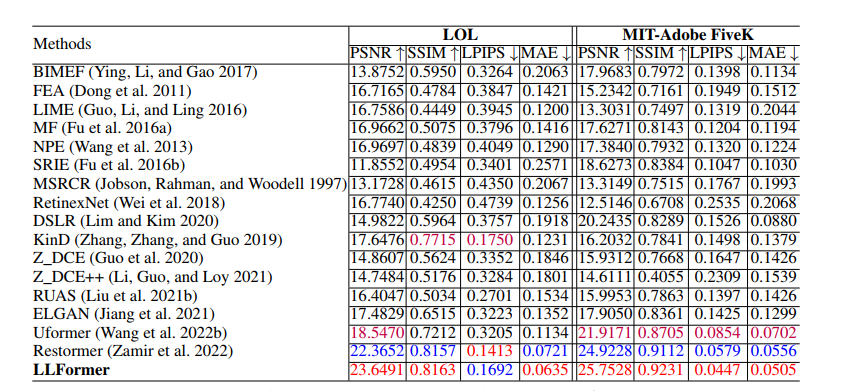
LLFormer 论文阅读笔记
Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method 这是南京大学在AAAI 2023发表的一篇AAAI2023 超高清图像暗图增强的工作。提出了一个超高清暗图增强数据集,提供了4K和8K的图片,同时提出了一个可用于暗图…
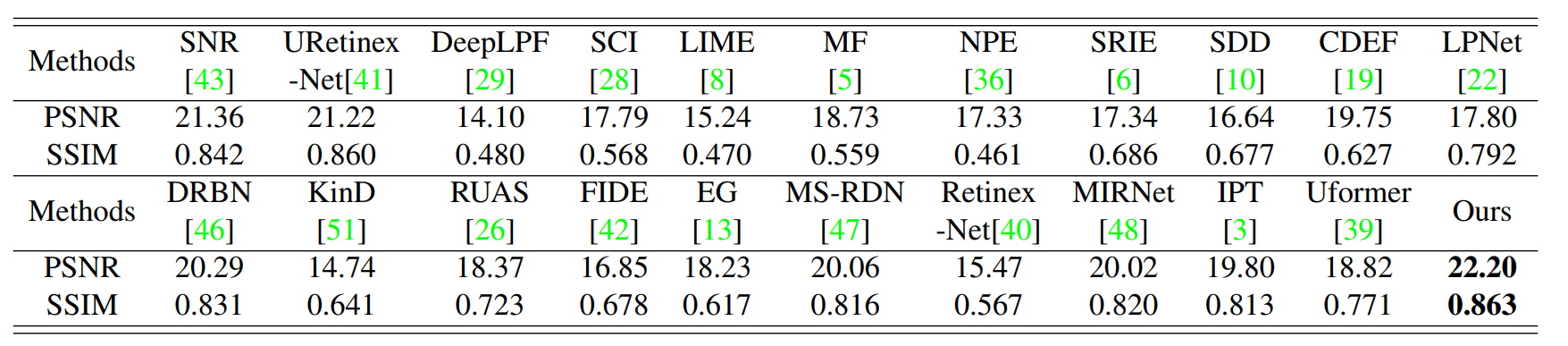
COMO-ViT论文阅读笔记
Low-Light Image Enhancement with Illumination-Aware Gamma Correction and Complete Image Modelling Network 这是一篇美团、旷视、深先院、华为诺亚方舟实验室、中国电子科技大学 五个单位合作的ICCV2023的暗图增强论文,不过没有开源代码。 文章的贡献点一个是…
论文阅读之Learning and Generalization of Motor Skills by Learning from Demonstration
0、论文基本信息
DMP经典论文 论文题目:Learning and Generalization of Motor Skills by Learning from Demonstration 会议名称:2009 ICRA 论文作者:Peter Pastor, Heiko Hoffmann, Tamin Asfour and Stefan Schaal
作者简介:…
论文阅读 Self-Mimic Learning for Small-scale Pedestrian Detection
Self-Mimic Learning for Small-scale Pedestrian Detection
ABSTRACT
检测小尺度行人是行人检测中最具挑战性的问题之一。由于缺乏视觉细节,小尺度行人的 representations 往往难以与背景杂乱物区分开。本文深入分析了小尺度行人检测问题,揭示了小尺度…

【论文阅读】MARS:用于自动驾驶的实例感知、模块化和现实模拟器
【论文阅读】MARS:用于自动驾驶的实例感知、模块化和现实模拟器 Abstract1 Introduction2 Method2.1 Scene Representation2.3 Towards Realistic Rendering2.4 Optimization3.1 Photorealistic Rendering3.2 Instance-wise Editing3.3 The blessing of moduler des…

OneFormer: One Transformer to Rule Universal Image Segmentation论文笔记
论文https://arxiv.org/pdf/2211.06220.pdfCodehttps://github.com/SHI-Labs/OneFormer 文章目录 1. Motivation2. 方法2.1 与Mask2Former的相同之处2.2 OneFormer创新之处2.3 Task Conditioned Joint Training2.4 Query Representations2.4 Task Guided Contrastive Queries 3…

Paper Reading: RSPrompter,基于视觉基础模型的遥感实例分割提示学习
目录 简介目标工作重点方法实验总结 简介
题目:《RSPrompter: Learning to Prompt for Remote Sensing Instance Segmentation based on Visual Foundation Model 》,基于视觉基础模型的遥感实例分割提示学习
日期:2023.6.28
单位…
![[论文阅读] SADGA: Structure-Aware Dual Graph Aggregation Network for Text-to-SQL](https://img-blog.csdnimg.cn/f224fb6c3b06424b9bc3cc0360bf13bc.png#pic_center)
[论文阅读] SADGA: Structure-Aware Dual Graph Aggregation Network for Text-to-SQL
“SADGA: Structure-Aware Dual Graph Aggregation Network for Text-to-SQL” 是一篇 text2sql 领域的论文,发布于 NeurIPS 2021。
原文链接:https://arxiv.org/abs/2111.00653 项目代码链接:https://github.com/DMIRLAB-Group/SADGA
总体…
![[论文阅读]Coordinate Attention for Efficient Mobile Network Design](https://img-blog.csdnimg.cn/7ea23dac66784e24a1ab286ea4a6a477.png)
[论文阅读]Coordinate Attention for Efficient Mobile Network Design
摘要 最近关于移动网络设计的研究已经证明了通道注意力(例如, the Squeeze-and-Excitation attention)对于提高模型的性能有显著的效果,但它们通常忽略了位置信息,而位置信息对于生成空间选择性注意图非常重要。在本文中,我们提出…
【论文笔记】Planning and Decision-Making for Autonomous Vehicles
文章目录 Summary1. INTRODUCTION2. MOTION PLANNING AND CONTROL2.1. Vehicle Dynamics and Control2.2. Parallel Autonomy2.3. Motion Planning for Autonomous Vehicles 3. INTEGRATED PERCEPTION AND PLANNING3.1. From Classical Perception to Current Challenges in Ne…

AI文章扩写:从1百字到1万字
人工智能(AI)作为一项前沿技术,正逐渐渗透到各个领域中。在写作领域,AI的应用已经取得了显著进展。本文将重点探讨如何利用人工智能扩写文章,为写作者提供一种快速、高效的创作辅助工具。 01
—
AI文章扩写原理 人工…

论文阅读:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
前言
要弄清MAML怎么做,为什么这么做,就要看懂这两张图。先说MAML**在做什么?**它是打着Mate-Learing的旗号干的是few-shot multi-task Learning的事情。具体而言就是想训练一个模型能够使用很少的新样本,快速适应新的任务。
定…

GODIVA论文阅读
论文链接:GODIVA: Generating Open-DomaIn Videos from nAtural Descriptions 文章目录 摘要引言相关工作Video-to-video generationText-to-image generationText-to-video generation GODIVA方法逐帧视频自动编码器GODIVA视频生成器 实验数据集评价指标自动评估指…
【论文阅读 08】Adaptive Anomaly Detection within Near-regular Milling Textures
2013年,太老了,先不看 比较老的一篇论文,近规则铣削纹理中的自适应异常检测
1 Abstract 在钢质量控制中的应用,我们提出了图像处理算法,用于无监督地检测隐藏在全局铣削模式内的异常。因此,我们考虑了基于…
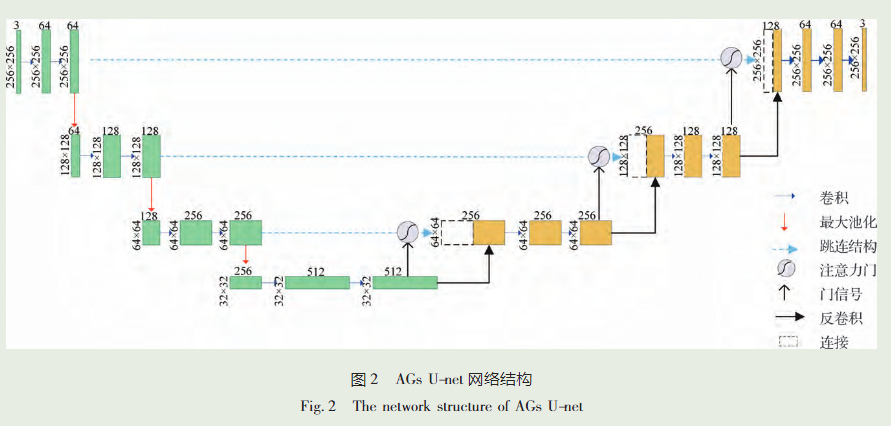
【论文阅读 09】融合门控自注意力机制的生成对抗网络视频异常检测
2021年 中国图象图形学报
摘 要
背景: 视频异常行为检测是智能监控技术的研究重点,广泛应用于社会安防领域。当前的挑战之一是如何提高异常检测的准确性,这需要有效地建模视频数据的空间维度和时间维度信息。生成对抗网络(GANs&…
论文阅读-Group-based Fraud Detection Network on e-Commerce Platforms
目录
摘要
1 Introduction
2 BACKGROUND AND RELATED WORK
2.1 Preliminaries
2.2 Related Works
3 MODEL
3.1 Structural Feature Initialization
3.2 Fraudster Community Detection 3.3 Training Objective
4 EXPERIMENT
4.1 Experimental Setup
4.2 Prediction …
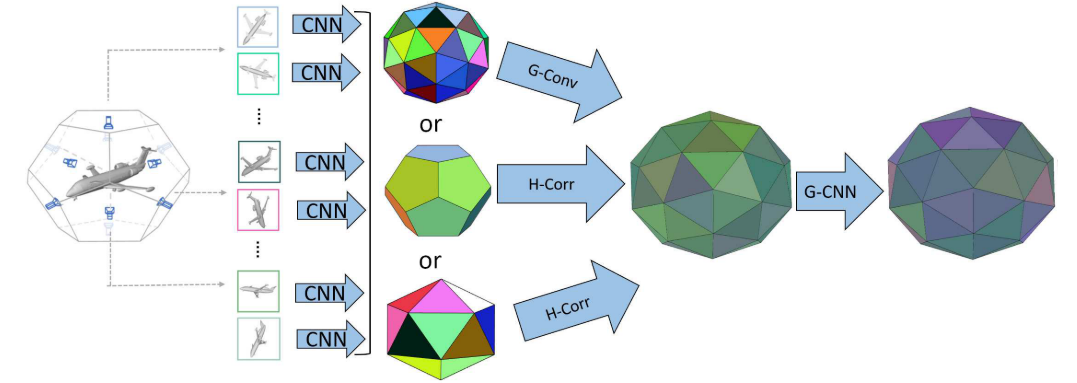
《论文阅读21》Equivariant Multi-View Networks
一、论文
研究领域:计算机视觉 | 多视角数据处理中实现等变性论文:Equivariant Multi-View Networks ICCV 2019 论文链接视频链接 二、论文简述
在计算机视觉中,模型在不同视角下对数据(例如,点云、图像等࿰…
看完100%会写毕业论文
写论文是每个学术研究者都要面对的任务之一,在开始写论文之前,准备工作是至关重要的。本文将介绍一些写论文准备工作的重要步骤,并且探讨如何利用AI写作大师辅助来提高写作效率和质量,让你看完100%会写毕业论文。 01
—
了解论文…
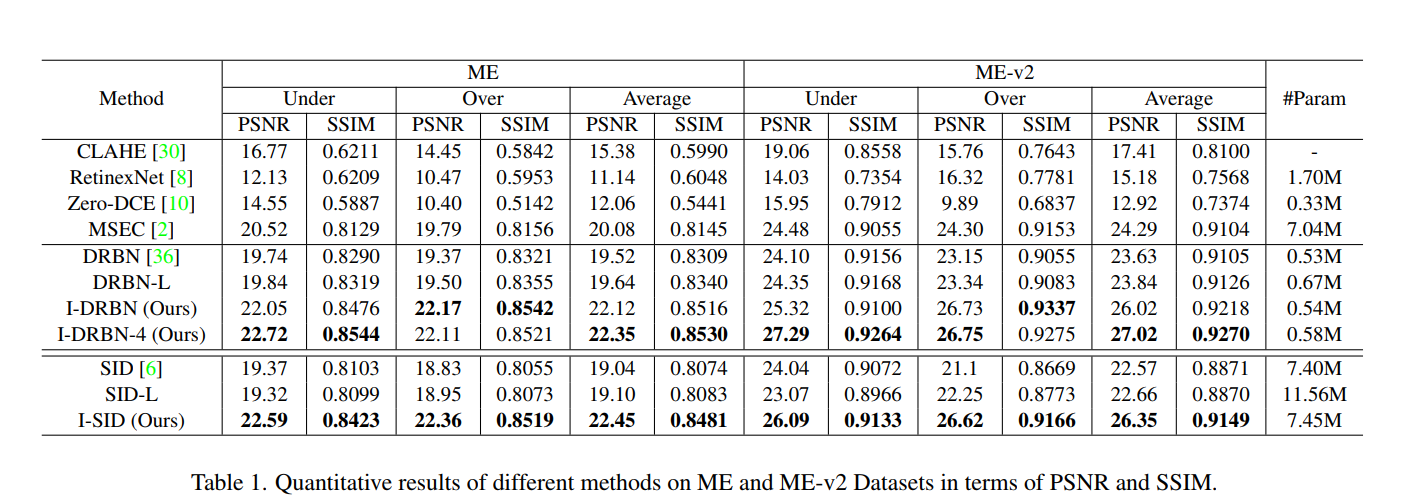
Exposure Normalization and Compensation for Multiple-Exposure Correction 论文阅读笔记
这是CVPR2022的一篇曝光校正的文章,是中科大的。一作作者按同样的思路(现有方法加一个自己设计的即插即用模块以提高性能的思路)在CVPR2023也发了一篇文章,名字是Learning Sample Relationship for Exposure Correction。 文章的…

【论文笔记】LLM-Augmenter
github:https://github.com/pengbaolin/LLM-Augmenter(暂无处readme外其他文件) paper:https://arxiv.org/pdf/2302.12813.pdf 
论文阅读_图形图像_U-NET
name_en: U-Net: Convolutional Networks for Biomedical Image Segmentation name_ch: U-Net:用于生物医学图像分割的卷积网络 addr: http://link.springer.com/10.1007/978-3-319-24574-4_28 doi: 10.1007/978-3-319-24574-4_28 date_read: 2023-02-08 date_publi…
![[论文笔记]Prefix Tuning](https://img-blog.csdnimg.cn/img_convert/0d307fd4adbc77ebb663456f611696e1.png)
[论文笔记]Prefix Tuning
引言
今天带来微调LLM的第二篇论文笔记Prefix-Tuning。
作者提出了用于自然语言生成任务的prefix-tuning(前缀微调)的方法,固定语言模型的参数而优化一些连续的任务相关的向量,称为prefix。受到了语言模型提示词的启发,允许后续的token序列注意到这些prefix,当成虚拟toke…

【论文笔记】A Review of Motion Planning for Highway Autonomous Driving
文章目录 I. INTRODUCTIONII. CONSIDERATIONS FOR HIGHWAY MOTION PLANNINGA. TerminologyB. Motion Planning SchemeC. Specificities of Highway DrivingD. Constraints on Highway DrivingE. What Is at Stake in this Paper III. STATE OF THE ARTA. Taxonomy DescriptionB…
论文笔记(整理):轨迹相似度顶会论文中使用的数据集
0 汇总
数据类型数据名称数据处理出租车数据波尔图 原始数据:2013年7月到2014年6月,170万条数据 ICDE 2023 Contrastive Trajectory Similarity Learning with Dual-Feature Attention 过滤位于城市(或国家)区域之外的轨迹 过…

1 论文笔记:Efficient Trajectory Similarity Computation with ContrastiveLearning
2022CIKM
1 intro
1.1 背景
轨迹相似度计算是轨迹分析任务(相似子轨迹搜索、轨迹预测和轨迹聚类)最基础的组件之一现有的关于轨迹相似度计算的研究主要可以分为两大类: 传统方法 DTW、EDR、EDwP等二次计算复杂度O(n^2)缺乏稳健性 会受到非…
【论文阅读】(CVPR2023)用于半监督医学图像分割的双向复制粘贴
目录 前言方法BCPMean-teacher and Traning StrategyPre-Training via Copy-PasteBidirectional Copy-Paste ImagesBidirectional Copy-Paste Supervisory Signals Loss FunctionTesting Phase 结论 先看这个图,感觉比较清晰。它整个的思路就是把有标签的图片和无标…
【论文笔记】SVDM: Single-View Diffusion Model for Pseudo-Stereo 3D Object Detection
原文链接:https://arxiv.org/abs/2307.02270
1. 引言 目前的从单目相机生成伪传感器表达的方法依赖预训练的深度估计网络。这些方法需要深度标签来训练深度估计网络,且伪立体方法通过图像正向变形合成立体图像,会导致遮挡区域的像素伪影、扭…

论文笔记:TMN: Trajectory Matching Networks for PredictingSimilarity
2022 ICDE
1 intro
1.1 背景
轨迹相似度可以划分为:
非学习度量方法 通常是为一两个特定的轨迹距离度量设计的,因此不能与其他度量一起使用通常需要二次时间(O(n^2))来计算轨迹之间的精确距离基于学习的度量方法 利用机器学习…
开题报告 PPT 应该怎么做
开题报告 PPT 应该怎么做
1、报告时首先汇报自己的姓名、单位、专业和导师。
2、研究背景(2-3张幻灯片)
简要阐明所选题目的研究目的及意义。
研究的目的,即研究应达到的目标,通过研究的背景加以说明(即你为什么要…
多模态文档理解综述:Pix2Struct
Overview Pix2Struct总览 Pix2Struct
总览
题目: Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding 机构:谷歌 论文: https://arxiv.org/pdf/2210.03347.pdf 代码: https://github.com/google-research/pix2struct 任务: 特点: …


论文阅读 - Outlier detection in social networks leveraging community structure
目录
摘要
1. Introduction
2. Related works
3. Preliminaries
3.1. 模块化度量 3.2. Classes of outliers
3.2.1. 点异常 3.2.2. Contextual anomalies
3.2.3. Collective anomalies 3.3. Problem definition 3.4. Outliers score 4. Methodology
4.1. Proposed appr…

【立体视觉(五)】之立体匹配与SGM算法
【立体视觉(五)】之立体匹配与SGM算法 一、立体匹配一)基本步骤二)局部立体匹配三)全局立体匹配四)评价标准1. 均方误差(RMS)2. 错误匹配率百分比(PBM) 二、半全局(SGM)立体匹配一)代价计算二&a…
论文阅读--Energy efficiency in heterogeneous wireless access networks
异构无线接入网络的能源效率
论文信息:Navaratnarajah S, Saeed A, Dianati M, et al. Energy efficiency in heterogeneous wireless access networks[J]. IEEE wireless communications, 2013, 20(5): 37-43.
I. ABSTRACT && INTRODUCTION 本文提出了无…
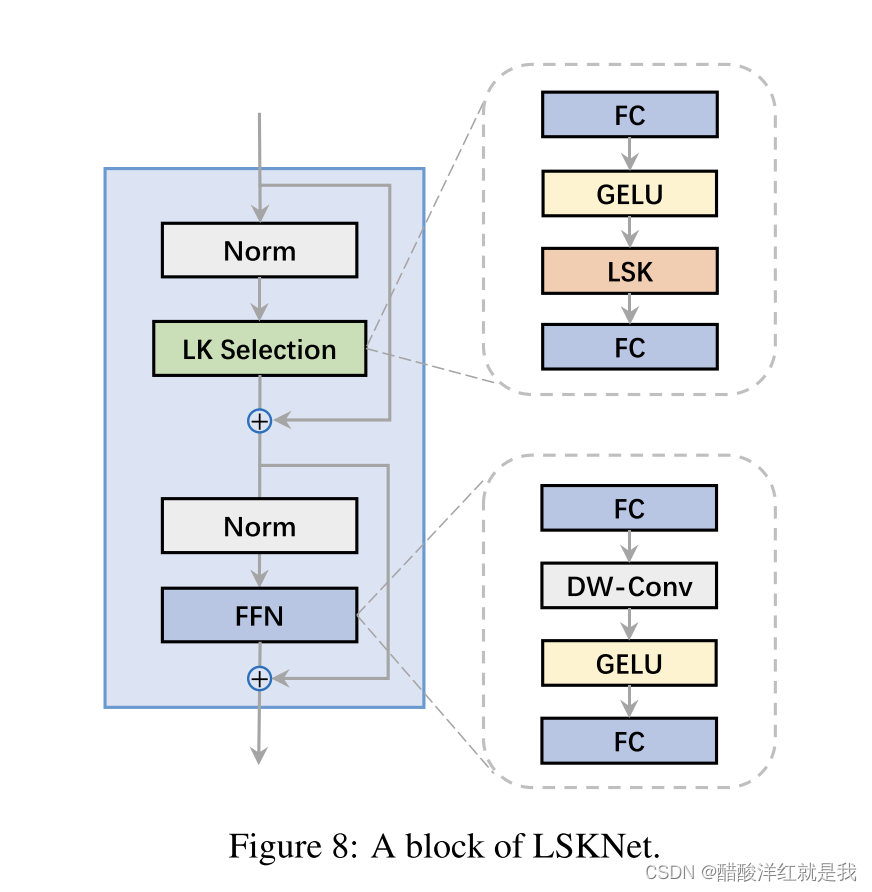
论文阅读——Large Selective Kernel Network for Remote Sensing Object Detection
目录 基本信息标题目前存在的问题改进网络结构另一个写的好的参考 基本信息
期刊CVPR年份2023论文地址https://arxiv.org/pdf/2303.09030.pdf代码地址https://github.com/zcablii/LSKNet
标题
遥感目标检测的大选择核网络
目前存在的问题
相对较少的工作考虑到强大的先验知…
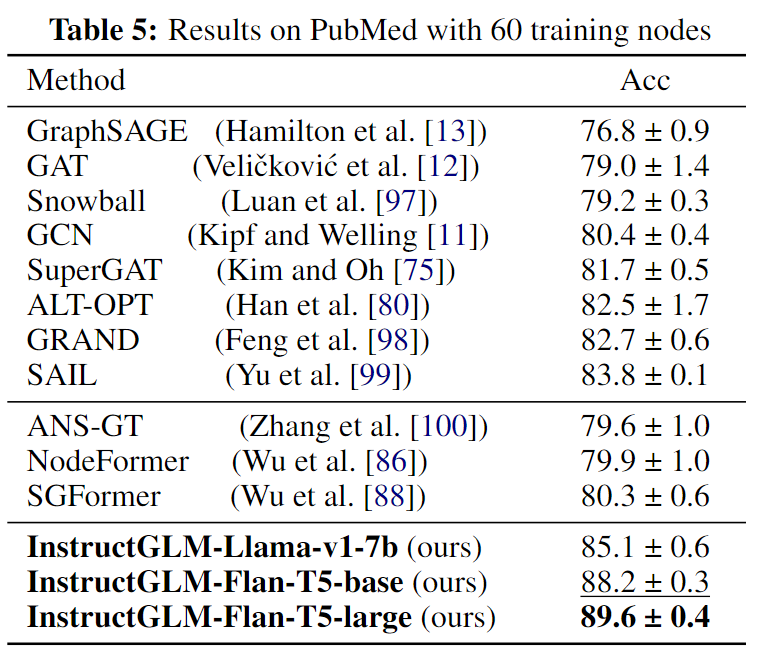
论文阅读 - Natural Language is All a Graph Needs
目录
摘要
Introduction
Related Work
3 InstructGLM
3.1 Preliminary
3.2 Instruction Prompt Design
3.3 节点分类的生成指令调整
3.4 辅助自监督链路预测
4 Experiments
4.1 Experimental Setup
4.2 Main Results
4.2.1 ogbn-arxiv 4.2.2 Cora & PubMed
4.…
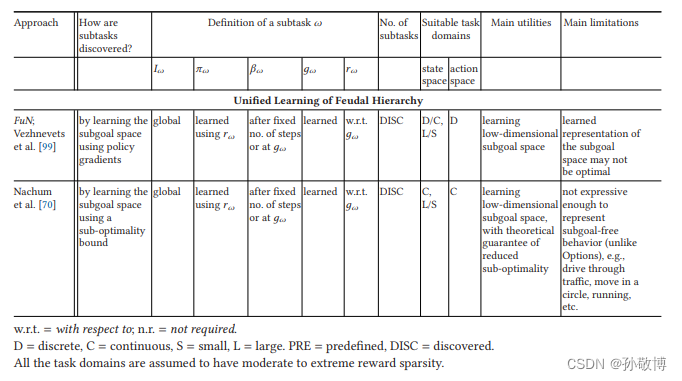
分层强化学习 综述论文阅读 Hierarchical Reinforcement Learning: A Comprehensive Survey
分层强化学习 综述论文阅读 Hierarchical Reinforcement Learning: A Comprehensive Survey 摘要一、介绍二、基础知识回顾2.1 强化学习2.2 分层强化学习2.2.1 子任务符号2.2.2 基于半马尔可夫决策过程的HRL符号 2.3 通用项定义 三、分层强化学习方法3.1 学习分层策略 (LHP)3.1…
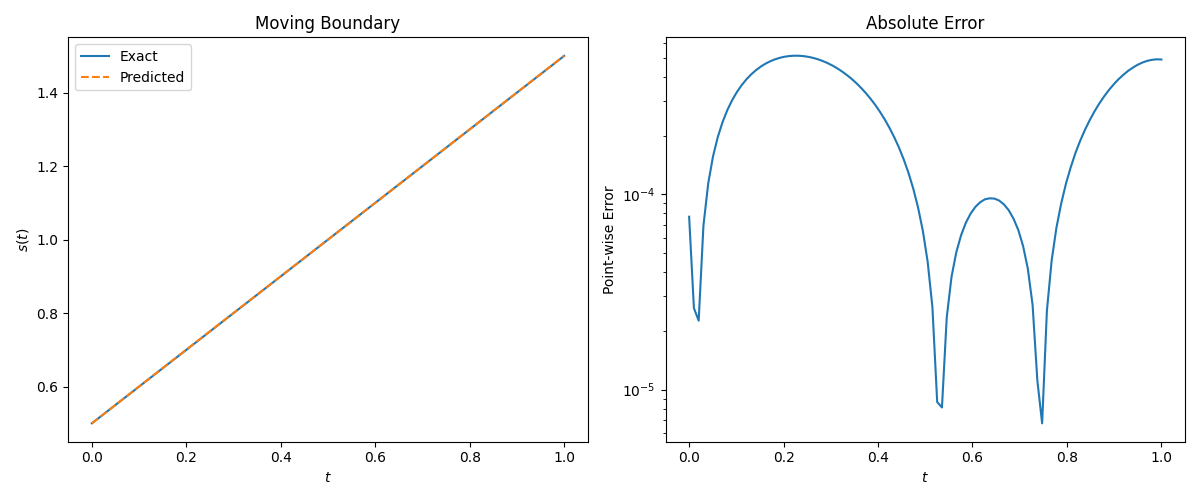
Deep learning of free boundary and Stefan problems论文阅读复现
Deep learning of free boundary and Stefan problems论文阅读复现 摘要1. 一维一相Stefan问题1.1 Direct Stefan problem1.2 Inverse Type I1.3 Inverse Type II 2. 一维二相Stefan问题2.1 Direct Stefan problem2.2 Inverse Type I2.3 Inverse Type II 3. 二维一相Stefan问题…
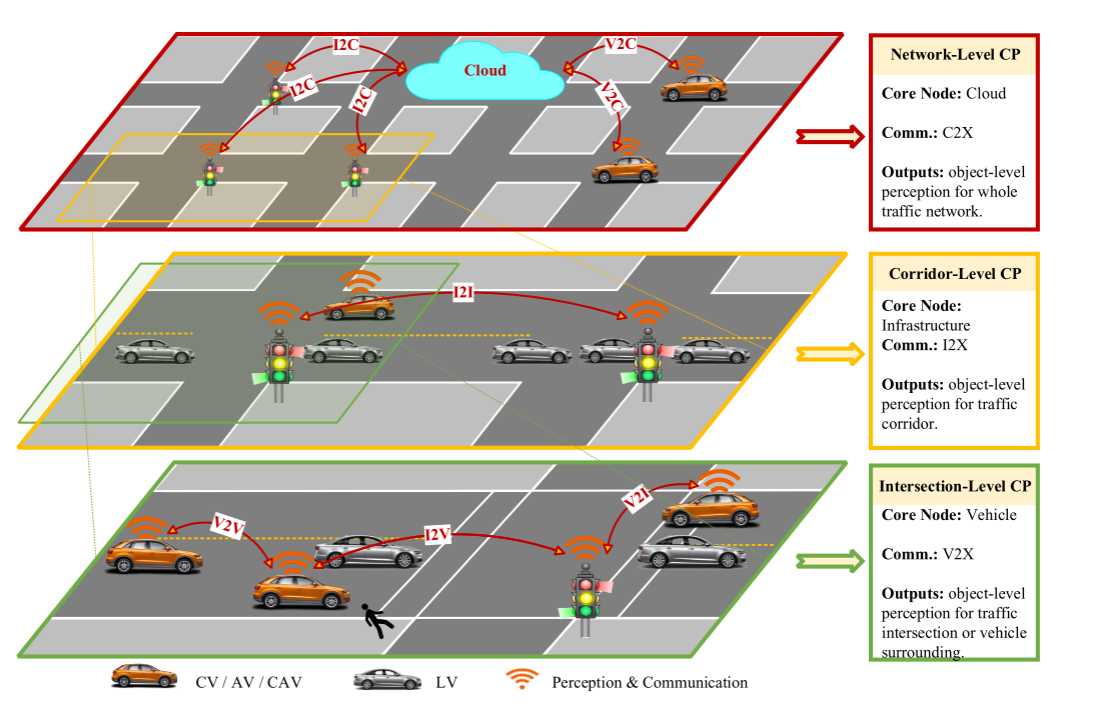
A Survey and Framework of Cooperative Perception 论文阅读
论文链接
A Survey and Framework of Cooperative Perception: From Heterogeneous Singleton to Hierarchical Cooperation 0. Abstract
首次提出统一的 CP(Cooperative Percepetion) 框架回顾了基于不同类型传感器的 CP 系统与分类对节点结构&#x…
如何下载IEEE Journal/Conference/Magazine的LaTeX/Word模板
当你准备撰写一篇学术论文或会议论文时,使用IEEE(电气和电子工程师协会)的LaTeX或Word模板是一种非常有效的方式,它可以帮助你确保你的文稿符合IEEE出版的要求。无论你是一名研究生生或一名资深学者,本教程将向你介绍如…
推荐一款AI写作大师、问答、绘画工具-「智元兔 AI」
在当今技术飞速发展的时代,人工智能(Artificial Intelligence,简称AI)的应用已经深入到各个领域。其中,AI写作大师、问答、绘画工具是备受关注和追捧的热门应用之一。在众多的选择中,有一款笔者在使用过程中…
【论文阅读】Equivariant Contrastive Learning for Sequential Recommendation
【论文阅读】Equivariant Contrastive Learning for Sequential Recommendation 文章目录 【论文阅读】Equivariant Contrastive Learning for Sequential Recommendation1. 来源2. 介绍3. 前置工作3.1 序列推荐的目标3.2 数据增强策略3.3 序列推荐的不变对比学习 4. 方法介绍4…
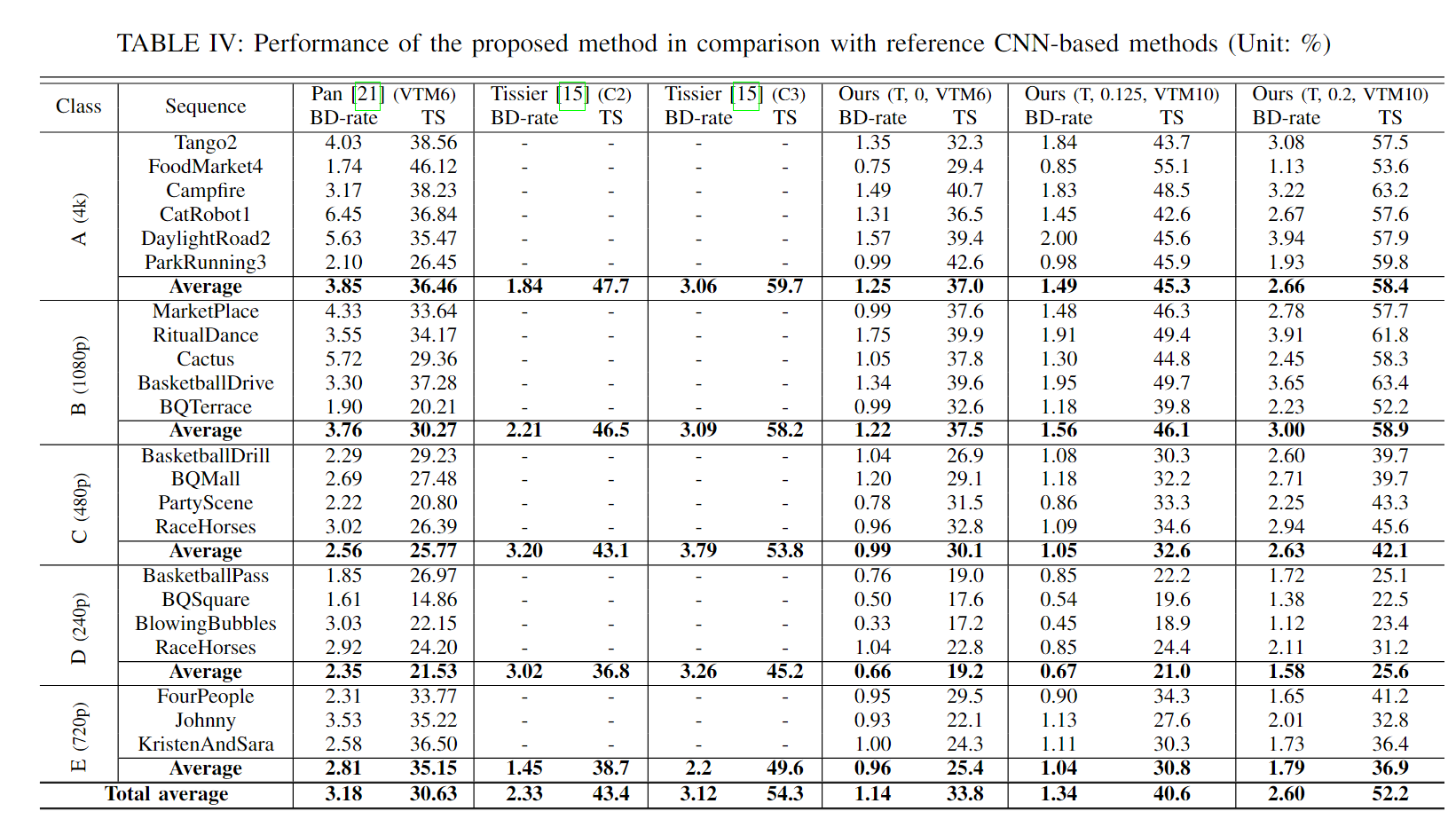
帧间快速算法论文阅读
Low complexity inter coding scheme for Versatile Video Coding (VVC)
通过分析相邻CU的编码区域,预测当前CU的编码区域,以终止不必要的分割模式。 𝐶𝑈1、𝐶𝑈2、𝐶𝑈3、&#x…
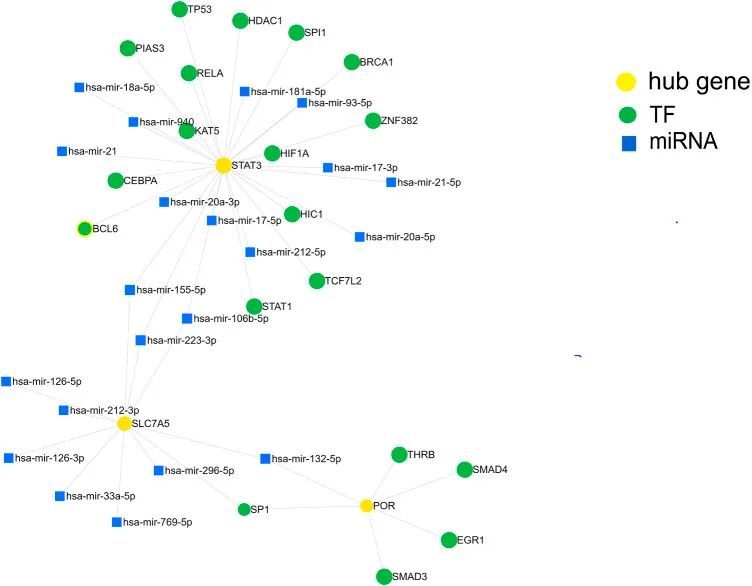
3+铜死亡+WGCNA,铜死亡为什么打得火热也是有迹可循的
今天给同学们分享一篇生信文章“A novel signature combing cuproptosis- and ferroptosis-related genes in sepsis-induced cardiomyopathy”,这篇文章发表在Front Genet.期刊上,影响因子为3.7。 结果解读:
差异基因表达分析
基因表达数据…

每日已开源的AI论文分享【2023920期】
目录
前言
3D语义场景补全
视频修复
3D人脸重建
视频线条检测
3D物体重建
尾言 前言 作者介绍:作者本人是一名人工智能炼丹师,目前在实验室主要研究的方向为生成式模型,对其它方向也略有了解,希望能够在CSDN这个平台上与同…
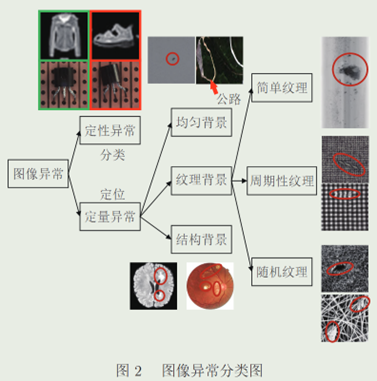
【论文阅读 05】图像异常检测研究现状综述
1 图像异常检测任务 图像异常检测任务根据异常的形态可以分为定性异常的分类和定量异常的定位两个类别. 定性异常的分类:整体地给出是否异常的判断,无需准确定位异常的位置。 如图2左上图所示, 左侧代表正常图像, 右侧代表异常图像, 在第1行中,模…

论文阅读:AugGAN: Cross Domain Adaptation with GAN-based Data Augmentation
Abstract
基于GAN的图像转换方法存在两个缺陷:保留图像目标和保持图像转换前后的一致性,这导致不能用它生成大量不同域的训练数据。论文提出了一种结构感知(Structure-aware)的图像转换网络(image-to-image translation network)。
Proposed Framework…

RT-DETR论文阅读笔记(包括YOLO版本训练和官方版本训练)
论文地址:RT-DETR论文地址
代码地址:RT-DETR官方下载地址 大家如果想看更详细训练、推理、部署、验证等教程可以看我的另一篇博客里面有更详细的介绍 内容回顾:详解RT-DETR网络结构/数据集获取/环境搭建/训练/推理/验证/导出/部署 目录
一…

CLIP Surgery论文阅读
CLIP Surgery for Better Explainability with Enhancement in Open-Vocabulary Tasks(CVPR2023) M norm ( resize ( reshape ( F i ˉ ∥ F i ‾ ∥ 2 ⋅ ( F t ∥ F t ‾ ∥ 2 ) ⊤ ) ) ) M\operatorname{norm}\left(\operatorname{resize}\…
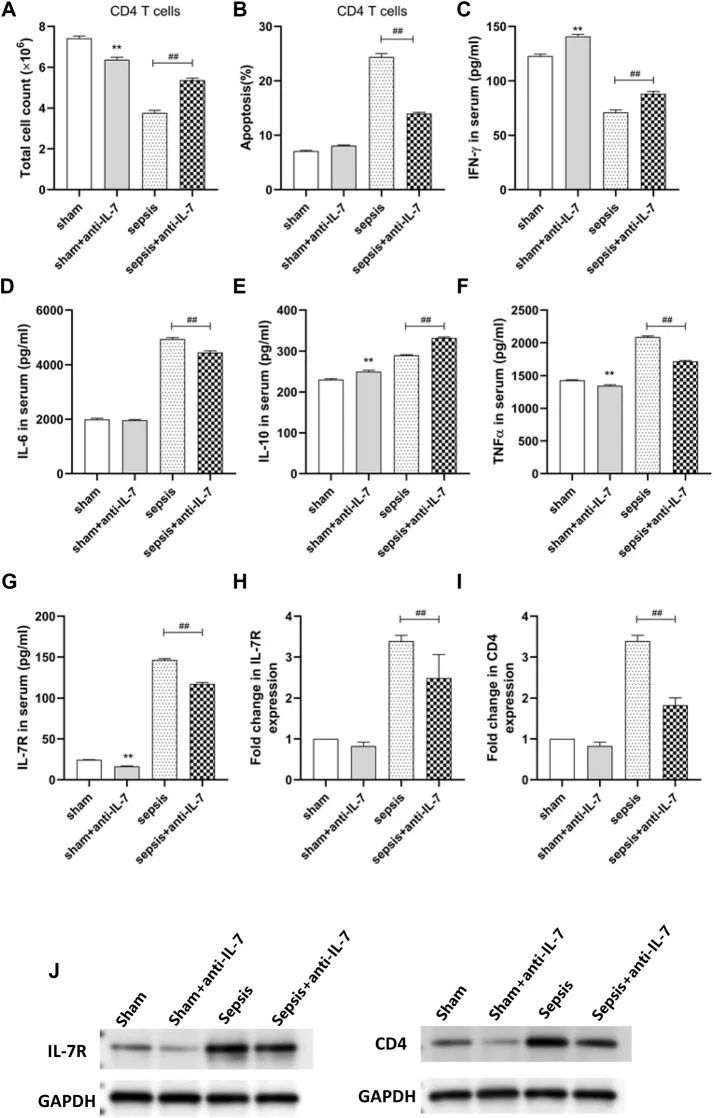
5+单细胞+铜死亡+实验,干湿结合生信思路,有条件做实验的可模仿
今天给同学们分享一篇生信文章“Single-cell transcriptomics reveals immune infiltrate in sepsis”,这篇文章发表在Front Pharmacol期刊上,影响因子为5.6。 结果解读 作者研究的流程图
作者首先制定了这项研究的总体技术路线,如图1所示。…

kimera论文阅读
功能构成:
Kimera包括四个关键模块:
Kimera-VIO的核心是基于gtsam的VIO方法[45],使用IMUpreintegration和无结构视觉因子[27],并在EuRoC数据集上实现了最佳性能[19];
Kimera-RPGO:一种鲁棒姿态图优化(RPGO)方法,利用现代技术进…
论文阅读:Ensemble Knowledge Transfer for Semantic Segmentation
论文地址:https://ieeexplore.ieee.org/document/8354272 项目及数据地址:https://github.com/ishann/aeroscapes 发表时间:2018年5月7日
语义分割网络通常以严格监督的方式学习,即它们在相似的数据分布上进行训练和测试。在域转…
论文阅读——Pyramid Grafting Network for One-Stage High Resolution Saliency Detection
目录 基本信息标题目前存在的问题改进网络结构CMGM模块解答为什么要用这两个编码器进行编码 另一个写的好的参考 基本信息
期刊CVPR年份2022论文地址https://arxiv.org/pdf/2204.05041.pdf代码地址https://github.com/iCVTEAM/PGNet
标题
金字塔嫁接网络的一级高分辨率显著性…

前几周的阅读的论文(截图版)
目录 显著性检测DMTSCWSSODGCoNet RSI与SOD结合ACCoNetGLGCNet RSI结合分割CADA_MaskFormerSeMask-Mask2Formershunted-MaskFormer 显著性检测
DMT
CVPR 2023
SCWSSOD
AAAI 2021
GCoNet
SCI1区 2023
RSI与SOD结合
ACCoNet
SCI1区 2023
GLGCNet
SCI1区 2023 …
【论文阅读】基于卷积神经的端到端无监督变形图像配准
📘End-to-End Unsupervised Deformable ImageRegistration with a Convolutional NeuralNetwork 📕《基于卷积神经的端到端无监督变形图像配准》 文章目录 摘要 Abstract. 1.导言 Introduction 附录 References未完待续 to be continued ... 摘要 Abstr…
【论文阅读】 Cola-Dif; An explainable task-specific synthesis network
文章目录 CoLa-Diff: Conditional Latent Diffusion Model for Multi-modal MRI SynthesisAn Explainable Deep Framework: Towards Task-Specific Fusion for Multi-to-One MRI Synthesis CoLa-Diff: Conditional Latent Diffusion Model for Multi-modal MRI Synthesis
论文…

【文献copilot】调用文心一言api对论文逐段总结
文献copilot:调用文心一言api对论文逐段总结
当我读文献的时候,感觉读得太慢了,看翻译软件翻译的又觉得翻译的不好。于是我就写了个程序辅助我读文献,它可以逐段总结,输出格式是:原文一句话总结分段总结&a…
【论文阅读笔记】 Curated Pacific Northwest AI-ready Seismic Dataset
Curated Pacific Northwest AI-ready Seismic Dataset
太平洋西北部人工智能地震数据集
摘要
描述了一个AI就绪地震数据集包括各种地震事件参数 仪器元数据 地震波行描述地震目录和事件属性(事件震级类型,信道类型,波形极性,信…

【论文阅读】(2023TPAMI)PCRLv2
目录 AbstractMethodMethodnsU-Net中的特征金字塔多尺度像素恢复多尺度特征比较从多剪切到下剪切训练目标 总结 Abstract
现有方法及其缺点:最近的SSL方法大多是对比学习方法,它的目标是通过比较不同图像视图来保留潜在表示中的不变合判别语义ÿ…
【网安AIGC专题10.19】论文6:Java漏洞自动修复+数据集 VJBench+大语言模型、APR技术+代码转换方法+LLM和DL-APR模型的挑战与机会
How Effective Are Neural Networks for Fixing Security Vulnerabilities 写在最前面摘要贡献发现 介绍背景:漏洞修复需求和Java漏洞修复方向动机方法贡献 数据集先前的数据集和Java漏洞Benchmark数据集扩展要求数据处理工作最终数据集 VJBenchVJBench 与 Vul4J 的…
【论文笔记】Unifying Large Language Models and Knowledge Graphs:A Roadmap
(后续更新完善) 2. KG-ENHANCED LLMS
2.1 KG-enhanced LLM Pre-training
以往将KGs集成到大型语言模型的工作主要分为三个部分:1)将KGs集成到训练目标中,2)将KGs集成到LLM输入中,3)将KGs集成到附加的融合模块中。
2.1.1 Integr…
论文阅读 - Detecting Social Bot on the Fly using Contrastive Learning
目录 摘要: 引言
3 问题定义
4 CBD
4.1 框架概述
4.2 Model Learning
4.2.1 通过 GCL 进行模型预训练 4.2.2 通过一致性损失进行模型微调 4.3 在线检测
5 实验
5.1 实验设置
5.2 性能比较
5.5 少量检测研究 6 结论 https://dl.acm.org/doi/pdf/10.1145/358…
![[论文笔记]BGE](https://img-blog.csdnimg.cn/img_convert/b1719d974e103a39ca7e66ff844f21f4.png)

【建议收藏】免费体验的AI论文写作网站-「智元兔 AI」
在当今技术飞速发展的时代,越来越多的领域开始应用人工智能(Artificial Intelligence,简称AI)。其中,AI写作工具备受瞩目,备受推崇。
在众多的选择中,智元兔AI是一款在笔者使用过程中非常有帮助…
探索ChatGPT在学术写作中的应用与心得
随着人工智能的迅猛发展,ChatGPT作为一种强大的自然语言处理模型,逐渐在学术界引起了广泛的关注。本文将探讨ChatGPT在学术写作中的应用,并分享使用ChatGPT进行学术写作时的一些经验和心得。 01
—
ChatGPT在学术写作中的应用 1.文献综述和…
论文阅读:One Embedder, Any Task: Instruction-Finetuned Text Embeddings
1. 优势
现存的emmbedding应用在新的task或者domain上时表现会有明显下降,甚至在相同task的不同domian上的效果也不行。这篇文章的重点就是提升embedding在不同任务和领域上的效果,特点是不需要用特定领域的数据进行finetune而是使用instuction finetun…

多模态论文阅读之VLMo
VLMo泛读 TitleMotivationContributionModelExpertimentsSummary Title
VLMo:Unified Vision_Langugae Pre-Training with Mixture-of-Modality-Experts
Motivation
CLIP和ALIGN都采用dual-encoder的方式分别编码图像和文本,模态之间的交互采用cosine similarity…
多视图聚类论文阅读(二)
Deep multi-view semi-supervised clustering with sample pairwise constraints
Neuro Compucting
基于样本对约束的深度多视图半监督聚类
1.1 聚类的相关工作
典型相关分析(CCA)[13]寻求两个投影,将两个视图映射到一个低维公共子空间,其中两个视图…
《论文阅读:Dataset Condensation with Distribution Matching》
点进去这篇文章的开源地址,才发现这篇文章和DC DSA居然是一个作者,数据浓缩写了三篇论文,第一篇梯度匹配,第二篇数据增强后梯度匹配,第三篇匹配数据分布。DC是匹配浓缩数据和原始数据训练一次后的梯度差,DS…
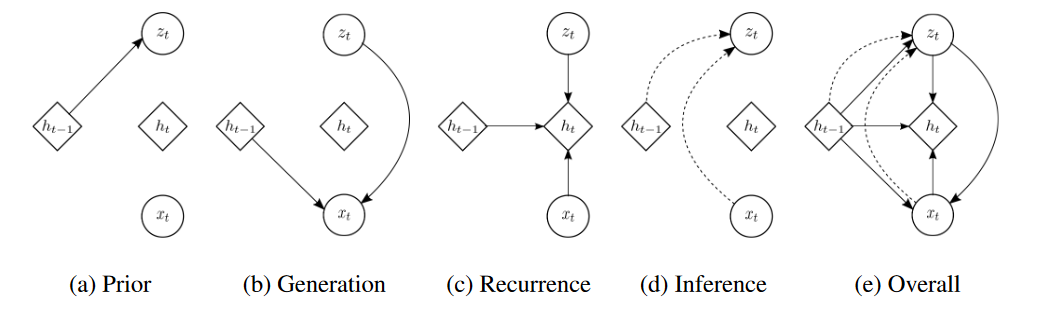
论文《A recurrent latent variable model for sequential data》笔记:详解VRNN
A recurrent latent variable model for sequential data
背景
1 通过循环神经网络的序列建模
循环神经网络(RNN)可以接收一个可变长度的序列 x ( x 1 , x 2 , . . . , x T ) x (x_1, x_2, ..., x_T) x(x1,x2,...,xT)作为输入,并通…
Adobe acrobat 11.0版本 pdf阅读器修改背景颜色方法
打开菜单栏,编辑,首选项,选择辅助工具项,页面中 勾选 替换文档颜色,页面背景自己选择一个颜色,然后确定,即可!
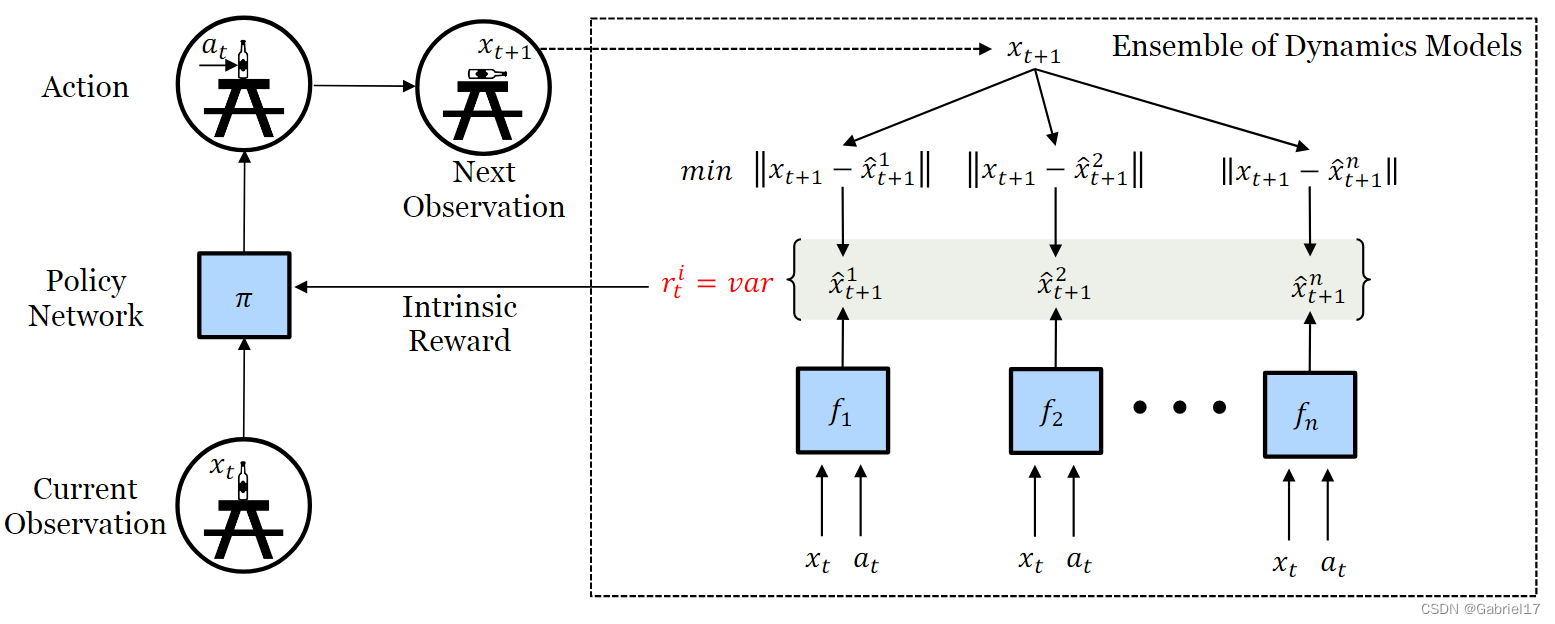
Self-Supervised Exploration via Disagreement论文笔记
通过分歧进行自我监督探索
0、问题
使用可微的ri直接去更新动作策略的参数的,那是不是就不需要去计算价值函数或者critic网络了?
1、Motivation
高效的探索是RL中长期存在的问题。以前的大多数方式要么陷入具有随机动力学的环境,要么效率…
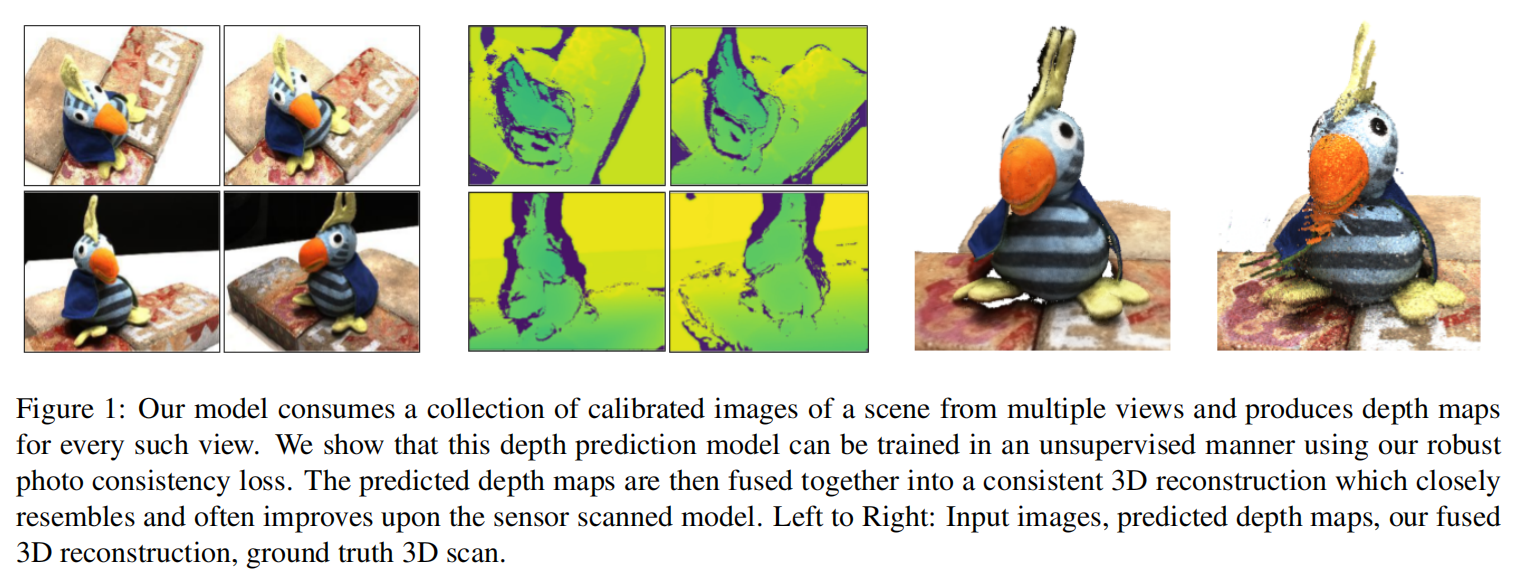
Unsupervised MVS论文笔记
Unsupervised MVS论文笔记 摘要1 引言2 相关工作3 实现方法 Tejas Khot and Shubham Agrawal and Shubham Tulsiani and Christoph Mertz and Simon Lucey and Martial Hebert. Tejas Khot and Shubham Agrawal and Shubham Tulsiani and Christoph Mertz and Simon Lucey and …

论文笔记——FasterNet
为了设计快速神经网络,许多工作都集中在减少浮点运算(FLOPs)的数量上。然而,作者观察到FLOPs的这种减少不一定会带来延迟的类似程度的减少。这主要源于每秒低浮点运算(FLOPS)效率低下。 为了实现更快的网络,作者重新回顾了FLOPs的运算符,并证明了如此低的FLOPS主要是由…
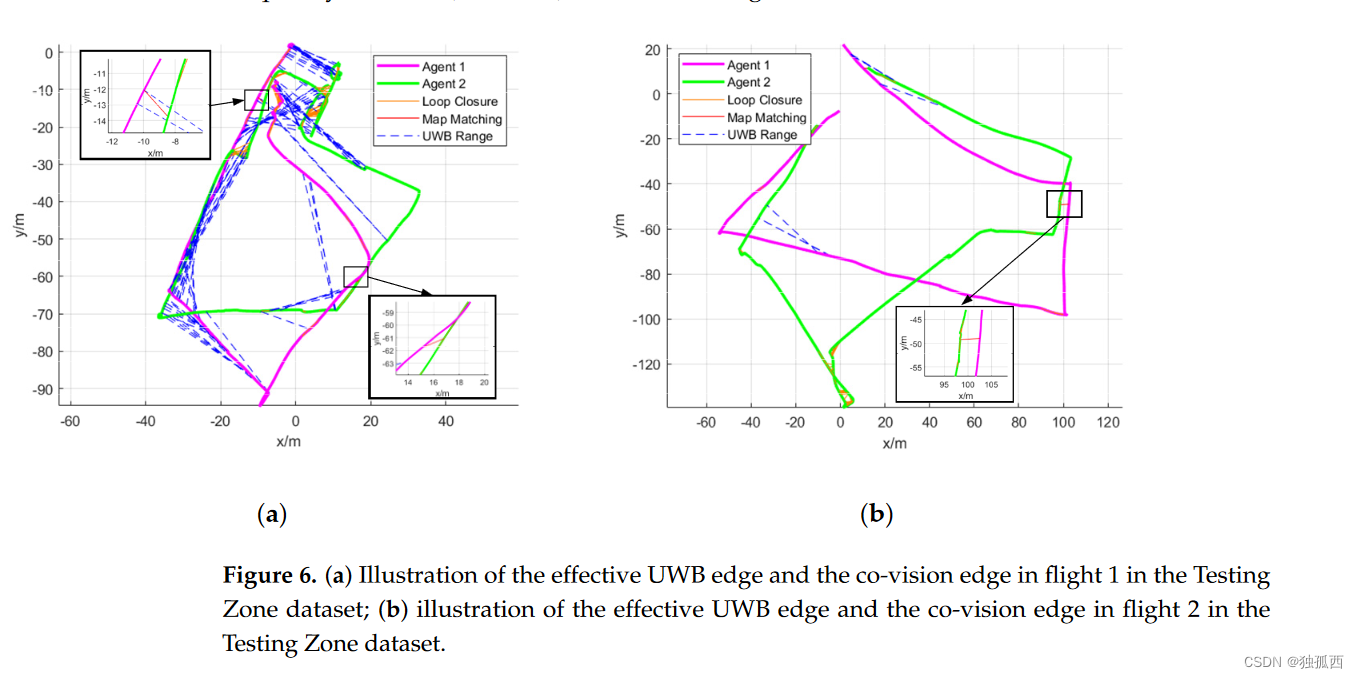
论文阅读:C2VIR-SLAM: Centralized Collaborative Visual-Inertial-Range SLAM
前言
论文全程为C2VIR-SLAM: Centralized Collaborative Visual-Inertial-Range Simultaneous Localization and Mapping,是发表在MDPI drones(二区,IF4.8)上的一篇论文。这篇文章使用单目相机、惯性测量单元( IMU )和UWB设备作为…
【论文阅读笔记】清单
我的论文清单
记录即将阅读的论文清单,持续更新。
未读论文
以下是我计划阅读但尚未开始的论文列表:
编号方向论文标题作者发表时间发表会议/期刊计划阅读日期code1NerfNeRFMeshing: Distilling Neural Radiance Fields into Geometrically-Accurate…

【论文阅读笔记】Prompt-to-Prompt Image Editing with Cross-Attention Control
【论文阅读笔记】Prompt-to-Prompt Image Editing with Cross-Attention Control 个人理解思考基本信息摘要背景挑战方法结果 引言方法论结果讨论引用 个人理解
通过将caption的注意力图注入到目标caption注意力中影响去噪过程以一种直观和便于理解的形式通过修改交叉注意力的…

一种使用热成像和自动编码器和 3D-CNN 模型堆叠集成进行跌倒检测的新方法
A Novel Approach for Fall Detection Using Thermal Imaging and a Stacking Ensemble of Autoencoder and 3D-CNN Models A Novel Approach for Fall Detection Using Thermal Imaging and a Stacking Ensemble of Autoencoder and 3D-CNN Models:一种使用热成像和自动编码器…
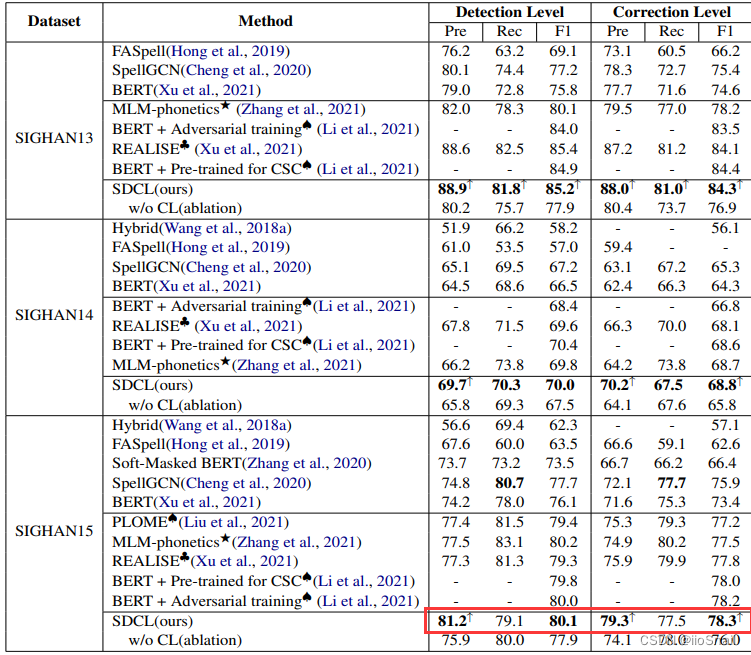
【论文笔记】SDCL: Self-Distillation Contrastive Learning for Chinese Spell Checking
文章目录 论文信息Abstract1. Introduction2. Methodology2.1 The Main Model2.2 Contrastive Loss2.3 Implementation Details(Hyperparameters) 3. Experiments代码实现个人总结值得借鉴的地方 论文信息
论文地址:https://arxiv.org/pdf/2210.17168.pdf
Abstrac…
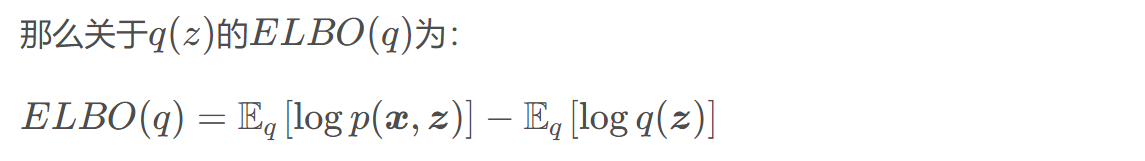
vqvae 论文阅读
https://arxiv.org/abs/1711.00937 直接3.1 首先我们定义一个嵌入空间. 是K*D维度的. K是离散空间向量的数量. D是每一个向量的维度. 所以e_i 中的i属于 1到K. 模型的输入是x, 也就是图片. 然后模型编码成一个z_e(x). 然后使用最近算法来得到 z_q 具体公式是下面1和2. 理解q这…

杂文月刊投稿方式论文发表要求
《杂文月刊》是由国家新闻出版总署批准的正规文学类期刊。主要内容取向:杂文、散文、小说、诗歌、漫画、文学评论、艺术评论、戏剧文化、地方文化、非遗文化、美学艺术、教育等历史、文化、文学、艺术类的文章。是广大专家、学者、教师、学子发表论文、交流信息的重…

【论文阅读】PSDF Fusion:用于动态 3D 数据融合和场景重建的概率符号距离函数
【论文阅读】PSDF Fusion:用于动态 3D 数据融合和场景重建的概率符号距离函数 Abstract1 Introduction3 Overview3.1 Hybrid Data Structure3.2 3D Representations3.3 Pipeline 4 PSDF Fusion and Surface Reconstruction4.1 PSDF Fusion4.2 Inlier Ratio Evaluati…
![论文阅读[121]使用CAE+XGBoost从荧光光谱中检测和识别饮用水中的有机污染物](https://img-blog.csdnimg.cn/5c7b9b90e3ba4c12a806aedc4d9c1e8c.png)
论文阅读[121]使用CAE+XGBoost从荧光光谱中检测和识别饮用水中的有机污染物
【论文基本信息】 标题:Detection and Identification of Organic Pollutants in Drinking Water from Fluorescence Spectra Based on Deep Learning Using Convolutional Autoencoder 标题译名:基于使用卷积自动编码器的深度学习,从荧光光谱…
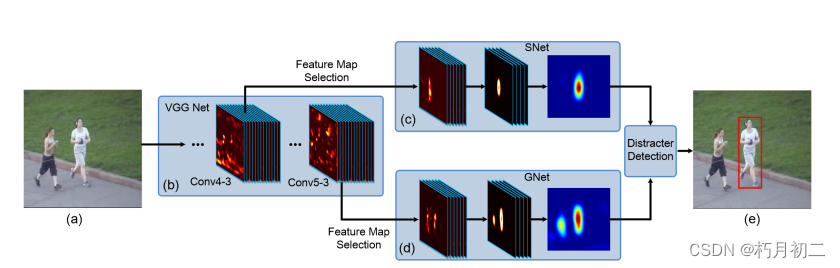
(论文阅读24/100)Visual Tracking with Fully Convolutional Networks
文献阅读笔记(sel - CNN) 简介 题目 Visual Tracking with Fully Convolutional Networks 作者 Lijun Wang, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu 原文链接 http://202.118.75.4/lu/Paper/ICCV2015/iccv15_lijun.pdf 【DeepLearning】…
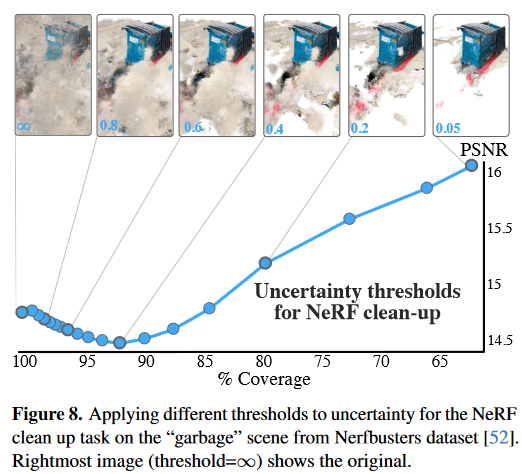
【论文阅读】Bayes’ Rays:神经辐射场的不确定性量化
【论文阅读】Bayes’ Rays:神经辐射场的不确定性量化 1. Introduction2. Related work3. Background3.2. Neural Laplace Approximations 4. Method4.1. Intuition4.2. Modeling perturbations4.3. Approximating H4.4. Spatial uncertainty 5. Experiments & A…
【论文阅读】ICRA: An Intelligent Clustering Routing Approach for UAV Ad Hoc Networks
文章目录 论文基本信息摘要1.引言2.相关工作3.PROPOSED SCHEME4.实验和讨论5.总结补充 论文基本信息
《ICRA: An Intelligent Clustering Routing Approach for UAV Ad Hoc Networks》 《ICRA:无人机自组织网络的智能聚类路由方法》
Published in: IEEE Transactions on Inte…
5+铜死亡+预后模型+分型生信思路,热点搭配免疫相关思路
今天给同学们分享一篇生信文章“The pathogenesis of DLD-mediated cuproptosis induced spinal cord injury and its regulation on immune microenvironment”,这篇文章发表在Front Cell Neurosci期刊上,影响因子为5.3。 结果解读:
基因芯…
RetroMAE论文阅读
1. Introduction
在NLP常用的预训练模型通常是由token级别的任务进行训练的,如MLM和Seq2Seq,但是密集检索任务更倾向于句子级别的表示,需要捕捉句子的信息和之间的关系,一般主流的策略是自对比学习(self-contrastive …
(论文阅读22/100)Learning a Deep Compact Image Representation for Visual Tracking
文献阅读笔记 简介 题目 Learning a Deep Compact Image Representation for Visual Tracking 作者 N Wang, DY Yeung 原文链接 Learning a Deep Compact Image Representation for Visual Tracking (neurips.cc) 关键词 Object tracking、DLT、SDAE 研究问题 track…
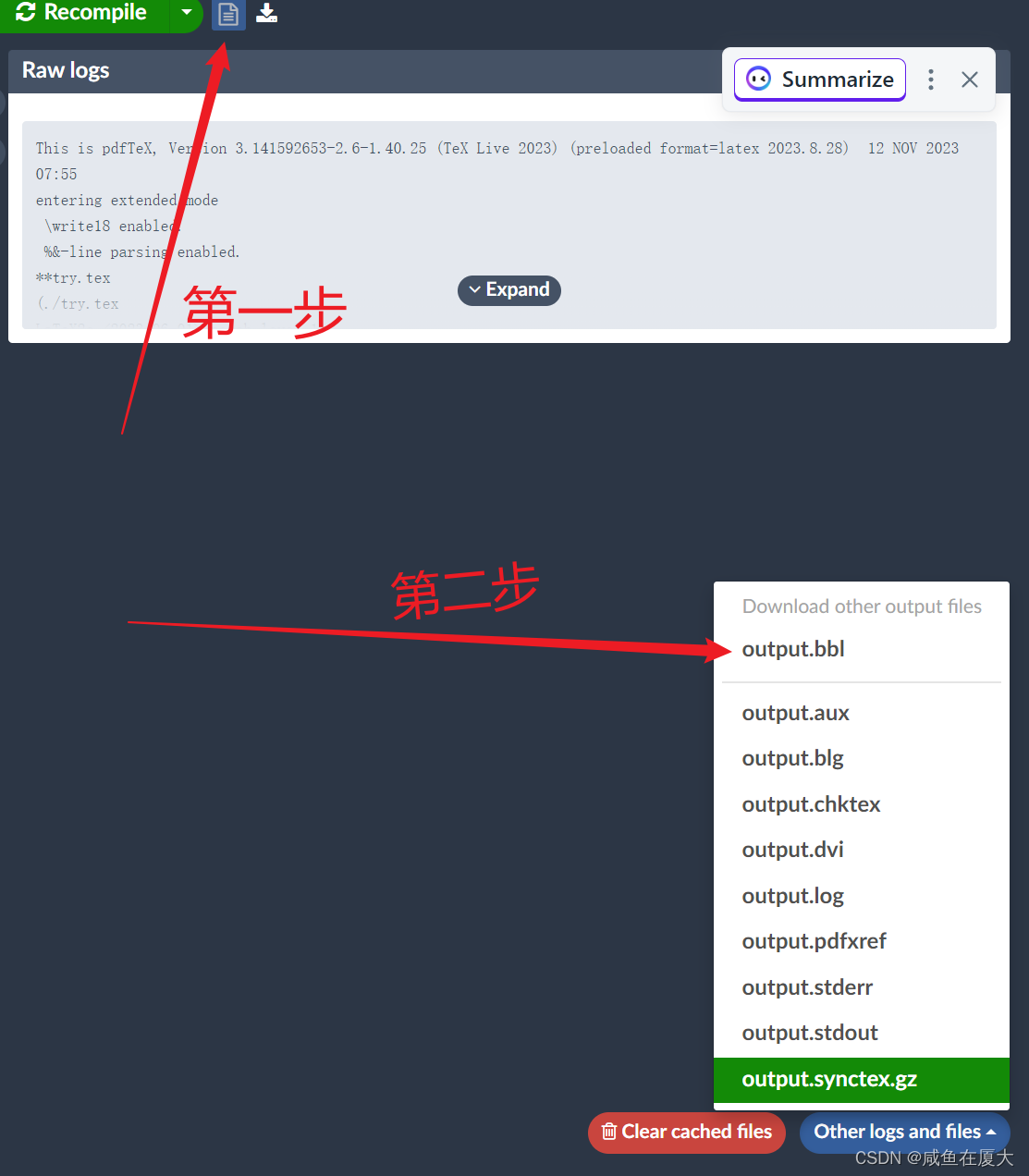
bibitem格式 添加参考文献
这次写论文时遇到一种bibitem格式的参考文献,latex中没有bib文件
分三步走
找到这篇文章的Bib Tex的引用,然后新建bib文件,命名为下图: 然后把Bib Tex引用的内容复制到上图的文件中,新建tex文件 内容为
\document…
ZKP Understanding Nova (1): MinRoot Example
Understanding Nova
Kothapalli, Abhiram, Srinath Setty, and Ioanna Tzialla. “Nova: Recursive zero-knowledge arguments from folding schemes.” Annual International Cryptology Conference. Cham: Springer Nature Switzerland, 2022.
Nova: Paper Code
1. Unders…
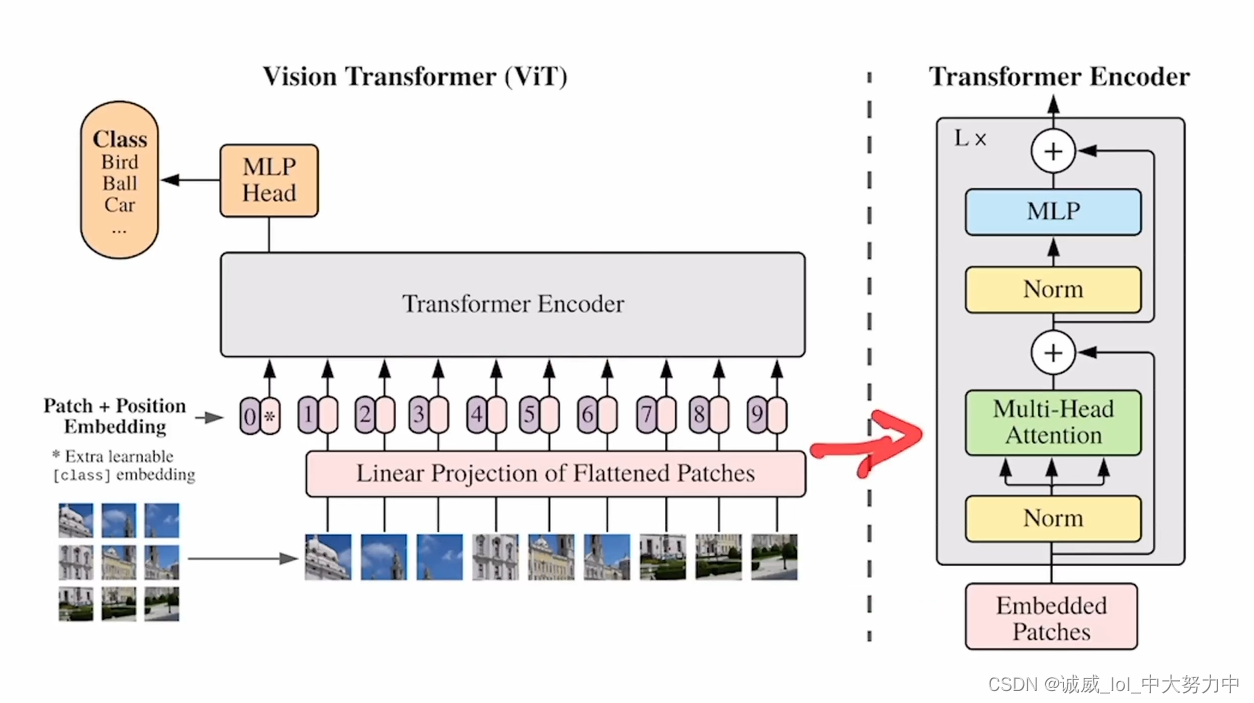
李沐——论文阅读——VIT(VIsionTransformer)
一、终极结论: 如果在足够多的数据上面去做预训练,那么,我们也可以不用 卷积神经网络,而是直接用 自然语言处理那边搬过来的 Transformer,也能够把视觉问题解决的很好
(tips:paperswithcode.co…
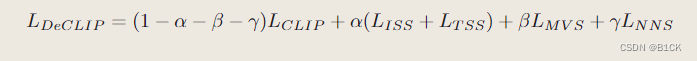
DeCLIP 论文阅读
DeCLIP:supervision exists everywhere:a data efficient contrastive language-image pre-training paradigm
贡献: 论文是为了充分利用单模态和多模态,充分利用单模态特征用自监督(SIMSAM和MLM),多模态用图像文本对…

【论文阅读】(CTGAN)Modeling Tabular data using Conditional GAN
论文地址:[1907.00503] Modeling Tabular data using Conditional GAN (arxiv.org) 摘要 对表格数据中行的概率分布进行建模并生成真实的合成数据是一项非常重要的任务,有着许多挑战。本文设计了CTGAN,使用条件生成器解决挑战。为了帮助进行公…

《Fine-Grained Image Analysis with Deep Learning: A Survey》阅读笔记
论文标题
《Fine-Grained Image Analysis with Deep Learning: A Survey》
作者
魏秀参,南京理工大学
初读
摘要 与上篇综述相同: 细粒度图像分析(FGIA)的任务是分析从属类别的视觉对象。 细粒度性质引起的类间小变化和类内…
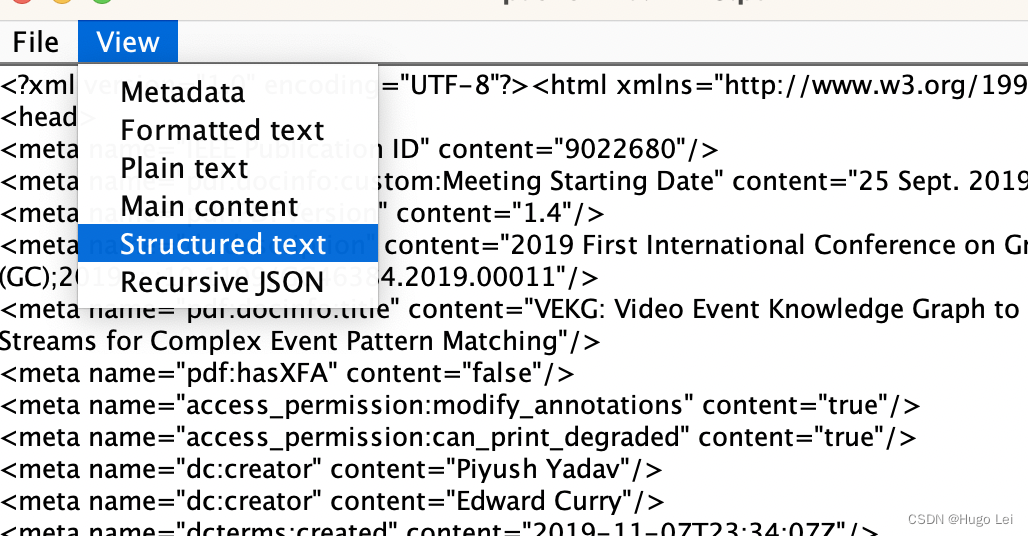
文档向量化工具(一):Apache Tika介绍
Apache Tika是什么?能干什么?
Apache Tika是一个内容分析工具包。
该工具包可以从一千多种不同的文件类型(如PPT、XLS和PDF)中检测并提取元数据和文本。
所有这些文件类型都可以通过同一个接口进行解析,这使得Tika在…

《Generic Dynamic Graph Convolutional Network for traffic flow forecasting》阅读笔记
论文标题
《Generic Dynamic Graph Convolutional Network for traffic flow forecasting》
干什么活:交通流预测(traffic flow forecasting )方法:动态图卷积网络(Dynamic Graph Convolutional Network)…

论文阅读:Auto White-Balance Correction for Mixed-Illuminant Scenes
论文阅读:Auto White-Balance Correction for Mixed-Illuminant Scenes
今天介绍一篇混合光照下的自动白平衡的文章
Abstract
自动白平衡(AWB)是相机 ISP 通路中比较重要的一个模块,主要用于校正环境光照引起的色偏问题&#x…

知云文献翻译——外语论文你get了吗?
今天博主分享一款实用的翻译软件,希望对大家日后的学习有所帮助。这个翻译网站,主要做文档翻译,可以上传PDF、Word、Excel这些格式,翻译语言也比较齐全。操作简单,功能多样的翻译软件;知云文献翻译最新版可以直接对PDF…
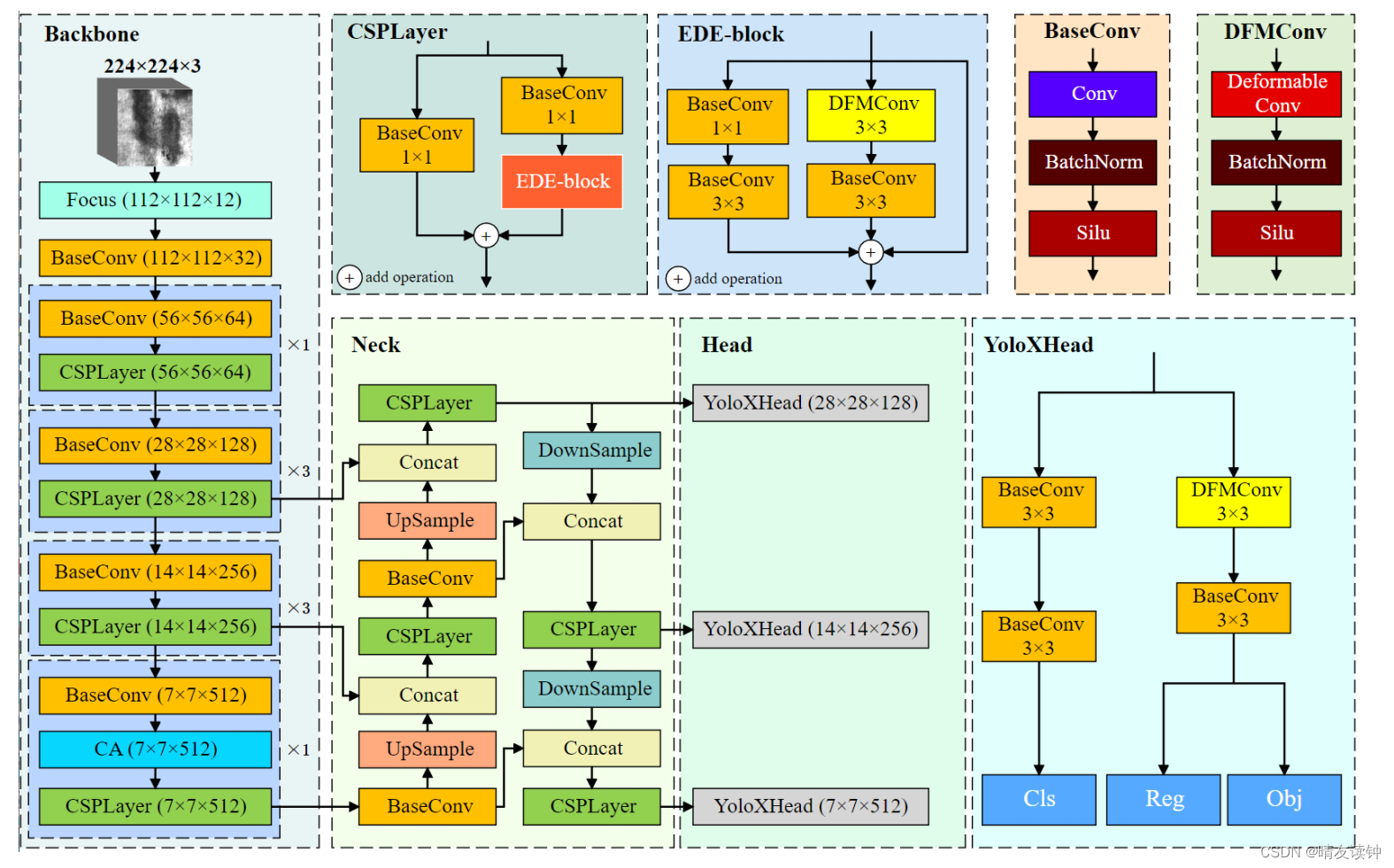
基于变形卷积和注意机制的带钢表面缺陷快速检测网络DCAM-Net(论文阅读笔记)
原论文链接->DCAM-Net: A Rapid Detection Network for Strip Steel Surface Defects Based on Deformable Convolution and Attention Mechanism | IEEE Journals & Magazine | IEEE Xplore DCAM-Net: A Rapid Detection Network for Strip Steel Surface Defects Base…

多视图聚类的论文阅读(一)
当聚类的方式使用的是某一类预定义好的相似性度量时, 会出现如下情况:
数据聚类方面取得了成功,但它们通常依赖于预定义的相似性度量,而这些度量受原始方法的影响:当输入维数相对较高时,往往是无效的。
1. Deep Mult…
论文阅读《DPS-Net: Deep Polarimetric Stereo Depth Estimation》
论文地址:https://openaccess.thecvf.com/content/ICCV2023/html/Tian_DPS-Net_Deep_Polarimetric_Stereo_Depth_Estimation_ICCV_2023_paper.html 概述 立体匹配模型难以处理无纹理场景的匹配,现有的方法通常假设物体表面是光滑的,或者光照是…
《论文阅读》DIFFUSEMP:一种基于扩散模型的多粒度控制共情回复生成框架 2023 IEEE TAC
《论文阅读》DIFFUSEMP:一种基于扩散模型的多粒度控制共情回复生成框架 前言简介相关知识Diffusion Model模型架构整体流程Acquisition of Control SignalsDiffusion Model with Control-Range Masking损失函数实验结果问题前言
今天为大家带来的是《DIFFUSEMP: A Diffusion …

无人驾驶汽车运动规划方法研究综述 - 阅读笔记
本文旨在对自己的研究方向做一些学习记录,方便日后回顾,详细论文细节见:无人驾驶汽车运动规划方法研究综述
1 摘要
文章从环境建模和路径搜索两个方面对现有的路径规划算法进行阐述(算法原理、应用现状、优缺点)。
…
ChatGPT论文降重:从97%到5%
ChatGPT在学术论文方面的功能非常强大,能够一键辅助你完成各种复杂的学术任务和课题,然而ChatGPT在论文降重上的表现就像一个"傻子"。
当你用ChatGPT给论文降重的时候,你会发现他很不听话,即使你要求他不能有重复、相同…

【论文笔记】NeuRAD: Neural Rendering for Autonomous Driving
原文链接:https://arxiv.org/abs/2311.15260
1. 引言
神经辐射场(NeRF)应用在自动驾驶中,可以创建可编辑的场景数字克隆(可自由编辑视角和场景物体),以进行仿真。但目前的方法或者需要大量的训…
【论文阅读】-使用小波变换进行数字图像模糊检测
使用小波变换进行数字图像模糊检测 文章目录 使用小波变换进行数字图像模糊检测1、论文提出的背景2、论文提出的模糊检测方案2.1 不同边缘的模糊效果2.2 边缘类型和锐度检测2.3 方案实现步骤3、论文方案Python实现4、实验结果及总结本文将详细介绍 Hanghang Tong 、Mingjing Li…
![论文阅读[2023ICME]Edge-FVV: Free Viewpoint Video Streaming by Learning at the Edge](https://img-blog.csdnimg.cn/direct/472224ca6a1544baa636cf087d36a706.png)
论文阅读[2023ICME]Edge-FVV: Free Viewpoint Video Streaming by Learning at the Edge
Edge-FVV: Free Viewpoint Video Streaming by Learning at the Edge
会议信息: Published in: 2023 IEEE International Conference on Multimedia and Expo (ICME)
作者:
1 背景
FVV允许观众从多个角度观看视频,但是如果所选视点的视频…
![[论文阅读]DETR](https://img-blog.csdnimg.cn/direct/fefcccbf4a1541128ea97dbe17b29a1d.png)
[论文阅读]DETR
DETR
End-to-End Object Detection with Transformers 使用 Transformer 进行端到端物体检测 论文网址:DETR 论文代码:DETR
简读论文 这篇论文提出了一个新的端到端目标检测模型DETR(Detection Transformer)。主要的贡献和创新点包括: 将目标检测视为一…
论文阅读:LSeg: LANGUAGE-DRIVEN SEMANTIC SEGMENTATION
可以直接bryanyzhu的讲解:CLIP 改进工作串讲(上)【论文精读42】_哔哩哔哩_bilibili
这里是详细的翻译工作
原文链接
https://arxiv.org/pdf/2201.03546.pdf
ICLR 2022
0、ABSTRACT
我们提出了一种新的语言驱动的语义图像分割模型LSeg。…
Memory-augmented Deep Autoencoder for Unsupervised Anomaly Detection 论文阅读
Memorizing Normality to Detect Anomaly: Memory-augmented Deep Autoencoder for Unsupervised Anomaly Detection 摘要1.介绍2.相关工作异常检测Memory networks 3. Memory-augmented Autoencoder3.1概述3.2. Encoder and Decoder3.3. Memory Module with Attention-based S…

论文阅读《Domain Generalized Stereo Matching via Hierarchical Visual Transformation》
论文地址:https://openaccess.thecvf.com/content/CVPR2023/html/Chang_Domain_Generalized_Stereo_Matching_via_Hierarchical_Visual_Transformation_CVPR_2023_paper.html 概述 立体匹配模型是近年来的研究热点。但是,现有的方法过分依赖特定数据集上…

3+肿瘤+免疫浸润+预后,经典的发文硬套路,解决你发文的烦恼
今天给同学们分享一篇生信文章“Cuproptosis-Related genes in the prognosis of colorectal cancer and their correlation with the tumor microenvironment”,这篇文章发表在Front Genet期刊上,影响因子为3.7。 结果解读:
不同临床特征的…
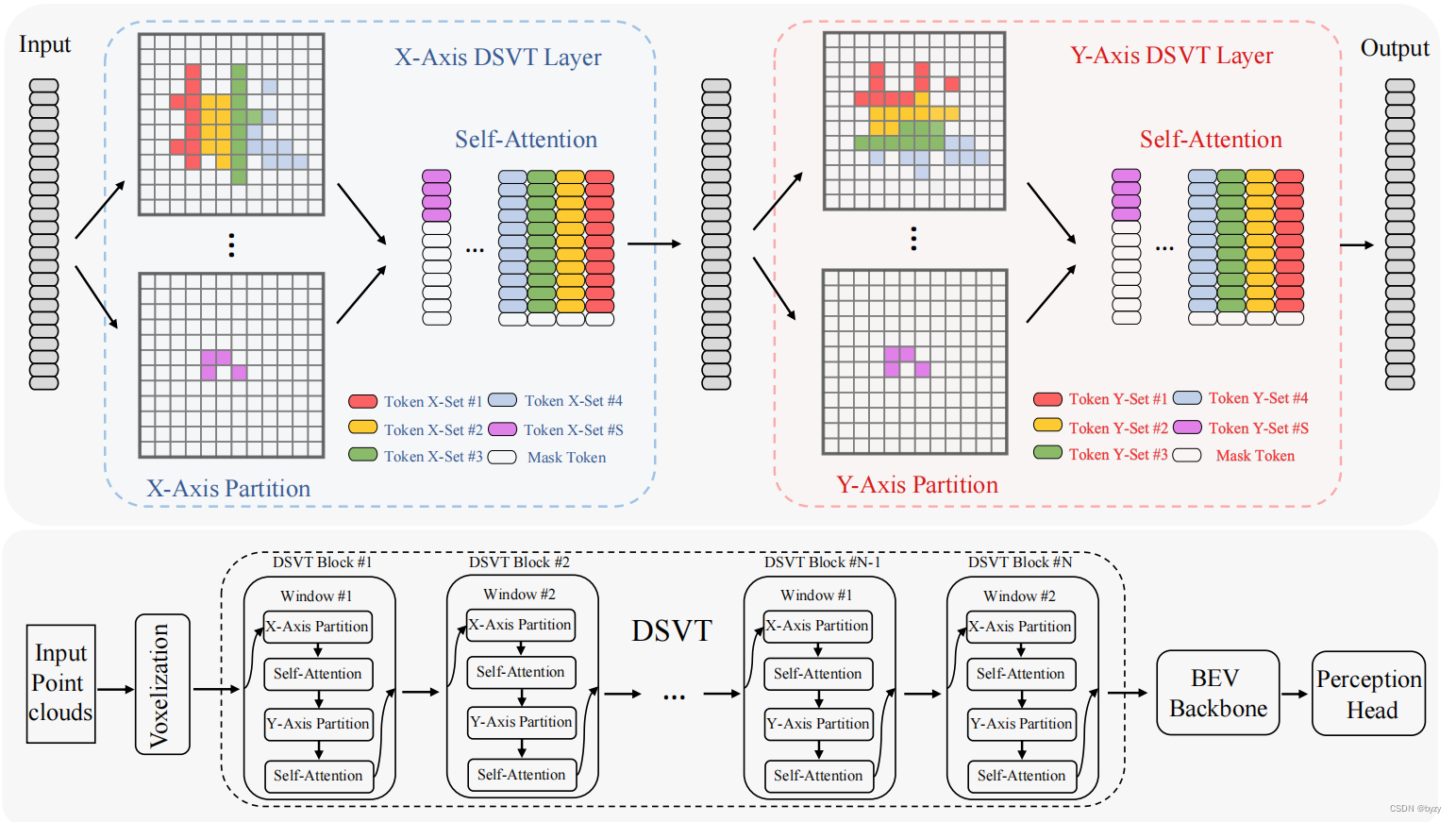
【论文笔记】DSVT: Dynamic Sparse Voxel Transformer with Rotated Sets
原文链接:https://arxiv.org/abs/2301.06051
1. 引言
本文提出DSVT,一种通用的、部署友好的、基于transformer的3D主干,可用于多种基于点云处理的3D感知任务中。
传统的稀疏点云特征提取方法,如PointNet系列和稀疏卷积…
![[论文阅读]Multimodal Virtual Point 3D Detection](https://img-blog.csdnimg.cn/direct/8b0c173e29da4b5e85f10f0c87f68892.png)
[论文阅读]Multimodal Virtual Point 3D Detection
Multimodal Virtual Point 3D Detection
多模态虚拟点3D检测 论文网址:MVP 论文代码:MVP
论文简读
方法MVP方法的核心思想是将RGB图像中的2D检测结果转换为虚拟的3D点,并将这些虚拟点与原始的Lidar点云合并。具体步骤如下: (1)…

EnlightenGAN论文阅读笔记
EnlightenGAN论文阅读笔记 论文是2019年IEEE的EnlightenGAN: Deep Light Enhancement without Paired Supervision.这篇论文是低光增强领域无监督学习的开山之作。 论文链接如下:arxiv.org/pdf/1906.06972.pdf 文章目录 EnlightenGAN论文阅读笔记出发点**出发点1**&…
【论文阅读笔记】Traj-MAE: Masked Autoencoders for Trajectory Prediction
Abstract
通过预测可能的危险,轨迹预测一直是构建可靠的自动驾驶系统的关键任务。一个关键问题是在不发生碰撞的情况下生成一致的轨迹预测。为了克服这一挑战,我们提出了一种有效的用于轨迹预测的掩蔽自编码器(Traj-MAE),它能更好地代表驾驶…
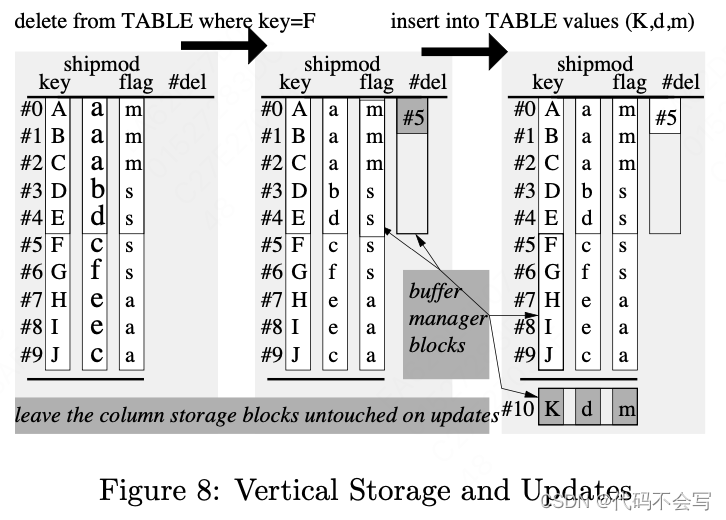
论文阅读:MonetDB/X100: Hyper-Pipelining Query Execution
目录 Abstract
1 Introduction
1.1 Outline
2 How CPU Work Abstract
在决策支持、OLAP和多媒体检索等计算密集型应用领域,数据库系统往往只能在现代cpu上实现较低的IPC(每周期指令)效率。本文首先以TPC-H基准为重点,深入研究了这种情况发生的原因。…

PPINN Parareal physics-informed neural network for time-dependent PDEs
论文阅读:PPINN Parareal physics-informed neural network for time-dependent PDEs PPINN Parareal physics-informed neural network for time-dependent PDEs简介方法PPINN加速分析 实验确定性常微分方程随机常微分方程Burgers 方程扩散反应方程 总结 PPINN Par…

【论文阅读】Uncertainty-aware Self-training for Text Classification with Few Label
论文下载 GitHub bib:
INPROCEEDINGS{mukherjee-awadallah-2020-ust,title "Uncertainty-aware Self-training for Few-shot Text Classification",author "Subhabrata Mukherjee and Ahmed Hassan Awadallah",booktitle "NeurIPS",yea…
怎么在PDF添加文本框?6种快速向PDF添加文字教程
有时您可能希望填写表格或在 PDF 文件中留下评论。这需要您将文本框和文本添加到 PDF。文本框是一个文本字段,您可以在其中键入文本。但是,除非您使用专用的 PDF 编辑器,否则编辑 PDF 文件具有挑战性。了解正确的 PDF 工具和将文本框添加到 P…
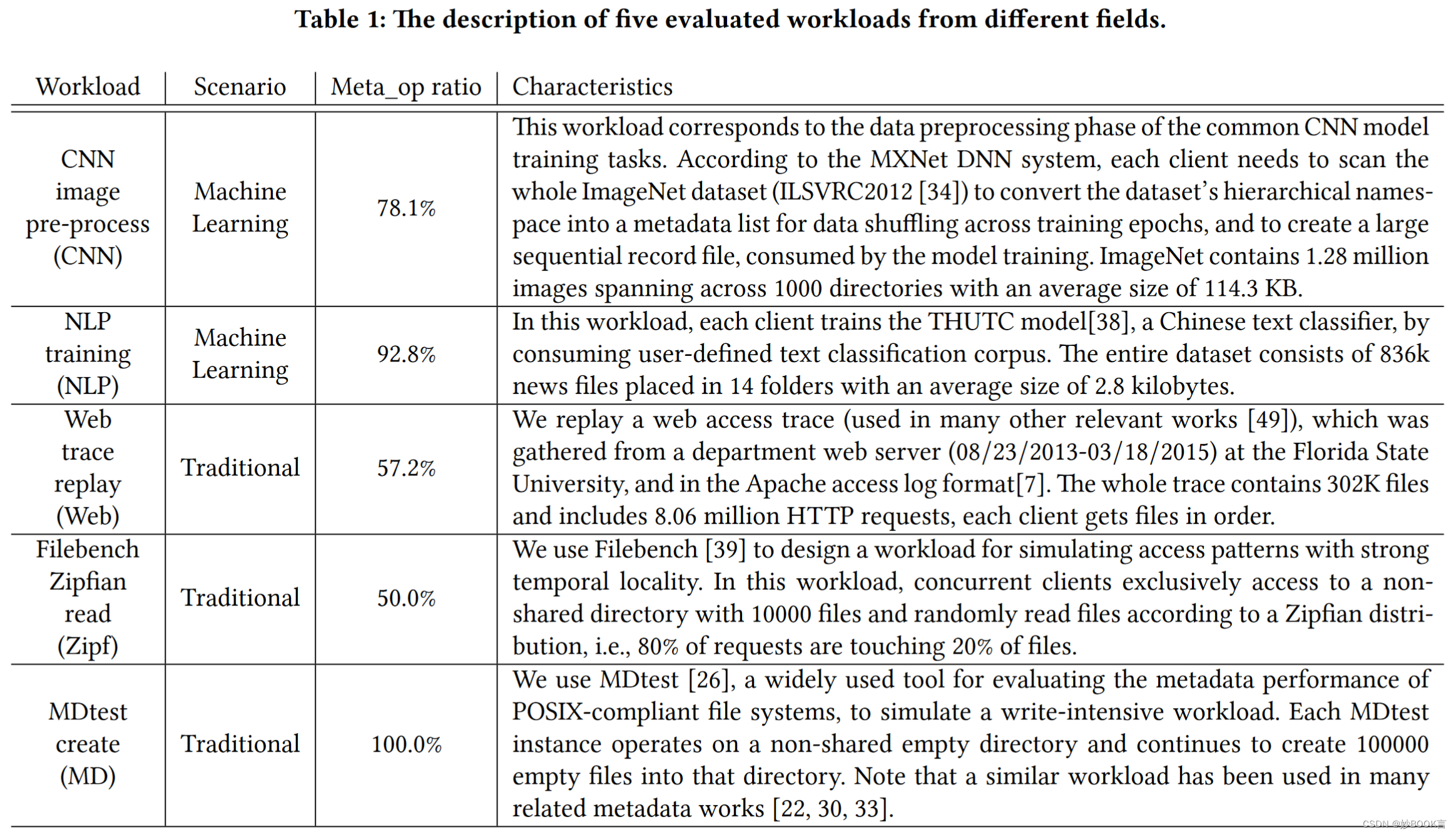
Lunule: An Agile and Judicious Metadata Load Balancer for CephFS——论文泛读
SC 2021 Paper 元数据论文阅读汇总
问题
CephFS采用动态子树分区方法,将分层命名空间划分并将子树分布到多个元数据服务器上。然而,这种方法存在严重的不平衡问题,由于其不准确的不平衡预测、对工作负载特性的忽视以及不必要/无效的迁移活动…

NLP论文阅读记录 - 2021 | WOS HG-News:基于生成式预训练模型的新闻标题生成
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.相关工作三.本文方法四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结思考 前言 HG-News: News Headline Generation Based on a Generative Pre-…

【开放集检测】OpenGAN: Open-Set Recognition via Open Data Generation 论文阅读
文章目录 英语积累为什么使用GAN系列网络进行开放集检测摘要1. 前言2. 相关工作开集检测基于GAN网络的开集检测基于暴露异常数据的开集检测 3. OpenGAN3.1 公式建模3.1.1 二分类方法存在问题如何解决 3.1.2 使用合成数据存在问题如何解决 3.1.3 OpenGAN3.1.4 模型验证 3.2 先前…
[论文笔记] PAI-Megatron中qwen和mistral合并到Megtron-LM
一、千问 关于tokenizer的改动:
1.1、更改build_tokenizer中tokenizer类的加载。 /mnt/nas/pretrain/code/Megatron-LM/megatron/tokenizer/__init__.py 或者 tokenizer.py 在build_tokenizer.py函数中:
elif args.tokenizer_type == "QwenTokenizer":assert a…

多模态大模型:关于Better Captions那些事儿
Overview 一、ShareGPT4V1.1、Motivation1.2、ShareGPT4V数据集构建1.3、ShareGPT4V-7B模型 一、ShareGPT4V
题目: ShareGPT4V: Improving Large Multi-Modal Models with Better Captions 机构:中科大,上海人工智能实验室 论文: https://arxiv.org/pdf…

RIS 系列 Mask Grounding for Referring Image Segmentation 论文阅读笔记
RIS 系列 Mask Grounding for Referring Image Segmentation 论文阅读笔记 一、Abstract二、引言三、相关工作Architecture Design for RISLoss Design for RISMasked Language Modeling 四、方法4.1 结构4.2 Mask Grounding讨论 4.3 跨模态对齐模块4.4 跨模态对齐损失4.5 损失…

论文阅读《Wavelet-Based Texture Reformation Network for Image Super-Resolution》
论文地址:https://arxiv.org/ftp/arxiv/papers/1907/1907.10213.pdf 源码地址:https://github.com/zskuang58/WTRN-TIP 概述 这篇论文提出了一种基于小波变换的纹理重构网络(WTRN),用于从参考图像中提取和迁移纹理信息…

【论文笔记】3D Gaussian Splatting for Real-Time Radiance Field Rendering
原文链接:https://arxiv.org/abs/2308.04079
1. 引言
网孔和点是最常见的3D场景表达,因其是显式的且适合基于GPU/CUDA的快速栅格化。神经辐射场(NeRF)则建立连续的场景表达便于优化,但渲染时的随机采样耗时且引入噪声…

scenic:单细胞调控网络推理和聚类
这是GRN分析中scenic的文献,发表在2017年的nature methods(SCENIC : single-cell regulatory network inference and clustering),学习了解其原理。
摘要
我们提出了scenery,一种用于从单细胞 rna-seq 数据中同时进行…

论文阅读《Rethinking Efficient Lane Detection via Curve Modeling》
目录
Abstract
1. Introduction
2. Related Work
3. BezierLaneNet
3.1. Overview
3.2. Feature Flip Fusion
3.3. End-to-end Fit of a Bezier Curve
4. Experiments
4.1. Datasets
4.2. Evalutaion Metics
4.3. Implementation Details
4.4. Comparisons
4.5. A…
【论文阅读】Self-Paced Curriculum Learning
论文下载 代码 Supplementary Materials bib:
INPROCEEDINGS{,title {Self-Paced Curriculum Learning},author {Lu Jiang and Deyu Meng and Qian Zhao and Shiguang Shan and Alexander Hauptmann},booktitle {AAAI},year {2015},pages {2694--2700}
}1. 摘…
7+衰老+WGCNA+机器学习+实验,非肿瘤领域的衰老相关研究
今天给同学们分享一篇生信文章“Identification of aging-related biomarkers and immune infiltration characteristics in osteoarthritis based on bioinformatics analysis and machine learning”,这篇文章发表在Front Immunol期刊上,影响因子为7.3…
《论文阅读》基于情绪-原因转换图的共情回复生成
《论文阅读》基于情绪-原因转换图的共情回复生成 前言摘要模型架构图构建回复概念预测回复生成前言
今天为大家带来的是《EMPATHETIC RESPONSE GENERATION VIA EMOTION CAUSE TRANSITION GRAPH》 出版:
时间:2023.2.23
类型:共情对话生成
关键词:图网络;共情回复;情绪…
2023APMCM亚太数学建模C题 - 中国新能源汽车的发展趋势(2)
五.问题二模型建立和求解
5.1 问题二模型建立和求解
针对题目二,题目要求收集中国新能源电动汽车行业发展数据,建立数学模型描述,并预测未来十年的发展。由于在第一文中,我们已经收集了一定的新能源行业发展数据&…
【论文阅读笔记】医学多模态新数据集-Large-scale Long-tailed Disease Diagnosis on Radiology Images
这是复旦大学2023.12.28开放出来的数据集和论文,感觉很宝藏,稍微将阅读过程记录一下。
Zheng Q, Zhao W, Wu C, et al. Large-scale Long-tailed Disease Diagnosis on Radiology Images[J]. arXiv preprint arXiv:2312.16151, 2023.
项目主页…
【论文阅读|冷冻电镜】DISCA: High-throughput cryo-ET structural pattern mining
论文题目
High-throughput cryo-ET structural pattern mining by unsupervised deep iterative subtomogram clustering
摘要
现有的结构排序算法的吞吐量低,或者由于依赖于可用模板和手动标签而固有地受到限制。本文提出了一种高吞吐量的、无需模板和标签的深度…
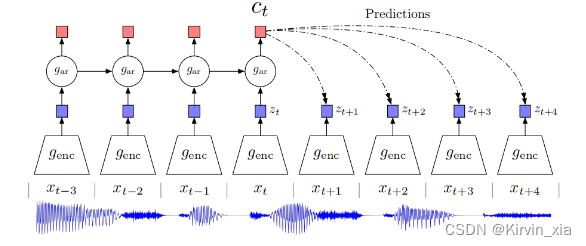
【论文阅读笔记】 Representation Learning with Contrastive Predictive Coding
Representation Learning with Contrastive Predictive Coding
摘要 这段文字是论文的摘要,作者讨论了监督学习在许多应用中取得的巨大进展,然而无监督学习并没有得到如此广泛的应用,仍然是人工智能中一个重要且具有挑战性的任务。在这项工作…

IMU用于无人机故障诊断
最近,来自韩国的研究团队通过开发以IMU为中心的数据驱动诊断方法,旨在多旋翼飞行器可以自我评估其性能,即时识别和解决推进故障。该方法从单纯的常规目视检查跃升为复杂的诊断细微差别,标志着无人机维护的范式转变。
与依赖额外传…

图像融合论文阅读:MURF: Mutually Reinforcing Multi-Modal Image Registration and Fusion
article{xu2023murf, title{MURF: Mutually Reinforcing Multi-modal Image Registration and Fusion}, author{Xu, Han and Yuan, Jiteng and Ma, Jiayi}, journal{IEEE Transactions on Pattern Analysis and Machine Intelligence}, year{2023}, publisher{IEEE} } 论文级别…
2023APMCM亚太数学建模C题 - 中国新能源汽车的发展趋势(3)
六、问题三的模型建立和求解
6.1问题分析
问题3.收集数据,建立数学模型分析新能源电动汽车对全球传统能源汽车行业的影响。
本题要求建立模型分析新能源电动汽车对全球传统能源汽车行业的影响。由于数据集可能略大,而在处理复杂问题、大量特征和大规模…

如何用AI提高论文阅读效率?
已经2024年了,该出现一个写论文解读AI Agent了。
大家肯定也在经常刷论文吧。
但真正尝试过用GPT去刷论文、写论文解读的小伙伴,一定深有体验——费劲。其他agents也没有能搞定的,今天我发现了一个超级厉害的写论文解读的agent ,…

Transformer - Attention is all you need 论文阅读
虽然是跑路来NLP,但是还是立flag说要做个project,结果kaggle上的入门project给的例子用的是BERT,还提到这一方法属于transformer,所以大概率读完这一篇之后,会再看BERT的论文这个样子。
在李宏毅的NLP课程中多次提到了…
Probabilistic Forecasting with Temporal Convolutional Neural Network
Abstract 我们提出了一种基于卷积神经网络(CNN)的概率预测框架,用于多个相关时间序列预测。该框架可用于估计参数和非参数设置下的概率密度。更具体地说,构建基于扩张因果卷积网络的堆叠残差块来捕获序列的时间依赖性。与表示学习…
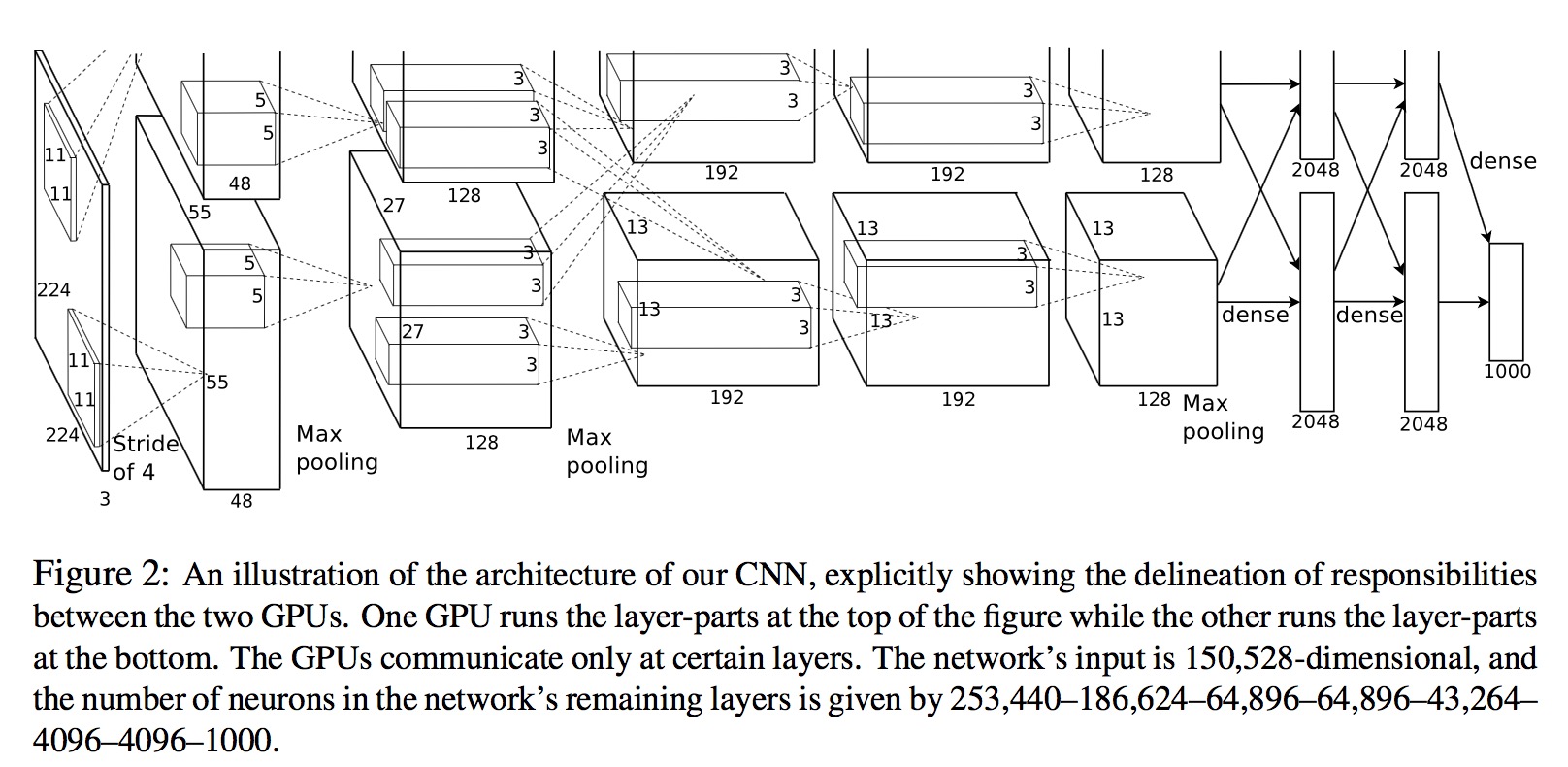
ImageNet Classification with Deep Convolutional 论文笔记
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。 🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心&…
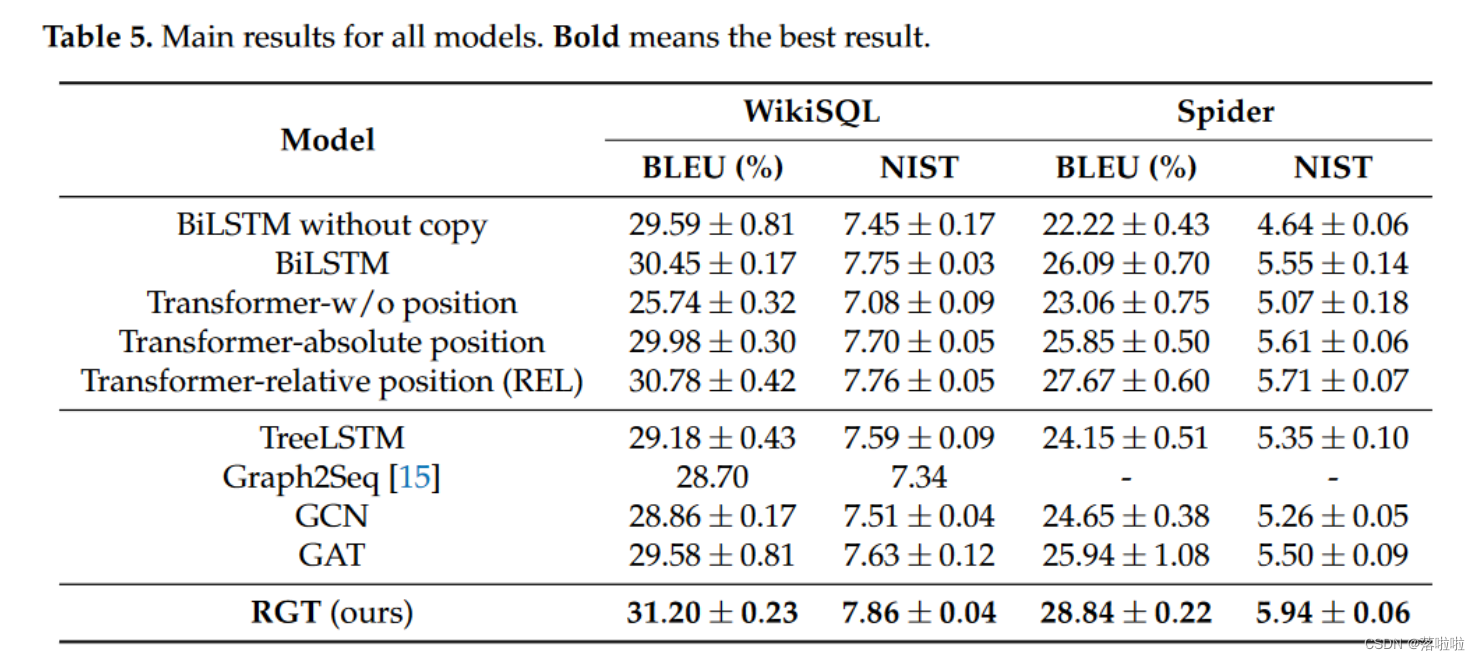
Relation-Aware Graph Transformer for SQL-to-Text Generation
Relation-Aware Graph Transformer for SQL-to-Text Generation
Abstract
SQL2Text 是一项将 SQL 查询映射到相应的自然语言问题的任务。之前的工作将 SQL 表示为稀疏图,并利用 graph-to-sequence 模型来生成问题,其中每个节点只能与 k 跳节点通信。由…
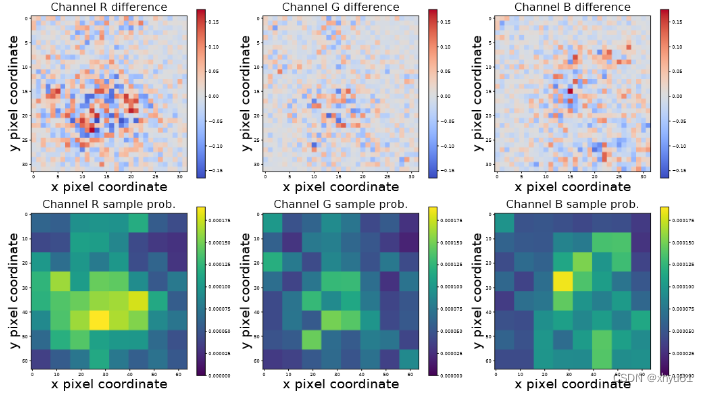
【论文笔记】ZOO: Zeroth Order Optimization
论文(标题写不下了): 《ZOO: Zeroth Order Optimization Based Black-box Attacks to Deep Neural Networks without Training Substitute Models》
Abstract
深度神经网络(DNN)是当今时代最突出的技术之一,在许多机器学习任务中…
![[论文阅读]4DRadarSLAM: A 4D Imaging Radar SLAM System for Large-scale Environments](https://img-blog.csdnimg.cn/direct/197bb0d9c2934ff9a95a6d0c9aa13049.png)
[论文阅读]4DRadarSLAM: A 4D Imaging Radar SLAM System for Large-scale Environments
目录 1.摘要和引言:
2. 系统框架:
2.1 前端:
2.2 回环检测:
2.3 后端:
3.实验和分析:
4.结论 1.摘要和引言:
这篇论文介绍了一种名为“4DRadarSLAM”的新型4D成像雷达SLAM系统࿰…

Efficient physics-informed neural networks using hash encoding
论文阅读:Efficient physics-informed neural networks using hash encoding Efficient physics-informed neural networks using hash encoding简介方法PINN哈希编码具有哈希编码的 PINN 实验Burgers 方程Helmholtz 方程N-S 方程训练效率对比 总结 Efficient physi…
论文阅读:TinyGPT-V 论文阅读及源码梳理对应
TODO
有待更新
QFormer作用?
QFormer来自论文BCLI2工作中,用来弥补Frozen Image encoder和Frozen LLM之间的gap。 基于Bert作为初始化的。
推理结构图 #mermaid-svg-5qFxDUGSPd77On5n {font-family:"trebuchet ms",verdana,arial,sans-ser…
2024年1月17日Arxiv热门NLP大模型论文:THE FAISS LIBRARY
Meta革新搜索技术!提出Faiss库引领向量数据库性能飞跃
引言:向量数据库的兴起与发展
随着人工智能应用的迅速增长,需要存储和索引的嵌入向量(embeddings)数量也在急剧增加。嵌入向量是由神经网络生成的向量表示&…

EM planner 论文阅读
论文题目:Baidu Apollo EM Motion Planner
0 前言 EM和Lattice算法对比
EM plannerLattice Planner参数较多(DP/QP,Path/Speed)参数少且统一化流程复杂流程简单单周期解空间受限简单场景解空间较大能适应复杂场景适合简单场景
…

【论文阅读】One For All: Toward Training One Graph Model for All Classification Tasks
目录 0、基本信息1、研究动机2、创新点——One For All :unique features3、准备4、具体实现4.1、用TAGs统一来自不同领域的图数据4.2、用NOI(NODES-OF-INTEREST)统一不同图任务4.2.1、NOI子图4.2.2、NOI提示结点 4.3、用于图的上下文学习&am…
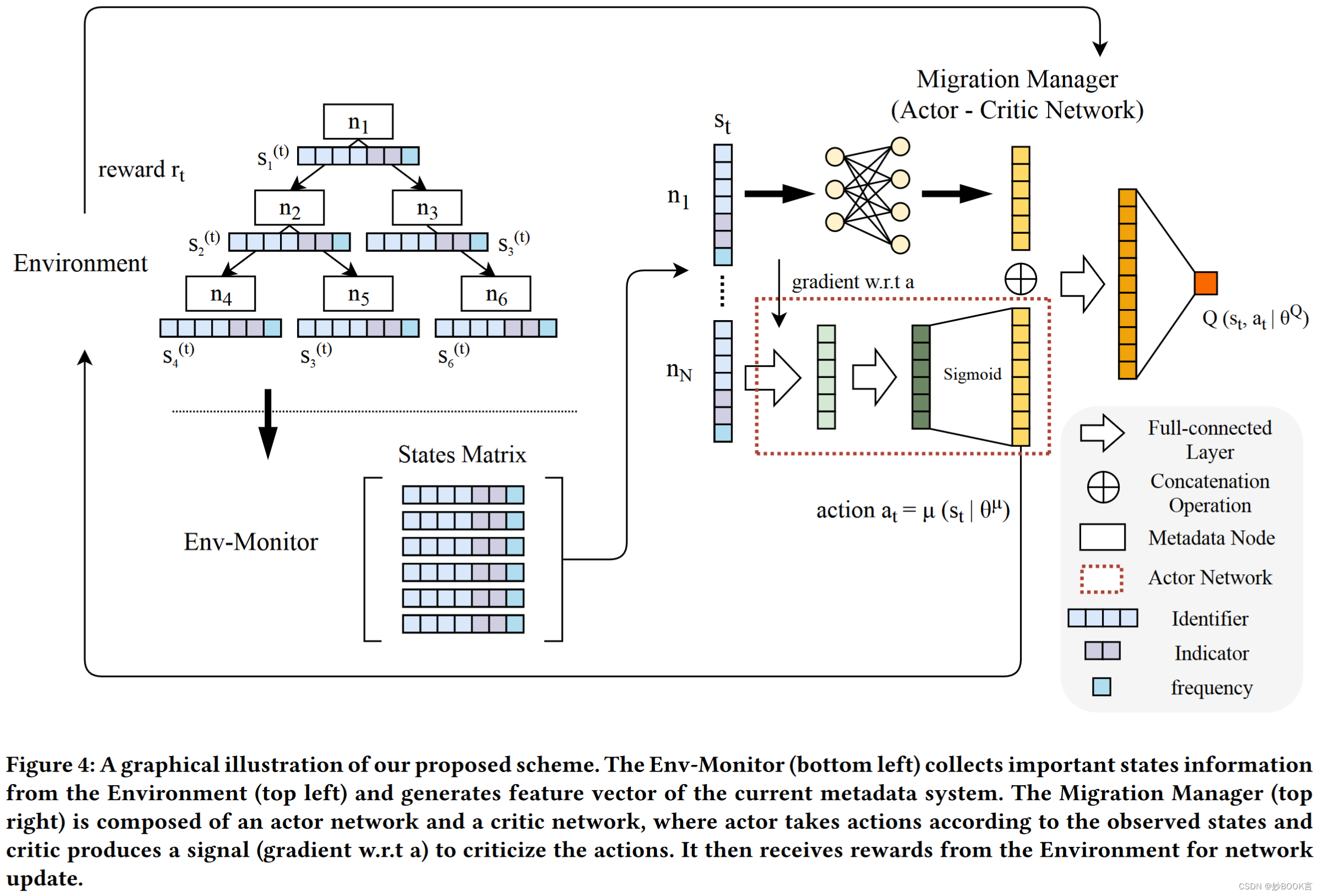
AdaM: An Adaptive Fine-Grained Scheme for Distributed Metadata Management——泛读论文
ICPP 2019 Paper 分布式元数据论文汇总
问题
为了同时解决元数据局部性和元数据服务器的负载均衡。
现有方法缺陷 基于哈希的方法:zFS [16],CalvinFS [21],DROP [24],AngleCut [8] 静态子树划分:HDFS [6], NFS [14…

【论文阅读笔记】MobileSal: Extremely Efficient RGB-D Salient Object Detection
1.介绍
MobileSal: Extremely Efficient RGB-D Salient Object Detection MobileSal:极其高效的RGB-D显著对象检测 2021年发表在 IEEE Transactions on Pattern Analysis and Machine Intelligence。 Paper Code
2.摘要
神经网络的高计算成本阻碍了RGB-D显着对象…

NLP论文阅读记录 - WOS | ROUGE-SEM:使用ROUGE结合语义更好地评估摘要
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.相关工作三.本文方法四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结 前言 ROUGE-SEM: Better evaluation of summarization using ROUGE combin…

【论文阅读】Consistency Models
文章目录 IntroductionDiffusion ModelsConsistency ModelsDefinitionParameterizationSampling Training Consistency Models via DistillationTraining Consistency Models in IsolationExperiment Introduction 相比于单步生成的模型(例如 GANs, VAEs, normalizi…
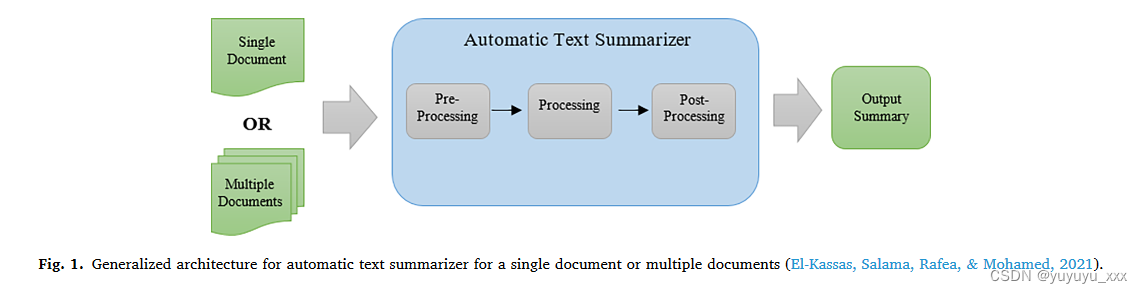
NLP论文阅读记录 - WOS | 2023 TxLASM:一种新颖的与语言无关的文本文档摘要模型
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.文献综述及相关工作三.本文方法四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结思考 前言 TxLASM: A novel language agnostic summarization mo…
NLP论文阅读记录 - 2021 | WOS 使用深度强化学习及其他技术进行自动文本摘要
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.相关工作2.1. Seq2seq 模型2.2.强化学习和序列生成2.3.自动文本摘要 三.本文方法四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结思考 前言 Auto…
Making Large Language Models Perform Better in Knowledge Graph Completion论文阅读
文章目录 摘要1.问题的提出引出当前研究的不足与问题KGC方法LLM幻觉现象解决方案 2.数据集和模型构建数据集模型方法基线方法任务模型方法基于LLM的KGC的知识前缀适配器知识前缀适配器 与其他结构信息引入方法对比 3.实验结果与分析结果分析:可移植性实验࿱…

【Image captioning】论文阅读七—Efficient Image Captioning for Edge Devices_AAAI2023
中文标题:面向边缘设备的高效图像描述(Efficient Image Captioning for Edge Devices) 文章目录 1. 引言2. 相关工作3. 方法3.1 Model Architecture(模型结构)3.2 Model Training (模型训练)3.3 Knowledge Distillation (知识蒸馏)4. 实验4.1 数据集和评价指标4.2 实施细…

【论文阅读】GraspNeRF: Multiview-based 6-DoF Grasp Detection
文章目录 GraspNeRF: Multiview-based 6-DoF Grasp Detection for Transparent and Specular Objects Using Generalizable NeRF针对痛点和贡献摘要和结论引言模型框架实验不足之处 GraspNeRF: Multiview-based 6-DoF Grasp Detection for Transparent and Specular Objects Us…

【word visio绘图】关闭visio两线交叉的跳线(跨线)
【visio绘图】关闭visio两线交叉的跳线(跨线) 1 如何在Visio绘图中关闭visio两线交叉的跳线(跨线)第一步:打开Visio并创建您的图形第二步:绘制您的连接线第三步:关闭跳线第四步:手动…
【论文阅读|小目标分割算法ASF-YOLO】
论文阅读|小目标分割算法ASF-YOLO 摘要(Abstract)1 引言(Introduction)2 相关工作(Related work)2.1 细胞实例分割(Cell instance segmentation)2.2 改进的YOLO用于实例分割…
【论文阅读笔记】Time Series Contrastive Learning with Information-Aware Augmentations
Time Series Contrastive Learning with Information-Aware Augmentations
摘要 背景:在近年来,已经有许多对比学习方法被提出,并在实证上取得了显著的成功。 尽管对比学习在图像和语言领域非常有效和普遍,但在时间序列数据上的应…

【论文阅读笔记】Advances in 3D Generation: A Survey
Advances in 3D Generation: A Survey 挖个坑,近期填完摘要 time:2024年1月31日 paper:arxiv 机构:腾讯 挖个坑,近期填完
摘要
生成 3D 模型位于计算机图形学的核心,一直是几十年研究的重点。随着高级神经…

论文阅读:Learning Lens Blur Fields
这篇文章是对镜头模糊场进行表征学习的研究,镜头的模糊场也就是镜头的 PSF 分布,镜头的 PSF 与物距,焦距,光学系统本身的像差都有关系,实际的 PSF 分布是非常复杂而且数量也很多,这篇文章提出用一个神经网络…
SVDiff: Compact Parameter Space for Diffusion Fine-Tuning——【论文笔记】
本文发表于ICCV 2023
论文地址:ICCV 2023 Open Access Repository (thecvf.com)
官方代码:mkshing/svdiff-pytorch: Implementation of "SVDiff: Compact Parameter Space for Diffusion Fine-Tuning" (github.com) 一、Introduction 最近几…
论文阅读-CARD:一种针对复制元数据服务器集群的拥塞感知请求调度方案
论文名称:CARD: A Congestion-Aware Request Dispatching Scheme for Replicated Metadata Server Cluster
摘要
复制元数据服务器集群(RMSC)在分布式文件系统中非常高效,同时面对数据驱动的场景(例如,大…

3D Line Mapping Revisited论文阅读
1. 代码地址
GitHub - cvg/limap: A toolbox for mapping and localization with line features.
2. 项目主页
3D Line Mapping Revisited
3. 摘要
提出了一种基于线的重建算法,Limap,可以从多视图图像中构建3D线地图,通过线三角化、精心…

【论文阅读笔记】InstantID : Zero-shot Identity-Preserving Generation in Seconds
InstantID:秒级零样本身份保持生成 理解摘要Introduction贡献 Related WorkText-to-image Diffusion ModelsSubject-driven Image GenerationID Preserving Image Generation Method实验定性实验消融实验与先前方法的对比富有创意的更多任务新视角合成身份插值多身份区域控制合…

论文阅读-通过云特征增强的深度学习预测云工作负载转折点
论文名称:Cloud Workload Turning Points Prediction via Cloud Feature-Enhanced Deep Learning
摘要
云工作负载转折点要么是代表工作负载压力的局部峰值点,要么是代表资源浪费的局部谷值点。预测这些关键点对于向系统管理者发出警告、采取预防措施以…
点云transformer算法: FlatFormer 论文阅读笔记
代码:https://github.com/mit-han-lab/flatformer论文:https://arxiv.org/abs/2301.08739[FlatFormer.pdf]
Flatformer是对点云检测中的 backbone3d部分的改进工作,主要在探究怎么高效的对点云应用transformer 具体的工作如下:一…
论文阅读-GROUP:一种聚焦于工作负载组行为的端到端多步预测方法
摘要
准确地预测工作负载可以使网络服务提供商实现应用程序的主动运行管理,确保服务质量和成本效益。对于云原生应用程序来说,多个容器协同处理用户请求,导致每个容器的工作负载变化受到工作负载组行为的影响。然而,现有方法主要…

论文笔记:相似感知的多模态假新闻检测
整理了RecSys2020 Progressive Layered Extraction : A Novel Multi-Task Learning Model for Personalized Recommendations)论文的阅读笔记 背景模型实验 论文地址:SAFE
背景 在此之前,对利用新闻文章中文本信息和视觉信息之间的关系(相似…
论文阅读-One for All : 动态多租户边缘云平台的统一工作负载预测
论文名称:One for All: Unified Workload Prediction for Dynamic Multi-tenant Edge Cloud Platforms
摘要
多租户边缘云平台中的工作负载预测对于高效的应用部署和资源供给至关重要。然而,在多租户边缘云平台中,异构的应用模式、可变的基…
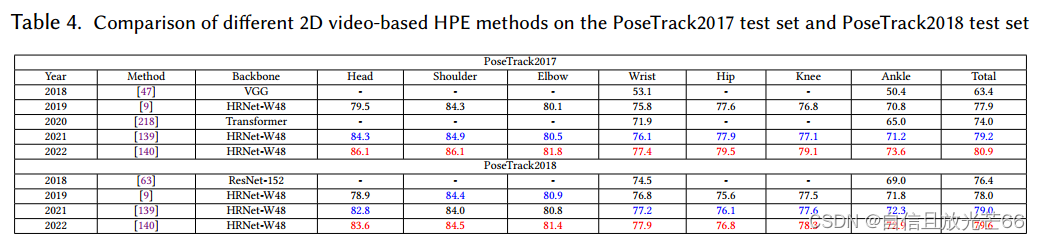
论文阅读:《Deep Learning-Based Human Pose Estimation: A Survey》——Part 1:2D HPE
目录
人体姿态识别概述
论文框架
HPE分类
人体建模模型
二维单人姿态估计
回归方法
目前发展
优化
基于热图的方法
基于CNN的几个网络
利用身体结构信息提供构建HPE网络
视频序列中的人体姿态估计
2D多人姿态识别
方法
自上而下
自下而上
2D HPE 总结
数据集…
论文阅读,ProtoGen: Automatically Generating Directory Cache Coherence Protocols(三)
目录
一、Article:文献出处(方便再次搜索)
(1)作者
(2)文献题目
(3)文献时间
(4)引用
二、Data:文献数据(总结归纳,方便理解&am…

Mopt: Optimized Mutation Scheduling For Fuzzers(2019)
目录
摘要:
背景知识:
1.模糊测试的工作流程包括:
2.突变调度器
3. 变异操作符:
4.从前的突变调度器的局限性
4.模糊器AFL的突变调度选择:
PSO粒子群优化算法:
MOPT主框架:
PSO初 始 …

论文阅读-面向机器学习的云工作负载预测模型的性能分析
论文名称:Performance Analysis of Machine Learning Centered Workload Prediction Models for Cloud
摘要
由于异构服务类型和动态工作负载的高变异性和维度,资源使用的精确估计是一个复杂而具有挑战性的问题。在过去几年中,资源使用和流…
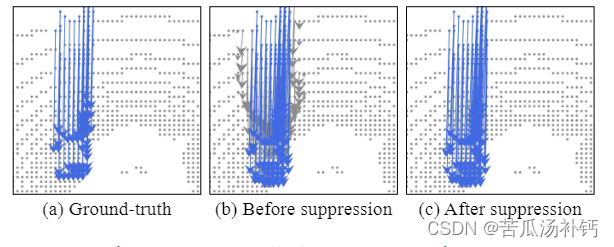
论文阅读:MotionNet基于鸟瞰图的自动驾驶联合感知和运动预测
MotionNet: Joint Perception and Motion Prediction for Autonomous Driving Based on Bird’s Eye View Maps
MotionNet:基于鸟瞰图的自动驾驶联合感知和运动预测
论文地址:MotionNet: Joint Perception and Motion Prediction for Autonomous Drivi…

【论文阅读】Deep Graph Contrastive Representation Learning
目录 0、基本信息1、研究动机2、创新点3、方法论3.1、整体框架及算法流程3.2、Corruption函数的具体实现3.2.1、删除边(RE)3.2.2、特征掩盖(MF) 3.3、[编码器](https://blog.csdn.net/qq_44426403/article/details/135443921)的设…
![[论文阅读]DeepFusion](https://img-blog.csdnimg.cn/direct/7aea0198a8a6438c84b14e0fb4ff44b6.png)
[论文阅读]DeepFusion
DeepFusion
Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection 用于多模态 3D 物体检测的激光雷达相机深度融合 论文网址:DeepFusion 论文代码:DeepFusion
摘要
激光雷达和摄像头是关键传感器,可为自动驾驶中的 3D 检测提供补…
【论文阅读】Relation-Aware Graph Transformer for SQL-to-Text Generation
Relation-Aware Graph Transformer for SQL-to-Text Generation
Abstract
SQL2Text 是一项将 SQL 查询映射到相应的自然语言问题的任务。之前的工作将 SQL 表示为稀疏图,并利用 graph-to-sequence 模型来生成问题,其中每个节点只能与 k 跳节点通信。由…
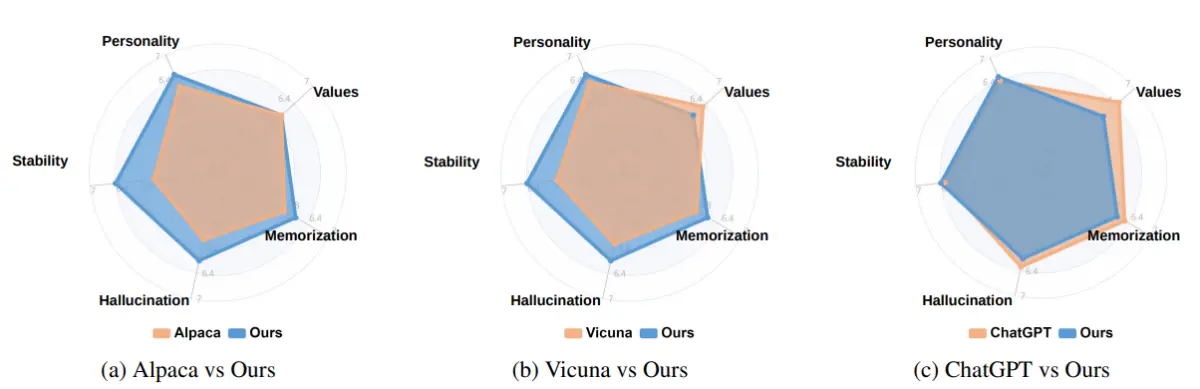
论文阅读_训练大模型用于角色扮演
英文名称: Character-LLM: A Trainable Agent for Role-Playing
中文名称: 角色-LLM:训练Agent用于角色扮演
文章: [https://arxiv.org/abs/2310.10158](https://arxiv.org/abs/2310.10158)
作者: Yunfan Shao, Linyang Li, Junqi Dai, Xipeng Qiu
机构: 复旦大学…

【论文阅读】ControlNet、文章作者 github 上的 discussions
文章目录 IntroductionMethodControlNetControlNet for Text-to-Image DiffusionTrainingInference Experiments消融实验定量分析 在作者 github 上的一些讨论消融实验更进一步的探索Precomputed ControlNet 加快模型推理迁移控制能力到其他 SD1.X 模型上其他 Introduction
提…
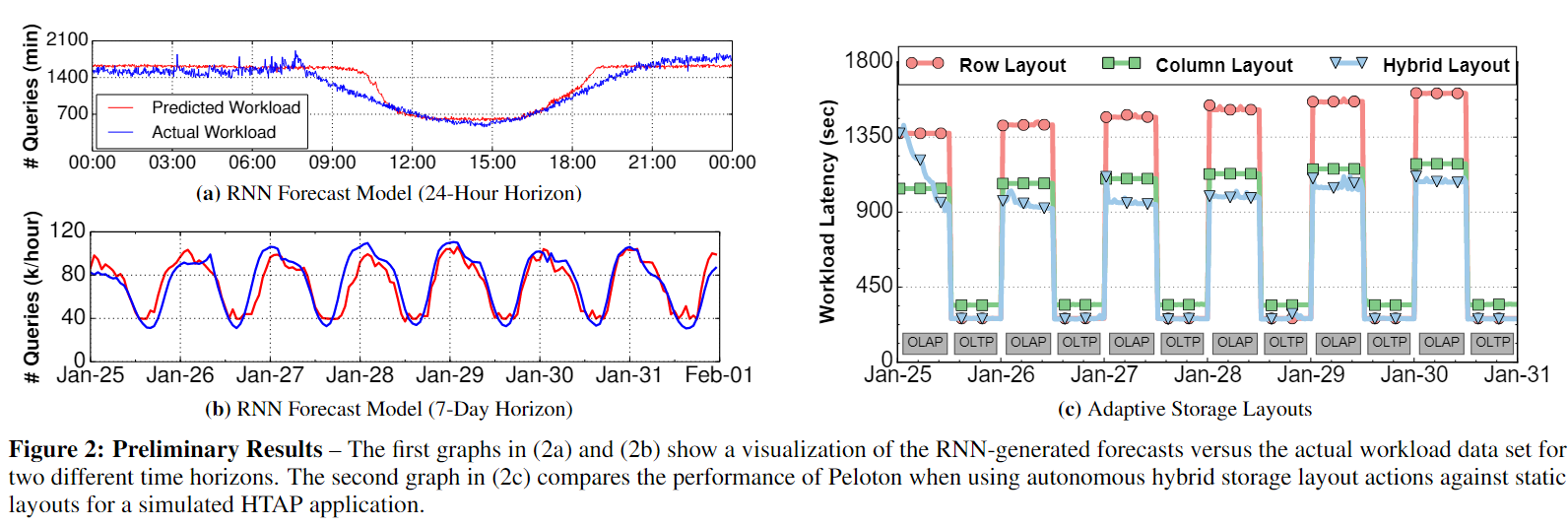
【论文阅读 CIDR17】Self-Driving Database Management Systems
Self-Driving Database Management Systems
MySummary
ABSTRACT
之前的advisory tools来帮助DBA处理系统调优和物理设计的各个方面,都仍然需要人类对数据库的任何更改做出最终决定,并且是在问题发生后修复问题的反动措施reactionary measures 。
An …
论文笔记:基于CLIP引导学习的多模式假新闻检测
整理了ICME2023 Multimodal Fake News Detection via CLIP-Guided Learning)论文的阅读笔记 背景模型实验 背景 对于我们这一代人来说,在线社交网络在很大程度上取代了以报纸和杂志为代表的传统信息交流方式。人们喜欢在社交媒体上寻找朋友或分享观点。然…
【论文阅读】Augmented Transformer network for MRI brain tumor segmentation
Zhang M, Liu D, Sun Q, et al. Augmented transformer network for MRI brain tumor segmentation[J]. Journal of King Saud University-Computer and Information Sciences, 2024: 101917. [开源] IF 6.9 SCIE JCI 1.58 Q1 计算机科学2区
【核心思想】
本文提出了一种新型…
【论文阅读 SIGMOD18】Query-based Workload Forecasting for Self-Driving
Query-based Workload Forecasting for Self-Driving Database Management Systems
My Summary
ABSTRACT
Autonomous DBMS的第一步就是能够建模并预测工作负载,以前的预测技术对查询的资源利用率进行建模。然而,当数据库的物理设计和硬件资源发生变化…
实例分割论文阅读之:FCN:《Fully Convolutional Networks for Semantica Segmentation》
论文地址:https://openaccess.thecvf.com/content_cvpr_2015/papers/Long_Fully_Convolutional_Networks_2015_CVPR_paper.pdf 代码链接:https://github.com/pytorch/vision
摘要
卷积网络是强大的视觉模型,可以产生特征层次结构。我们证明,…

WWW 2024 | 时间序列(Time Series)和时空数据(Spatial-Temporal)论文总结
WWW 2024已经放榜,本次会议共提交了2008篇文章,research tracks共录用约400多篇论文,录用率为20.2%。本次会议将于2024年5月13日-17日在新加坡举办。
本文总结了WWW 2024有关时间序列(Time Series)和时空数据…

【论文阅读|基于 YOLO 的红外小目标检测的逆向范例】
基于 YOLO 的红外小目标检测的逆向范例 摘要1 引言2 相关工作2.1 逆向推理2.2 物体检测方法 3 方法3.1 总体架构3.2 逆向标准的可微分积分 4 实验4.1 数据集和指标4.2 实验环境4.4 OL-NFA 为少样本环境带来稳健性 5 结论 论文题目: A Contrario Paradigm for YOLO-b…
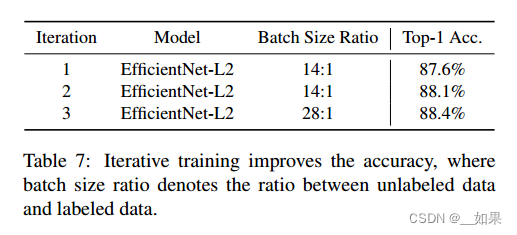
论文精读--Noisy Student
一个 EfficientNet 模型首先作为教师模型在标记图像上进行训练,为 300M 未标记图像生成伪标签。然后将相同或更大的 EfficientNet 作为学生模型并结合标记图像和伪标签图像进行训练。学生网络训练完成后变为教师再次训练下一个学生网络,并迭代重复此过程…

YOLOv9改进 | 一文带你了解全新的SOTA模型YOLOv9(论文阅读笔记,效果完爆YOLOv8)
官方论文地址: 官方论文地址点击即可跳转
官方代码地址: 官方代码地址点击即可跳转 图1. 在MS COCO数据集上实时对象检测器的比较。基于GELAN和PGI的对象检测方法在对象检测性能方面超越了所有以前的从头开始训练的方法。在准确性方面,新方法…

论文阅读《Sylph: A Hypernetwork Framework for Incremental Few-shot Object Detection》
论文地址:https://arxiv.org/abs/2203.13903 代码地址:https://github.com/facebookresearch/sylph-few-shot-detection 目录 1、存在的问题2、算法简介3、算法细节3.1、基础检测器3.2、小样本超网络3.2.1、支持集特征提取3.2.2、代码预测3.2.3、代码聚合…

论文笔记:利用词对比注意增强预训练汉字表征
整理了 ACL2020短文 Enhancing Pre-trained Chinese Character Representation with Word-aligned Att)论文的阅读笔记 背景模型实验 论文地址:论文
背景 近年来,以 BERT 为代表的预训练模型在 NLP 领域取得取得了非常显著的效果。但是&…

论文阅读笔记——PathAFL:Path-Coverage Assisted Fuzzing
文章目录 前言PathAFL:Path-Coverage Assisted Fuzzing1、解决的问题和目标2、技术路线2.1、如何识别 h − p a t h h-path h−path?2.2、如何减少 h − p a t h h-path h−path的数量?2.3、哪些h-path将被添加到种子队列?2.4、种…
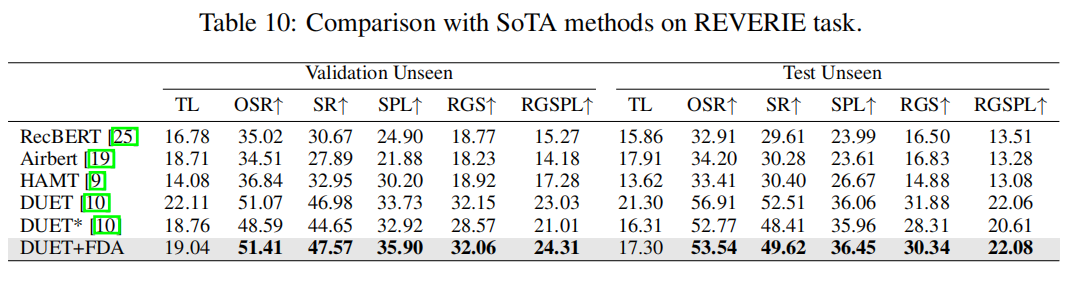
基于频率增强的数据增广的视觉语言导航方法(VLN论文阅读)
基于频率增强的数据增广的视觉语言导航方法(VLN论文阅读) 摘要 视觉和语言导航(VLN)是一项具有挑战性的任务,它需要代理基于自然语言指令在复杂的环境中导航。 在视觉语言导航任务中,之前的研究主要是在空间…
《论文阅读》利用提取的情感原因提高共情对话生成的内容相关性 CCL 2022
《论文阅读》利用提取的情感原因提高共情对话生成的内容相关性 前言简介模型架构情绪识别情绪原因提取实验结果示例总结前言
亲身阅读感受分享,细节画图解释,再也不用担心看不懂论文啦~ 无抄袭,无复制,纯手工敲击键盘~
今天为大家带来的是《Using Extracted Emotion Caus…
《论文阅读》一个基于情感原因的在线共情聊天机器人 SIGIR 2021
《论文阅读》一个基于情感原因的在线共情聊天机器人 前言简介数据集构建模型架构损失函数实验结果咨询策略总结前言
亲身阅读感受分享,细节画图解释,再也不用担心看不懂论文啦~ 无抄袭,无复制,纯手工敲击键盘~
今天为大家带来的是《Towards an Online Empathetic Chatbot…
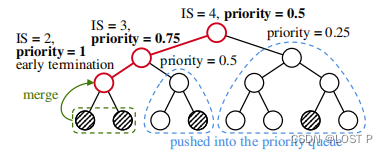
【USENIX论文阅读】Day2
Birds of a Feather Flock Together: How Set Bias Helps to Deanonymize You via Revealed Intersection Sizes("物以类聚:集合偏差如何帮助去匿名化——通过揭示交集大小) Xiaojie Guo, Ye Han, Zheli Liu, Ding Wang, Yan Jia, Jin L…
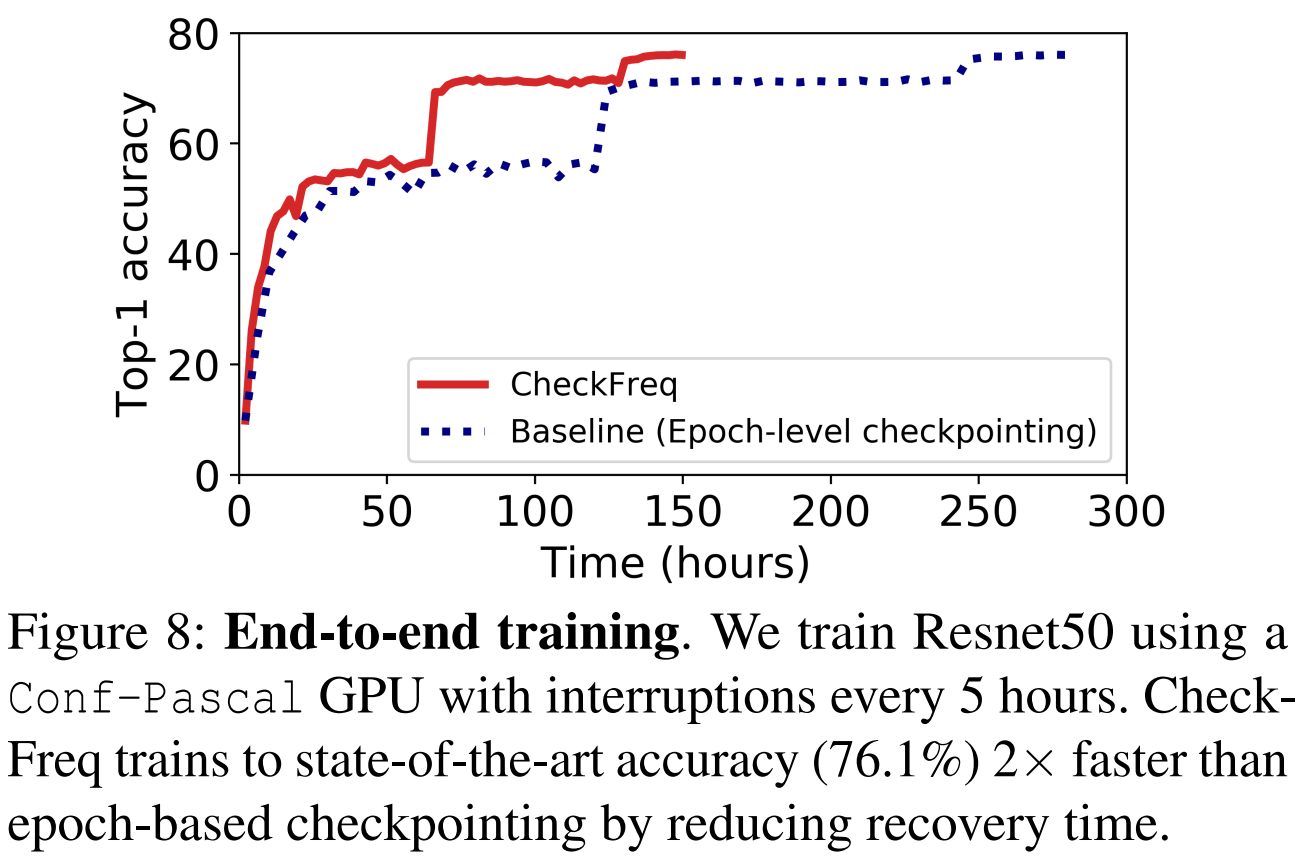
论文阅读-CheckFreq:频繁、精细的DNN检查点操作。
论文名称:CheckFreq: Frequent, Fine-Grained DNN Checkpointing.
摘要
训练深度神经网络(DNNs)是一项资源密集且耗时的任务。在训练过程中,模型在GPU上进行计算,重复地学习权重,持续多个epoch。学习到的权重存在GPU内存中&…
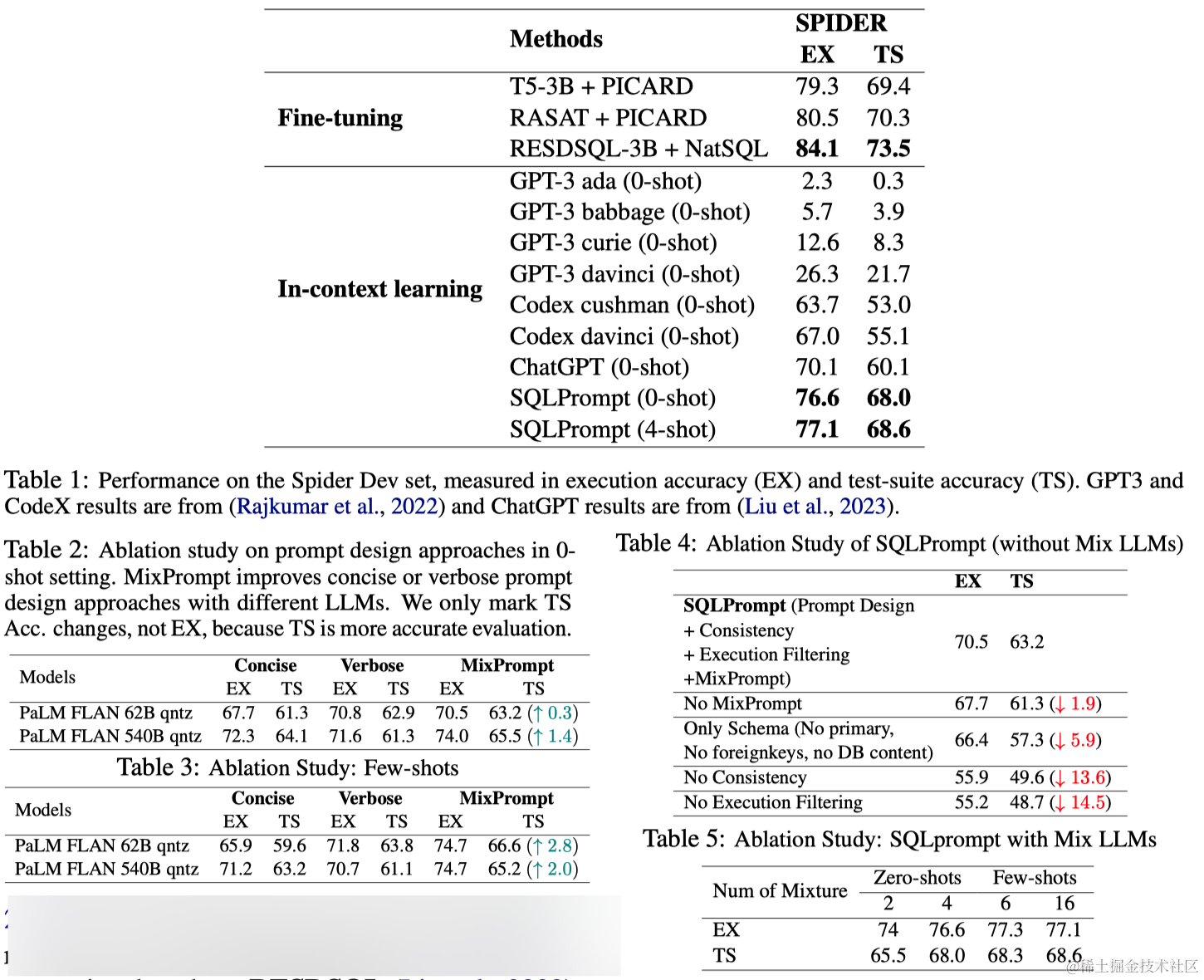
论文笔记:SQLPrompt: In-Context Text-to-SQL with Minimal Labeled Data
导语
本文提出了SQLPrompt,通过创新的Prompt设计、基于执行一致性的解码策略,以及混合不同格式的Prompt和不同LLMs输出的方式,提高了LLM在Few-shot In-context Learning下的能力。
会议:EMNLP 2023 Findings (Short&…

【论文笔记】Multi-Chain Reasoning:对多思维链进行元推理
目录 写在前面1. 摘要2. 相关知识3. MCR方法3.1 生成推理链3.2 基于推理链的推理 4. 实验4.1 实验设置4.2 实验结果 5. 提及文献 写在前面
文章标题:Answering Questions by Meta-Reasoning over Multiple Chains of Thought论文链接:【1】代码链接&…

计算机毕业设计 | SSM 旅游网站后台管理系统(附源码)
1,概述
1.1 背景分析
随着人们生活水平的提高和对休闲旅游的日益重视,旅游业已成为全球最大的经济产业之一。越来越多的人选择通过在线方式进行旅行预订,这种趋势为旅游网站提供了巨大的商机。用户体验是决定旅游网站成功与否的关键因素。良…

【论文笔记】Attention Is All You Need
【论文笔记】Attention Is All You Need 文章目录 【论文笔记】Attention Is All You NeedAbstract1 Introduction2 Background补充知识:软注意力 soft attention 和硬注意力 hard attention?补充知识:加法注意力机制和点乘注意力机制Extende…
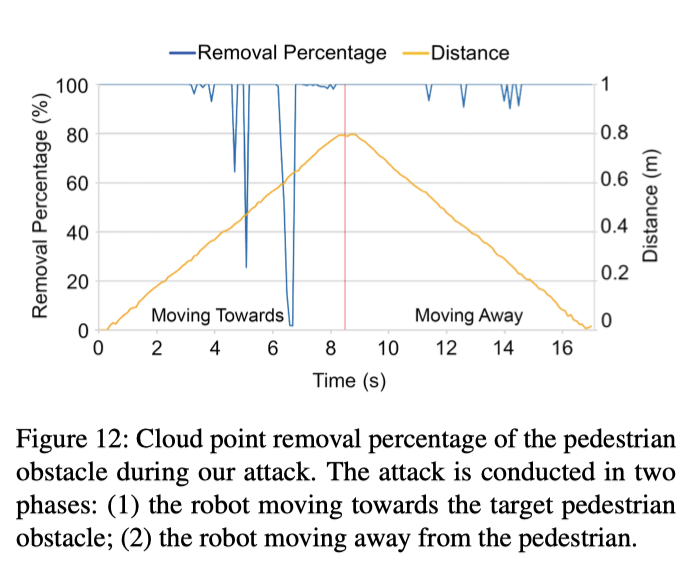
【论文阅读】Usenix Security 2023 你看不见我:对基于激光雷达的自动驾驶汽车驾驶框架的物理移除攻击
文章目录 一.论文信息二.论文内容1.摘要2.引言3.作者贡献4.主要图表5.结论 一.论文信息
论文题目: You Can’t See Me: Physical Removal Attacks on LiDAR-based Autonomous Vehicles Driving Frameworks(你看不见我:对基于激光雷达的自动驾驶汽车驾驶…

论文笔记:A survey on zero knowledge range proofs and applications
https://link.springer.com/article/10.1007/s42452-019-0989-z
描述了构建零知识区间证明(ZKRP)的不同策略,例如2001年Boudot提出的方案;2008年Camenisch等人提出的方案;以及2017年提出的Bulletproofs。
Introducti…
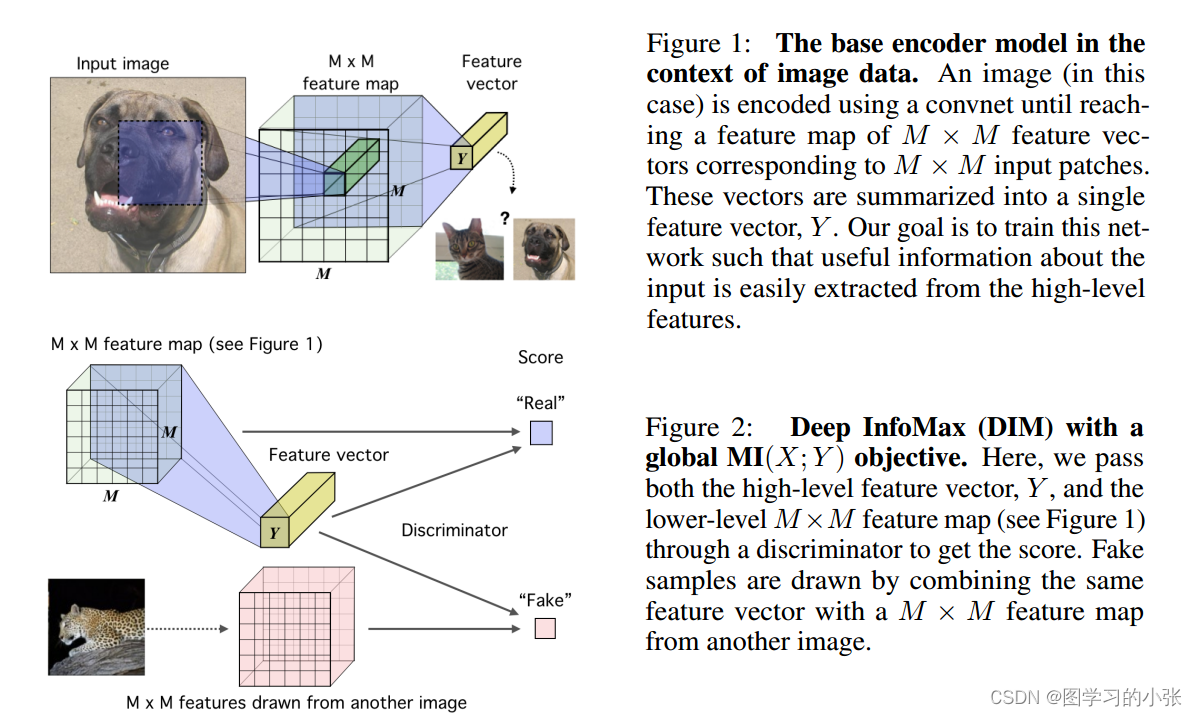
论文笔记:基于互信息估计和最大化的深度表示学习
整理了ICLR2019 LEARNING DEEP REPRESENTATIONS BY MUTUAL INFORMATION ESTIMATION AND MAXIMIZATION)论文的阅读笔记 背景模型 论文地址:DIM code:代码地址
背景 发现有用的表示是深度学习的一个核心目标,由于之前的工作已经可以…

论文阅读:2015ResNet深度残差网络(待补充)
top5错误率:每张图片算法都会给出它认为最可能的五个类别,五个里面有一个是正确则算法预测正确。 技术爆炸1:2012年,DL和CNN用于CV;技术爆炸2:2015年,超过人类水平,网络可以更深&…

【论文阅读-PRIVGUARD】Day4:3节
3 PRIVANALYZER:强制执行隐私政策的静态分析
本节介绍PRIVANALYZER,这是一个用于强制执行由PRIVGUARD追踪的隐私政策的静态分析器**。我们首先回顾LEGALEASE政策语言,我们使用它来正式编码政策,然后描述如何静态地强制执行它们**…

论文阅读:基于超像素的图卷积语义分割(图结构数据)
#Superpixel-based Graph Convolutional Network for Semantic Segmentation github链接 引言 GNN模型根据节点特征周围的边来训练节点特征,并获得最终的节点嵌入。通过利用具有不同滤波核的二维卷积对来自附近节点的信息进行整合,给定超像素方法生成的…

多模态论文阅读-LLaVA
Visual Instruction Tuning Abstract1. Introduction2. Related Work3. GPT-assisted Visual Instruction Data Generation4. Visual Instruction Tuning4.1 Architecture4.2 Training 5 Experiments5.1 Multimodal Chatchot5.2 ScienceQA 6 Conclusion Abstract
使用机器生成…

2024环境工程、能源系统与化学材料国际会议(ICEEESCM 2024)
2024环境工程、能源系统与化学材料国际会议(ICEEESCM 2024)
一、【会议简介】
2024环境工程、能源系统与化学材料国际会议(ICEEESCM 2024)将于2024年在西安举行。会议将围绕环境工程、能源系统与化学材料等议题展开讨论,旨在为从事环境工程…

【论文阅读】《Graph Neural Prompting with Large Language Models》
文章目录 0、基本信息1、研究动机2、创新点3、准备3.1、知识图谱3.2、多项选择问答3.3、提示词工程(prompt engineering) 4、具体实现4.1、提示LLMs用于问答4.2、子图检索4.3、Graph Neural Prompting4.3.1、GNN Encoder4.3.2、Cross-modality Pooling4.…

Synthetic Temporal Anomaly Guided End-to-End Video Anomaly Detection 论文阅读
Synthetic Temporal Anomaly Guided End-to-End Video Anomaly Detection 论文阅读 Abstract1. Introduction2. Related Work3. Methodology3.1. Architecture3.1.1 Autoencoder3.1.2 Temporal Pseudo Anomaly Synthesizer 3.2. Training3.3. Anomaly Score 4. Experiments4.1.…

YOLOv9理性解读 | 网络结构损失函数耗时评估
论文:https://arxiv.org/pdf/2402.13616.pdfHuggingFace Demo:https://hf-mirror.com/spaces/kadirnar/Yolov9Github:https://github.com/WongKinYiu/yolov9
由台北中研院和台北科技大学等机构的研究团队推出的新的目标检测算法,…
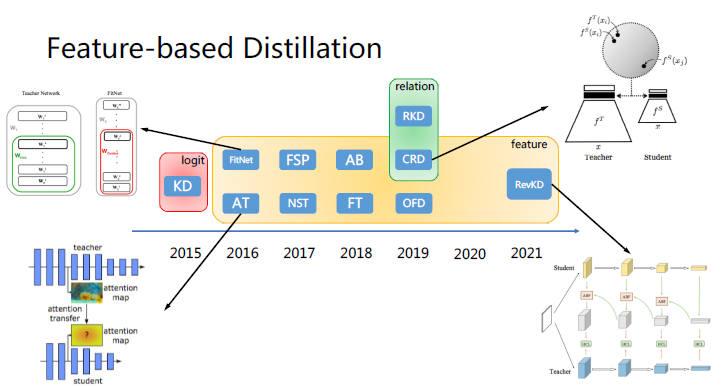
论文阅读:2022Decoupled Knowledge Distillation解耦知识蒸馏
SOTA的蒸馏方法往往是基于feature蒸馏的,而基于logit蒸馏的研究被忽视了。为了找到一个新的切入点去分析并提高logit蒸馏,我们将传统的KD分成了两个部分:TCKD和NCKD。实验表明:TCKD在传递和样本难度有关的知识,同时NCK…

【论文阅读】《PRODIGY: Enabling In-context Learning Over Graphs》
文章目录 0、基本介绍1、研究动机2、创新点3、挑战4、准备4.1、图上分类任务4.2、少样本提示4.3、提示图表示4.3.1、Data graph G D \mathcal{G}^D GD4.3.2、task graph G T \mathcal{G}^T GT 5、方法论5.1、提示图上的信息传播架构5.1.1、Data graph Message Passing5.1.2、…
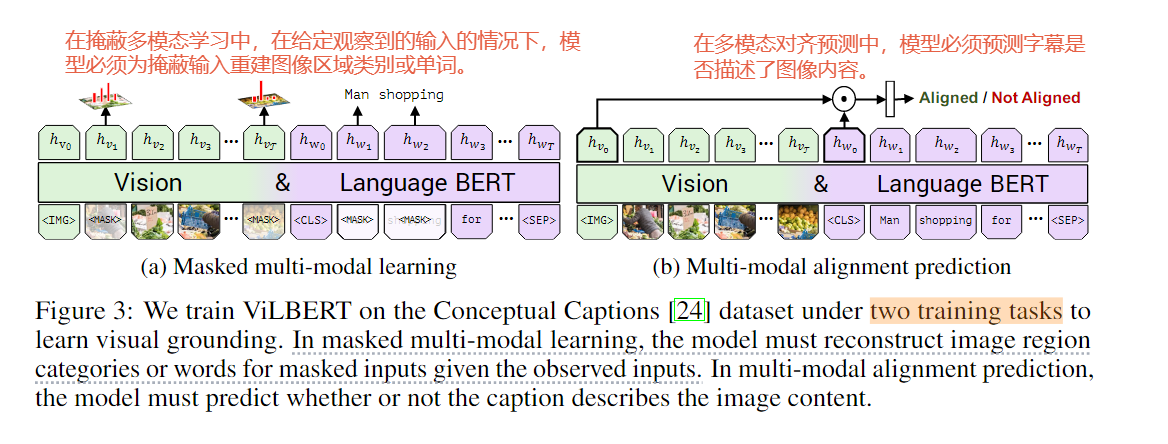
【论文阅读-基于VilLBERT方法的导航】Vison-Language Navigation 视觉语言导航(2)
文章目录 1. 【2023ICCV】Learning Vision-and-Language Navigation from YouTube Videos摘要和结论引言Building VLN Dataset from YouTube Videos模型框架实验 2. 【2021ICCV】Airbert: In-domain Pretraining for Vision-and-Language Navigation摘要和结论引言BnB DatasetA…
【论文阅读】基于图像处理和卷积神经网络的板式换热器气泡识别与跟踪
Bubble recognizing and tracking in a plate heat exchanger by using image processing and convolutional neural network 基于图像处理和卷积神经网络的板式换热器气泡识别与跟踪 期刊信息:International Journal of Multiphase Flow 2021 期刊级别:…
NERF论文笔记(1/2)
NeRF:Representing Scene as Neural Radiance Fields for View Synthesis 笔记
摘要
实现了一个任意视角视图生成算法:输入稀疏的场景图像,通过优化连续的Volumetric场景函数实现;用全连接深度网络表达场景,输入是一个连续的5维…

【论文笔记】Improving Language Understanding by Generative Pre-Training
Improving Language Understanding by Generative Pre-Training 文章目录 Improving Language Understanding by Generative Pre-TrainingAbstract1 Introduction2 Related WorkSemi-supervised learning for NLPUnsupervised pre-trainingAuxiliary training objectives 3 Fra…
论文阅读---CASCADING REINFORCEMENT LEARNING
论文概述:
本文主要介绍了一种名为"Cascading Reinforcement Learning"(级联强化学习)的算法,用于解决在学习过程中存在多个阶段和多个决策点的问题。该算法使用了一种级联的马尔可夫决策过程来建模学习环境࿰…

【论文阅读】CVPR 2023 色彩后门:色彩空间中的鲁棒中毒攻击
文章目录 一.论文信息二.论文内容1.摘要2.引言4.主要图表5.结论 一.论文信息
论文题目: Color Backdoor: A Robust Poisoning Attack in Color Space(色彩后门:色彩空间中的鲁棒中毒攻击)
论文来源: 2023-CVPR
论文团队&#x…

论文阅读_代码生成模型_CodeLlama
英文名称: Code Llama: Open Foundation Models for Code
中文名称: Code Llama:开放基础代码模型
链接: https://arxiv.org/abs/2308.12950
代码: https://github.com/facebookresearch/codellama
作者: Baptiste Rozire, Jonas Gehring, Fabian Gloeckle, Sten So…
Towards Interpretable Video Anomaly Detection 论文阅读
Towards Interpretable Video Anomaly Detection 论文阅读 Abstract1. Introduction2. Related Work3. Proposed Technique3.1. Overall Structure3.2. Global Object Monitoring3.3. Local Object Monitoring3.4. Sequential Anomaly Detection3.5. Anomaly Interpretation3.6…

《基于ICEEMDAN 和分布熵的SS-Y伸缩仪信号随机噪声压制方法》论文笔记
吴林斌.基于ICEEMDAN 和分布熵的SS-Y 伸缩仪信号随机噪声压制方法[J/OL].大地测量与地球动力学. https://doi.org/10.14075/j.jgg.2023.07.103 CEEMDAN和ICEEMDAN性质差不多,只是改良了一下 这篇文章相较于上级篇文章,没有用方差…
论文阅读-高效构建检查点
论文标题:On Efficient Constructions of Checkpoints
摘要
高效构建检查点/快照是训练和诊断深度学习模型的关键工具。在本文中,我们提出了一种适用于检查点构建的有损压缩方案(称为LC-Checkpoint)。LC-Checkpoint同时最大化了…
最佳 PDF 转 Word 转换器软件,可实现无缝转换
如今,PDF文件格式因其高安全性而被计算机用户所熟悉,这使得无法直接编辑内容。因此,每当用户需要复制内容时,都会遇到很多困难。在这里将介绍了一些可以让您将 PDF 转换为 Word 的工具。 借助高效、免费的 PDF 转 Word 转换器软件…
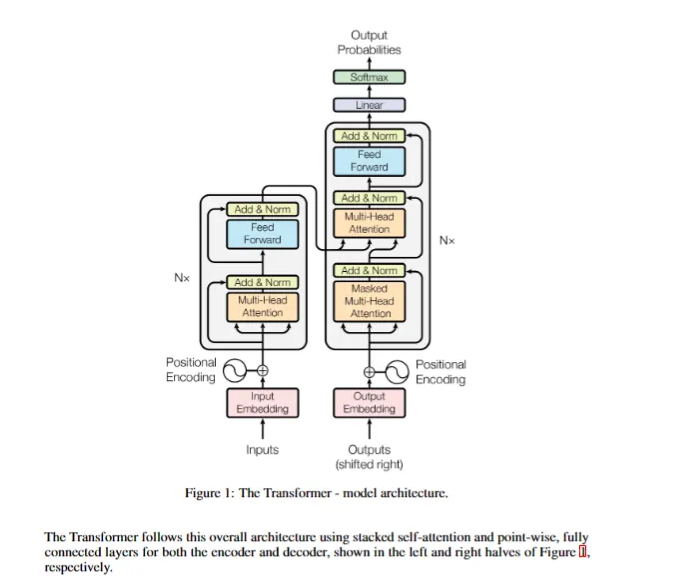
ChatGPT 4.0使用之论文阅读
文章目录 阅读环境准备打开AskYourPDF进入主站 粗读论文直接通过右侧边框进行提问选中文章内容翻译或概括插图的理解 总结 拥有了GPT4.0之后,最重要的就是学会如何充分发挥它的强大功能,不然一个月20美元的费用花费的可太心疼了(家境贫寒&…

Matryoshka Representation Learning (MRL)-俄罗斯套娃向量表征学习
前言
在2024年1月底OpenAI发布新的向量模型,并提到新的向量模型支持将向量维度缩短。向量模型支持缩短维度而又不会威胁到向量的表示能力的原因在于使用了Matryoshka Representation Learning。 Matryoshka Representation Learning (MRL)是2022年发表的论文&#…

AI论文速读 | STG-LLM 大语言模型如何理解时空数据?
论文标题:How Can Large Language Models Understand Spatial-Temporal Data?
论文链接:https://arxiv.org/abs/2401.14192
作者:Lei Liu, Shuo Yu, Runze Wang, Zhenxun Ma, Yanming Shen(申彦明)
关键词…
AI论文速读 | 【综述】(LLM4TS)大语言模型用于时间序列
题目:Large Language Models for Time Series: A Survey
作者:Xiyuan Zhang , Ranak Roy Chowdhury , Rajesh K. Gupta and Jingbo Shang
机构:加州大学圣地亚哥分校(UCSD)
网址:https://arxiv.org/abs/…

【论文翻译】结构化状态空间模型
文章目录 3.2 对角结构化状态空间模型3.2.1 S4D:对角SSM算法3.2.2 完整应用实例 3.3 对角化加低秩(DPLR)参数化3.3.1 DPLR 状态空间核算法3.3.2 S4-DPLR 算法和计算复杂度3.3.3赫尔维兹(稳定)DPLR形式 这篇文章是Mamba作者博士论文…

论文阅读:PrivateSQL: A Differentially Private SQL Query Engine
基本信息
来源:PVLDB Endowment 2019 Duke University Ios Kotsogiannis 团队 主方向Theory of database privacy and security key word:Differential privacy 差分隐私
Abstract
差分隐私被认为是隐私数据分析的事实标准。但是,该定义和…

论文阅读:《High-Resolution Image Synthesis with Latent Diffusion Models》
High-Resolution Image Synthesis with Latent Diffusion Models
论文链接 代码链接
What’s the problem addressed in the paper?(这篇文章究竟讲了什么问题?比方说一个算法,它的 input 和 output 是什么?问题的条件是什么)
这篇文章提…

论文阅读:SOLOv2: Dynamic, Faster and Stronger
目录
概要
Motivation
整体架构流程
技术细节
小结 论文地址:[2003.10152] SOLOv2: Dynamic and Fast Instance Segmentation (arxiv.org)
代码地址:GitHub - WXinlong/SOLO: SOLO and SOLOv2 for instance segmentation, ECCV 2020 & NeurIPS…

浅析扩散模型与图像生成【应用篇】(八)——BBDM
8. BBDM: Image-to-Image Translation with Brownian Bridge Diffusion Models 本文提出一种基于布朗桥(Brownian Bridge)的扩散模型用于图像到图像的转换。图像到图像转换的目标是将源域 A A A中的图像 I A I_A IA,映射到目标域 B B B中得…

《Balanced Meta-Softmax for Long-Tailed Visual Recognition》阅读笔记
论文标题
《Balanced Meta-Softmax for Long-Tailed Visual Recognition》
用于长尾视觉识别的平衡元-Softmax
作者
Jiawei Ren、Cunjun Yu、Shunan Sheng、Xiao Ma、Haiyu Zhao、Shuai Yi 和 Hongsheng Li
商汤科技、南洋理工大学、新加坡国立大学和香港中文大学多媒体实…

AI论文速读 | 【综述】城市计算中跨域数据融合的深度学习:分类、进展和展望
题目:Deep Learning for Cross-Domain Data Fusion in Urban Computing: Taxonomy, Advances, and Outlook
作者:Xingchen Zou, Yibo Yan, Xixuan Hao, Yuehong Hu, Haomin Wen(温皓珉), Erdong Liu, Junbo Zhang(张钧…
论文阅读:Scalable Diffusion Models with Transformers
Scalable Diffusion Models with Transformers
论文链接
介绍
传统的扩散模型基于一个U-Net骨架,这篇文章提出了一种新的扩散模型结构,将U-Net替换为一个transformer,并将这种结构称为Diffusion Transformers (DiTs)。他们还发现ÿ…
【论文阅读笔记】Activating More Pixels in Image Super-Resolution Transformer
论文地址:https://arxiv.org/abs/2205.04437 代码位置:https://github.com/XPixelGroup/HAT
论文小结 本文方法是基于Transformer的方法,探索了Transformer在低级视觉任务(如SR)中的应用潜力。本文提升有效利用像素范…

【论文阅读】(WALT)Photorealistic Video Generation with Diffusion Models
(WALT)Photorealistic Video Generation with Diffusion Models 文章目录 (WALT)Photorealistic Video Generation with Diffusion Models论文概述WALTLearning Visual TokensLearning to Generate Images and VideosConditional …
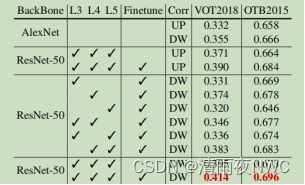
Siamrpn++论文中文翻译(详细!)
SiamRPN: Evolution of Siamese Visual Tracking with Very Deep Networks
SiamRPN:具有非常深度网络的Siamese视觉跟踪的进化 【siamrpn论文地址】
https://arxiv.org/abs/1812.11703 摘要
基于Siamese网络的跟踪器将跟踪表示为目标模板和搜索区域之间的卷积特征…

知识图谱 | 2023年图书馆学、情报学CSSCI期刊论文主题透视
数据来源 检索平台来源期刊年份有效数据中国知网大学图书馆学报国家图书馆学刊情报科学情报理论与实践情报学报情报杂志情报资料工作数据分析与知识发现图书馆建设图书馆论坛图书馆学研究图书馆杂志图书情报工作图书情报知识图书与情报现代情报信息资源管理学报中国图书馆学报2…
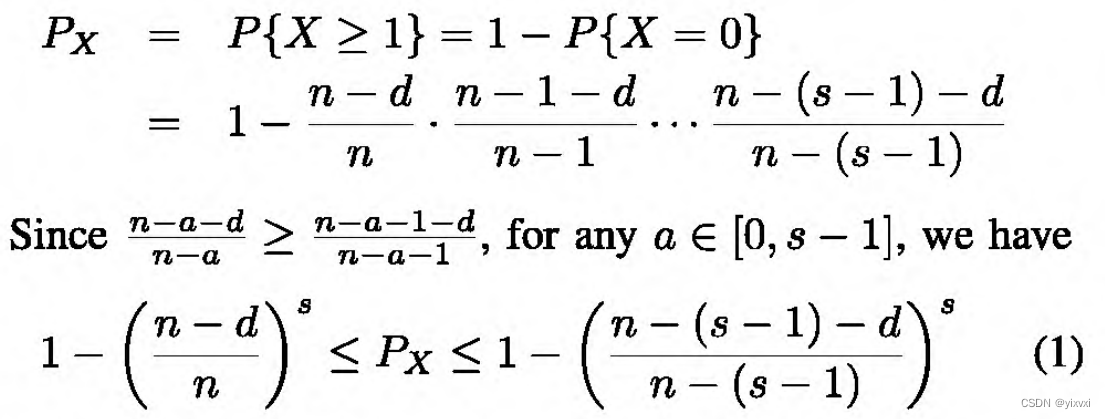
论文笔记:Efficient Bootstrapping for Confidential Transactions
EcoBoost: Efficient Bootstrapping for Confidential Transactions
设计了一种被称为EcoBoost的新方法,以提高支持机密交易的区块链的引导效率。具体来说,利用随机抽样来验证高概率保密交易的正确性。因此,与事务数量相比**,验证…
动态SLAM论文阅读笔记
近期阅读了许多动态SLAM相关的论文,它们基本都是基于ORB-SLAM算法,下面简单记录一下它们的主要特点:
1.DynaSLAM
采用CNN网络进行分割多视图几何辅助的方式来判断动态点,并进行了背景修复工作。
2.Detect-SLAM
实时性问题&…

【论文阅读】High-Resolution Image Synthesis with Latent Diffusion Model
High-Resolution Image Synthesis with Latent Diffusion Model
引用: Rombach R, Blattmann A, Lorenz D, et al. High-resolution image synthesis with latent diffusion models[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern re…

【论文阅读】Mamba:选择状态空间模型的线性时间序列建模(一)
文章目录 Mamba:选择状态空间模型的线性时间序列建模介绍状态序列模型选择性状态空间模型动机:选择作为一种压缩手段用选择性提升SSM 选择性SSM的高效实现先前模型的动机选择扫描总览:硬件感知状态扩展 Mamba论文 Mamba:选择状态空间模型的线性时间序列建…

【论文笔记】Language Models are Unsupervised Multitask Learners
Language Models are Unsupervised Multitask Learners 回顾一下第一代 GPT-1 : 设计思路是 “海量无标记文本进行无监督预训练少量有标签文本有监督微调” 范式;模型架构是基于 Transformer 的叠加解码器(掩码自注意力机制、残差、Layernorm…
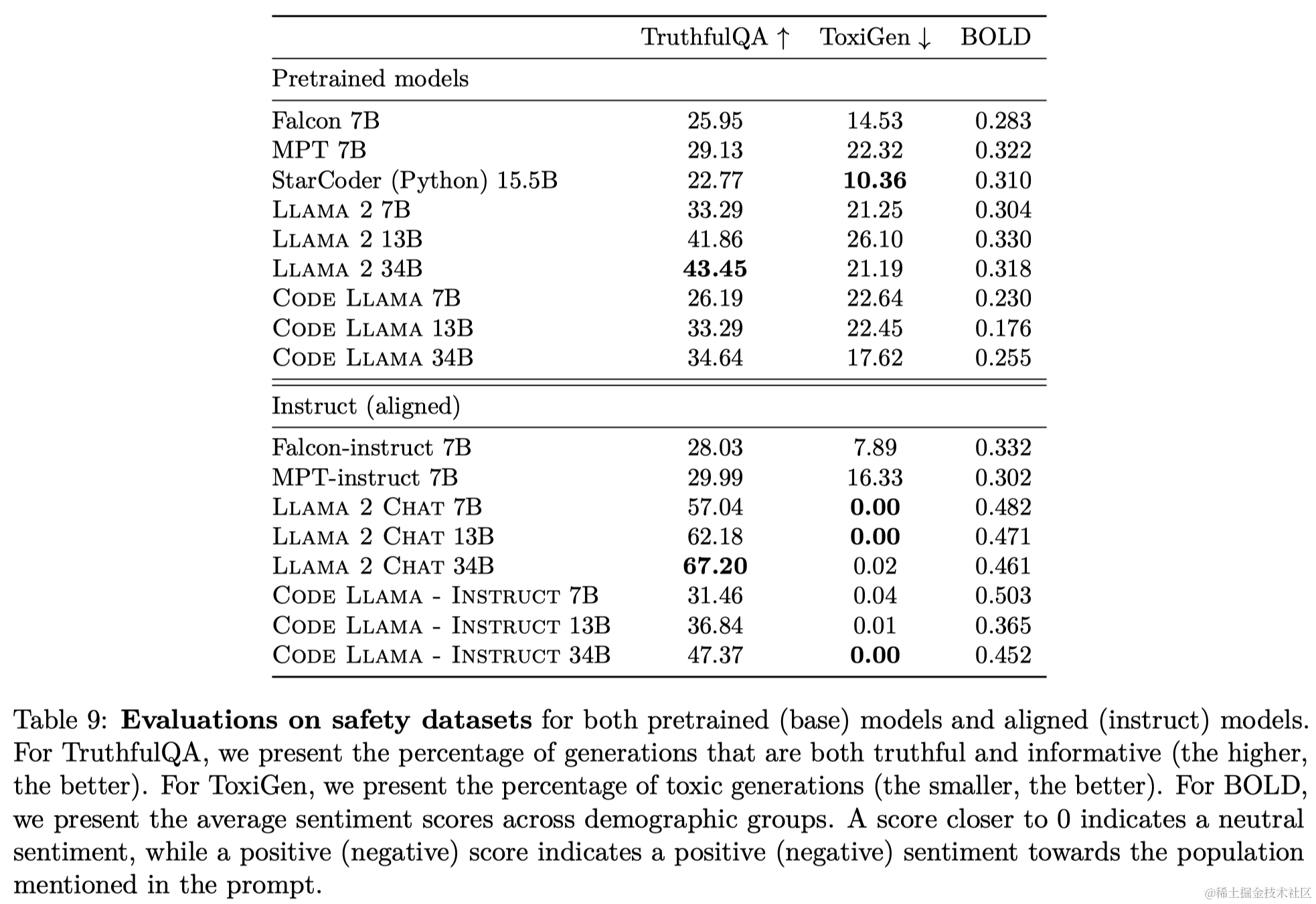
论文笔记:Code Llama: Open Foundation Models for Code
导语
Code Llama是开源模型Llama 2在代码领域的一个专有模型,作者通过在代码数据集上进行进一步训练得到了了适用于该领域的专有模型,并在测试基准中超过了同等参数规模的其他公开模型。
链接:https://arxiv.org/abs/2308.12950机构&#x…

【论文阅读】Mamba:选择状态空间模型的线性时间序列建模(二)
文章目录 3.4 一个简化的SSM结构3.5 选择机制的性质3.5.1 和门控机制的联系3.5.2 选择机制的解释 3.6 额外的模型细节A 讨论:选择机制C 选择SSM的机制 Mamba论文 第一部分
Mamba:选择状态空间模型的线性时间序列建模(一) 3.4 一个简化的SSM结构
如同结构SSM&#…

【论文阅读】Segment Anything论文梳理
Abstract 我们介绍了Segment Anything(SA)项目:新的图像分割任务、模型和数据集。高效的数据循环采集,使我们建立了迄今为止最大的分割数据集,在1100万张图像中,共超过10亿个掩码。 该模型被设计和训练为可…
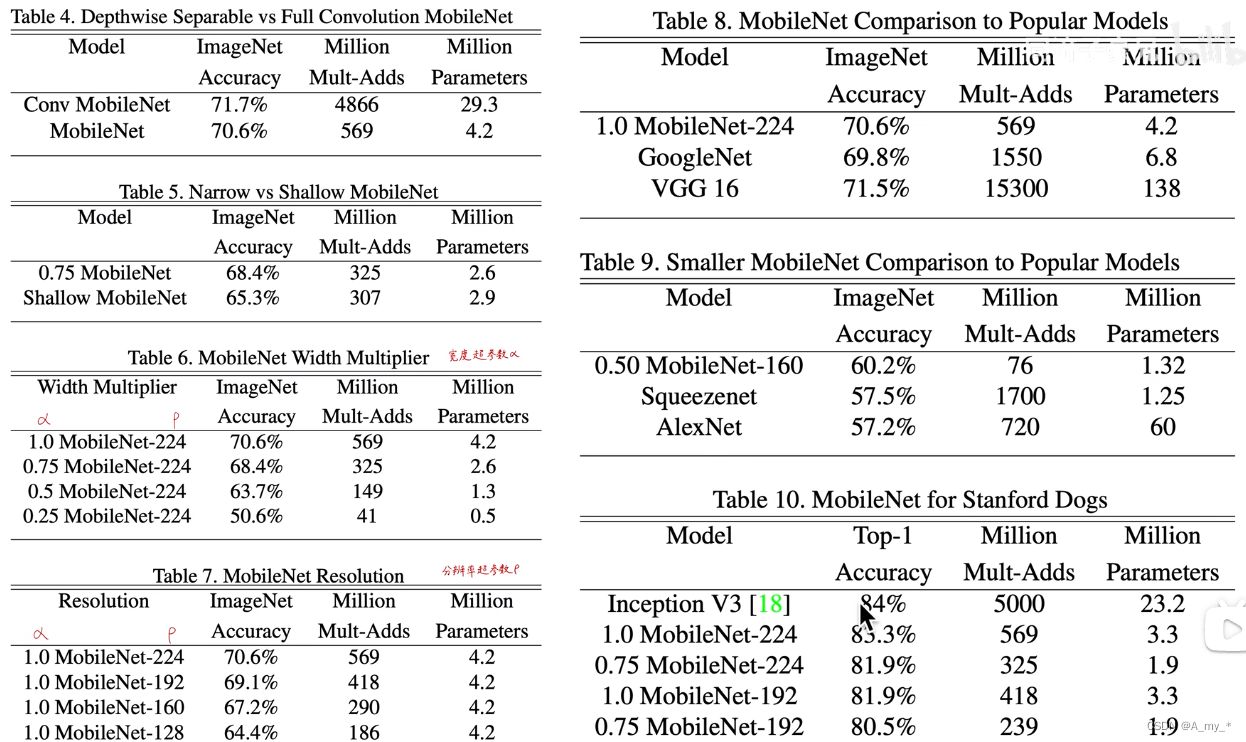
论文阅读:2017MobileNet V1谷歌轻量化卷积神经网络
拓展:贾扬清:深度学习框架caffe(Convolutional Architecture for Fast Feature Embedding)
主要贡献:
深度可分离卷积(Depthwise separable convolution)逐点卷积(Pointwise convo…
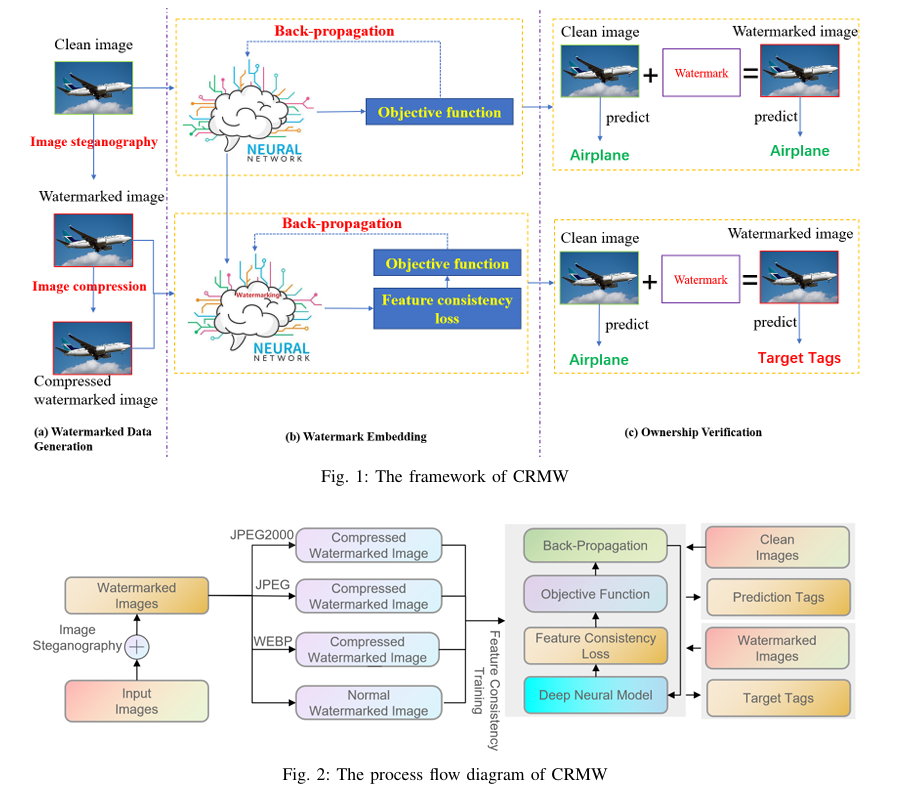
【图像版权】论文阅读:CRMW 图像隐写术+压缩算法
不可见水印 前言背景介绍ai大模型水印生成产物不可见水印CRMW 在保护深度神经网络模型知识产权方面与现有防御机制有何不同?使用图像隐写术和压缩算法为神经网络模型生成水印数据集有哪些优势?特征一致性训练如何发挥作用,将水印数据集嵌入到…
[论文笔记] Open-sora 2、视频数据集介绍 MSR-VTT
MSR-VTT
COVE - Computer Vision Exchange
论文参考:https://www.microsoft.com/en-us/research/wp-content/uploads/2016/06/cvpr16.msr-vtt.tmei_-1.pdf 用于视频理解的大规模视频基准,特别是将视频翻译为文本的新兴任务。这是通过从商业视频搜索引擎收集 257 个热门查询…
论文阅读--A Survey of Meta-Reinforcement Learning
论文概述 本文是一篇关于元强化学习(Meta Reinforcement Learning)的综述。元强化学习是将改进强化学习算法的发展看作是一个机器学习问题的方法,通过在给定任务分布的情况下学习一个能够适应任何新任务的策略,来提高强化学习算法…

浅析扩散模型与图像生成【应用篇】(七)——Prompt-to-Prpmpt
7. Prompt-to-Prompt Image Editing with Cross Attention Control 本文提出一种利用交叉注意力机制实现文本驱动的图像编辑方法,可以对生成图像中的对象进行替换,整体改变图像的风格,或改变某个词对生成图像的影响程度,如下图所示…
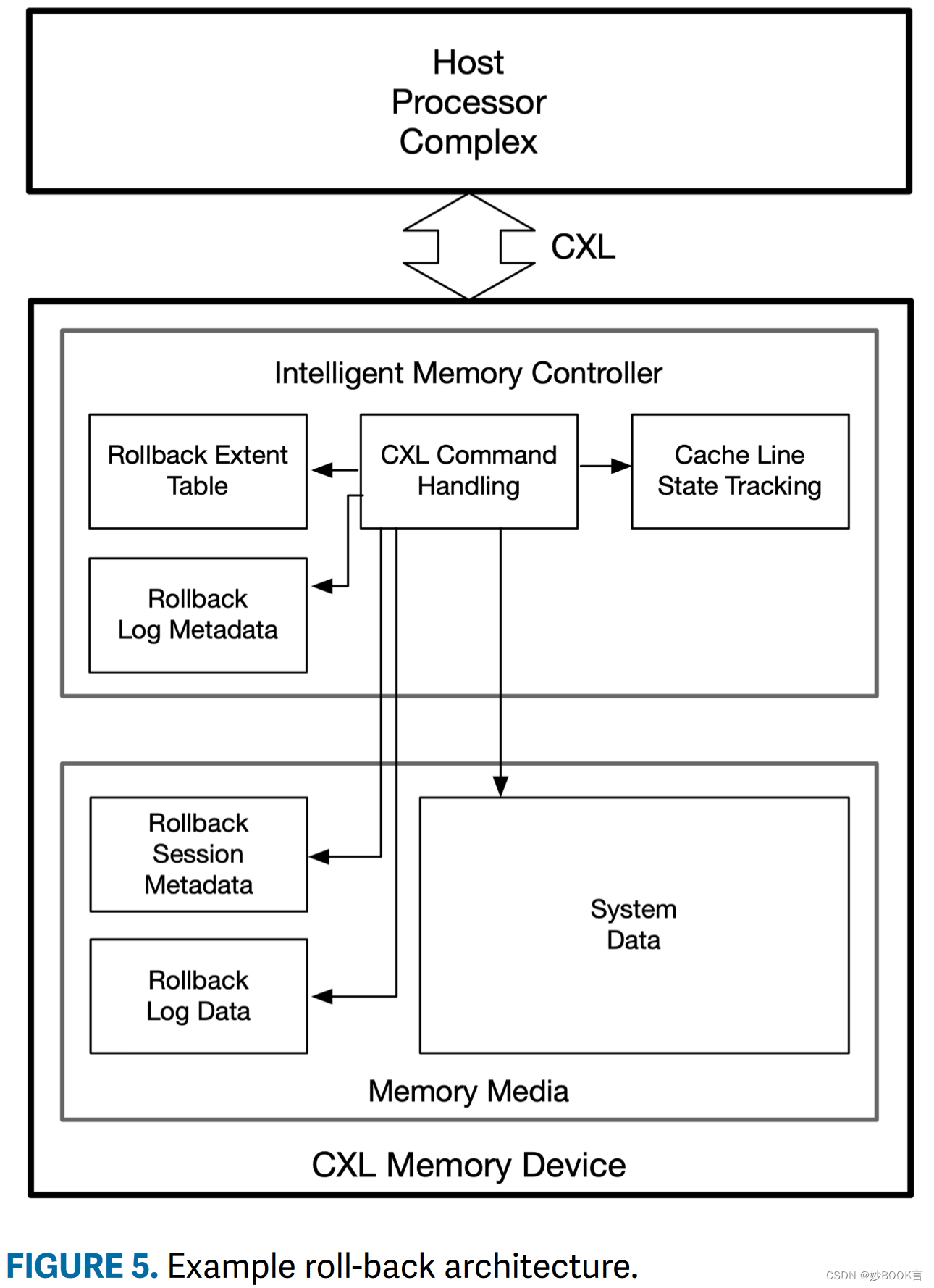
CXL-Enabled Enhanced Memory Functions——论文阅读
IEEE Micro 2023 Paper CXL论文阅读笔记整理
问题
计算快速链路(CXL)协议是系统社区的一个重要里程碑。CXL提供了标准化的缓存一致性内存协议,可用于将设备和内存连接到系统,同时保持与主机处理器的内存一致性。CXL使加速器&…
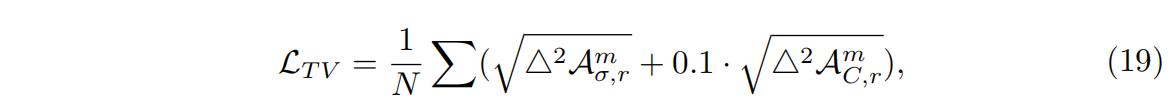
【论文阅读】TensoRF: Tensorial Radiance Fields 张量辐射场
发表于ECCV2022. 论文地址:https://arxiv.org/abs/2203.09517 源码地址:https://github.com/apchenstu/TensoRF 项目地址:https://apchenstu.github.io/TensoRF/ 摘要
本文提出了TensoRF,一种建模和重建辐射场的新方法。不同于Ne…

读《文明之光》第1册总结
人类几千年的文明史和地球的历史相比,实在是太短暂了,大约相当于几分钟和一年的关系。人类已经走过的路,相比今后要走的漫漫长路,只能算是刚刚起步。如果跳出一个个具体事件,站在历史的高度去看,我们会发现…

去除PDF论文行号的完美解决方案
去除PDF论文行号的完美解决方案 1. 遇到的问题
我想去除论文的行号,但是使用网上的Adobe Acrobat裁剪保存后
如何去掉pdf的行编号? - 知乎 (zhihu.com)
翻译时依然会出现行号,或者是转成word,这样就大大损失了格式,…
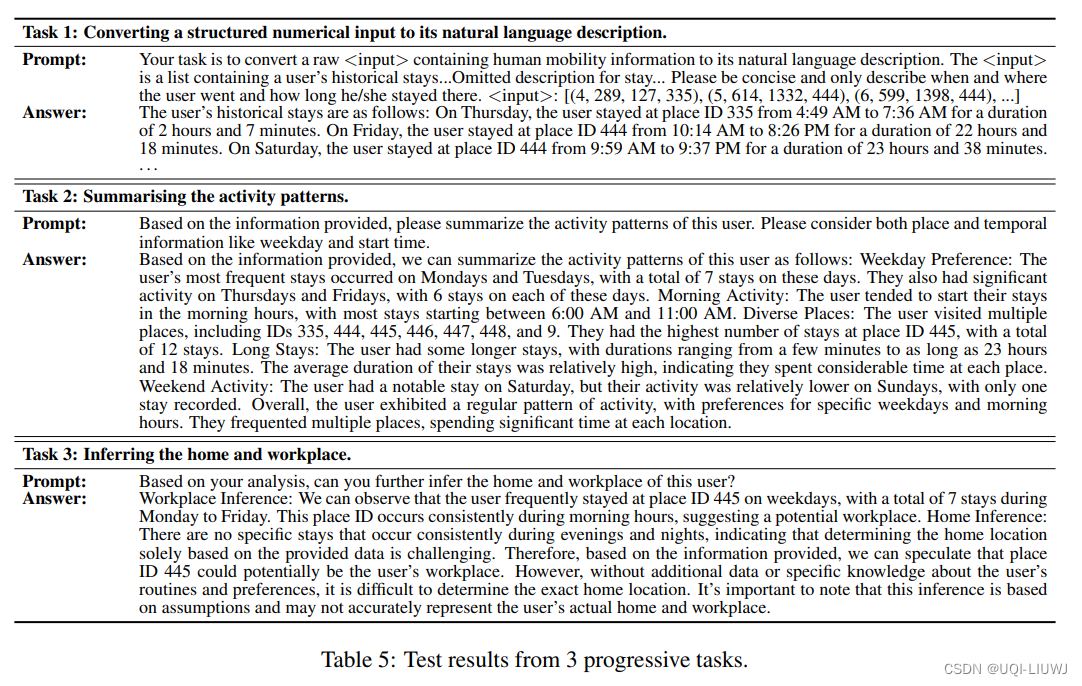
论文笔记 Where Would I Go Next? Large Language Models as Human Mobility Predictor
arxiv 2023 08的论文
1 intro
1.1 人类流动性的独特性
人类流动性的独特特性在于其固有的规律性、随机性以及复杂的时空依赖性 ——>准确预测人们的行踪变得困难近期的研究利用深度学习模型的时空建模能力实现了更好的预测性能 但准确性仍然不足,且产生的结果…
【论文阅读笔记】 Adaptive Weighting Scheme for Automatic Time-Series Data Augmentation
Adaptive Weighting Scheme for Automatic Time-Series Data Augmentation
摘要
该段落讨论了数据增强方法在图像、文本和音频分类任务中提高泛化能力的重要性,并指出自动化增强方法最近在图像分类和对象检测领域取得了进一步的改进,达到了最先进的性能…

论文阅读《FENET: FOCUSING ENHANCED NETWORK FOR LANE DETECTION》
ABSTRACT
受人类驾驶专注力的启发,这项研究开创性地利用聚焦采样(Focusing Sampling)、部分视野评估(Partial Field of View Evaluation)、增强型 FPN 架构和定向 IoU 损失(Directional IoU Lossÿ…

Scalable Diffusion Models with Transformers(DiTs)论文阅读 -- 文生视频Sora模型基础结构DiT
nlpcver
忠于理想
关注他
106 人赞同了该文章
文章地址:Scalable Diffusion Models with Transformers
简介
文章提出使用Transformers替换扩散模型中U-Net主干网络,分析发现,这种Diffusion Transformers(DiTs)…
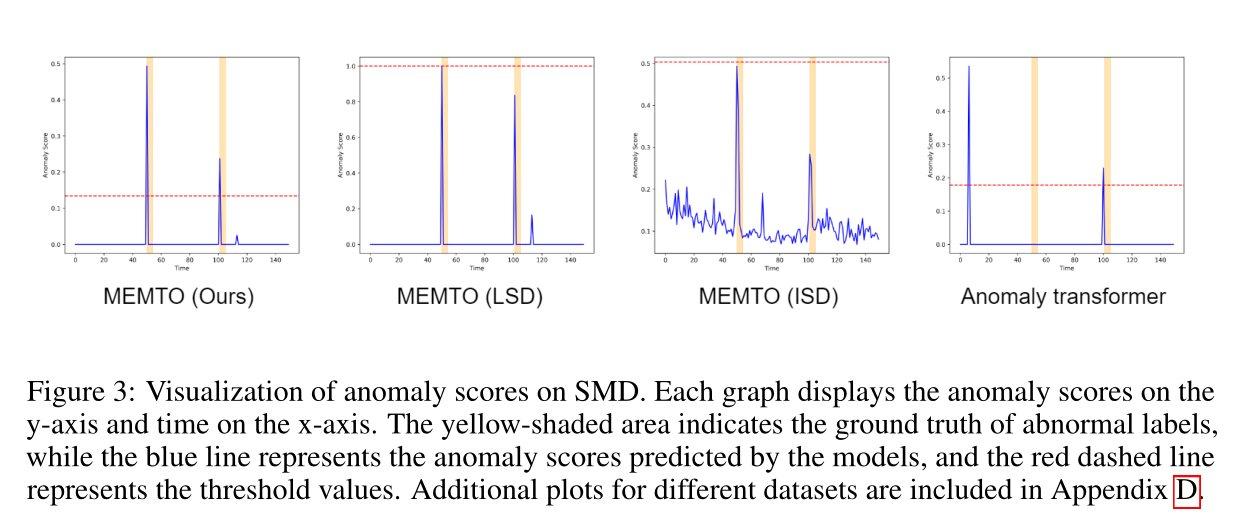
MEMTO: Memory-guided Transformer for Multivariate Time Series Anomaly Detection
目录 一、问题与思路1.1 现存问题1.2 解决思路 二、模型与方法2.1 模型概览2.2 Encoder and decoder2.3 门控存储器模块2.3.1 门控存储器更新阶段2.3.2 查询更新阶段2.3.3 损失函数2.3.4 初始化内存项2.3.5 异常评分2.3.6 阈值设定 三、实验与分析3.1 模型结果3.2 消融实验3.3 …

RAG综述 《Retrieval-Augmented Generation for Large Language Models: A Survey》笔记
文章目录 概述RAG 的定义RAG的框架Naive RAGAdvanced RAGpre-retrieval processRetrievalpost-retrieval process Modular RAG RetrievalEnhancing Semantic Representationschunk 优化 微调向量模型Aligning Queries and DocumentsAligning Retriever and LLM GenerationAugme…

【论文阅读】Generative Pretraining from Pixels
Generative Pretraining From Pixels
引用: Chen M, Radford A, Child R, et al. Generative pretraining from pixels[C]//International conference on machine learning. PMLR, 2020: 1691-1703.
论文链接: http://proceedings.mlr.press/v119/chen…
论文阅读:Detecting, Explaining, and Mitigating Memorization in Diffusion Models
一、论文信息
论文名称:Detecting, Explaining, and Mitigating Memorization in Diffusion Models
作者团队: 会议:Accepted by ICLR 2024 (Oral)
论文链接:https://openreview.net/pdf?id=84n3UwkH7b
二、扩散模型的记忆现象 三、研究背景 Training Data Extract…
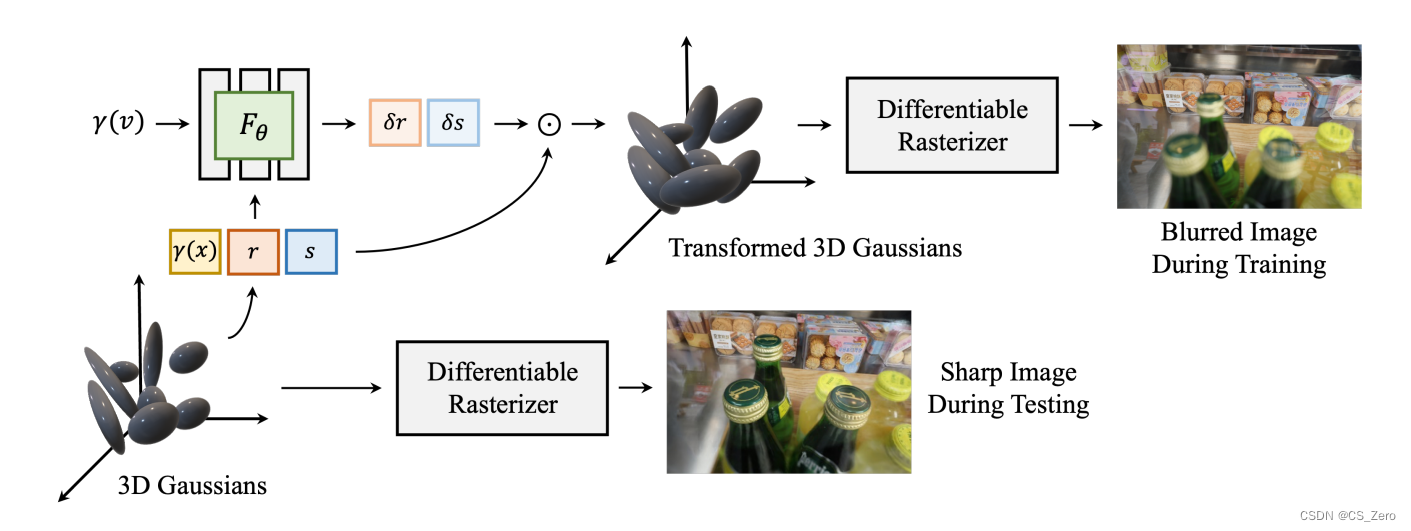
【视觉三维重建】【论文笔记】Deblurring 3D Gaussian Splatting
去模糊的3D高斯泼溅,看Demo比3D高斯更加精细,对场景物体细节的还原度更高,[官网](https://benhenryl.github.io/Deblurring-3D-Gaussian-Splatting/)
背景技术
Volumetric rendering-based nerual fields:…

【论文阅读】ACM MM 2023 PatchBackdoor:不修改模型的深度神经网络后门攻击
文章目录 一.论文信息二.论文内容1.摘要2.引言3.作者贡献4.主要图表5.结论 一.论文信息
论文题目: PatchBackdoor: Backdoor Attack against Deep Neural Networks without Model Modification(PatchBackdoor:不修改模型的深度神经网络后门攻击…

近年来文本检测相关工作梳理
引言
场景文本检测任务,一直以来是OCR整个任务中最为重要的一环。虽然有一些相关工作是端对端OCR工作的,但是从工业界来看,相关落地应用较为困难。因此,两阶段的OCR方案一直是优先考虑的。
在两阶段中(文本检测文本识…
什么是R语言?什么是R包?-R语言001
R语言是一种专为统计计算和图形而设计的编程语言和环境。它最初由罗斯伊哈卡和罗伯特亨特尔在1993年创建,灵感来源于S语言。R语言已经发展成为统计学、数据分析、科学研究以及许多其他领域中最受欢迎和广泛使用的工具之一。R语言的核心是一个开源的解释型语言&#…
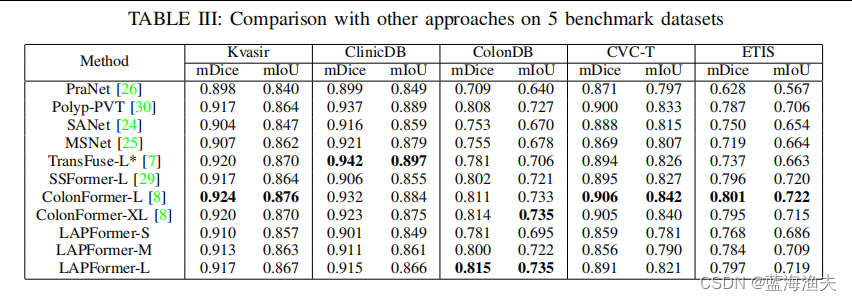
论文阅读:LAPFormer: A Light and Accurate PolypSegmentation Transformer
这是一个基于Transformer的轻量级图像分割模型。作者们使用MiT(Mix Transformer)作为编码器,并为LAPFormer设计了一个新颖的解码器,该解码器利用多尺度特征,并包含特征精炼模块和特征选择模块,以生成精细的…
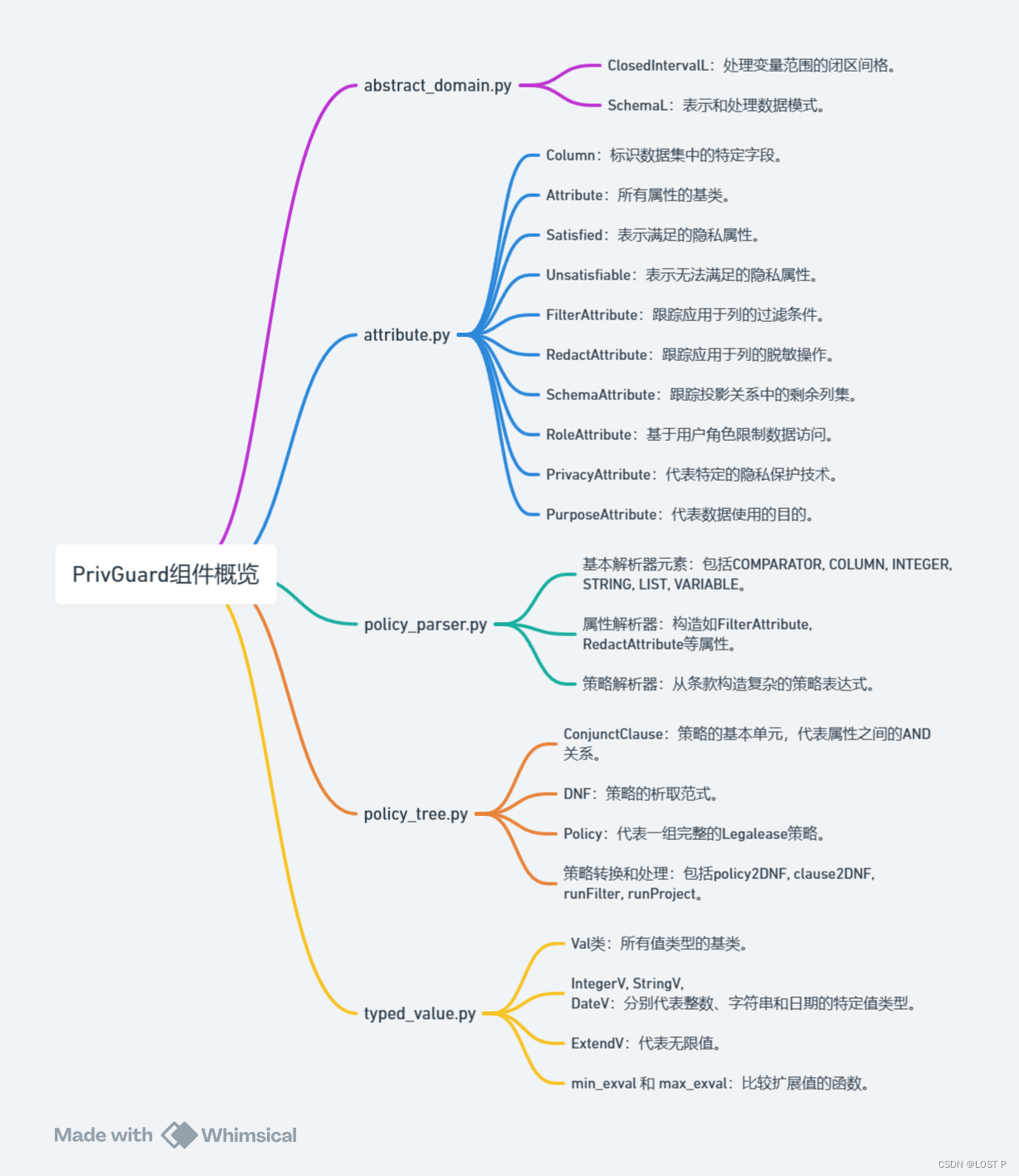
【PRIVGUARD-privguard-artifact-main】代码学习(parser部分)
privguard-artifact-main:parser部分简述 1.abstract_domain.py
(1)简介 实现PrivGuard中的抽象域功能。PrivGuard是一个旨在确保Python程序符合特定隐私策略的工具。代码中定义了两种类型的抽象域:闭区间格(ClosedIn…

图像分割论文阅读:Adaptive Context Selection for Polyp Segmentation
这篇论文的主要内容是关于一种用于息肉分割的自适应上下文选择网络(Adaptive Context Selection Network,简称ACSNet)
1,模型的整体结构 模型的整体结构基于编码器-解码器框架,并且包含了三个关键模块:局部…
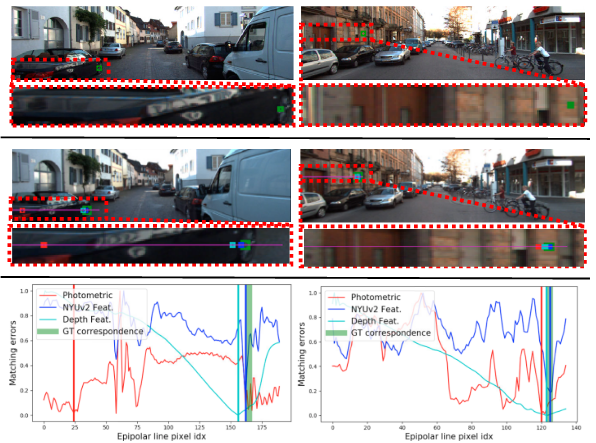
Unsupervised Learning of Monocular Depth Estimation and Visual Odometry 论文阅读
论文链接
Unsupervised Learning of Monocular Depth Estimation and Visual Odometry with Deep Feature Reconstruction 0. Abstract
尽管基于学习的方法在单视图深度估计和视觉里程计方面显示出有希望的结果,但大多数现有方法以监督方式处理任务。最近的单视图…

【论文阅读】VMamba:视觉状态空间模型
文章目录 VMamba:视觉状态空间模型摘要相关工作状态空间模型 方法准备状态空间模型离散化选择扫描机制 2D 选择扫描VMamba 模型整体结构VSS块 实验分析实验有效感受野输入尺度 总结 VMamba:视觉状态空间模型
摘要
受最近提出的状态空间模型启发,我们提出了视觉状态…

【论文笔记】Language Models are Few-Shot Learners
Language Models are Few-Shot Learners
本部分是 GPT-3 技术报告的第一部分:论文正文、部分附录。
后续还有第二部分:GPT-3 的广泛影响、剩下的附录。
以及第三部分(自己感兴趣的):GPT-3 的数据集重叠性研究。 回顾…

【论文阅读】THEMIS: Fair and Efficient GPU Cluster Scheduling
11. THEMIS: Fair and Efficient GPU Cluster Scheduling
出处: 2020 USENIX Themis:公平高效的 GPU 集群调度 |USENIX主要工作:使用拍卖机制,针对长时间运行、位置敏感的ML应用程序。任务以短期的效率公平来赢取投标但确保长期是完成时间公…

论文阅读笔记 | Limited-Reference Image Quality Assessment: Paradigms and Discussions
文章目录 文章题目发表年限期刊/会议名称动机主要思想或方法架构实验结果 文章链接:https://dl.acm.org/doi/10.1145/3581783.3613436 文章题目
Limited-Reference Image Quality Assessment: Paradigms and Discussions
发表年限
2023
期刊/会议名称
MM’23: …
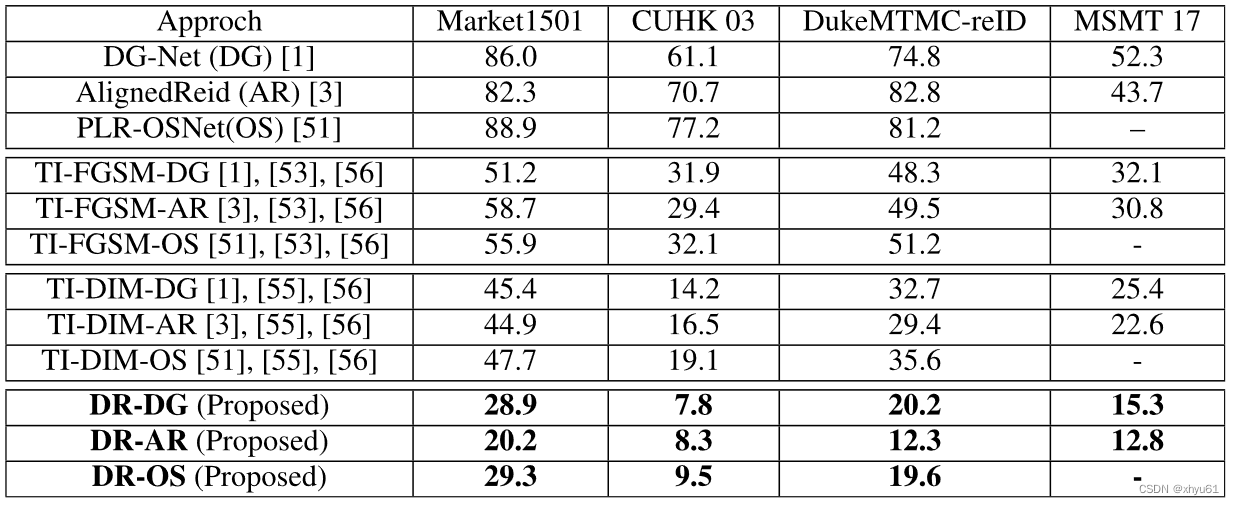
【论文笔记】An Effective Adversarial Attack on Person Re-Identification ...
原文标题(文章标题处有字数限制): 《An Effective Adversarial Attack on Person Re-Identification in Video Surveillance via Dispersion Reduction》
Abstract
通过减少神经网络内部特征图的分散性攻击reid模型。
erbloo/Dispersion_r…
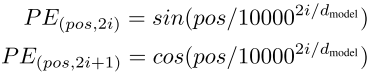
【论文阅读笔记】Attention Is All You Need
1.论文介绍
Attention Is All You Need 2017年 NIPS transformer 开山之作 回顾一下经典,学不明白了 Paper Code
2. 摘要
显性序列转导模型基于包括编码器和解码器的复杂递归或卷积神经网络。性能最好的模型还通过注意力机制连接编码器和解码器。我们提出了一个新…

《Multi-modal Dense Video Captioning》(MDVC)论文笔记
原文链接:
2003.07758v2.pdf (arxiv.org)
代码链接:
v-iashin/MDVC: PyTorch implementation of Multi-modal Dense Video Captioning (CVPR 2020 Workshops) (github.com)
原文笔记: What:
我们提出了一种新的密集视频字幕方…
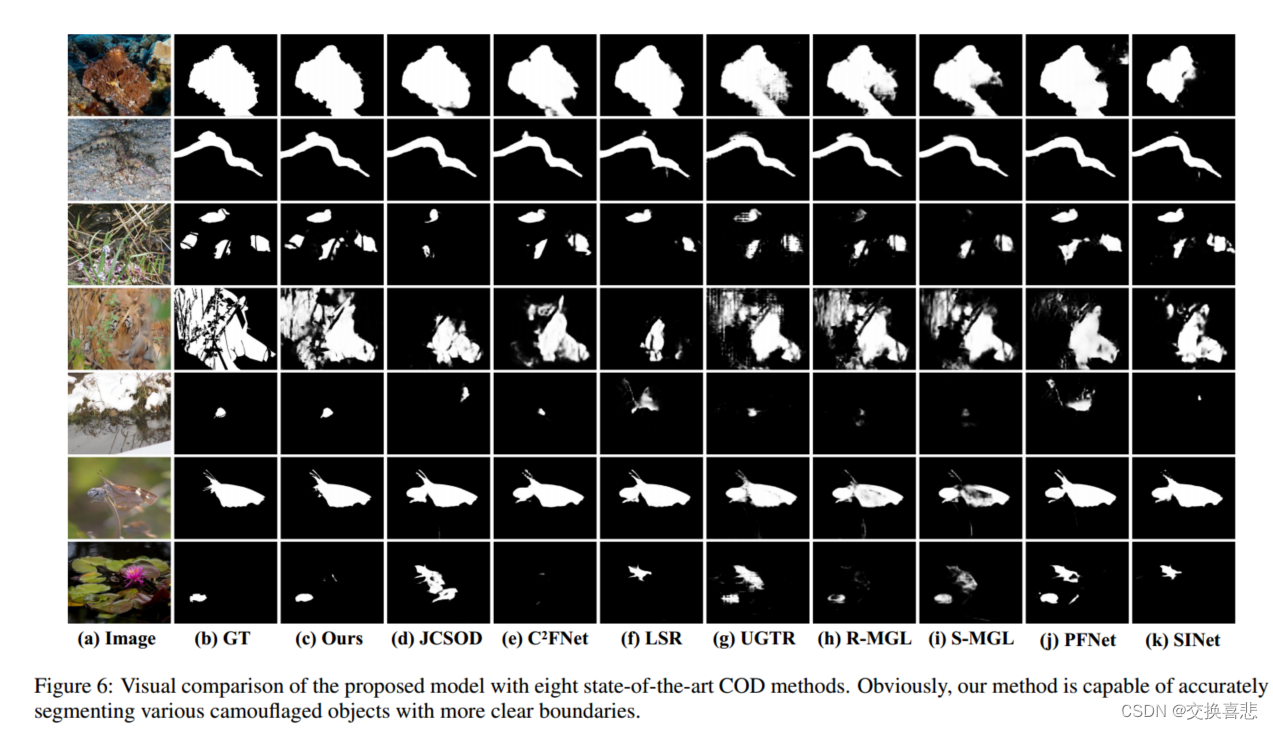
伪装目标检测论文BGNet:Boundary-Guided Camouflaged Object Detection
论文地址:link 代码地址:link 这篇论文是22年的CVPR收录的一篇关于伪装目标检测的文章,作者主要是用了一些通道注意力和Atrous卷积来实现边缘引导的伪装目标检测,模型并不复杂,看了两天的论文和代码,为了加深印象在这里…
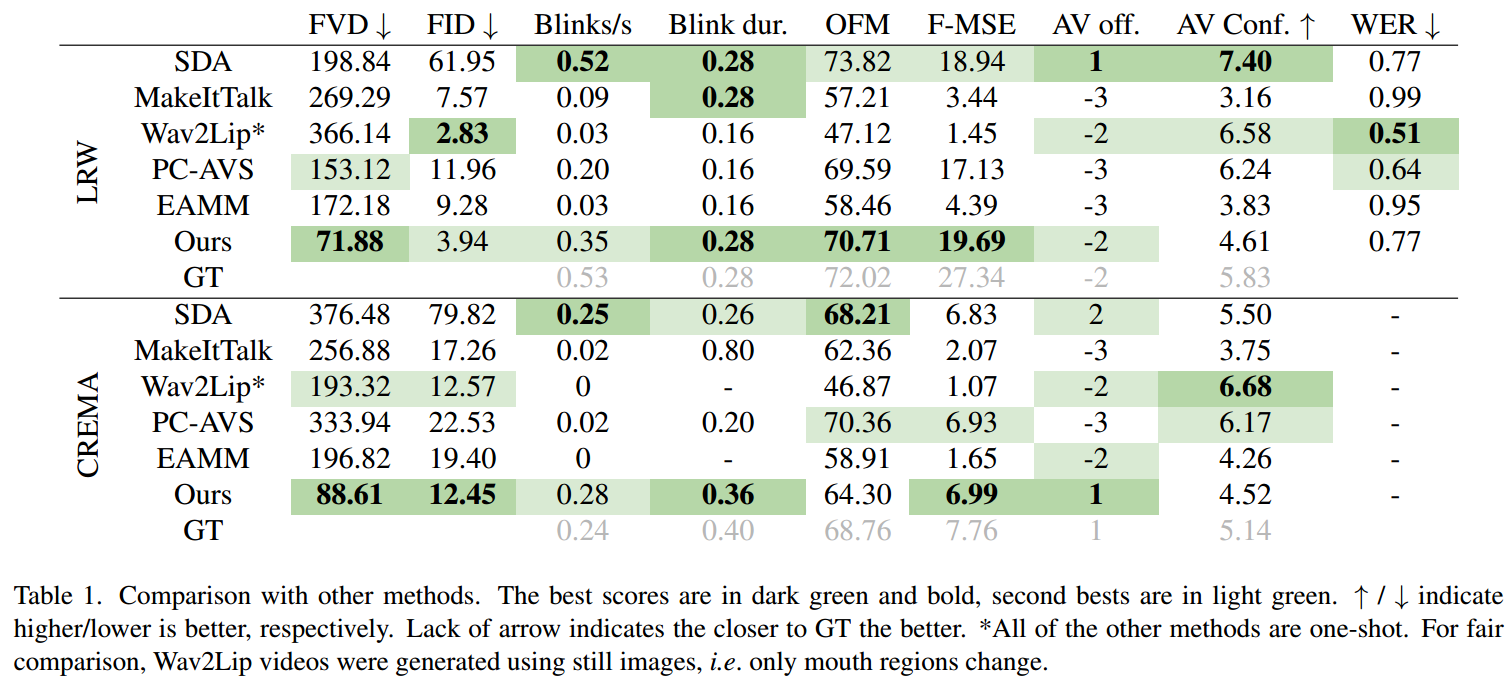
【论文阅读】Diffused Heads: Diffusion Models Beat GANs on Talking-Face Generation
Diffused Heads: 扩散模型在说话人脸生成方面击败GANs
paper:[2301.03396] Diffused Heads: Diffusion Models Beat GANs on Talking-Face Generation (arxiv.org)
code:MStypulkowski/diffused-heads: Official repository for Diffused Heads: Diffu…
![[论文笔记] Dual-Channel Span for Aspect Sentiment Triplet Extraction](https://img-blog.csdnimg.cn/img_convert/b9f1b3a80a11baf04f6d2162abd203c8.png)
[论文笔记] Dual-Channel Span for Aspect Sentiment Triplet Extraction
一种利用句法依赖和词性相关性信息来过滤噪声(无关跨度)的基于span方法。 会议EMNLP 2023作者Pan Li, Ping Li, Kai Zhang团队Southwest Petroleum University论文地址https://aclanthology.org/2023.emnlp-main.17/代码地址https://github.com/bert-ply…

IEEE Transactions on Medical Imaging(TMI)论文推荐:2024年01月(2)
Structural Priors Guided Network for the Corneal Endothelial Cell Segmentation 摘要: 角膜内皮显微镜图像中模糊的细胞边界分割具有挑战性,影响临床参数估计的准确性。现有的深度学习方法仅考虑像素分类精度,缺乏对细胞结构知识的利用。因此&#x…

论文阅读:Iterative Denoiser and Noise Estimator for Self-Supervised Image Denoising
这篇论文是发表在 2023 ICCV 上的一篇工作,主要介绍利用自监督学习进行降噪的。
Abstract
随着深度学习工具的兴起,越来越多的图像降噪模型对降噪的效果变得更好。然而,这种效果的巨大进步都严重依赖大量的高质量的数据对,这种对…

Fast-R-CNN论文笔记
目标检测之Fast R-CNN论文精讲,Fast RCNN_哔哩哔哩_bilibili
一 引言
1.1 R-CNN和SPPNet缺点
😀R-CNN Training is a multi-stage pipeline 多阶段检测器(两阶段和一阶段检测器) 1️⃣首先训练了一个cnn用来提取候选区域的特征…

【论文阅读】Vision Mamba:双向状态空间模型的的高效视觉表示学习
文章目录 Vision Mamba:双向状态空间模型的的高效视觉表示学习摘要介绍相关工作用于视觉应用的状态空间模型 方法准备视觉MambaVim块结构细节高效分析计算效率 实验图片分类语义分割目标检测和实例分割消融实验双向SSM分类设计 总结和未来工作 论文地址: Vision Mam…
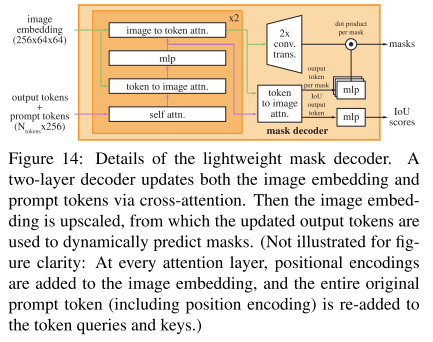
【论文阅读笔记】Segment Anything
1. 论文介绍
Segment Anything 分割任意物体 2023年 发表在ICCV Paper Code demo
2.摘要
我们介绍Segment Anything(SA)项目:用于图像分割的新任务、模型和数据集。在数据收集循环中使用我们的高效模型,我们构建了迄今为止最大…
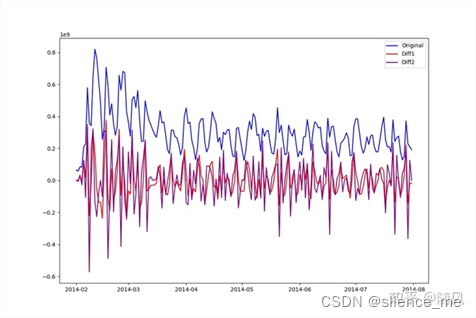
【论文笔记合集】ARIMA 非平稳过程通过差分转化为平稳过程
本文作者: slience_me 文章目录 ARIMA 非平稳过程通过差分转化为平稳过程文章原文具体解释详解参照 ARIMA 非平稳过程通过差分转化为平稳过程
文章原文 Many time series forecasting methods start from the classic tools [38, 10]. ARIMA [7, 6] tackles the fo…
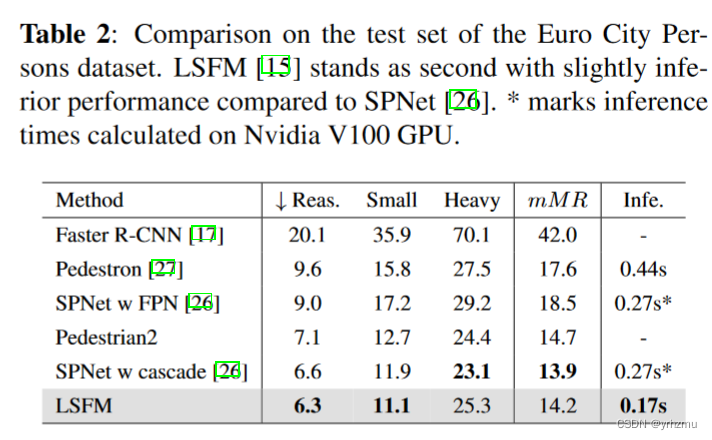
<REAL-TIME TRAFFIC OBJECT DETCTION FOR AUTONOMOUS DRIVING>论文阅读
Abstract 随着计算机视觉的最新进展,自动驾驶迟早成为现代社会的一部分,然而,仍有大量的问题需要解决。尽管现代计算机视觉技术展现了优越的性能,他们倾向于将精度优先于效率,这是实时应用的一个重要方面。大型目标检测…
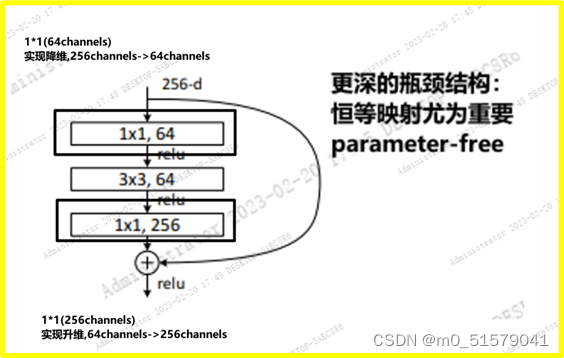
【AI论文阅读笔记】ResNet残差网络
论文地址:https://arxiv.org/abs/1512.03385
摘要
重新定义了网络的学习方式
让网络直接学习输入信息与输出信息的差异(即残差)
比赛第一名1 介绍
不同级别的特征可以通过网络堆叠的方式来进行丰富
梯度爆炸、梯度消失解决办法:1.网络参数的初始标准化…

论文阅读-federated unlearning via class-discriminative pruning
论文阅读-federated unlearning via class-discriminative pruning FUCP 通过类别区分性剪枝进行联邦遗忘 综述中描述:属于面向全局模型中的局部参数调整
利用卷积层的结构特定进行联邦忘却学习,wang等人提出了针对图像分类任务的联邦忘却学习算法FUCP&…
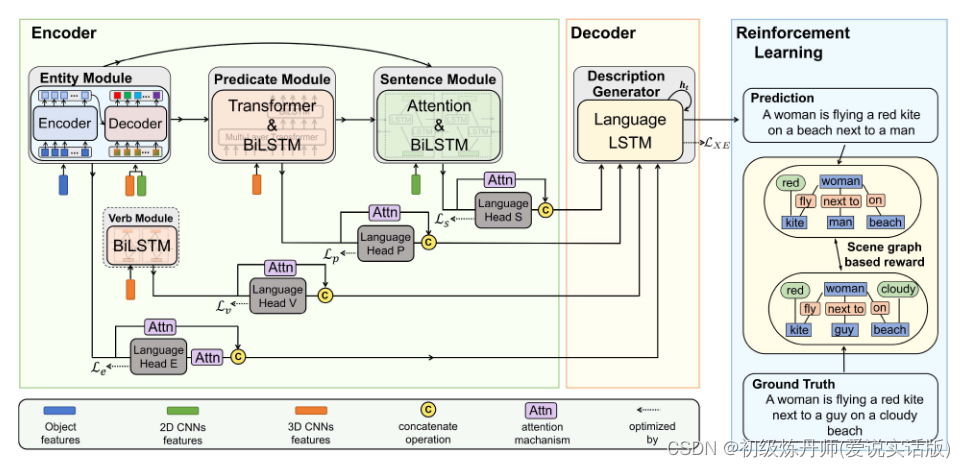
《Learning Hierarchical Modular Networks for Video Captioning》论文笔记
论文信息
原文链接:
Learning Hierarchical Modular Networks for Video Captioning | IEEE Journals & Magazine | IEEE Xplore
原文代码
GitHub - MarcusNerva/HMN: [CVPR2022] Official code for Hierarchical Modular Network for Video Captioning. Ou…
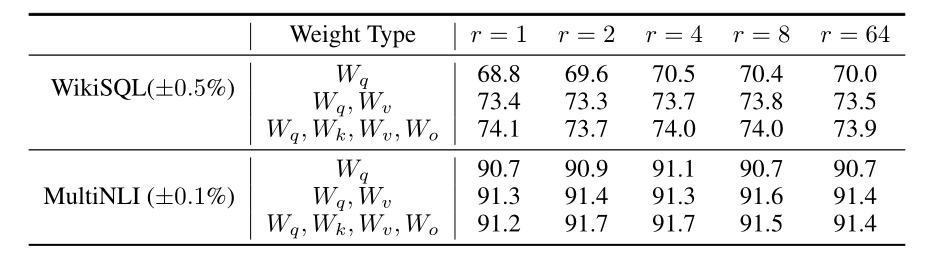
论文阅读之LORA: LOW-RANK ADAPTATION OF LARGE LAN- GUAGE MODELS(2021)
文章目录 论文地址主要内容主要贡献模型图技术细节实验结果 论文地址
LORA: LOW-RANK ADAPTATION OF LARGE LAN- GUAGE MODELS
主要内容
这篇文章的主要内容是介绍了一种名为LoRA(Low-Rank Adaptation)的技术,这是一种针对大型语言模型进行…
AI论文速读 |(Mamba×时空图预测!) STG-Mamba:通过选择性状态空间模型进行时空图学习
(来了来了,虽迟但到,序列建模的新宠儿mamba终于杀入了时空预测!) 论文标题:STG-Mamba: Spatial-Temporal Graph Learning via Selective State Space Model
作者:Lincan Li, Hanchen Wang&…

【论文阅读】Faster Neural Networks Straight from JPEG
Faster Neural Networks Straight from JPEG
论文链接:Faster Neural Networks Straight from JPEG (neurips.cc)
作者:Lionel Gueguen,Alex Sergeev,Ben Kadlec,Rosanne Liu,Jason Yosinski
机构&#…
论文阅读--Offline RL Without Off-Policy Evaluation
论文概述
本文主要介绍了一种离线强化学习算法——一步算法(one-step algorithm),该算法只使用行为策略(beta)的一个在线Q值估计,进行一步的约束/正则化策略改进,从而实现强化学习。该算法在D4RL基准测试中的表现超过了迭代算法的表现&#…
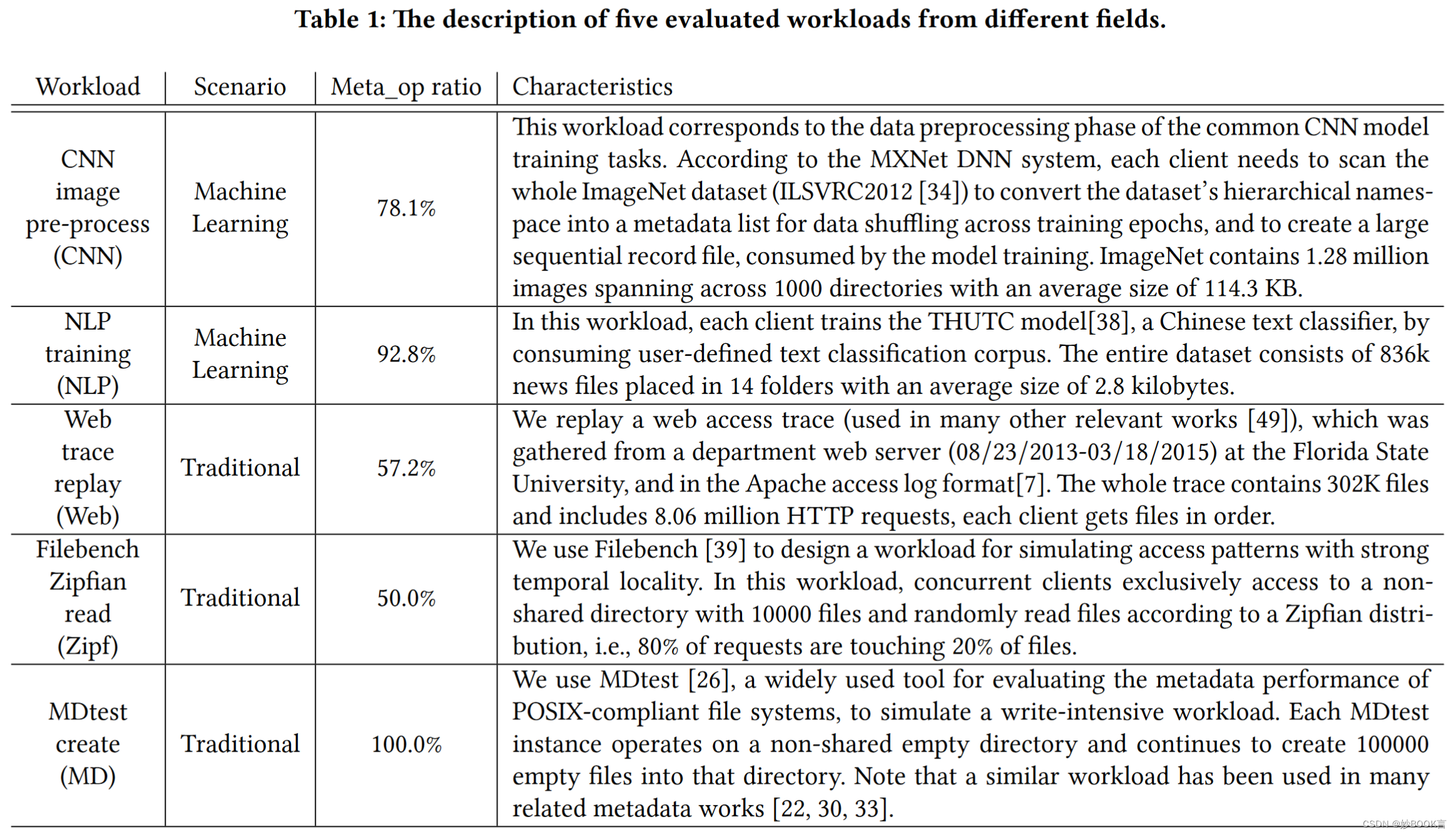
Lunule: An Agile and Judicious Metadata Load Balancer for CephFS——论文阅读
SC 2021 Paper 分布式元数据论文阅读笔记
问题
CephFS采用动态子树分区方法,将分层命名空间划分并将子树分布到多个元数据服务器上。然而,这种方法存在严重的不平衡问题,由于其不准确的不平衡预测、对工作负载特性的忽视以及不必要/无效的迁…

【论文阅读】MSGNet:学习多变量时间序列预测中的多尺度间序列相关性
MSGNet:学习多变量时间序列预测中的多尺度间序列相关性 文献介绍摘要总体介绍背景及当前面临的问题现有解决方案及其局限性本文的解决方案及其贡献 背景知识的相关工作背景知识问题表述: Method论文主要工作1.输入嵌入和剩余连接 (Input Embedding and R…
【视频异常检测】Real-world Anomaly Detection in Surveillance Videos 论文阅读
Real-world Anomaly Detection in Surveillance Videos 论文阅读 Abstract1. Introduction2. Related Work3. Proposed Anomaly Detection Method3.1. Multiple Instance Learning3.2. Deep MIL Ranking Model 4. Dataset4.1. Previous datasets4.2. Our dataset 5. Experiment…
【论文阅读】Energy Efficient Real-time Task Scheduling on CPU-GPU Hybrid Clusters
Energy Efficient Real-time Task Scheduling on CPU-GPU Hybrid Clusters 出处:2017IEEE Xplore 基于CPU-GPU混合集群的高效实时任务调度 主要工作:通过动态电压和频率缩放研究了新兴CPU-GPU混合集群的节能问题。 首次分析GPU特定的DVFS模型。 设计了…

三维指静脉生物识别成像设备设计和多视图验证研究
文章目录 三维指静脉生物识别成像设备设计和多视图验证研究总结摘要介绍多视角指静脉识别模型结构内容特征编码Transformer(CFET)主导特征选择模块(DFSM) 实验和结果数据集实施细节视角研究池化层的作用消融实验和SOTA方法比较 论文:
Study of 3D Finger Vein Biometrics on I…

Mamba(论文笔记)
What can I say?
2024年我还能说什么?
Mamba out!
曼巴出来了! 原文链接:
[2312.00752] Mamba: Linear-Time Sequence Modeling with Selective State Spaces (arxiv.org) 原文笔记:
What:
Mamba: Linear-Time …
论文阅读--临床驱动的多标签医学图像分类中的三元组注意力与双池对比学习---TA-DCL
来源:https://github.com/ZhangYH0502/TA-DCL. 模型结合了两种技术:三元组注意力(Triplet attention)和双池对比学习(Dual-pool contrastive learning)。这个模型是为了解决临床应用中多标签医学图像分类问…

【视频异常检测】Diversity-Measurable Anomaly Detection 论文阅读
Diversity-Measurable Anomaly Detection 论文阅读 Abstract1. Introduction2. Related Work3. Diversity-Measurable Anomaly Detection3.1. The framework3.2. Information compression module3.3. Pyramid deformation module3.4. Foreground-background selection3.5. Trai…

显隐特征融合的指静脉识别网络
文章目录 显隐特征融合的指静脉识别网络总结摘要介绍显隐式特征融合网络(EIFNet)掩膜生成模块(MGM)掩膜特征提取模块(MFEM)内容特征提取模块(CFEM)特征融合模块(FFM) THUFVS实验和结果数据集实现细节评估掩膜生成模型消融实验FFM模块门控层Batch Size损失函数超参数选择 论文
…
[论文笔记] Open-Sora 4、sora复现训练过程 (新repo)
sudo -H pip install --upgrade youtube-dl -i https://pypi.doubanio.com/simple/
一、概况 OpenAI 的 Sora 在生成一分钟高质量视频方面非常出色。然而,它几乎没有透露任何有关其细节的信息。为了让AI更加“开放”,致力于打造Sora的开源版本。本报告描述了colossal-ai首次…

【ControlNet v3版本论文阅读】
网络部分最好有LDM或者Stable Diffusion的基础,有基础的话会看的很轻松
Abstract
1.提出了一种网络结构支持额外输入条件控制大型预训练的扩散模型。利用预训练模型学习一组不同的条件控制。 2.ControlNet对于小型(<50k)或大型ÿ…
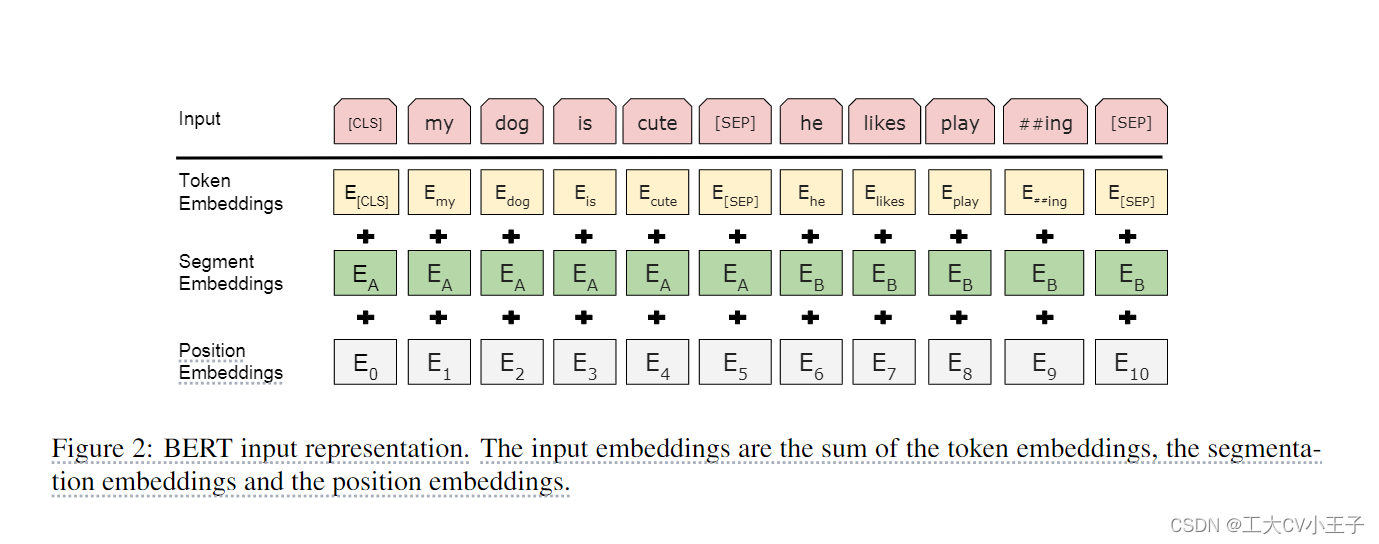
《BERT》论文笔记
原文链接:
[1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (arxiv.org)
原文笔记:
What:
BETR:Pre-training of Deep Bidirectional Transformers for Language Understand…
TransUNet论文笔记
论文:TransUNet:Transformers Make Strong Encoders for Medical Image Segmentation
目录
Abstract
Introduction
Related Works
各种研究试图将自注意机制集成到CNN中。
Transformer
Method
Transformer as Encoder
图像序列化
Patch Embed…
《论文阅读》PAGE:一个用于会话情绪原因蕴含基于位置感知的图模型 ICASSP 2023
《论文阅读》PAGE:一个用于会话情绪原因蕴含基于位置感知的图模型 ICASSP 2023 前言 简介任务定义模型构架Utterances Encoding with EmotionPosition-aware GraphCausal Classifier实验结果 前言
亲身阅读感受分享,细节画图解释,再也不用担…
【论文阅读】通过组件对齐评估和改进 text-to-SQL 的组合泛化
Measuring and Improving Compositional Generalization in Text-to-SQL via Component Alignment
NAACL 2022| CCF B
Abstract
在 text-to-SQL 任务中,正如在许多 NLP 中一样,组合泛化是一个重大挑战:神经网络在训练和测试分布不同的情况…

【目标检测经典算法】R-CNN、Fast R-CNN和Faster R-CNN详解系列一:R-CNN图文详解
学习视频:Faster-RCNN理论合集
概念辨析
在目标检测中,proposals和anchors都是用于生成候选区域的概念,但它们在实现上有些许不同。 Anchors(锚框): 锚框是在图像中预定义的一组框,它们通常以…

《A ConvNet for the 2020s》阅读笔记
论文标题
《A ConvNet for the 2020s》
面向 2020 年代的 ConvNet
作者
Zhuang Liu、Hanzi Mao、Chao-Yuan Wu、Christoph Feichtenhofer、Trevor Darrell 和 Saining Xie
来自 Facebook AI Research (FAIR) 和加州大学伯克利分校
初读
摘要 “ViT 盛 Conv 衰” 的现状&…

ConsiStory:Training-Free的主体一致性生成
Overview 一、总览二、PPT详解 ConsiStory 一、总览
题目: Training-Free Consistent Text-to-Image Generation 机构:NVIDIA, Tel-Aviv University 论文:https://arxiv.org/pdf/2402.03286.pdf 代码:https://consistory-paper.g…

论文阅读_参数微调_P-tuning_v2
1 P-Tuning
PLAINTEXT 1
2
3
4
5
6
7英文名称: GPT Understands, Too
中文名称: GPT也懂
链接: https://arxiv.org/abs/2103.10385
作者: Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, Jie Tang
机构: 清华大学, 麻省理工学院
日期: 2021-03-18…

论文阅读:Face Deblurring using Dual Camera Fusion on Mobile Phones
今天介绍一篇发表在 ACM SIGGRAPH 上的文章,是用手机的双摄系统来做人脸去模糊的工作。这也是谷歌计算摄影研究组的工作。
快速运动物体的运动模糊在摄影中是一个一直以来的难题,在手机摄影中也是非常常见的问题,尤其在光照不足,…
BERT 论文阅读笔记
文章目录 前言论文阅读同类工作比较模型架构训练方式使用步骤实验结果 其他 前言
BERT是在NLP领域中第一个预训练好的大型神经网络,可以通过模型微调的方式应用于后续很多下游任务中,从而避免了下游NLP应用需要单独构建一个新的神经网络进行复杂的预训练…

论文笔记:Retrieval-Augmented Generation forAI-Generated Content: A Survey
北大202402的RAG综述
1 intro
1.1 AICG
近年来,人们对人工智能生成内容(AIGC)的兴趣激增。各种内容生成工具已经精心设计,用于生产各种模态下的多样化对象 文本&代码:大型语言模型(LLM)…
GPT系列 论文阅读笔记
文章目录 GPT-1GPT-2GPT-3 GPT-1
GPT-1的核心:基于Transformer的解码器构建一个模型,在大量无标号的文本数据上训练一个模型,然后再在下游的子任务上进行微调。当前面临的问题:在NLP领域,有各种各样的下游任务。目前&…
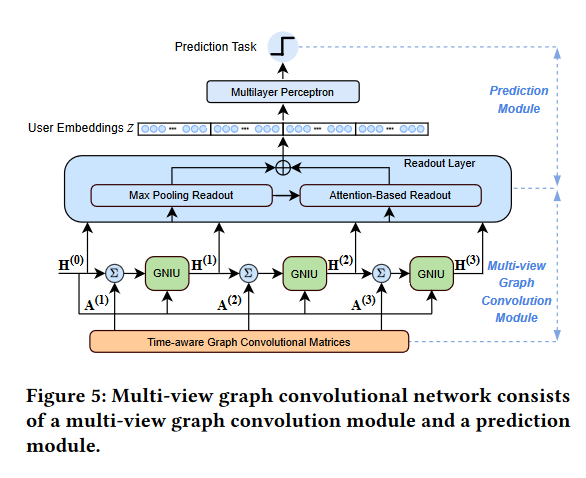
MINT: Detecting Fraudulent Behaviors from Time-series Relational Data论文阅读笔记
2. 问题定义
时间序列关系数据(Time Series Relation Data)
这个数据是存放在关系型数据库中,每一条记录都是泰永时间搓的行为。
更具体地,每条记录表示为 x ( v , t , x 1 , x 2 , … , x m − 2 ) x (v,t,x_1,x_2,\dots,x…
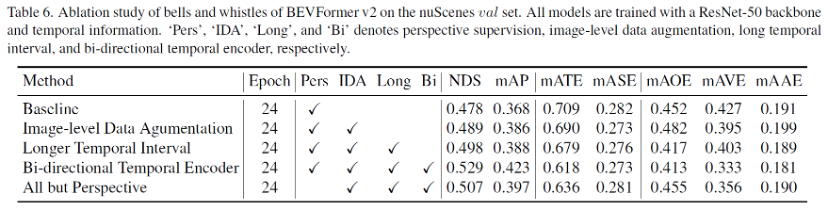
BEVFormer v2论文阅读
摘要
本文工作
提出了一种具有透视监督(perspective supervision)的新型鸟瞰(BEV)检测器,该检测器收敛速度更快,更适合现代图像骨干。现有的最先进的BEV检测器通常与VovNet等特定深度预训练的主干相连,阻碍了蓬勃发展…
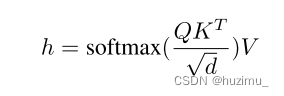
论文阅读:Forget-Me-Not: Learning to Forget in Text-to-Image Diffusion Models
Forget-Me-Not: Learning to Forget in Text-to-Image Diffusion Models
论文链接 代码链接 这篇文章提出了Forget-Me-Not (FMN),用来消除文生图扩散模型中的特定内容。FMN的流程图如下: 可以看到,FMN的损失函数是最小化要消除的概念对应的…
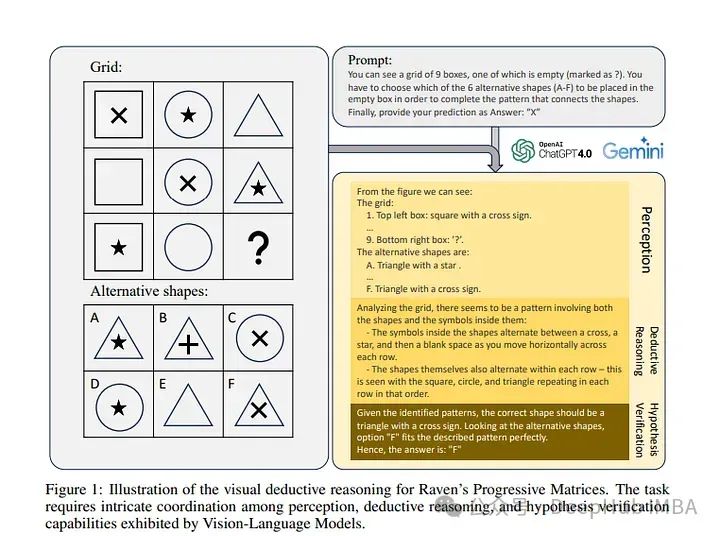
2024年3月的计算机视觉论文推荐
从去年开始,针对LLM的研究成为了大家关注的焦点。但是其实针对于计算机视觉的研究领域也在快速的发展。每周都有计算机视觉领域的创新研究,包括图像识别、视觉模型优化、生成对抗网络(gan)、图像分割、视频分析等。
我们今天来总结一下2024年3月上半月份…
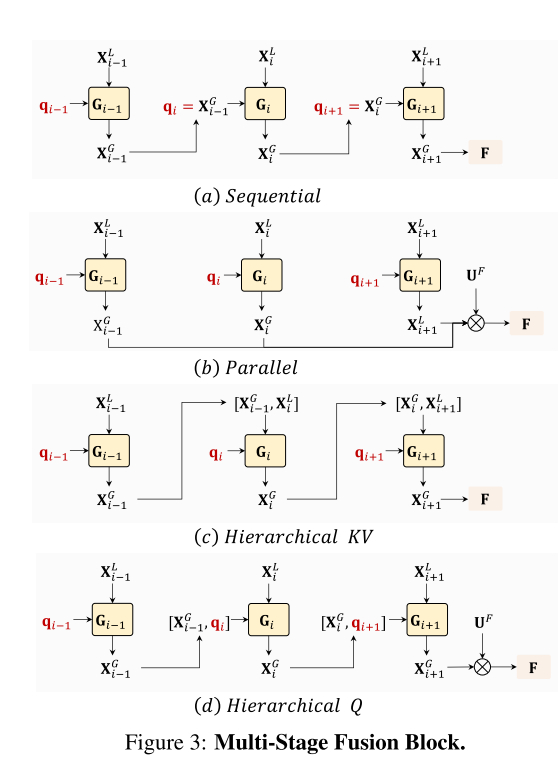
论文阅读:UniFormer和UniFormerV2
文章目录 UNIFormer动机方法动态位置嵌入(DPE)多头关系聚合器(MHRA) 模型代码总结 UniFormerV2动机方法整体框架实现细节 总结 UNIFormer
本文主要介绍了UniFormer: Unified Transformer for Efficient Spatial-Temporal Representation Learning 代码:https://git…

VPCFormer:一个基于transformer的多视角指静脉识别模型和一个新基准
文章目录 VPCFormer:一个基于transformer的多视角指静脉识别模型和一个新基准总结摘要介绍相关工作单视角指静脉识别多视角指静脉识别Transformer 数据库基本信息 方法总体结构静脉掩膜生成VPC编码器视角内相关性的提取视角间相关关系提取输出融合IFFN近邻感知模块(NPM) patch嵌…
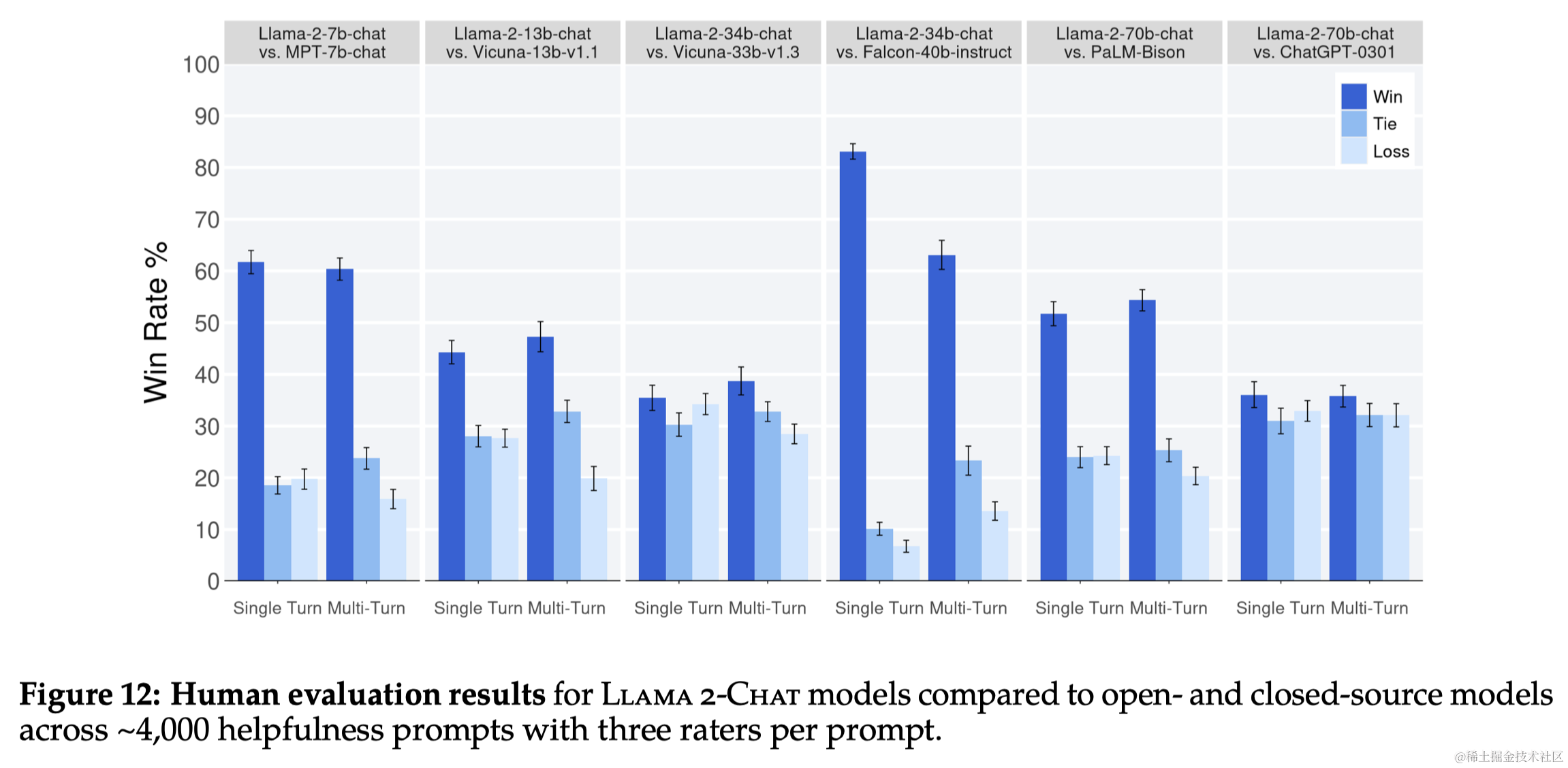
论文笔记:Llama 2: Open Foundation and Fine-Tuned Chat Models
导语
Llama 2 是之前广受欢迎的开源大型语言模型 LLaMA 的新版本,该模型已公开发布,可用于研究和商业用途。本文记录了阅读该论文的一些关键笔记。
链接:https://arxiv.org/abs/2307.09288
1 引言
大型语言模型(LLMsÿ…

文献速递:基于SAM的医学图像分割---医疗 SAM 适配器:适配用于医学图像分割的 Segment Anything 模型
Title
题目 Medical SAM Adapter: Adapting Segment Anything Model for Medical Image Segmentation
医疗 SAM 适配器:适配用于医学图像分割的 Segment Anything 模型 01
文献速递介绍 最近,Segmentation Anything 模型(SAM)…
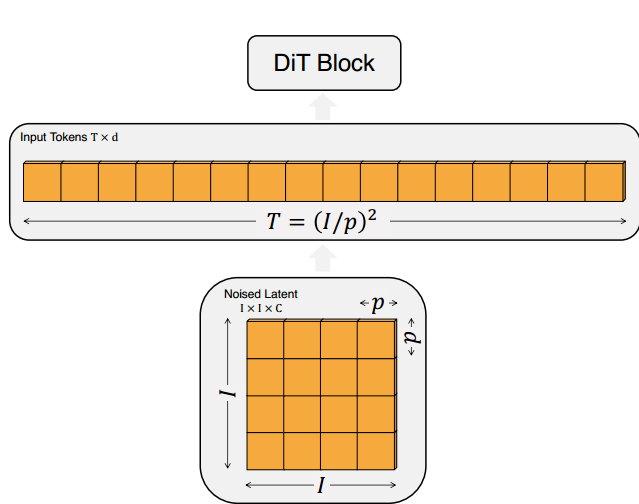
【论文阅读】Scalable Diffusion Models with Transformers
DiT:基于transformer架构的扩散模型。
paper:[2212.09748] Scalable Diffusion Models with Transformers (arxiv.org)
code:facebookresearch/DiT: Official PyTorch Implementation of "Scalable Diffusion Models with Transformer…
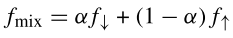
【论文阅读笔记】Split frequency attention network for single image deraining
1.论文介绍
Split frequency attention network for single image deraining 用于单幅图像去噪的分频注意力网络 Paper Code 2023年 SIVP
2.摘要
雨纹对图像质量的影响极大,基于数据驱动的单图像去噪方法不断发展并取得了巨大的成功。然而,传统的卷积…
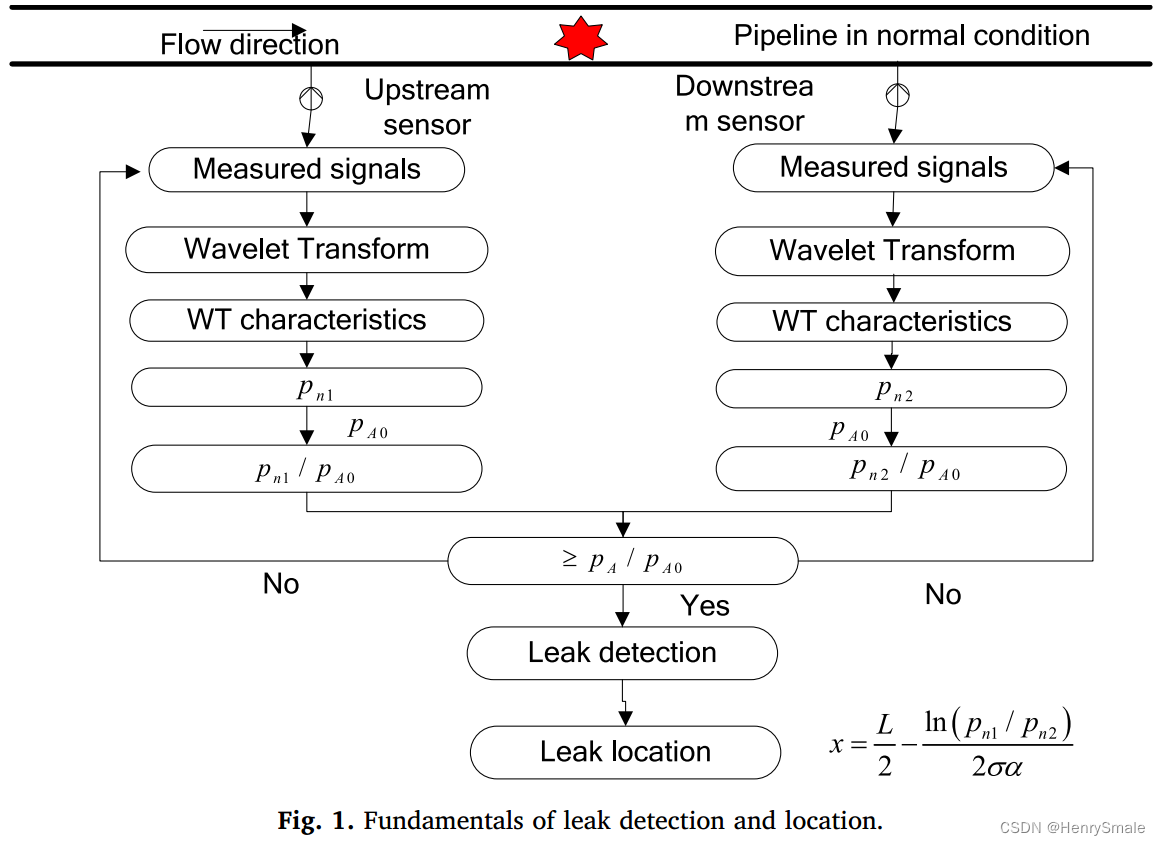
论文笔记:液体管道泄漏综合检测与定位模型
0 简介
An integrated detection and location model for leakages in liquid pipelines
1 摘要
许多液体,如水和油,都是通过管道运输的,在管道中可能发生泄漏,造成能源浪费、环境污染和对人类健康的威胁。本文描述了一种集成的…

【最新!红外小目标检测算法HCFNet】
文章目录 摘要1 引言2 相关工作2.1 传统方法2.2 深度学习方法 3 方法3.1 PPA3.2 维度感知选择性整合模块3.3 多稀释通道细化器模块3.4 损失函数设计 4 实验4.1 数据集与评估指标4.2 实现细节4.3 消融和对比 5 结论 论文:HCF-Net: Hierarchical Context Fusion Netwo…
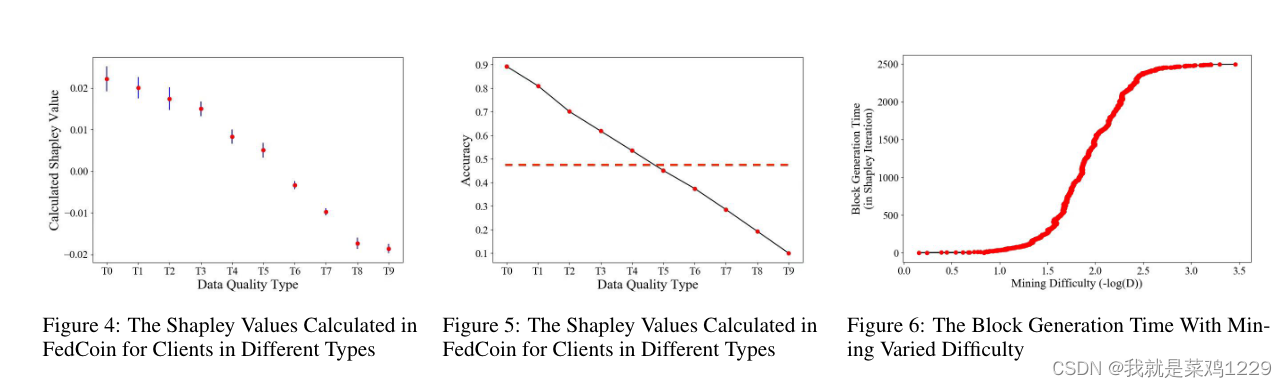
【FedCoin: A Peer-to-Peer Payment System for Federated Learning】
在这篇论文中,我们提出了FedCoin,一个基于区块链的点对点支付系统,专为联邦学习设计,以实现基于Shapley值的实际利润分配。在FedCoin系统中,区块链共识实体负责计算SV,并且新的区块是基于“Shapley证明”&a…
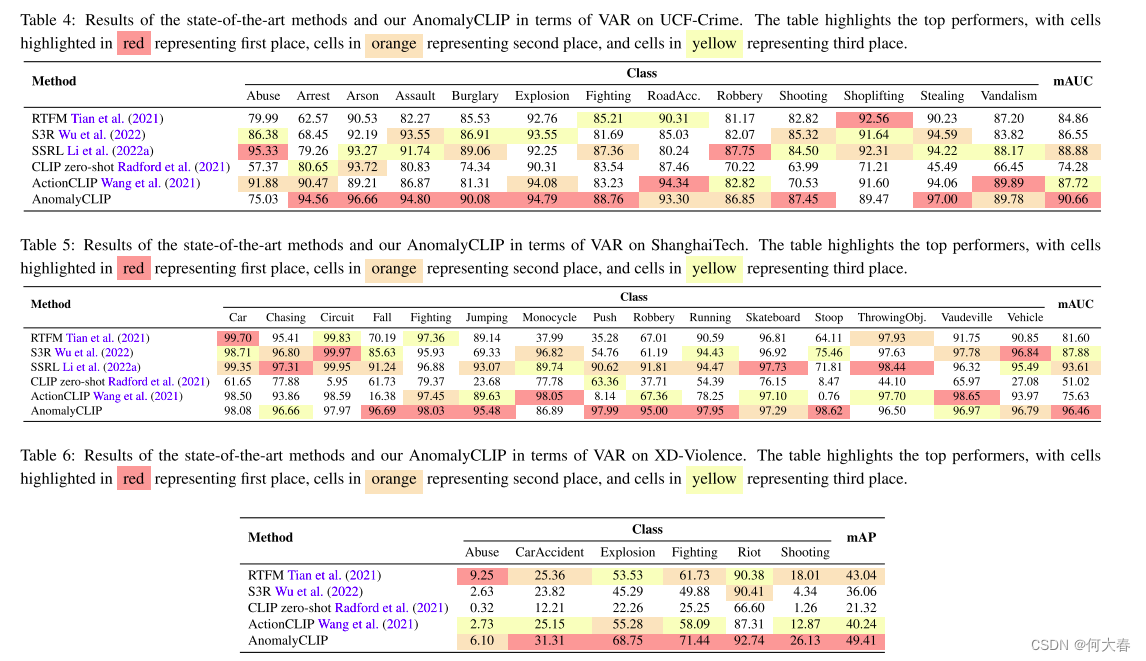
【视频异常检测】Delving into CLIP latent space for Video Anomaly Recognition 论文阅读
Delving into CLIP latent space for Video Anomaly Recognition 论文阅读 ABSTRACT1. Introduction2. Related Works3. Proposed approach3.1. Selector model3.2. Temporal Model3.3. Predictions Aggregation3.4. Training 4. Experiments4.1. Experiment Setup4.2. Evaluat…

论文笔记:分层问题-图像共注意力问答
整理了2017 Hierarchical Question-Image Co-Attention for Visual Question Answering)论文的阅读笔记 背景模型问题定义模型结构平行共注意力交替共注意力 实验可视化 背景 视觉问答(VQA)的注意力模型在此之前已经有了很多工作,这种模型生成了突出显示…
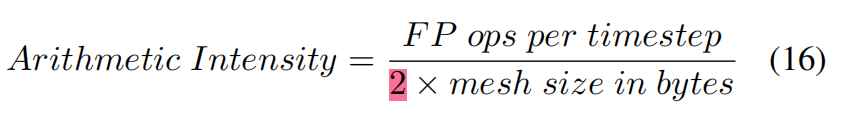
论文阅读,Accelerating the Lattice Boltzmann Method(五)
目录
一、Article:文献出处(方便再次搜索)
(1)作者
(2)文献题目
(3)文献时间
(4)引用
二、Data:文献数据(总结归纳,方便理解&am…
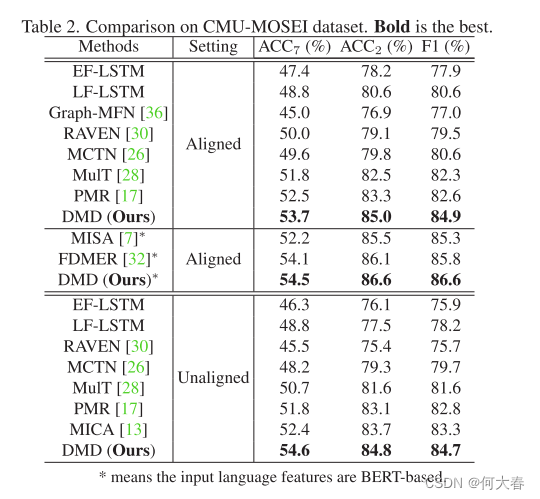
Decoupled Multimodal Distilling for Emotion Recognition 论文阅读
Decoupled Multimodal Distilling for Emotion Recognition 论文阅读 Abstract1. Introduction2. Related Works2.1. Multimodal emotion recognition2.2. Knowledge distillation3. The Proposed Method3.1. Multimodal feature decoupling3.2. GD with Decoupled Multimodal …

《Vision mamba》论文笔记
原文出处:
[2401.09417] Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model (arxiv.org)
原文笔记:
What:
Vision Mamba: Efficient Visual Representation Learning with Bidirectional St…

英语广场期刊投稿发表论文
《英语广场》是由国家新闻出版总署批准的正规期刊,杂志本着“轻松读原作,快乐学英语”的宗旨,倡导“寓学于乐”的学习理念,其活泼的办刊风格和优秀的文章选材受到读者特别是广大中学生的广泛欢迎,取得了良好的社会效益…
《论文阅读》一种基于反事实推理的会话情绪检测无训练去偏框架 EMNLP 2023
《论文阅读》一种基于反事实推理的会话情绪检测无训练去偏框架 EMNLP 2023 前言简介相关工作模型构架Basic ClassificationBias ExtractionUnbiased Inference实验结果前言
亲身阅读感受分享,细节画图解释,再也不用担心看不懂论文啦~ 无抄袭,无复制,纯手工敲击键盘~
今天…

Lightweight Frequency-Based Tiering for CXL Memory Systems——论文泛读
arXiv Paper CXL论文阅读笔记整理
问题
现代工作负载要求越来越大的内存容量。基于计算快速链路(CXL)的内存分层已成为一种很有前途的解决方案,通过在同一系统中使用传统DRAM和慢速层CXL内存设备来应对这一趋势。与本地DRAM相比,…
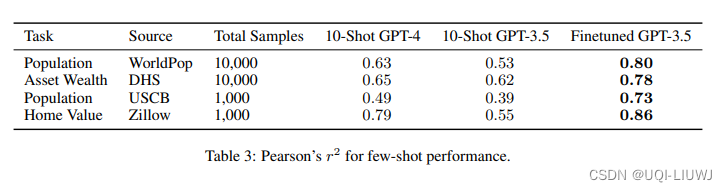
论文笔记:GEOLLM: EXTRACTING GEOSPATIALKNOWLEDGE FROM LARGE LANGUAGE MODELS
ICLR 2024 reviewer 评分 35668
1 intro
1.1 地理空间预测
地理空间预测在各个领域都有广泛的应用 包括贫困估算,公共卫生,粮食安全,生物多样性保护,环境保护。。。这些预测中使用的变量包括地理坐标、遥感数据、卫星图像、人类…

论文阅读-Policy Optimization for Continuous Reinforcement Learning
摘要
我们研究了连续时间和空间环境下的强化学习( RL ),其目标是一个具有折扣的无限时域,其动力学由一个随机微分方程驱动。基于连续RL方法的最新进展,我们提出了占用时间(专门针对一个折现目标)的概念,并展示了如何有效地利用它…

论文笔记✍GS3D- An Efficient 3D Object Detection Framework for Autonomous Driving
论文笔记✍GS3D: An Efficient 3D Object Detection Framework for Autonomous Driving
📜 Abstract 🔨 主流做法限制 :
我们在自动驾驶场景中提出了一种基于单个 RGB 图像的高效 3D 物体检测框架。我们的工作重点是提取 2D 图像中的底层 3…
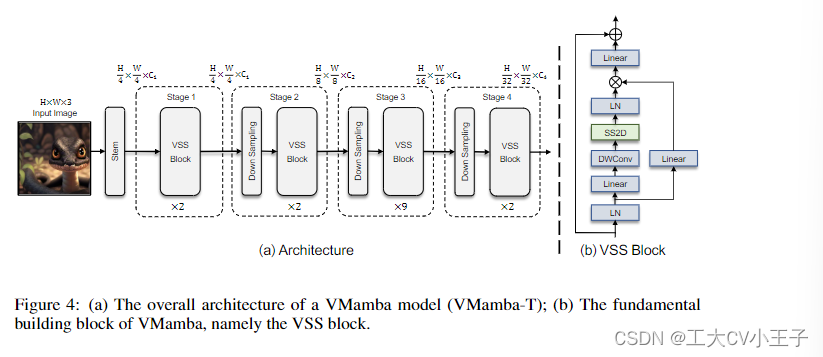
《VMamba》论文笔记
原文链接:
[2401.10166] VMamba: Visual State Space Model (arxiv.org)
原文笔记:
What:
VMamba: Visual State Space Model
Why:
多年以来CNN和VIT作为视觉特征提取的主流框架
CNN具有模型简单,共享权重&…
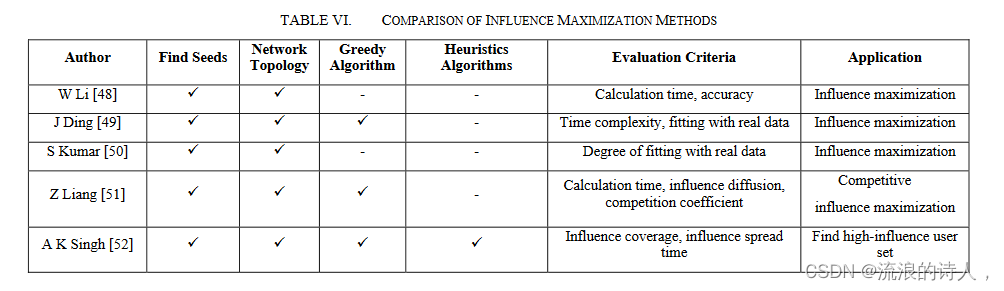
A Review on Influence Dissemination in Social Networks
Abstract 影响力传播研究是社交网络信息传播的关键问题。由于影响力分析在营销、广告、个性化推荐、舆情监测等方面的现实意义,研究人员从不同角度研究了该问题并提出了解决方案。在本文中,我们回顾了社交网络中的影响力传播,并得出结论&…
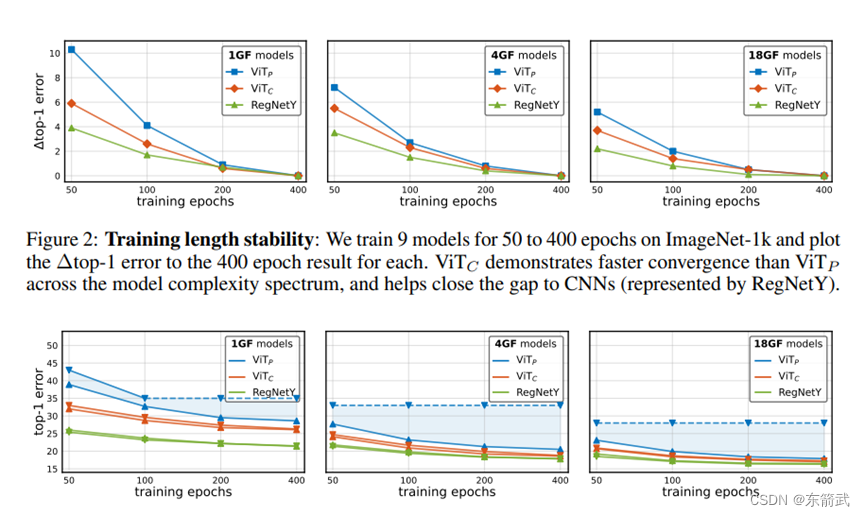
论文阅读---VITC----Early Convolutions Help Transformers See Better
论文题目:Early Convolutions Help Transformers See Better
早期的卷积网络帮助transformers性能提升
vit 存在不合格的可优化性,它们对优化器的选择很敏感。相反现代卷积神经网络更容易优化。
vit对优化器的选择[40](AdamW [27] vs. SGD)࿰…

论文笔记:基于多粒度信息融合的社交媒体多模态假新闻检测
整理了ICMR2023 Multi-modal Fake News Detection on Social Media via Multi-grained Information Fusion)论文的阅读笔记 背景模型实验 背景 在假新闻检测领域,目前的方法主要集中在文本和视觉特征的集成上,但不能有效地利用细粒度和粗粒度…
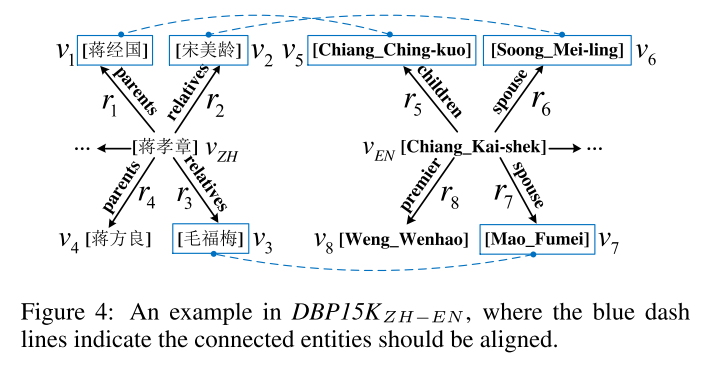

(表征学习论文阅读)A Simple Framework for Contrastive Learning of Visual Representations
Chen T, Kornblith S, Norouzi M, et al. A simple framework for contrastive learning of visual representations[C]//International conference on machine learning. PMLR, 2020: 1597-1607. 1. 前言
本文作者为了了解对比学习是如何学习到有效的表征,对本文所…

记录何凯明在MIT的第一堂课:神经网络发展史
https://www.youtube.com/watch?vZ5qJ9IxSuKo
目录
表征学习
主要特点:
方法和技术:
LeNet
全连接层
主要特点:
主要特点:
网络结构:
AlexNet
主要特点:
网络结构:
Sigmoid
Re…
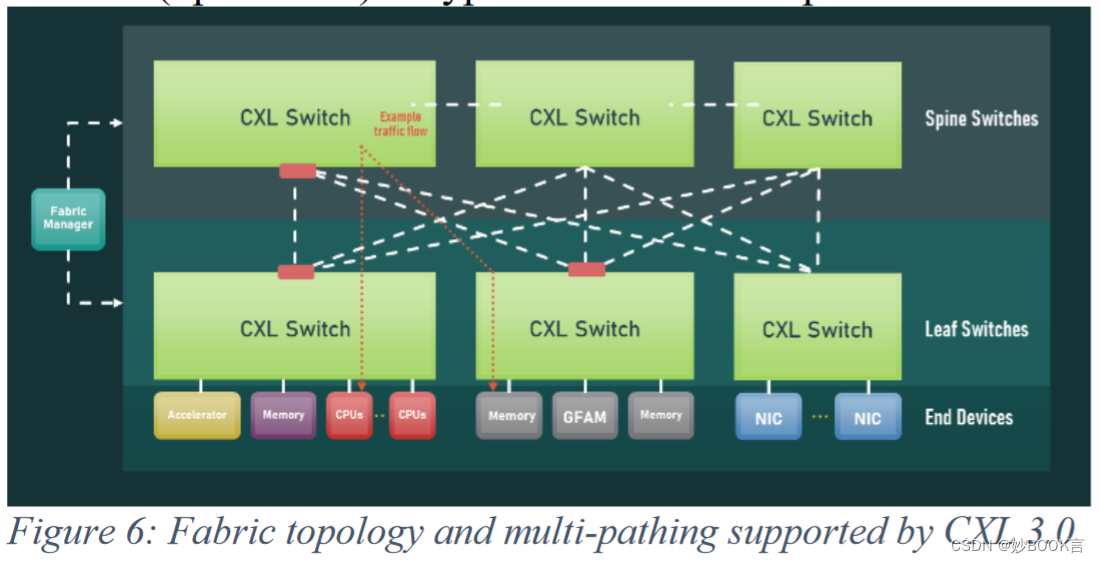
Compute Express Link (CXL): An Open Interconnect for Cloud Infrastructure——论文阅读
DAC 2023 Paper CXL论文阅读笔记整理
背景
Compute Express Link是一种开放的行业标准互连,在PCI Express(PCIe)之上提供缓存和内存语义,具有资源池和织物功能。本文探讨了CXL在解决云基础设施中的一些挑战方面的作用。
CXL主要…
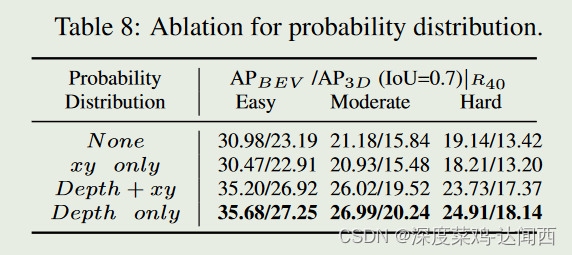
论文笔记 - :DIGGING INTO OUTPUT REPRESENTATION FOR MONOCULAR 3D OBJECT DETECTION
Title: 深入研究单目 3D 物体检测的输出表示
Abstract
单目 3D 对象检测旨在从单个图像中识别和定位 3D 空间中的对象。最近的研究取得了显着的进展,而所有这些研究都遵循基于 LiDAR 的 3D 检测中的典型输出表示。
然而,在本文中,我们认为…
Mamba: Linear-Time Sequence Modeling with Selective State Spaces(论文笔记)
What can I say?
2024年我还能说什么?
Mamba out!
曼巴出来了! 原文链接:
[2312.00752] Mamba: Linear-Time Sequence Modeling with Selective State Spaces (arxiv.org) 原文笔记:
What:
Mamba: Linear-Time …
AI论文速读 | 【综述】用于轨迹数据管理和挖掘的深度学习:综述与展望
论文标题:Deep Learning for Trajectory Data Management and Mining: A Survey and Beyond
作者:Wei Chen(陈伟), Yuxuan Liang(梁宇轩), Yuanshao Zhu, Yanchuan Chang, Kang Luo, Haomin Wen(温皓珉), Lei Li, Yanwei Yu(于彦伟), Qingsong Wen(文青…
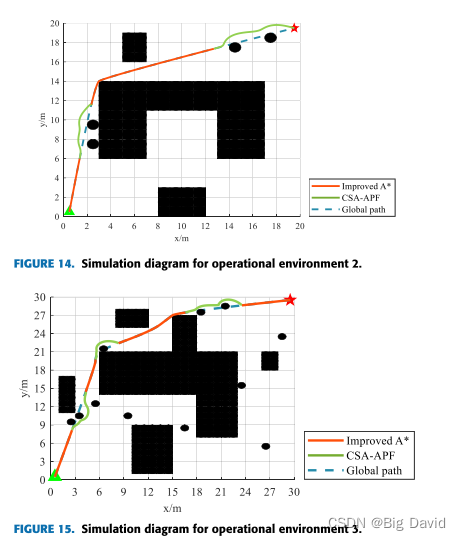
【一种基于改进A*算法和CSA-APF算法的混合路径规划方法】—— 论文阅读
论文题目:A Hybrid Path Planning Method Based on Improved A∗ and CSA-APF Algorithms
1 摘要
大问题:复杂动态环境下全局路径规划难以避开动态障碍物,且局部路径容易陷入局部最优的问题
问题1:针对A*算法产生冗余路径节点和…
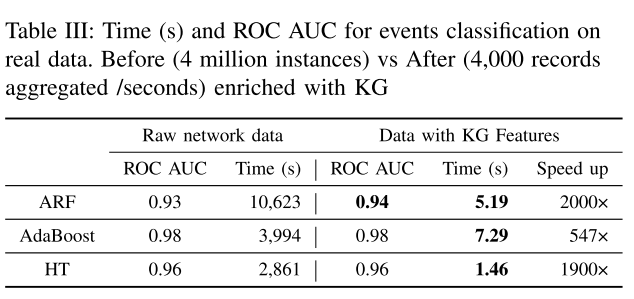
Stream2Graph论文翻译
Stream2Graph: Dynamic Knowledge Graph for Online Learning Applied in Large-scale Network
Abstract
知识图谱(KG)是用于存储某个领域(医疗保健、金融、电子商务、ITOps等)中的知识的有价值的信息来源。大多数工业KG本质上是动态的,因为它们定期更新流数据(客…

论文阅读 BERT GPT - transformer在NLP领域的延伸
文章目录 不会写的很详细,只是为了帮助我理解在CV领域transformer的拓展1 摘要1.1 BERT - 核心1.2 GPT - 核心 2 模型架构2.1 概览 3 区别3.1 finetune和prompt 3.2 transformer及训练总结 不会写的很详细,只是为了帮助我理解在CV领域transformer的拓展 …
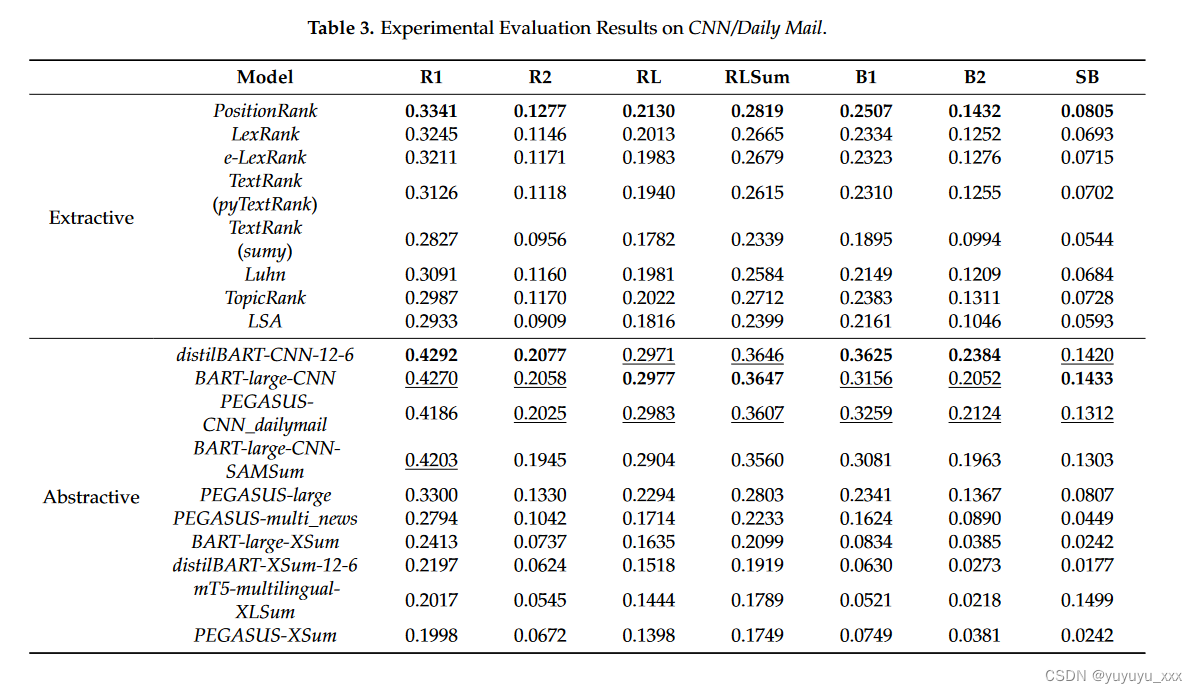
NLP论文阅读记录 - 05 | 2023 抽象总结与提取总结:实验回顾
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.相关工作2.1 提取方法2.2 抽象方法2.3 数据集 三.本文方法四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结思考 前言 Abstractive vs. Extractiv…
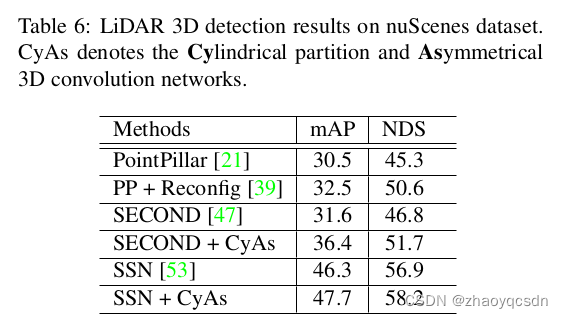
Cylinder3D论文阅读
Cylindrical and Asymmetrical 3D Convolution Networks for LiDAR Segmentation(2020年论文) 作者:香港中文大学 论文链接:https://arxiv.org/pdf/2011.10033.pdf 代码链接:https://github.com/xinge008/Cylinder3D
…

如何在电脑上免费更改 PDF 格式文档的字体大小?
对于需要编辑或修改的 PDF 文件来说,更改其字体大小是一个非常常见且必要的工作。虽然 Adobe Acrobat Pro DC 等专业的 PDF 编辑软件可以帮助您完成此任务,但他们通常都需要昂贵的恢复。幸运的是,有许多免费的 PDF 编辑工具可供选择。在本文中…

论文阅读:Feature Refinement to Improve High Resolution Image Inpainting
项目地址:https://github.com/geomagical/lama-with-refiner 论文地址:https://arxiv.org/abs/2109.07161 发表时间:2022年6月29日 项目体验地址:https://colab.research.google.com/github/advimman/lama/blob/master/colab/LaMa…
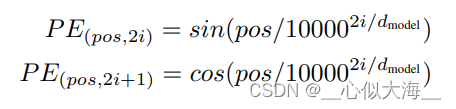
论文阅读:Attention is all you need
【最近课堂上Transformer之前的DL基础知识储备差不多了,但学校里一般讲到Transformer课程也接近了尾声;之前参与的一些科研打杂训练了我阅读论文的能力和阅读源码的能力,也让我有能力有兴趣对最最源头的论文一探究竟;我最近也想按…
论文阅读笔记AI篇 —— Transformer模型理论+实战 (二)
论文阅读笔记AI篇 —— Transformer模型理论实战(二) 第二遍阅读(通读)2.1 Background2.2 Model Architecture2.2.1 Encoder and Decoder Stacks2.2.2 Scaled Dot-Product Attention2.2.3 Multi-Head Attention 2.3 Why Self-Atte…
【论文总结】基于深度学习的特征点提取,特征点检测的方法总结
这里写目录标题 相关工作1. Discriminative Learning of Deep Convolutional Feature Point Descriptors(2015)网络结构sift算法损失函数的构建 2.MatchNet(2015)网络中的组成部分其他组成部分损失函数结果 3.LIFT: Learned Invariant Feature Transform(2016)网络结构训练网络…
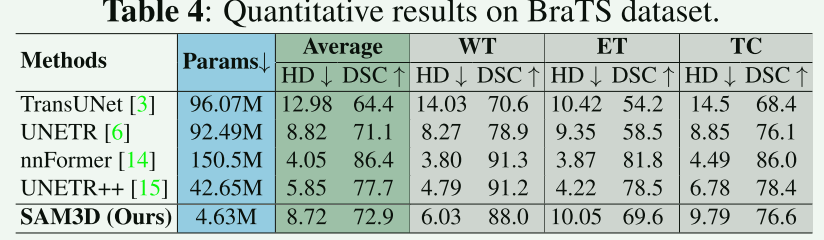
【论文阅读笔记】Sam3d: Segment anything model in volumetric medical images[
Bui N T, Hoang D H, Tran M T, et al. Sam3d: Segment anything model in volumetric medical images[J]. arXiv preprint arXiv:2309.03493, 2023.【开源】
本文提出的SAM3D模型是针对三维体积医学图像分割的一种新方法。其核心在于将“分割任何事物”(SAM&#…
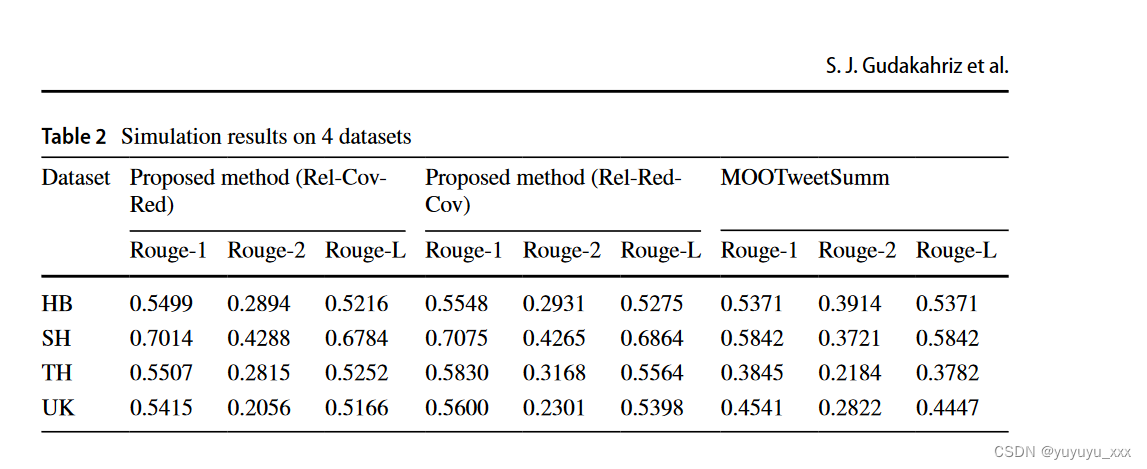
NLP论文阅读记录 - 2022 | W0S 基于文本概念的多目标剪枝观点文本摘要
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.文本摘要的文献综述和分类2.1文本摘要分类2.2 以前的作品 三.本文方法3.1 总结为两阶段学习3.1.1 基础系统 3.2 重构文本摘要 四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实…

论文阅读笔记AI篇 —— Transformer模型理论+实战 (四)
论文阅读笔记AI篇 —— Transformer模型理论实战 (四) 一、理论1.1 理论研读1.2 什么是AI Agent? 二、实战2.1 先导知识2.1.1 tensor的创建与使用2.1.2 PyTorch的模块2.1.2.1 torch.nn.Module类的继承与使用2.1.2.2 torch.nn.Linear类 2.2 Transformer代…
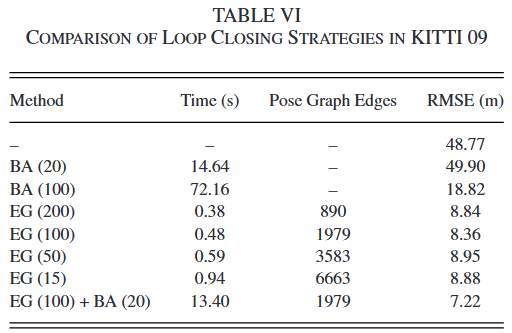
ORB-SLAM 论文阅读
论文链接
ORB-SLAM 0. Abstract
本文提出了 ORB-SLAM,一种基于特征的单目同步定位和建图 (SLAM) 系统该系统对严重的运动杂波具有鲁棒性,允许宽基线环路闭合和重新定位,并包括全自动初始化选择重建的点和关键帧的适者生存策略具有出色的鲁棒…

论文阅读2---多线激光lidar内参标定原理
前言:该论文介绍多线激光lidar的标定内参的原理,有兴趣的,可研读原论文。
1、标定参数
rotCorrection:旋转修正角,每束激光的方位角偏移(与当前旋转角度的偏移,正值表示激光束逆时针旋转&…
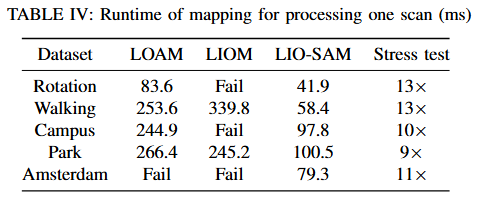
LIO-SAM 论文阅读
论文链接
LIO-SAM 0. Abstract
提出了一种通过平滑和映射进行紧耦合激光雷达惯性里程计的框架 LIO-SAM,它实现了高精度、实时的移动机器人轨迹估计和地图构建 LIO-SAM 在因子图上制定激光雷达惯性里程计,允许将多种相对和绝对测量(包括闭环…
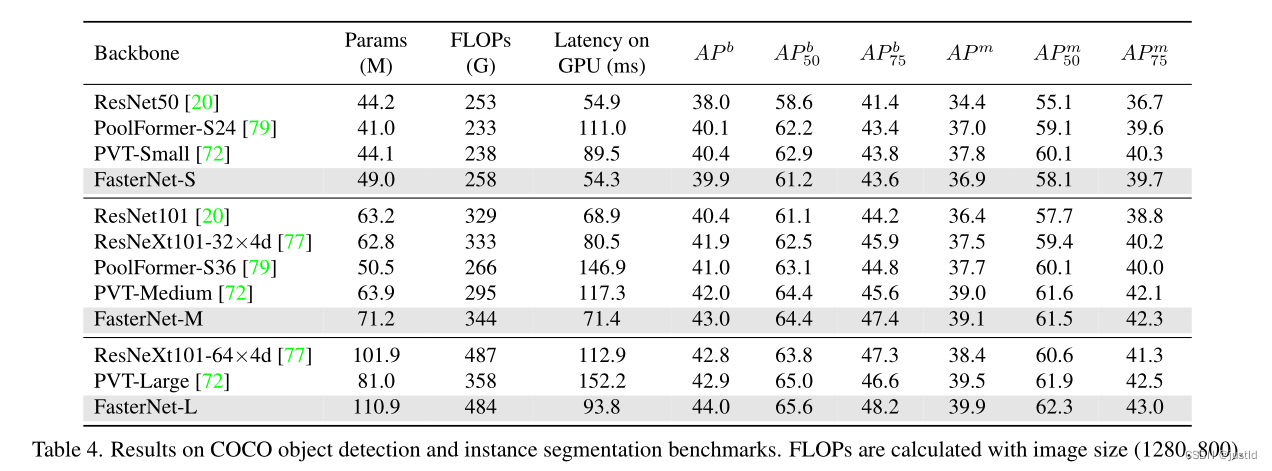
【论文笔记】Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks
论文地址:Run, Dont Walk: Chasing Higher FLOPS for Faster Neural Networks
代码地址:https://github.com/jierunchen/fasternet
该论文主要提出了PConv,通过优化FLOPS提出了快速推理模型FasterNet。
在设计神经网络结构的时候ÿ…

论文阅读 - Non-Local Spatial Propagation Network for Depth Completion
文章目录 1 概述2 模型说明2.1 局部SPN2.2 非局部SPN2.3 结合置信度的亲和力学习2.3.1 传统正则化2.3.2 置信度引导的affinity正则化 3 效果3.1 NYU Depth V23.2 KITTI Depth Completion 参考资料 1 概述
本文提出了一种非局部的空间传播网络用于深度图补全,简称为…
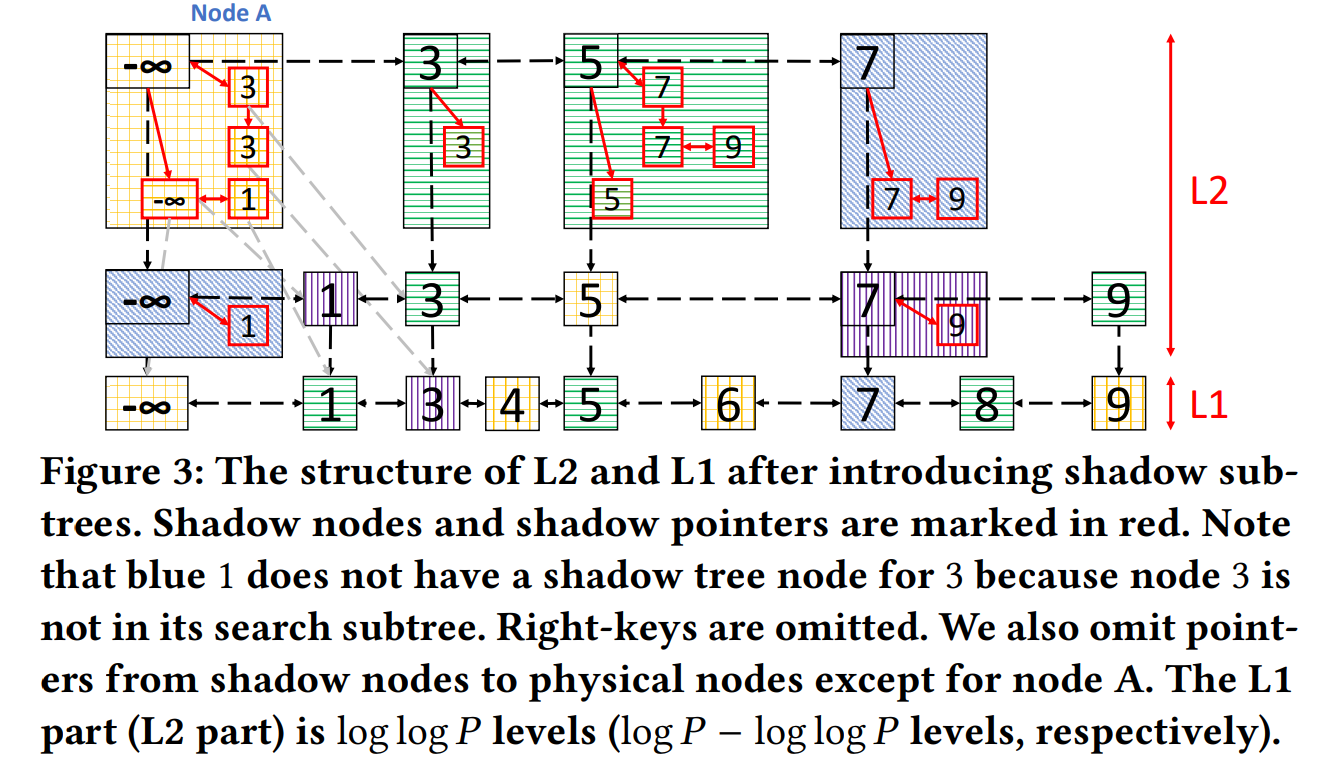
论文阅读-PIM-tree:一种面向内存处理的抗偏移索引
论文名称:PIM-tree: A Skew-resistant Index for Processing-in-Memory
摘要
当今的内存索引性能受到内存延迟/带宽瓶颈的限制。Processing-in-memory (PIM) 是一种新兴的方法,可能通过实现低延迟内存访问,其聚合内存带宽随 PIM 节点数量扩…

TRS 2024 论文阅读 | 基于点云处理和点Transformer网络的人体活动连续识别
注1:本文系“无线感知论文速递”系列之一,致力于简洁清晰完整地介绍、解读无线感知领域最新的顶会/顶刊论文(包括但不限于 Nature/Science及其子刊; MobiCom, Sigcom, MobiSys, NSDI, SenSys, Ubicomp; JSAC, 雷达学报 等)。 本次介绍的论文是:<IEEE Transactions on Radar …
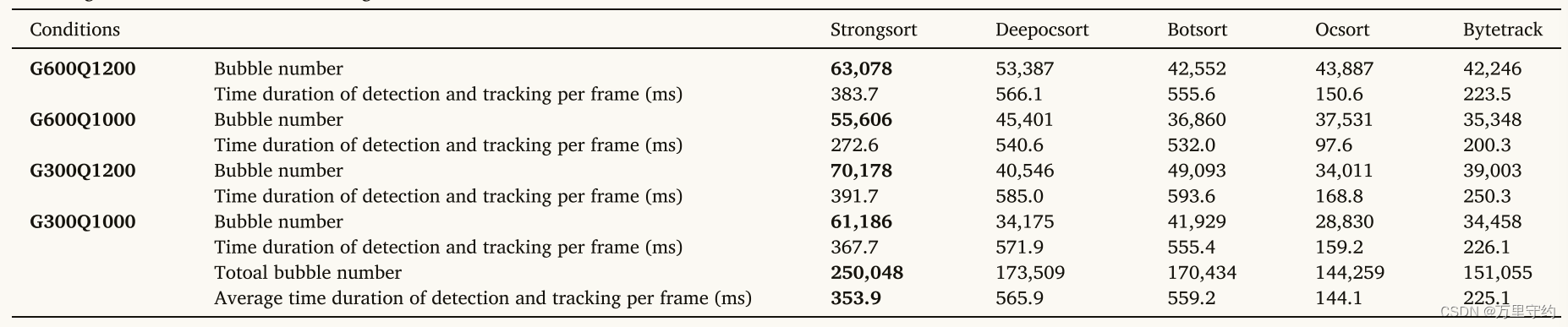
【论文阅读】基于人工智能目标检测与跟踪技术的过冷流沸腾气泡特征提取
Bubble feature extraction in subcooled flow boiling using AI-based object detection and tracking techniques 基于人工智能目标检测与跟踪技术的过冷流沸腾气泡特征提取 期刊信息:International Journal of Heat and Mass Transfer 2024 级别:EI检…

用于自动驾驶最优间距选择和速度规划的多配置二次规划(MPQP) 论文阅读
论文链接:https://arxiv.org/pdf/2401.06305.pdf
论文题目:用于自动驾驶最优间距选择和速度规划的多配置二次规划(MPQP)
1 摘要
本文介绍了用于自动驾驶最优间距选择和速度规划的多配置二次规划(MPQP)。…

【论文阅读】Grasp-Anything: Large-scale Grasp Dataset from Foundation Models
文章目录 Grasp-Anything: Large-scale Grasp Dataset from Foundation Models针对痛点和贡献摘要和结论引言相关工作Grasp-Anything 数据集实验 - 零镜头抓取检测实验 - 机器人评估总结 Grasp-Anything: Large-scale Grasp Dataset from Foundation Models
Project page&…
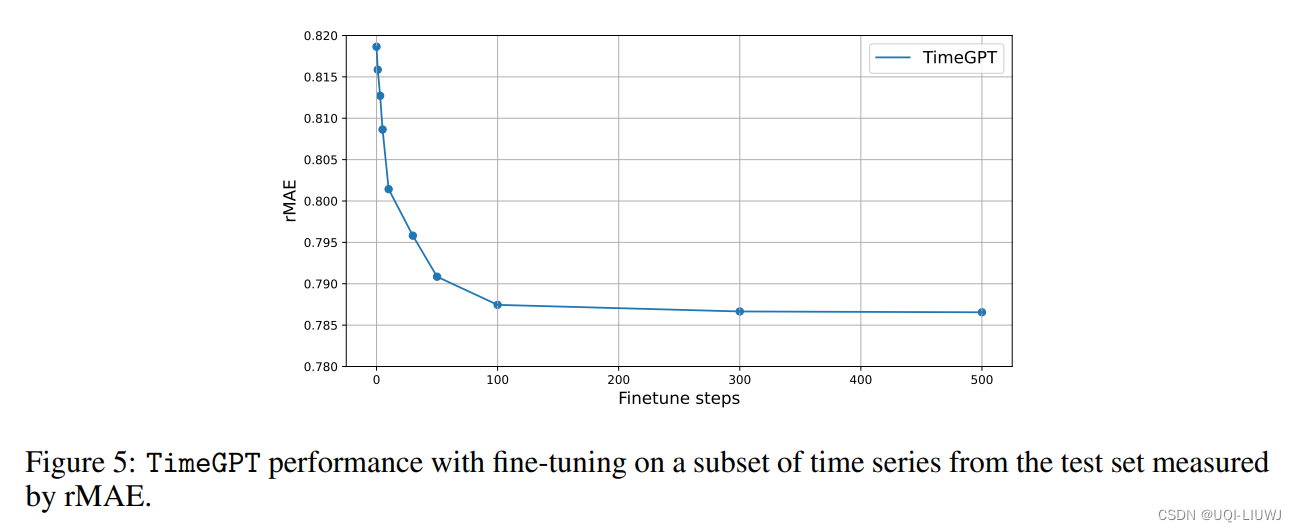
论文笔记:TimeGPT-1
时间序列的第一个基础大模型
1 方法
最basic的Transformer架构 采用了公开可用的最大时间序列数据集进行训练,包含超过1000亿个数据点。 训练集涵盖了来自金融、经济、人口统计、医疗保健、天气、物联网传感器数据、能源、网络流量、销售、交通和银行业等广泛领域…
![[论文阅读] |RAG评估_Retrieval-Augmented Generation Benchmark](https://img-blog.csdnimg.cn/direct/917cb2d98d70495c96388e5cba5fcd64.png)
[论文阅读] |RAG评估_Retrieval-Augmented Generation Benchmark
写在前面
检索增强能够有效缓解大模型存在幻觉和知识时效性不足的问题,RAG通常包括文本切分、向量化入库、检索召回和答案生成等基本步骤。近期组里正在探索如何对RAG完整链路进行评估,辅助阶段性优化工作。上周先对评估综述进行了初步的扫描࿰…
【论文阅读】Long-Tailed Recognition via Weight Balancing(CVPR2022)
论文
问题:真实世界中普遍存在长尾识别问题,朴素训练产生的模型在更高准确率方面偏向于普通类,导致稀有的类别准确率偏低。 key:解决LTR的关键是平衡各方面,包括数据分布、训练损失和学习中的梯度。 文章主要讨论了三种方法&…

论文笔记:多任务学习模型:渐进式分层提取(PLE)含pytorch实现
整理了RecSys2020 Progressive Layered Extraction : A Novel Multi-Task Learning Model for Personalized Recommendations)论文的阅读笔记 背景模型代码 论文地址:PLE
背景 多任务学习(multi-task learning,MTL)&a…
论文阅读-面向公平性的分布式系统负载均衡机制
摘要
当一组自利的用户在分布式系统中共享多个资源时,我们面临资源分配问题,即所谓的负载均衡问题。特别地,负载均衡被定义为将负载分配到分布式系统的服务器上,以便最小化作业响应时间并提高服务器的利用率。在本文中࿰…

《Solving Long-tailed Recognition with Deep Realistic Taxonomic Classifier》阅读笔记
论文标题
《Solving Long-tailed Recognition with Deep Realistic Taxonomic Classifier》
使用深度现实分类器解决长尾识别问题
作者
Tz-Ying Wu、Pedro Morgado、Pei Wang、Chih-Hui Ho 和 Nuno Vasconcelos
来自加州大学圣地亚哥分校
初读
摘要 长尾识别问题&#x…
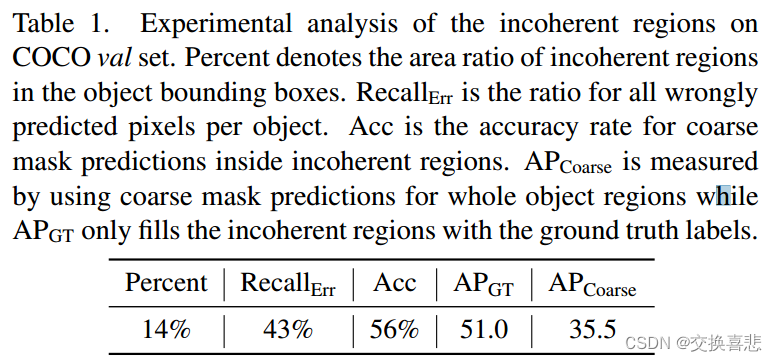
实例分割论文阅读之:《Mask Transfiner for High-Quality Instance Segmentation》
1.摘要
两阶段和基于查询的实例分割方法取得了显著的效果。然而,它们的分段掩模仍然非常粗糙。在本文中,我们提出了一种高质量和高效的实例分割Mask Transfiner。我们的Mask Transfiner不是在规则的密集张量上操作,而是将图像区域分解并表示…
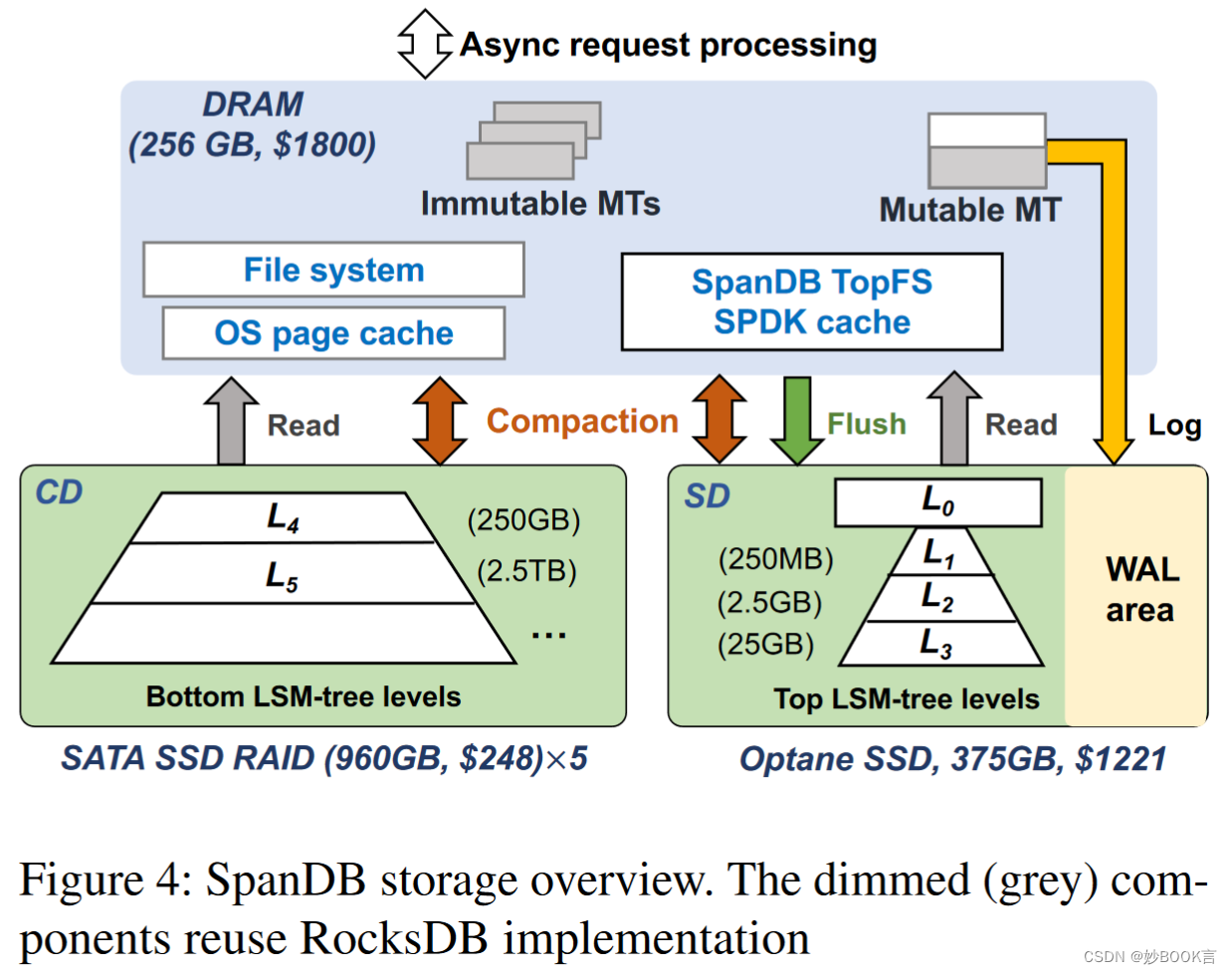
SpanDB: A Fast, Cost-Effective LSM-tree Based KV Store on Hybrid Storage——论文泛读
FAST 2021 Paper 论文阅读笔记整理
问题
键值(KV)存储支持许多关键的应用和服务。它们在内存中执行快速处理,但通常受到I/O性能的限制。最近出现的高速NVMe SSD推动了新KV系统设计,以利用其低延迟和高带宽。
挑战
当前基于LSM…

论文阅读:GamutMLP A Lightweight MLP for Color Loss Recovery
这篇文章是关于色彩恢复的一项工作,发表在 CVPR2023,其中之一的作者是 Michael S. Brown,这个老师是加拿大 York 大学的,也是 ISP 领域的大牛,现在好像也在三星研究院担任兼职,这个老师做了很多这种类似的工…
PointMixer论文阅读笔记
MLP-mixer是最近很流行的一种网络结构,比起Transformer和CNN的节构笨重,MLP-mixer不仅节构简单,而且在图像识别方面表现优异。但是MLP-mixer在点云识别方面表现欠佳,PointMixer就是在保留了MLP-mixer优点的同时,还可以…
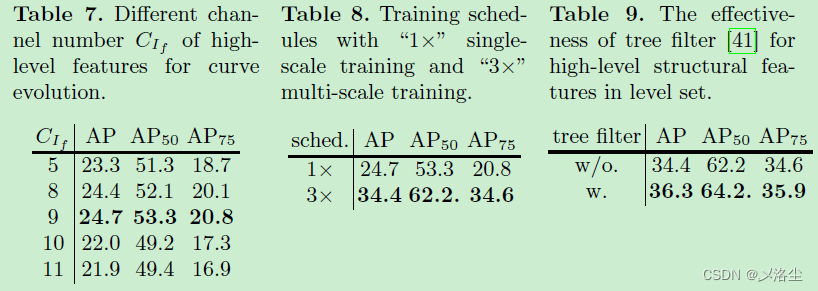
弱监督实例分割 Box-supervised Instance Segmentation with Level Set Evolution 论文笔记
弱监督实例分割 Box-supervised Instance Segmentation with Level Set Evolution 论文笔记一、Abstract二、引言三、相关工作3.1 基于 Box 的实例分割3.2 基于层级的分割四、提出的方法4.1 图像分割中的层级模型4.2 基于 Box 的实例分割在 Bounding Box 内的层级进化输入的数据…
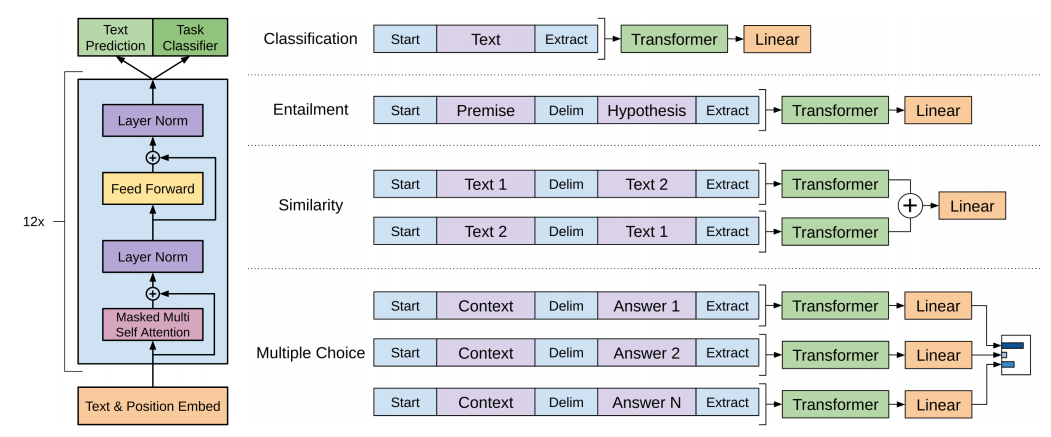
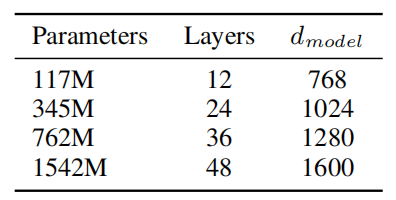
不确定性问题的论文笔记
Statistics starting from 01/2024, 仅列出了优秀工作中的一部分 每一年的排列顺序: CVPR, ICLR, ECCV, ICCV, ICML, AAAI, TPAMI,TIP,Arxiv 等 每周更新 2024
论文信息速览笔记是 否 已精读精读笔记Shao W, Xu Y, Peng L, et al. Failure Detection fo…

【论文阅读】【yolo系列】YOLO-Pose的论文阅读
Abstract 我们介绍YOLO-pose,一种无热图联合检测的新方法,基于流行的YOLO目标检测框架的图像二维多人姿态估计。 【现有方法的问题】现有的基于热图的两阶段方法是次优的,因为它们不是端到端可训练的,训练依赖于surrogate L1 loss…
MLP-Mixer: AN all MLP Architecture for Vision
发表于NeurIPS 2021, 由Google Research, Brain Team发表。 Mixer Architecture
Introduction
当前的深度视觉结构包含融合特征(mix features)的层:(i)在一个给定的空间位置融合。(ii)在不同的空间位置,或者一次融合所有。在CNN中,(ii) 是由N x N(N &g…
《论文阅读》通过识别对话中的情绪原因来提高共情回复的产生 EMNLP 2021
《论文阅读》通过识别对话中的情绪原因来提高共情回复的产生 EMNLP 2021 前言简介方法实现Emotion ReasonerResponse Generator实验结果示例总结前言
亲身阅读感受分享,细节画图解释,再也不用担心看不懂论文啦~ 无抄袭,无复制,纯手工敲击键盘~ 今天为大家带来的是《Improv…

【论文阅读笔记】Revisiting RCAN: Improved Training for Image Super-Resolution
论文地址:https://arxiv.org/abs/2201.11279 代码地址:https://github.com/zudi-lin/rcan-it
论文小结 本文的工作,就是重新审视之前的RCAN,然后做实验来规范化SR任务的训练流程。 此外,作者得出一个结论:…
论文阅读:Ground-Fusion: A Low-cost Ground SLAM System Robust to Corner Cases
前言
最近看到一篇ICRA2024上的新文章,是关于多传感器融合SLAM的,好像使用了最近几年文章中较火的轮式里程计。感觉这篇文章成果不错,代码和数据集都是开源的,今天仔细读并且翻译一下,理解创新点、感悟研究方向、指导…
YOLO系列论文阅读(v1--v3)
搞目标检测,绕不开的一个框架就是yolo,而且更糟糕的是,随着yolo的发展迭代,yolo网络可以做的事越来越多,语义分割,关键点检测,3D目标检测。。。这几天决定把YOLO系列彻底梳理一下,在…

浅析扩散模型与图像生成【应用篇】(四)——Palette
4. Palette: Image-to-Image Diffusion Models 该文提出一种基于扩散模型的通用图像转换(Image-to-Image Translation)模型——Palette,可用于图像着色,图像修复,图像补全和JPEG图像恢复等多种转换任务。Palette是一种…

【论文阅读】多传感器SLAM数据集
一、M2DGR
该数据集主要针对的是地面机器人,文章正文提到,现在许多机器人在进行定位时,其视角以及移动速度与车或者无人机有着较大的差异,这一差异导致在地面机器人完成SLAM任务时并不能直接套用类似的数据集。针对这一问题该团队…
单词级文本攻击—论文阅读
TAAD2.2论文概览 0.前言1-101.Bridge the Gap Between CV and NLP! A Gradient-based Textual Adversarial Attack Frameworka. 背景b. 方法c. 结果d. 论文及代码 2.TextHacker: Learning based Hybrid Local Search Algorithm for Text Hard-label Adversarial Attacka. 背景b…

Detecting Twenty-thousand Classes using Image-level Supervision
Detecting Twenty-thousand Classes using Image-level Supervision 摘要背景方法PreliminariesDetic:具有图像类别的检测器loss技术细节扩展Grad-CAMGrad-CAM原理 总结 摘要 摘要 由于检测数据集的规模较小,目前的物体检测器在词汇量方面受到限制。而图像分类器的数…

【论文翻译】Mamba 中的状态空间模型背景
文章目录 Chapter 2 用状态空间模型进行序列建模2.1 背景:序列建模框架2.1.1 用深度序列模型学习 2.2 背景:状态空间模型2.2.1 线性时不变SSM 2.3 状态空间序列模型2.3.1连续化表达(离散化)BilinearZOH 对应于Mamba作者博士论文MO…
用HARU-Net增强核分割:一种基于混合注意的残差u块网络
文章目录 Enhancing Nucleus Segmentation with HARU-Net: A Hybrid Attention Based Residual U-Blocks Network摘要本文方法损失函数后处理消融实验 Enhancing Nucleus Segmentation with HARU-Net: A Hybrid Attention Based Residual U-Blocks Network
摘要
核图像分割是…
【论文阅读】单词级文本攻击TAAD2.2
TAAD2.2论文概览 0.前言1-101.Bridge the Gap Between CV and NLP! A Gradient-based Textual Adversarial Attack Frameworka. 背景b. 方法c. 结果d. 论文及代码 2.TextHacker: Learning based Hybrid Local Search Algorithm for Text Hard-label Adversarial Attacka. 背景b…
【图像拼接/视频拼接】论文精读:Efficient Video Stitching Based on Fast Structure Deformation
第一次来请先看这篇文章:【图像拼接(Image Stitching)】关于【图像拼接论文精读】专栏的相关说明,包含专栏使用说明、创新思路分享等(不定期更新)
图像拼接系列相关论文精读 Seam Carving for Content-Aware Image ResizingAs-Rigid-As-Possible Shape ManipulationAdap…
【论文阅读随笔】RoPE/旋转编码:ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING
文章目录 1.目的:通过绝对位置编码的方式实现相对位置编码2.理解RoPE,在我看来有几个需要注意的点:3.本文相关复数概念:3.1.复数乘法的几何意义3.2.复数内积 VS. 复数乘法 4.REF: 1.目的:通过绝对位置编码的…
【论文阅读】(2024.03.05-2024.03.15)论文阅读简单记录和汇总
(2024.03.05-2024.03.15)论文阅读简单记录和汇总 2024/03/05:随便简单写写,以后不会把太详细的记录在CSDN,有道的Markdown又感觉不好用。
目录
(ICMM 2024)Quality Scalable Video Coding Based on Neural Represent…
论文阅读:Diffusion Model-Based Image Editing: A Survey
Diffusion Model-Based Image Editing: A Survey
论文链接 GitHub仓库
摘要
这篇文章是一篇基于扩散模型(Diffusion Model)的图片编辑(image editing)方法综述。作者从多个方面对当前的方法进行分类和分析,包括学习…
论文阅读_解释大模型_语言模型表示空间和时间
英文名称: LANGUAGE MODELS REPRESENT SPACE AND TIME
中文名称: 语言模型表示空间和时间
链接: https://www.science.org/doi/full/10.1126/science.357.6358.1344
https://arxiv.org/abs/2310.02207
作者: Wes Gurnee & Max Tegmark
机构: 麻省理工学院
日期: 2023-10-03…
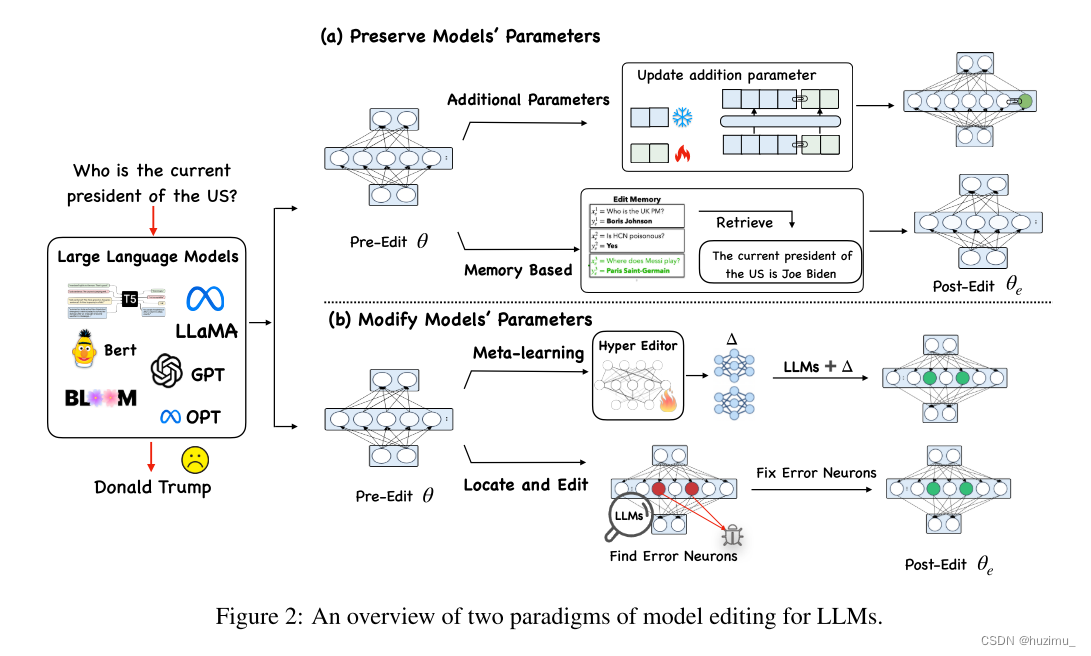
论文阅读:Editing Large Language Models: Problems, Methods, and Opportunities
Editing Large Language Models: Problems, Methods, and Opportunities
论文链接 代码链接
摘要
由于大语言模型(LLM)中可能存在一些过时的、不适当的和错误的信息,所以有必要纠正模型中的相关信息。如何高效地修改模型中的相关信息而不影…

RUAS论文阅读笔记
这是CVPR2021的一篇暗光增强的论文
Retinex增强和去噪部分
第一部分的核心公式是一种retinex公式(用于暗图增强的retinex公式有几种类型,虽然本质一样但是对于各个分量的定义不一样):yx⊗tyx\otimes tyx⊗t,其中x是正…
文献速递:深度学习乳腺癌诊断---使用深度学习改善乳腺癌组织学分级
Title
题目 Improved breast cancer histological grading using deep learning
使用深度学习改善乳腺癌组织学分级 01
文献速递介绍 乳腺癌组织学分级是乳腺癌中一个确立的临床变量,它包括来自三个方面的信息,即小管形成程度、核多态性和有丝分裂计…
Similarity and Matching of Neural Network Representations 论文阅读笔记
这是NIPS2021的一篇论文,文章主要是探究了通过一个stiching layer将两个已训练的不同初始化的相同结构的网络的某一层进行匹配的可能性。 前言
作者对 “什么情况下两个表征是相似的?” 提出了一个新的问题:“如果我们知道两个表征是相似的&…

【论文阅读总结】Mask R-CNN翻译总结
Mask R-CNN1.摘要Mask R-CNN相关介绍与优点2.引言3.文献综述3.1 R-CNN3.2 Instance Segmentation【实例分割】4. Mask R-CNN介绍4.1 Faster R-CNN(相关细节请看相关文章)4.2 Mask R-CNN4.3 Mask Representation【遮罩表示法】4.4 RoIAlign【感兴趣区域对齐】4.4.1 RoIPool【感兴…
【论文笔记】Learning Deconvolution Network for Semantic Segmentation
重要说明:严格来说,论文所指的反卷积并不是真正的 deconvolution network 。 关于 deconvolution network 的详细介绍,请参考另一篇博客:什么是Deconvolutional Network?
一、参考资料
Learning Deconvolution Netwo…

论文笔记(四十二)Diff-DOPE: Differentiable Deep Object Pose Estimation
Diff-DOPE: Differentiable Deep Object Pose Estimation 文章概括摘要I. 介绍II. 相关工作III. DIFF-DOPEIV. 实验结果A. 实施细节和性能B. 准确性C. 机器人-摄像机校准 V. 结论VI. 致谢 文章概括
作者:Jonathan Tremblay, Bowen Wen, Valts Blukis, Balakumar Su…

【论文笔记】Attention和Visual Transformer
Attention和Visual Transformer Attention和Transformer为什么需要AttentionAttention机制Multi-head AttentionSelf Multi-head Attention,SMA TransformerVisual Transformer,ViT Attention和Transformer
Attention机制在相当早的时间就已经被提出了&…
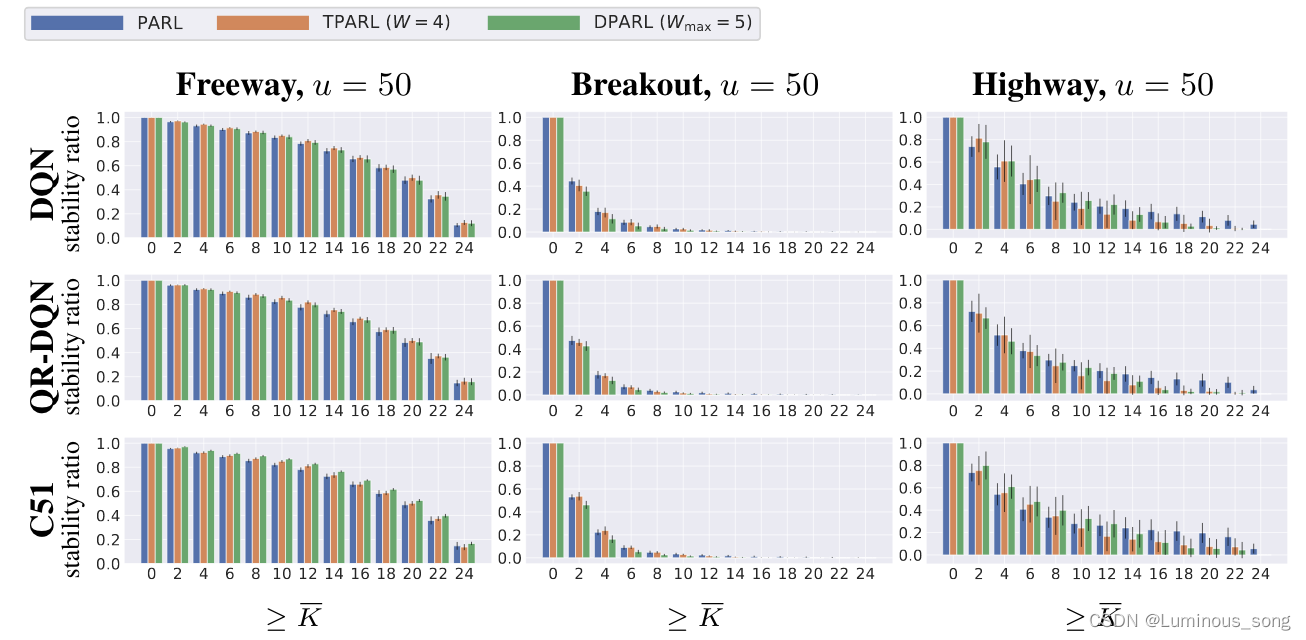
【论文阅读】COPA:验证针对中毒攻击的离线强化学习的稳健策略
COPA: Certifying Robust Policies for Offline Reinforcement Learning against Poisoning Attacks
作者:Fan Wu, Linyi Li, Chejian Xu 发表会议:2022ICRL
摘要
目前强化学习完成任务的水平已经和人类相接近,因此研究人员的目光开始转向…

【论文阅读】RapSheet:端点检测和响应系统的战术来源分析(SP-2020)
Tactical Provenance Analysis for Endpoint Detection and Response Systems S&P-2022 伊利诺伊大学香槟分校 Hassan W U, Bates A, Marino D. Tactical provenance analysis for endpoint detection and response systems[C]//2020 IEEE Symposium on Security and Priva…
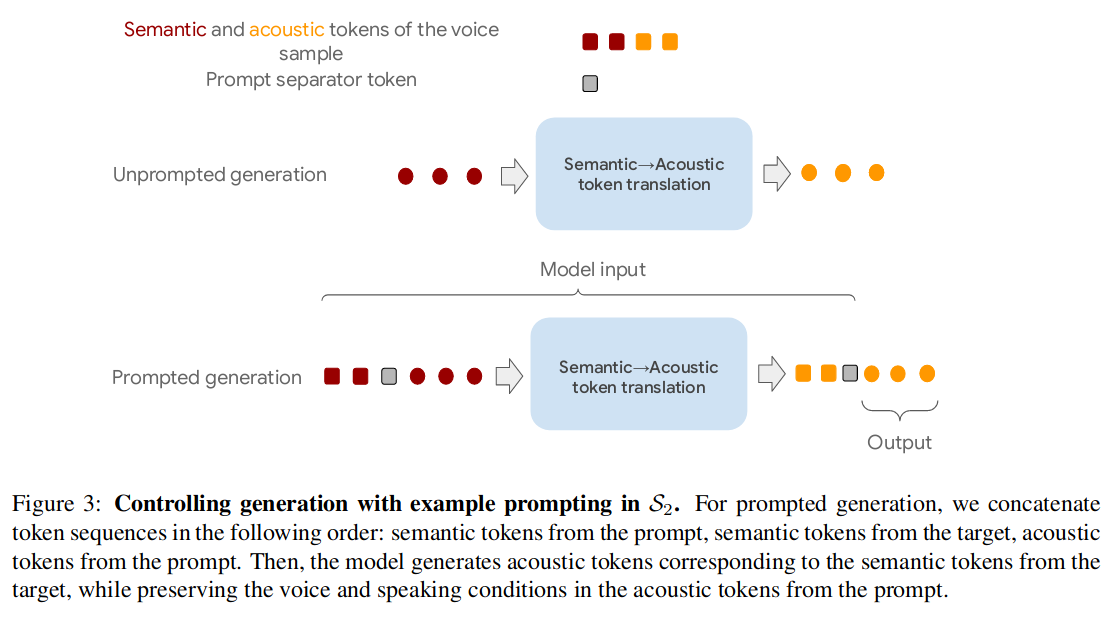
论文阅读_语音合成_Spear-TTS
论文信息
number headings: auto, first-level 2, max 4, _.1.1 name_en: Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision name_ch: 说话、阅读和提示:少量监督实现高保真文本转语音 paper_addr: http://arxiv.org/abs/2302.0354…
![[论文阅读] (30)李沐老师视频学习——3.研究的艺术·讲好故事和论点](https://img-blog.csdnimg.cn/4d4a9a2edc814a68bfb40eac06927424.png#pic_center)
[论文阅读] (30)李沐老师视频学习——3.研究的艺术·讲好故事和论点
《娜璋带你读论文》系列主要是督促自己阅读优秀论文及听取学术讲座,并分享给大家,希望您喜欢。由于作者的英文水平和学术能力不高,需要不断提升,所以还请大家批评指正,非常欢迎大家给我留言评论,学术路上期…
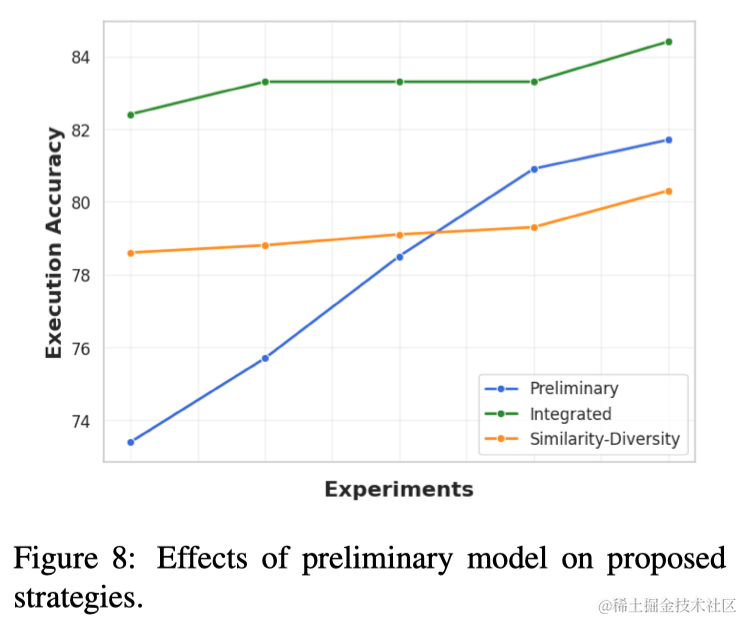
LLM少样本示例的上下文学习在Text-to-SQL任务中的探索
导语
本文探索了如何通过各种提示设计策略,来增强大型语言模型(LLMs)在Few-shot In-context Learning中的文本到SQL转换能力。通过使用示例SQL查询的句法结构来检索演示示例,并选择同时追求多样性和相似性的示例可以提高性能&…
![[论文总结] 深度学习在农业领域应用论文笔记12](https://img-blog.csdnimg.cn/img_convert/b1683bbd890e82d3bd670ad50e0cbef5.png)
[论文总结] 深度学习在农业领域应用论文笔记12
文章目录 1. 3D-ZeF: A 3D Zebrafish Tracking Benchmark Dataset (CVPR, 2020)摘要背景相关研究所提出的数据集方法和结果个人总结 2. Automated flower classification over a large number of classes (Computer Vision, Graphics & Image Processing, 2008)摘要背景分割…

论文记录:Neural Motifs: Scene Graph Parsing with Global Context (CVPR-18)
(这里只是记录了论文的一些内容以及自己的一点点浅薄的理解,具体实验尚未恢复。由于本人新人一枚,若有错误以及不足之处,还望不吝赐教)
总结 本文关注的问题是 Scene Graph 的生成。通过观察 VG 数据集发现࿱…

《论文阅读》对话阅读理解——增强多方多轮对话中对话感知
2023-3-12组会记录
对话阅读理解
前言
本周分享的一篇论文为:Enhanced Speaker-aware Multi-party Multi-turn Dialogue Comprehension
大家在读开放域对话的时候应该也可以看出来,目前主流的对话类型还是双方对话,即一问一答,轮流发言,这样其实是真实对话中的最简单的…
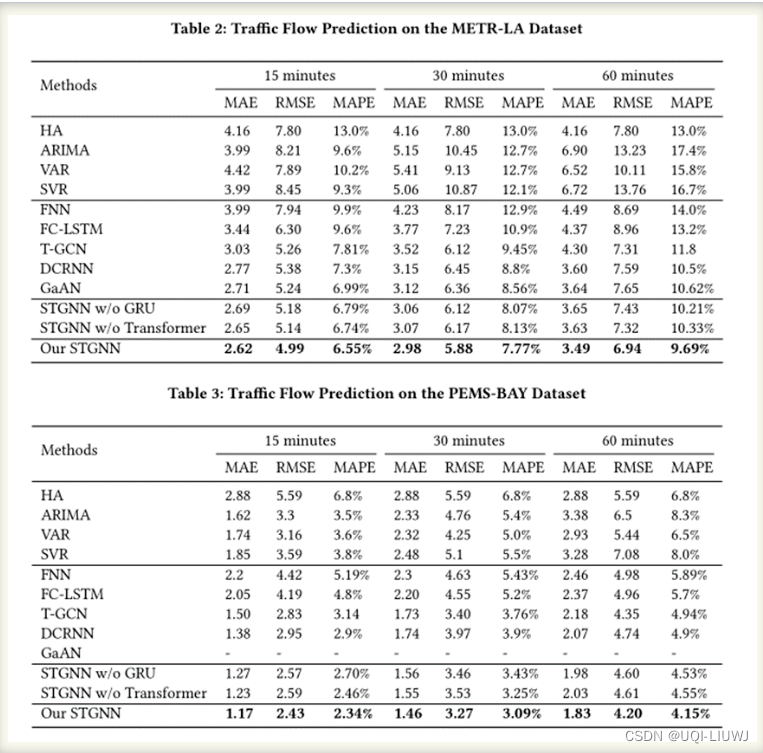
论文笔记:Traffic Flow Prediction via Spatial Temporal Graph Neural Network
WWW 2020
1 模型
图神经网络图注意力——空间依赖关系
RNNTransformer——短期&长期依赖关系 缺点:运用RNN于较长序列仍然会带来误差积累,并且RNN模型的运算效率并不高 2 实验
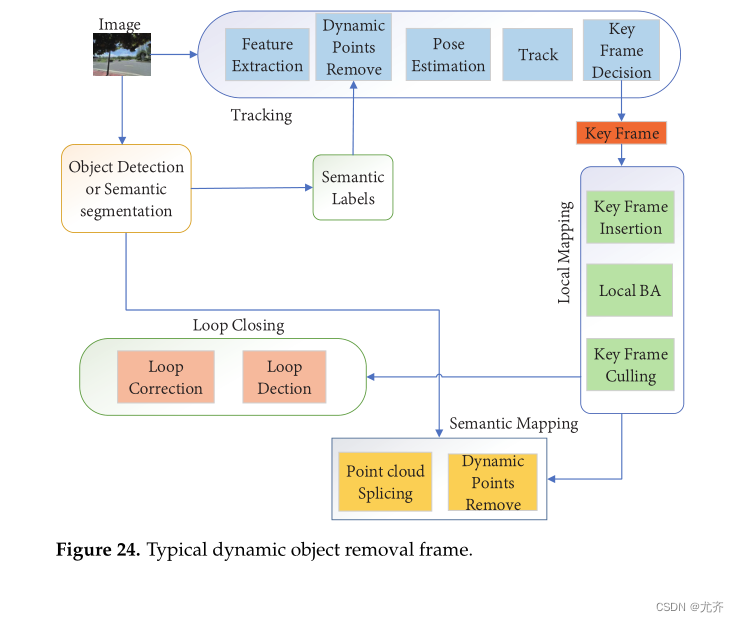
论文笔记_SLAM_2022_An Overview on Visual SLAM: From Tradition to Semantic
基本情况
出处:Chen W, Shang G, Ji A, et al. An overview on visual slam: From tradition to semantic[J]. Remote Sensing, 2022, 14(13): 3010.
作者单位:泉州信息工程学院/南京信息工程大学/南京航空航天大学
参考:https://blog.csd…
PLUS操作流程、应用与实践,多源不同分辨率数据的处理、ArcGIS的应用、PLUS模型的应用、InVEST模型的应用
PLUS模型是由中国地质大学(武汉)地理与信息工程学院高性能空间计算智能实验室开发,是一个基于栅格数据的可用于斑块尺度土地利用/土地覆盖(LULC)变化模拟的元胞自动机(CA)模型。PLUS模型集成了基于土地扩张分析的规则挖掘方法和基于多类型随机…
《论文阅读》任务型对话系统——面向角色的对话摘要
《论文阅读》任务型对话系统——面向角色的对话摘要 前言文本摘要对话摘要Other Roles Matter! Enhancing Role-Oriented Dialogue Summarization via Role Interactions角色信息的作用角色对话摘要的定义解决方法两种交互模型构架启发前言
分享的一篇论文为: Other Roles Ma…

EEG-SEED数据集作者的---基线论文阅读和分析
《Investigating Critical Frequency Bands and Channels for EEG-based Emotion Recognition with Deep Neural Networks》
方法:
A.预处理根据被试的反应,只选择诱发目标情绪的实验时期进行进一步分析。
将原始脑电图数据降采样至200Hz采样率。目视…

论文阅读笔记《Multilevel Graph Matching Networks for Deep Graph Similarity Learning》
核心思想 本文提出一种多级图匹配网络(MGMN)用于图相似性的度量。常见的图相似性网络都是利用图神经网络或其他图嵌入技术将整幅图转化为特征向量,然后计算两个特征向量之间的相似程度。这种做法的缺点在于只关注了图一级的信息交互ÿ…

论文阅读笔记——《室内服务机器人的实时场景分割算法》
一、主要工作
通过深度可分离卷积、膨胀卷积和通道注意力机制设计轻量级的高准确度特征提取模块。融合浅层特征与深层语义特征获得更丰富的图像特征。在NYUDv2和CamVid数据集上的MIoU分别达到72.7%和59.9%,模型的计算力为4.2GFLOPs,参数量为8.3Mb。
二…
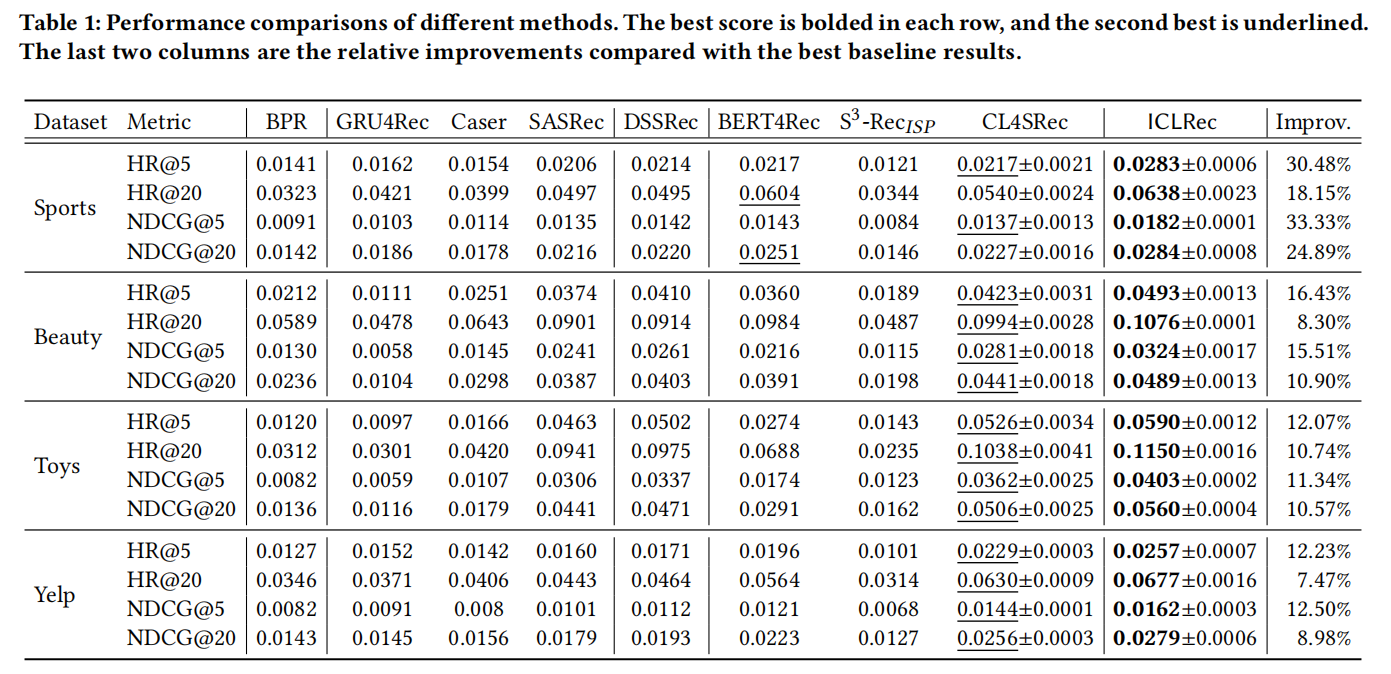
【论文阅读_序列推荐】Intent Contrastive Learning for Sequential Recommendation
【论文阅读_序列推荐】Intent Contrastive Learning for Sequential Recommendation 文章目录【论文阅读_序列推荐】Intent Contrastive Learning for Sequential Recommendation1. 来源2. 介绍3. 准备工作3.1 问题定义3.2 用于下一个项目预测的深度 SR 模型3.3 SR中的对比SSL …
[论文阅读] (29)李沐老师视频学习——2.研究的艺术·找问题和明白问题的重要性
《娜璋带你读论文》系列主要是督促自己阅读优秀论文及听取学术讲座,并分享给大家,希望您喜欢。由于作者的英文水平和学术能力不高,需要不断提升,所以还请大家批评指正,非常欢迎大家给我留言评论,学术路上期…
论文阅读 | 频谱监测、认知电子战、网电攻击
文章目录 1.《超短波信号的频谱监测与信号源定位》1.1 信号预处理技术1.2 对指定频段的宽带信号截获、分析以及频率分选研究1.3 对指定频段的信号进行最佳分频段扫描分析并还原原信号1.4 总结2.《认知电子战理论及关键技术研究》2.1 认知电子战发展现状2.2 认知电子战发展趋势分…
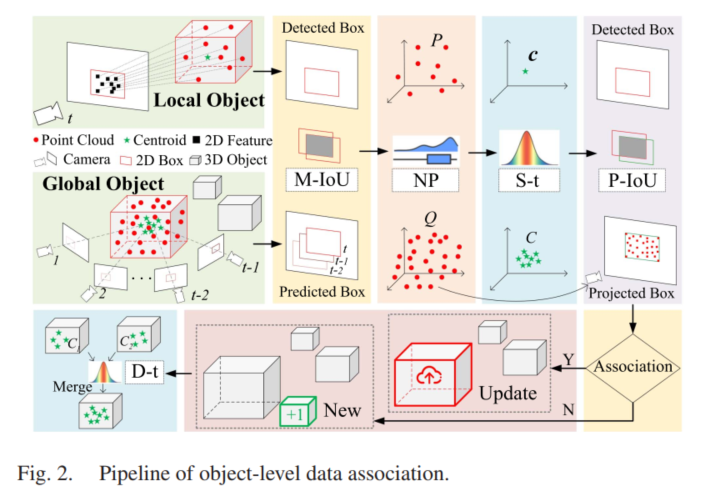
【论文阅读】An Object SLAM Framework for Association, Mapping, and High-Level Tasks
一、系统概述
这篇文章是一个十分完整的物体级SLAM框架,偏重于建图及高层应用,在前端的部分使用了ORBSLAM作为基础框架,用于提供点云以及相机的位姿,需要注意的是,这篇文章使用的是相机,虽然用的是点云这个…
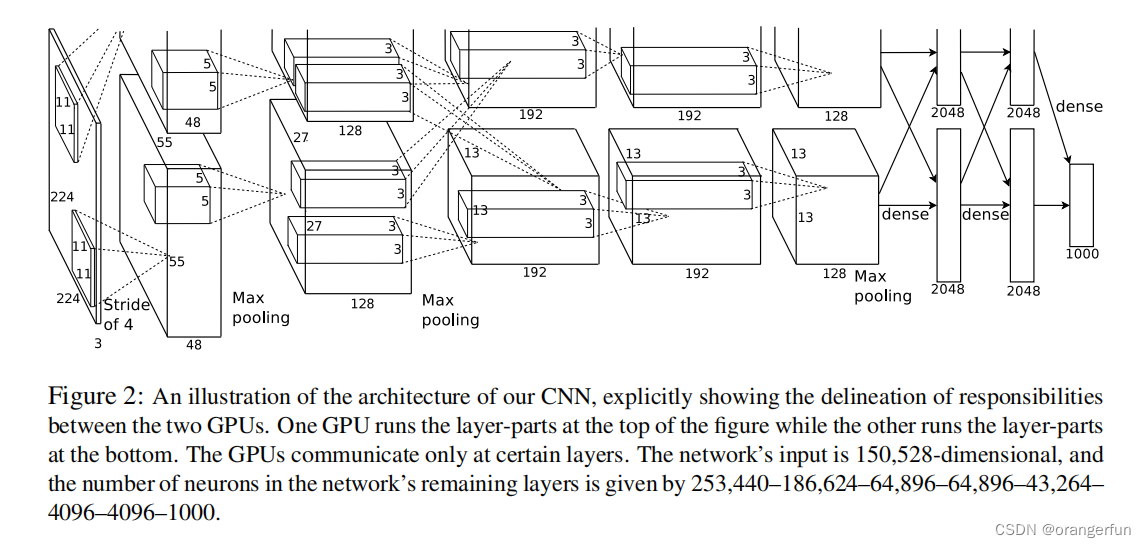
【论文阅读】AlexNet: ImageNet Classification with Deep Convolutional Neural Networks
1. 简介
AlexNet是一个用于图像识别的卷积神经网络,其应用在ILSVRC比赛中,AlexNet所用的数据集是ImageNet,总共识别1000个类别
2. 网络结构
整体网络结果如下图所示,一共有8层,前五层是卷积层,后三层是全…
【自监督论文阅读 4】BYOL
文章目录 一、摘要二、引言三、相关工作四、方法4.1 BYOL的描述4.2 Intuitions on BYOL’s behavior(BYOL行为的直觉)4.3 实验细节 五、实验评估5.1 Linear evaluation on ImageNet(ImageNet上的线性评估)5.2 Semi-supervised tra…

【论文阅读 07】Anomaly region detection and localization in metal surface inspection
比较老的一篇论文,金属表面检测中的异常区域检测与定位 总结:提出了一个找模板图的方法,使用SIFT做特征提取,姿态估计看差异有哪些,Hough聚类做描述符筛选,仿射变换可视化匹配图之间的关系…

Tune-A-Video论文阅读
论文链接:Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation 文章目录 摘要引言相关工作文生图扩散模型文本到视频生成模型文本驱动的视频编辑从单个视频生成 方法前提DDPMsLDMs 网络膨胀微调和推理模型微调基于DDIM inversio…
1.如何读论文【论文精读】
论文的基本结构
1.title
2.abstract
3.introduction
4.method
5.experiments
6.conclusion第一遍:标题、摘要、结论。可以看一看方法和实验部分重要的图和表。这样可以花费十几分钟时间了解到论文是否适合你的研究方向。第二遍:确定论文值得读之后&…

论文笔记--Goat: Fine-tuned LLaMA Outperforms GPT-4 on Arithmetic Tasks
论文笔记--Goat: Fine-tuned LLaMA Outperforms GPT-4 on Arithmetic Tasks 1. 文章简介2. 文章概括3 文章重点技术3.1 LLM的选择3.2 算数任务的可学习性(learnability)3.3 大模型的加减乘除 4. 数值实验结果5. 文章亮点6. 原文传送门7. References 1. 文章简介
标题ÿ…

【论文阅读】通过3D和2D网络的交叉示教实现稀疏标注的3D医学图像分割(CVPR2023)
目录 前言方法标注3D-2D Cross Teaching伪标签选择Hard-Soft Confidence Threshold Consistent Prediction Fusion 结论 论文:3D Medical Image Segmentation with Sparse Annotation via Cross-Teaching between 3D and 2D Networks 代码:https://githu…
论文阅读《Performance Comparison of Neural and Non-Neural Approaches to Session-based Recommendation》
这篇没有精度,就简单放一些论文中的表格吧,这篇文章可以做会话推荐的研究背景
论文链接:https://dl.acm.org/doi/abs/10.1145/3298689.3347041 近年来,我们可以观察到会话推荐问题。这些问题涉及到对用户长期偏好的预测问题&…
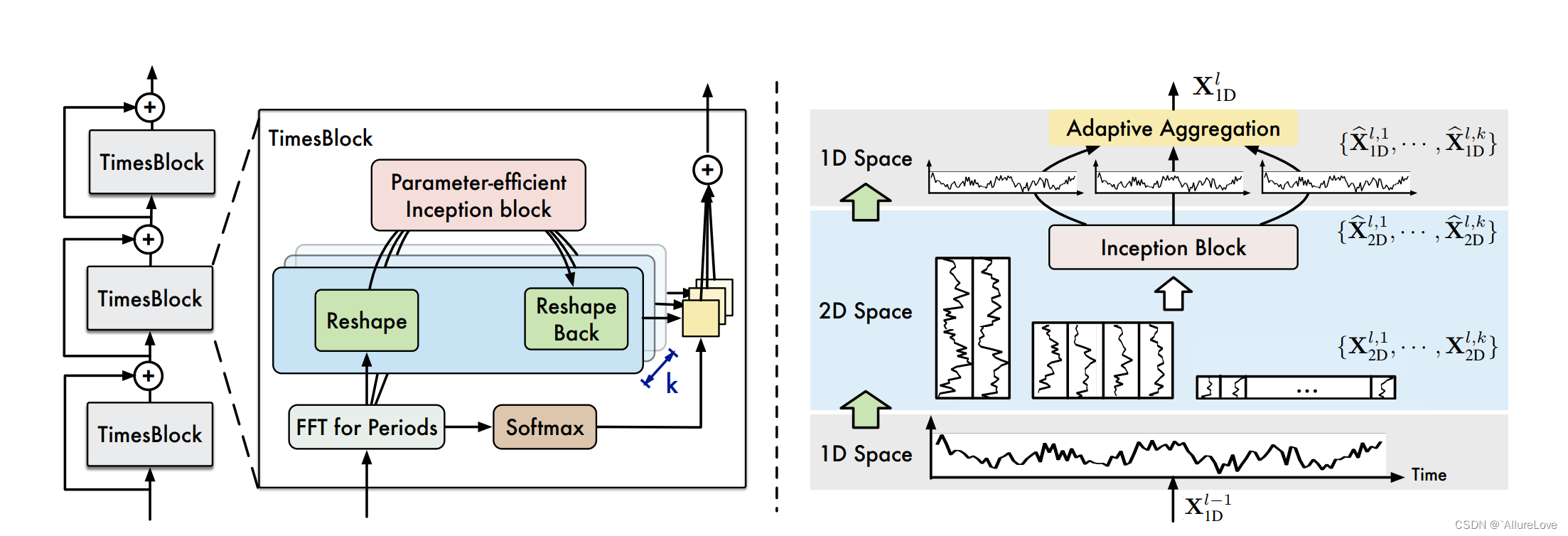
【论文阅读】基于深度学习的时序异常检测——TimesNet
系列文章链接 参考数据集讲解:数据基础:多维时序数据集简介 论文一:2022 Anomaly Transformer:异常分数预测 论文二:2022 TransAD:异常分数预测 论文三:2023 TimesNet:基于卷积的多任…
RWEQ风蚀方程模型与ArcGIS数据处理Python代码库添加结合理论研究和科研实践
RWEQ模型是应用比较普遍的能适应大区域定量估算风蚀量的模型。该模型是基于大量野外实验的一种经验模型,在实际测定风力导致的土壤侵蚀量以及当地的气象、地表植被、土壤湿度、地表的结皮和地表的可蚀性等因子的基础上得出的一个经验方程。 1、掌握土壤风蚀模型的原…
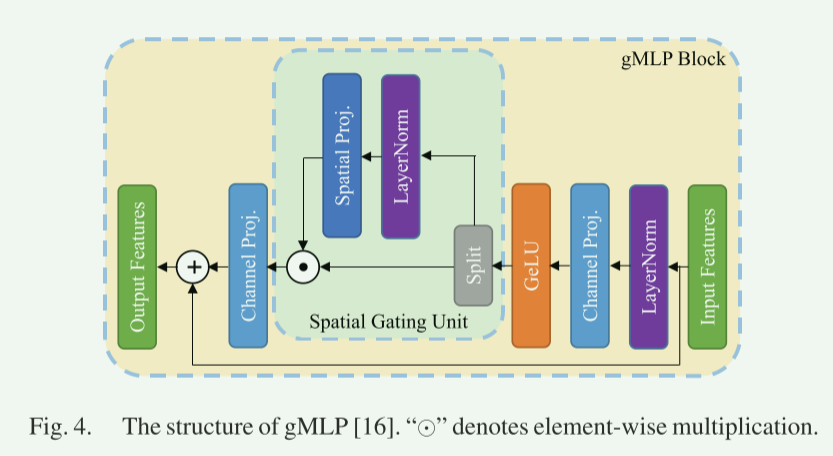
【论文阅读】Deep Instance Segmentation With Automotive Radar Detection Points
基于汽车雷达检测点的深度实例分割
一个区别:
automotive radar 汽车雷达 :
分辨率低,点云稀疏,语义上模糊,不适合直接使用用于密集LiDAR点开发的方法 ;
返回的物体图像不如LIDAR精确,可以…
论文笔记--Llama 2: Open Foundation and Fine-Tuned Chat Models
论文笔记--Llama 2: Open Foundation and Fine-Tuned Chat Models 1. 文章简介2. 文章概括3 文章重点技术3.1 预训练Pretraining3.1.1 预训练细节3.1.2 Llama2模型评估 3.2 微调Fine-tuning3.2.1 Supervised Fine-Tuning(FT)3.2.2 Reinforcement Learning with Human Feedback(…
论文阅读_LMM 的黎明_GPT4_4V
英文名称: The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)
中文名称: LMM 的黎明:GPT-4V 的初步探索
文章: http://arxiv.org/abs/2309.17421
中文翻译:https://mp.weixin.qq.com/s/a8Y_yU5XYgJhQ2xMuTK13w
作者: Zhengyuan Yang
日期:…
AAAI 最佳论文列表(1984→2023最新)附论文下载
明天AAAI全文截稿了,不知道大家的论文投的咋样啦?我不得不提一句,今年的AAAI投稿量又破新高了,快14,000!卷哭...
不过这个投稿量也在意料之中,AAAI属于中国计算机学会CCF的A类国际学术会议,在人…

《Attention Is All You Need》论文笔记
下面是对《Attention Is All You Need》这篇论文的浅读。
参考文献:
李沐论文带读
HarvardNLP
《哈工大基于预训练模型的方法》
下面是对这篇论文的初步概览:
对Seq2Seq模型、Transformer的概括:
下面是蒟蒻在阅读完这篇论文后做的一…
2023.8.14论文阅读
文章目录 ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation摘要本文方法实验结果 DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection摘要本文方法实验结果 ESPNet: Efficient Spatial Pyramid of Dilated Convo…

论文阅读 - Understanding Diffusion Models: A Unified Perspective
文章目录 1 概述2 背景知识2.1 直观的例子2.2 Evidence Lower Bound(ELBO)2.3 Variational Autoencoders(VAE)2.4 Hierachical Variational Autoencoders(HVAE) 3 Variational Diffusion Models(VDM)4 三个等价的解释4.1 预测图片4.2 预测噪声4.3 预测分数 5 Guidance5.1 Class…
《论文阅读14》FAST-LIO
一、论文
研究领域:激光雷达惯性测距框架论文:FAST-LIO: A Fast, Robust LiDAR-inertial Odometry Package by Tightly-Coupled Iterated Kalman Filter IEEE Robotics and Automation Letters, 2021 香港大学火星实验室 论文链接论文github 二、论文概…
【论文笔记】基于指令回译的语言模型自对齐-MetaAI
MetaAI最近发布的Humpback,论文链接:https://arxiv.org/abs/2308.06259
解决什么问题?
大量高质量的指令微调数据集的生成。
思路 在这项工作中,我们通过开发迭代自训练算法来利用大量未标记的数据来创建高质量的指令调优数据集…

BEiT: BERT Pre-Training of Image Transformers 论文笔记
BEiT: BERT Pre-Training of Image Transformers 论文笔记
论文名称:BEiT: BERT Pre-Training of Image Transformers
论文地址:2106.08254] BEiT: BERT Pre-Training of Image Transformers (arxiv.org)
代码地址:unilm/beit at master …
[论文笔记]ON LAYER NORMALIZATION IN THE TRANSFORMER ARCHITECTURE
引言
这是论文ON LAYER NORMALIZATION IN THE TRANSFORMER ARCHITECTURE的阅读笔记。本篇论文提出了通过Pre-LN的方式可以省掉Warm-up环节,并且可以加快Transformer的训练速度。
通常训练Transformer需要一个仔细设计的学习率warm-up(预热)阶段:在训练开始阶段学习率需要设…
毫米波雷达成像论文阅读笔记: IEEE TPAMI 2023 | CoIR: Compressive Implicit Radar
原始笔记链接:https://mp.weixin.qq.com/s?__bizMzg4MjgxMjgyMg&mid2247486680&idx1&snedf41d4f95395d7294bc958ea68d3a68&chksmcf51be21f826373790bc6d79bcea6eb2cb3d09bb1860bba0af0fd5e60c448ca006976503e460#rd ↑ \uparrow ↑点击上述链接即…
![[论文分享]Pedestrian attribute recognition based on attribute correlation](https://img-blog.csdnimg.cn/66748dba526c4dd0aefd7ce8f1c090bd.png)
[论文分享]Pedestrian attribute recognition based on attribute correlation
Pedestrian attribute recognition based on attribute correlation 行人属性识别广泛应用于行人跟踪和行人重识别。 两项最基本的挑战:
多标签性质数据样本的差异性特征,例如类别不平衡和部分遮挡。
不同方法的示意图:
此项工作中&#…
论文阅读》用提示和释义模拟对话情绪识别的思维过程 IJCAI 2023
《论文阅读》用提示和复述模拟对话情绪识别的思维过程 IJCAI 2023 前言简介相关知识prompt engineeringparaphrasing模型架构第一阶段第二阶段History-oriented promptExperience-oriented Prompt ConstructionLabel Paraphrasing损失函数前言
你是否也对于理解论文存在困惑?…
机器学习笔记:node2vec(论文笔记:node2vec: Scalable Feature Learning for Networks)
2016 KDD
1 intro
利用graph上的节点相似性,对这些节点进行embedding 同质性:节点和其周围节点的embedding比较相似 蓝色节点和其周围的节点结构等价性 结构相近的点embedding相近 比如蓝色节点,都处于多个簇的连接处
2 随机游走
2.1 介绍…
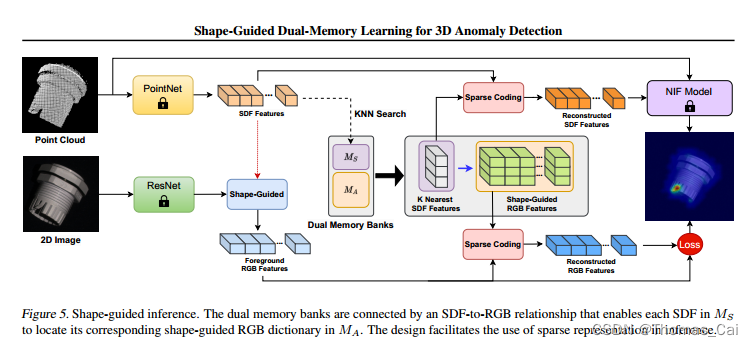
3D异常检测论文笔记 | Shape-Guided Dual-Memory Learning for 3D Anomaly Detection
文章目录 摘要一、介绍三、方法3.1. 形状引导专家学习3.2. Shape-Guided推理 摘要
我们提出了一个形状引导的专家学习框架来解决无监督的三维异常检测问题。我们的方法是建立在两个专门的专家模型的有效性和他们的协同从颜色和形状模态定位异常区域。第一个专家利用几何信息通…

论文笔记:Reinforcing Local Structure Perception for Monocular Depth Estimation
提出问题
混合数据集中深度范围的变化会导致网络的不稳定。虽然已经引入了一些仿射不变的损失函数,但现有的方法可能会导致次优的几何结构,如模糊的边界和细节。
思路
我们提出了一种新的像素级监督损失,称为 the windowed correlation re…
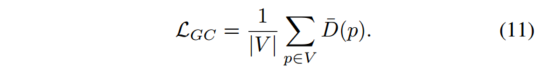
MaskVO: Self-Supervised Visual Odometry with a Learnable Dynamic Mask 论文阅读
论文信息
题目:MaskVO: Self-Supervised Visual Odometry with a Learnable Dynamic Mask 作者:Weihao Xuan, Ruijie Ren, Siyuan Wu, Changhao Chen 时间:2022 来源: IEEE/SICE International Symposium on System Integration …
《论文阅读》常识感知的提示用于可控的同情对话生成 2023 AAAI
《论文阅读》常识感知的提示用于可控的同情对话生成 前言简介基础知识即插即用(Plug and Play)Future Discriminators(FUDGE)动机数据集方法前言
你是否也对于理解论文存在困惑?
你是否也像我之前搜索论文解读,得到只是中文翻译的解读后感到失望?
小白如何从零读懂论…

SegGPT: Segmenting Everything In Context论文笔记
论文https://arxiv.org/pdf/2304.03284.pdfCodehttps://github.com/baaivision/Painter 文章目录 1. 背景2. Motivation3. Method3.1 In-Context Coloring3.2 Context Ensemble3.3 In-Context Tuning 1. 背景
在Painter中,将各种密集预测任务视为一种着色问题。
在…

【CVPR2021】MVDNet论文阅读分析与总结
Challenge:
现有的目标检测器主要融合激光雷达和相机,通常提供丰富和冗余的视觉信息 利用最先进的成像雷达,其分辨率比RadarNet和LiRaNet中使用的分辨率要细得多,提出了一种有效的深度后期融合方法来结合雷达和激光雷达信号。 MV…
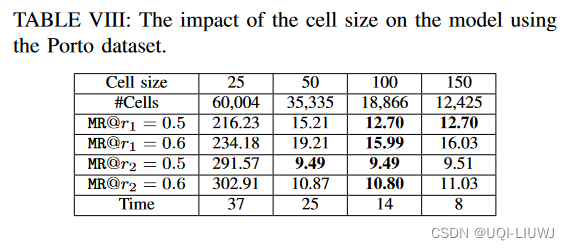
论文笔记:Deep Representation Learning for Trajectory Similarity Computation
ICDE 2018
1 intro
1.1 背景
用于计算轨迹相似性的成对点匹配方法(DTW,LCSS,EDR,ERP)的问题: 轨迹的采样率不均匀 如果两个轨迹表示相同的基本路径,但是以不同的采样率生成,那么这…
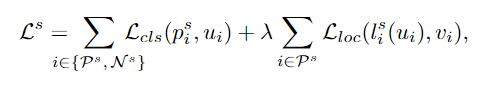
【Spatial-Temporal Action Localization(四)】论文阅读2019年
文章目录 1. You Only Watch Once: A Unified CNN Architecture for Real-Time Spatiotemporal Action Localization摘要和结论引言:针对痛点和贡献相关工作模型框架实验 2. STEP: Spatio-Temporal Progressive Learning for Video Action Detection摘要和结论引言&…
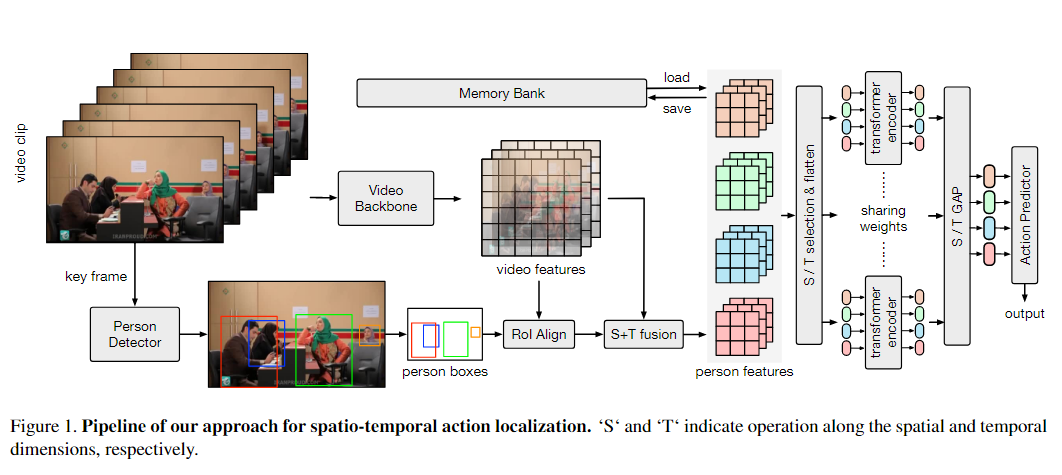
【Spatial-Temporal Action Localization(六)】论文阅读2021年
文章目录 1. MultiSports: A Multi-Person Video Dataset of Spatio-Temporally Localized Sports Actions摘要和结论引言:针对痛点和贡献数据特点 2. Actor-Context-Actor Relation Network for Spatio-Temporal Action Localization摘要和结论引言:针对…

NExT-GPT: Any-to-Any Multimodal LLM论文笔记
论文https://arxiv.org/pdf/2309.05519.pdf代码https://github.com/NExT-GPT/NExT-GPT/tree/main 1. Motivation
现有的多模态大模型大都只是支持输入端的多模态(Text、Image、Video、Audio等),但是输出端都是Text。也有一些现有的输入输出都…
【ICCV 2023】FocalFormer3D : Focusing on Hard Instance for 3D Object Detection
原文链接:https://arxiv.org/abs/2308.04556
1. 引言 目前的3D目标检测方法没有显式地去考虑漏检问题。 本文提出了困难实例探测(HIP)。受目标检测的级联解码头启发,HIP逐步探测误检样本,极大提高召回率。在每个阶…

【论文笔记】NeRF-RPN: A general framework for object detection in NeRFs
原文链接:https://arxiv.org/abs/2211.11646
1. 引言 NeRF模型能直接从给定的RGB图像和相机姿态学习3D场景的NeRF表达。本文提出NeRF-RPN,使用从NeRF模型提取的辐射场和密度,直接生成边界框提案。
3. 方法 如图所示,本文的方法有…

Baichuan2 技术报告笔记
文章目录 预训练预训练数据模型架构TokenizerPositional EmbeddingsAcitivations and NormalizationsOptimizations 对齐Supervised Fine-TuningRLHF 安全性预训练阶段对齐阶段 参考资料 对Baichuan2技术报告阅读后的笔记 Baichuan2 与其他大模型的对比如下表 预训练
预训练数…
论文阅读 | RAFT: Recurrent All-Pairs Field Transforms for Optical Flow
RAFT: Recurrent All-Pairs Field Transforms for Optical Flow
ECCV2020光流任务best paper 论文地址:【here】 代码地址:【here】
介绍
光流是对两张相邻图像中的逐像素运动的一种估计。目前碰到的一些困难包括:物体的快速运动ÿ…

联合分析专题--解密多组学联合分析在中药方向的研究思路
研究必要性
中药主要由植物药(根、茎、叶、果)、动物药(内脏、皮、骨、器官等)和矿物药组成。因植物药占中药的大多数,所以中药也称中草药。中药基因组学的理解,侧重于中药本身,主要包括中药转…

评估在线不平衡学习的PAUC
评估在线不平衡学习的PAUC
原始论文《Prequential AUC: properties of the area under the ROC curve for data streams with concept drift》 由于正常的AUC需要计算整体数据集上,每个数据的预测置信度的排名。那么我们首先要求我们的在线学习算法在进行预测时也返…
【论文阅读】End-to-End Spatio-Temporal Action Localisation with Video Transformers
文章目录 摘要和结论引言模型框架Vision EncoderTubelet Decoder(factorise Queries CA MHSA)Training objectiveMatching 摘要和结论
e2e,纯基于Transformer的模型,输入视频输出tubelets。无论是 对单个帧的稀疏边界框监督 还是 完整的小管注释。在这两…

【ICCV‘23】One-shot Implicit Animatable Avatars with Model-based Priors
文章目录 前置知识 前置知识
1)SMPL模型 \quad SMPL这类方法只建模穿很少衣服的人体(裸体模型),它只能刻画裸体角色的动画,并不能刻画穿衣服的人体的动画 2)data-efficient \quad 这个词推荐用ÿ…
论文阅读:Bayesian GAN
Bayesian GAN
点击访问paper 官方github 半监督学习对比算法
1.简介
贝叶斯 GAN(Saatchi 和 Wilson,2017)是生成对抗网络(Goodfellow,2014)的贝叶斯公式,我们在其中学习生成器参数 θ g \th…
3+单细胞+代谢+WGCNA+机器学习
今天给同学们分享一篇生信文章“Identification of new co-diagnostic genes for sepsis and metabolic syndrome using single-cell data analysis and machine learning algorithms”,这篇文章发表Front Genet.期刊上,影响因子为3.7。 结果解读&#x…

大模型LLM论文目录
持续更新中ing!!! 友情链接:大模型相关资料、基础技术和排行榜 大模型LLM论文目录 标题和时间作者来源简介Artificial General Intelligence: Concept, State of the Art, and Future Prospects,2014GoertzelJournal o…
【论文笔记】UniPAD: A Universal Pre-training Paradigm for Autonomous Driving
原文链接:https://arxiv.org/pdf/2310.08370.pdf
1. 引言
过去的3D场景理解预训练方法多采用2D图像领域中的想法,可大致分为基于对比的方法和基于MAE的方法。
基于对比的方法通过对比损失,在特征空间中将相似的3D点拉进而将不相似的点分开…
【论文阅读】多模态NeRF:Cross-Spectral Neural Radiance Fields
https://cvlab-unibo.github.io/xnerf-web
intro
从不同的light spectrum sensitivity获取信息,同时需要obtain a unified Cross-Spectral scene representation – allowing for querying, for any single point, any of the information sensed across spectra。…

【论文阅读】NeROIC:在线图像集合中对象的神经渲染
论文连接: NeROIC: Neural Rendering of Objects from Online Image Collections
introduction
从在线图像集合中获取对象表示的新颖方法,从具有不同相机、照明和背景的照片中捕获任意对象的高质量几何形状和材料属性。这使得各种以对象为中心的渲染应…

【论文笔记】Denoising Diffusion Probabilistic Models
Pre Knowledge
1.条件概率的一般形式 P ( A , B ) P ( B ∣ A ) P ( A ) P(A,B)P(B|A)P(A) P(A,B)P(B∣A)P(A) P ( A , B , C ) P ( C ∣ B , A ) P ( B , A ) P ( C ∣ B , A ) P ( B ∣ A ) P ( A ) P(A,B,C)P(C|B,A)P(B,A)P(C|B,A)P(B|A)P(A) P(A,B,C)P(C∣B,A)P(B,A)P…

(论文阅读30/100)Convolutional Pose Machines
30.文献阅读笔记CPMs 简介 题目 Convolutional Pose Machines 作者 Shih-En Wei, Varun Ramakrishna, Takeo Kanade, and Yaser Sheikh, CVPR, 2016. 原文链接 https://arxiv.org/pdf/1602.00134.pdf 关键词 Convolutional Pose Machines(CPMs)…
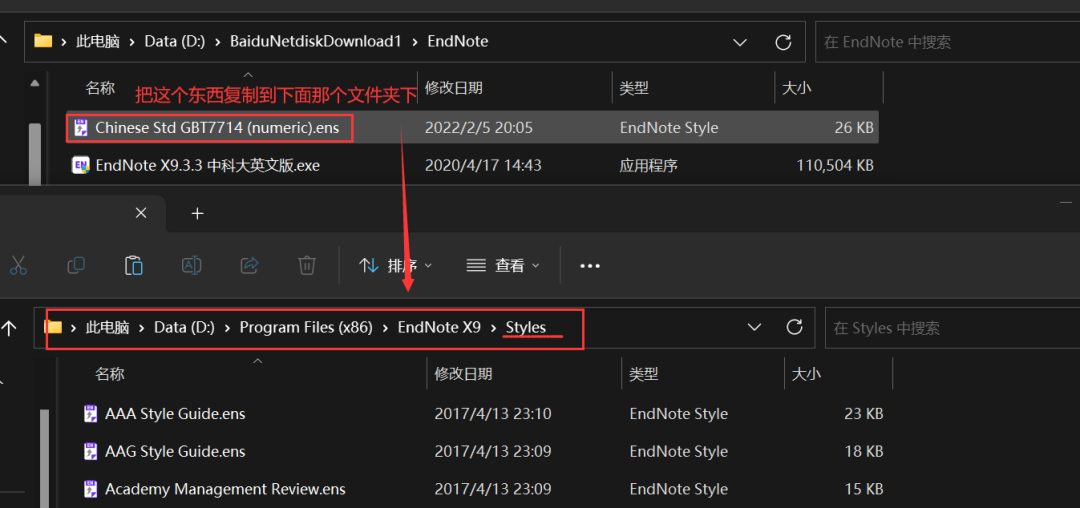
EndNote-文献管理工具【安装篇】
下载:(文末附安装包,建议使用这一个,官网都需要付费)
打开安装包,双击: 安装完了之后不要直接运行,因为EndNote软件少了一个类型的软件:GB/T17714。 因此我们需要把这个…

Ph.D,一个Permanent head Damage的群体
一个群体 Permanent head Damage 的博士生群体 Permanent head Damage Ph.D
博士生一年级的同学们,不要担忧或高兴得太早,抱歉你们还没有经历Qualification——预备考试,你们暂且不能被称为博士,只能称自己是要努力成为博士预备…
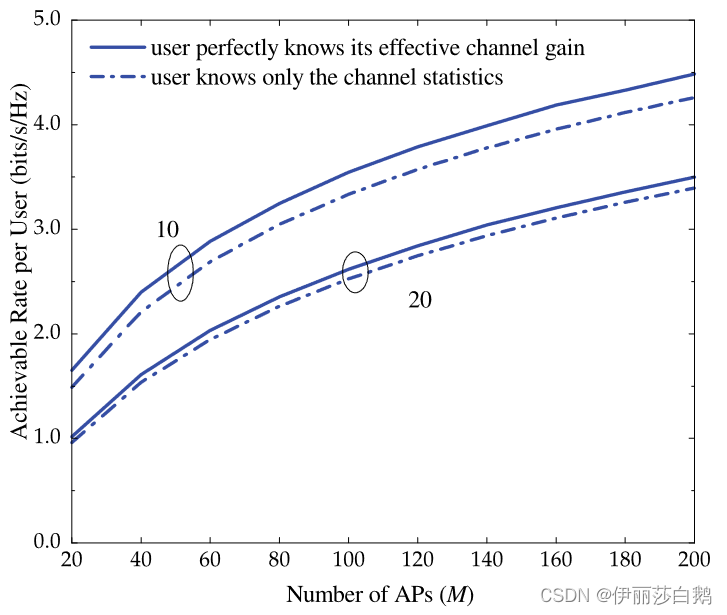
论文阅读--Cell-free massive MIMO versus small cells
无蜂窝大规模MIMO与小蜂窝网络
论文信息 Ngo H Q, Ashikhmin A, Yang H, et al. Cell-free massive MIMO versus small cells[J]. IEEE Transactions on Wireless Communications, 2017, 16(3): 1834-1850. 无蜂窝大规模MIMO中没有小区或者小区边界的界定,所有接入…
RAL期刊投稿信息【来自官网】
官网信息来源:RA-L Information for Authors
期刊范围
RA-L 的范围是发表同行评审文章,及时、简明地介绍创新研究理念和应用成果,报道机器人和自动化领域的重要理论发现和应用案例研究。
RA-L 关键词
具体涉及此处列出的主题领域和关键词…
论文阅读--Cell-free massive MIMO versus small cells--未完成
无蜂窝大规模MIMO与小蜂窝网络
论文信息 Ngo H Q, Ashikhmin A, Yang H, et al. Cell-free massive MIMO versus small cells[J]. IEEE Transactions on Wireless Communications, 2017, 16(3): 1834-1850. 无蜂窝大规模MIMO中没有小区或者小区边界的界定,所有接入…
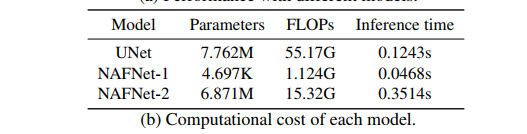
ExposureDiffusion: Learning to Expose for Low-light Image Enhancement论文阅读笔记
南洋理工大学、鹏城实验室、香港理工大学在ICCV2023发表的暗图增强论文。用diffusion模型来进行raw图像暗图增强,同时提出了一个自适应的残差层用来对具有不同信噪比的不同区域采取不同的去噪策略。 方法的框图如下所示: 一张raw图片可以由信号和噪声…
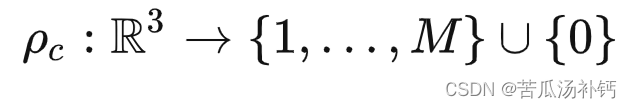
论文阅读:Image-to-Lidar Self-Supervised Distillation for Autonomous Driving Data
目录
摘要
Motivation
整体架构流程
技术细节
雷达和图像数据的同步
小结 论文地址: [2203.16258] Image-to-Lidar Self-Supervised Distillation for Autonomous Driving Data (arxiv.org)
论文代码:GitHub - valeoai/SLidR: Official PyTorch implementati…
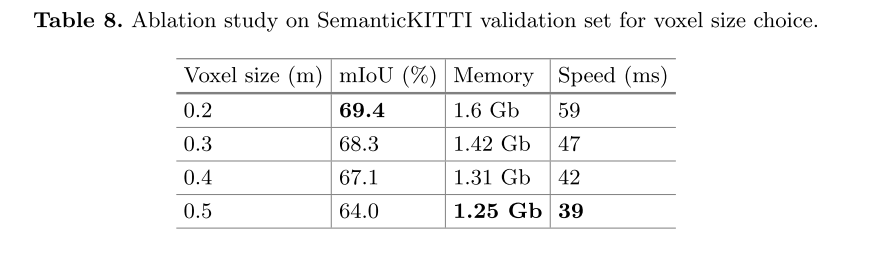
论文阅读:Efficient Point Cloud Segmentation with Geometry-Aware Sparse Networks
来源:ECCV2022
链接:Efficient Point Cloud Segmentation with Geometry-Aware Sparse Networks | SpringerLink
0、Abstract 在点云学习中,稀疏性和几何性是两个核心特性。近年来,为了提高点云语义分割的性能,人们提…

Paper Reading:《Consistent-Teacher: 减少半监督目标检测中不一致的伪目标》
#pic_center 550x200 目录 简介工作重点方法ASA, adaptive anchor assignmentFAM-3D, 3D feature alignment moduleGMM, Gaussian Mixture Model实施细节 实验与SOTA的比较消融实验 总结 简介 题目:《Consistent-Teacher: Towards Reducing Inconsistent Pseudo-ta…
[论文笔记]GPT-1
引言
今天带来论文Improving Language Understanding by Generative Pre-Training的笔记,它的中文题目为:通过生成式预训练改进语言理解。其实就是GPT的论文。
自然语言理解可以应用于大量NLP任务上,比如文本蕴含、问答、语义相似和文档分类。虽然无标签文本语料是丰富的,…
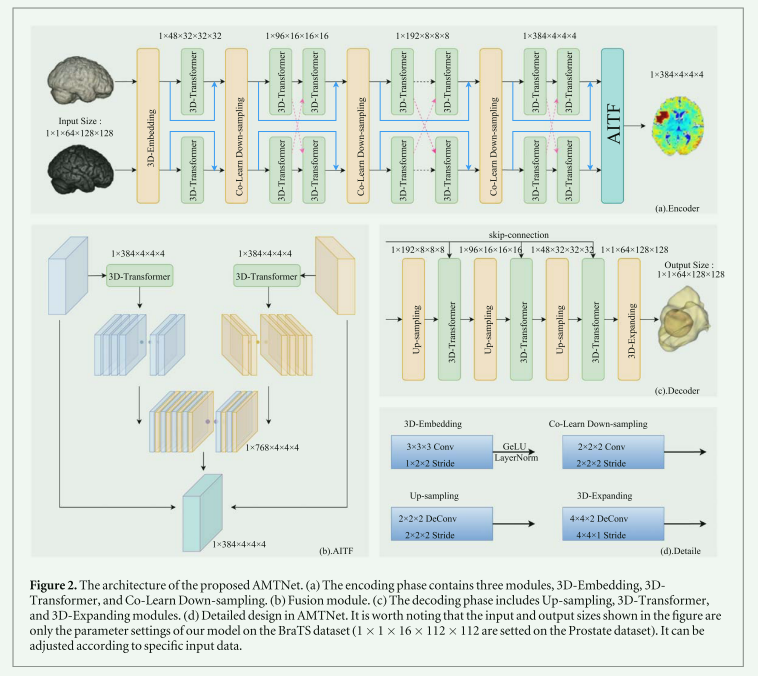
【论文阅读笔记】两篇完整模态脑瘤分割
两篇完整模态脑瘤分割论文,都是使用Transformer,没有什么特别的特色,也没有开源代码,因此只是简单记录一下。
3D CATBraTS: Channel attention transformer for brain tumour semantic segmentation
El Badaoui R, Coll E B, Ps…

使用微信读书高效阅读论文,自带翻译功能。
下面以“向文本到图像扩散模型添加条件控制”(Adding Conditional Control to Text-to-Image Diffusion Models)这篇论文示例下阅读效果。
论文地址:https://arxiv.org/abs/2302.05543 选择右侧的download PDF, 然后进入论文预览页面&#x…

自动驾驶车辆运动规划方法综述 - 论文阅读
本文旨在对自己的研究方向做一些记录,方便日后自己回顾。论文里面有关其他方向的讲解读者自行阅读。 参考论文:自动驾驶车辆运动规划方法综述
1 摘要
规划决策模块中的运动规划环节负责生成车辆的局部运动轨迹 ,决定车辆行驶质量的决定因素…

NLP论文阅读记录 - 2021 | WOS 基于动态记忆网络的抽取式摘要
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.前提三.本文方法四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结思考 前言 Extractive Summarization Based on Dynamic Memory Network…
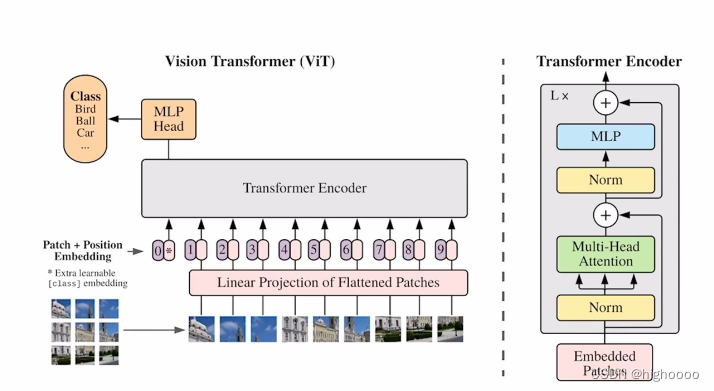
论文阅读 Vision Transformer - VIT
文章目录 1 摘要1.1 核心 2 模型架构2.1 概览2.2 对应CV的特定修改和相关理解 3 代码4 总结 1 摘要
1.1 核心
通过将图像切成patch线形层编码成token特征编码的方法,用transformer的encoder来做图像分类
2 模型架构
2.1 概览 2.2 对应CV的特定修改和相关理解
解…
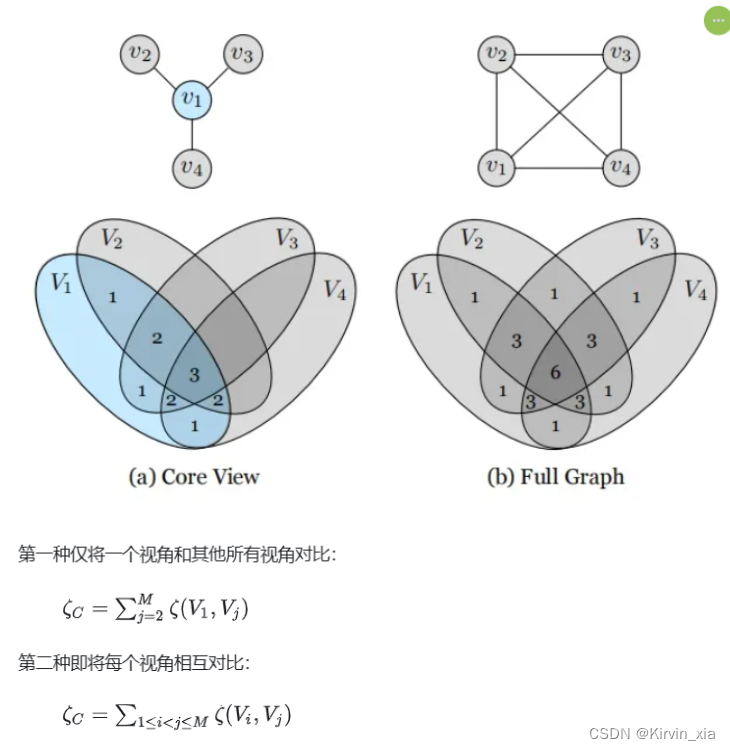
【论文阅读笔记】Contrastive Multiview Coding
Contrastive Multiview Coding
摘要 这篇文章主要探讨人类通过多种感官通道来观察世界,比如左眼观察到的长波长光通道,或右耳听到的高频振动通道。每个观察角度都带有噪音且是不完整的,但一些重要的因素,如物理、几何和语义&…
论文阅读笔记AI篇 —— Transformer模型理论+实战 (一)
资源地址Attention is all you need.pdf(0积分) - CSDN
第一遍阅读(Abstract Introduction Conclusion)
Abstract中强调Transformer摒弃了循环和卷积网络结构,在English-to-German翻译任务中,BLEU得分为28.4, 在En…

【论文阅读】Can Large Language Models Empower Molecular Property Prediction?
文章目录 0、基本信息1、研究动机2、创新性3、方法论4、实验结果 0、基本信息
作者:Chen Qian, Huayi Tang, Zhirui Yang文章链接:Can Large Language Models Empower Molecular Property Prediction?代码链接:Can Large Language Models E…
视频异常检测论文笔记
看几篇中文的学习一下别人的思路 基于全局-局部自注意力网络的视频异常检测方法主要贡献:网络结构注意力模块结构: 融合自注意力和自编码器的视频异常检测主要贡献:网络结构Transformer模块动态图 融合门控自注意力机制的生成对抗网络视频异常…

论文阅读_CogTree_推理的认知树
英文名称: From Complex to Simple: Unraveling the Cognitive Tree for Reasoning with Small Language Models中文名称: 从复杂到简单:揭示小型语言模型推理的认知树链接: http://arxiv.org/abs/2311.06754v1代码: https://github.com/alibaba/EasyNLP作者: Junbi…
FastSpeech2——TTS论文阅读
笔记地址:https://flowus.cn/share/1683b50b-1469-4d57-bef0-7631d39ac8f0 【FlowUs 息流】FastSpeech2
论文地址:lFastSpeech 2: Fast and High-Quality End-to-End Text to Speechhttps://arxiv.org/abs/2006.04558
Abstract:
tacotron→…

《小学生作文辅导》期刊投稿邮箱
《小学生作文辅导》是国家新闻出版总署批准的正规教育类期刊,适用于全国各小学语文老师事业单位及个人,具有原创性的学术理论、工作实践、科研成果和科研课题及相关领域等人员评高级职称时的论文发表(单位有特殊要求除外)。
栏目…
论文笔记——BiFormer
Title: BiFormer: Vision Transformer with Bi-Level Routing AttentionPaper: https://arxiv.org/pdf/2303.08810.pdfCode: https://github.com/rayleizhu/BiFormer
一、前言
众所周知,Transformer相比于CNNs的一大核心优势便是借助自注意力机制的优势捕捉长距离…

【论文阅读笔记】Supervised Contrastive Learning
【论文阅读笔记】Supervised Contrastive Learning
摘要
自监督批次对比方法扩展到完全监督的环境中,以有效利用标签信息提出两种监督对比损失的可能版本
介绍
交叉熵损失函数的不足之处,对噪声标签的不鲁棒性和可能导致交叉的边际,降低了…
Toolformer论文阅读笔记(简略版)
文章目录 引言方法限制结论 引言
大语言模型在zero-shot和few-shot情况下,在很多下游任务中取得了很好的结果。大模型存在的限制:无法获取最新的信息、无法进行精确的数学计算、无法理解时间的推移等。这些限制可以通过扩大模型规模一定程度上解决&…

【论文阅读】SPARK:针对视觉跟踪的空间感知在线增量攻击
SPARK: Spatial-Aware Online Incremental Attack Against Visual Tracking introduction
在本文中,我们确定了视觉跟踪对抗性攻击的一个新任务:在线生成难以察觉的扰动,误导跟踪器沿着不正确的(无目标攻击,UA&#x…

【论文阅读笔记】Deep learning for time series classification: a review
【论文阅读笔记】Deep learning for time series classification: a review
摘要 在这篇文章中,作者通过对TSC的最新DNN架构进行实证研究,探讨了深度学习算法在TSC中的当前最新性能。文章提供了对DNNs在TSC的统一分类体系下在各种时间序列领域中的最成功…
论文阅读 Forecasting at Scale (二)
最近在看时间序列的文章,回顾下经典 论文地址 项目地址 Forecasting at Scale 3.2、季节性 3.3、假日和活动事件3.4、模型拟合3.5、分析师参与的循环建模4、自动化预测评估4.1、使用基线预测4.2、建模预测准确性4.3、模拟历史预测4.4、识别大的预测误差 5、结论6、致…
Anthropic LLM论文阅读笔记
研究时间:与Instrcut GPT同期的工作,虽然其比ChatGPT发布更晚,但是其实完成的时间比ChatGPT更早。与ChatGPT的应用区别:该模型比ChatGPT回答我不知道的概率更高。将强化学习用于大语言模型(RLHF)࿱…

医学图像分割:U_Net 论文阅读
“U-Net: Convolutional Networks for Biomedical Image Segmentation” 是一篇由Olaf Ronneberger, Philipp Fischer, 和 Thomas Brox发表的论文,于2015年在MICCAI的医学图像计算和计算机辅助干预会议上提出。这篇论文介绍了一种新型的卷积神经网络架构——U-Net&a…

mask transformer相关论文阅读
前面讲了mask-transformer对医学图像分割任务是非常适用的。本文就是总结一些近期看过的mask-transformer方面的论文。 因为不知道mask transformer是什么就看了一些论文。后来得出结论,应该就是生成mask的transformer就是mask transformer。 相关论文: …
中英双语大模型ChatGLM论文阅读笔记
论文传送门: [1] GLM: General Language Model Pretraining with Autoregressive Blank Infilling [2] Glm-130b: An open bilingual pre-trained model Github链接: THUDM/ChatGLM-6B 目录 笔记Abstract 框架总结1. 模型架构2. 预训练设置3. 训练稳定性…
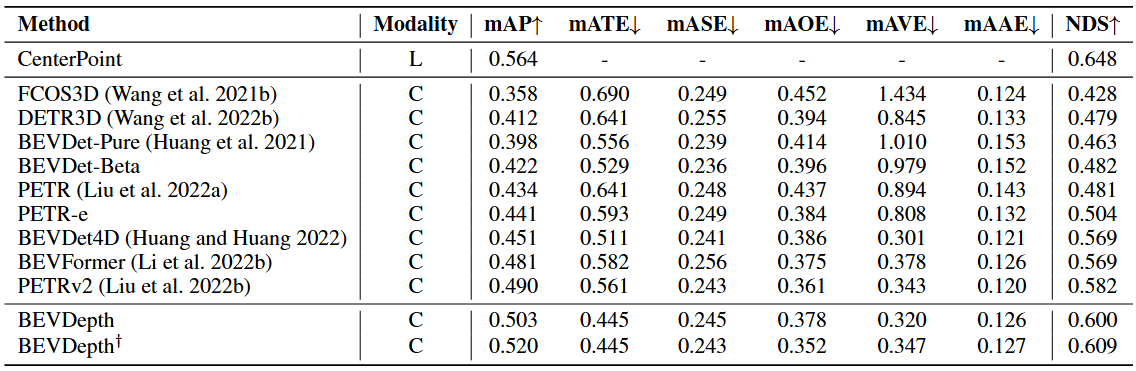
BEVDepth: Acquisition of Reliable Depth for Multi-View 3D Object Detection 论文阅读
论文链接
BEVDepth: Acquisition of Reliable Depth for Multi-View 3D Object Detection
0. Abstract
提出了一种新的 3D 物体检测器,具有值得信赖的深度估计,称为 BEVDepth,用于基于相机的鸟瞰 (BEV) 3D 物体检测BEVDepth通过利用显式深…
论文笔记:Confidential Assets
Confidential Assets
描述了一种称为“保密交易”的方案,该方案模糊了所有UTXO的金额,同时保持了不创建或销毁硬币的公共可验证性。进一步将此方案扩展到“保密资产”,一种单一的基于区块链的分类帐可以跟踪多种资产类型的方案。将保密交易扩…
论文编写软件latex安装教程
目录 1.下载安装包2.安装texlive 本人系统为windows,本教程基于windows系统,如果是其它系统请参考对应教程,注意选择对应系统的安装包! 1.下载安装包
有三种集成环境安装包
texlive 是主流的环境,集成了较多的包&…
论文阅读:一种通过降低噪声和增强判别信息实现细粒度分类的视觉转换器
论文标题: A vision transformer for fine-grained classification by reducing noise and enhancing discriminative information 翻译: 一种通过降低噪声和增强判别信息实现细粒度分类的视觉转换器
摘要
最近,已经提出了几种基于Vision T…
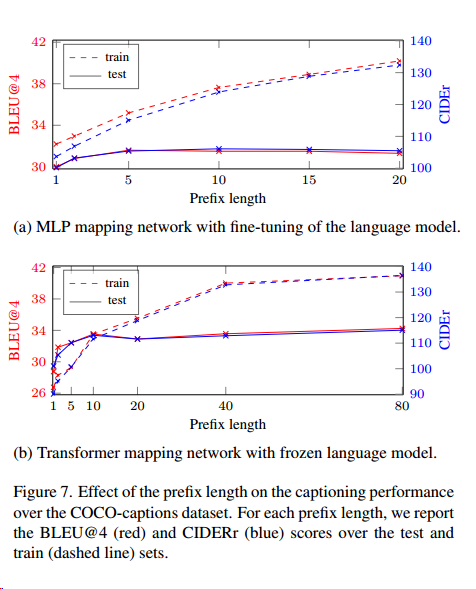
【Image captioning】论文阅读八—ClipCap: CLIP Prefix for Image Captioning_2021
中文标题:ClipCap: CLIP前缀用于图像描述(ClipCap: CLIP Prefix for Image Captioning) 文章目录 1. 介绍2. 相关工作3. 方法3.1 综述3.2 语言模型微调3.3 映射网络架构3.4 推理 4. 结果5. 结论 摘要:图像描述是视觉语言理解中的…

【论文笔记】GPT,GPT-2,GPT-3
参考:GPT,GPT-2,GPT-3【论文精读】 GPT Transformer的解码器,仅已知"过去",推导"未来" 论文地址:Improving Language Understanding by Generative Pre-Training 半监督学习࿱…
【论文阅读】Membership Inference Attacks Against Machine Learning Models
基于confidence vector的MIA Machine Learning as a Service简单介绍什么是Membership Inference Attacks(MIA)攻击实现过程DatasetShadow trainingTrain attack model Machine Learning as a Service简单介绍
机器学习即服务(Machine Learn…
![最值得收藏的顶级专业数据恢复软件列表 [持续更新]](https://img-blog.csdnimg.cn/img_convert/9c468fef582e83c2771ce4b6e1c0aa0b.jpeg)
最值得收藏的顶级专业数据恢复软件列表 [持续更新]
互联网上充斥着很多的数据恢复软件,每个软件都声称自己是最好的。现在该同意谁的观点呢?我们创建了 2023 年顶级专业数据恢复软件列表。下载顶级一流数据恢复专业软件的免费试用版,我们强烈建议用户评估演示版本,然后选择付费版本…
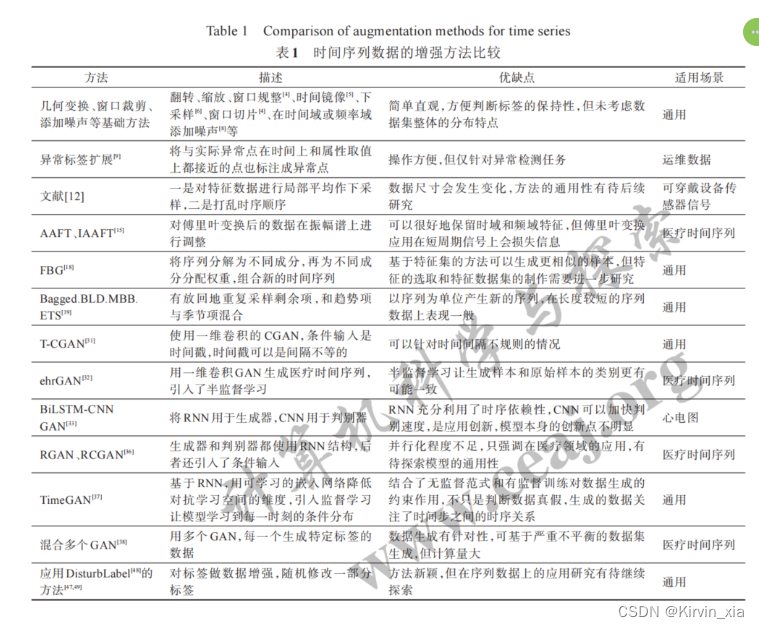
【论文阅读笔记】序列数据的数据增强方法综述
【论文阅读笔记】序列数据的数据增强方法综述
摘要 这篇论文探讨了在深度学习模型中由于对精度的要求不断提高导致模型框架结构变得更加复杂和深层的趋势。随着模型参数量的增加,训练模型需要更多的数据,但人工标注数据的成本高昂,且由于客观…
【论文笔记】Gemini: A Family of Highly Capable Multimodal Models——细看Gemini
Gemini
【一句话总结,对标GPT4,模型还是transformer的docoder部分,提出三个不同版本的Gemini模型,Ultra的最牛逼,Nano的可以用在手机上。】
谷歌提出了一个新系列多模态模型——Gemini家族模型,包括Ultra…

论文阅读:Lidar Annotation Is All You Need
目录
概要
Motivation
整体架构流程
技术细节
小结 概要 论文重点在探讨利用点云的地面分割任务作为标注,直接训练Camera的精细2D分割。在以往的地面分割任务中,利用Lidar来做地面分割是目前采用激光雷达方案进行自动驾驶的常见手段。来自Evocargo …
无水印的免费 PDF 编辑器精选
PDF(便携式文档格式)编辑器是一种软件程序,可让您编辑、注释和修改 PDF 文件。PDF 编辑器有多种形式,从仅允许您添加文本或图像的基本编辑器到允许您编辑文本、更改字体、添加或删除图片,甚至创建表单的更高级编辑器。…
论文阅读-一个用于云计算中自我优化的通用工作负载预测框架,
论文标题:A Self-Optimized Generic Workload Prediction Framework for Cloud Computing
概述
准确地预测未来的工作负载,如作业到达率和用户请求率,对于云计算中的资源管理和弹性非常关键。然而,设计一个通用的工作负载预测器…

【论文阅读】MAKE-A-VIDEO: TEXT-TO-VIDEO GENERATION WITHOUT TEXT-VIDEO DATA
Make-a-video:没有文本-视频数据的文本-视频生成。
paper:
code: ABSTRACT
优点:
(1)加速了T2V模型的训练(不需要从头开始学习视觉和多模态表示),
(2)不需要配对的文本-视频数据,
(3)生成的视频继承了当今图像生成模型的庞大…
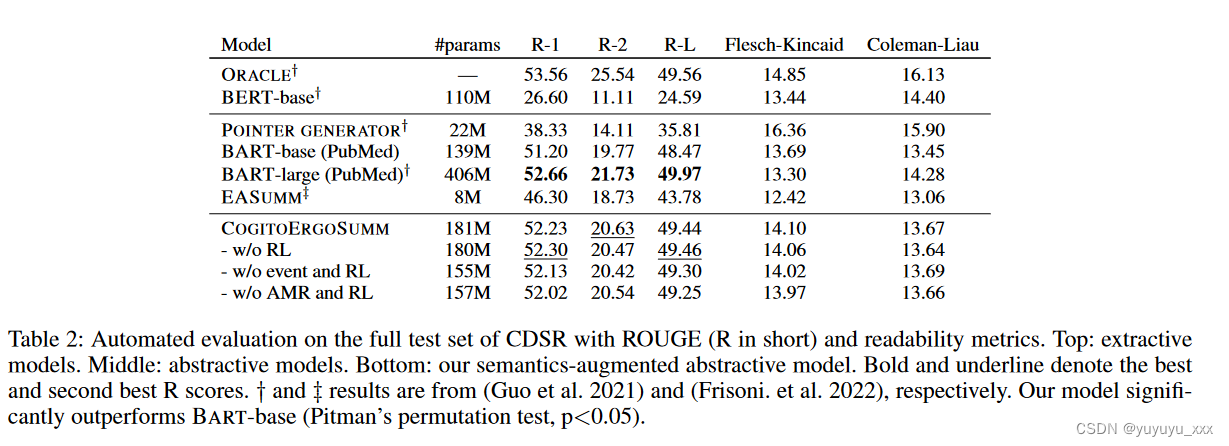
NLP论文阅读记录 - AAAI-23 | 01 Cogito Ergo Summ:通过语义解析图和一致性奖励对生物医学论文进行抽象总结
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.相关工作2.1抽象概括2.2图增强摘要2.3 抽象概括的强化学习 三.本文方法COGITOERGOSUMM 框架3.1 问题陈述3.2 图表构建**事件图****AMR 图****图合并和重新连接**Model文本编码器图编码器解码器…

【论文阅读+复现】SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion Models
SparseCtrl:在文本到视频扩散模型中添加稀疏控制。
(AnimateDiff V3,官方版AnimateDiffControlNet,效果很丝滑)
code:GitHub - guoyww/AnimateDiff: Official implementation of AnimateDiff.
paper:htt…

论文阅读:基于MCMC的能量模型最大似然学习剖析
On the Anatomy of MCMC-Based Maximum Likelihood Learning of Energy-Based Models 相关代码:点击 本文只介绍关于MCMC训练的部分,由此可知,MCMC常常被用于训练EBM。最后一张图源于Implicit Generation and Modeling with Energy-Based Mod…
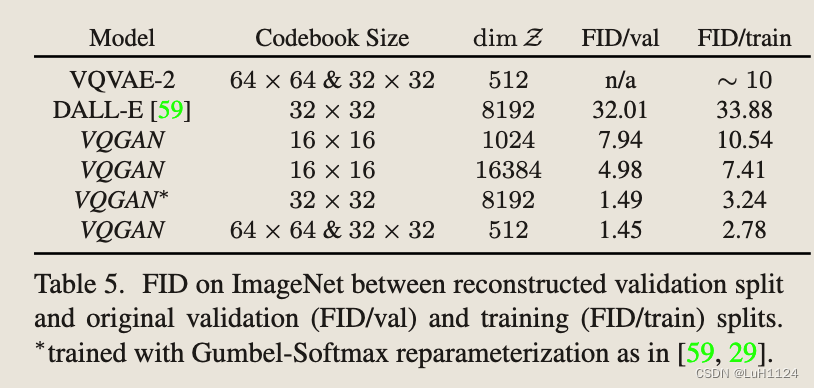
【论文阅读笔记】Taming Transformers for High-Resolution Image Synthesis
Taming Transformers for High-Resolution Image Synthesis 记录前置知识AbstractIntroductionRelated WorkMethodLearning an Effective Codebook of Image Constituents for Use in TransformersLearning the Composition of Images with Transformers条件合成合成高分辨率图…
【图像拼接】论文精读:Fisheye image rectification for efficient large-scale stereo
第一次来请先看这篇文章:【图像拼接(Image Stitching)】关于【图像拼接论文精读】专栏的相关说明,包含专栏使用说明、创新思路分享等(不定期更新)
图像拼接系列相关论文精读 Seam Carving for Content-Aware Image ResizingAs-Rigid-As-Possible Shape ManipulationAdap…
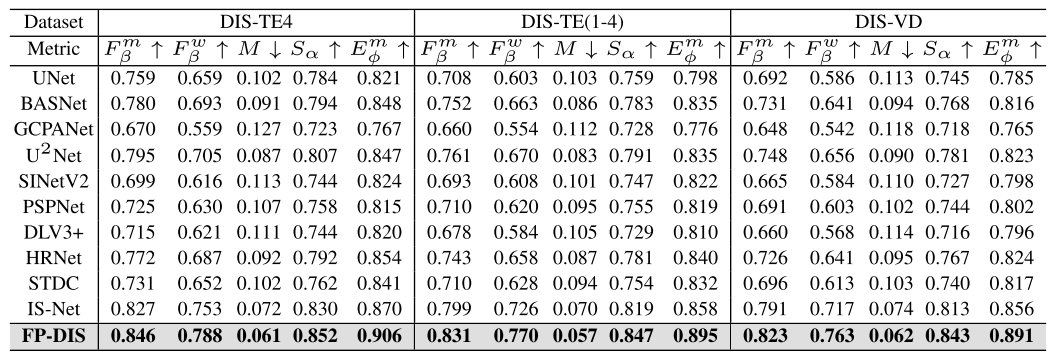
【论文阅读笔记】Dichotomous Image Segmentation with Frequency Priors
1. 论文介绍
Dichotomous Image Segmentation with Frequency Priors 基于频率先验的二分图像分割 2023年发表在IJCAI Paper Code
2. 摘要
二分图像分割(DIS)具有广泛的实际应用,近年来得到了越来越多的研究关注。本文提出了解决DIS与信息…

【计算机病毒传播模型】报告:区块链在车联网中的应用
区块链在车联网中的应用 写在最前面题目 - 26 车联网安全汇报演讲稿-删减2后,最终版(1469字版本)汇报演讲稿-删减1后(2555字版本)汇报演讲稿-删减前(3677字版本)1 概述1.1 车联网1.2 区块链1.3 …
NLP论文阅读记录 - 2021 | RefSum:重构神经总结
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.前提堆叠重新排序 三.本文方法3.1 总结为两阶段学习3.1.1 基础系统3.1.2 元系统 3.2 重构文本摘要3.2.1 重构3.2.2 预训练重构3.2.3 微调重构3.2.4 应用场景3.2.4.1 重构为基础学习者3.2.4.2 …
论文阅读-Examining Zero-Shot Vulnerability Repair with Large Language Models
1.本文主旨: 这篇论文探讨了使用大型语言模型(LLM)进行零射击漏洞修复的方法。人类开发人员编写的代码可能存在网络安全漏洞,新兴的智能代码补全工具是否能帮助修复这些漏洞呢?在本文中,作者研究了大型语言…
【图像拼接】论文精读:Rectangular-Output Image Stitching(RDISNet)
第一次来请先看这篇文章:【图像拼接(Image Stitching)】关于【图像拼接论文精读】专栏的相关说明,包含专栏使用说明、创新思路分享等(不定期更新)
图像拼接系列相关论文精读 Seam Carving for Content-Aware Image ResizingAs-Rigid-As-Possible Shape ManipulationAdap…
新颖度爆表。网络药理学+PPI+分子对接+实验验证
今天给同学们分享一篇生信文章“The convergent application of metabolites from Avena sativa and gut microbiota to ameliorate non-alcoholic fatty liver disease: a network pharmacology study”,这篇文章发表在J Transl Med期刊上,影响因子为7.…
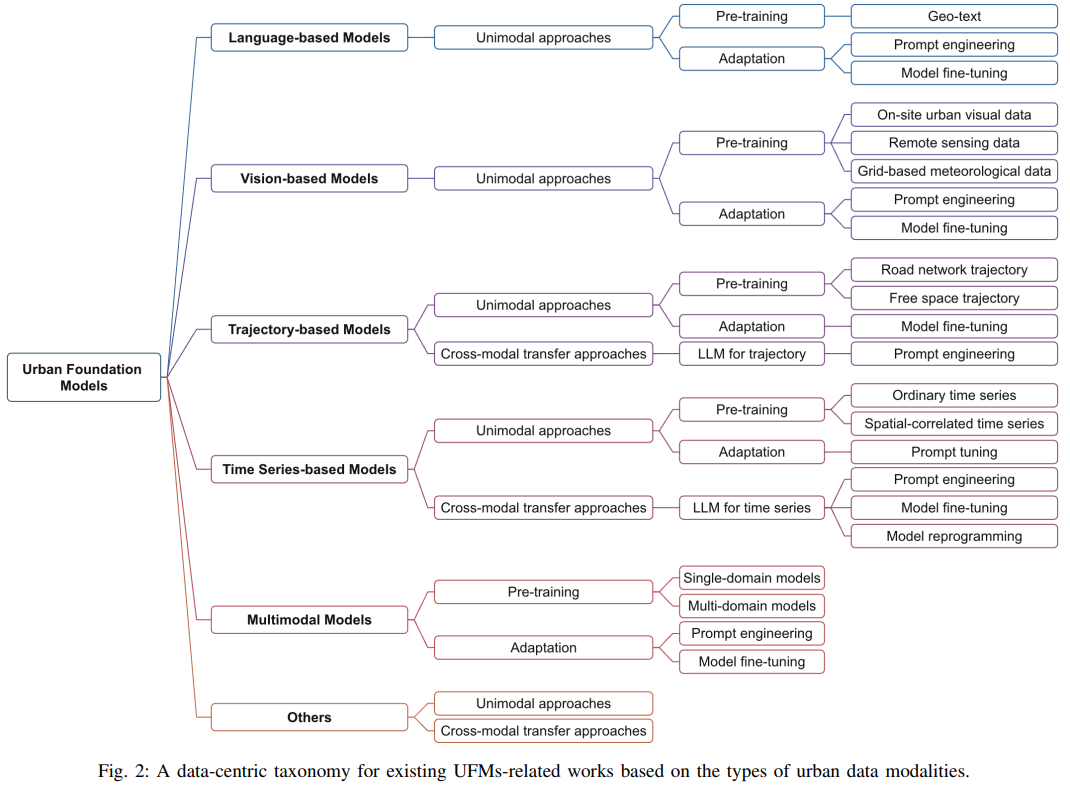
AI论文速读 |【综述】城市基础模型回顾与展望——迈向城市通用智能
最近申请了一个公众号,名字为“时空探索之旅”。之后会同步将知乎有关时空和时序的论文总结和论文解读发布在公众号,更方便大家查看与阅读。欢迎大家关注,也欢迎多多提建议。 🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘…
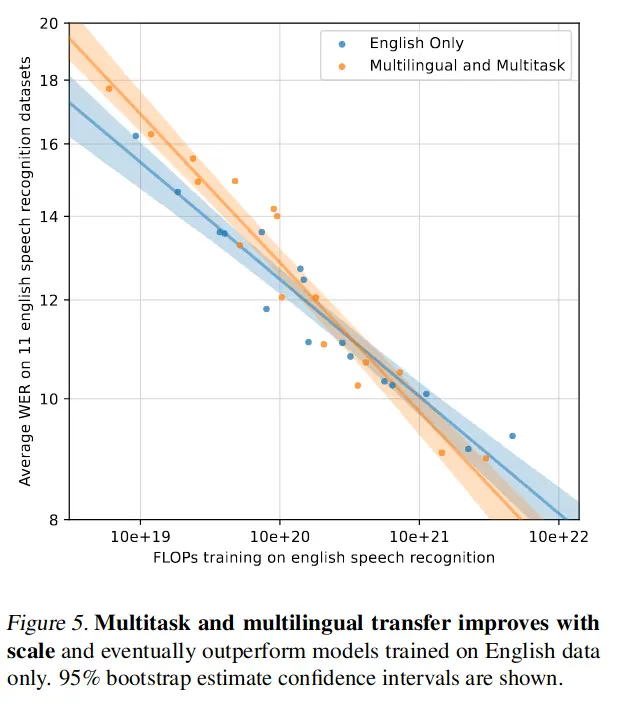
论文阅读_语音识别_Wisper
英文名称: Robust Speech Recognition via Large-Scale Weak Supervision
中文名称: 通过大规模弱监督实现鲁棒语音识别
链接: https://proceedings.mlr.press/v202/radford23a.html
代码: https://github.com/openai/whisper
作者: Alec Radford, Jong Wook Kim, Tao Xu, Greg…

论文阅读_用模型模拟记忆过程
英文名称: A generative model of memory construction and consolidation
中文名称: 记忆构建和巩固的生成模型
文章: https://www.nature.com/articles/s41562-023-01799-z
代码: https://github.com/ellie-as/generative-memory
作者: Eleanor Spens, Neil Burgessÿ…
论文精读--MoCo
MoCo作为无监督的表征学习的工作,它不仅在分类任务上逼近了有监督的基线模型,而且在很多的主流视觉任务上都超越了有监督预训练模型
MoCo证明无监督学习在视觉领域是可行的,我们有可能真的不需要大规模的有标注的数据去训练
Abstract
未完…
论文阅读:How Do Neural Networks See Depth in Single Images?
是由Technische Universiteit Delft(代尔夫特理工大学)发表于ICCV,2019。这篇文章的研究内容很有趣,没有关注如何提升深度网络的性能,而是关注单目深度估计的工作机理。
What they find?
所有的网络都忽略了物体的实际大小,而关注他们的垂直…
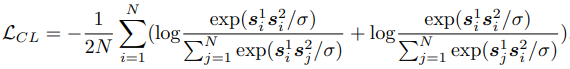
论文阅读——ONE-PEACE
ONE-PEACE: EXPLORING ONE GENERAL REPRESENTATION MODEL TOWARD UNLIMITED MODALITIES 适应不同模态并且支持多模态交互。
预训练任务不仅能提取单模态信息,还能模态间对齐。
预训练任务通用且直接,使得他们可以应用到不同模态。 各个模态独立编码&am…
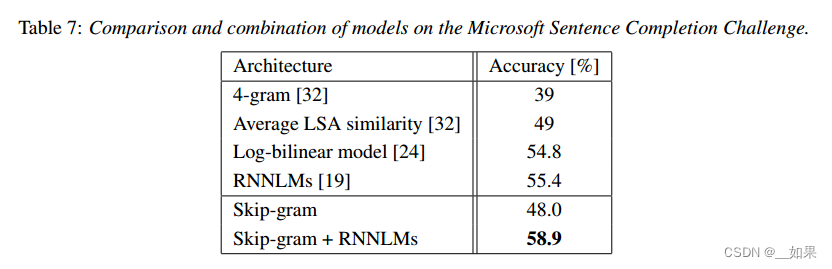
论文精读--word2vec
word2vec从大量文本语料中以无监督方式学习语义知识,是用来生成词向量的工具
把文本分散嵌入到另一个离散空间,称作分布式表示,又称为词嵌入(word embedding)或词向量
Abstract We propose two novel model architec…

Colmap学习笔记(一):Pixelwise View Selection for Unstructured Multi-View Stereo论文阅读
1. 摘要
本文展示一套MVS系统,该系统利用非结构化的图片实现鲁棒且稠密的建模。本文的主要贡献是深度和法向量的联合估计,用光度和几何先验进行像素筛选,多视图几何一致项,该项同时进行精修和基于图片的深度和法向量的融合。在标…
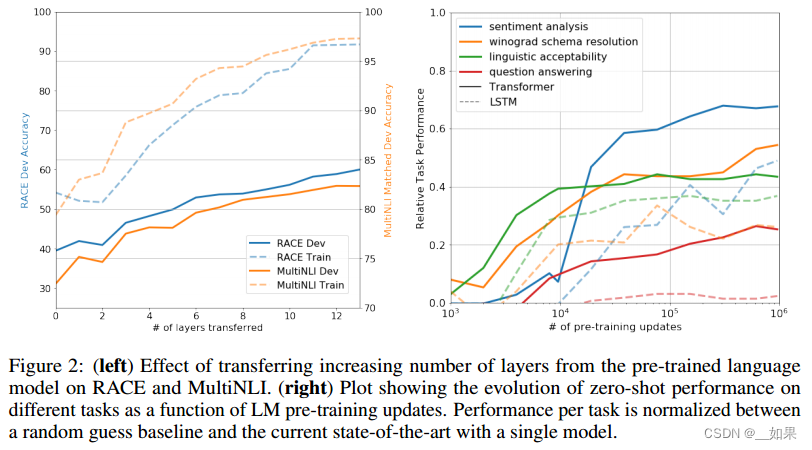
论文精读--GPT1
把transformer的解码器拿出来,在没有标号的大量文本数据上训练一个语言模型,来获得预训练模型,然后到子任务上微调,得到每个任务所需的分类器
Abstract Natural language understanding comprises a wide range of diverse tasks…
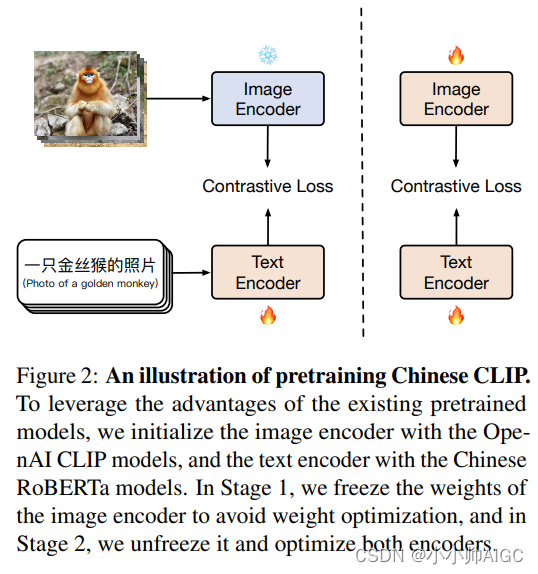
多模态表征—CLIP及中文版Chinese-CLIP:理论讲解、代码微调与论文阅读
我之前一直在使用CLIP/Chinese-CLIP,但并未进行过系统的疏导。这次正好可以详细解释一下。相比于CLIP模型,Chinese-CLIP更适合我们的应用和微调,因为原始的CLIP模型只支持英文,对于我们的中文应用来说不够友好。Chinese-CLIP很好地…
![[论文笔记] Mistral论文解读](https://img-blog.csdnimg.cn/direct/4ab32b4826344530b826f1e8295485e1.png)
[论文笔记] Mistral论文解读
https://arxiv.org/pdf/2310.06825.pdf GQA: 1、加快推理速度 2、减小内存需求 3、允许更大的batch 4、更高的吞吐量
SWA: 1、较低的计算成本 更有效的处理 较长的序列。 2、感受野更符合常理。不再是全局感受野,而是只和前4096个进行语义融合。…
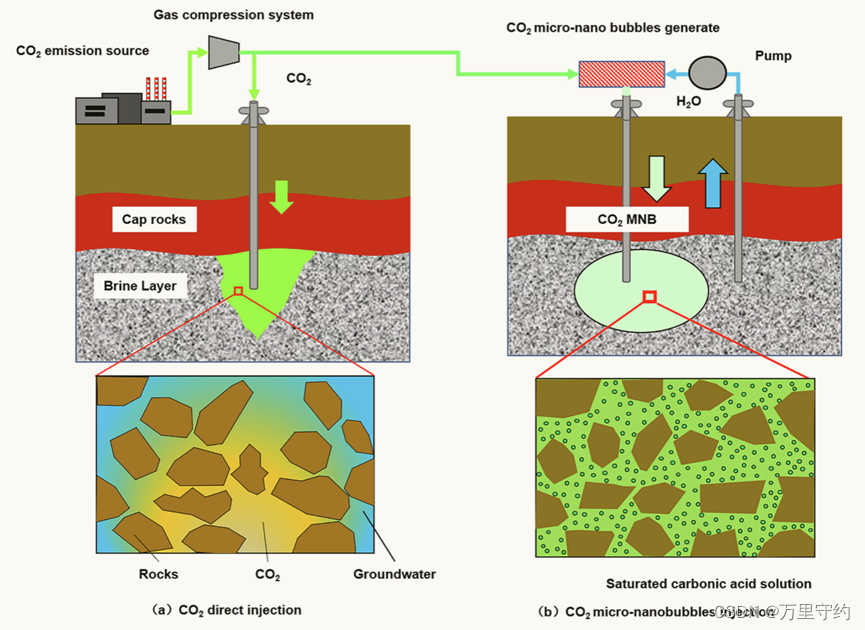
【论文阅读】微纳米气泡技术作为CO2-EOR和CO2地质储存技术的新方向:综述
Micro and nanobubbles technologies as a new horizon for CO2-EOR and CO2 geological storage techniques: A review 微纳米气泡技术作为CO2-EOR和CO2地质储存技术的新方向:综述 期刊信息:Fuel 2023 期刊级别:EI检索 SCI升级版工程技术1区…

【论文阅读】Vison-Language Navigation 视觉语言导航(1)
ACL 2022 VLN视觉和语言导航:任务、方法和未来方向综述 多模态任务新蓝海:视觉语言导航最新进展
Leader board in VLN
RXR: Room-across-Room (RxR) is a large-scale, multilingual dataset for Vision-and-Language Navigation (VLN) in…
【SLAM论文笔记】PL-EVIO笔记(下)
线特征的表达
Plucker坐标: L w [ n w l , d w l ] \bold{L}_w[\bold{n}^l_w,\bold{d}_w^l] Lw[nwl,dwl] n w l \bold{n}^l_w nwl指由坐标系原点与线决定的平面的法向量, d w l \bold{d}_w^l dwl指由线段端点决定的方向向量。
从世界坐标…
【SLAM论文笔记】PL-EVIO笔记(中)
滑窗优化
窗口由10个关键帧组成。 优化的状态参数包括事件点与图像点的逆深度、事件线特征的4参数正交表达(下一小节描述),各个关键帧IMU的加计和陀螺的零偏、世界坐标系下的位置p、速度v与姿态四元数q,IMU与相机的外参ÿ…
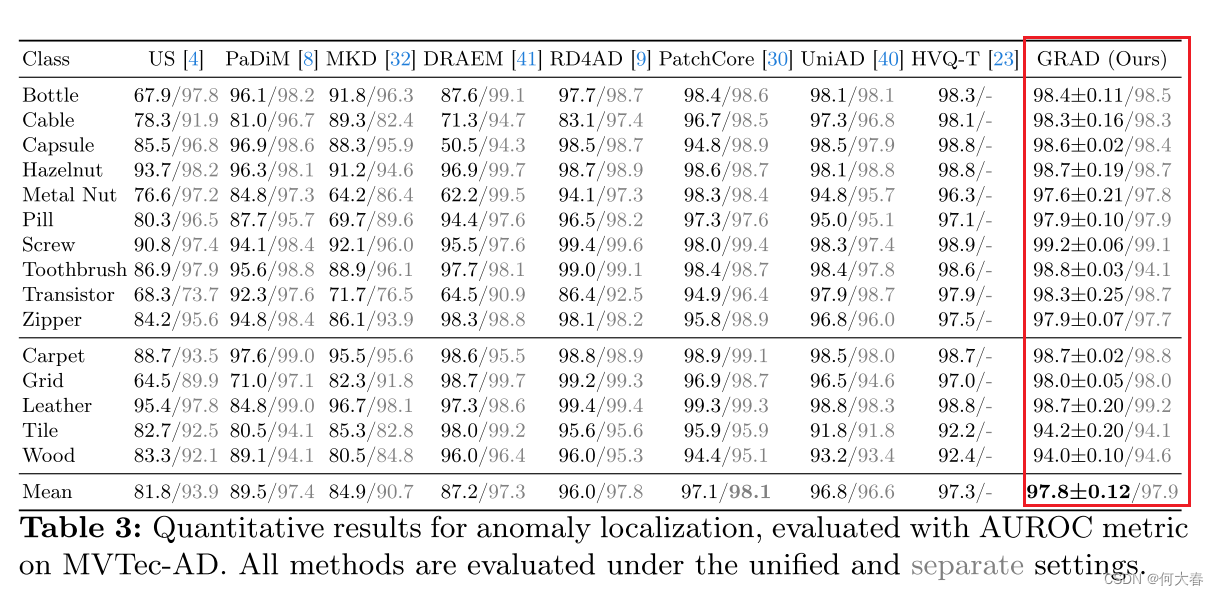
Grid-Based Continuous Normal Representation for Anomaly Detection 论文阅读
Grid-Based Continuous Normal Representation for Anomaly Detection 论文阅读 摘要简介方法3.1 Normal Representation3.2 Feature Refinement3.3 Training and Inference 4 实验结果5 总结 文章信息: 原文链接:https://arxiv.org/abs/2402.18293 源码…

【论文阅读】(DiTs)Scalable Diffusion Models with Transformers
(DiTs)Scalable Diffusion Models with Transformers 文章目录 (DiTs)Scalable Diffusion Models with Transformers论文概述Diffusion Transformers实验参考文献 引用: [1] Peebles W, Xie S. Scalable diffusion mod…

浅析扩散模型与图像生成【应用篇】(六)——DiffuseIT
6. Diffusion-based Image Translation using Disentangled Style and Content Representation 本文介绍了一种基于扩散模型的图像转换方法,图像转换就是根据文本引导或者图像的引导,将源图像转换到目标域中,如下图所示。 在图像转换中待…

【论文阅读】(DALLE-3)Improving Image Generation with Better Captions
(DALLE-3)Improving Image Generation with Better Captions 文章目录 (DALLE-3)Improving Image Generation with Better Captions简介Method实验 引用: Betker J, Goh G, Jing L, et al. Improving image generation…

论文阅读笔记 | MetaIQA: Deep Meta-learning for No-Reference Image Quality Assessment
文章目录 文章题目发表年限期刊/会议名称论文简要动机主要思想或方法架构实验结果 文章链接:https://doi.org/10.48550/arXiv.2004.05508 文章题目
MetaIQA: Deep Meta-learning for No-Reference Image Quality Assessment
发表年限
2020
期刊/会议名称
Publi…
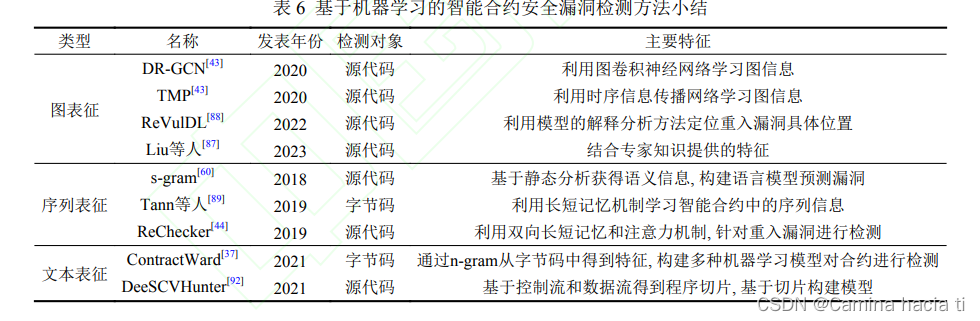
【论文阅读】关于智能合约的漏洞检测
两篇论文,都是关于智能合约漏洞检测的综述文章 [1]崔展齐,杨慧文,陈翔等.智能合约安全漏洞检测研究进展[J/OL].软件学报:1-33[2024-03-05].https://doi.org/10.13328/j.cnki.jos.007046. [2]王丹,黄松,王兴亚.以太坊智能合约测试研究综述[J].信息技术与信息化,2023(…
[论文笔记] Open-Sora 1、sora复现方案概览
GitHub - hpcaitech/Open-Sora: Unofficial implementation of OpenAIs Sora Open-Sora已涵盖: 提供完整的Sora复现架构方案,包含从数据处理到训练推理全流程。 支持动态分辨率,训练时可直接训练任意分辨率的视频,无需进行缩放。 支持多种模型结构。由于Sora实际模型结构未…
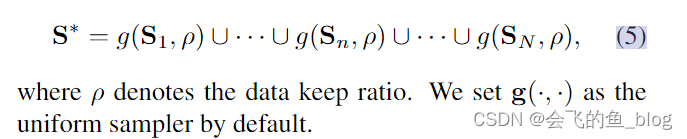
论文阅读:Dataset Quantization
摘要
最先进的深度神经网络使用大量(百万甚至数十亿)数据进行训练。昂贵的计算和内存成本使得在有限的硬件资源上训练它们变得困难,特别是对于最近流行的大型语言模型 (LLM) 和计算机视觉模型 (CV)。因此最近流行的数据集蒸馏方法得到发展&a…

【论文阅读】DeepLab:语义图像分割与深度卷积网络,自然卷积,和完全连接的crf
【论文阅读】DeepLab:语义图像分割与深度卷积网络,自然卷积,和完全连接的crf 文章目录 【论文阅读】DeepLab:语义图像分割与深度卷积网络,自然卷积,和完全连接的crf一、介绍二、联系工作三、方法3.1 整体结构3.2 使用空间金字塔池…

论文速览 | MobiSys 2018 | AIM: 通过智能手机实现声学成像 | AIM: Acoustic Imaging on a Mobile
无线感知/雷达成像部分最新工作<持续更新>: 链接地址 注1:本文系“无线感知论文速递”系列之一,致力于简洁清晰完整地介绍、解读无线感知领域最新的顶会/顶刊论文(包括但不限于 Nature/Science及其子刊; MobiCom, Sigcom, MobiSys, NSDI, SenSys, Ubicomp; JSAC, 雷达学报…
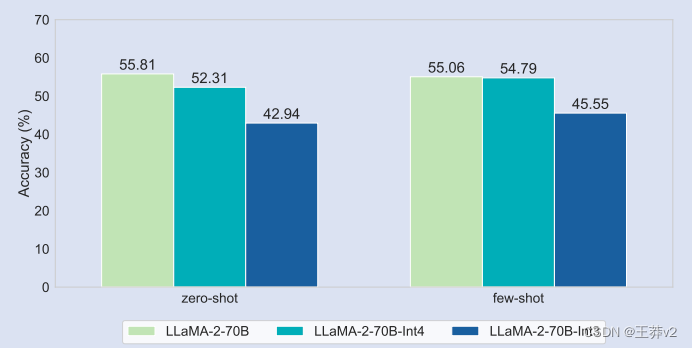
【论文阅读】OpsEval
粗糙翻译,如有兴趣请看原文,链接:https://arxiv.org/abs/2310.07637
摘要
信息技术(IT)运营(Ops),特别是用于IT运营的人工智能(AlOps),是保持现…

《PDVC》论文笔记
PS:模型代码解释清明后出
原文链接:
[2108.07781v1] End-to-End Dense Video Captioning with Parallel Decoding (arxiv.org)
原文笔记:
What:
End-to-End Dense Video Captioning with Parallel Decoding
并行解码的端到端…
【论文阅读笔记】SAM-Adapter: Adapting Segment Anything in Underperformed Scenes
1.论文介绍
SAM-Adapter: Adapting Segment Anything in Underperformed Scenes SAM适配器:在表现不佳的场景中适配任何片段
2023年 ICCV Paper Code SAM Fails to Segment Anything? – SAM-Adapter: Adapting SAM in Underperformed Scenes: Camouflage, Shado…

论文笔记:Teaching Large Language Models to Self-Debug
ICLR 2024 REVIEWER打分 6666
1 论文介绍
论文提出了一种名为 Self-Debugging 的方法,通过执行生成的代码并基于代码和执行结果生成反馈信息,来引导模型进行调试不同于需要额外训练/微调模型的方法,Self-Debugging 通过代码解释来指导模型识…

论文笔记:UNDERSTANDING PROMPT ENGINEERINGMAY NOT REQUIRE RETHINKING GENERALIZATION
ICLR 2024 reviewer评分 6888
1 intro
zero-shot prompt 在视觉-语言模型中,已经取得了令人印象深刻的表现 这一成功呈现出一个看似令人惊讶的观察:这些方法相对不太受过拟合的影响 即当一个提示被手动工程化以在给定训练集上达到低错误率时࿰…
【SCI绘图】【曲线图系列2 python】多类别标签对比的曲线图
SCI,CCF,EI及核心期刊绘图宝典,爆款持续更新,助力科研!
本期分享:
【SCI绘图】【曲线图系列2 python】多类别标签对比的曲线图,文末附完整代码。 1.环境准备
python 3
import proplot as pp…

【论文阅读】CompletionFormer:深度完成与卷积和视觉变压器
【论文阅读】CompletionFormer:深度完成与卷积和视觉变压器 文章目录 【论文阅读】CompletionFormer:深度完成与卷积和视觉变压器一、介绍二、联系工作深度完成Vision Transformer 三、方法四、实验结果 CompletionFormer: Depth Completion with Convolutions and Vision Tran…
【SCI绘图】【小提琴系列1 python】绘制按分类变量分组的垂直小提琴图
SCI,CCF,EI及核心期刊绘图宝典,爆款持续更新,助力科研!
本期分享:
【SCI绘图】【小提琴系列1 python】绘制按分类变量分组的垂直小提琴图,文末附完整代码 小提琴图是一种常用的数据可视化工具…
论文笔记:Evaluating the Performance of Large Language Models on GAOKAO Benchmark
1 论文思路
采用zero-shot prompting的方式,将试题转化为ChatGPT的输入 对于数学题,将公式转化为latex输入
主观题由专业教师打分
2 数据
2010~2022年,一共13年间的全国A卷和全国B卷 3 结论
3.1 不同模型的zeroshot 高考总分 3.2 各科主…
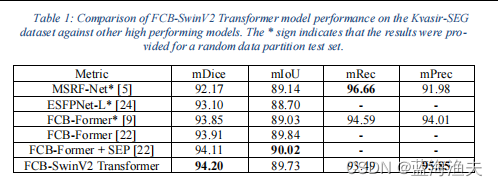
论文阅读:FCB-SwinV2 Transformer for Polyp Segmentation
这是对FCBFormer的改进,我的关于FCBFormer的论文阅读笔记:论文阅读FCN-Transformer Feature Fusion for PolypSegmentation-CSDN博客
1,整体结构
依然是一个双分支结构,总体结构如下: 其中一个是全卷积分支ÿ…
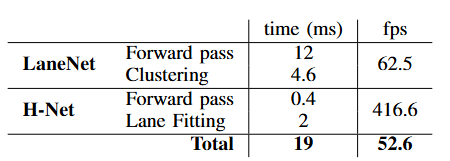
LaneNet 论文阅读
论文链接
Towards End-to-End Lane Detection: an Instance Segmentation Approach 0. Abstract
在本文中,将车道检测问题转化为实例分割问题——其中每个车道形成自己的实例——可以进行端到端训练为了在拟合车道之前对分段车道实例进行参数化,应用基…
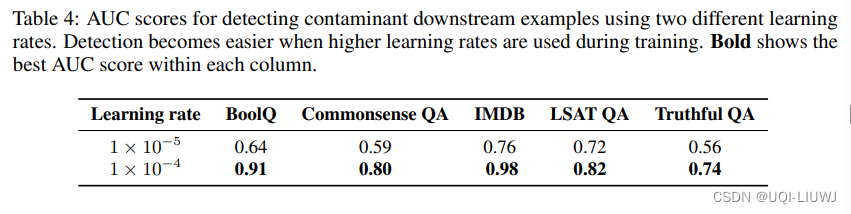
论文笔记:Detecting Pretraining Data from Large Language Models
iclr 2024 reviewer评分 5688
1 intro
论文考虑的问题:给定一段文本和对一个黑盒语言模型的访问权限,在不知道其预训练数据的情况下,能否判断该模型是否在这段文本上进行了预训练 这个问题是成员推断攻击(Membership Inference Attacks&…
【救命爆品!】SCI润色,好用到哭!
五月收到返稿意见,提示语言太差,需要润色,于是向周围伙伴们打听了是给润色公司还是别的润色软件润色比较好。得出的结论是,如果需要稳妥一点,还是找专门的润色机构,在返稿的时候,附上润色证明&a…
![[论文阅读笔记30] (AAAI2024) UCMCTrack: Multi-Object Tracking with Uniform CMC 详细推导](https://img-blog.csdnimg.cn/direct/a920d6f9a9f44044a4f4162b0d6686cb.png)
[论文阅读笔记30] (AAAI2024) UCMCTrack: Multi-Object Tracking with Uniform CMC 详细推导
这是群友的一篇工作,之前也没仔细看,正好今天放假,打算读一下论文陶冶情操。 这篇文章的公式比较多,我做一篇笔记解释一下,希望对大家有帮助~
论文地址: https://ojs.aaai.org/index.php/AAAI/article/view/28493
代…
《论文阅读》利用情感语义关联生成同情回复 EMNLP 2023
《论文阅读》利用情感语义关联生成同情回复 前言简介贡献相关研究Context EncoderDynamic Correlation Encoding ModuleEmotion PredictingResponse Predicting损失函数实验结果消融实验总结前言
亲身阅读感受分享,细节画图解释,再也不用担心看不懂论文啦~ 无抄

伪装目标检测论文阅读之:《Confidence-Aware Learning for Camouflaged Object Detection》
论文地址:link code:link 摘要: 任意不确定性捕获了观测结果中的噪声。对于伪装目标检测,由于伪装前景和背景的外观相似,很难获得高精度的注释,特别是目标边界周围的注释。我们认为直接使用“嘈杂”的伪装图进行训…
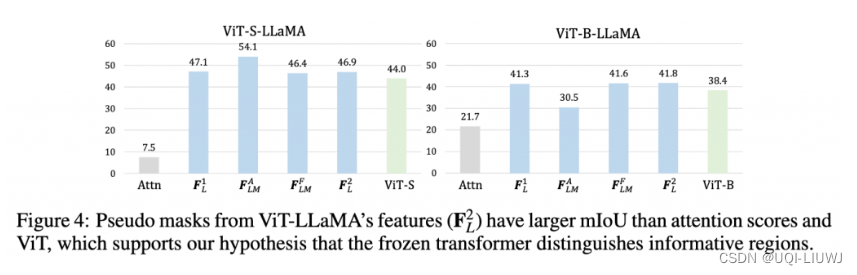
论文笔记:FROZEN TRANSFORMERS IN LANGUAGE MODELSARE EFFECTIVE VISUAL ENCODER LAYERS
iclr 2024 spotlight reviewer 评分 6668
1 intro
在CV领域,很多Vision-language Model 会把来自图像的Embedding输入给LLM,并让LLM作为Decoder输出文字、类别、检测框等 但是在这些模型中,LLM并不会直接处理来自图像的Token,需…

《论文阅读》构建情感共识并利用未配对数据生成共情对话 ACL 2021
《论文阅读》构建情感共识并利用未配对数据生成共情对话 ACL 2021 前言简介模型构架损失函数实验结果前言
亲身阅读感受分享,细节画图解释,再也不用担心看不懂论文啦~ 无抄袭,无复制,纯手工敲击键盘~
今天为大家带来的是《Constructing Emotion Consensus and Utilizing …
论文阅读--Conservative Q-Learning for Offline Reinforcement Learning
摘要
在强化学习( RL )中有效地利用以前收集的大量数据集是大规模实际应用的关键挑战。离线RL算法承诺从先前收集的静态数据集中学习有效的策略,而无需进一步的交互。然而,在实际应用中,离线RL是一个主要的挑战,标准的离线RL方法…
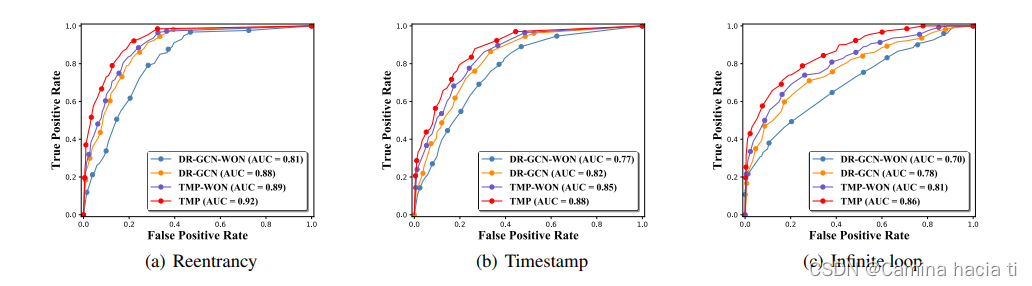
【论文阅读】Smart Contract Vulnerability Detection Using Graph Neural Networks
1、摘要
1、使用图神经网络(GNN)进行智能合约漏洞检测:构建了一个合约图来表示智能合约函数的句法和语义结构,图中的节点表示关键函数调用或变量,而边则捕获其时态执行轨迹。 2、为了突出显示主要节点,设计…
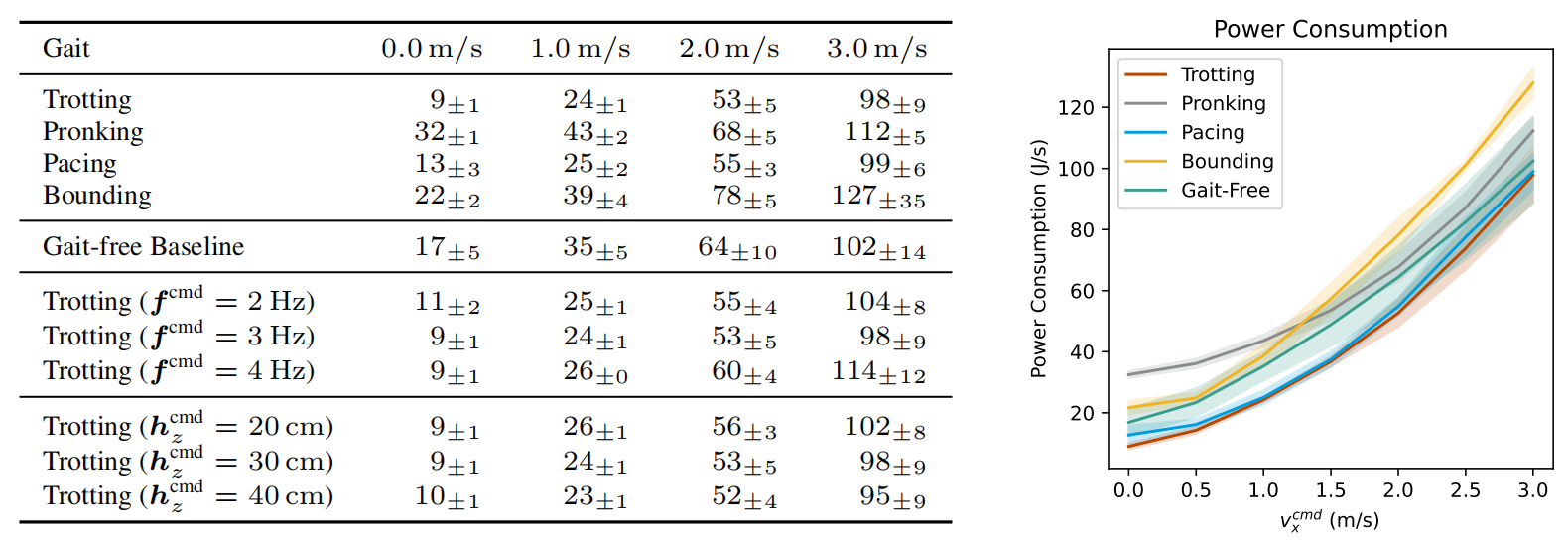
论文阅读:Walk These Ways: 通过行为多样性调整机器人控制以实现泛化
Walk These Ways: 通过行为多样性调整机器人控制以实现泛化
摘要:
通过学习得到的运动策略可以迅速适应与训练期间经历的类似环境,但在面对分布外测试环境失败时缺乏快速调整的机制。这就需要一个缓慢且迭代的奖励和环境重新设计周期来在新任务上达成良…

Node2Vec论文翻译
node2vec: Scalable Feature Learning for Networks
node2vec:可扩展的网络特征学习
ABSTRACT
网络中节点和边缘的预测任务需要在学习算法使用的工程特征上付出仔细的努力。最近在更广泛的表示学习领域的研究通过学习特征本身在自动化预测方面取得了重大进展。然…
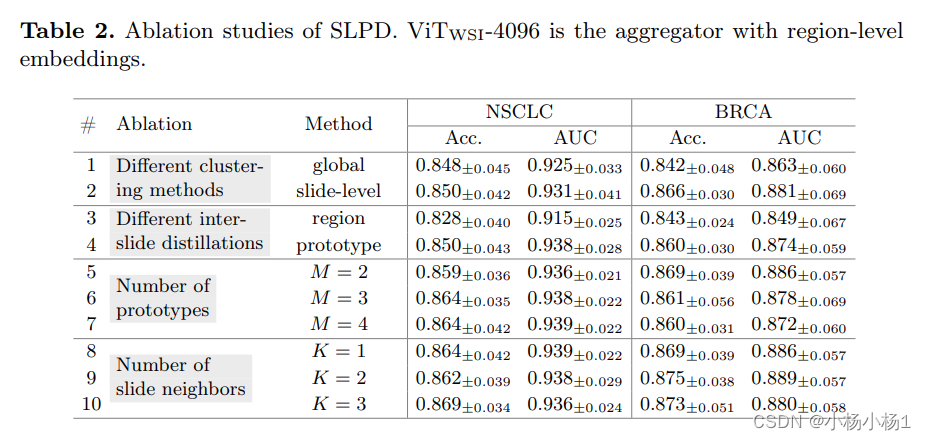
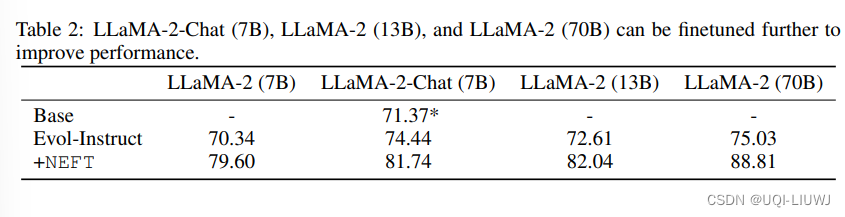
论文笔记:NEFTune: Noisy Embeddings Improve Instruction Finetuning
iclr 2024 reviewer 评分 5666
1 论文思路
论文的原理很简单:在finetune过程的词向量中引入一些均匀分布的噪声即可明显地提升模型的表现 2 方法评估
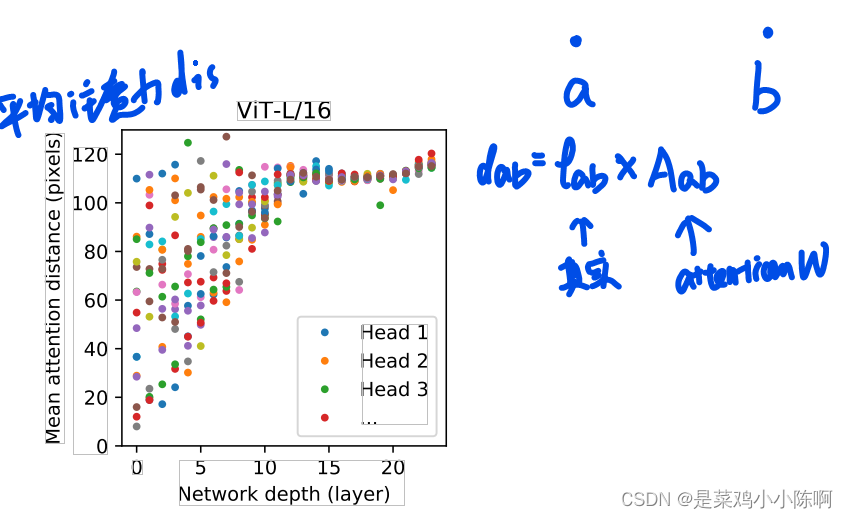

2024年能源环境、材料科学与人工智能国际会议(ICEEMSAI2024)
2024年能源环境、材料科学与人工智能国际会议(ICEEMSAI2024)
会议简介
2024国际能源环境、材料科学和人工智能大会(ICEEMSAI 2024)主要围绕能源环境、物质科学和人工智慧等研究领域,旨在吸引能源环境、先进材料和人工智能专家学者、科技人员…

【论文阅读】MCTformer: 弱监督语义分割的多类令牌转换器
【论文阅读】MCTformer: 弱监督语义分割的多类令牌转换器 文章目录 【论文阅读】MCTformer: 弱监督语义分割的多类令牌转换器一、介绍二、联系工作三、方法四、实验结果 Multi-class Token Transformer for Weakly Supervised Semantic Segmentation 本文提出了一种新的基于变换…
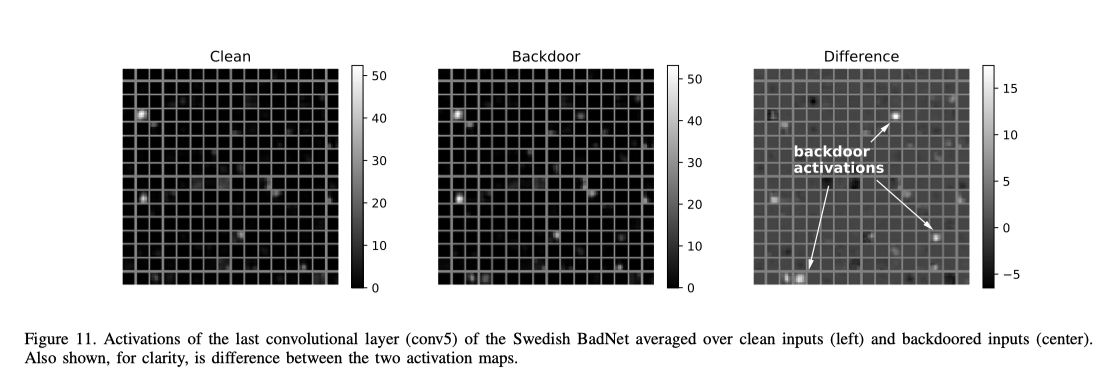
【论文阅读】IEEE Access 2019 BadNets:评估深度神经网络的后门攻击
文章目录 一.论文信息二.论文内容1.摘要2.引言3.主要图表4.结论 一.论文信息
论文题目: BadNets: Evaluating Backdooring Attacks on Deep Neural Networks(BadNets:评估深度神经网络的后门攻击)
论文来源: 2019-IEEE Access
…

【论文阅读】Improved Denoising Diffusion Probabilistic Models
Improved Denoising Diffusion Probabilistic Models 文章目录 Improved Denoising Diffusion Probabilistic Models概述Improving the Log-likelihoodLearning ∑ θ ( x t , t ) \sum_{\theta}(x_{t}, t) ∑θ(xt,t)Improving the Noise ScheduleReducing Gradient Nois…
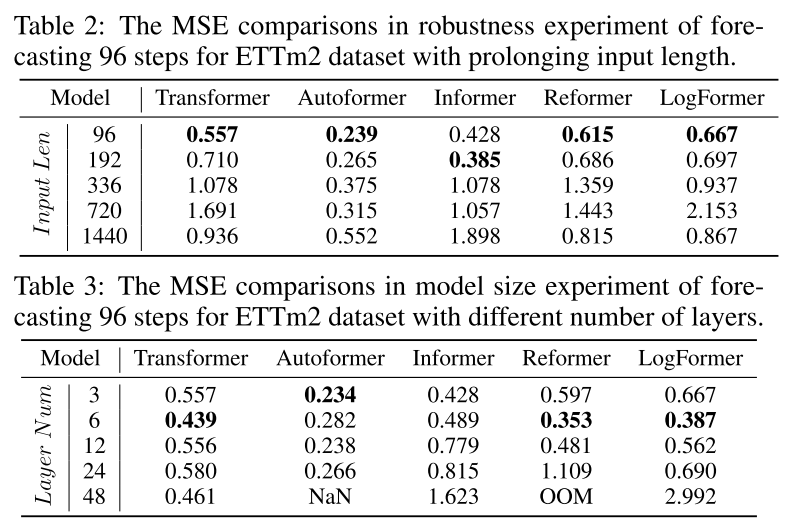
【论文笔记合集】Transformers in Time Series A Survey综述总结
本文作者: slience_me 文章目录 Transformers in Time Series A Survey综述总结1 Introduction2 Transformer的组成Preliminaries of the Transformer2.1 Vanilla Transformer2.2 输入编码和位置编码 Input Encoding and Positional Encoding绝对位置编码 Absolute …
![[论文笔记]LLaMA: Open and Efficient Foundation Language Models](https://img-blog.csdnimg.cn/img_convert/5438e10bf23516a6eb5033737338c247.png)
[论文笔记]LLaMA: Open and Efficient Foundation Language Models
引言
今天带来经典论文 LLaMA: Open and Efficient Foundation Language Models 的笔记,论文标题翻译过来就是 LLaMA:开放和高效的基础语言模型。
LLaMA提供了不可多得的大模型开发思路,为很多国产化大模型打开了一片新的天地,论文和代码值…

【论文阅读】MoCoGAN: Decomposing Motion and Content for Video Generation
MoCoGAN: Decomposing Motion and Content for Video Generation
引用: Tulyakov S, Liu M Y, Yang X, et al. Mocogan: Decomposing motion and content for video generation[C]//Proceedings of the IEEE conference on computer vision and pattern recognitio…
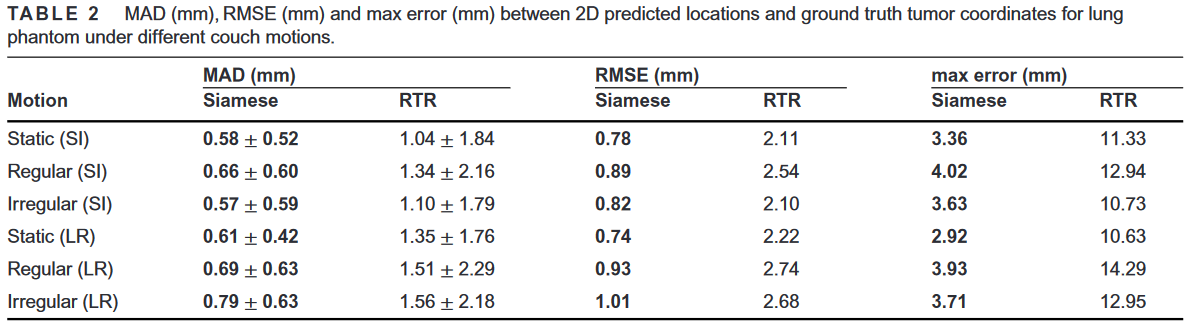
医学图像目标跟踪论文阅读笔记 2024.03.08~2024.03.14
“Inter-fractional portability of deep learning models for lung target tracking on cine imaging acquired in MRI-guided radiotherapy”
2024年 期刊 Physical and Engineering Sciences in Medicine 医学4区
没资源,只读了摘要,用的是U-net、a…
《论文阅读》E-CORE:情感相关性增强的移情对话生成 EMNLP 2023
《论文阅读》E-CORE:情感相关性增强的移情对话生成 EMNLP 2023 前言摘要模型架构图构建边的构建和初始化节点的初始化图更新情感相关性加强解码损失函数总结前言
亲身阅读感受分享,细节画图解释,再也不用担心看不懂论文啦~ 无抄袭,无复制,纯手工敲击键盘~
今天为大家带来…
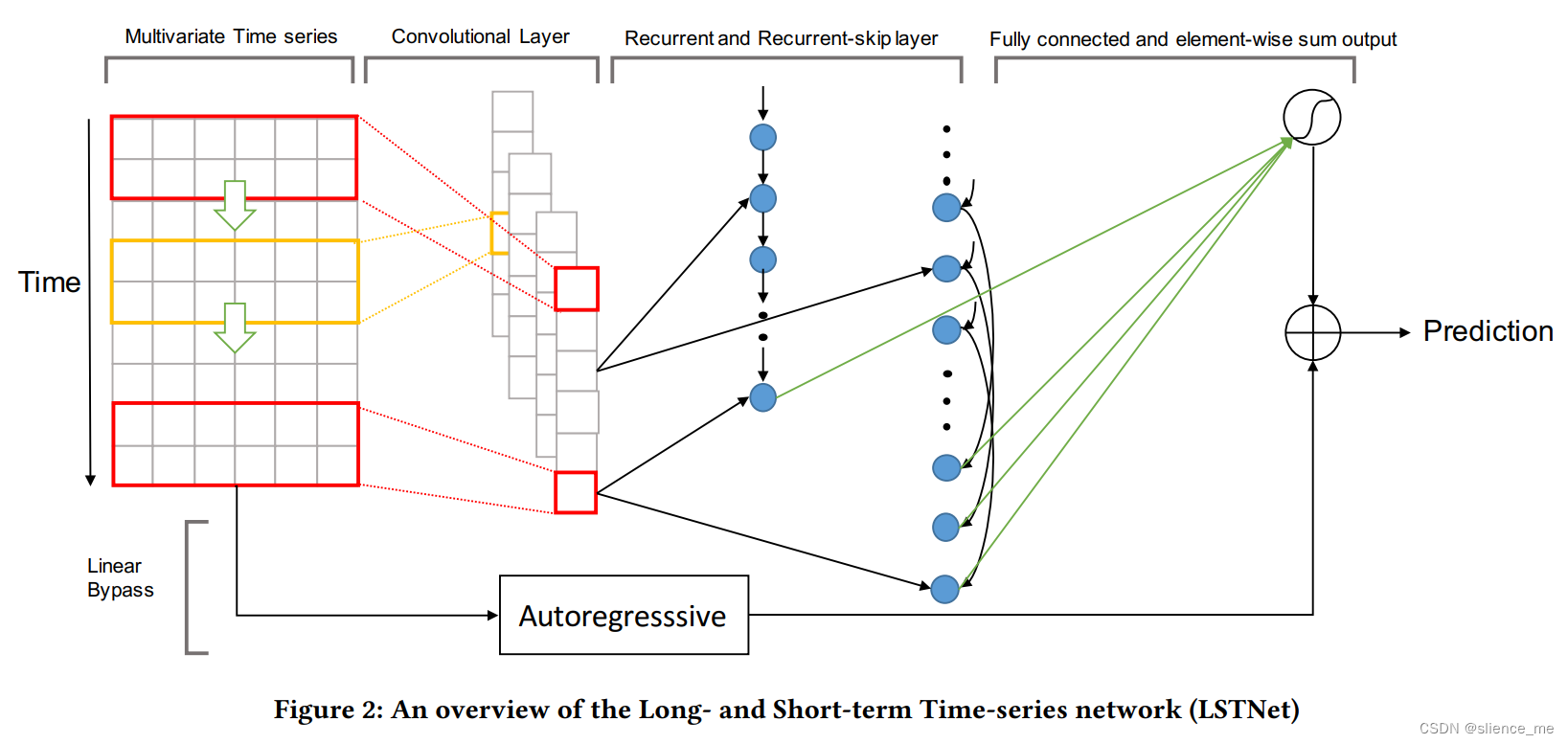
【论文笔记合集】LSTNet之循环跳跃连接
本文作者: slience_me LSTNet 循环跳跃连接
文章仅作为个人笔记 论文链接
文章原文 LSTNet [25] introduces convolutional neural networks (CNNs) with recurrent-skip connections to capture the short-term and long-term temporal patterns. LSTNet [25]引入…
CXL (Compute Express Link) Technology——论文阅读
Journal of Computer and Communications 2023 Paper CXL论文阅读笔记整理
CXL概述
CXL(计算高速链路)技术是一种较新的高速互连标准,旨在实现数据中心系统中CPU、GPU和其他高性能组件之间更快的通信。
CXL技术研究:CXL技术基于…

OCR-free相关论文梳理
引言
通用文档理解,是OCR任务的终极目标。现阶段的OCR各种垂类任务都是通用文档理解任务的子集。这感觉就像我们一下子做不到通用文档理解,退而求其次,先做各种垂类任务。
现阶段,Transformer技术的发展,让通用文档理…

【论文精读】OTA: Optimal Transport Assignment for Object Detection(物体探测的最优传输分配)
OTA最优传输 🚀🚀🚀摘要一、1️⃣ Introduction---介绍二、2️⃣Related Work---相关工作2.1 🎓 Fixed Label Assignment--静态标签分配2.2 ✨Dynamic Label Assignment--动态标签分配 三、3️⃣Method---论文方法3.1 Ἱ…

【论文阅读】(DALL-E)Zero-Shot Text-to-Image Generation
(DALL-E)Zero-Shot Text-to-Image Generation
引用: Ramesh A, Pavlov M, Goh G, et al. Zero-shot text-to-image generation[C]//International conference on machine learning. Pmlr, 2021: 8821-8831.
论文链接: [2102.120…
【文献阅读】AlphaFold touted as next big thing for drug discovery — but is it?
今天来精读2023年10月发在《Nature》上的一篇新闻:AlphaFold touted as next big thing for drug discovery — but is it? (nature.com)https://www.nature.com/articles/d41586-023-02984-w Questions remain about whether the AI tool for predicting protein …
关于短群签名论文阅读
参考文献为2004年发表的Short Group Signatures
什么群签名? 群签名大致就是由一组用户组成一个群,其中用户对某条消息的签名,改签名不会揭示是哪一个用户签署的,签名只能表明该消息确实是来自该群的签名。对于群还有一个群管理者…
![[论文笔记] ChatDev:Communicative Agents for Software Development](https://img-blog.csdnimg.cn/img_convert/9b6a113ee0043b16bdde0622000a4bf1.png)
[论文笔记] ChatDev:Communicative Agents for Software Development
Communicative Agents for Software Development(大模型驱动的全流程自动化软件开发框架) 会议arxiv 2023作者Chen Qian Xin Cong Wei Liu Cheng Yang团队Tsinghua University论文地址https://arxiv.org/pdf/2307.07924.pdf代码地址https://github.com/O…
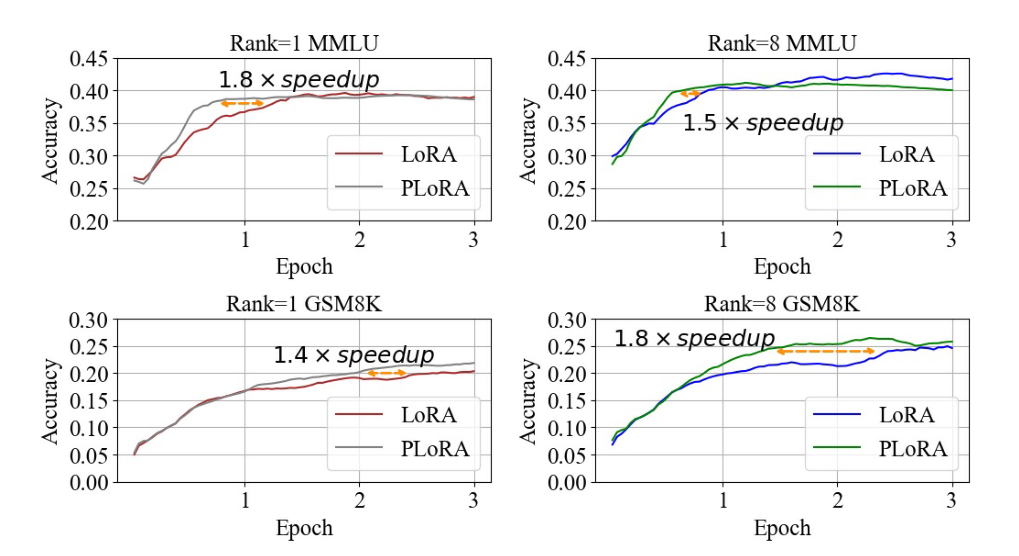
论文阅读之PeriodicLoRA: Breaking the Low-Rank Bottleneck in LoRA Optimization(2024)
文章目录 论文地址主要内容主要贡献模型图技术细节实验结果 论文地址
PeriodicLoRA: Breaking the Low-Rank Bottleneck in LoRA Optimization
主要内容
这篇文章的主要内容是介绍了一种名为PeriodicLoRA(PLoRA)的参数高效微调(Parameter-…

agent利用知识来做规划:《KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents》笔记
文章目录 简介KnowAgent思路准备知识Action Knowledge的定义Planning Path Generation with Action KnowledgePlanning Path Refinement via Knowledgeable Self-LearningKnowAgent的实验结果 总结参考资料 简介
《KnowAgent: Knowledge-Augmented Planning for LLM-Based Age…

大模型论文阅读:ADAPTIVE BUDGET ALLOCATION FOR PARAMETEREFFICIENT FINE-TUNING
大模型论文阅读:ADAPTIVE BUDGET ALLOCATION FOR PARAMETEREFFICIENT FINE-TUNING
论文链接:https://arxiv.org/pdf/2303.10512v1.pdf 当存在大量下游任务时,微调所有预训练模型的参数变得不可行。因此,为了以参数高效的方式学习预训练权重的增量更新,提出了许多微调方法,…
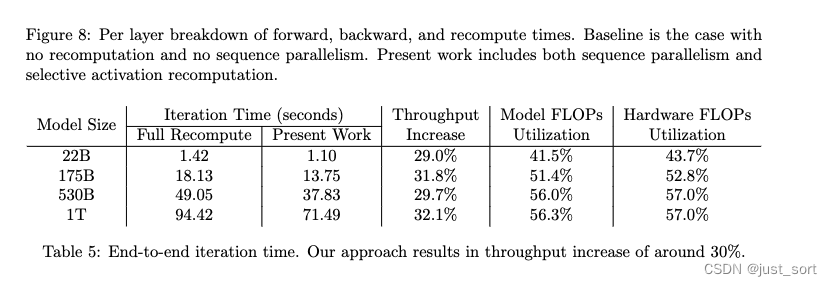
AI Infra论文阅读之《在LLM训练中减少激活值内存》
写了一个Megatron-LM的3D Parallel进程组可视化的Playground,界面长下面这样: 可以直接访问:https://huggingface.co/spaces/BBuf/megatron-lm-parallel-group-playground
脚本也开源在:https://github.com/BBuf/megatron-lm-par…
《VideoMamba》论文笔记
原文链接:
[2403.06977] VideoMamba: State Space Model for Efficient Video Understanding (arxiv.org)
原文笔记
What:
VideoMamba: State Space Model for Efficient Video Understanding
作者探究Mamba模型能否用于VideoUnderStanding作者引入…
论文阅读-多级检查点重新启动MPI应用的共同设计
论文名称:Co-Designing Multi-Level Checkpoint Restart for MPI Applications
摘要—高性能计算(HPC)系统继续通过包含更多硬件组件来支持更大的应用部署来扩展。关键是,这种扩展往往会减少故障之间的平均时间,从而使…
图像分割论文阅读:Automatic Polyp Segmentation via Multi-scale Subtraction Network
这篇论文的主要内容是介绍了一种名为多尺度差值网络(MSNet)的自动息肉分割方法。
1,模型整体结构 整体结构包括编码器,解码器,编码器和解码器之间是多尺度差值模块模块(MSM),以及一…

【论文阅读】ELA: Efficient Local Attention for Deep Convolutional Neural Networks
(ELA)Efficient Local Attention for Deep Convolutional Neural Networks
论文链接:ELA: Efficient Local Attention for Deep Convolutional Neural Networks (arxiv.org)
作者:Wei Xu, Yi Wan
单位:兰州大学信息…
![[论文笔记] CNN计算在工业场景下的一个模型优化案例](https://img-blog.csdnimg.cn/direct/8b2487acecd14c3a8e69a6263a834149.png)
[论文笔记] CNN计算在工业场景下的一个模型优化案例
0.背景
这是一篇论文笔记,现在正在处理轴承振动问题,《高噪声下改进卷积神经网络轴承故障诊断》,唐治尧,中国设备工程,2024,是随手找到的一篇使用大数据对既有振动数据集中的数据进行分析的类似样板实现。这里对这篇论文做笔记。
1.论文的目的,实验环境和结论
现有的…

论文笔记:GPT-4 Is Too Smart To Be Safe: Stealthy Chat with LLMs via Cipher
ICLR 2024 reviewer评分 5688
1 论文思路 输入转换为密码,同时附上提示,将加密输入喂给LLMLLM输出加密的输出加密的输出通过解密器解密
——>这样的步骤成功地绕过了GPT-4的安全对齐【可以回答一些反人类的问题,这些问题如果明文问的话&…
论文笔记 - :MonoLSS: Learnable Sample Selection For Monocular 3D Detection
论文笔记✍MonoLSS: Learnable Sample Selection For Monocular 3D Detection
📜 Abstract 🔨 主流做法限制 :
以前的工作以启发式的方式使用特征来学习 3D 属性,没有考虑到不适当的特征可能会产生不利影响。
🔨 本…

Monkey 和 TextMonkey ---- 论文阅读
文章目录 Monkey贡献方法增强输入分辨率多级描述生成多任务训练 实验局限结论 TextMonkey贡献方法移位窗口注意(Shifted Window Attention)图像重采样器(Image Resampler)Token Resampler位置相关任务(Position-Relate…
【论文笔记】Text2QR
论文:Text2QR: Harmonizing Aesthetic Customization and Scanning Robustness for Text-Guided QR Code Generation
Abstract
二维码通常包含很多信息但看起来并不美观。stable diffusion的出现让平衡扫描鲁棒性和美观变为可能。 为了保证美观二维码的稳定生成&a…
Zetero的安装和坚果云配置
一、Zetero安装配置 Zotero——科研小白的第一款文献管理软件
二、Zetero配置坚果云扩大空间
Zotero具备跨平台同步功能,但是其自带的免费云存储空间只有300 MB,如果要管理的文献比较多,这些空间就不够用了 Zotero | 用坚果云无限扩展文献存…

FastEI论文阅读
前言 研究FastEI有很长时间了,现在来总结一下,梳理一下认知。论文地址:https://www.nature.com/articles/s41467-023-39279-7,Github项目地址:https://github.com/Qiong-Yang/FastEI。
概要 这篇文章做的工作是小分子…
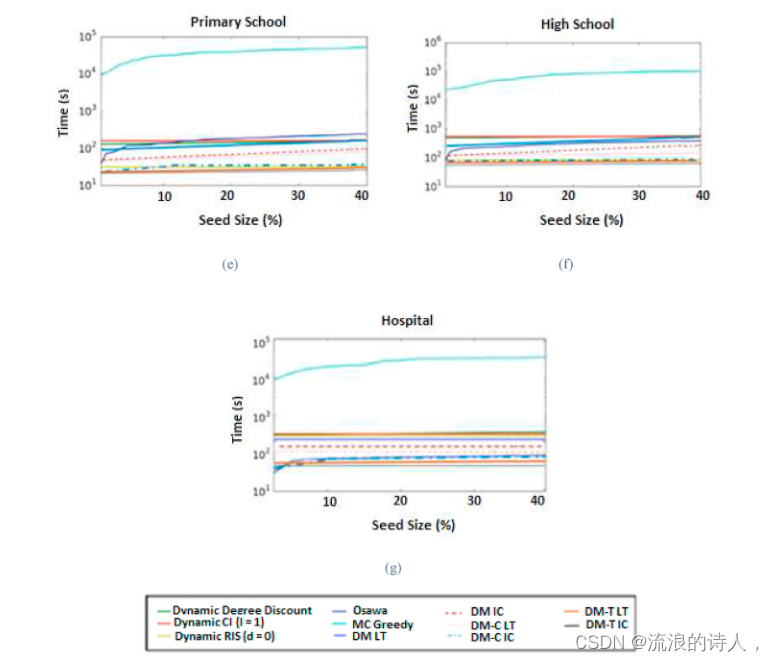
Maximization influence in dynamic social networks and graphs
ABSTRACT 社会影响力和影响力扩散在社交网络中得到了广泛的研究。然而,大多数现有的影响力扩散研究都集中在静态网络上。在本文中,我们研究动态社交网络(即随时间变化的网络)中影响力扩散最大化的问题。我们在线性阈值(…
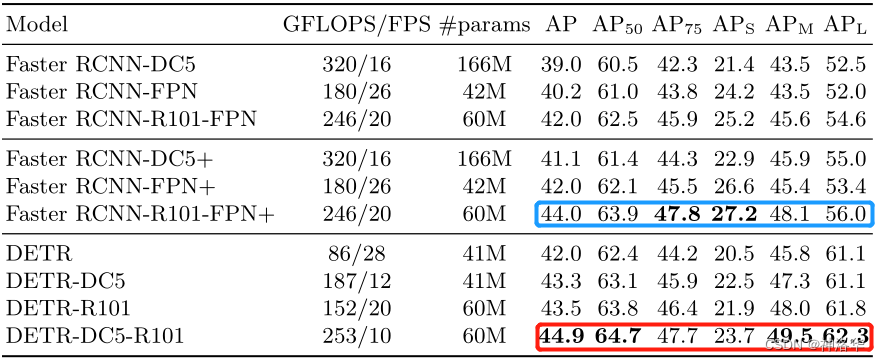
【论文阅读】DETR 论文逐段精读
【论文阅读】DETR 论文逐段精读 文章目录 【论文阅读】DETR 论文逐段精读📖DETR 论文精读【论文精读】🌐前言📋摘要📚引言🧬相关工作🔍方法💡目标函数📜模型结构⚙️代码 Ǵ…
文章分享:《呼吸道传染病标本采集及检测专家共识》
【摘要】呼吸道传染病临床特点多表现为发热和(或)呼吸道症状,病原学组成复杂,标本类型选择多样,如何从发热伴呼吸道症候群患者中早期正确识别出潜在呼吸道传染病患者是防控的关键环节。增强医务人员对呼吸道传染病临床…

【路径规划论文整理(1)】Path Deformation Roadmaps(附带对PRM改进算法、同伦映射的整理)
本系列主要是对精读的一些关于路径搜索论文的整理,包括了论文所拓展的其他一些算法的改进思路。 这是本系列的第一篇文章: Jaillet, Lonard & Simon, Thierry. (2008). Path Deformation Roadmaps: Compact Graphs with Useful Cycles for Motion Pl…
文献分享:《Clinical metagenomics》
摘要|临床宏基因组下一代测序(mNGS)是对患者样本中微生物和宿主遗传物质(DNA和RNA)的综合分析,目前正迅速从研究向临床实验室发展。这种新兴的方法正在改变医生诊断和治疗传染病的方式,其应用涉及广泛的领域…

【论文阅读】RSMamba:基于状态空间模型的遥感图像分类
【论文阅读】基于状态空间模型的遥感图像分类 文章目录 【论文阅读】基于状态空间模型的遥感图像分类一、介绍二、方法2.1 预准备 2.1 RSMamba2.2 动态多路径激活2.3 模型结构 三、实验结果 RSMamba: Remote Sensing Image Classification with State Space Mode 遥感图像分类是…
论文阅读《Semantic Prompt for Few-Shot Image Recognition》
论文地址:https://arxiv.org/pdf/2303.14123.pdf 论文代码:https://github.com/WentaoChen0813/SemanticPrompt 目录 1、存在的问题2、算法简介3、算法细节3.1、预训练阶段3.2、微调阶段3.3、空间交互机制3.4、通道交互机制 4、实验4.1、对比实验4.2、组…

【论文阅读】Natural Adversarial Examples 自然对抗的例子
文章目录 一、文章概览(一)摘要(二)导论(三)相关工作 二、IMAGENET-A 和 IMAGENET-O(一)数据集构造方式(二)数据收集过程 三、模型的故障模式四、实验&#x…
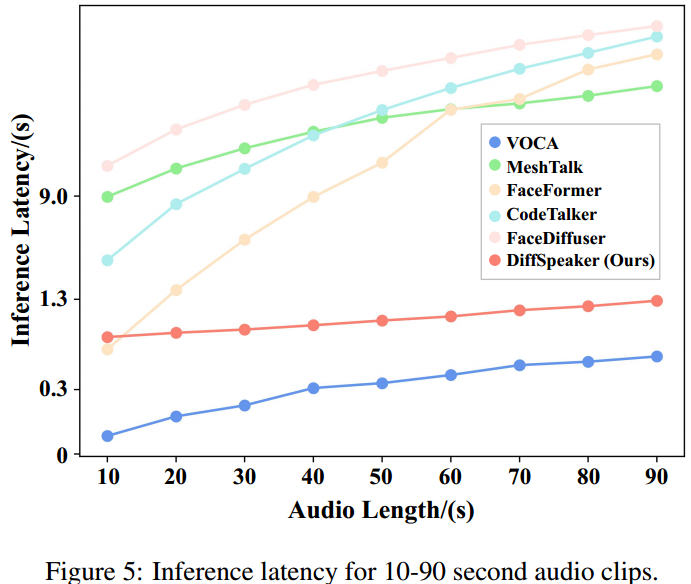
【论文阅读】DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer
DiffSpeaker: 使用扩散Transformer进行语音驱动的3D面部动画
code:GitHub - theEricMa/DiffSpeaker: This is the official repository for DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer
paper:https://arxiv.org/pdf/…

论文阅读_时序模型_iTransformer
1
2
3
4
5
6
7
8英文名称: ITRANSFORMER: INVERTED TRANSFORMERS ARE EFFECTIVE FOR TIME SERIES FORECASTING
中文名称: ITRANSFORMER:倒置Transformers在时间序列预测中的有效性
链接: https://openreview.net/forum?idX6ZmOsTYVs
代码: https://github.com/thum…
《论文阅读》EmpDG:多分辨率交互式移情对话生成 COLING 2020
《论文阅读》EmpDG:多分辨率交互式移情对话生成 COLING 2020 前言简介模型架构共情生成器交互鉴别器损失函数前言
亲身阅读感受分享,细节画图解释,再也不用担心看不懂论文啦~ 无抄袭,无复制,纯手工敲击键盘~
今天为大家带来的是《EmpDG: Multi-resolution Interactive E…
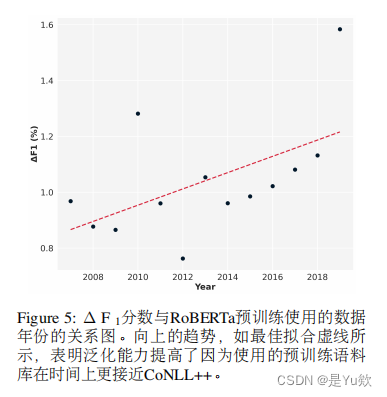
【ACL 2023获奖论文】再现奖:Do CoNLL-2003 Named Entity Taggers Still Work Well in 2023?
【ACL 2023获奖论文】再现奖:Do CoNLL-2003 Named Entity Taggers Still Work Well in 2023? 写在最前面动机主要发现和观点总结 正文1引言6 相关工作解读 2 注释一个新的测试集以度量泛化CoNLL数据集的创建数据集统计注释质量与评估者间协议目标与意义 3 实验装置…
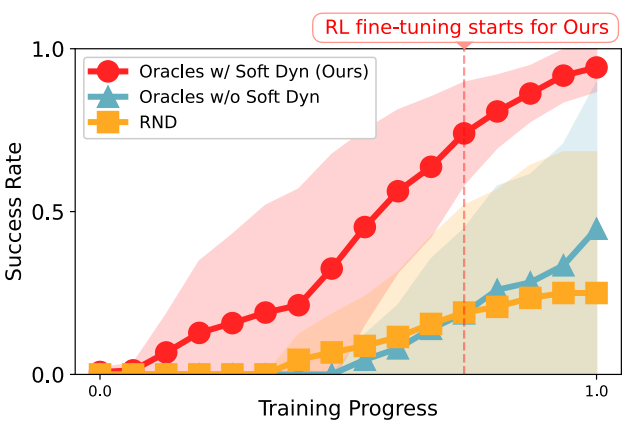
论文阅读:机器人跑酷学习
项目开源地址:https://github.com/ZiwenZhuang/parkour
摘要:
跑酷对腿部机动性是一项巨大的挑战,要求机器人在复杂环境中快速克服各种障碍。现有方法可以生成多样化但盲目的机动技能,或者是基于视觉但专门化的技能,…
《论文阅读》端到端情感原因对提取的有效子句间建模
《论文阅读》端到端情感原因对提取的有效子句间建模 前言简介模型架构Document EncodingInter-Clause Relationship ModelingClause Pair Representation Learning and Ranking损失函数问题前言
亲身阅读感受分享,细节画图解释,再也不用担心看不懂论文啦~ 无抄袭,无复制,纯…
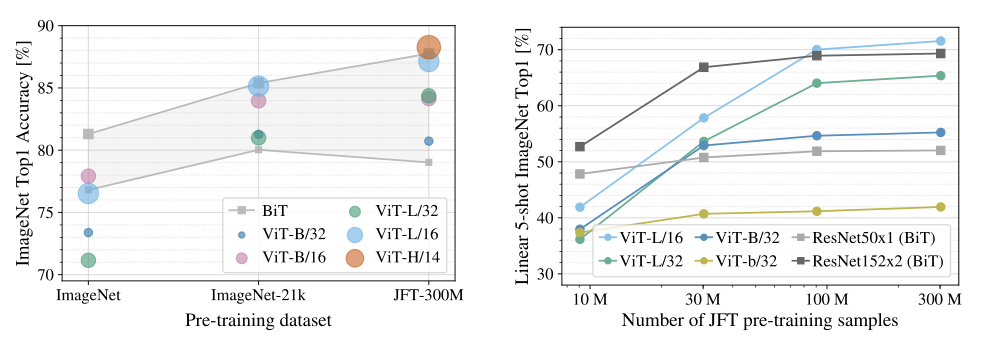
论文阅读之AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
文章目录 原文链接主要内容模型图技术细节实验结果 原文链接
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
主要内容
这篇文章的主要内容是介绍了一种新的计算机视觉模型——Vision Transformer(ViT),这是…
《论文阅读》带边界调整的联合约束学习用于情感原因对提取 ACL 2023
《论文阅读》带边界调整的联合约束学习用于情感原因对提取 前言简介Clause EncoderJoint Constrained LearningBoundary Adjusting损失函数前言
亲身阅读感受分享,细节画图解释,再也不用担心看不懂论文啦~ 无抄袭,无复制,纯手工敲击键盘~
今天为大家带来的是《Joint Cons…